简介
命名实体识别(Named Entity Recognition, NER)旨在从文本中抽取出命名实体,比如人名、地名、机构名等。它是一个非常重要的基础性任务,可以有效帮助后续的文本语义理解。
NER任务一般有两种类型:flat NER和nested NER。前者就是普通的NER,每个token只对应一个label;后者是比较复杂的NER,每个的token对应若干个label。除非特殊声明,一般提到的NER默认为flat NER。
本文将介绍如下几个具有影响力的NER相关工作:
| 模型 | 年份 | 备注 |
|---|---|---|
| BiLSTM-CRF | 2015 | 基础、经典模型 |
| Lattice LSTM | 2018 | 词+字经典模型 |
| SoftLexicon | 2020 | 提出一种融入词信息的方法,可以用在不同模型上 |
| FLAT | 2020 | |
| BERT-MRC | 2020 | |
| A Rigourous Study on NER | 2020 | 通过控制变量法来探讨NER的关键因素 |
| Lex-BERT | 2021 | 更加优雅的 |
单纯使用预训练微调来完成NER的方法本文不作介绍。
BiLSTM-CRF[1], 2015
BiLSTM-CRF模型是非常经典的NER模型,有三点优势:
- 凭借双向LSTM可以高效地利用过去和未来的输入特征;
- 凭借CRF层可以利用句子级的标签信息;
- 和之前的工作相比,模型具有鲁棒性,对词嵌入的依赖更弱;
BiLSTM-CRF的模型结构非常简单,如下图所示:
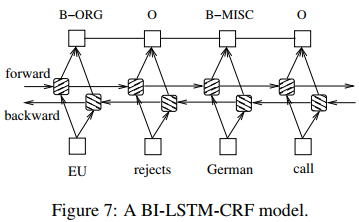
凭借当前的深度学习框架,只需要几行代码即可实现该模型。以下是关于BiLSTM-CRF的一些实战经验(大部分来自论文):
- 模型性能和隐藏单元大小无关;
- 模型在10个epoch内就可以收敛;
- 单独使用CRF非常依赖于人工特征,相比之下BiLSTM和BiLSTM-CRF对此影响较小,具有一定的鲁棒性;
- 一般情况,基于字的NER比基于词的NER效果好;
- 使用BiLSTM-CRF可以在输入多拼接些词嵌入,比如BERT等预训练模型得到的词嵌入,或者word2vec、glove等传统方法的词嵌入;
Lattice LSTM[2], 2018
基于词的NER存在分词错误传播,因此往往采用更细粒度的基于字的NER方法,虽然该过程会丢失词信息,但是成绩更好(事实上F1一般都可以达到90+)。尽管如此,还是有很多工作尝试融入词信息,LatticeLSTM就是这类思路的一个代表模型,它把词的嵌入特征也输入到了模型中,模型结构如下:

Lattice LSTM利用额外的LSTM单元来提取词级的特征,于是对于存在多种实体组合可能的句子,每个字符位置处的LSTM会接受多个输入,如下图所示,“桥”所对应LSTM单元会接受额外两个输入。
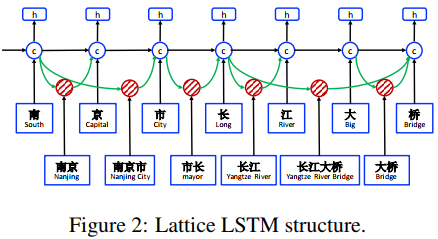
Lattice LSTM的结果有了2到3个百分点的提升,但是缺点也非常明显,由于句子中词的组合形式千变万化(正如它的名字“栅格”一样),这就使得模型非常复杂,训练困难。
FLAT[3], 2020
FLAT参考Transformer-XL利用相对位置编码来把词的信息融入到Transformer中去。
SoftLexicon[4], 2020
SoftLexicon把BMES四个特征和字嵌入拼接,这种方式看起来很好,但是在总结词集合各个词嵌入时直接均化词嵌入感觉还是会丢失语义信息。仅根据论文,SoftLexicon的成绩是比FLAT更好的,而且计算要更加简单。
BERT-MRC, 2020
BERT-MRC把NER当成阅读理解任务,这样实现了一个模型搞定两种NER任务(flat ner和nested ner),并且BERT-MRC具有一定的零样本学习能力。
A rigourous study on NER[5], 2020
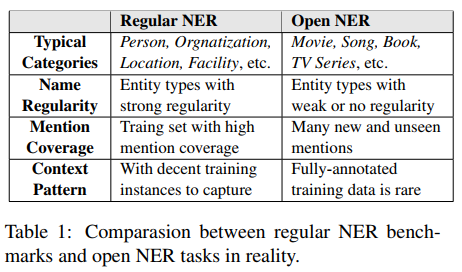
regular NER一般会有如下三个问题:
- strong name regularity: 同一实体类的名字规律性太强。比如姓名一般由姓和名组成,地名一般带有街、路;
- high mention coverage: 由于训练集和测试集来自于同一个语料,所以测试集中的实体很大部分都已经在训练集中见过了;
