1.explain
(1).准备基础数据(创建表,在c1字段插入重复数据,并在c1字段创建索引)
use testdb; create table t1_explain(id int,c1 char(20),c2 char(20),c3 char(20)); insert into t1_explain values(10,'a','b','c'); insert into t1_explain values(10,'a','b','c'); insert into t1_explain values(10,'a','b','c'); insert into t1_explain values(10,'a','b','c'); insert into t1_explain values(10,'a','b','c'); insert into t1_explain values(10,'a','b','c'); create index idx_c1 on t1_explain(c1);
(2).通过执行计划看一下cost值的消耗(explain format=json)
mysql> explain format=json select * from t1_explain where c1='a'G *************************** 1. row *************************** EXPLAIN: { "query_block": { "select_id": 1, "cost_info": { "query_cost": "1.10" }, "table": { "table_name": "t1_explain", "access_type": "ref", "possible_keys": [ "idx_c1" ], "key": "idx_c1", "used_key_parts": [ "c1" ], "key_length": "81", "ref": [ "const" ], "rows_examined_per_scan": 6, "rows_produced_per_join": 6, "filtered": "100.00", "index_condition": "(`testdb`.`t1_explain`.`c1` = 'a')", "cost_info": { "read_cost": "0.50", "eval_cost": "0.60", "prefix_cost": "1.10", "data_read_per_join": "1K" }, "used_columns": [ "id", "c1", "c2", "c3" ] } } } 1 row in set, 1 warning (0.00 sec) mysql>
(3).删除索引,并通过执行计划查看cost值的消耗
mysql> ALTER TABLE `testdb`.`t1_explain` DROP INDEX `idx_c1` ; Query OK, 0 rows affected (0.28 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> mysql> explain format=json select * from t1_explain where c1='a'G *************************** 1. row *************************** EXPLAIN: { "query_block": { "select_id": 1, "cost_info": { "query_cost": "0.85" }, "table": { "table_name": "t1_explain", "access_type": "ALL", "rows_examined_per_scan": 6, "rows_produced_per_join": 1, "filtered": "16.67", "cost_info": { "read_cost": "0.75", "eval_cost": "0.10", "prefix_cost": "0.85", "data_read_per_join": "248" }, "used_columns": [ "id", "c1", "c2", "c3" ], "attached_condition": "(`testdb`.`t1_explain`.`c1` = 'a')" } } } 1 row in set, 1 warning (0.01 sec) mysql>
两次查询的cost值不同,通过索引查询的cost值比全表扫描的cost值大。这是因为当通过索引查询时索引数据都是重复的(基数很低),所以要做一个索引全扫描;还因为“SELECT *”扫描完索引后要回表查询id, c2,c3这几个字段。就好比你要读完一本书,不会先把目录全部读一遍,然后再把后面的内容都读一遍。
(4).如果将c1字段的值改成不重复的,来看一下效果
重新写入基础数据
truncate table t1_explain; insert into t1_explain values(10,'a','b','c'); insert into t1_explain values(10,'b','b','c'); insert into t1_explain values(10,'c','b','c'); insert into t1_explain values(10,'d','b','c'); insert into t1_explain values(10,'e','b','c'); insert into t1_explain values(10,'f','b','c'); create index idx_c1 on t1_explain(c1);
查看执行计划
