1 解析json
# 方法一
import requests
response=requests.get('http://httpbin.org/get')
import json
res1=json.loads(response.text) #太麻烦
# 方法一
res2=response.json() #直接获取json数据
2 SSL
# https的网站更安全。https的网站要校验证书
https=http+ssl
import requests
respone=requests.get('https://www.12306.cn',
cert=('/path/server.crt',
'/path/key'))
#cert相当于 证书
3使用代理
# 使用代理
#ip 代理收费(通过代理访问自己的服务,在服务端取出客户端ip查看一下)
import requests
proxies={
# 'http':'http://aaa:123@localhost:9743',#带用户名密码的代理,@符号前是用户名与密码
# 'http':'http://localhost:9743',
# 'https':'https://localhost:9743',
'http':'http://124.205.155.148:9090'
}
respone=requests.get('http://127.0.0.1:8000/',
proxies=proxies)
#
print(respone.status_code)
4 认证设置
路由器的弹窗,很少使用了
5 异常处理
继承requests的异常;也可以自己指定except异常
#异常处理
import requests
from requests.exceptions import * #可以查看requests.exceptions获取异常类型
try:
r=requests.get('http://www.baidu.com',timeout=0.00001)
except ReadTimeout:
print('===:')
# except ConnectionError: #网络不通
# print('-----')
# except Timeout:
# print('aaaaa')
except RequestException:
print('Error')
上传文件
#上传文件
import requests
files={'file':open('a.jpg','rb')}
respone=requests.post('http://httpbin.org/post',files=files)
print(respone.status_code)
解析库beautifulsoup
find:
-name="标签名" 标签
-id,class_,="" 把这个标签拿出来
-标签.text 取标签的内容
-标签.get(属性名) 取标签属性的内容
find_all
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库 ,通过转换器实现查找,修改文档的方式
以前是用re解析requests获取到的html文档,使用 Beautiful Soup 可以加快解析效率
查找:find和findall()
查找标签:name= name=div.find(name='ul') #只找第一个ul标签
查找类名:class_= div.find_all(class_="article") #找出下面所有类名为article的标签
id=
取内容:点 h3.text #把h3标签的内容取出来,用h3.text
取属性get article_url=a.get('href') #取出a标签的href属性
import requests
from bs4 import BeautifulSoup
url='https://www.autohome.com.cn/news/1/#liststart'
res=requests.get(url)
# print(res.text)
soup=BeautifulSoup(res.text,'lxml')
div=soup.find(id='auto-channel-lazyload-article')
ul = div.find(name = 'ul')
# print(ul)
li_list = ul.find_all(name='li')
for li in li_list:
p= li.find(name='p')# 这与下面的h3都是有两个嵌套的,却可以直接查找
if p:
print(p.text)# 注意:p是段落标签,直接查找p,结果会带被p夹裹着。因此要。text取出内容
h3 = li.find(name='h3')# h3是嵌套在a标签内部的!,而a标签是在li内部的,却可以直接查找
if h3:
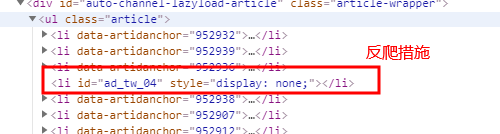
print(h3.text)# 注意网页内的反扒措施,使得你的程序出错!
