解释器是一种不常使用的设计模式,它用于描述如何构成一个简单的语言解释器,主要应用于使用面向对象语言开发的编译器和解释器设计。当我们需要开发一个新的语言时,可以考虑使用解释器模式
模式动机
如果在系统中某一特定类型的问题发生的频率很高,此时可以考虑将这些问题的实例表述为一个语言中的句子。再构建一个解释器,解释器通过解释这些句子来解决对应的问题。
举个例子,我们希望系统提供一个功能来支持一种新的加减法表达式语言,当输入表达式为 "1 + 2 + 3 - 4 + 1" 时,输出计算结果为 3。为了实现上述功能,需要对输入表达式进行解释,如果不作解释,直接把 "1 + 2 + 3 - 4 + 1" 丢过去,现有的如 Java、C 之类的编程语言只会把它当作普通的字符串,不可能实现我们想要的计算效果。我们必须自己定义一套规则来实现该语句的解释,即实现一个简单语言来解释这些句子,这就是解释器模式的模式动机。
模式定义
定义语言的文法,并且建立一个解释器来解释该语言中的句子,这里的 “语言” 意思是使用规定格式和语法的代码,它是一种类行为型模式。
模式结构
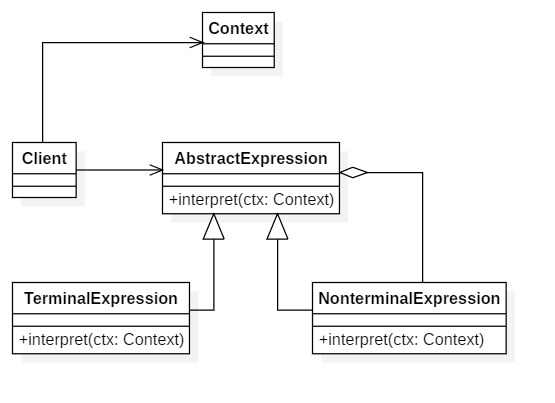
-
AbstractExpression(抽象表达式)
声明了抽象的解释操作,它是所有终结符表达式和非终结符表达式的公共父类
-
TerminalExpression(终结符表达式)
抽象表达式的子类,实现了文法中的终结符相关联的解释操作,在句子中每一个终结符都是该类的一个实例。
-
NonterminalExpression(非终结符表达式)
也是抽象表达式的子类,实现了文法中的非终结符相关联的解释操作,非终结符表达式中可以包含终结符表达式,也可以继续包含非终结符表达式,因此其解释操作一般通过递归方式来完成。
-
Context(环境类)
环境类又称上下文类,它用于存储解释器之外的一些全局信息,通常它临时存储了需要解释的语句。
-
Client(客户类)
客户类中构造了表示以规定文法定义的一个特定句子的抽象语法树,该抽象语法树由非终结符表达式和终结符表达式实例组合而成。在客户类中还将调用解释操作,实现对句子的解释,有时候为了简化客户类代码,也可以将抽象语法树的构造工作封装到专门的类中完成,客户端只需提供待解释的句子并调用该类的解释操作即可,该类可以称为解释器封装类
模式分析
还是以之前提到的加减法表达式语言来举例,我们要为这门语言定义语法规则,可以使用如下文法来定义
expression ::= value | symbol
symbol ::= expression '+' expression | expression '-' expression
value ::= an integer // 一个整数值
该文法规则包含三条定义语句,第一句是表达式的组成方式,expression 是我们最终要得到的句子,假设是 "1 + 2 + 3 - 4 + 1",那么该句的组成元素无非就是两种,数字(value)和运算符号(symbol),如果用专业术语来描述的话,symbol 和 value 称为语法构造成分或语法单位。根据句子定义,expression 要么是一个 value,要么是一个 symbol。
value 是一个终结符表达式,因为它的组成元素就是一个整数值,不能再进行分解。与之对应的 symbol 则是非终结符表达式,它的组成元素仍旧可以是表达式 expression,expression 又可以是 value 或者 symbol,即可以进一步分解。
按照上述的文法规则,我们可以通过一种称之为抽象语法树(Abstract Syntax Tree)的图形方式来直观地表示语言的构成,每一颗抽象语法树对应一个语言实例,如 "1 + 2 + 3 - 4 + 1" 可以通过如图的抽象语法树来表示。
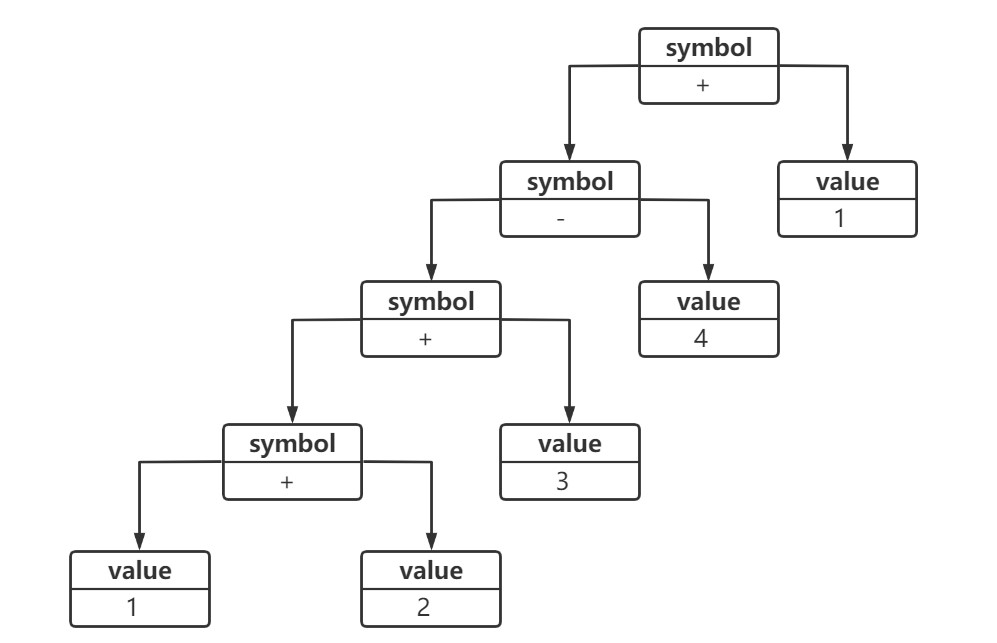
每一个具体的语句都可以用类似的抽象语法树来表示,终结符表达式类的实例作为树的叶子节点,而非终结符表达式类的实例作为非叶子节点。抽象语法树描述了如何构成一个复杂的句子,通过对抽象语法树的分析,可以识别出语言中的终结符和非终结符类。
在解释器模式中,每一个终结符和非终结符都有一个具体类与之对应,正因为使用类来表示每一个语法规则,使得系统具有较好的扩展性和灵活性。对于所有的终结符和非终结符,首先要抽象出一个公共父类
public abstract class AbstractExpression {
