
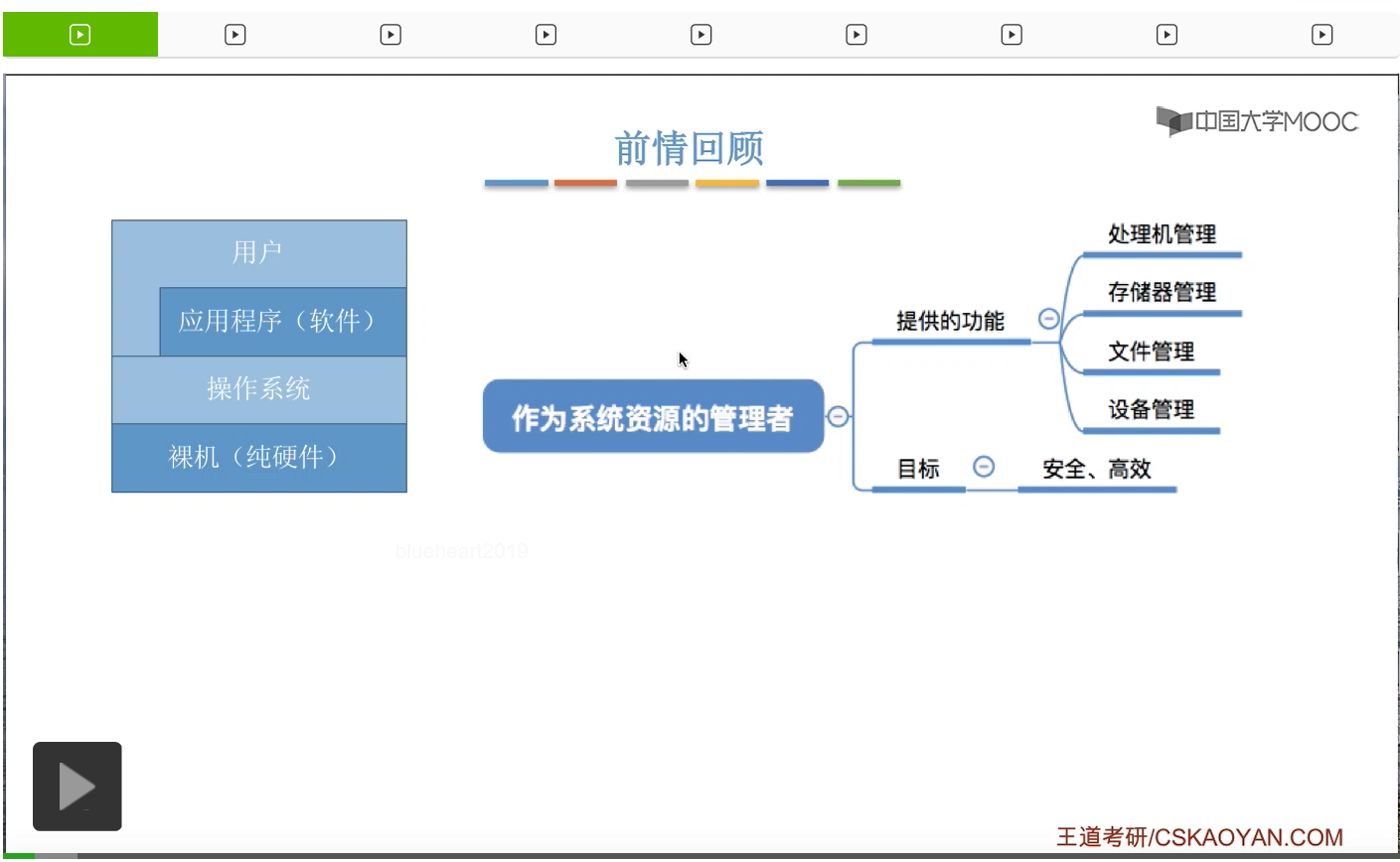
操作系统它作为系统资源的管理者,也需要对文件进行管理。文件也属于一种系统资源,它其实就是一组有意义的信息或者说数据的集合。手机照片、word文档、PPT讲义、PDF文件,这些都是各种各样的文件。但是各种各样的文件它又在我们前面呈现出了不一样的一些特性。那这些特性其实也需要操作系统来关心。所以其实不同的文件它有不同的属性,而因为源文件属性的不同,所以我们在使用文件的时候也会有各种各样的差别。第二个问题,既然文件它是一组有意义的信息或者说数据的集合,那么这些信息在内部是怎么被组织起来的,也就是文件内部的这些数据的组织形式的问题。
第四个问题,从下往上看,操作系统的上层应该是应用程序和用户,所以操作系统应该为它的上层提供简单易用的一些接口,用来方便操作各种各样的文件。那操作系统应该为上层提供哪些功能,这是我们之后还会探讨的问题。

最后一个会探讨的问题,从上往下看,操作系统的下面一层是硬件,所以操作系统也需要对硬件进行管理。而我们知道,一般来说文件是存放在我们的磁盘也就是外存当中的,而外存作为一种计算机的硬件,肯定也需要操作系统对它进行管理。那么这些文件的数据应该怎么被存放在外存上,这是我们最后一个会探讨的问题。

那我们首先来看一下一个文件应该有哪些属性。

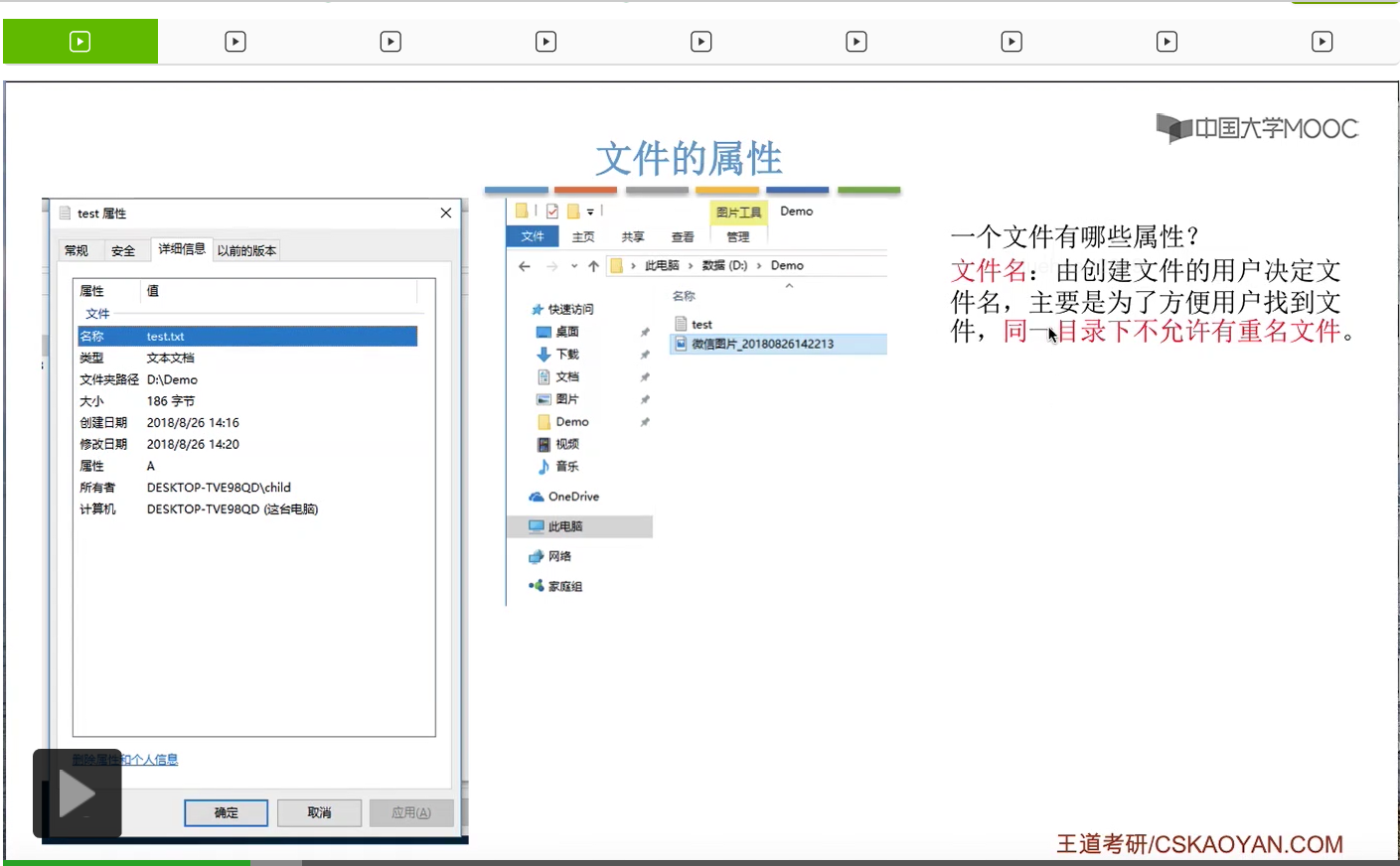
那为什么不允许有重名文件,这一点咱们会在之后的小节当中再进行进一步的解释。总之文件名对于用户来说是很重要甚至说是最重要的一个属性。因为我们都是根据文件名来找到一个文件的。

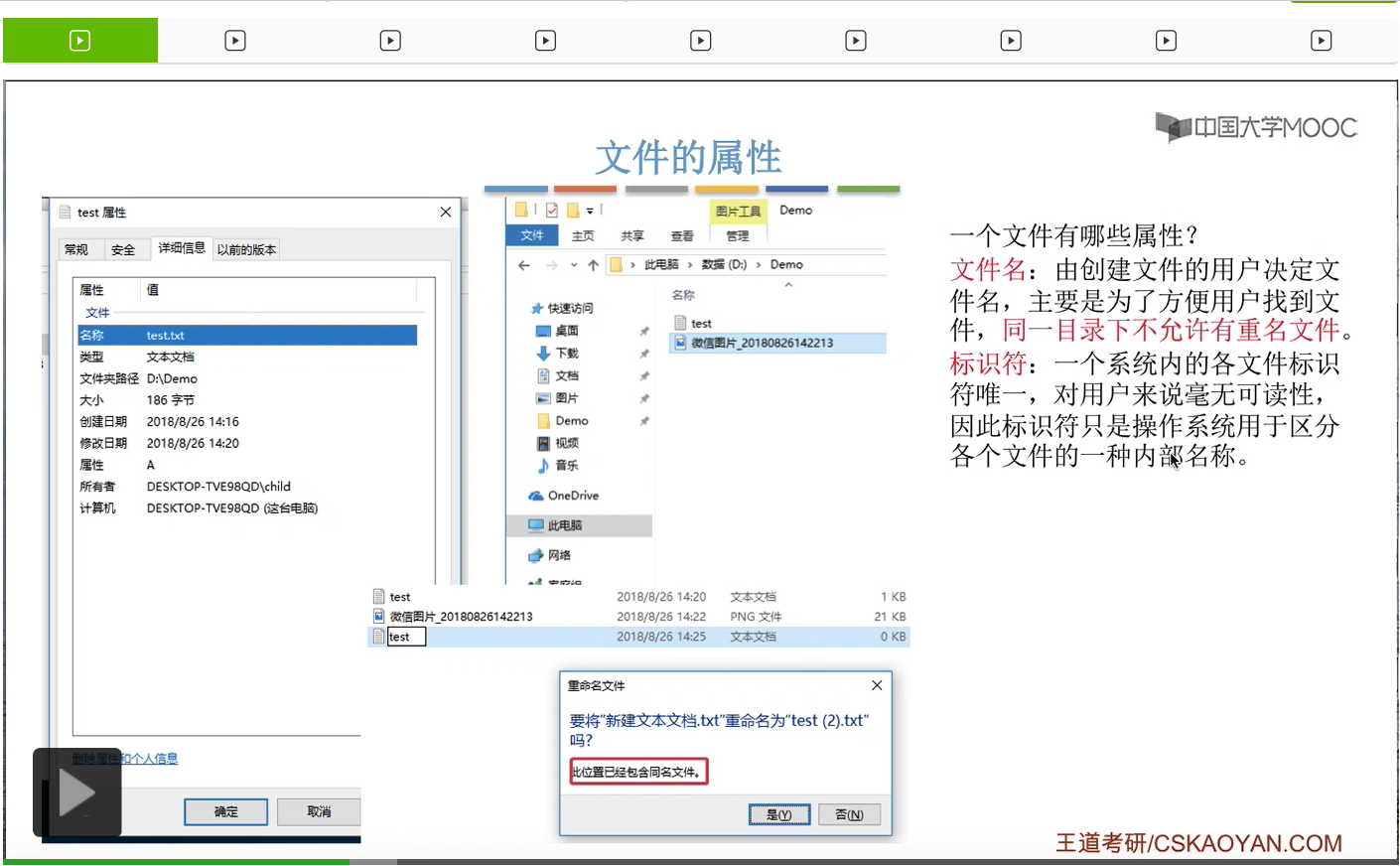
那文件的第二个重要属性是标识符。其实在一个系统当中,肯定是有很多重名文件的。虽然说在同一文件夹下不允许有重名的文件,所以其实用文件名并不能唯一地区分出每一个文件到底是哪一个。因此,操作系统会在背后为各个文件设置一个标识符。那每个文件的标识符都是唯一的,只不过这个标识符对用户来说毫无可读性,一般来说就是一连串没有意义的数字字母的组合。所以在这个界面,也没有向用户展示出一个文件的标识符。它只是操作系统用于区分各个文件的一种内部的名称。
第三,每个文件会有一个叫做文件类型的属性。
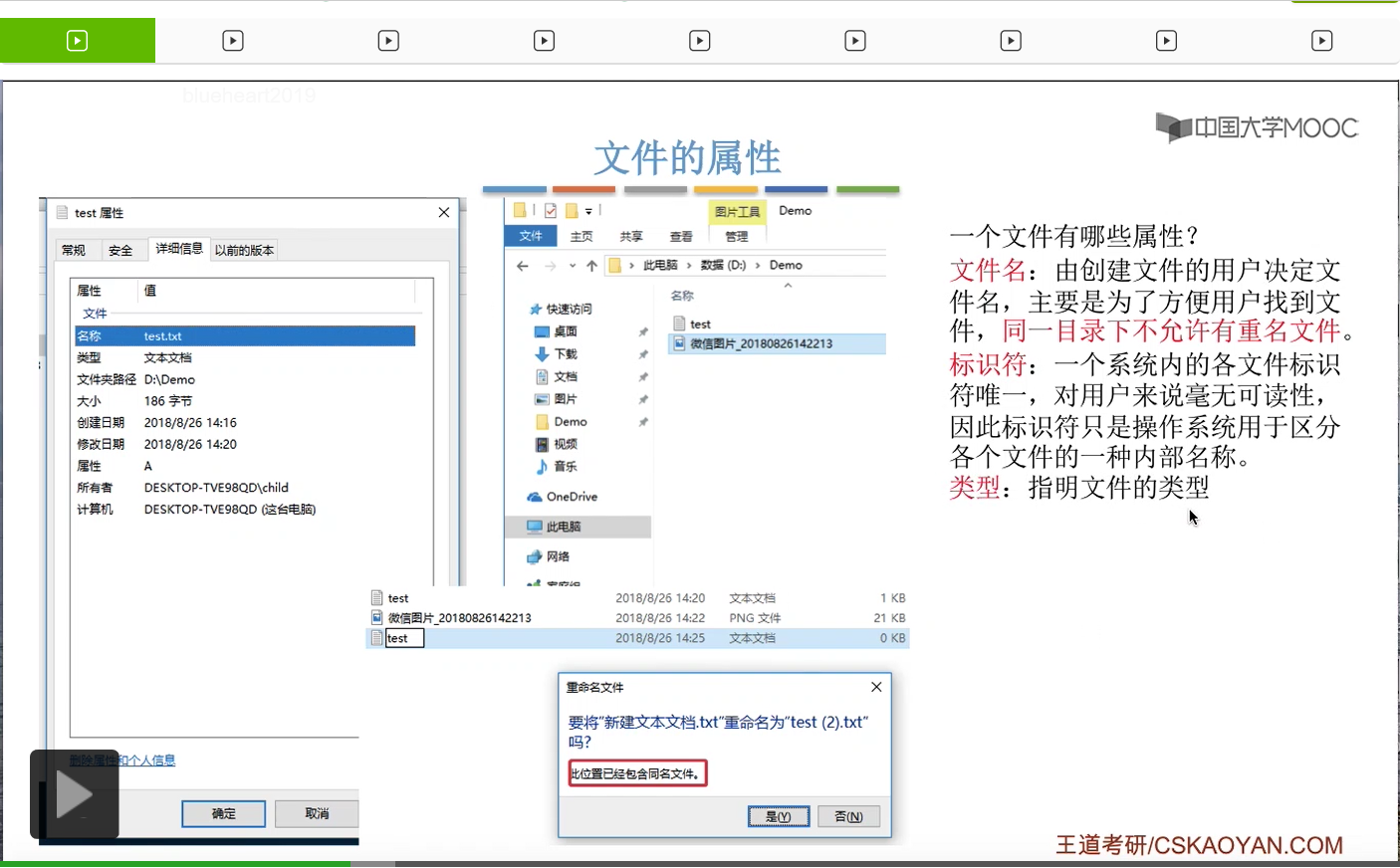
指明文件的类型有很多好处。比如说操作系统可以为不同类型的文件设置一个默认的打开的应用程序。