mysql> explain format=json select * from t1_explain where c1='a'G *************************** 1. row *************************** EXPLAIN: { "query_block": { "select_id": 1, "cost_info": { "query_cost": "0.35" }, "table": { "table_name": "t1_explain", "access_type": "ref", "possible_keys": [ "idx_c1" ], "key": "idx_c1", "used_key_parts": [ "c1" ], "key_length": "81", "ref": [ "const" ], "rows_examined_per_scan": 1, "rows_produced_per_join": 1, "filtered": "100.00", "index_condition": "(`testdb`.`t1_explain`.`c1` = 'a')", "cost_info": { "read_cost": "0.25", "eval_cost": "0.10", "prefix_cost": "0.35", "data_read_per_join": "248" }, "used_columns": [ "id", "c1", "c2", "c3" ] } } } 1 row in set, 1 warning (0.00 sec) mysql>
删除索引,并通过执行计划查看cost值的消耗
mysql> drop index idx_c1 on t1_explain; Query OK, 0 rows affected (0.24 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain format=json select * from t1_explain where c1='a'G *************************** 1. row *************************** EXPLAIN: { "query_block": { "select_id": 1, "cost_info": { "query_cost": "0.85" }, "table": { "table_name": "t1_explain", "access_type": "ALL", "rows_examined_per_scan": 6, "rows_produced_per_join": 1, "filtered": "16.67", "cost_info": { "read_cost": "0.75", "eval_cost": "0.10", "prefix_cost": "0.85", "data_read_per_join": "248" }, "used_columns": [ "id", "c1", "c2", "c3" ], "attached_condition": "(`testdb`.`t1_explain`.`c1` = 'a')" } } } 1 row in set, 1 warning (0.00 sec) mysql>
这次c1字段的值不重复(基数较高),则通过索引查询的cost值比全表扫描的cost值小。
这里可能没有体现出选择性,我们说基数高比较好,但是要有一个衡量目标。例如,某一字段的基数是几十万条,但是表中数据有几十亿条,在这个字段上创建索引就不是很合适,因为选择性比较低,通过索引查询在索引中可能就要扫描上亿条数据。
通常在创建索引时要考虑以上内容(回表、基数、选择性),在MySQL中可以通过系统表innodb_index_stats来查看索引选择性如何,并且可以看到组合索引中每一个字段的选择性如何,还可以计算索引的大小(单位:M)。
select stat_value as pages, index_name, stat_value * @@innodb_page_size / 1024 / 1024 as size from mysql.innodb_index_stats where table_name ='t1_explain' and database_name = 'testdb' and stat_name = 'size' and stat_description = 'Number of pages in the index' group by index_name;

如果是分区表,则使用下面的语句。
select stat_value as pages, index_name, sum(stat_value) * @@innodb_page_size / 1024 / 1024 as size from mysql.innodb_index_stats where table_name ='t#P%' and database_name = 'test' and stat_name = 'size' and stat_description = 'Number of pages in the index' group by index_name;
也可以通过show index from table_name 查看Cardinality字段的值,以及字段的基数是多少。
2.MySQL中的优化特性
(1).Nested-Loop Join Algorithm(嵌套循环Join算法)
最简单的Join算法及外循环读取一行数据,根据关联条件列到内循环中匹配关联,在这种算法中,我们通常称外循环表为驱动表,称内循环表为被驱动表。Nested-Loop Join算法的伪代码如下:
for each row in t1 matching range{ for each row in t2 matching reference key { for each row in t3{ if row satisfies join conditions,send to client } } }
(2).Block Nested-Loop Join Algorithm(块嵌套循环Join算法,即BNL算法)