public abstract void interpret(Context ctx);
}
对于终结符表达式,其代码主要是对终结符元素的处理
public class TerminalExpression extends AbstractExpression {
public void interpret(Context ctx) {
// 对于终结符表达式的解释操作
}
}
对于终结符表达式,其代码比较复杂,因为通过非终结符表达式可以将表达式组合成更复杂的结构。表达式可以通过非终结符连接在一起,对于两个操作元素的非终结符表达式,其典型代码如下
public class NonterminalExpression extends AbstractExpression {
private AbstractExpression left;
private AbstractExpression right;
public NonterminalExpression(AbstractExpression left, AbstractExpression right) {
this.left = left;
this.right = right;
}
public void interpret(Context ctx) {
// 递归调用每一个组成部分的 interpret() 方法
// 在递归调用时指定组成部分的连接方式,即非终结符的功能
}
}
通常在解释器模式中还提供了一个环境类 Context,用于存储一些全局信息,用于在进行具体的解释操作时从中获取相关信息。当系统无须提供全局公共信息时,可以省略环境类
public class Context {
private HashMap map = new HashMap();
public void assign(String key, String value) {
// 往环境类中设值
}
public void lookup(String key) {
// 获取存储在环境类中的值
}
}
模式实例
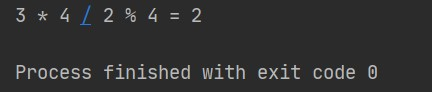
现需构造一个语言解释器,使系统可以执行整数间的乘、除和求模运算。当用户输入表达式 "3 * 4 / 2 % 4",输出结果为 2
-
抽象表达式类 Node(抽象节点)
public interface Node { public int interpret(); } -
终结符表达式类 ValueNode(值节点类)
public class ValueNode implements Node { private int value; public ValueNode(int value) { this.value = value; } @Override public int interpret() { return this.value; } } -
抽象非终结符表达式类 SymbolNode(符号节点类)
public abstract class SymbolNode implements Node { protected Node left; protected Node right; public SymbolNode(Node left, Node right) { this.left = left; this.right = right; } } -
非终结符表达式类 MulNode(乘法节点类)
public class MulNode extends SymbolNode { public MulNode(Node left, Node right) { super(left, right); } @Override public int interpret() { return super.left.interpret() * super.right.interpret(); } } -
非终结符表达式类 DivNode(除法节点类)
public class DivNode extends SymbolNode { public DivNode(Node left, Node right) { super(left, right); } @Override public int interpret() { return super.left.interpret() / super.right.interpret(); } } -
非终结符表达式类 ModNode(求模节点类)
