4.1 数组应用一:日期计算的实验范例
4.1.1 Calendar
4.1.2 What Day Is It?
4.2 数组应用二:高精度运算的实验范例
4.2.1 Adding Reversed Numbers
4.2.2 VERY EASY !!!
4.3 数组应用三:多项式表示与处理的实验范例
4.3.1 Polynomial Showdown
4.3.2 Modular multiplication of Polynomial
4.4 数组应用四:数值矩阵运算的实验范例
4.4.1 Error Correction
4.4.2 Matrix Chain Multiplication
4.5 字符串处理一:串的存储结构的实验范例
4.5.1 TEX Quotes
4.6 字符串处理二:串模式匹配的实验范例
模式匹配(pattern matching)
Brute和Force提出的朴素的模式匹配算法,也称Brute Force算法;
蛮力算法,只需将P与T中长度为m的n-m+1个子串逐一比对,即可确定可能的匹配位置。
/****************************************************************** * Text : 0 1 2 . . . i-j. . . . i . . n-1 * ----------------|----------|-------- * Pattern : 0 . . . . .j . . * |----------| * *******************************************************************/ #include <cstring> int match(char* P, char* T) {//串匹配算法(Brute-force-1) size_t n = strlen(T), i = 0;//主串长度、当前接受比对字符的位置 size_t m = strlen(P), j = 0;//模式串长度、当前接受比对字符的位置 while (j<m&&i<n) {//自左向右逐个比对字符 if(T[i]==P[j])//若匹配 { i++;j++;//则转到下一对字符 } else {//否则 i -= j - 1;j = 0; }//主串回退、模式串复位 } return i - j;//如何通过返回值,判断匹配结果? } /*=================================================================*/ /*代码11.1 蛮力串匹配算法(版本一)*/
如代码11.1所示的版本借助整数i和j,分别指示T和P中当前接受比对的字符T[i]与P[j]。若当前字符对匹配,则i和j同时递增以指向下一对字符。一旦j增长到m则意味着发现了匹配,即可返回P相对于T的对齐位置i-j。一旦当前字符对失配,则i回退并指向T中当前对齐位置的下一个字符,同时j复位至P的首字符处,然后开始下一轮比对。
/******************************************************** * Text :0 1 2 . . . i i+1. . . i+j . . n-1 * ------------|----------|-------- * Pattern : 0 1 . . . j . . * |----------| *********************************************************/ #include<cstring> int match(char* P, char* T) {//串匹配算法(Brute-force-2) size_t n = strlen(T), i = 0;//主串长度、与模式串首字符的对齐位置 size_t m = strlen(P), j;//模式串长度、当前接受比对字符的位置 for (i = 0;i < n-m+1;i++) {//主串从第i个字符起,与 for (j = 0;j < m;j++) //模式串中对应的字符逐个比对 if (T[i + j] != P[j])break;//若失配,模式串整体右移一个字符,再做一轮比对 if (j>=m)break;//找到匹配子串 } return i;//如何通过返回值,判断匹配结果? } /*=================================================================================*/ /*代码11.2 蛮力串匹配算法(版本二)*/