比如说.txt文件,就是默认用记事本这个应用程序打开的。那像.mp4这样的文件一般来说就是默认用一个视频播放的应用程序来打开并且呈现给用户。所以文件类型也是一个很重要的属性。
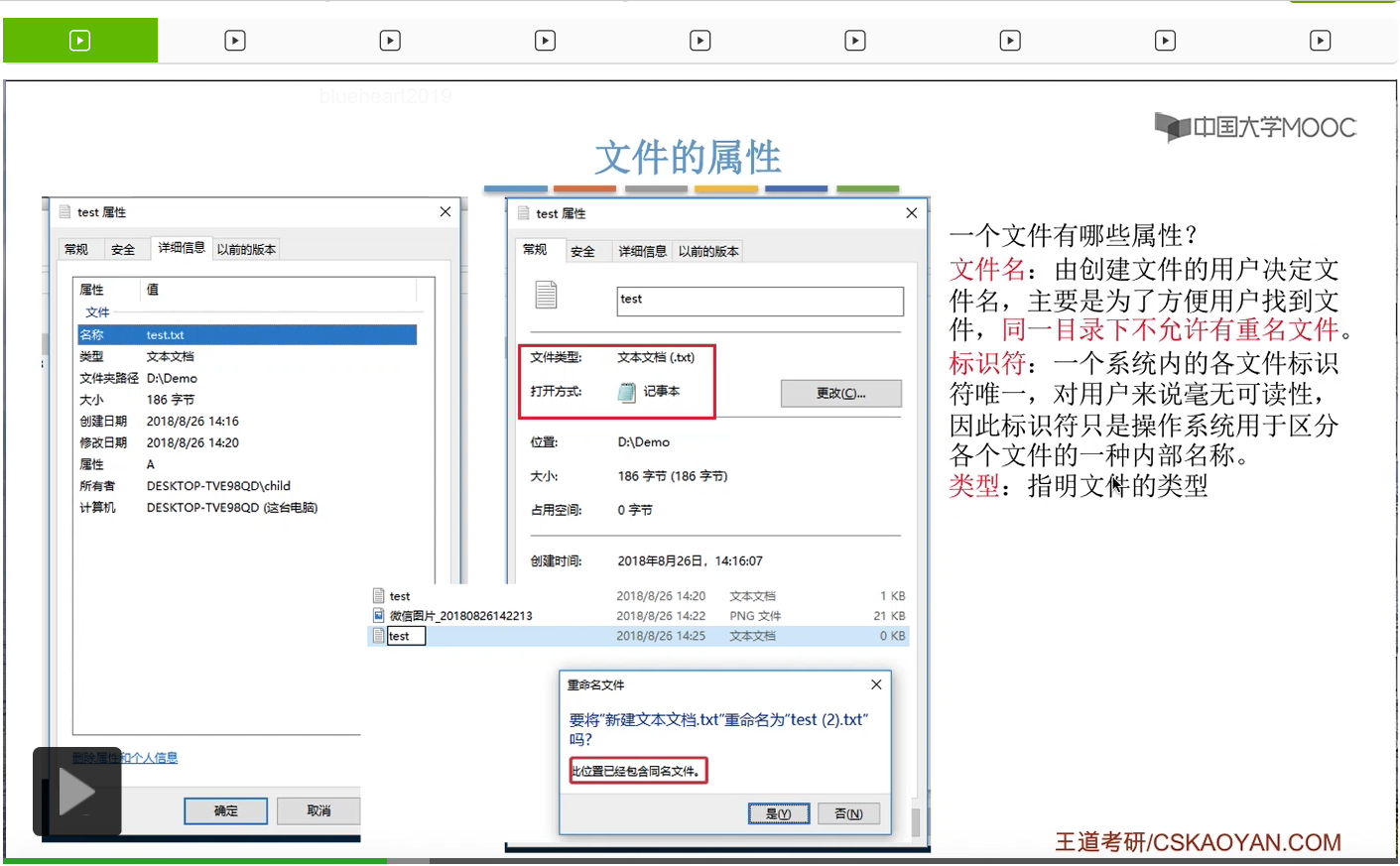
第四个很重要的属性是文件的位置。那这个位置包括文件的存放路径,这个存放路径是让用户使用的。不过这个文件平时是存放在外存也就是磁盘当中的,所以当我们双击打开这个文件的时候,其实操作系统需要从外存把文件的数据读入内存,因此操作系统也需要关心文件在外存当中存放的位置这个问题。只不过在外存当中存放的地址这个属性,对用户来说是不可见的,只有操作系统需要关心。
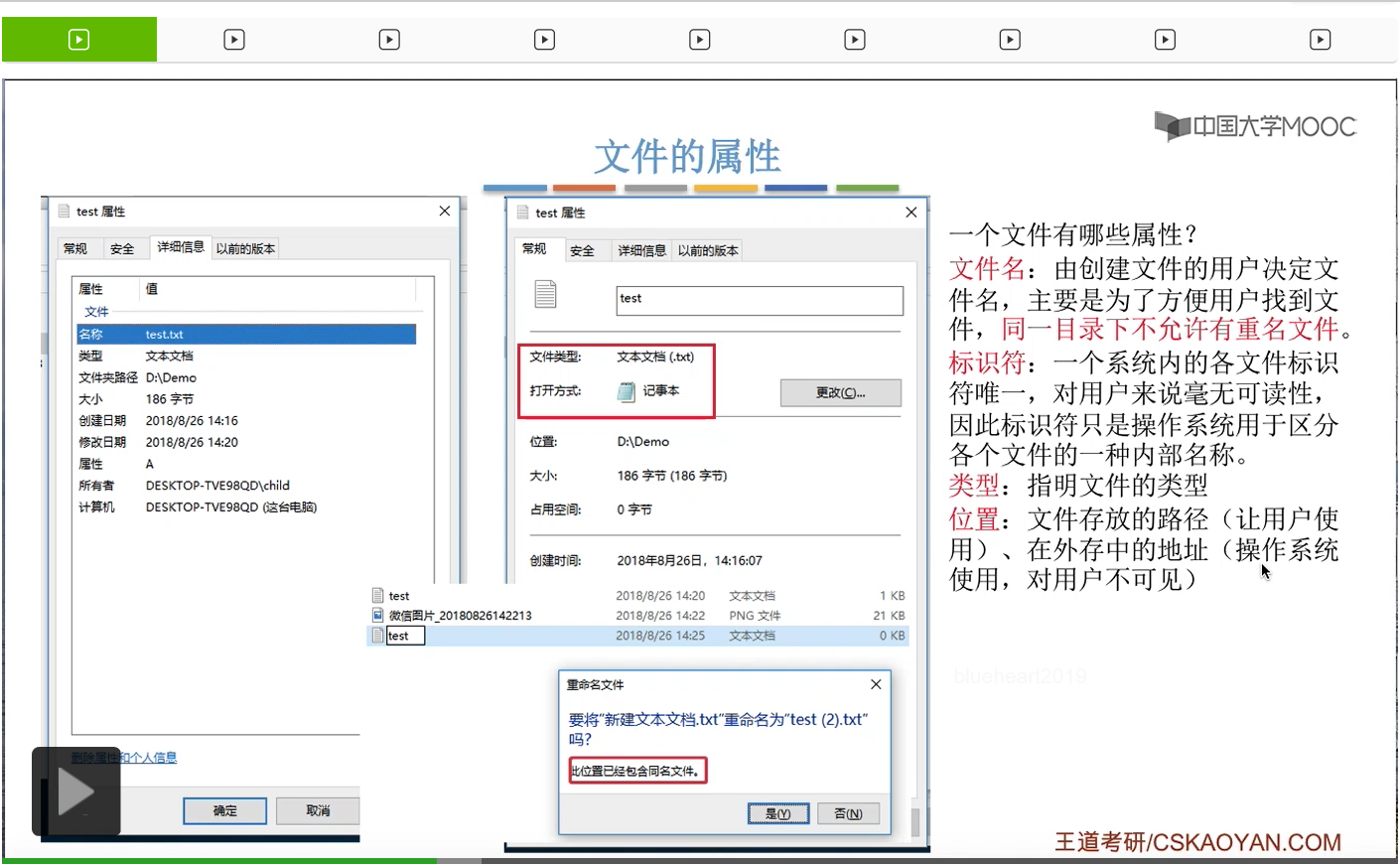
那除了上面介绍的这些很重要的属性之外,还有文件的大小。

