功能概述
Redis Cluster是Redis的自带的官方分布式解决方案,提供数据分片、高可用功能,在3.0版本正式推出。
使用Redis Cluster能解决负载均衡的问题,内部采用哈希分片规则:
基础架构图如下所示:
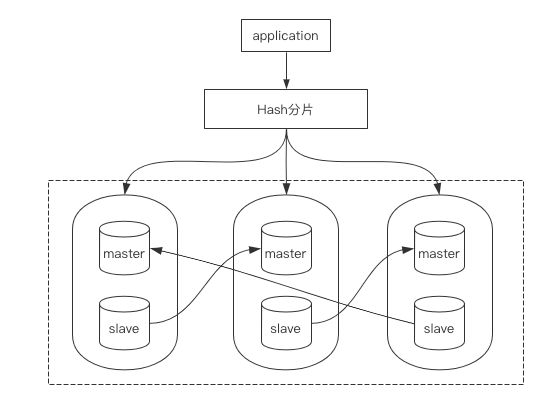
图中最大的虚线部分为一个Cluster集群,由6个Redis实例组成。
集群分片
整个Cluster集群中有16384个槽位,必须要将这些槽位分别规划在3台Master中。
如果有任意1个槽位没有被分配,则集群创建不成功。
当集群中任意一个Master尝试进行写入操作后,会通过Hash算法计算出该条数据应该落在哪一个Master节点上。
如下图所示:
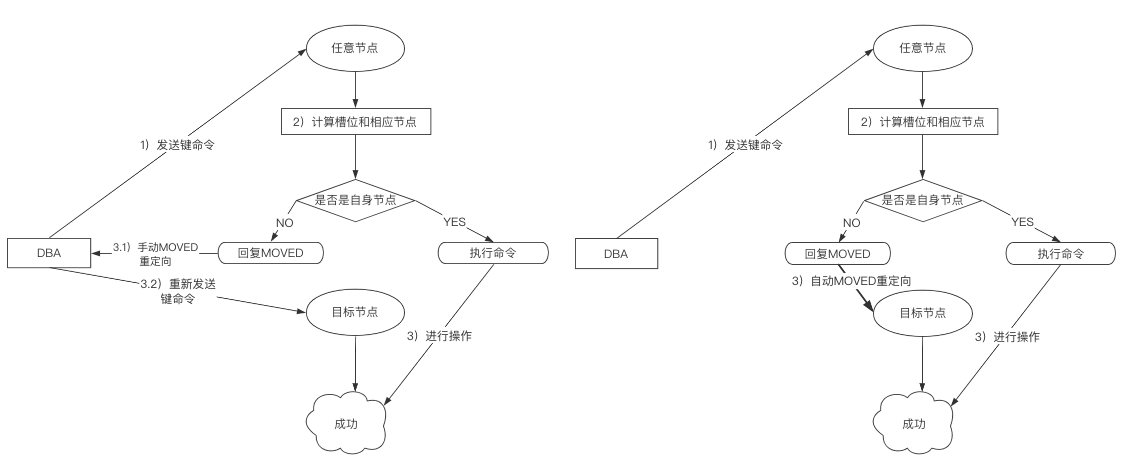
情况1:如果你未指定任何参数就进行写入,如在Master1上写入数据,经过内部计算发现该数据应该在Master2上写入时,会提示你应该进入Master2写入该条数据,执行并不会成功
情况2:如果你指定了一个特定参数进行写入,如在Master1上写入数据,经过内部计算发现该数据应该在Master2上写入时,会自动将写入环境重定向至Master2,执行成功
同理,读取数据也是这样,这个过程叫做MOVED重定向,如果你是情况1进行操作则必须手动进行重定向,情况2则会自动进行重定向。
集群通信
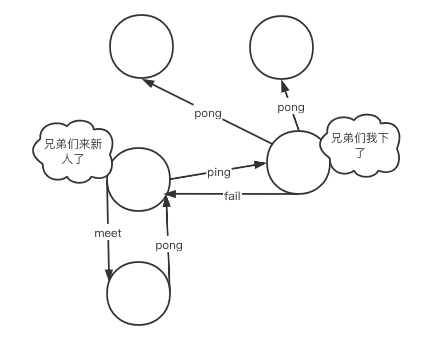
集群中各个节点的信息是互通的,这种现象由Gossip(流言)协议产生。
Gossip协议规定每个集群节点之间互相交换信息,使其能够彼此知道对方的状态。
在通信建立时,集群中的每一个节点都会单独的开辟一个TCP通道,用于与其他节点进行通信,这个通信端口会在基础端口上+10000。
通信建立成功后,每个节点在固定周期内通过特定规则选择节点来发送ping消息(心跳机制)。
当收到ping消息的节点则会使用pong消息作为回应,也就是说,当有一个新节点加入后,一瞬间集群中所有的其他节点也能够获取到该信息。
Gossip协议的主要职责就是进行集群中节点的信息交换,常见的Gossip协议消息有以下几点区分:
- meet:用于通知新节点加入,消息发送者通知接受者加入到当前集群
- ping:集群内每个节点与其他节点进行心跳检测的命令,用于检测其他节点是否在线,除此之外还能交换其他额外信息
- pong:用于回复meet以及ping信息,表示已收到,能够正常通行。此外还能进行群发更新节点状态
- fail:当其他节点收到fail消息后立马把对应节点更新为下线状态,此时集群开始进行故障转移
初步搭建
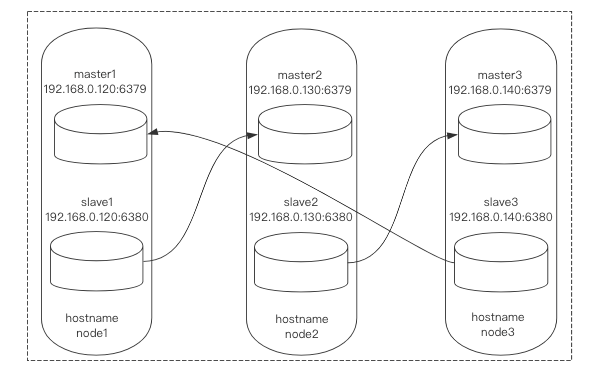
地址规划
3台服务器,每台服务器开启2台实例构建基础主从。
服务器采用centos7.3,Redis版本为6.2.1
地址规划与结构图如下:
在每个节点hosts文件中加入以下内容;
$ vim /etc/hosts
192.168.0.120 node1
192.168.0.130 node2
192.168.0.140 node3
集群准备
为所有节点下载Redis:
$ cd ~
$ wget https://download.redis.io/releases/redis-6.2.1.tar.gz
为所有节点配置目录:
$ mkdir -p /usr/local/redis_cluster/redis_63{79,80}/{conf,pid,logs}
所有节点进行解压:
$ tar -zxvf redis-6.2.1.tar.gz -C /usr/local/redis_cluster/
所有节点进行编译安装Redis:
$ cd /usr/local/redis_cluster/redis-6.2.1/
$ make && make install
书写集群配置文件,注意!Redis普通服务会有2套配置文件,一套为普通服务配置文件,一套为集群服务配置文件,我们这里是做的集群,所以书写的集群配置文件,共6份:
$ vim /usr/local/redis_cluster/redis_6379/conf/redis.cnf
# 快速修改::%s/6379/6380/g
# 守护进行模式启动
daemonize yes
