一、迭代器
1.什么是迭代器
迭代:就是重复做一些事情,但是每一个重复都必须基于上一次重复的结果
迭代器:迭代取值的工具
看看如下的案例,就不属于是迭代
n = 0
while True:
print(n)
迭代:
l=['a','b','c'] def iterator(item): i=0 while i < len(item): print(l[i]) i+=1
2.为什么要有迭代器?
迭代器提供一种不依赖索引取值的方式。基于索引的迭代器取值方式只适用于列表、元祖、字符串类型。
而对于没有索引的字典、集合、文件则不适用
3.可以迭代取值的对象
在python中但凡有__iter__方法的对象,都是可迭代对象;
字符串、列表、字典、元祖、集合、文件,只有数字不是可迭代对象;
文件对象本身就是迭代器对象
num1=10 num2=10.1 s1='hello' l=[1,2,3] t=(1,2,3) d={'x':1} s2={1,2,3} f=open('a.txt','w') s1.__iter__() l.__iter__() t.__iter__() d.__iter__() s2.__iter__() f.__iter__()
迭代器对象一定是可迭代对象。
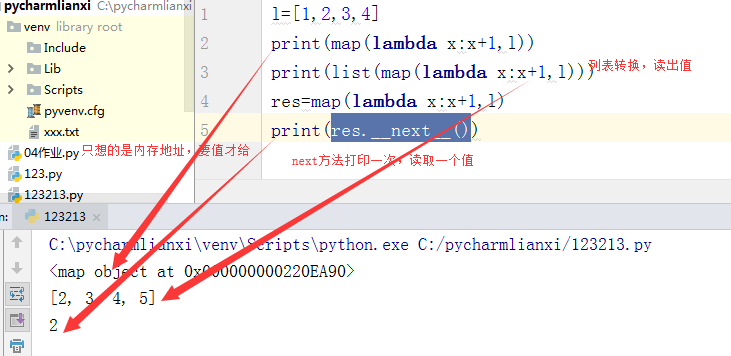
迭代器的调用方式不是打印迭代器,而是执行双下next方法。否则打印出来的就是他对应的内存地址
info={'name':'wuxi','age':22,'is_beautiful':True,'sex':'male'}
info_iter=info.__iter__() #加_iter_变成迭代器对象
print(info_iter) #打印出的是字典的内存地址
#<dict_keyiterator object at 0x0000000002927228>
#通过双下next方法取值
res1=info_iter.__next__()
print(res1) #得到的是字典的K值
#next一次,打印一次结果。超过部分弹出警告!
res1=info_iter.__next__()
res2=info_iter.__next__()
res3=info_iter.__next__()
res4=info_iter.__next__()
res5=info_iter.__next__()
print(res1,res2,res3,res4,res5)
#超出部分,弹出StopIteration
for循环
for循环内部的本质
1.将in后面的对象调用__iter__转换成迭代器对象
2.调用__next__迭代取值
3.内部有异常捕获StopIteration,当__next__报这个错 自动结束循环
for循环其实就是循环打印next方法。for循环不许考虑是否取值超出范围。
for循环内部就是加入的while部分的代码:遇到警告就结束循环
info={‘wuxi’:‘name’} iter_info=info.__iter__()#转成迭代器 while True: try: print(info_iter.__next__())#迭代器才可以执行next方法 except StopIteration: break
知识点:
迭代器对象无论执行多少次__iter__方法,还是其本身(******)
print(f1 is f1.__iter__().__iter__().__iter__().__iter__())
#结果为True
4.文件对象
文件对象既是可迭代对象也是迭代器对象。因为既具有双下iter方法,也具有双下next方法
f1 = open('xxx.txt','r',encoding='utf-8') iter_f = f1.__iter__() #调用f1内置的__iter__方法 print(iter_f is f1) #检测内存地址,结果是相同的
迭代器方法读文件:
f1 = open('xxx.txt','r',encoding='utf-8') # 调用f1内置的__iter__方法 # iter_f = f1.__iter__()
print(iter(f1).__next__(),end='')
print(iter(f1).__next__(),end='')
print(iter(f1).__next__(),end='')
print(iter(f1).__next__(),end='')
#结果是next一次,读一行
#111111111
#22222222
#33333333
#4444444
问:__iter__方法就是用来帮我们生成迭代器对象
而文件对象本身就是迭代器对象,为什么还内置有__iter__方法???