public class ModNode extends SymbolNode { public ModNode(Node left, Node right) { super(left, right); } @Override public int interpret() { return super.left.interpret() % super.right.interpret(); } } -
解释器封装类 Calculator(计算器类)
Calculator 类是本实例的核心类之一,Calculator 类中定义了如何构造一棵抽象语法树,在构造过程中使用了栈结构 Stack。通过一连串判断语句判断字符,如果是数字,实例化终结符表达式类 ValueNode 并压栈;如果判断为运算符号,则取出栈顶内容作为其左表达式,而将之后输入的数字封装在 ValueNode 类型的对象作为其右表达式,创建非终结符表达式 MulNode 类型的对象,最后将该表达式压栈。
public class Calculator { private String statement; private Node node; public void build(String statement) { Node left = null, right = null; Stack<Node> stack = new Stack<Node>(); String[] statementArr = statement.split(" "); for (int i = 0; i < statementArr.length; i++) { if (statementArr[i].equalsIgnoreCase(("*"))) { left = stack.pop(); int val = Integer.parseInt(statementArr[++i]); right = new ValueNode(val); stack.push(new MulNode(left, right)); } else if (statementArr[i].equalsIgnoreCase(("/"))) { left = stack.pop(); int val = Integer.parseInt(statementArr[++i]); right = new ValueNode(val); stack.push(new DivNode(left, right)); } else if (statementArr[i].equalsIgnoreCase(("%"))) { left = stack.pop(); int val = Integer.parseInt(statementArr[++i]); right = new ValueNode(val); stack.push(new ModNode(left, right)); } else { stack.push(new ValueNode(Integer.parseInt(statementArr[i]))); } } this.node = stack.pop(); } public int compute() { return node.interpret(); } } -
客户端测试类 Client
程序执行时将递归调用每一个表达式类的 interpret() 的解释方法,最终完成对整棵抽象语法树的解释。
public class Client { public static void main(String[] args) { String statement = "3 * 4 / 2 % 4"; Calculator calculator = new Calculator(); calculator.build(statement); int result = calculator.compute(); System.out.println(statement + " = " + result); } } -
运行结果
模式优缺点
解释器模式优点如下:
- 易于改变和扩展文法。由于使用类来表示语言的文法规则,可以通过继承机制来改变或扩展文法。
- 易于实现文法。抽象语法树中每一个节点类的实现方式都是相似的,编写并不复杂。
- 增加了新的解释表达式的方式。增加新的表达式时无须对现有表达式类进行修改,符合开闭原则
解释器模式缺点如下:
- 对于复杂文法难以维护。
- 执行效率低。解释器模式使用了大量循环和递归调用。
- 应用场景有限。