# 设置数据库数量,默认数据库为0
databases 16
# 绑定地址,需要修改
bind 192.168.0.120
# 绑定端口,需要修改
port 6379
# pid文件存储位置,文件名需要修改
pidfile /usr/local/redis_cluster/redis_6379/pid/redis_6379.pid
# log文件存储位置,文件名需要修改
logfile /usr/local/redis_cluster/redis_6379/logs/redis_6379.log
# RDB快照备份文件名,文件名需要修改
dbfilename redis_6379.rdb
# 本地数据库存储目录,需要修改
dir /usr/local/redis_cluster/redis_6379
# 集群相关配置
# 是否以集群模式启动
cluster-enabled yes
# 集群节点回应最长时间,超过该时间被认为下线
cluster-node-timeout 15000
# 生成的集群节点配置文件名,文件名需要修改
cluster-config-file nodes_6379.conf
启动集群
启动集群
在启动集群时,会按照Redis服务配置文件的配置项判断是否启动集群模式,如图所示:
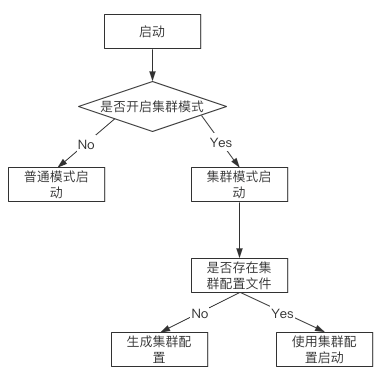
每个节点上执行以下2条命令进行服务启动:
$ redis-server /usr/local/redis_cluster/redis_6379/conf/redis.cnf
$ redis-server /usr/local/redis_cluster/redis_6380/conf/redis.cnf
集群模式启动,进程后会加上[cluster]的字样:
$ ps -ef | grep redis
root 51311 1 0 11:30 ? 00:00:00 redis-server 192.168.0.120:6379 [cluster]
root 51329 1 0 11:30 ? 00:00:00 redis-server 192.168.0.120:6380 [cluster]
root 51396 115516 0 11:31 pts/1 00:00:00 grep --color=auto redis
同时,查看一下集群节点配置文件,会发现生成了一组集群信息,每个Redis服务都是不同的:
$ cat /usr/local/redis_cluster/redis_6379/nodes_6379.conf
c8a8c7d52e6e7403e799c75302b6411e2027621b :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
$ cat /usr/local/redis_cluster/redis_6380/nodes_6380.conf
baa10306639fcaca833db0d521235bc9593dbeca :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
# 第一段信息是这个Redis服务作为集群节点的一个身份编码
# 别名为集群的node-id
加入集群
现在虽然说每个服务都成功启动了,但是彼此之间并没有任何联系。
所以下一步要做的就是将6个服务加入至一个集群中,如下操作示例:
$ redis-cli -h node1 -p 6379
node1:6379> cluster meet 192.168.0.130 6379
node1:6379> cluster meet 192.168.0.140 6379
node1:6379> cluster meet 192.168.0.120 6380
node1:6379> cluster meet 192.168.0.130 6380
node1:6379> cluster meet 192.168.0.140 6380
查看当前集群所有的节点:
node1:6379> cluster nodes
214dc5a10149091047df1c61fd3415d91d6204ea 192.168.0.130:6379@16379 master - 0 1617291123000 1 connected