如代码11.2所示的版本,借助整数i指示P相对于T的对齐位置,且随着i不断递增,对齐的位置逐步右移。在每一对齐位置i处,另一整数j从0递增至m-1,依次指示当前接受比对的字符为T[i+j]与P[j]。因此,一旦发现匹配,即可直接返回当前的对齐位置i。
11.2.3 时间复杂度
从理论上讲,蛮力算法至多迭代n-m+1轮,且各轮至多需进行m次比对,故总共只需做不超过(n-m+1)*m次比对。这种最坏的情况的确/是肯定会发生的。
考查如图11.2所示的实例。无论采用上述哪个版本的蛮力算法,都需做n-m+1轮迭代,且各轮都需做m次比对。因此,整个算法共需做m*(n-m-1)次字符比对,其中成功的和失败的各有(m-1)*(n-m-1)+1和n-m-2次。因m<<n,渐进的时间复杂度应为o(n*m)。

当然,蛮力算法的效率也并非总是如此低下。如图11.3所示,若将模式串P左右颠倒,则每经一次比对都可排除主串中的一个字符,故此类情况下的运行时间将为o(n)。实际上,此类最好(或接近最好)情况出现的概率并不很低,尤其是在字符表较大时(习题[11-9])。

教材 309 页代码 11.1、310 页代码 11.2 所实现的两个蛮力算法,在通常情况下的效率并不算低。
4.6.1 Blue Jeans
由于碱基序列的串长仅为60,因此计算子串匹配时采用了Brute Force算法。另外使用了一些字符串库函数,例如字串长度函数strlen(),比较字串大小的函数strcmp(),字串复制函数strcpy(),使得程序更加清晰和简练。
KMP算法
KMP算法的思路可概括为:当前比对一旦失配,即利用此前的比对(无论成功或失败)所提供的信息,尽可能长距离地移动模式串。其精妙之处在于,无需显式地反复保存或更新比对的历史,而是独立于具体的主串,事先根据模式串预测出所有可能出现的失配情况,并将这些信息“浓缩”为一张next表。
蛮力算法在最坏情况下所需时间,为主串长度与模式串长度的乘积(o(n*m)),故无法应用于规模稍大的应用环境,很有必要改进。为此,不妨从分析以上最坏情况入手。
稍加观察不难发现,问题在于这里存在大量的局部匹配:每一轮的m次比对中,仅最后一次可能失配。而一旦发现失配,主串、模式串的字符指针都要回退,并从头开始下一轮尝试。 实际上,这类重复的字符比对操作没有必要。既然这些字符在前一轮迭代中已经接受过比对并且成功,我们也就掌握了它们的所有信息。那么,如何利用这些信息,提高匹配算法的效率呢?
以下以蛮力算法的前一版本(代码11.1)为基础进行改进。
简单示例
如图11.4所示,用T[i]和P[j]分别表示当前正在接受比对的一对字符。

当本轮比对进行到最后一对字符并发现失配后,蛮力算法会令两个字符指针同步回退( 即令 i = i - j + 1和j = 0(代码是i-=j-1;)),然后再从这一位置继续比对。然而事实上,指针i完全不必回退。
记忆 = 经验 = 预知力
经过前一轮比对,我们已经清楚地知道,子串substr(T, i - j, j)完全由'0'组成。记住这一性质便可预测出:在回退之后紧接着的下一轮比对中,前j - 1次比对必然都会成功。因此,尽可令i保持不变、j = j - 1,然后继续比对。如此,将使下一轮的比对减少j - 1次!
上述“令i保持不变、j = j - 1”的含义,可理解为“令P相对于T右移一个单元,然后从前一失配位置继续比对”。实际上这一技巧可推而广之:利用以往的成功比对所提供的信息(记忆),不仅可避免主串字符指针的回退,而且可使模式串尽可能大跨度地右移(经验)。
一般实例
如图11.5所示,再来考查一个更具一般性的实例。
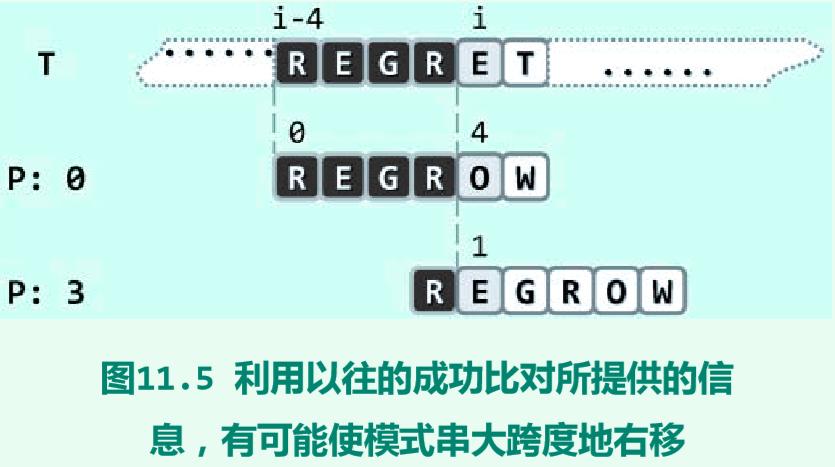
本轮比对进行到发现'E' = T[i] ≠ P[4] = 'O'失配后,在保持i不变的同时,应将模式串P右移几个单元呢?有必要逐个单元地右移吗?不难看出,在这一情况下移动一个或两个单元都是徒劳的。事实上,根据此前的比对结果,必然有
suffix(prefix(T, i), 4) = substr(T, i - 4, 4) = prefix(P, 4) = "REGR"
若在此局部能够实现匹配,则至少紧邻于T[i]左侧的若干字符均应得到匹配————比如,当 P[0]与T[i - 1]对齐时,即属这种情况。注意到i - 1是能够如此匹配的最左侧位置,故可放心地将P右移4 - 1 = 3个单元(等效于i保持不变,同时令j = 1),然后继续比对。
11.3.2 next表

就是说,在prefix(P, j)中长度为t的真前缀应该与长度为t的真后缀完全匹配。更准确地,值得试探的t必然来自集合:
N(P, j) =
{ t | prefix(prefix(P, j), t) = suffix(prefix(P, j), t), 0 ≤t < j}
需特别注意的是,集合N(P, j)具体由哪些t值构成,仅取决于模式串P以及前一轮迭代的失配位置j,而与主串T无关!
