一、把gitee仓库flask_demo中的项目下载到本地进行环境搭建作为之后的爬虫爬取的网站使用,运行之后看到页面数据为空即可!数据库以自己名字缩写命名 (25分)
进入gitee复制地址

使用git clone 下载项目

创建虚拟环境 下载项目依赖包 创建数据库 进行数据库迁移 运行项目







运行项目进入浏览器
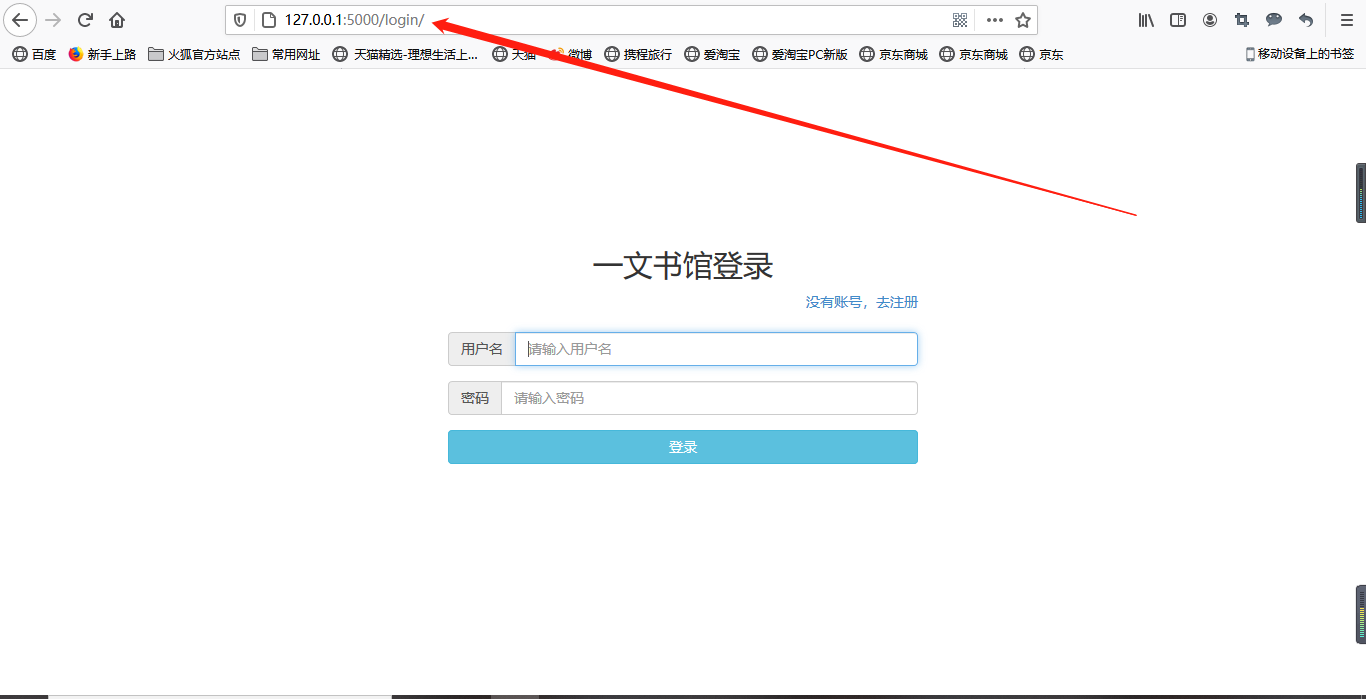

二、爬取当当网计算机网络前一百图书数据并存入mongodb中进行使用然后运行项目看到页面出现数据 (25 分)
提示由于项目中mongodb所用的数据库存放位置为下代码所示如果想自己改路径在front/views文件下更改,把数据库名字改为自己名字缩写,爬虫文件名以自己名字命名!!!!
clint = pymongo.MongoClient()
db1 = clint.dangdang
books = db1.jsjwl
需求分析
进入网址发现所需爬取的数据为json格式

