多目标跟踪方法:deep-sort
读'Simple Online and Realtime Tracking with a Deep Association Metric, arXiv:1703.07402v1 ' 总结
前言
这篇文章依然属于tracking-by-detection 类,其在匹配detections时使用的是传统的匈牙利算法。文章中需要注意的几点包括:
在计算detections和tracks之间的匹配程度时,使用了融合的度量方式。包括卡尔曼滤波中预测位置和观测位置在马氏空间中的距离 和 bounding boxes之间表观特征的余弦距离。
其中bounding box的表观特征是通过一个深度网络得到的128维的特征
在匈牙利匹配detections和tracks时,使用的是级联匹配的方式。这里要注意的是,并不是说级联匹配的方式就比global assignment效果好,而是因为本文使用kalman滤波计算运动相似度的缺陷导致使用级联匹配方式效果更好。
具体内容
We adopt a conventional single hypothesis tracking methodology with recursive kalman filtering and frame-by-frame data association.
轨迹处理和状态估计
状态估计: 使用一个8维空间去刻画轨迹在某时刻的状态
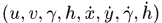 ,分别表示bounding box中心的位置、纵横比、高度、以及在图像坐标中对应的速度信息。然后使用一个kalman滤波器预测更新轨迹,该卡尔曼滤波器采用匀速模型和线性观测模型。其观测变量为
,分别表示bounding box中心的位置、纵横比、高度、以及在图像坐标中对应的速度信息。然后使用一个kalman滤波器预测更新轨迹,该卡尔曼滤波器采用匀速模型和线性观测模型。其观测变量为
轨迹处理: 这个主要说轨迹什么时候终止、什么时候产生新的轨迹。首先对于每条轨迹都有一个阈值a用于记录轨迹从上一次成功匹配到当前时刻的时间。当该值大于提前设定的阈值
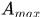 则认为改轨迹终止,直观上说就是长时间匹配不上的轨迹认为已经结束。然后在匹配时,对于没有匹配成功的detections都认为可能产生新的轨迹。但由于这些detections可能是一些false alarms,所以对这种情形新生成的轨迹标注状态'tentative' ,然后观查在接下来的连续若干帧(论文中是3帧)中是否连续匹配成功,是的话则认为是新轨迹产生,标注为'confirmed',否则则认为是假性轨迹,状态标注为'deleted'。
则认为改轨迹终止,直观上说就是长时间匹配不上的轨迹认为已经结束。然后在匹配时,对于没有匹配成功的detections都认为可能产生新的轨迹。但由于这些detections可能是一些false alarms,所以对这种情形新生成的轨迹标注状态'tentative' ,然后观查在接下来的连续若干帧(论文中是3帧)中是否连续匹配成功,是的话则认为是新轨迹产生,标注为'confirmed',否则则认为是假性轨迹,状态标注为'deleted'。
分配
匹配自然是指当前有效的轨迹和当前的detections之间的匹配。所谓有效的轨迹是指那些还存活着的轨迹,即状态为tentative和confirmed的轨迹。轨迹和detection之间的匹配程度结合了运动信息和表观信息。
运动匹配度
使用detection和track在kalman 滤波器预测的位置之间的马氏距离刻画运动匹配程度。
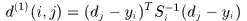
表示第j个detection和第i条轨迹之间的运动匹配度,其中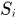 是轨迹由kalman滤波器预测得到的在当前时刻观测空间的协方差矩阵,
是轨迹由kalman滤波器预测得到的在当前时刻观测空间的协方差矩阵,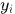 是轨迹在当前时刻的预测观测量,
是轨迹在当前时刻的预测观测量, 时第j个detection的状态
时第j个detection的状态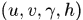
考虑到运动的连续性,可以通过该马氏距离对detections进行筛选,文中使用卡方分布的0.95分位点作为阈值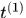 ,定义如下示性函数
,定义如下示性函数
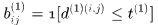
表观匹配度
单独使用马氏距离最为匹配度度量会导致IDSwitch等情形严重,特别的当相机运动时可能导致马氏距离度量失效,所以这个时候应该靠表观匹配度补救。对于每一个detection,包括轨迹中的detections,使用深度网络提取出单位范数的特征向量$r$,深度网络稍后再说。然后使用detection和轨迹包含的detections的特征向量之间的最小余弦距离作为detection和track之间的表观匹配程度。当然轨迹太长导致表观产生变化,在使用这种最小距离作为度量就有风险,所以文中只对轨迹的最新的 之内detections进行计算最小余弦距离。
之内detections进行计算最小余弦距离。