baa10306639fcaca833db0d521235bc9593dbeca 192.168.0.120:6380@16380 master - 0 1617291120000 3 connected
7a151f97ee9b020a3c954bbf78cd7ed8a674aa70 192.168.0.140:6379@16379 master - 0 1617291123000 2 connected
bae708f7b8df32edf4571c72bbf87715eb45c169 192.168.0.130:6380@16380 master - 0 1617291124175 4 connected
fd1dde2a641727e52b4e82cfb351fe3c17690a17 192.168.0.140:6380@16380 master - 0 1617291124000 0 connected
c8a8c7d52e6e7403e799c75302b6411e2027621b 192.168.0.120:6379@16379 myself,master - 0 1617291121000 5 connected
查看端口监听,可以发现Gossip监听的1000+端口出现了,此时代表集群各个节点之间已经能互相通信了:
$ netstat -lnpt | grep redis
tcp 0 0 192.168.0.120:6379 0.0.0.0:* LISTEN 51311/redis-server
tcp 0 0 192.168.0.120:6380 0.0.0.0:* LISTEN 51329/redis-server
tcp 0 0 192.168.0.120:16379 0.0.0.0:* LISTEN 51311/redis-server
tcp 0 0 192.168.0.120:16380 0.0.0.0:* LISTEN 51329/redis-server
主从配置
6个服务之间并没有任何主从关系,所以现在进行主从配置,记录下上面cluster nodes命令输出的node-id信息,只记录主节点:
| hostname | 节点 | node-id |
|---|---|---|
| node1 | 192.168.0.120:6379 | c8a8c7d52e6e7403e799c75302b6411e2027621b |
| node2 | 192.168.0.130:6379 | 214dc5a10149091047df1c61fd3415d91d6204ea |
| node3 | 192.168.0.140:6379 | 7a151f97ee9b020a3c954bbf78cd7ed8a674aa70 |
首先是node1的6380,将它映射到node2的6379:
$ redis-cli -h node1 -p 6380
node1:6380> cluster replicate 214dc5a10149091047df1c61fd3415d91d6204ea
然后是node2的6380,将它映射到node3的6379:
$ redis-cli -h node2 -p 6380
node2:6380> cluster replicate 7a151f97ee9b020a3c954bbf78cd7ed8a674aa70
最后是node3的6380,将它映射到node1的6379:
$ redis-cli -h node3 -p 6380
node3:6380> cluster replicate c8a8c7d52e6e7403e799c75302b6411e2027621b
查看集群节点信息,内容有精简:
$ redis-cli -h node1 -p 6379
node1:6379> cluster nodes
192.168.0.130:6379@16379 master
192.168.0.120:6380@16380 slave
192.168.0.140:6379@16379 master
192.168.0.130:6380@16380 slave
192.168.0.140:6380@16380 slave
192.168.0.120:6379@16379 myself,master
# myself表示当前登录的是那个服务
分配槽位
接下来我们要开始分配槽位了,为了考虑今后的写入操作能分配均匀,槽位也要进行均匀分配。