产看请求所需要传递的参数,和请求方法再代码中模拟
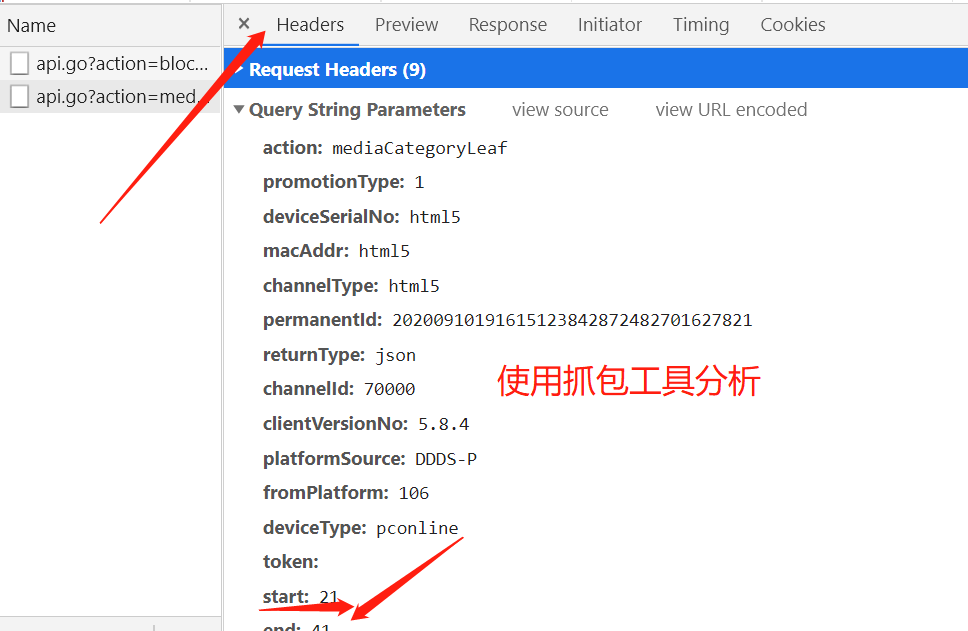
data = {
'action': 'mediaCategoryLeaf',
'start': '0',
'end': '99',
'category': 'JSJWL',
'dimension': 'dd_sale',
}
代码编写
引入模块并把数据库和所要存放的集合指定
import requests
from urllib import parse
import json
import pymongo
clint = pymongo.MongoClient()
db = clint.dangdang
books = db.jsjwl
进行UA伪装和session模拟根据分析来爬取json数据
session = requests.Session()
pre_url = 'http://e.dangdang.com/'
user = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/86.0.4240.183 Safari/537.36',
'Referer': 'http://e.dangdang.com/'
}
data = {
'action': 'mediaCategoryLeaf',
'start': '0',
'end': '99',
'category': 'JSJWL',
'dimension': 'dd_sale',
}
parse = parse.urlencode(data)
url = 'http://e.dangdang.com/media/api.go?' + parse
print(url)
session.get(pre_url, headers=user)
json_str = session.get(url, headers=user)
将数据存入mongodb数据库中
json_str = json_str.text
json_dic = json.loads(json_str)
for i in json_dic.get('data').get('saleList'):
li = []
for g in i['mediaList']:
print(g)
books.insert(g)
print('ok')
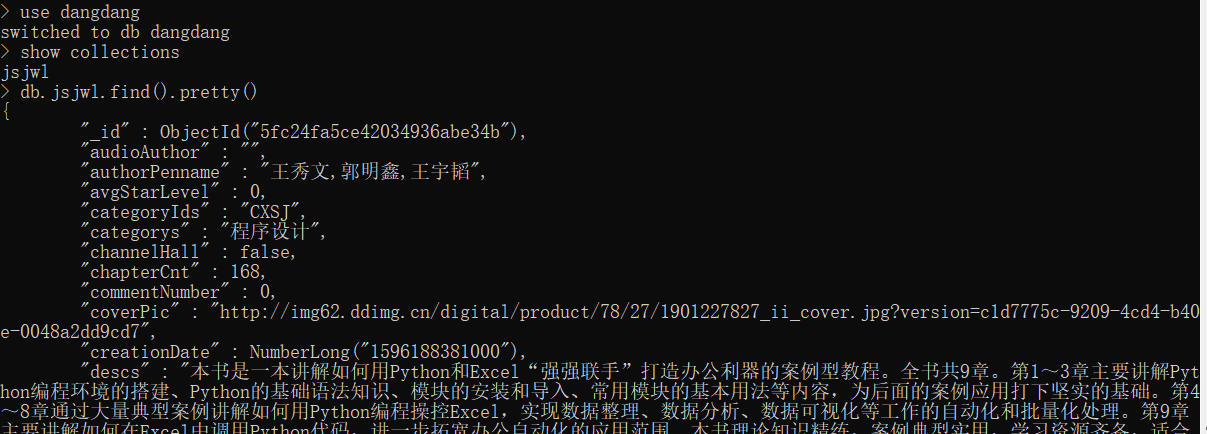
运行成功之后查看mongodb中有数据 页面显示出数据