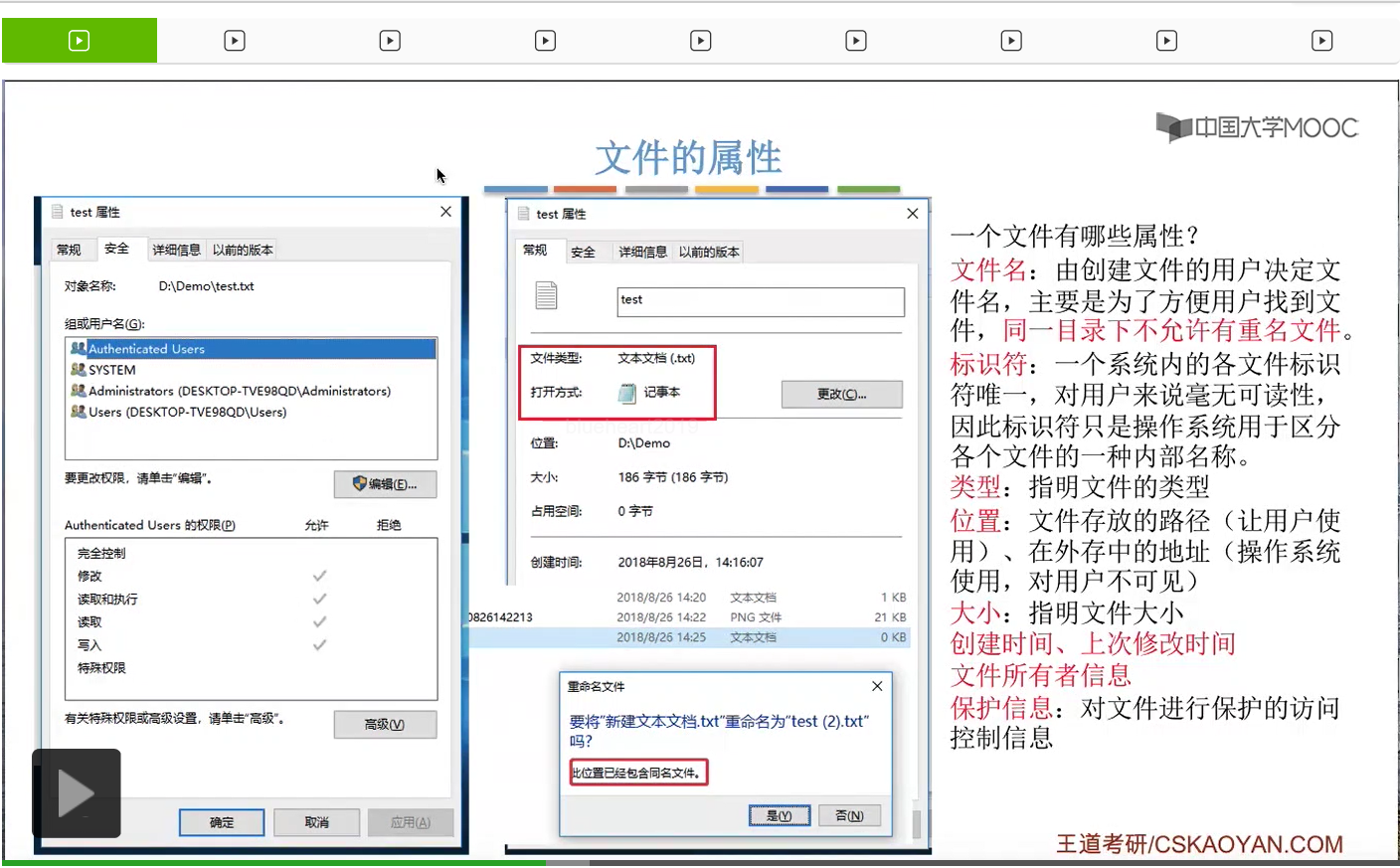
另外还有一个很重要的属性就是文件的保护信息。只不过文件的保护信息这个属性咱们平时在使用的过程当中几乎体会不到,那大家可以看一下自己的文件属性安全这个页签里,那大家会发现其实操作系统对这个系统当中的各种用户进行了一个分组,那不同分组的用户对于这个文件的操作权限是不同的。有的分组的用户可以对这个文件进行读和写,而有的分组甚至也不能读也不能写,不能访问这个文件。所以文件的保护信息可以让操作系统更好地保护一个文件的安全。如果我们创建的文件不想让别的计算机用户来访问的话,那么我们就可以设置一下它的保护信息就可以实现这件事。因为我自己的那个账户是没有权限访问游戏的那个启动程序的,所以这是文件的保护信息的一个作用。
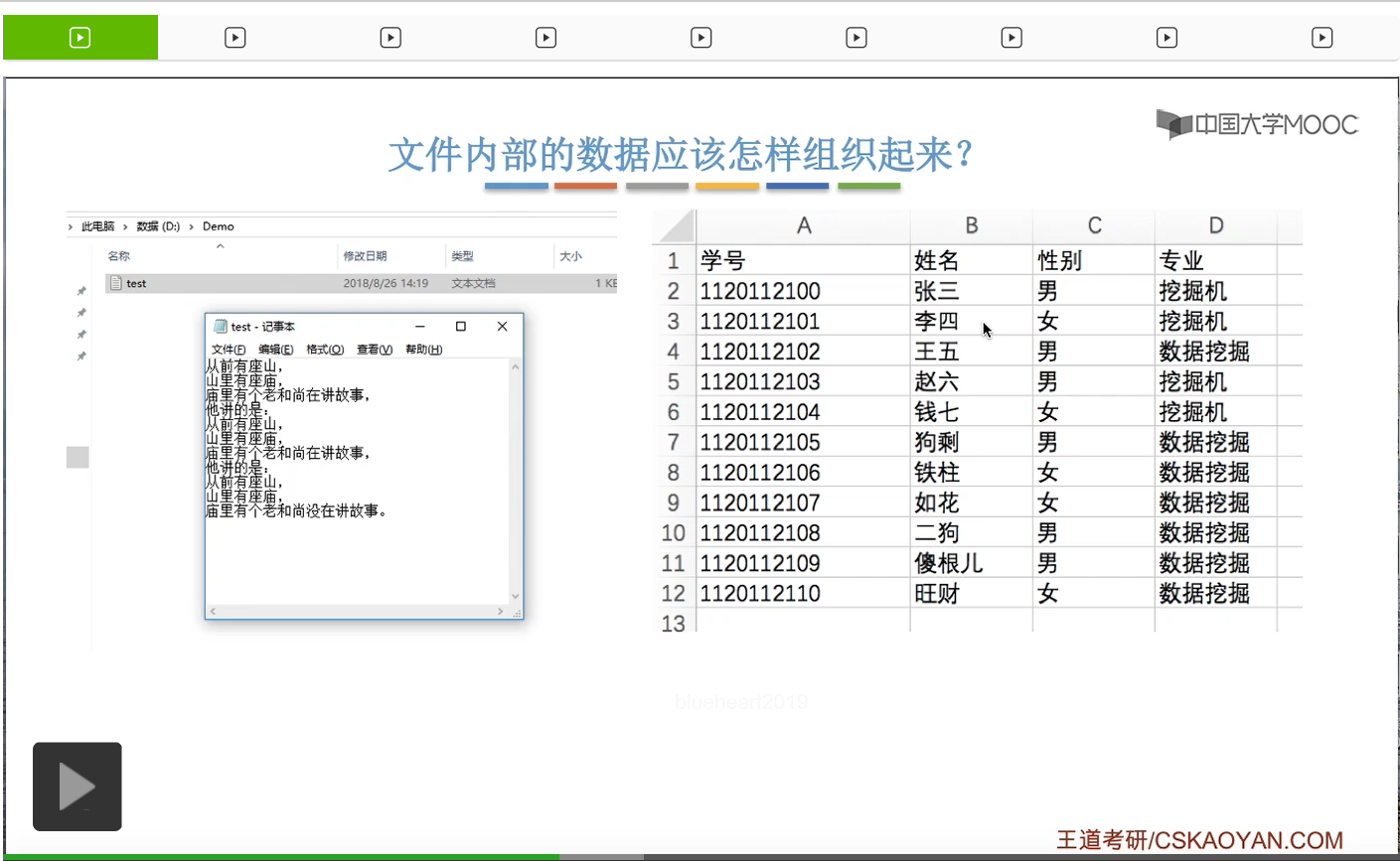
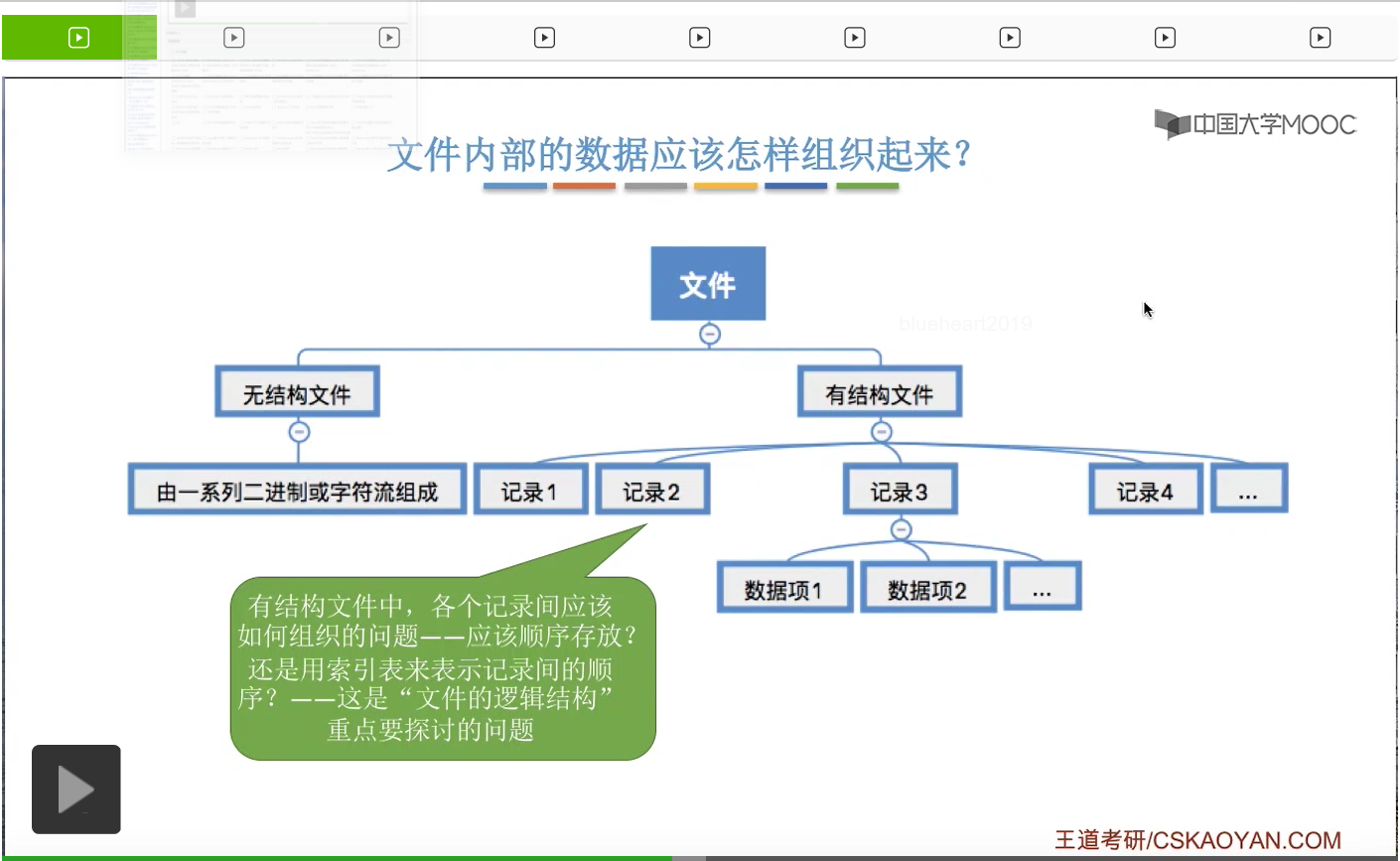
像.txt这种文件,它是一种看起来没有很明显的结构特性的文件。那这种文件它是由一些二进制或者说字符流组成,就是所谓的无结构文件,又称为流式文件。另外,在我们用户看来,还有一些文件表现出了很强的结构特性。比如说咱们使用的Excel表,还有有编程经验的同学肯定也使用过一些数据库,那数据库表也是一种有很明显的这种组织结构的一种文件。
 所以对于这种有结构文件来说,它是由一条一条的记录组成。那像这个地方这样的一行就是一条记录。而每个记录又是由一组相关的数据项组成,比如说学号是一个数据项,姓名是一个数据项,性别和专业又是另外的数据项。
所以对于这种有结构文件来说,它是由一条一条的记录组成。那像这个地方这样的一行就是一条记录。而每个记录又是由一组相关的数据项组成,比如说学号是一个数据项,姓名是一个数据项,性别和专业又是另外的数据项。
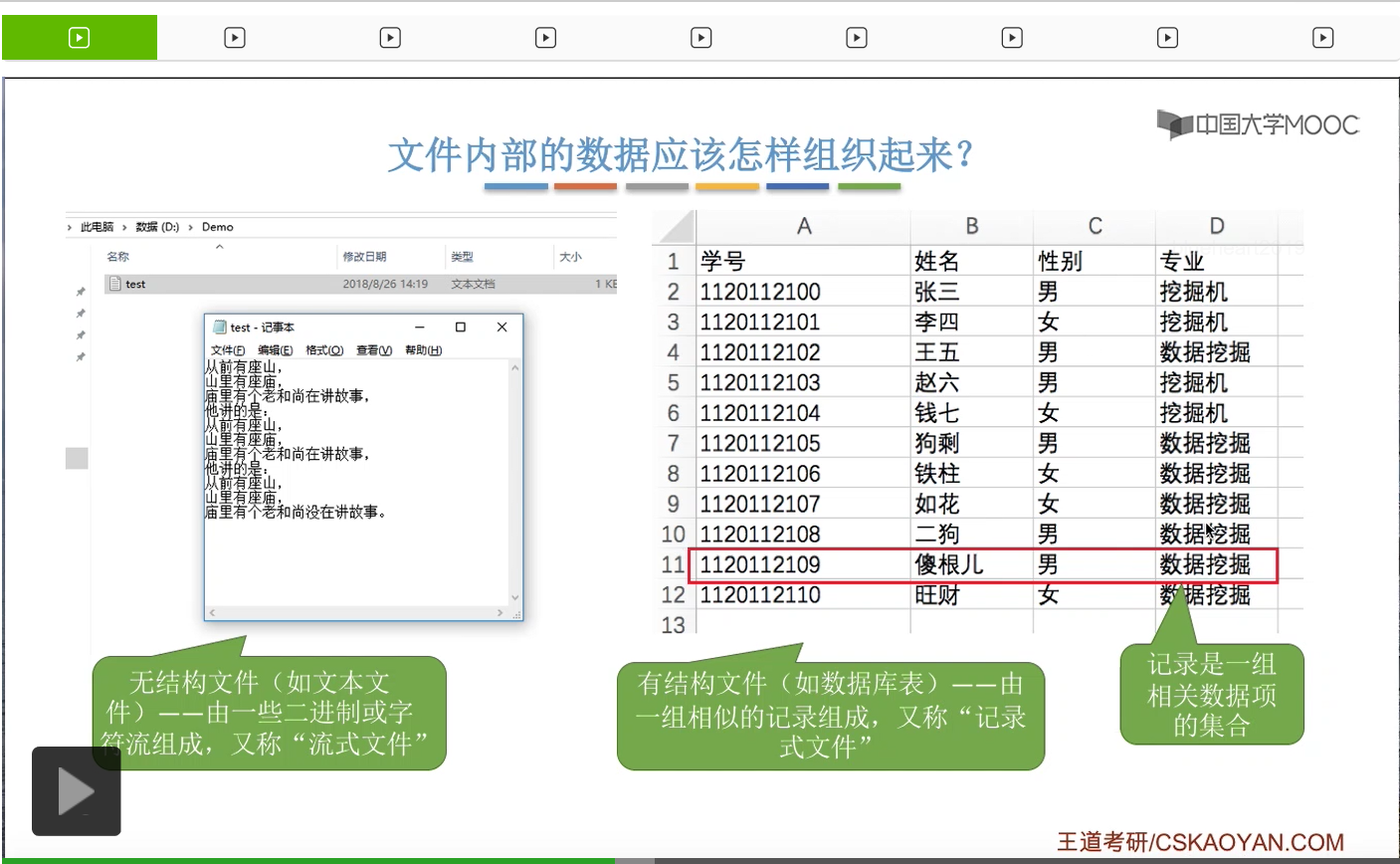
所以数据项它是文件系统当中最基本的一个数据单位。
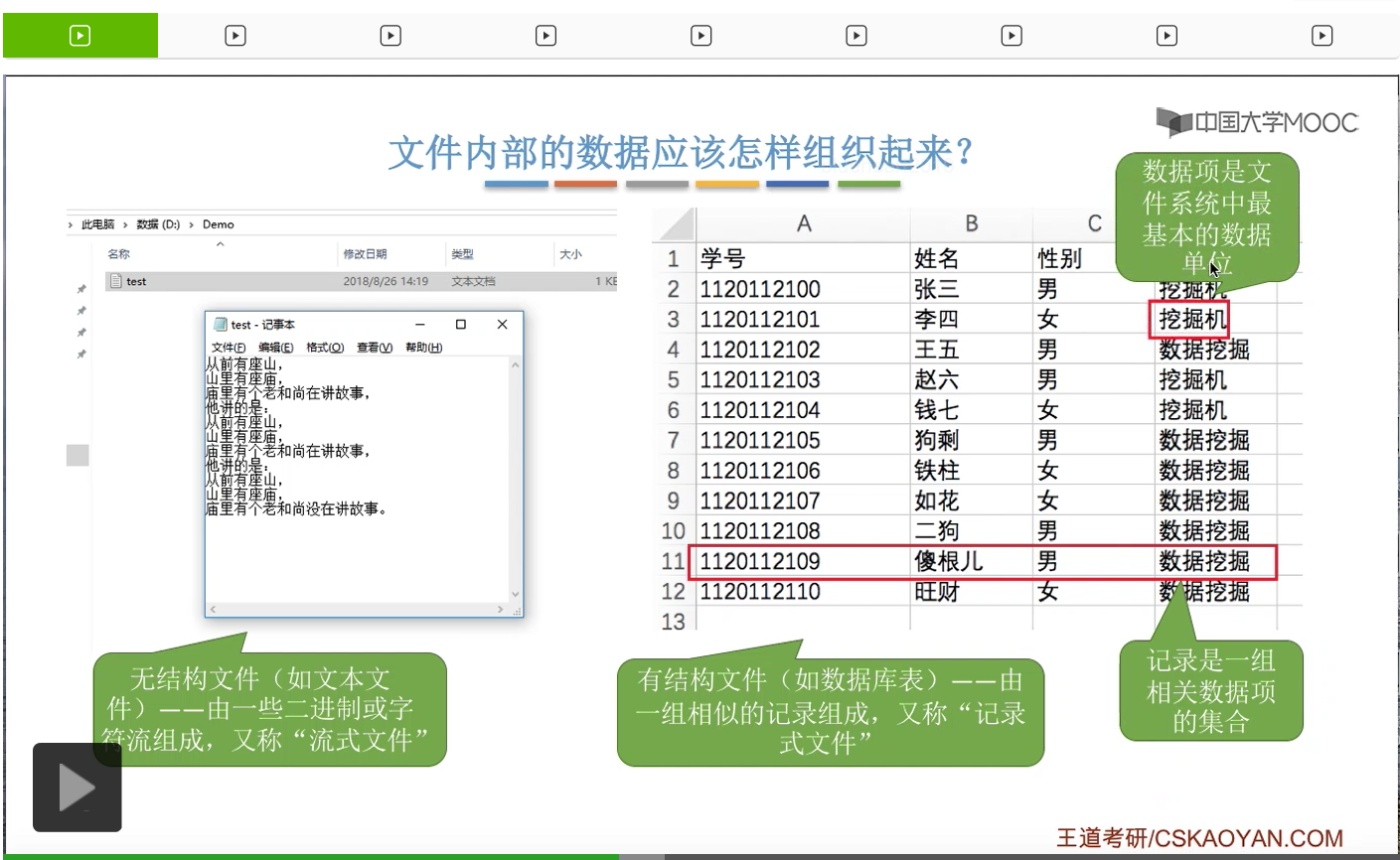
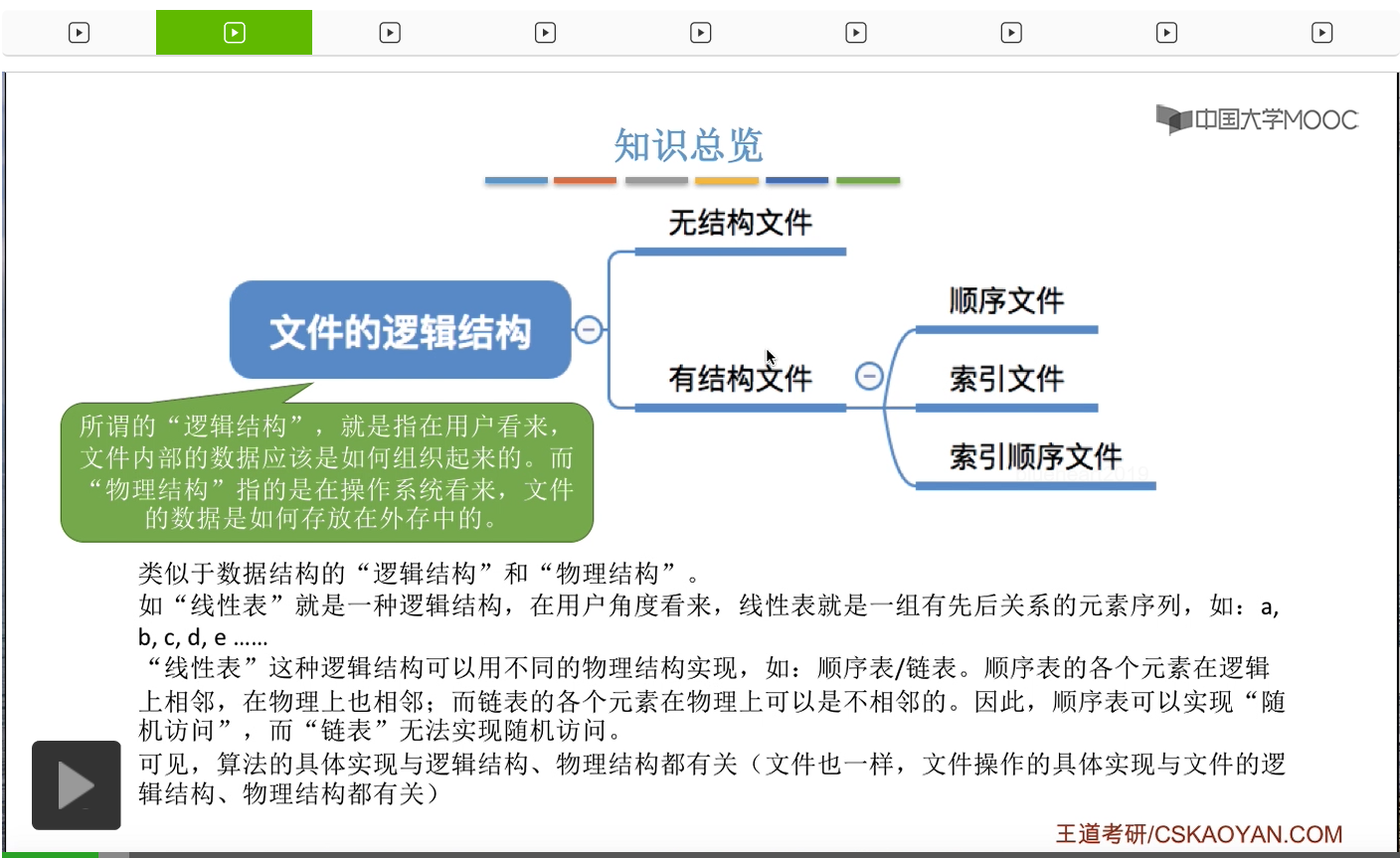
因此文件可以分为无结构文件和有结构文件这样两大类。那无结构文件它就是由一系列二进制或者说字符流组成,它没有明显的结构特性。而对于有结构文件来说,它是由一个一个的记录组成。每一个记录又由一系列的数据项组成。
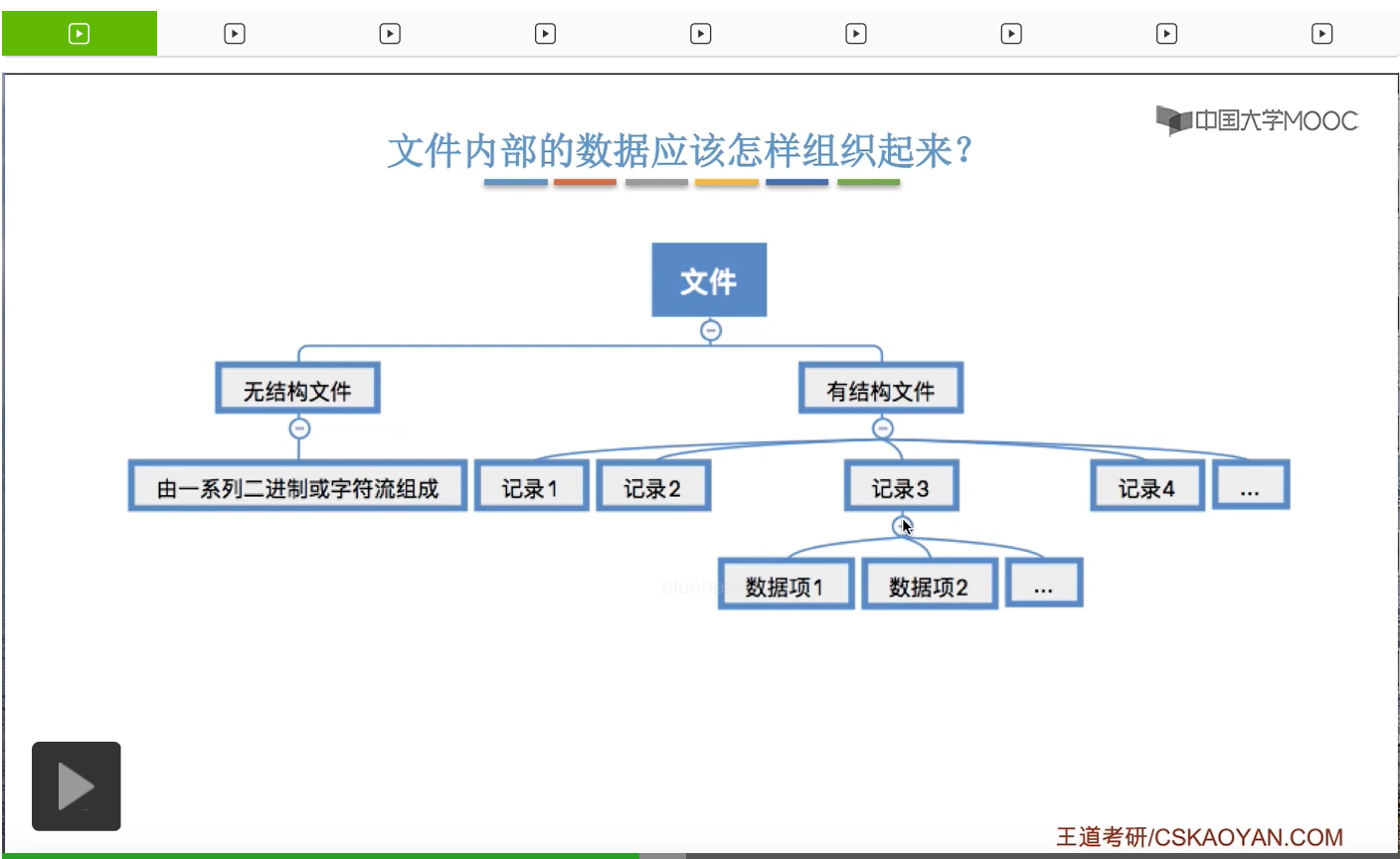
那这些记录应该如何组织的问题,也就是这些记录它们应该是顺序地存放,还是用一个索引表来表示它们之间的这种先后顺序?这些问题是咱们之后要讨论的文件的逻辑结构相关的一些问题,在这个地方暂时不展开。所以文件的逻辑结构要探讨的问题其实就是文件内部的这些记录这些数据应该被怎么组织起来的一个问题。那这是下个小节当中会讲解的内容。
接下来我们再来看一下文件之间应该怎样被组织起来。
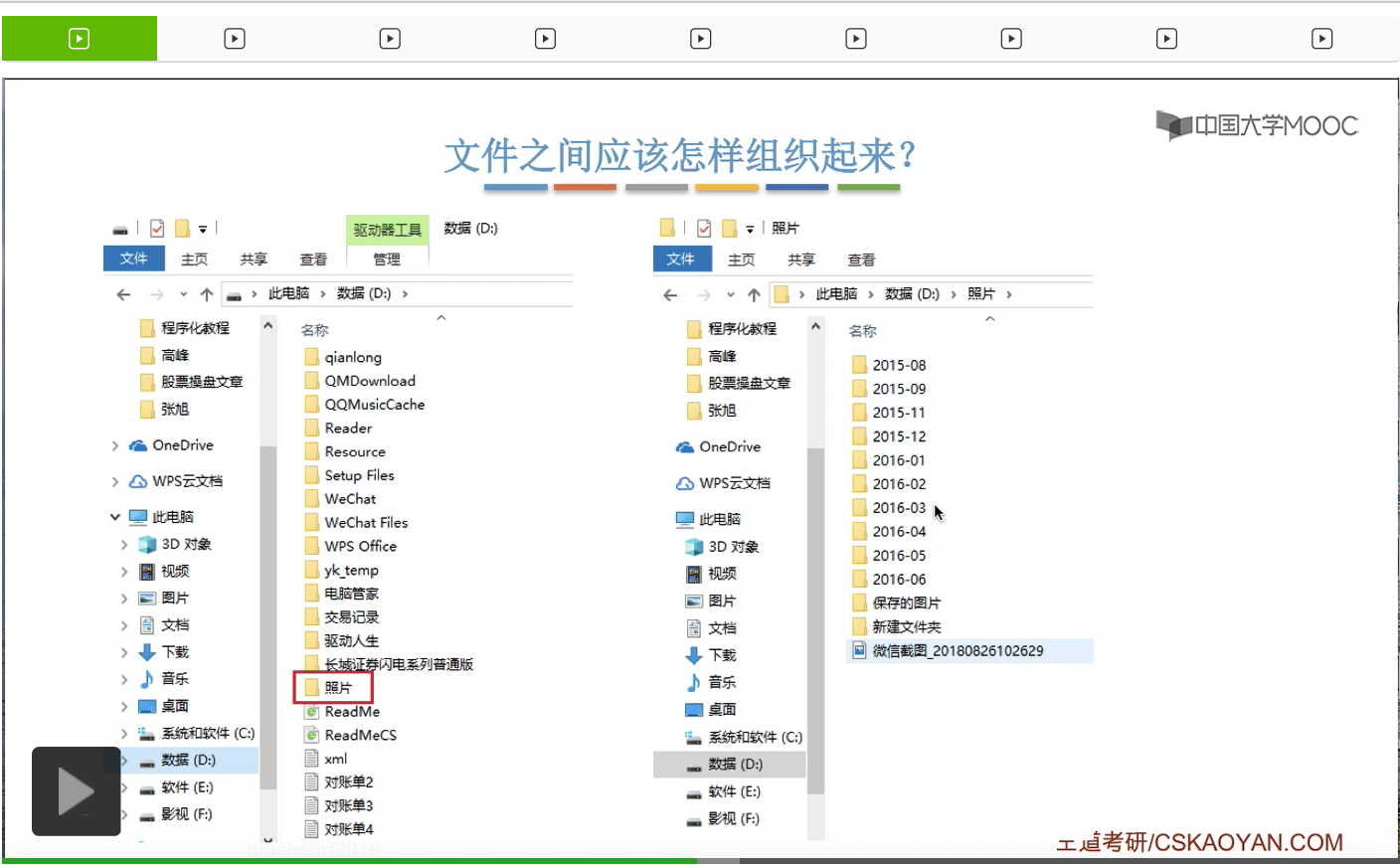
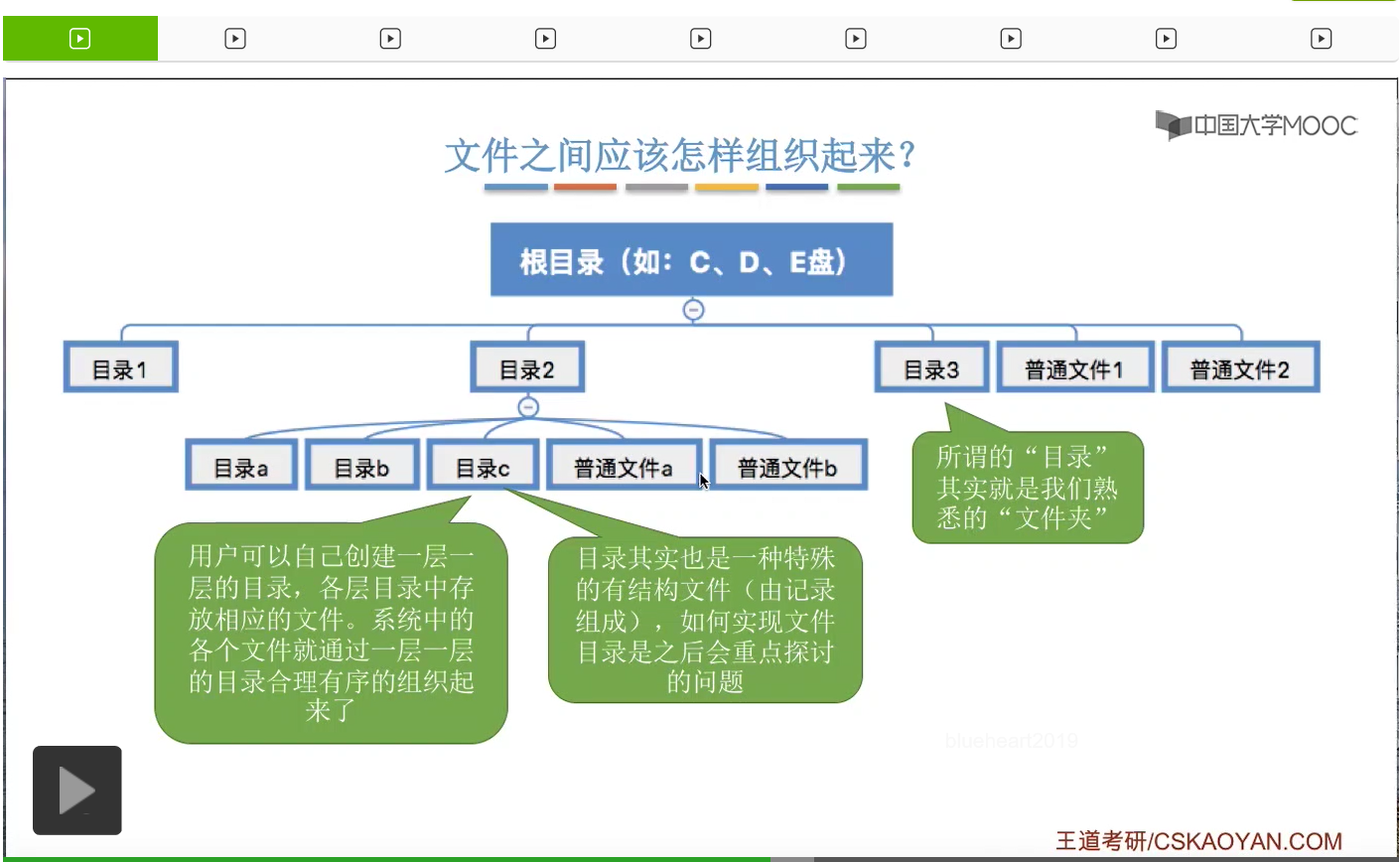
所以其实我们平时使用的这个Windows操作系统的文件之间的组织形式,看起来是一种树状的组织形式。一个根目录下可以有各种各样的文件目录,也可以有一些普通的文件。那在各个目录下面,我们还可以创建更深一层的目录,也可以存放一些普通的文件。那其实这个地方所谓的目录,文件目录,就是我们熟悉的文件夹。
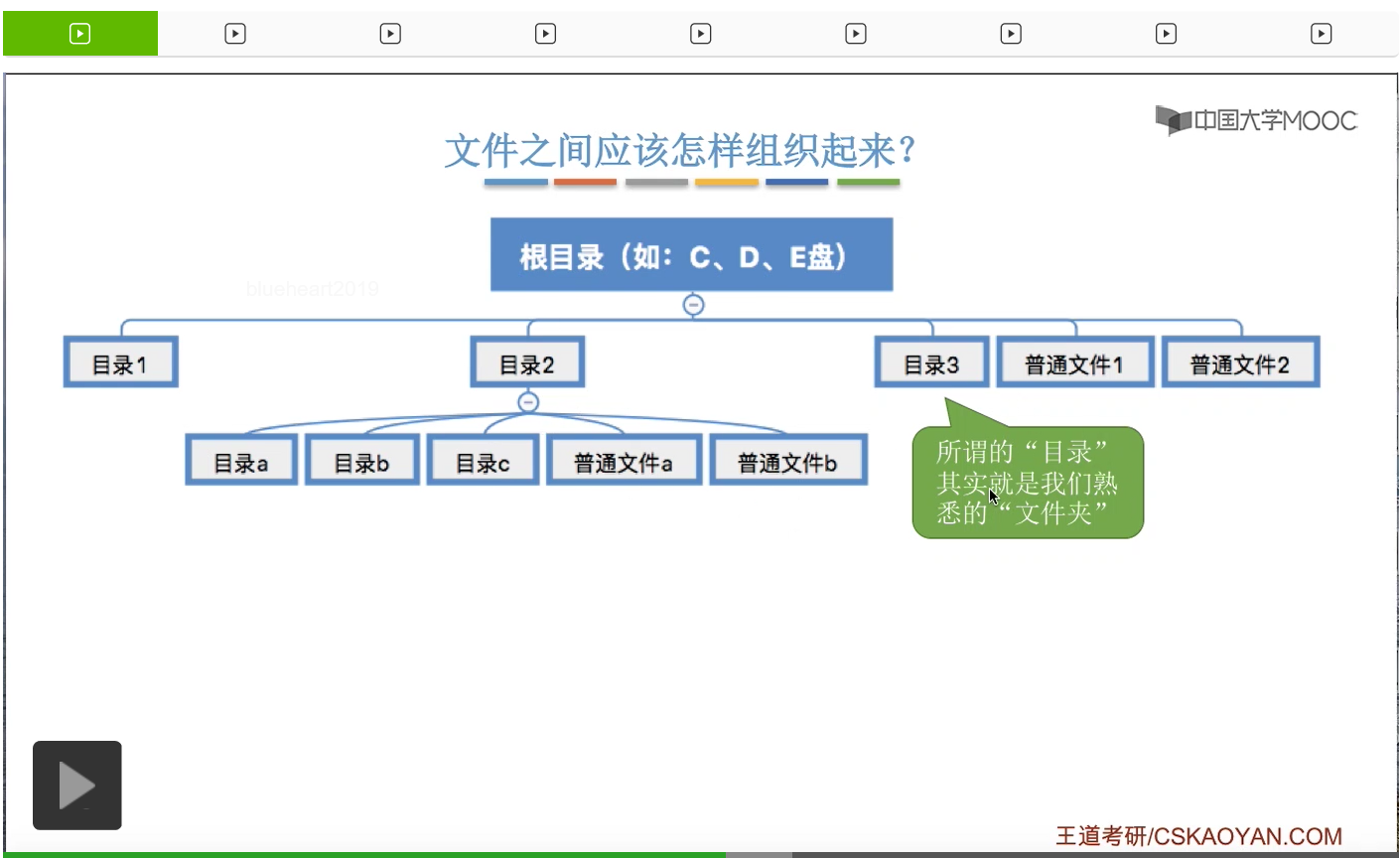
我们普通用户可以自己创建一层一层的目录,在各层目录当中存放一些我们想要存放的文件,所以我们的各种各样的文件,就通过目录这种功能把它们有序地组织起来了。
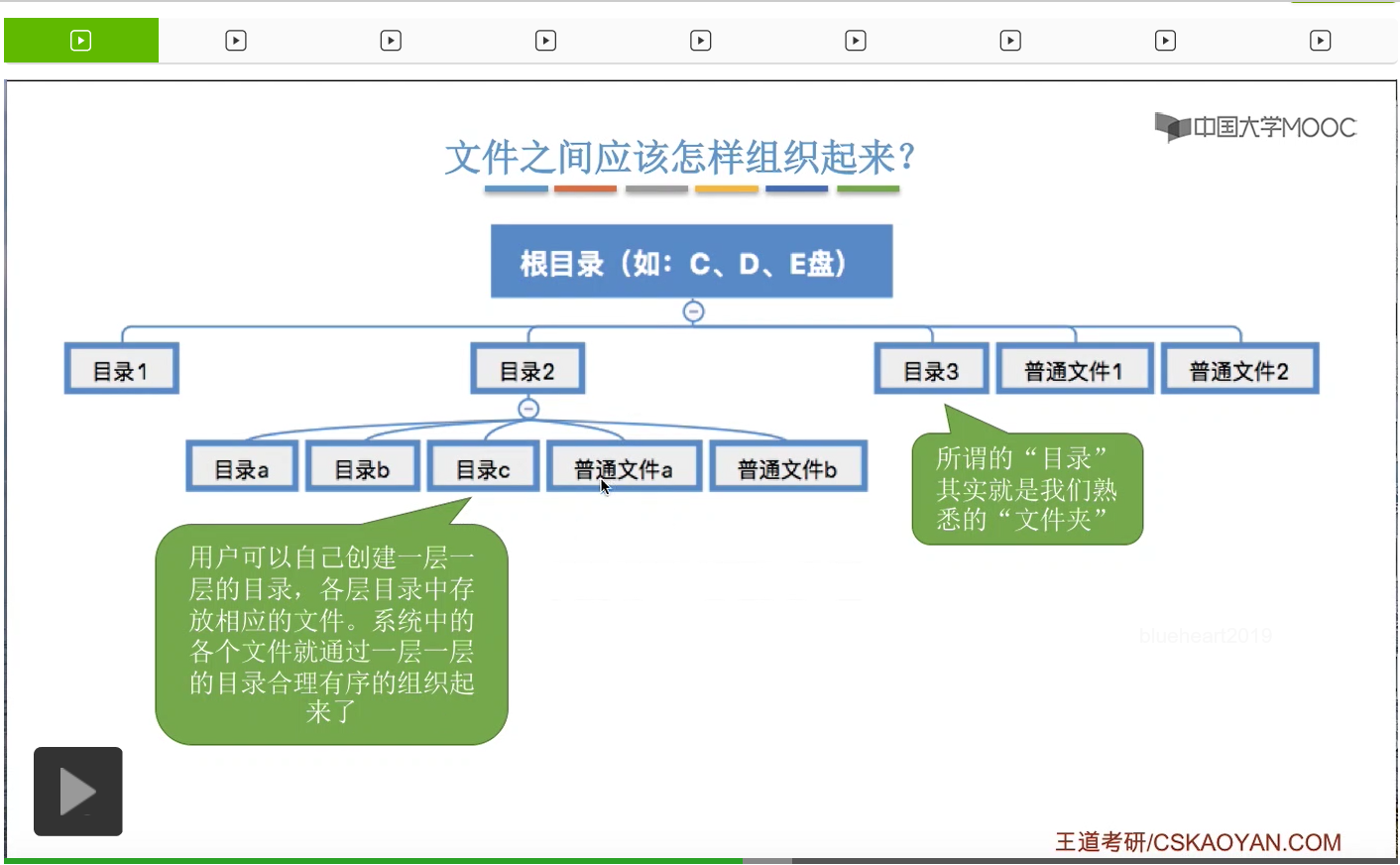
那其实我们平时看见的目录或者说文件夹,它也是一种特殊的有结构文件。那这个有结构文件它也是由一系列的记录组成,那具体这个目录应该是怎么实现的,这也是咱们之后会重点探讨的问题,这儿先不展开。总之文件通过目录这样的功能,把它们有序地一层一层地组织起来了,这样很方便我们用户使用。
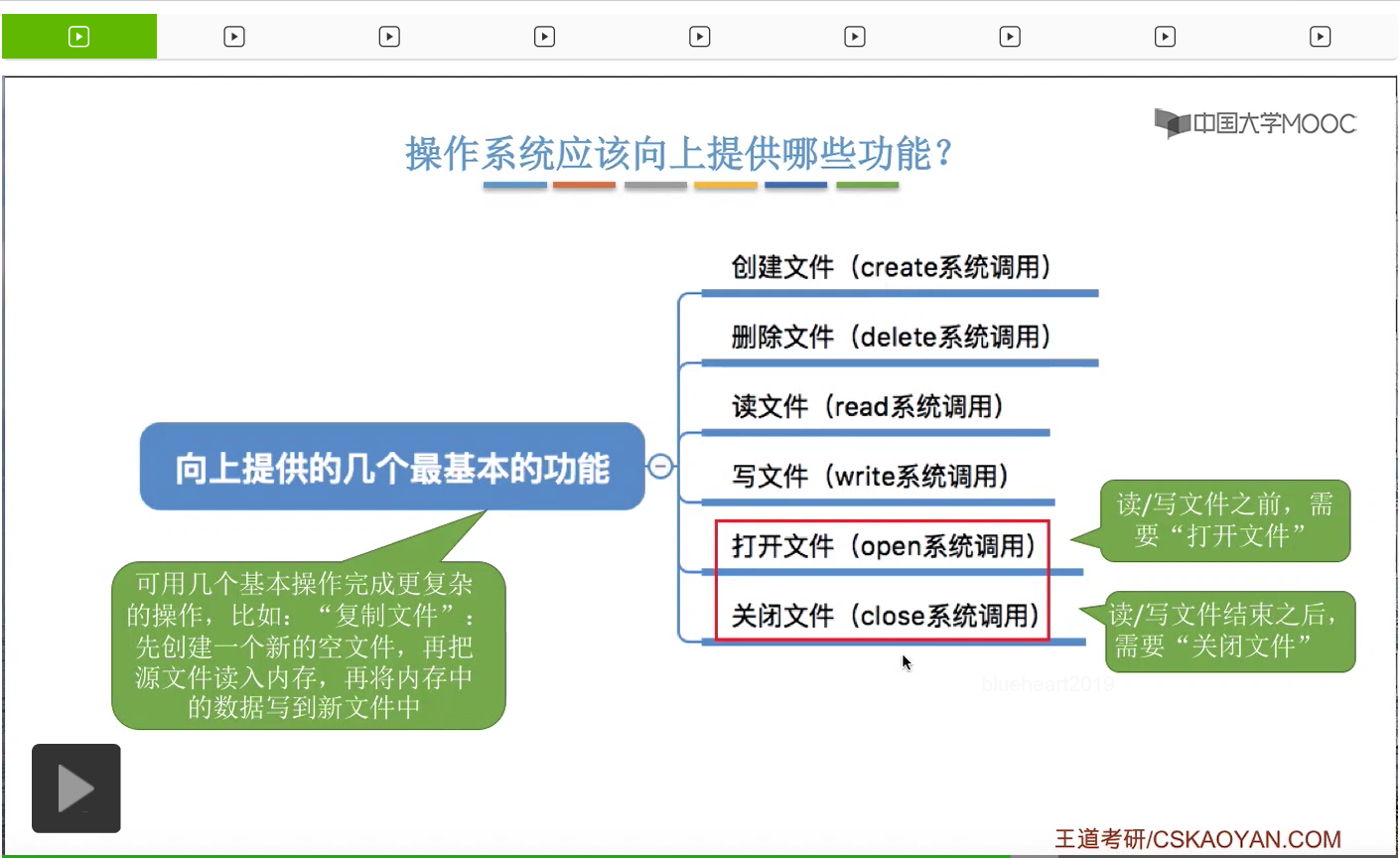
接下来我们考虑一下操作系统应该对它的上层提供哪些功能。
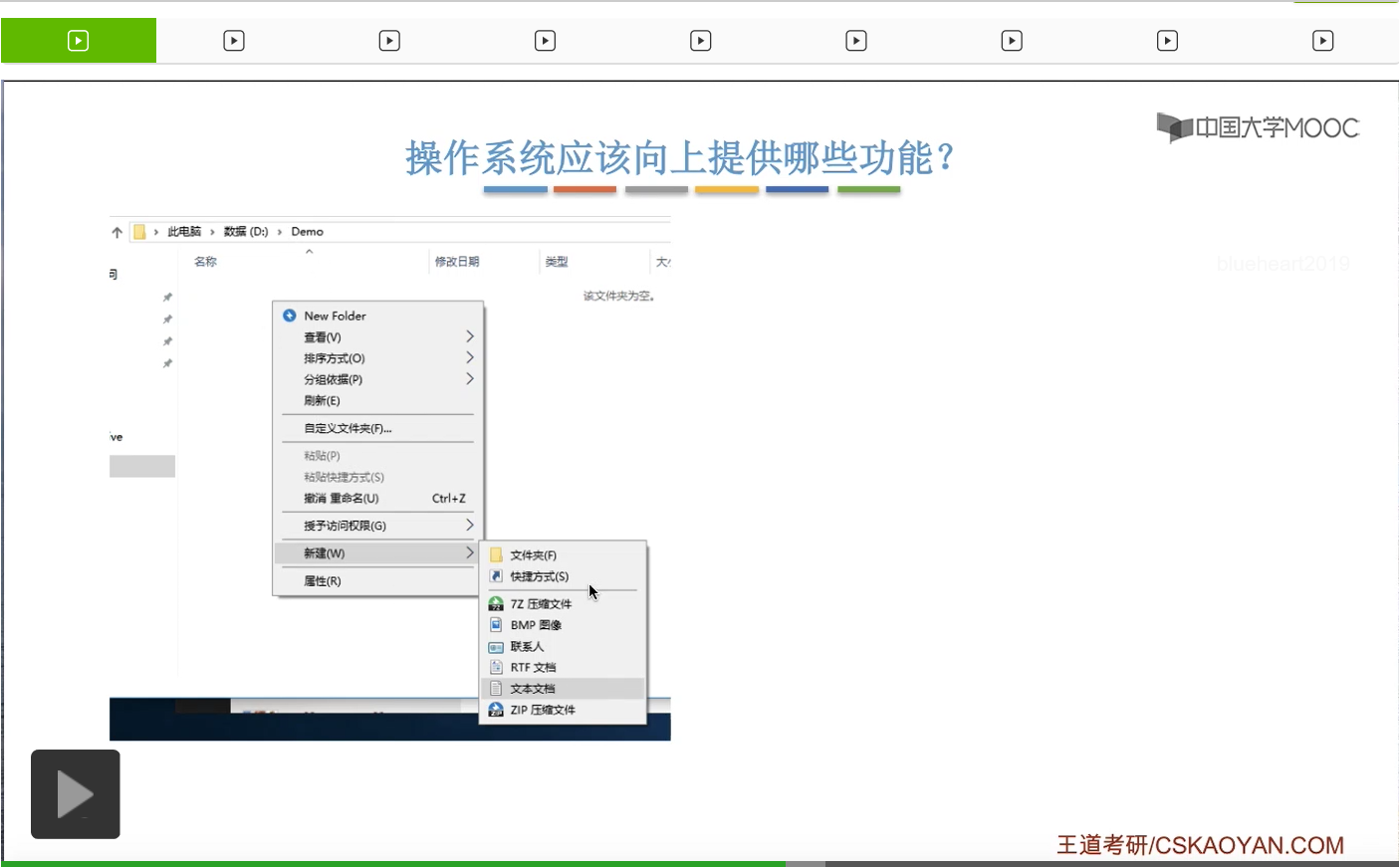
那点了新建之后,其实在背后是使用了操作系统提供的一个创建文件的功能。在我们点了新建按钮之后,这个图形化交互进程其实是在背后调用了操作系统向上层提供的create系统调用来完成这个文件创建的一个工作。
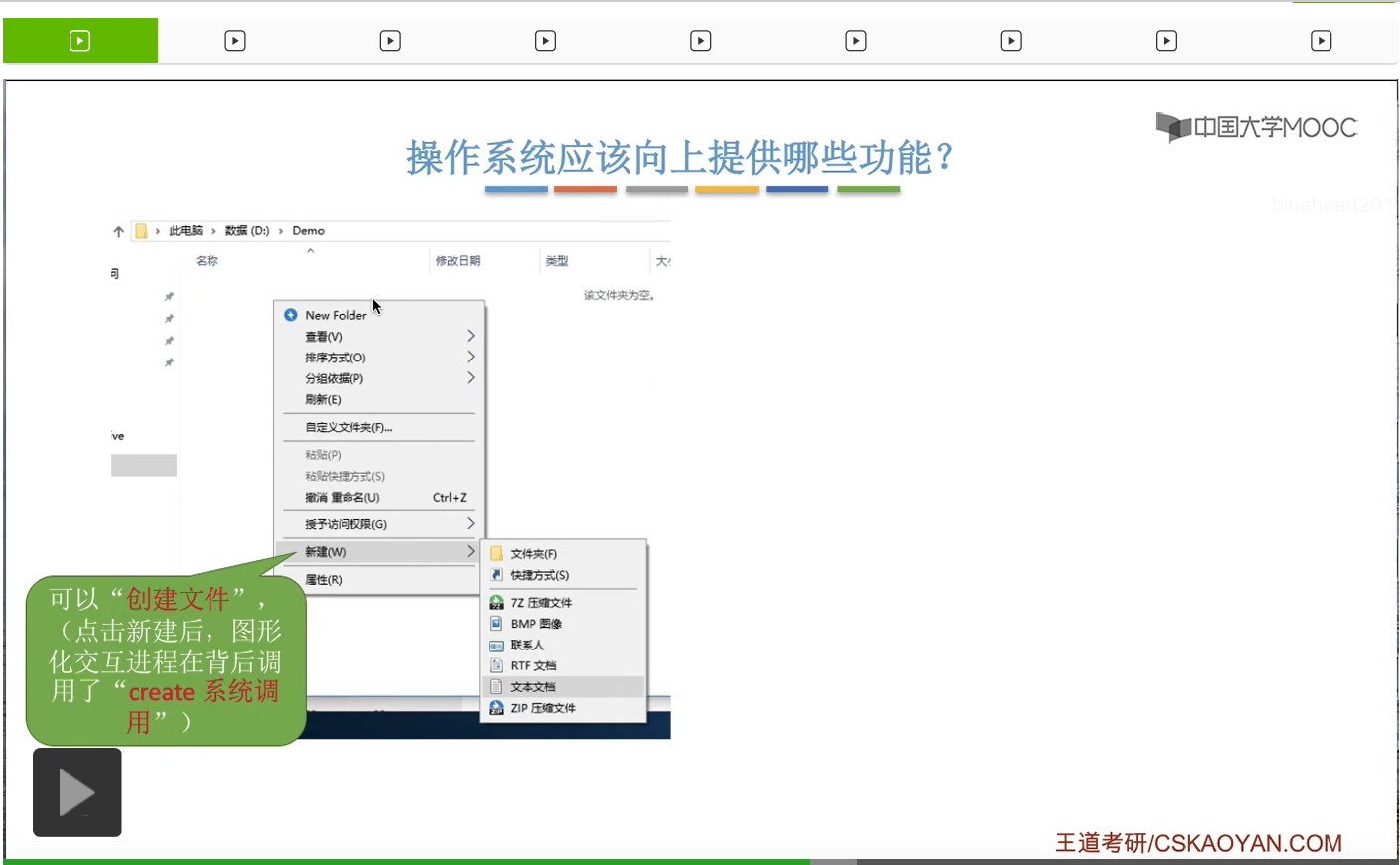
那在我们创建了文件之后,这个文件的数据就已经在外存当中了。