仅在Master上进行分配,从库不进行分配,仅做主库的备份和读库使用。
使用python计算每个master节点分多少槽位:
$ python3
>>> divmod(16384,3)
(5461, 1)
槽位分配情况如下,槽位号从0开始,到16383结束,共16384个槽位:
| 节点 | 槽位数量 |
|---|---|
| node1:6379 | 0 - 5461 |
| node2:6379 | 5461 - 10922 |
| node3:6379 | 10922 - 16383 |
开始分配:
$ redis-cli -h node1 -p 6379 cluster addslots {0..5461}
$ redis-cli -h node2 -p 6379 cluster addslots {5462..10922}
$ redis-cli -h node3 -p 6379 cluster addslots {10923..16383}
检查槽位是否分配正确,这里进行内容截取:
$ redis-cli -h node1 -p 6379
node1:6379> CLUSTER nodes
192.168.0.130:6379@16379 master - 0 1617292240544 1 connected 5462-10922
192.168.0.140:6379@16379 master - 0 1617292239000 2 connected 10923-16383
192.168.0.120:6379@16379 myself,master - 0 1617292238000 5 connected 0-5461
# 看master节点的最后
检查状态
使用以下命令检查集群状态是否ok,如果槽位全部分配完毕应该是ok,不然的话就检查你分配槽位时是否输错了数量:
$ redis-cli -h node1 -p 6379
node1:6379> CLUSTER info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:5
cluster_stats_messages_ping_sent:2825
cluster_stats_messages_pong_sent:2793
cluster_stats_messages_meet_sent:5
cluster_stats_messages_sent:5623
cluster_stats_messages_ping_received:2793
cluster_stats_messages_pong_received:2830
cluster_stats_messages_received:5623
MOVED重定向
现在我们在node1的master节点上进行写入:
$ redis-cli -h node1 -p 6379
node1:6379> set k1 "v1"
(error) MOVED 12706 192.168.0.140:6379
它会提示你去node2的master上进行写入。
这个就是MOVED重定向。
-c参数
如何解决这个问题?其实在登录的时候加上参数-c即可,-c参数无所谓你的Redis是否是集群模式,建议任何登录操作都加上,这样即使是Redis集群也会自动进行MOVED重定向:
$ redis-cli -c -h node1 -p 6379
node1:6379> set k1 "v1"
-> Redirected to slot [12706] located at 192.168.0.140:6379
OK
一并对主从进行验证,这条数据是写入至了node3的Master中,我们登录node2的Slave中进行查看:
$ redis-cli -h node2 -p 6380 -c
node2:6380> keys *
1) "k1"
故障转移
故障模拟
模拟node1的6379下线宕机,此时应该由node3的6380接管它的工作:
$ redis-cli -h node1 -p 6379 shutdown
登录集群任意节点查看目前的集群节点信息:
node2:6379> cluster nodes