为了可以for循环迭代器。
for循环的三个步骤:1.将in后面的容器执行iter,再结合和控制报错的功能执行next。
如果迭代器无iter方法,那就报错了。
最后补充:迭代器执行iter,得到的还是本身
调用方法的书写形式:
s='hello' print(len(s))
我发现。s.后面也有len方法。因此,可以这么写:
len(s)替换为.__len__()
s='hello' print(s.__len__())
len(s)与s.__len__()是一样的
因此:
迭代器的调用可以这么写
s='hello world' #调用: iter(s).__next__()
总结迭代器的优缺点:
优点:
1、提供了一种通用的、可以不依赖索引的迭代取值方式
2、迭代器对象更加节省内存
缺点:
1.迭代器的取值不如按照索引灵活,同一个值只能取一次,只能从前往后一次取值
2.取完会报错:stopiteration
二、生成器
生成器就用用户自己定义的迭代器。在python中,内部有yeild方法的函数被称为生成器。跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。调用一个生成器函数,返回的是一个迭代器对象。
def func(): print('first') yield 666 # 函数内如果有yield关键字,那么加括号执行函数的时候并不会触发函数体代码的运行 print('second') yield 777 print('third') yield 888 print('forth') yield yield

生成器,本质就是迭代器,因此他的调用方式不是函数名加括号。直接打印函数名则为函数名的内存地址
用生成器函数写range的原理
def my_range(start,stop,step): while start<stop: yield start start += step res=my_range(2,12,3) print(res.__next__()) print(res.__next__()) print(res.__next__())
生成器表达式
从形式上来看,生成器表达式和列表推导式很像,仅仅是将列表推导式中的[]替换为(),但是两者差别挺大,生成器表达式可以说组合了迭代功能和列表解析功能。
生成器表达式可以认为是一种特殊的生成器函数,类似于lambda表达式和普通函数。但是和生成器一样,生成器表达式也是返回生成器generator对象,一次只返回一个值。
列表推导式的写法是
# 列表推导式的写法是: squares_list=[i*i for i in range(5)] # 一次性返回整个list print(squares_list) [0, 1, 4, 9, 16]
生成器表达式
# 生成器表达式: squares2=(i*i for i in range(5)) # 生成器表达式一次返回一个值 print('生成器表达式:',squares2) # 生成器表达式: <generator object .. print(next(squares2)) # 0这种写法等于squares2.__next__() print(next(squares2)) # 1 print(next(squares2)) # 4
现在这个需要一个一个print。用for循环可以自动打印,也不占内存
squares2=(i*i for i in range(5)) # 生成器表达式就是一个generator对象 for i in squares2: print('i: ',i)
并且可以简写:
[print('i: ',i) for i in (i*i for i in range(5))]
三、python常用内置方法:
print(abs(-1))
print(all([1,'a',True])) # 列表中所有元素的布尔值为真,最终结果才为真
print(all('')) # 传给all的可迭代对象如果为空,最终结果为真
print(any([0,'',None,False])) #列表中所有元素的布尔值只要有一个为真,最终结果就为真
print(any([])) # 传给any的可迭代对象如果为空,最终结果为假
print(bin(11)) #十进制转二进制
print(oct(11)) #十进制转八进制
print(hex(11)) #十进制转十六进制
print(bool(0)) #0,None,空的布尔值为假
res='你好egon'.encode('utf-8') # unicode按照utf-8进行编码,得到的结果为bytes类型
res=bytes('你好egon',encoding='utf-8') # 同上
print(res)
def func():
pass
print(callable('aaaa'.strip)) #判断某个对象是否是可以调用的,可调用指的是可以加括号执行某个功能
print(chr(90)) #按照ascii码表将十进制数字转成字符
print(ord('Z')) #按照ascii码表将字符转成十进制数字
print(dir('abc')) # 查看某个对象下可以用通过点调用到哪些方法
print(divmod(1311,25)) # 1311 25
将字符内的表达式拿出运行一下,并拿到该表达式的执行结果
res=eval('2*3')
res=eval('[1,2,3,4]')
res=eval('{"name":"egon","age":18}')
print(res,type(res))
with open('db.txt','r',encoding='utf-8') as f:
s=f.read()
dic=eval(s)
print(dic,type(dic))
print(dic['egon'])
s={1,2,3}
s.add(4)
print(s)
不可变集合
fset=frozenset({1,2,3})
x=111111111111111111111111111111111111111111111111111111111111111111111111111111111111
# print(globals()) # 查看全局作用域中的名字与值的绑定关系
# print(dir(globals()['__builtins__']))
def func():
x=1
print(locals())
# func()
print(globals())
字典的key必须是不可变类型
dic={[1,2,3]:'a'}
不可hash的类型list,dict,set== 可变的类型
可hash的类型int,float,str,tuple == 不可变的类型
hash()
def func():
"""
帮助信息
:return:
"""
pass
# print(help(max))
len({'x':1,'y':2}) #{'x':1,'y':2}.__len__()
obj=iter('egon') #'egon'.__iter__()
print(next(obj)) #obj.__next__()
面向对象里讲
classmethod
staticmethod
property
delattr
hasattr
getattr
setattr
exec
isinstance
issubclass