三、根据第一二题把项目运行在本地,然后进行模拟登录使用bs4语法 (25 分)
开启本地项目,访问地址为http://127.0.0.1:5000

需求分析
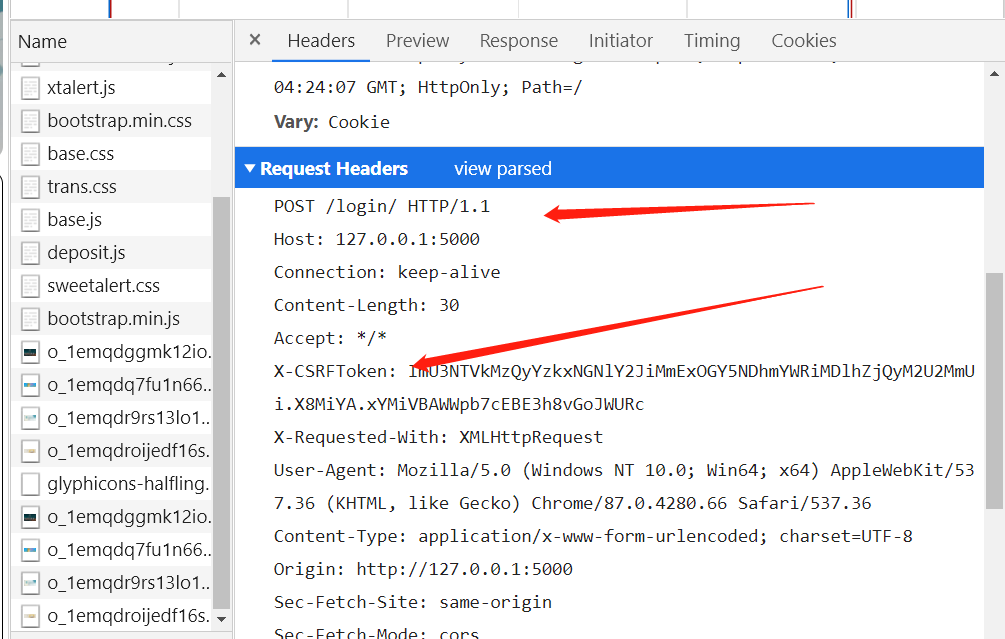
点击网址进入模拟登录分析发现登陆时有一个csrf防御,所以我们需要怕渠道input隐藏域的值和账号密码数据一起传给服务器进行登录
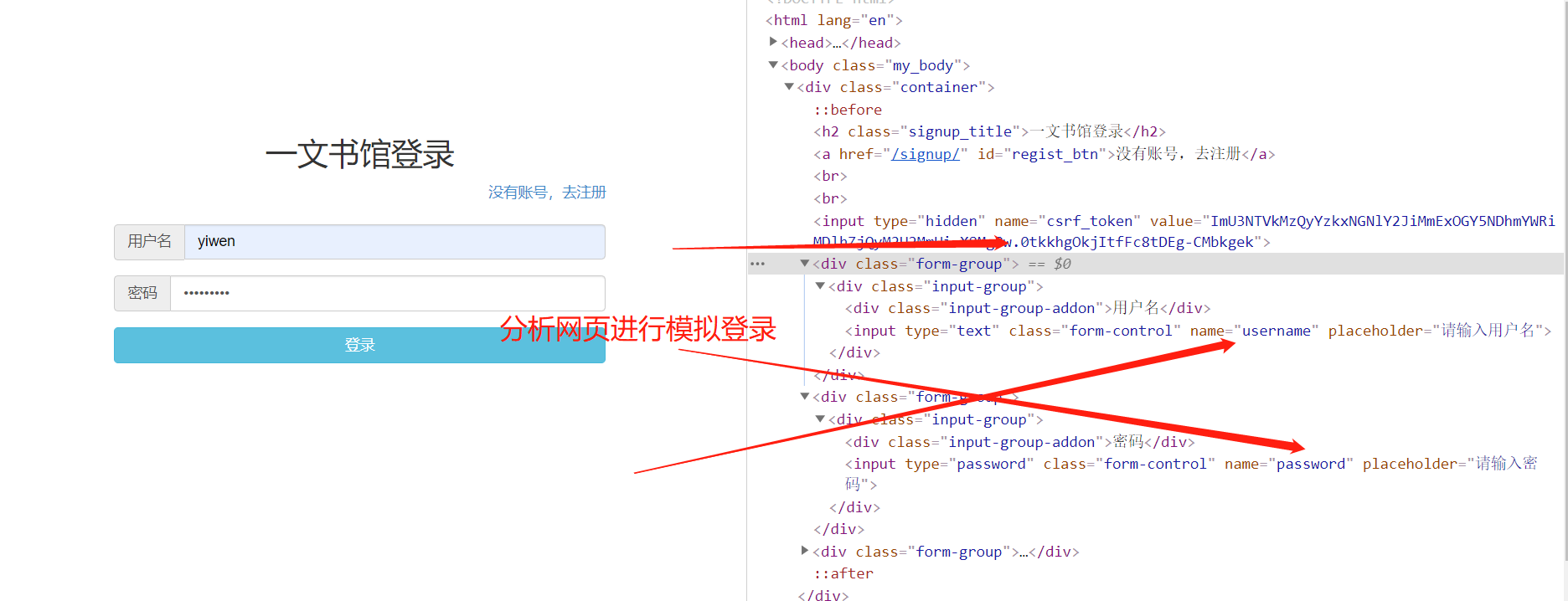
登录成功的那一刻有一个请求发送给服务器我们进行分析然后再进行代码编写
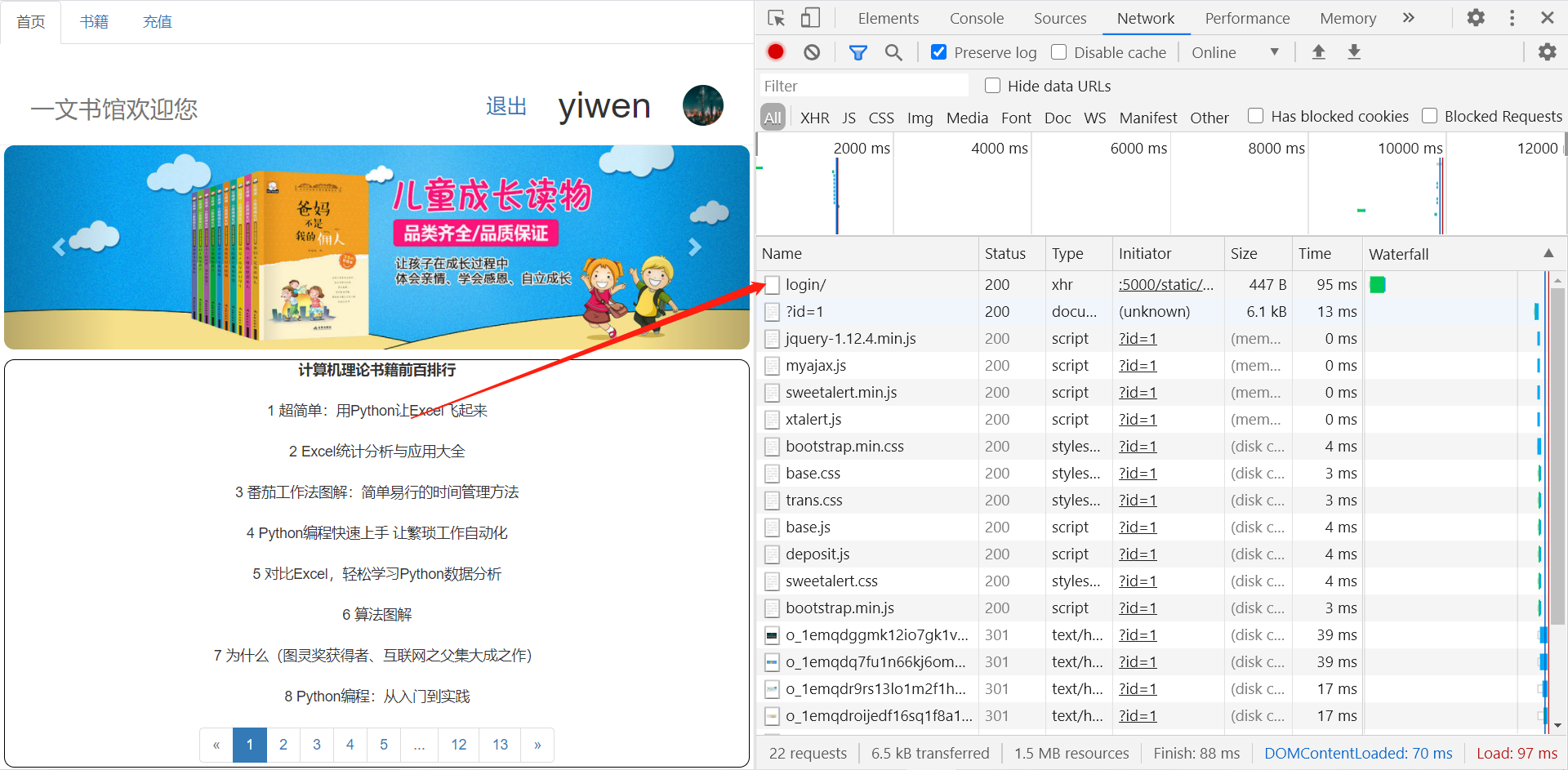
分析请求头信息和请求体信息我们之后就可以进行模拟登录和获取首页信息
编写爬虫程序进行模拟登录
引入模块爬取首页使用bs4解析到csrf_token的值
import requests
from bs4 import BeautifulSoup
session = requests.Session()
pre_url = 'http://127.0.0.1:5000/'
res = session.get(pre_url).text
soup = BeautifulSoup(res, 'lxml')
inp_text = soup.select('.container > input')[0].attrs['value']
把登录需要的data数据用post请求传参进行登录登录成功获得首页内容
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.66 Safari/537.36',
'X-CSRFToken': inp_text,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'
}
data = {
'username': 'yiwen',
'password': 'genius'
}
url = 'http://127.0.0.1:5000/login/'
res = session.post(url=url, data=data, headers=headers)
print(res.text)
print(res.headers)
print(session.get(url=pre_url).text)