从图11.6还可看出,若下一轮迭代从T[i]与P[t]的比对开始,其效果相当于将模式串P右移j - t个单元。因此,为保证模式串与主串的对齐位置(指针i)绝不倒退,同时又不致遗漏任何可能的匹配,必须在集合N(P, j)中挑选最大的t。也就是说,当有多个值得试探的右移方案时,应该保守地选择其中移动距离最短者。于是,只需令
next[j] = max(N(P, j))
则一旦发现P[j]与T[i]失配,就可以转而用P[next[j]]与T[i]继续比对。
既然集合N(P, j)仅取决于模式串P以及失配位置j,而与主串无关,作为该集合内的最大者, next[j]也同样具有这一性质。于是,对于任一模式串P,不妨通过预处理提前计算出所有位置j所对应的next[j]值,并整理为表格以便此后反复查询————亦即,将“记忆力”转化为“预知力”。
11.3.3 KMP算法
上述思路可整理为代码11.3,即著名的KMP算法②。
这里,假定可通过buildNext()构造出模式串P的next表。对照代码11.1的蛮力算法,只是 在else分支对失配情况的处理手法有所不同,这也是KMP算法的精髓所在。
#include <cstring> int match(char* P, char* T) {//KMP算法 int* next = buildNext(P);//构造next表 int n = (int)strlen(T), i = 0;//主串指针 int m = (int)strlen(P), j = 0;//模式串指针 //size_t n = strlen(T), i = 0;//主串指针 //size_t m = strlen(P), j = 0;//模式串指针 while ((j < m) && (i<n)) {//自左向右逐个比对字符 if (j<0||T[i] == P[j]) {//若匹配,或P已移出最左侧(两个判断的次序不可交换) i++; j++; }//则转到下一字符 else {//否则 j = next[j];//模式串右移(注意:主串不用回退) } } delete[]next;//释放next表 return i - j; } /*===========================================*/ /*代码11.3 KMP主算法*/
11.3.4 next[0] = -1
空串是任何非空串的真子串、真前缀和真后缀,故只要j > 0则必有0∈N(P, j)。此时的 N(P, j)必非空,从而保证“在其中取最大值”这一操作的确可行。但反过来,若j = 0,则前缀prefix(P, j)本身就是空串,它没有真子串,于是必有集合N(P, j) = Ø。
此种情况下,又该如何定义next[0]呢?按照串匹配算法的构思,若某轮迭代中首对字符即失配,则应将模式串P直接右移一个字符,然后从其首字符起继续下一轮比对。

如表11.3所示,不妨假想地在P[0]的左侧“附加”一个P[-1],而且该字符与任何字符都是匹配的。于是就实际效果而言,上述处理方法完全等同于“令next[0] = -1”。
11.3.5 next[j + 1]
那么,若已知next[0, j],如何才能递推地计算出next[j + 1]?是否有高效方法?