a = li.find(name='a')
if a:
print(a.get('href'))
img =li.find(name='img')# 注意这个img是在a标签内部,不可以跨越两个标签进行查找!,可以跨越一个
if img:
print(img.get('src'))
美化:
soup=BeautifulSoup(html_doc,'lxml')
ress=soup.prettify() #美化一下
遍历文档树
#1、用法
from b34 import Beauti fulSoup
s0up=BeautifulSoup (html doc, '1xml')
# Boup=BeautifulSoup(open('a.html'),'1xm1')
#遍历文档树.# 则这种速度比find速度要快
print (soup.p)存在多个相同的标签则只返回第一个
print (soup.a) #存在多个相同的标签则只返回第一个
#2、获取标签的名称
print (soup. p. name)# 从上往下,获取一个;获取的是标签的名字
#3、获取标签的属性
print (soup.p.attrs)#{'class': ['title'], 'id': 'bbaa'}
# print(soup.p)# 获取标签的全部内容,不渲染标签
#4.获取标签的内容
print (soup.p.atring) # p下的文本只有一一个时,取到,否则为None
print(soup.p.string)拿到一个生成器对象,取到p下所有的文本内容# 获取标签的全部内容,p标签不能嵌套任何东西
print (soup.p.text) #取到p 下所有的文本内容
print (soup.p)存在多个相同的标签则只返回第一个
print (soup.a) #存在多个相同的标签则只返回第一个
for line in soup.stripped_ atrings: #去掉空白
print (line)
#5、嵌套选择
print (soup.head. title.string)
print (soup .body.a.atring)
#6、子节点子孙节点
print (3oup.p. contenta) #P 下所有子节点
print (3oup.p. children) #得到一 个迭代器,包含p下所有子节点
for i, ch11d in enumerate (3oup.p. chi1dren) :
print (位,child)
print (soup .p. descendanta) #获取子孙节点,p下所有的标签都会选择出来
for i,child in enumerate (3oup.p. descendante) :
print(I, child)
#7、父节点祖先节点
print (soup.a.parent) #获取a标签的父节点
print (aoup.a.parenta) #找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲...
#8、兄弟节点
print='=====>')
print(3oup.a.next_ gaibling) #下一 一个兄弟
print (3oup.a.previou3_ gibling) #上一个兄弟
print (1i3t (3oup.a.next_ aibling3)) #下面的兄弟们=>生成器对象
print (soup.a.previous _aiblinga) #上面的兄弟们=>生成器对象
# 关于next_sibling和previous_sibling
sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>",'lxml')
print(sibling_soup.b.next_sibling)
print(sibling_soup.c.previous_sibling )
查找文档数
#五种过滤器 :字符串,正则,布尔,方法,列表
import re
# print(soup.find_all(name='b'))
# print(soup.find_all(name=re.compile('^b')))
# print(soup.find_all(id=re.compile('^b')))
# print(soup.find_all(name=['a','b']))
# print(soup.find_all(name=True))
# def has_class_but_no_id(tag):
# return tag.has_attr('class') and not tag.has_attr('id')
# print(soup.find_all(name=has_class_but_no_id))
css选择
#css选择
# xpath
# print(soup.select(".title"))
# print(soup.select("#bbaa"))
# print(soup.select('#bbaa b')[0].attrs.get('name'))
#recursive=False 只找同一层
#limit 找到第几个之后停止
sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>",'lxml')
print(sibling_soup.b.next_sibling)
print(sibling_soup.c.previous_sibling )
selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys #键盘按键操作
import time
# from selenium.webdriver.chrome.options import Options
# chrome_options = Options()
# chrome_options.add_argument('window-size=1920x3000') #指定浏览器分辨率
# chrome_options.add_argument('--disable-gpu') #谷歌文档提到需要加上这个属性来规避bug
# chrome_options.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面
# chrome_options.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 提升速度
# chrome_options.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
# chrome_options.binary_location = r"C:Program Files (x86)GoogleChromeApplicationchrome.exe" #手动指定使
# bro=webdriver.PhantomJS()
# bro=webdriver.Chrome(chrome_options=chrome_options)
bro=webdriver.Chrome()
bro.get('https://www.baidu.com')
# print(bro.page_source)
# time.sleep(3)
time.sleep(1)
#取到输入框
inp=bro.find_element_by_id('kw')
#往框里写字
inp.send_keys("美女")
inp.send_keys(Keys.ENTER) #输入回车
#另一种方式,取出按钮,点击su
time.sleep(3)
bro.close()