四、爬取诗词名句网中三国演义这本书的全部内容并把爬取到的内容按顺序写入本地以自己名字缩写命名的文件夹中 (25分)

需求分析
进入需要爬取的网址查看发现每章节的url地址存放再href属性中

我们获得的url地址并不完整需要补全
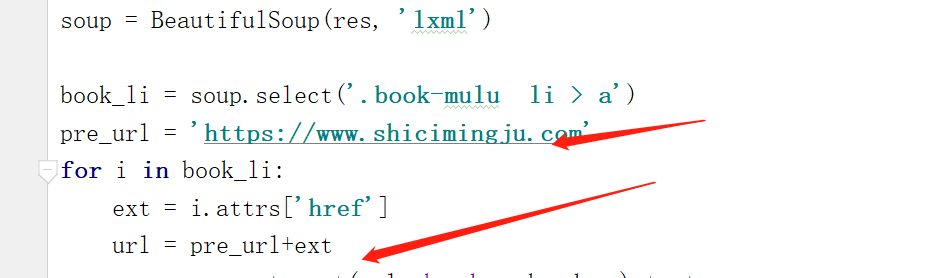
我们得到url之后去进行内容爬取发现内容在一个div下,接下来我们就可以开始代码编写了

代码编写
导入模块并判断以自己名字缩写命名的文件夹是否存在,不存在则新建
import requests
from bs4 import BeautifulSoup
import os
os.path.dirname(__file__)
sanguo = os.path.join(os.path.dirname(__file__), 'sanguo')
if not os.path.exists(sanguo):
os.mkdir(sanguo)
进行UA伪装爬取到三国演义目录对应的url
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.66 Safari/537.36 '
}
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
res = requests.get(url=url, headers=headers).text
print(res)
soup = BeautifulSoup(res, 'lxml')
book_li = soup.select('.book-mulu li > a')
循环得到的url列表进行文章内容爬取并有序不打乱目录存入本地sanguo文件夹中
pre_url = 'https://www.shicimingju.com'
for i in book_li:
ext = i.attrs['href']
url = pre_url+ext
res = requests.get(url, headers=headers).text
soup = BeautifulSoup(res, 'lxml')
context = soup.select('.chapter_content')[0].text
book = 'sanguo/'+ str(book_li.index(i)+1) + i.text + '.text'
with open(book, 'w', encoding='utf-8')as f:
f.write(context)
print('%s下载完成' % i.text)
print('下载完成')