若next[j] = t,则意味着在前缀prefix(P, j)中,自匹配的真前缀和真后缀的最大长度为t,故必有next[j + 1]≤next[j] + 1——而且特别地,当且仅当P[j] = P[t]时如图11.7 取等号。那么一般地,若P[j]≠P[t],又该如何得到next[j + 1]?
此种情况下如图11.8,由next表的定义,next[j + 1]的下一候选者应该依次是
next[ next[j] ] + 1, next[ next[ next[j] ] ] + 1, ...

因此,只需反复用next[t]替换t(即令t = next[t]),即可按优先次序遍历以上候选者; 一旦发现P[j]与P[t]匹配(含通配),即可将next[t] + 1赋予next[j + 1]。
既然总有next[t] < t,故在此过程中t必然严格递减;同时,即便t降低至0,亦必然会终止于通配的next[0] = -1,而不致下溢。如此,该算法的正确性完全可以保证。
11.3.6 构造next表
按照以上思路,可实现next表构造算法如代码11.4所示。
#include <cstring> int* buildNext(char* P) {//构造模式串P的next表 size_t m = strlen(P),j=0;//"主"串指针 int* N = new int[m];//next表 int t = N[0] = -1;//模式串指针 while(j<m-1){ if (0 > t||P[j]==P[t]) {//匹配 t++; j++; N[j] = t;//此句可改进... } else {//失配 t = N[t]; }
} return N; } /*=============================================*/ /*代码11.4 next表的构造*/
可见,next表的构造算法与KMP算法几乎完全一致。实际上按照以上分析,这一构造过程完全等效于模式串的自我匹配,因此两个算法在形式上的近似亦不足为怪。
11.3.7 性能分析
O(nm)?
通过上述分析与实例可以看出,相对于蛮力算法,KMP算法(代码11.3)借助next表可避免大量不必要的字符比对操作。然而就渐进意义而言,时间复杂度会有实质性的改进吗?这一点并非一目了然,甚至乍看起来并不乐观。比如,从算法流程的角度来看,该算法依然需做O(n)轮迭代,而且任何一轮迭代都有可能需要比对多达Ω(m)对字符。
如此说来,在最坏情况下,KMP算法仍有可能共需执行O(nm)次比对?不是的。正如以下更为精确的分析将要表明的,即便在最坏情况下,KMP算法也只需运行线性的时间!
O(n)!
为此,请注意代码11.3中用作字符指针的变量i和j。若令k = 2i - j并考查k在KMP算法过程中的变化趋势,则不难发现:while循环每迭代一轮,k都会严格递增。
为验证这一点,只需分别核对while循环内部的if-else分支。无非两种情况:若执行if分支,则i和j同时加一,于是k = 2i - j必将增加;反之若执行else分支,则尽管i保持不变, 但在赋值j = next[j]之后j必然减小,于是k = 2i - j也必然会增加。
现在,纵观算法的整个过程:启动时有i = j = 0,即k = 0;算法结束时i≤n且j≥0, 故有k≤2n。也就是说,在此期间尽管k从0开始持续地严格单调递增,但总体增幅不超过2n。 既然k为整数,故while循环至多执行2n轮。另外,while循环体内部不含任何循环或调用,故只需O(1)时间。因此,若不计构造next表所需的时间,KMP算法的运行时间不超过O(n)——这一结论也可等效地理解为,KMP算法单步迭代的分摊复杂度仅为O(1)。
总体复杂度
既然next表构造算法的流程与KMP算法并无实质区别,故仿照上述分析可知,next表的构造仅需O(m)时间。综上可知,KMP算法的总体运行时间为O(n + m)。
11.3.8 继续改进
尽管以上KMP算法已可保证线性的运行时间,但在某些情况下仍有进一步改进的余地。
反例
考查模式串P = "000010"。按照11.3.2节的定义,其next表应如表11.4所示。 在KMP算法过程中,假设如图11.9前一轮比对因T[i] = '1' ≠'0' = P[3] 失配而中断。于是按照以上的next表,接下来KMP算法将依次将P[2]、P[1]和P[0] 与T[i]对准并做比对。


从图11.9可见,这三次比对都报告“失配”。 那么,这三次比对的失败结果属于偶然吗?进一步地,这些比对能否避免?
