GIL全局解释器锁
全局解释器的官方解释
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe.
ps:python解释器有很多种 最常见的就是Cpython解释器
GIL的存在是因为CPython解释器的内存管理不是线程安全的
垃圾回收机制
1.引用计数
2.标记清除
3.分代回收
引用计数:值和变量绑定关系的个数
标记清除:内存快满的时候,扫描内存,没有绑定变量的值会被清除掉
分代回收:频繁扫描是无意义的,因此采取措施降低扫描频率。垃圾回收是会消耗资源的,而程序运行内部会用到变量与值,并且部分是于常量,要减少垃圾回收消耗的时间
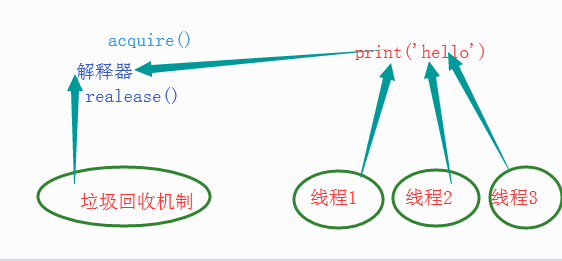
GIL本质也是一把互斥锁:将并发变成串行牺牲效率保证数据的安全
用来阻止同一个进程下的多个线程的同时执行(同一个进程内多个线程无法实现并行但是可以实现并发)
python的多线程没法利用多核优势 是不是就是没有用了?
研究python的多线程是否有用需要分情况讨论
四个任务 计算密集型的
分析:计算密集,无阻塞态,一个线程走完另一个线程启动,因此开4个线程需要40秒
开4个进程,那就是并行,因此只需要10秒
单核情况下
开线程更省资源
多核情况下
开进程 10s
开线程 40s
计算密集型,多核开进程最快
from multiprocessing import Process
from threading import Thread
import os, time
def work():
res = 0
for i in range(10000000):
res *= i
if __name__ == '__main__':
l = []
# print(os.cpu_count()) # 本机为6核
start = time.time()
for i in range(6):
p=Process(target=work) # 耗时 2.8391623497009277
# p = Thread(target=work) # 耗时 4.586262226104736
l.append(p)
p.start()
for p in l:
p.join()
stop = time.time()
print('run time is %s' % (stop - start))
四个任务 IO密集型的
分析:阻塞态,开哪个都可以,都是等待,开进程开销还更大,因此开线程
单核情况下
开线程更节省资源
多核情况下
开线程更节省资源
# IO密集型开线程更节省资源
from multiprocessing import Process
from threading import Thread
import threading
import os,time
def work():
time.sleep(2)
if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本机为6核
start=time.time()
for i in range(4000):
p=Process(target=work) #耗时9.001083612442017s多,大部分时间耗费在创建进程上
# p=Thread(target=work) #耗时2.051966667175293s多
l.append(p)
p.start()
for p in l:
p.join()#join的作用:让列表中的线程不要接着往下走!
stop=time.time()
print('run time is %s' %(stop-start))
join的作用:让进程等待结束再进行下一个进程(后来总结:让列表中的线程不要接着往下走!)
如何实现TCP服务端实现并发?
思路:while循环开线程
#服务端
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
def talk(conn):
while True:
try:
data = conn.recv(1024)
if len(data) == 0:break
print(data.decode('utf-8'))
conn.send(data.upper())
except ConnectionResetError as e:
print(e)
break
conn.close()
while True:
conn, addr = server.accept() # 监听 等待客户端的连接 阻塞态
t = Thread(target=talk,args=(conn,))
t.start()
ps:常见问题
GIL是不是python解释器的特点?