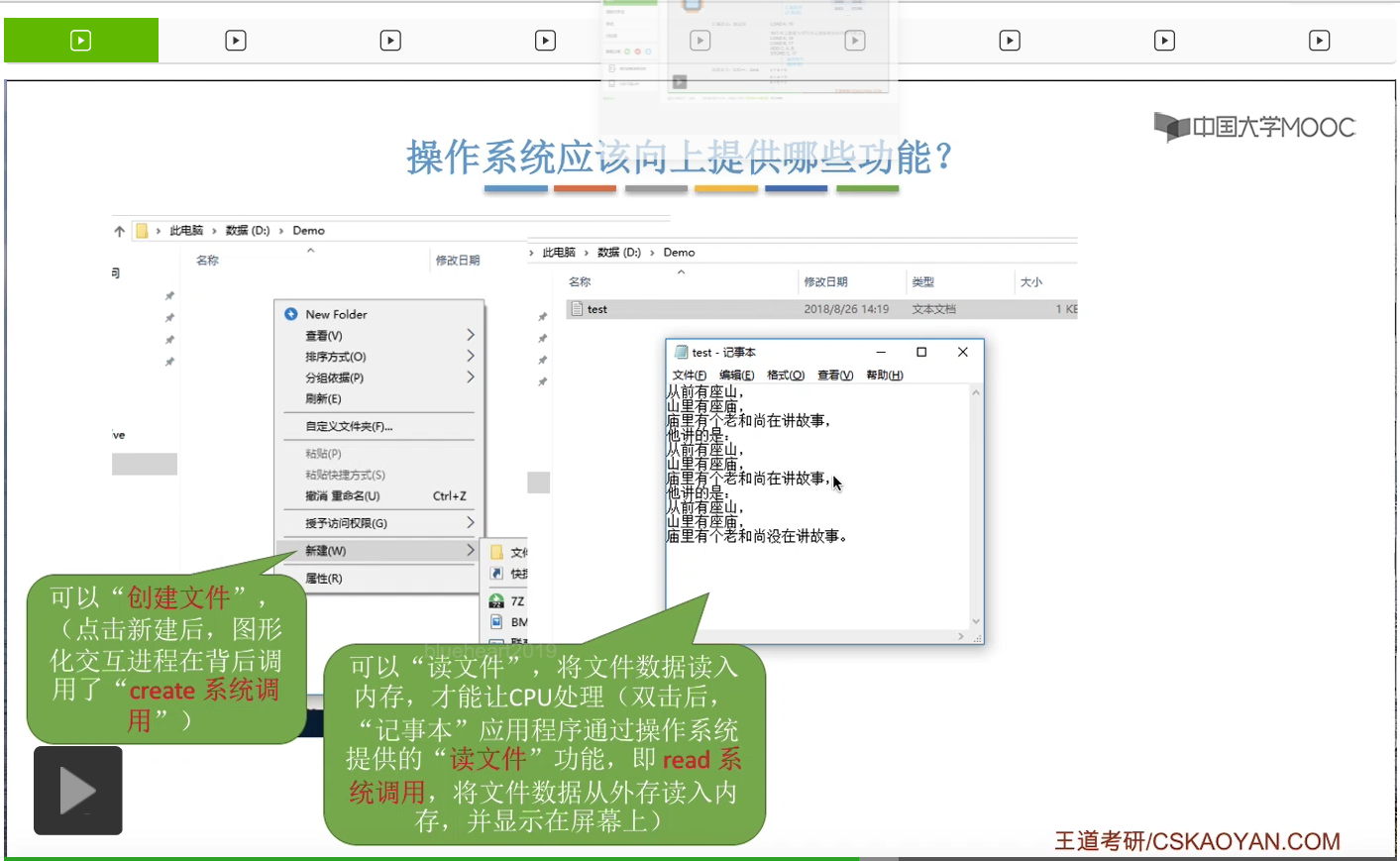
那我们可以双击打开这个文件,为了读取这个文件的数据,那我们需要把文件的数据从外存读入内存。因为只有读入内存之后,才可以让CPU处理。所以这个地方就使用到了一个叫做读文件的功能。其实在我们双击这个txt文件之后,操作系统先是默认地打开了自动地打开了.txt对应的那种应用程序,也就是记事本这个应用程序。那这个应用程序又调用了操作系统向上提供的read系统调用来实现了读文件的功能,通过读文件的功能就可以把这个文件的数据放到内存,然后就可以呈现在用户面前。
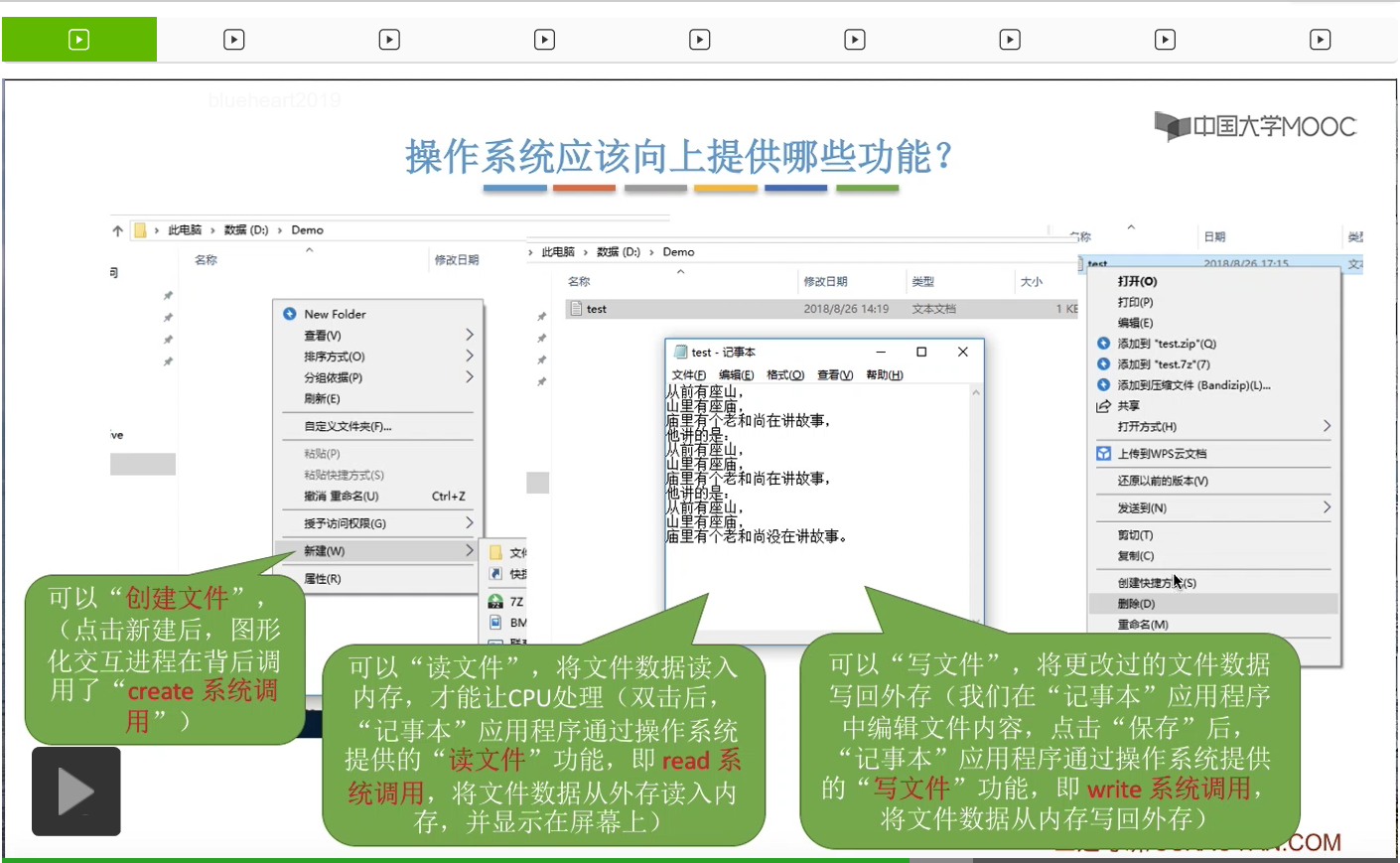
那另外,当我们把这个文件编辑结束之后,我们可以保存文件。其实在我们点击了文件保存那个按钮之后,记事本这个应用程序在背后也做了一系列事情,主要是调用了操作系统向上层提供的这个write系统调用,write系统调用就实现了所谓的写文件功能。这个功能就是负责把文件的数据从内存再写回外存。因为我们平时编辑这个文件的时候,其实只是改变了文件在内存当中的那个副本的数据。所以为了保存这个文件的内容,我们必须再使用写文件的功能。那这是第三个需要向上层提供的很基本的功能。