214dc5a10149091047df1c61fd3415d91d6204ea 192.168.0.130:6379@16379 myself,master - 0 1617294532000 1 connected 5462-10922
bae708f7b8df32edf4571c72bbf87715eb45c169 192.168.0.130:6380@16380 slave 7a151f97ee9b020a3c954bbf78cd7ed8a674aa70 0 1617294533000 2 connected
# 已下线
c8a8c7d52e6e7403e799c75302b6411e2027621b 192.168.0.120:6379@16379 master,fail - 1617294479247 1617294475173 5 disconnected
7a151f97ee9b020a3c954bbf78cd7ed8a674aa70 192.168.0.140:6379@16379 master - 0 1617294536864 2 connected 10923-16383
# 自动升级为主库,并且插槽也转移了
fd1dde2a641727e52b4e82cfb351fe3c17690a17 192.168.0.140:6380@16380 master - 0 1617294536000 6 connected 0-5461
baa10306639fcaca833db0d521235bc9593dbeca 192.168.0.120:6380@16380 slave 214dc5a10149091047df1c61fd3415d91d6204ea 0 1617294535853 1 connected
恢复工作
重启node1的6379:
$ redis-server /usr/local/redis_cluster/redis_6379/conf/redis.cnf
登录node1的6379,发现他已经自动的进行上线了,并且作为node3中6380的从库:
$ redis-cli -h node1 -p 6379
node1:6379> cluster nodes
# 自动上线
c8a8c7d52e6e7403e799c75302b6411e2027621b 192.168.0.120:6379@16379 myself,slave fd1dde2a641727e52b4e82cfb351fe3c17690a17 0 1617294746000 6 connected
cluster命令
以下是集群中常用的可执行命令,命令执行格式为:
cluster 下表命令
命令如下,未全,如果想了解更多请执行cluster help操作:
| 命令 | 描述 |
|---|---|
| INFO | 返回当前集群信息 |
| MEET <ip> <port> [<bus-port>] | 添加一个节点至当前集群 |
| MYID | 返回当前节点集群ID |
| NODES | 返回当前节点的集群信息 |
| REPLICATE <node-id> | 将当前节点作为某一集群节点的从库 |
| FAILOVER [FORCE|TAKEOVER] | 将当前从库升级为主库 |
| RESET [HARD|SOFT] | 重置当前节点信息 |
| ADDSLOTS <slot> [<slot> ...] | 为当前集群节点增加一个或多个插槽位,推荐在bash shell中执行,可通过{int..int}指定多个插槽位 |
| DELSLOTS <slot> [<slot> ...] | 为当前集群节点删除一个或多个插槽位,推荐在bash shell中执行,可通过{int..int}指定多个插槽位 |
| FLUSHSLOTS | 删除当前节点中所有的插槽信息 |
| FORGET <node-id> | 从集群中删除某一节点 |
| COUNT-FAILURE-REPORTS <node-id> | 返回当前集群节点的故障报告数量 |
| COUNTKEYSINSLOT <slot> | 返回某一插槽中的键的数量 |
| GETKEYSINSLOT <slot> <count> | 返回当前节点存储在插槽中的key名称。 |
| KEYSLOT <key> | 返回该key的哈希槽位 |
| SAVECONFIG | 保存当前集群配置,进行落盘操作 |
| SLOTS | 返回该插槽的信息 |