实际上,即便说P[3]与T[i]的比对还算必要, 后续的这三次比对却都是不必要的。实际上,它们的失败结果早已注定。
只需注意到P[3] = P[2] = P[1] = P[0] = '0',就不难看出这一点————既然经过此前的比对已发现T[i]≠P[3],那么继续将T[i]和那些与P[3]相同的字符做比对,既重蹈覆辙,更徒劳无益。
记忆 = 教训 = 预知力
从算法策略的层次来看,11.3.2节引入next表的实质作用,在于帮助我们利用以往成功比对所提供的经验,将记忆力转化为预知力。然而实际上,此前已进行过的比对,还远不止这些。 确切地说,还包括那些失败的比对————作为“教训”,它们同样有益,但可惜此前一直被忽略了。
依然以图11.9为例,以往的失败比对,实际上已经为我们提供了一条极为重要的信息 ————T[i] ≠P[4]————可惜我们却未能有效地加以利用。原算法之所以会执行后续四次本不必要的比对,原因也正在于未能充分汲取教训。
改进
为把这类“负面”信息引入next表,只需将11.3.2节中集合N(P, j)的定义修改为:
N(P, j) = { t | prefix(prefix(P, j), t) = suffix(prefix(P, j), t)
且 P[j]≠P[t], 0≤t< j}
也就是说,除“对应于自匹配长度”以外,t只有还同时满足“当前字符对不匹配”的必要条件,方能归入集合N(P, j)并作为next表项的候选。
相应地,原next表构造算法(代码11.4)也需稍作修改,调整为如下改进版本。
#include <cstring> int* buildNext(char* P) { //构造模式串P的next表(改进版本) size_t m = strlen(P), j = 0; // "主"串指针 int* N = new int[m]; //next表 int t = N[0] = -1;//模式串指针 while(j<m-1) if (t<0||P[j]==P[t]) { //匹配 //t++; j++; t++; N[j] = (P[j]!=P[t])?t:N[t]; //注意此句与未改进之前的区别 } else //失配 t = N[t]; return N; } /********************************************************/ /****代码11.5 改进的next表构造算法****/
由代码11.5可见,改进后的算法与原算法的唯一区别在于,每次在prefix(P, j)中发现长度为t的真前缀和真后缀相互匹配之后,还需进一步检查P[j]是否等于P[t]。唯有在P[j]≠P[t] 时,才能将t赋予next[j];否则,需转而代之以next[t]。
仿照11.3.7节的分析方法易知,改进后next表的构造算法同样只需O(m)时间。
实例
仍以P = "000010"为例,改进之后的next表如表11.5所示。读者可参照图11.9,就计算效率将新版本与原版本(表11.4)做一对比。 
利用新的next表针对图11.9中实例重新执行KMP算法,在首轮比对因T[i] = '1' ≠'0' = P[3]失配而中断之后,将随即以P[ next[3] ] = P[-1](虚拟通配符)与T[i]对齐,并启动下一轮比对。将其效果而言,等同于聪明且安全地跳过了三个不必要的对齐位置。
4.6.2 Oulipo
4.7 相关题库
4.7.1 时间日期格式转换
4.7.2 Moscow Time
4.7.3 Double Time
4.7.4 Maya Calendar
4.7.5 Time Zones
4.7.6 Polynomial Remains
4.7.7 Factoring a Polynomial
4.7.8 What's Cryptanalysis?
4.7.9 Run Length Encoding
4.7.10 Zipper
4.7.11 Anagram Groups
4.7.12 Inglish-Number Translator
4.7.13 Message Decrowding
4.7.14 Common Permutation
4.7.15 Human Gene Functions
4.7.16 Palindrome
4.7.17 Power Strings
4.7.18 Period
4.7.19 Seek the Name,Seek the Fame
4.7.20 Excuses,Excuses!
4.7.21 Product
4.7.22 Expression Evaluator
4.7.23 Integer Inquiry
4.7.24 Super long sums
4.7.25 Exponentiation
4.7.26 NUMBER BASE CONVERSION
4.7.27 If We Were a Child Again
4.7.28 Simple Arithmetics
4.7.29 a^b-b^a
4.7.30 Fibonacci Number
4.7.31 How many Fibs
4.7.32 Heritage