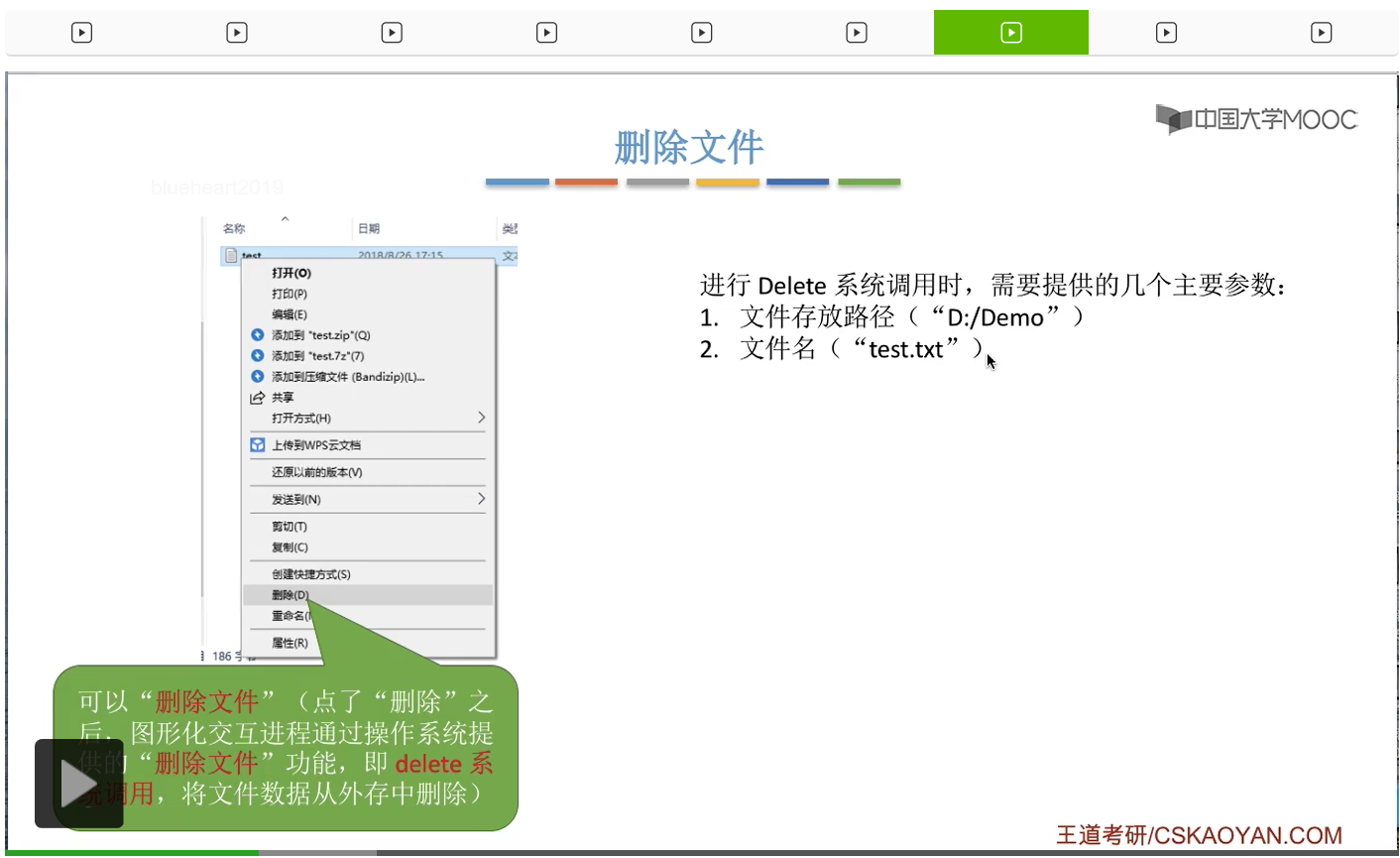
第四个,既然我们可以创建一个文件,那当然我们也可以删除一个文件。
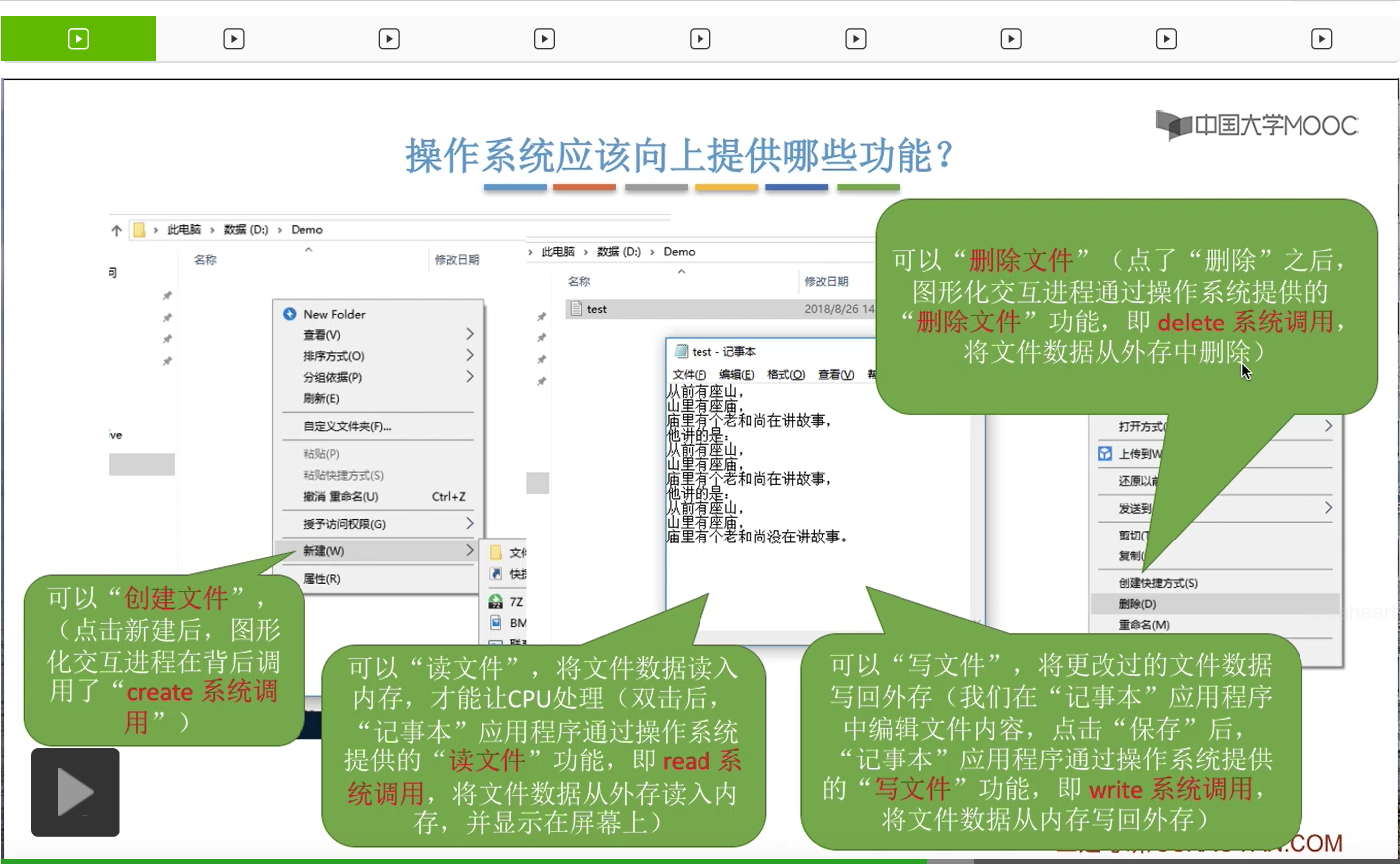
那其实在我们点了删除这个按钮之后,这个图形化交互进程是在背后调用了操作系统提供的删除文件的功能,也就是delete系统调用,这样的话就可以把文件的数据从外存当中抹除了。
那除了咱们平时肉眼可见的这一系列对文件的操作功能之外,操作系统还需要提供打开文件和关闭文件这两个基本的功能。那这个地方的打开和关闭和我们平时所谓的双击还有点那个关闭窗口的小XX其实是不一样的两个东西。那具体打开文件和关闭文件的时候需要做什么咱们之后再进行探讨。很多对文件的复杂操作可以用这些基本功能来进行组合。
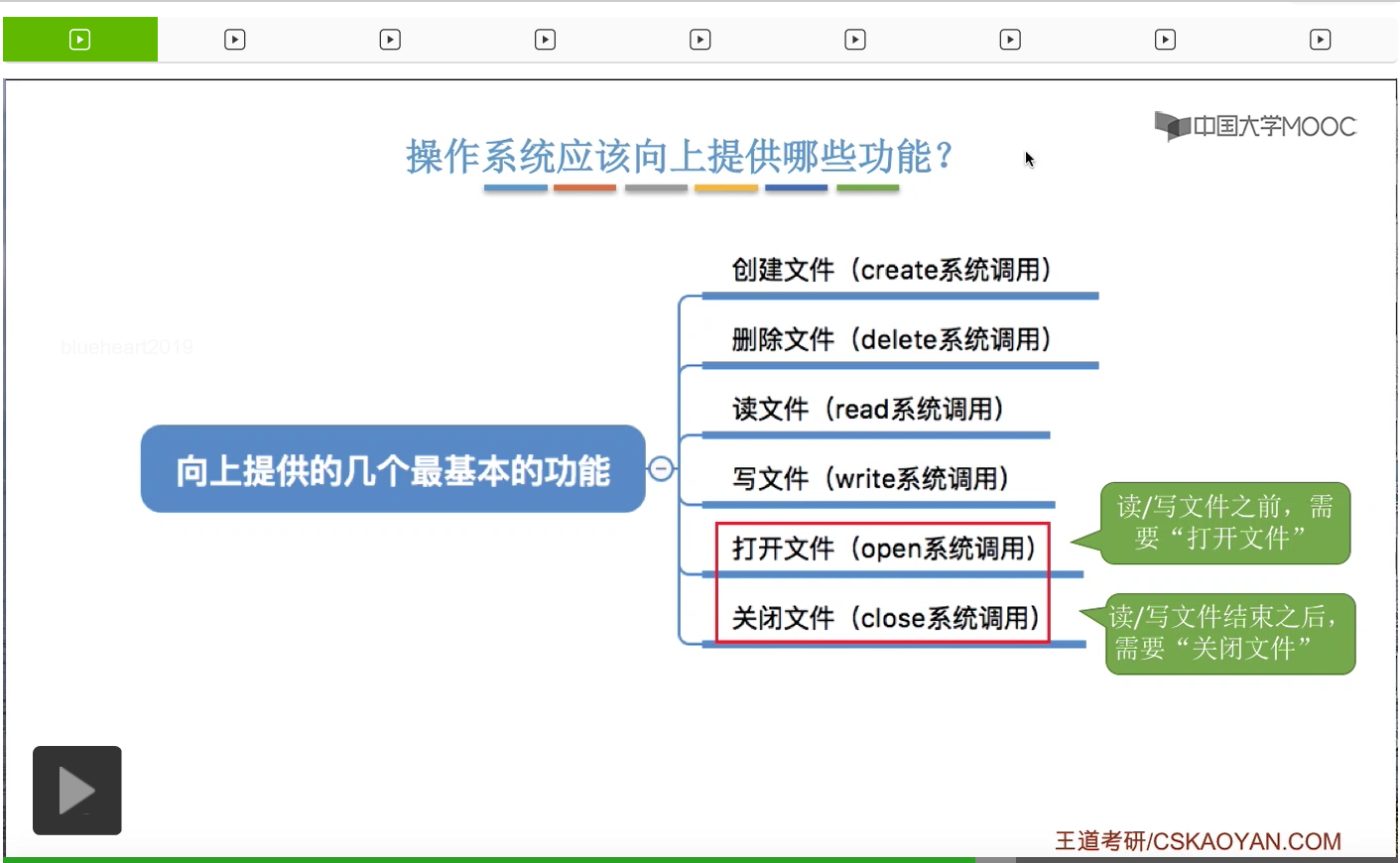
因此可以看到,其实更复杂的这些功能也可以用这些基础的功能来进行实现。
那操作系统在处理这些系统调用的时候在背后需要做哪些事情这是咱们之后会再展开探讨的问题。