同样的,该度量同样可以确定一个门限函数 ,这个阈值由训练集得到
,这个阈值由训练集得到
两种度量的融合: 加权平均 
其中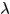 是超参数,用于调整不同项的权重。
是超参数,用于调整不同项的权重。
门限函数 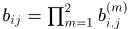
总结: 距离度量对于短期的预测和匹配效果很好,而表观信息对于长时间丢失的轨迹而言,匹配度度量的比较有效。超参数的选择要看具体的数据集,比如文中说对于相机运动幅度较大的数据集,直接不考虑运动匹配程度。
另外还有一点我想说的是这两个匹配度度量的阈值范围是不同的,如果想取相通的重要程度,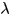 应该取0.1左右。
应该取0.1左右。
级联匹配
为什么采用级联匹配?
如果一条轨迹被遮挡了一段较长的时间,那么在kalman滤波器的不断预测中就会导致概率弥散。那么假设现在有两条轨迹竞争同一个detection,那么那条遮挡时间长的往往得到马氏距离更小,使detection倾向于分配给丢失时间更长的轨迹,但是直观上,该detection应该分配给时间上最近的轨迹。导致这种现象的原因正是由于kalman滤波器连续预测没法更新导致的概率弥散。这么理解吧,假设本来协方差矩阵是一个正态分布,那么连续的预测不更新就会导致这个正态分布的方差越来越大,那么离均值欧氏距离远的点可能和之前分布中离得较近的点获得同样的马氏距离值。
所以文中才引入了级联匹配的策略让'more frequently seen objects'分配的优先级更高。这样每次分配的时候考虑的都是遮挡时间相同的轨迹,就不存在上面说的问题了。具体的算法如下:

在匹配的最后阶段还对unconfirmed和age=1的未匹配轨迹进行基于IoU的匹配。这可以缓解因为表观突变或者部分遮挡导致的较大变化。当然有好处就有坏处,这样做也有可能导致一些新产生的轨迹被连接到了一些旧的轨迹上。但这种情况较少。
【妈蛋,这个编辑器稍微写长一点就卡成狗,卡的心情烦躁】
深度表观描述子
预训练的网络时一个在大规模ReID数据集上训练得到的,这个ReID数据集包含1261个人的1100000幅图像,使得学到的特征很适合行人跟踪。
然后使用该预训练网络作为基础网络,构建wide ResNet,用来提取bounding box的表观特征,网络结构如下:

该网络在Nvidia GeForce GTX 1050 mobile GPU下提出32个bounding boxes大约花费30ms,显然可以满足实时性要求。
实验
实验设置和结果
实验是在MOT16数据集上跑的,使用的detections并非公共检测结果。而是参考文献1中提供的检测结果. 实验结果如下表所示。

结论
相对于没使用深度表观特征的原始sort方法,IDSw下降了约45%,可见该深度表观特征的有效性
由于表观特征的使用,使轨迹因遮挡导致的motion 信息没用时不至于错误分配detection,使得ML更少,MT更多。
该方法存在的一个问题使FP太大。。,论文中分析原因有两点。一方面是detections问题,两一方面是轨迹最大允许丢失匹配的帧数!$A_{max}$太大导致去多false alarms被分配到轨迹中。提高detections的置信度可以显著提升性能。
速度够快,20Hz
总结
该方法相对简单,也容易理解。
我认为其优异性能很大程度上 取决于detections的质量很好,如果在提供的public detections上跑的话,可能要需要很复杂的预处理
在motion 匹配度时仅仅使用了距离关系,并不是真正的运动信息。我觉得这一点改用或结合速度信息,解决相似的人相遇而过导致的IDSw问题。
1 F. Yu, W.Li ,et.al. Poi: Multiple object tracking with high performance detection and appearance feature. ECCV,2016