BNL算法是对Nested-Loop Join算法的优化。具体做法是将外循环的行缓存起来,读取缓冲区中的行,减少内循环表被扫描的次数。例如,外循环表与内循环表均有100行记录,普通的嵌套内循环表需要扫描100次,如果使用块嵌套循环,则每次外循环读取10行记录到缓冲区中,然后把缓冲区数据传递给下一个内循环,将内循环读取到的每行和缓冲区中的10行进行比较,这样内循环表只需要扫描10次即可完成,使用块嵌套循环后内循环整体扫描次数少了一个数量级。使用块嵌套循环,内循环表扫描方式应是全表扫描,因为是内循环表匹配Join Buffer中的数据的。使用块嵌套循环连接,MySQL会使用连接缓冲区(Join Buffer),且会遵循下面一些原则:
1.连接类型为ALL、index、range,会使用到Join Buffer。 2.Join Buffer是由join_buffer_size 变量控制的。 3.每次连接都使用一个Join Buffer,多表的连接可以使用多个Join Buffer。 4.Join Buffer只存储与查询操作相关的字段数据,而不是整行记录。
BNL算法的伪代码如下:
for each row in t1 matching range{ for each row in t2 matching reference key { store used columns for t1,t2 in join buffer if buffer is full{ for each row in t3{ for each t1,t2 combination in join buffer{ if row satisfies join conditions, send to client } } empty join buffer } } } if buffer is not empty{ for each row in t3{ for each t1,t2 combination in join buffer{ if row satisfies join conditions, send to client } } }
对上面的过程解释如下:
①将t1、t2的连接结果放到缓冲区中,直到缓冲区满为止。
②遍历t3,与缓冲区内的数据匹配,找到匹配的行,发送到客户端。
③清空缓冲区。
④重复上面的步骤,直至缓冲区不满。
⑤处理缓冲区中剩余的数据,重复步骤②。
假设S是每次存储t1、t2组合的大小,C是组合的数量,则t3被扫描的次数为:(S * C)/join_buffer_size+ 1。
由此可见,随着join_buffer_size的增大,t3被扫描的次数会减少,如果join_buffer_size足够大,大到可以容纳所有t1和t2连接产生的数据,那么t3只会被扫描一次。
(3).MySQL中的优化特性
1).Index Condition Pushdown(ICP,索引条件下推)
ICP是MySQL针对索引从表中检索时的一种优化特性,在没有ICP时处理过程如下图所示:
①根据索引读取一条索引记录,然后使用索引的叶子节点中的主键值回表读取整个表行。
②判断这行记录是否符合where条件。
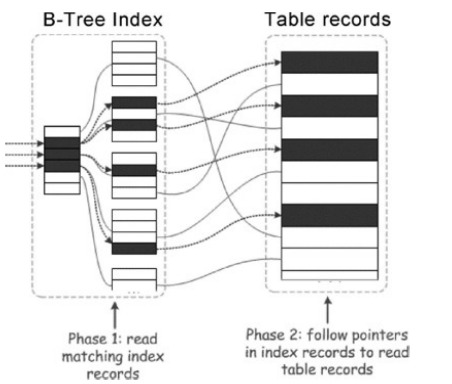
有ICP后处理过程如下图所示:

①根据索引读取一条索引记录,但并不回表取出整行数据。
②判断记录是否满足where条件的一部分,并且只能使用索引字段进行检查。如果不满足条件,则继续获取下一条索引记录。
③如果满足条件,则使用索引回表取出整行数据。
④再判断where条件的剩余部分,选择满足条件的记录。
ICP的意思就是筛选字段在索引中的where条件从服务器层下推到存储引擎层,这样可以在存储引擎层过滤数据。由此可见,ICP可以减少存储引擎访问基表的次数和MySQL服务器访问存储引擎的次数。
ICP的使用场景如下:
1.组合索引(a,b)where条件中的a字段是范围扫描,那么后面的索引字段b则无法使用到索引。在没有ICP时需要把满足a字段条件的数据全部提取到服务器层,并且会有大量的回表操作;而有了ICP之后,则会将b字段条件下推到存储引擎层,以减少回表次数和返回给服务器层的数据量。 2.组合索引(a,b)的第一个字段的选择性非常低,第二个字段查询时又利用不到索引(%b%),在这种情况下,通过ICP也能很好地减少回表次数和返回给服务器层的数据量。
ICP的使用限制如下:
1.只能用于InnoDB和MyISAM。 2.适用于range、ref、eq_ref和ref_or_null访问方式,并且需要回表进行访问。 3.适用于二级索引。 4.不适用于虚拟字段的二级索引。
2).Multi-Range Read(MRR)
如果通过二级索引扫描时需要回表查询数据,那么此时由于主键顺序与二级索引的顺序不一致会导致大量的随机I/O。而通过Multi-Range Read特性,MySQL会将索引扫描到的数据根据rowid进行一次排序,然后再回表查询。此方式的好处是将回表查询从随机I/O转换成顺序I/O。
在没有MRR时,通过索引查询到数据之后回表形式如下图所示:

从上图中可以看到,当通过二级索引扫描完数据之后,根据rowid(或者主键)回表查询,但是这个过程是随机访问的。如果表数据量非常大,在传统的机械硬盘中IOPS不高的情况下性能会很差。
有了MRR之后,回表形式如下图所示:
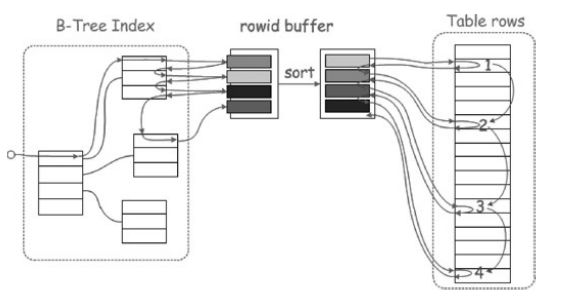
根据索引查询完之后会将rowid放到缓冲区中进行排序,排序之后再回表访问,此时是顺序I/O。这里排序所用到的缓冲区是由参数read_rnd_buffer_size所控制的。
3).Batched Key Access(BKA)
BKA是对BNL算法的更一步扩展及优化,其作用是在表连接时可以进行顺序I/O,所以BKA是在MRR基础之上实现的,同时BKA支持内连接、外连接和半连接操作。当两个表连接时,在没有BKA的情况下如下图所示,可以看到访问t2表时是随机I/O。
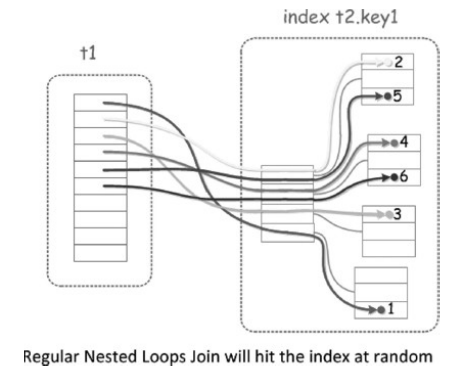
有了BKA之后如下图所示,可以看到对t2表进行连接访问时,先将t1中相关的字段放入Join buffer中,然后利用MRR特性接口进行排序(根据rowid),排序之后即可通过rowid到t2表中进行查找。

这里也有一个隐含的条件,就是关联字段需要有索引,否则还是会使用BNL算法的。