那接下来我们再来看一下,既然文件它是要存放在外存当中,而外存又属于一种硬件,从上往下看操作系统又是最接近硬件的一个层次,因此操作系统需要对硬件进行管理。那相应的,这些文件的数据应该被怎么放到外存这个硬件当中,当然也是操作系统需要关心和解决的问题。
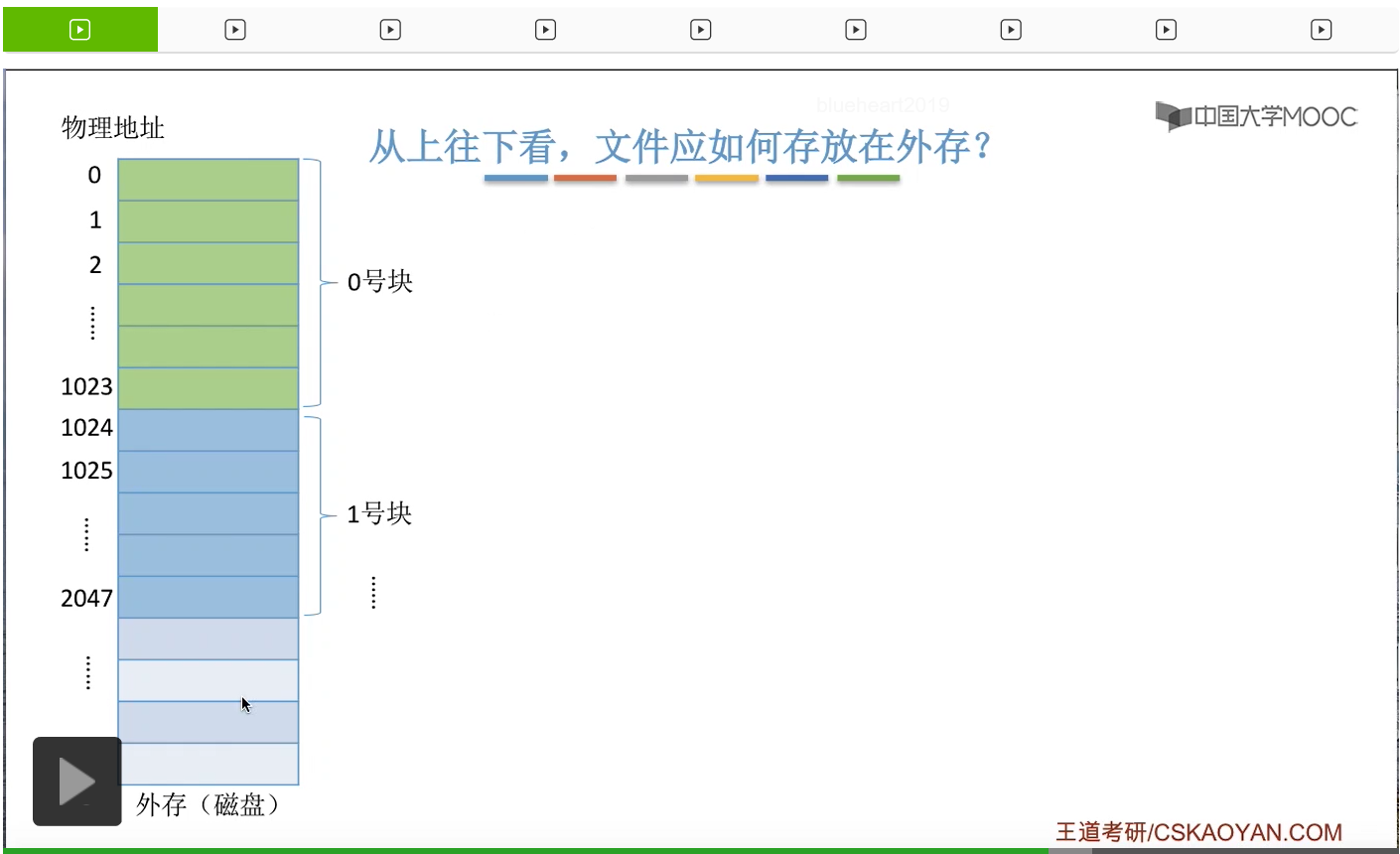
首先大家需要知道的是,外存也会像内存一样,被分为一个一个的这种存储单元。那每个存储单元可以放一定量的数据,比如说是一个字节B。并且每个存储单元会对应一个物理地址。

那同样类似于内存的是,内存会被分为一个一个大小相等的内存块,外存也会被分为一个一个大小相等的块,或者叫磁盘块、物理块。每一个磁盘块的大小都是相等的,并且每个磁盘块一般会包含2的整数幂个地址。比如说在这个例子当中,一个磁盘块包含1024个地址,也就是2^10个地址,总共1KB这么大小。那相应的,文件的逻辑地址也可以分为逻辑块号和块内地址这样的两个部分。操作系统同样也需要把文件的逻辑地址转换为外存的物理地址,也就是物理块号和块内地址这样的形式。那块内地址的位数取决于这个磁盘块的大小。比如说在这个例子当中,一个磁盘块占2^10个字节这么多,所以要表示2^10个物理地址,总共就需要10个二进制位才可以表示。因此,在这个例子当中,块内地址的位数应该是10位。
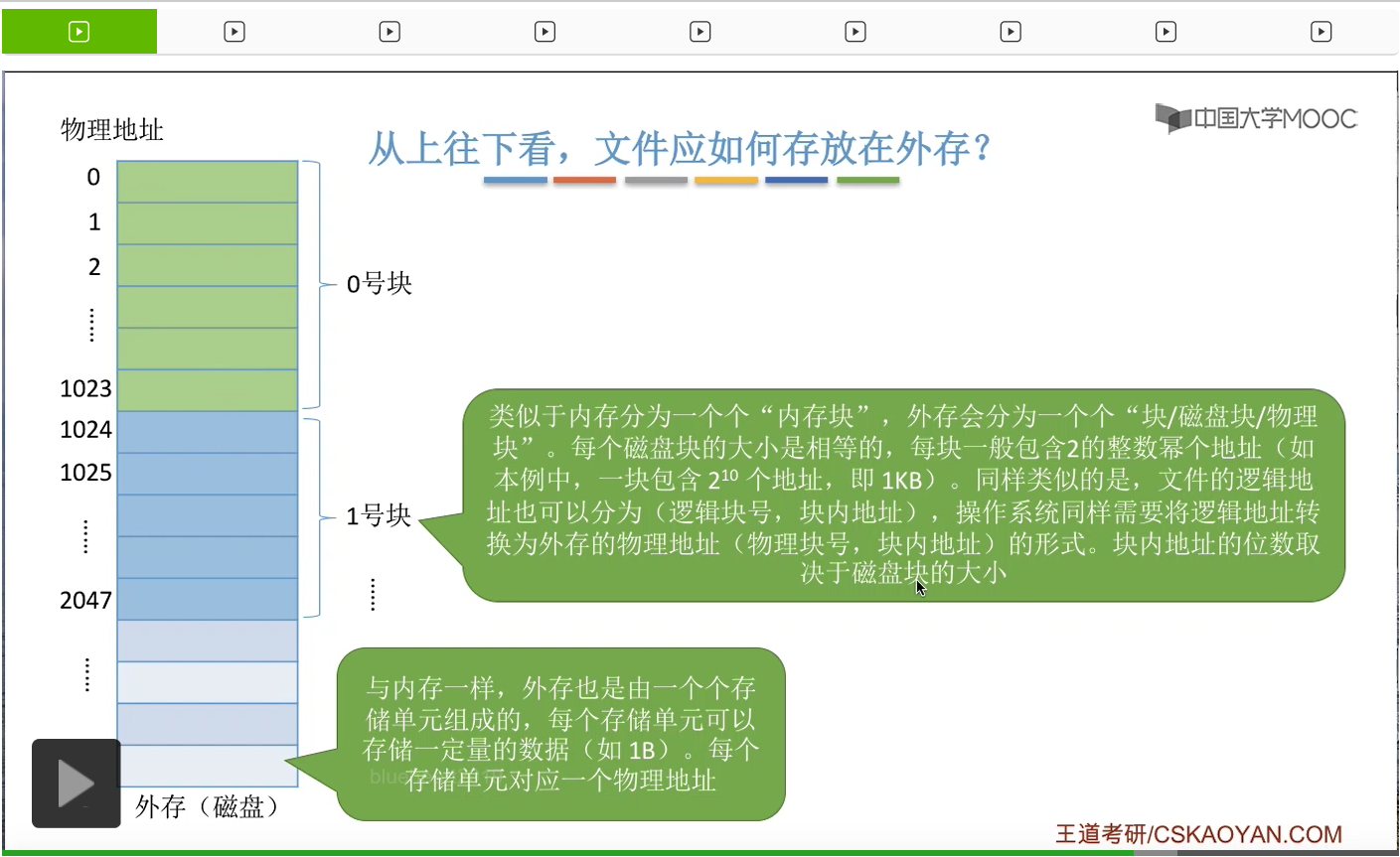
操作系统是以块为单位为各个文件分配存储空间的。所以即使我们的文件大小只有10个字节,但是它依然会占用1整个块也就是1KB的磁盘块。那另外,操作系统在进行读写文件的时候,也是以块为单位进行这种数据交换的。
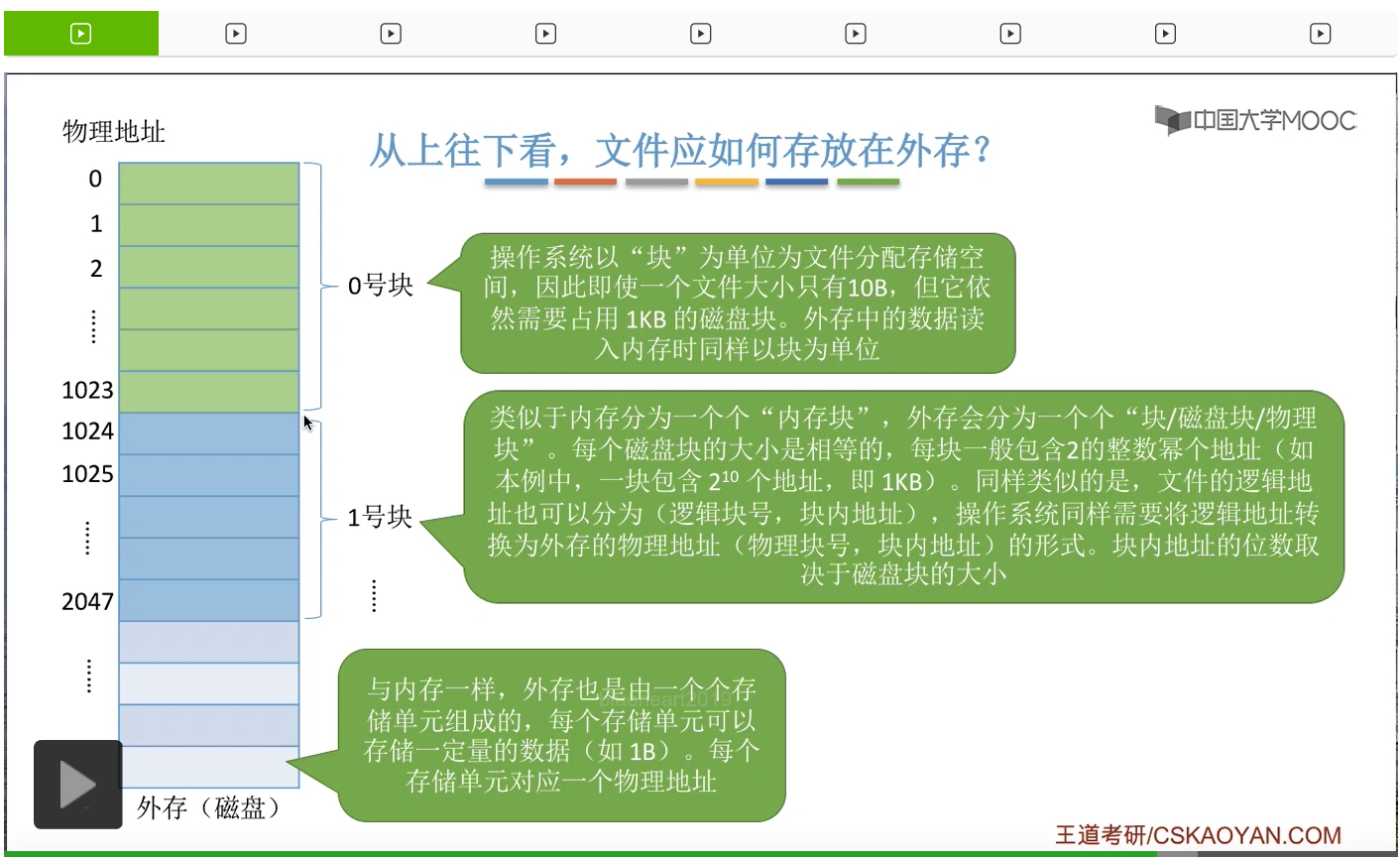
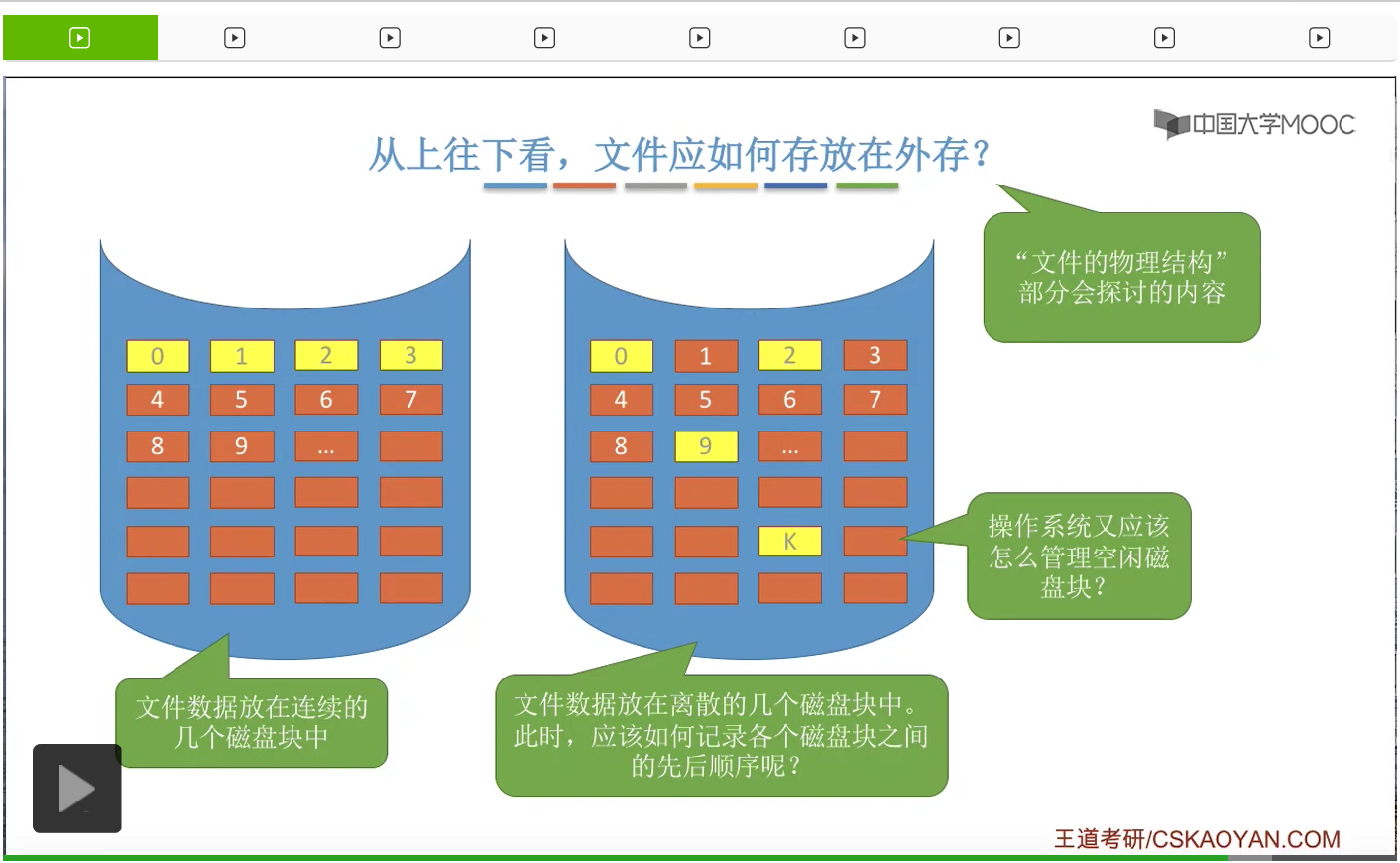
所以通过这个部分的学习我们知道,外存被分为一个一个的磁盘块。那么当文件比较大的时候,是不是应该连续地存放在这些一些相邻的磁盘块当中呢?
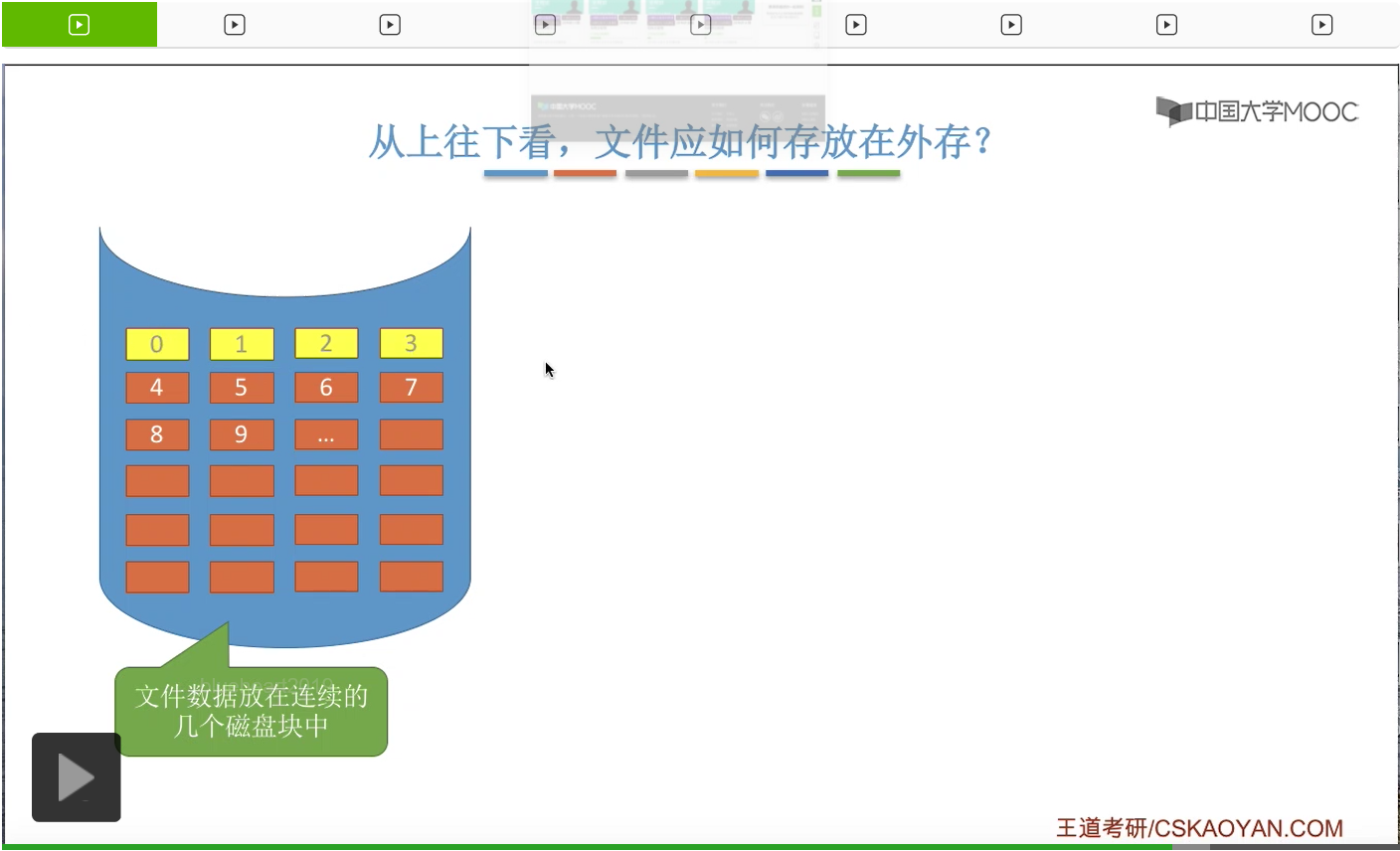
或者能不能找到某一种方法,让文件离散地存放在各个磁盘块当中,然后用某一种方式来记录下这些磁盘块的先后顺序呢?