- sufficient context diversity: 由于训练语料足够多,以至于能够对实体上下文进行充分的学习;
所以在这些数据集上模型很容易达到SOTA,但是open NER和regular NER是有差距(discrepancy)的,如下图所示。
本文将通过randomization test实验来解释regular NER和open NER之间差异,然后总结一些结论来更有效更高效地构建NER模型。
- name permuation(NP):将相同的name替换成相同的n-gram字符串;
- mention permutation(MP):将每个mention都替换成独一无二的n-gram字符串;
- context reduction(CR):降低训练集中context的多样性,保留所有entity mention;
- mention reduction(MR):保留context的多样性,减少entity mention;
略过繁琐的实验细节,直接来看实验结论:
1. Decent name regularity is vital to the generalization over unseen entity mentions
实验结果表明,如果实体在训练集中出现过,那么name regularity的缺失对性能不会有很大的影响;但是对于一些训练集没有见过的实体,缺失name regularity会对结果造成较大的影响。这一结论表明,如果我们降低了训练集和测试集之间的实体重合率,那么实体的名字最好要有规律,对于一些比较随意的、不形成规律的实体,比如歌名、电影名,NER的结果会下滑。
这也能解释为什么ABSA任务中的target抽取结果会比较差。
2. High mention coverage weakens the model ability to capture informative context knowledge
实验结果表明,测试集中的实体如果大量出现在训练集中,那么这样只会导致模型过拟合。
3. Sufficient context diversity may not require enormous training data to capture
从零开始适当增加语料可以同时让模型学习到name regularity和context diversity,但是二者是分开的。文中指出3000条语料差不多就可以让模型学到充足的context pattern,再增加语料就没有必要了,此时可以考虑使用一些词典来替换语料中的实体词,从而达到继续学习name regularity的目的。
From the above experiments, it seems that once it reaches a certain amount, the instances in training data are enough to capture sufficient context patterns. And increasing training instances can mainly provide more name regularity knowledge rather than more context diversity.
Bidirectional LSTM-CRF Models for Sequence Tagging. Zhiheng Huang. 2015 ↩︎
Chinese NER using lattice LSTM. Zhang Yue, Jie Yang. 2018 ↩︎
FLAT: Chinese NER Using Flat-Lattice Transformer. Xiaonan Li, Hang Yan, Xipeng Qiu, Xuanjing Huang. ACL 2020 ↩︎
Simplify the Usage of Lexicon in Chinese NER. Ruotian Ma, Minlong Peng, Qi Zhang, Zhongyu Wei, Xuanjing Huang. ACL 2020 ↩︎
A Rigourous Study on Named Entity Recognition: Can Fine-tuning Pretrained Model Lead to the Promised Land?. Hongyu Lin, Yaojie Lu, Xianpei Han, Le Sun. EMNLP 2020 ↩︎