GIL是Cpython解释器的特点,python解释器有多个语言编写的版本
GIL与普通互斥锁
from threading import Thread
import time
n = 100
def task():
global n
tmp = n
# time.sleep(1)
n = tmp -1
t_list = []
for i in range(100):
t = Thread(target=task)
t.start()
t_list.append(t)
for t in t_list:
t.join()#
print(n)
之前不明白第二个for循环join什么时候开始运行,在线程sleep的时候,原本是直接到最下面执行print,现在多了两行代码,走到join这里,发现要等待,不能跳着运行
死锁
死锁的原因是一个线程抢两把锁
from threading import Thread,Lock,current_thread,RLock
import time
mutexA = Lock()
mutexB = Lock()
class MyThread(Thread):
def run(self): # 创建线程自动触发run方法 run方法内调用func1 func2相当于也是自动触发
self.func1()
self.func2()
def func1(self):
#抢锁外,隔离
mutexA.acquire()
print('%s抢到了A锁'%self.name) # self.name等价于current_thread().name
mutexB.acquire()
print('%s抢到了B锁'%self.name)
mutexB.release()
print('%s释放了B锁'%self.name)
mutexA.release()
print('%s释放了A锁'%self.name)
def func2(self):
mutexB.acquire()
print('%s抢到了B锁'%self.name)
# time.sleep(1)
mutexA.acquire()
print('%s抢到了A锁' % self.name)
mutexA.release()
print('%s释放了A锁' % self.name)
mutexB.release()
print('%s释放了B锁' % self.name)
for i in range(10):
t = MyThread()
t.start()
现在是线程1跑到func2,抢到了B锁,准备抢A锁,而A锁在线程2的手上产生了死锁

创建线程自动触发run方法 run方法内调用func1 func2相当于也是自动触发
self.name等价于current_thread().name。线程号的意思
不要轻易动“锁”有关的事!
解决方法:Rlock递归锁
所有取名递归,就是它可以有一个计数的功能,数值可加可减
将锁替换为Rlock()即可
from threading import Thread,Lock,current_thread,RLock
import time
from threading import Thread,Lock,current_thread,RLock
import time
"""
Rlock可以被第一个抢到锁的人连续的acquire和release
每acquire一次锁身上的计数加1
每release一次锁身上的计数减1
只要锁的计数不为0 其他人都不能抢
"""
# mutexA = Lock()
# mutexB = Lock()
mutexA = mutexB = RLock() # A B现在是同一把锁
class MyThread(Thread):
def run(self): # 创建线程自动触发run方法 run方法内调用func1 func2相当于也是自动触发
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print('%s抢到了A锁'%self.name) # self.name等价于current_thread().name
mutexB.acquire()
print('%s抢到了B锁'%self.name)
mutexB.release()
print('%s释放了B锁'%self.name)
mutexA.release()
print('%s释放了A锁'%self.name)
def func2(self):
mutexB.acquire()
print('%s抢到了B锁'%self.name)
time.sleep(1)
mutexA.acquire()
print('%s抢到了A锁' % self.name)
mutexA.release()
print('%s释放了A锁' % self.name)
mutexB.release()
print('%s释放了B锁' % self.name)
for i in range(10):
t = MyThread()
t.start()
信号量
与互斥锁类似
互斥锁,就是多个线程抢一个坑位
信号量,就是多个线程抢多个坑位
互斥锁:一个厕所(一个坑位)
信号量:公共厕所(多个坑)
导入模块from threading import Semaphore,Thread
from threading import Semaphore,Thread
import time
import random
sm = Semaphore(5) # 造了一个含有五个的坑位的公共厕所
#以下位置进行加锁
def task(name):
sm.acquire()#加锁位置
print('%s占了一个坑位'%name)
time.sleep(random.randint(1,3))
sm.release()#放锁位置
print('%s走了'%name)
for i in range(40):
t = Thread(target = task ,args =(i,))
t.start()
结果:
0占了一个坑位
1占了一个坑位
2占了一个坑位
3占了一个坑位
4占了一个坑位
4走了
0走了
1走了
3走了
2走了
event事件
之前的join方法是让主进程等待子进程
案例演示:等红绿灯
操作步骤:
1先生成一个event对象
2发信号e.set()
3.等待信号e.wait()
from threading import Event,Thread
import time
# 先生成一个event对象
e = Event()
def light():
print('红灯正亮着')
time.sleep(1)
e.set() # 发信号
print('绿灯亮了')
def car(name):
print('%s正在等红灯'%name)
e.wait() # 等待信号
print('%s加油门飙车了'%name)
t = Thread(target=light)
t.start()
for i in range(10):
t = Thread(target=car,args=('伞兵%s'%i,))
t.start()
线程q
同一个进程下的多个线程本来就是数据共享 为什么还要用队列
因为队列是管道+锁 使用队列你就不需要自己手动操作锁的问题
因为锁操作的不好极容易产生死锁现象
q = queue.Queue()
q.put('hahha')
print(q.get())
q = queue.LifoQueue()
q.put(1)
q.put(2)
q.put(3)
print(q.get())
q = queue.PriorityQueue()
# 数字越小 优先级越高
q.put((10,'haha'))
q.put((100,'hehehe'))
q.put((0,'xxxx'))
q.put((-10,'yyyy'))
print(q.get())