那这是咱们之后在文件的物理结构那个部分会探讨的内容。那除了分配给文件的这些磁盘块应该怎么组织起来这个问题之外,操作系统还需要关心怎么管理这些空闲的磁盘块,怎么对这些磁盘块进行分配与回收这些问题,那这些都是咱们之后会再展开讲解的问题。所以其实文件的物理结构探讨的是文件这些数据在物理上应该是怎么存放怎么组织的一个问题。而刚才咱们提到的文件的逻辑结构,指的是文件的各个记录在逻辑上应该是什么样的一种组织关系的问题。那这些知识点通过之后的学习大家会有更精细的认识。
那除了咱们刚才探讨的这一系列功能之外,操作系统还需要实现文件的共享还有文件保护这两个比较重要的功能。并且会结合Windows操作系统文件共享还有文件保护的这个实际应用来进行探讨。

文件是一组有意义的信息的集合。另外,对于用户来说,文件名这个属性是特别重要的,还有文件的类型、文件的位置包括文件的这个存放路径还有文件在物理上的存放位置这两个信息都是特别重要的信息。关于文件有哪些属性这个问题建议大家在网上学习累的时候可以自己调试一下自己的电脑,随便找几个文件点开它的属性看一下然后这样的话就可以加深对文件属性相关的一些理解还有记忆。那在之后的讲解当中我们会依次介绍文件的逻辑结构还有目录的实现。另外操作系统对上层提供的一系列的系统调用的功能在背后做了一些什么事情这些都是之后会探讨的内容。那除了逻辑上的结构之外,文件在外存当中是怎么存放的,也就是文件物理结构的问题也十分重要。操作系统又应该怎么对文件的空闲块进行管理,那这是存储空间管理相关的内容。最后我们还会介绍文件共享和文件保护这样两个很重要但是平时咱们很少使用过的功能。其实文件管理的功能离我们生活并不遥远。我们每天都在使用操作系统提供的文件管理的功能。

那其實在數據結構那門課當中也接觸過很多邏輯結構和物理結構的問題。但是對一種邏輯結構來説,也可以用不同的物理結構來實現。那這個文件可以分爲無結構文件和有結構文件兩種。我們需要重點討論的是有結構文件的這幾種邏輯結構。
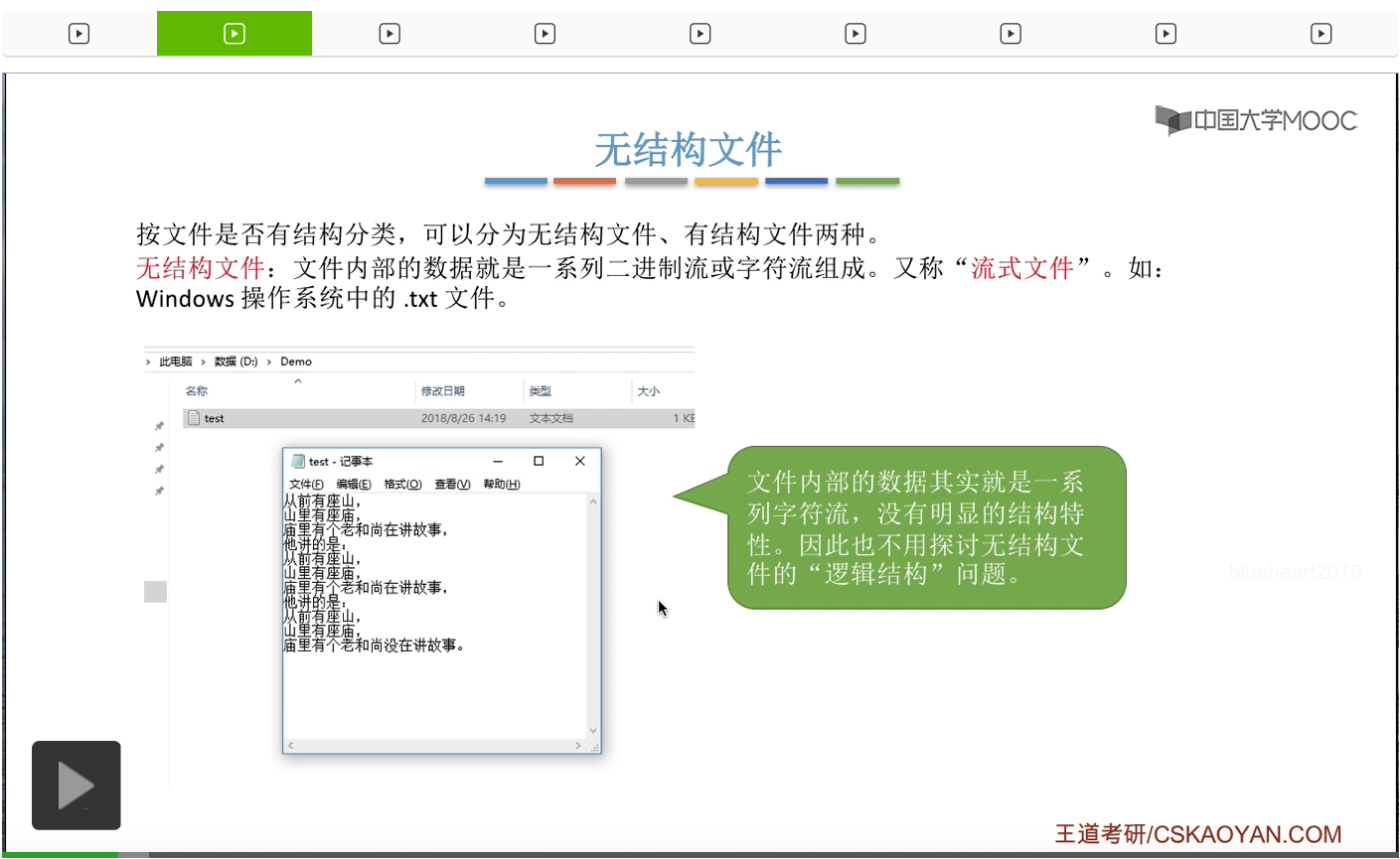
上個小节中我们已经知道,所谓无结构文件它其实就是由一系列的二进制流或者说字符流组成,又称为流式文件。比如说像咱们Windows操作系统里的.txt文件就是一种很典型的无结构文件。那由于这种结构没有很明显的这种结构特性,所以我们也不必要来讨论它的这种逻辑结构的问题。
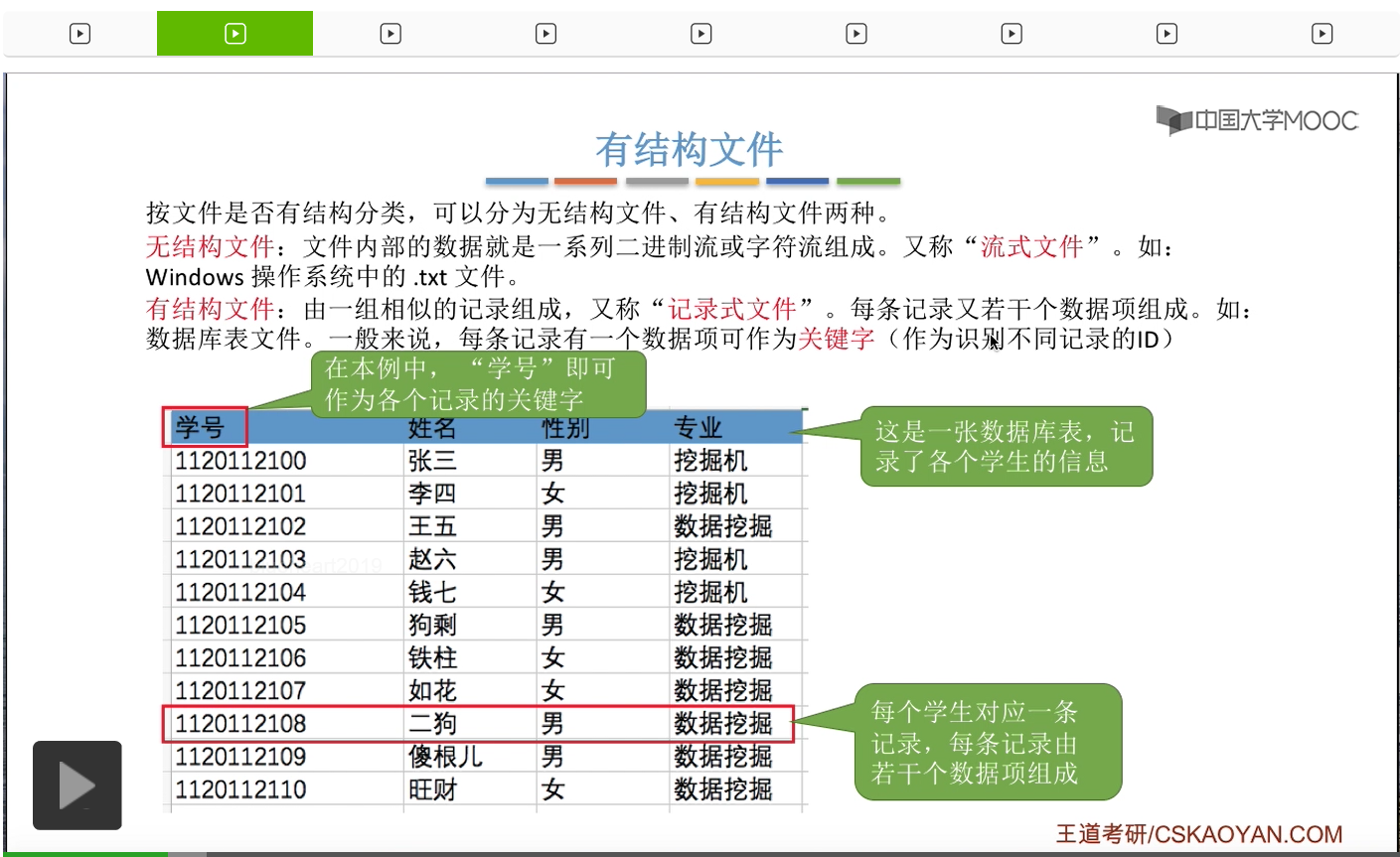
因此我们重点关注的是有结构文件。它由一组相似的记录组成,又称为记录式文件。而每条记录又由若干个数据项组成,比如说像我们的数据库表文件。那一般来说每条记录可以有一个数据项作为关键字。像这个数据库表当中,就可以用学号这个数据项作为关键字来作为识别不同记录的一个ID。那每个学生会对应一条记录,每条记录又由若干个数据项组成。其中的学号可以作为记录的关键字。那这是有结构文件它由一系列的记录组成。
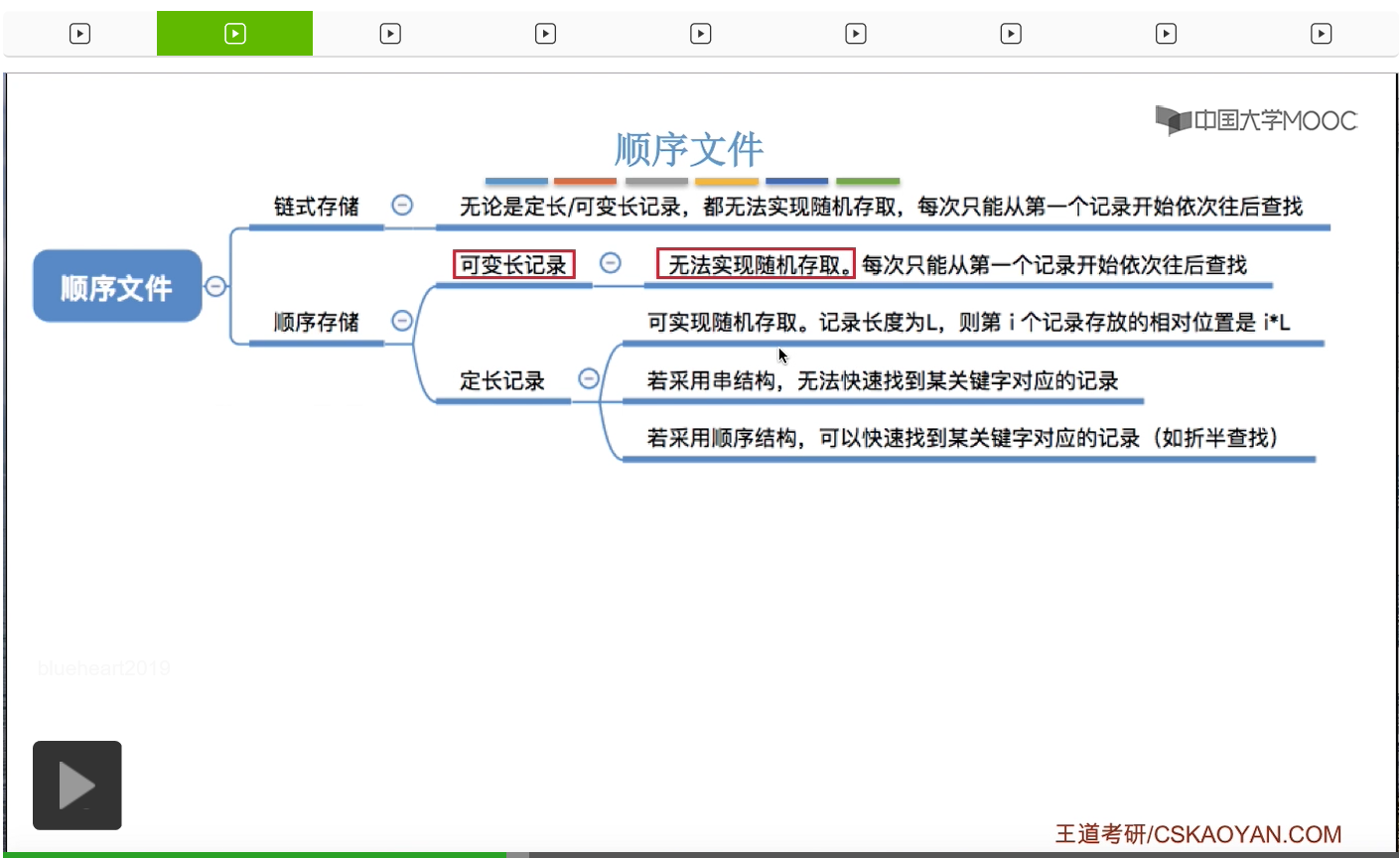
根据各条记录的长度,也就是占用的存储空间是否相等又可以把这些记录分为定长记录和可变长记录两种。

所以既然每一个数据项的长度都相同,那么每一条记录的这个总长度也是相同的,也就是128个字节。并且在定长记录当中,每个数据项在记录当中所处的位置都是相同的。

不过可变长记录的这种有结构文件其实才是咱们生活当中最常见的一种有结构文件。因此由于每个记录的特长这个数据项长度是不确定的,有的特别多,有的又特别少,有的甚至没有。所以像这些记录,它就是一种可变长的记录。那像之前的那个例子当中,专业这个数据项用几个字就可以描述,所以即使我们给各个学生的专业那个数据项分配了总共固定60个字节的这种长度,那即使有存储空间的浪费,也不至于特别明显。但是像这个例子当中,如果我们给每个学生的特长这个数据项都分配一个巨长、巨大的一个存储空间的话,那显然有的学生对这个数据项的存储空间利用是很不充分的。那这样的话就会存储空间利用率极低的一个问题。所以在这个例子当中,最好是让这个有结构文件的这些记录是可变长的记录。

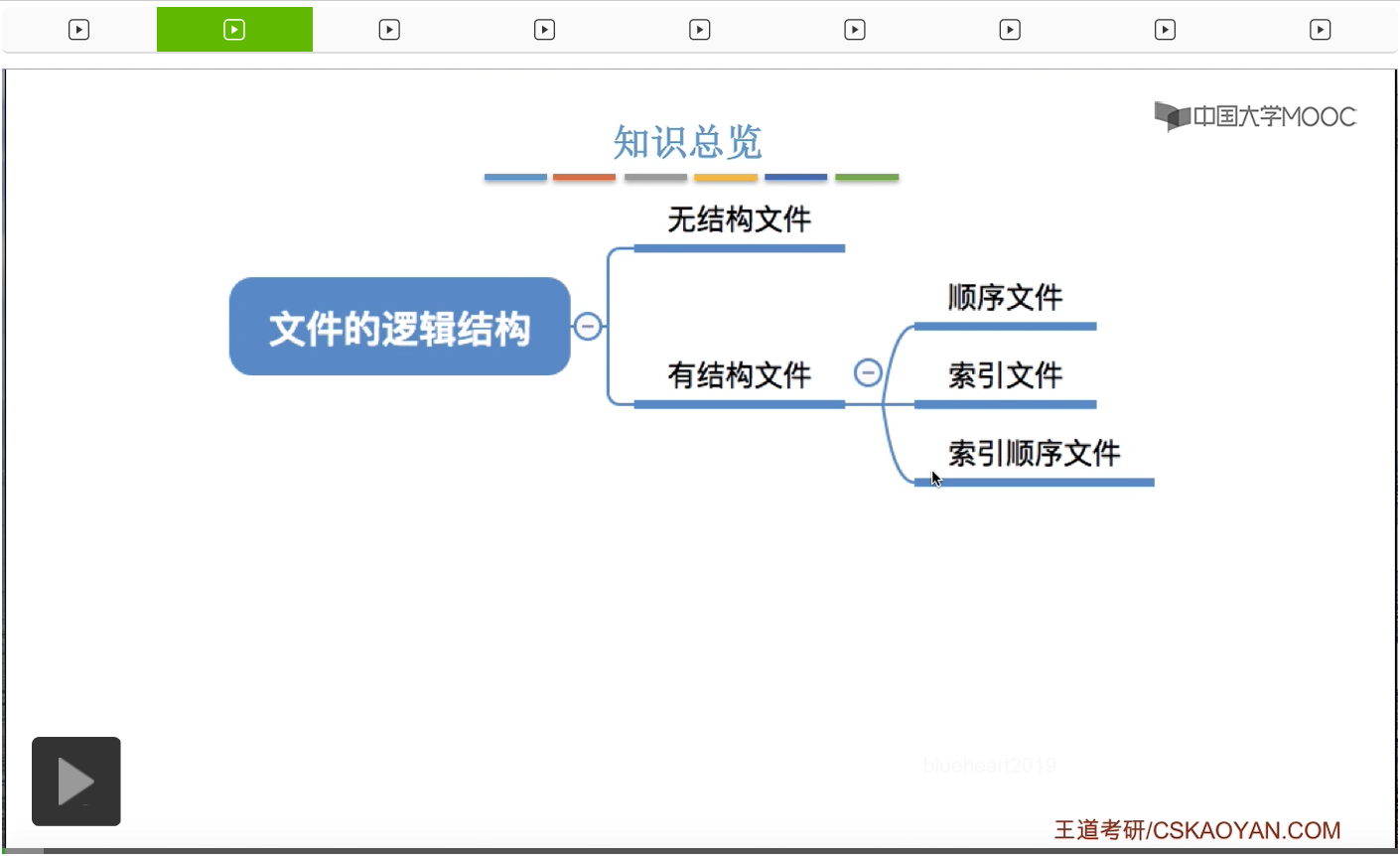
那接下来我们需要再讨论,这些记录应该在逻辑上怎么被组织起来的问题,也就是有结构文件的逻辑结构的问题,分为顺序文件、索引文件和索引顺序文件这三种。

我们首先来看顺序文件这种逻辑结构。如果是顺序文件结构的话,那显然记录到底是定长的还是可变长的,这些记录是否按照关键字有序地排列,另外这些记录在物理上到底是顺序存储还是链式存储,所有的这些区别都会影响顺序文件到底能不能实现某一些操作的功能。
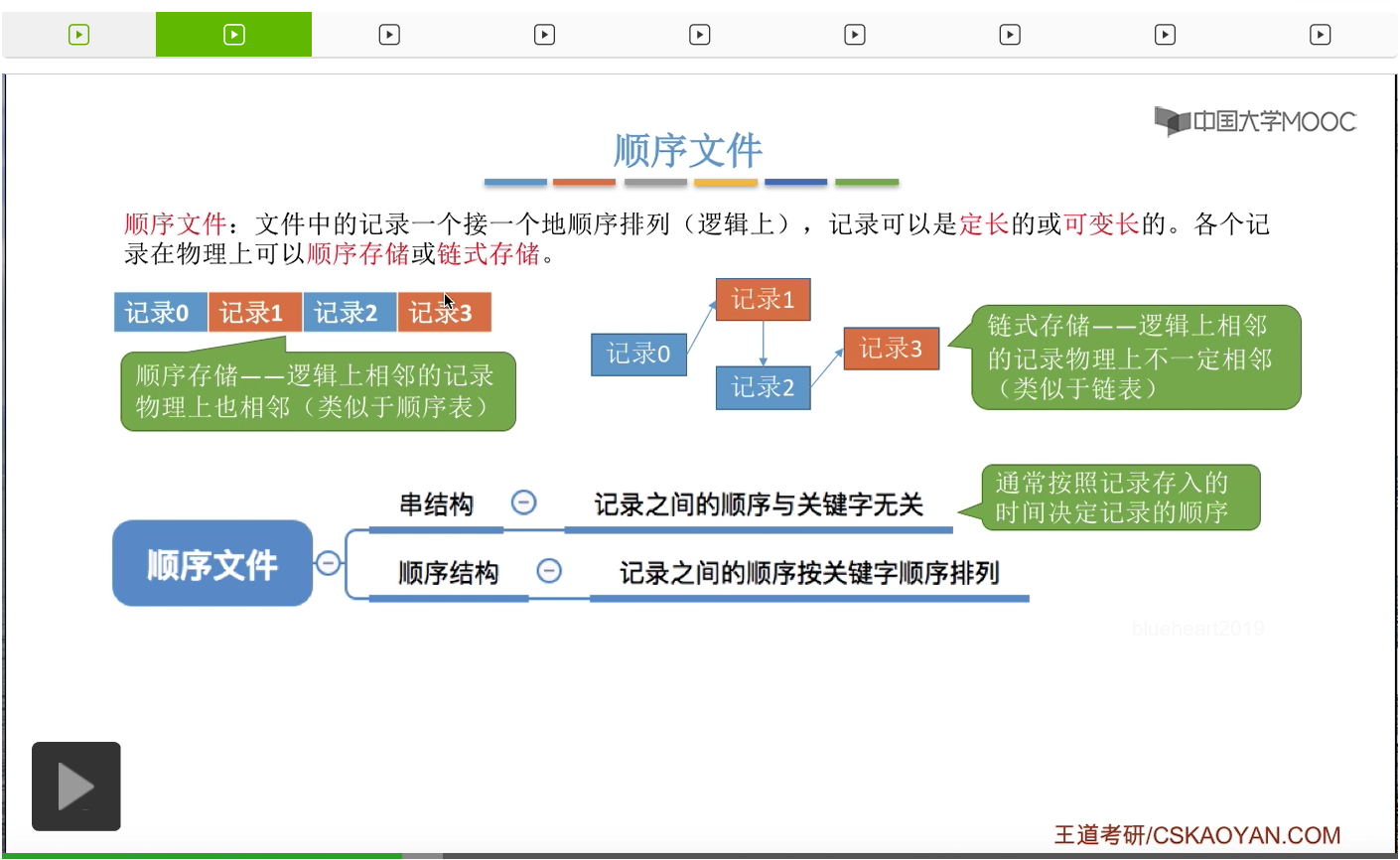
那接下来我们会重点讨论两个问题。也就是说是否能实现这些记录的随机存取、随机访问这件事情呢?

我们直接给出结论。假设一个顺序文件在物理上是采用链式存储的方式来实现的话,那么无论这个顺序文件它是定长记录还是可变长记录,也无论它是串结构还是顺序结构,它肯定都无法实现随机存取。每次只能从第一个记录开始依次往后寻找,那这个和我们的链表很类似。如果我们要在一个链表当中找到某一个元素的话,那么我们每次都只能从链头开始依次往后寻找。因此各个元素之间的存储位置它并没有规律,它都是离散的。所以我们并不能直接计算出某一个元素在物理上的存放地址。因此,如果我们采用的是链式存储的话,那么对这个顺序文件的记录的检索、查询都是不太方便的。那如果说采用的是顺序存储这样的物理结构的话,是不是会有所不同呢。假设采用的是顺序存储的物理结构,并且这个文件是可变长记录的文件,那它依然是无法实现随机存取的,每次只能从第一个记录开始依次往后查找。
来看一下为什么。由于这个文件的记录是可变长的,也就是每个记录的长度不一样,所以必须在每个记录之前用一定的存储空间来表示这个记录的长度。
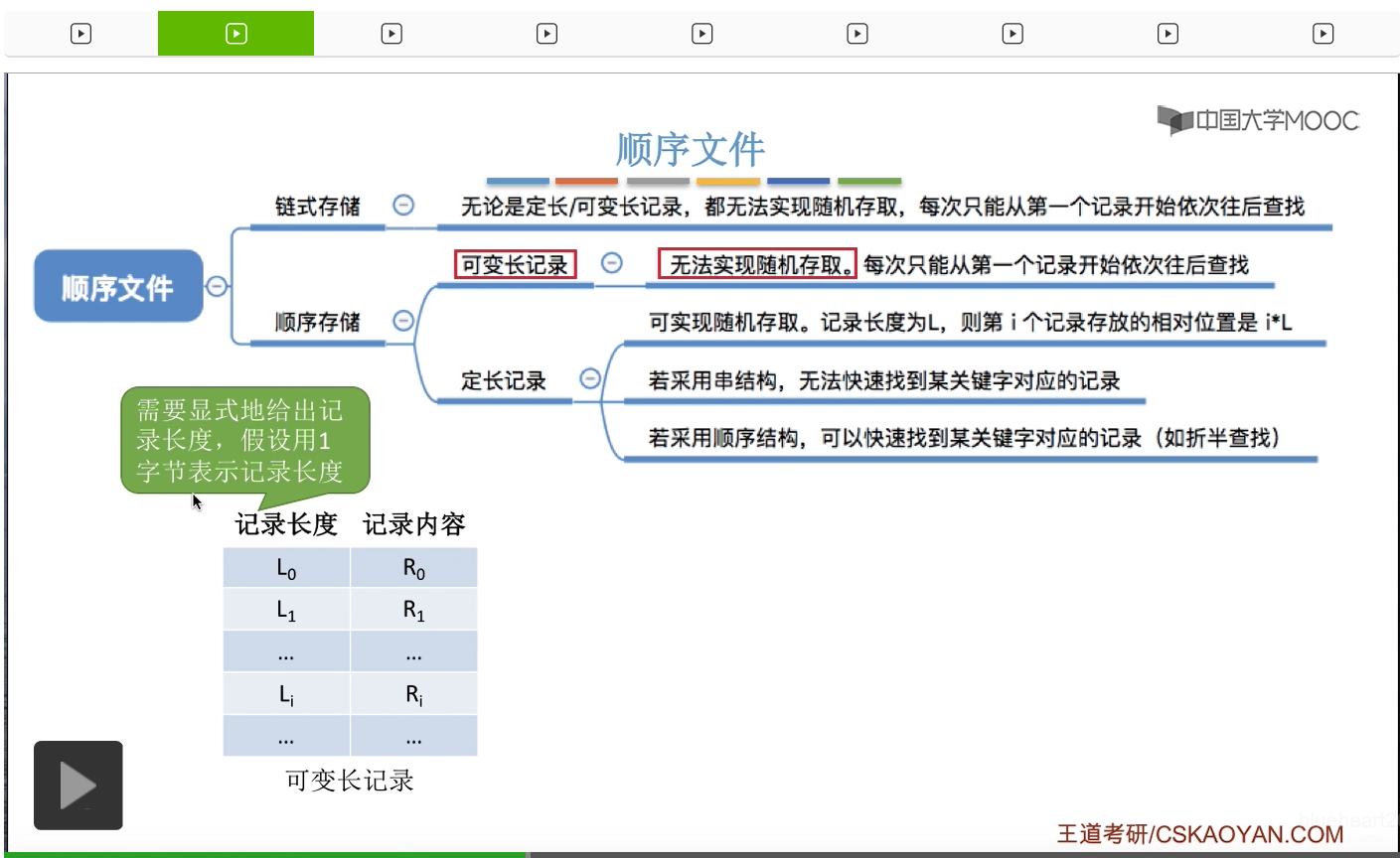
假设这个记录长度可以用一个字节来表示,那第0条记录它的逻辑地址是0,第2条记录就应该是第0条记录的长度L0再加上它的这个记录长度这个字段占用的字节数1个字节,所以L0+1这是第一个记录对应的逻辑地址。那相应的应该是之前所有的这些记录的长度之和再加上所有的这些记录的这个长度字段所占用的字节,每一个占用1个字节。那前面总共有i个记录的话,总共就会占用i个字节。所以由于这个文件中的记录是可变长的,L0、L1、L2这些数据并不会呈现出某种规律性。因此我们想要找到某一条记录对应的地址的话,那么只能从第一条记录开始依次往后寻找。因此,如果说这个文件是可变长记录的文件,那么即使它采用了顺序存储的这种方式,依然无法实现随机存取。
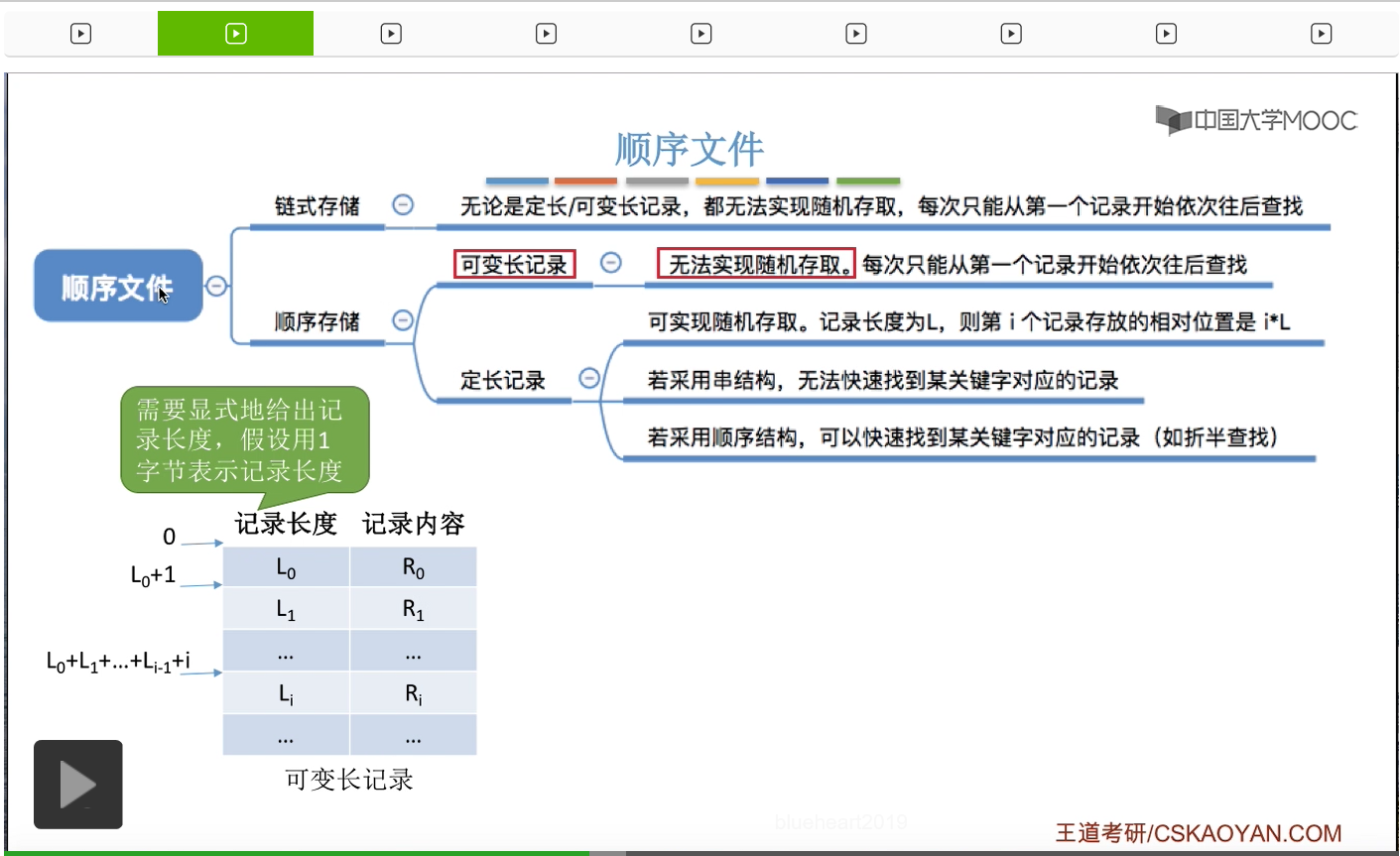
那如果说这个文件是一个定长记录的顺序文件,并且在物理上是采用顺序存储的方式的话,情况就不一样了。这就可以实现随机存取。假设每个记录的长度固定为L,并且这些记录在物理上是顺序存储的,那就意味着各个逻辑上相邻的记录在物理上也是相邻地存储的,所以第0号记录的这个逻辑地址为0的话,那么i号记录的逻辑地址直接可以用i*L就可以直接得到。因此如果是定长记录的顺序文件,并且在物理上也是顺序存储的话,那么是可以实现随机存取的功能的。那么如果说这个顺序文件是串结构,也就是说这些记录的顺序和它们的关键字顺序是没有关系的话,那么这就无法快速地找到某个关键字对应的记录。因为它并不是按关键字的顺序来排列的,所以我们每次只能从头开始依次往后遍历地寻找这个关键字对应的记录。但是如果说这个定长记录的顺序文件采用的是顺序结构的话,那么也就意味着这些记录是按照关键字的顺序来排列的。那这样的话我们就可以用像折半查找啊之类的一些方法来快速地找到某一个关键字对应的记录。

那到这个地方我们就回答了之前提出的两个问题,关于是否可以实现对各个记录的随机存取这件事,我们得出的结论是,如果说物理上采用的是链式存储,那么肯定是无法实现记录的随机存取的。而如果说物理上采用的是顺序存储的话,那么可变长记录的顺序文件是无法实现随机存取的。而定长记录的这个顺序文件是可以实现随机存取的。如果说在这个基础上,再能保证这个定长记录的顺序文件它是一种顺序结构,也就是按照关键字的顺序来排列的话,那么我们就可以实现快速地检索某一个记录的这个功能。

那一般来说考题当中所指的顺序文件,默认的是指这个物理上采用顺序存储的这种顺序文件,所以我们不需要考虑各个记录链式存储的这种情况。在之后我们的讲解当中,再提到顺序文件的时候,也是默认如此。那显然,在顺序表那种数据结构当中,要增加或者删除一个元素是比较困难的。

同样的,如果采用的是顺序存储的这种结构的话,那么它要删除或者增加一个记录也是比较困难的。不过如果采用的是串结构的话,那么由于不需要保证各个记录按照关键字来排序,因此,对于串结构的这个顺序文件来说,增加和删除一个记录相对来说要简单一些。我们只需要很简单地把要增加的那个记录插到这个文件的末尾就可以了。那在实际应用当中,为了减少磁盘的I/O次数,一般来说系统、操作系统会管理一个日志文件,用这个日志文件来记录对于这个文件当中的各个记录进行修改的一些信息。然后每隔一段比较长的时间,再把这些信息统一地合并到外存当中的这个文件数据当中。比如说每隔一个小时才合并一次,或者说每隔十分钟才合并一次,那这样的话就可以减少对于顺序存储的顺序文件进行增删改所带来的一些开销了。不过这个知识点只是简单地提一提,在考试当中并不会进行考查。那以上的这些内容是顺序文件这种逻辑结构当中需要特别注意的一些知识点。特别是定长记录可以实现随机存取,而可变长记录不可以实现随机存取这两件事。

接下来我们再来看第二种逻辑结构,索引文件。通过之前的讲解我们知道,如果说一个顺序文件它是可变长记录的话,那么要找到第i个记录就必须先顺序地查找前面的i-1个记录。但是在实际生活当中,又有很多应用场景又必须使用可变长记录。能不能解决可变长记录的这种查找速度慢的问题呢?能否让可变长记录的文件也实现可以随机访问的这个功能呢?基于这个需求,人们提出了索引文件这种逻辑结构。

每一个文件会建立一张索引表。

并且每一个索引表的表项会对应这个文件的一条记录,文件的这些记录在物理上不需要连续存放。但是索引表的各个表项在物理上是需要连续存放的。另外,每一个索引表的表项的这个大小都是相等的。比如说,索引号、长度、指针这三个字段分别占4个字节,那么1个索引表的表项总共就需要占12字节的长度。
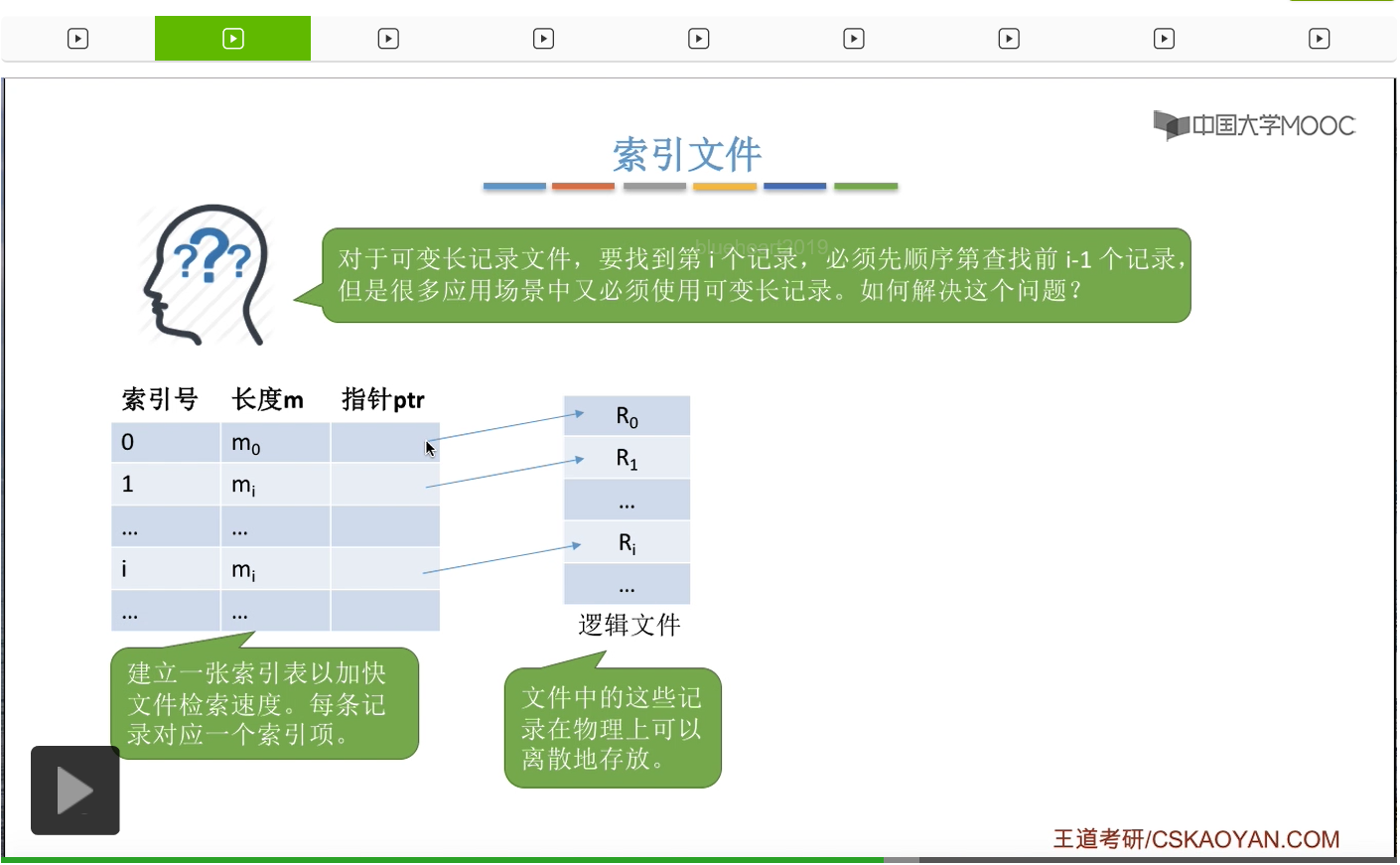
因此索引表本身也可以理解成是一种定长记录的顺序文件。那经过之前的讲解我们也知道,定长记录的顺序文件是可以支持随机访问的,所以我们可以快速地找到第i个记录对应的索引表项到底是存放在什么地方。

另外呢,如果我们把这个关键字作为索引号的内容,并且让索引表当中的这些表项按照关键字的顺序来排列的话,那么我们就可以让这个索引文件支持折半查找。这样的话就可以大幅度地提升索引文件的检索速度。
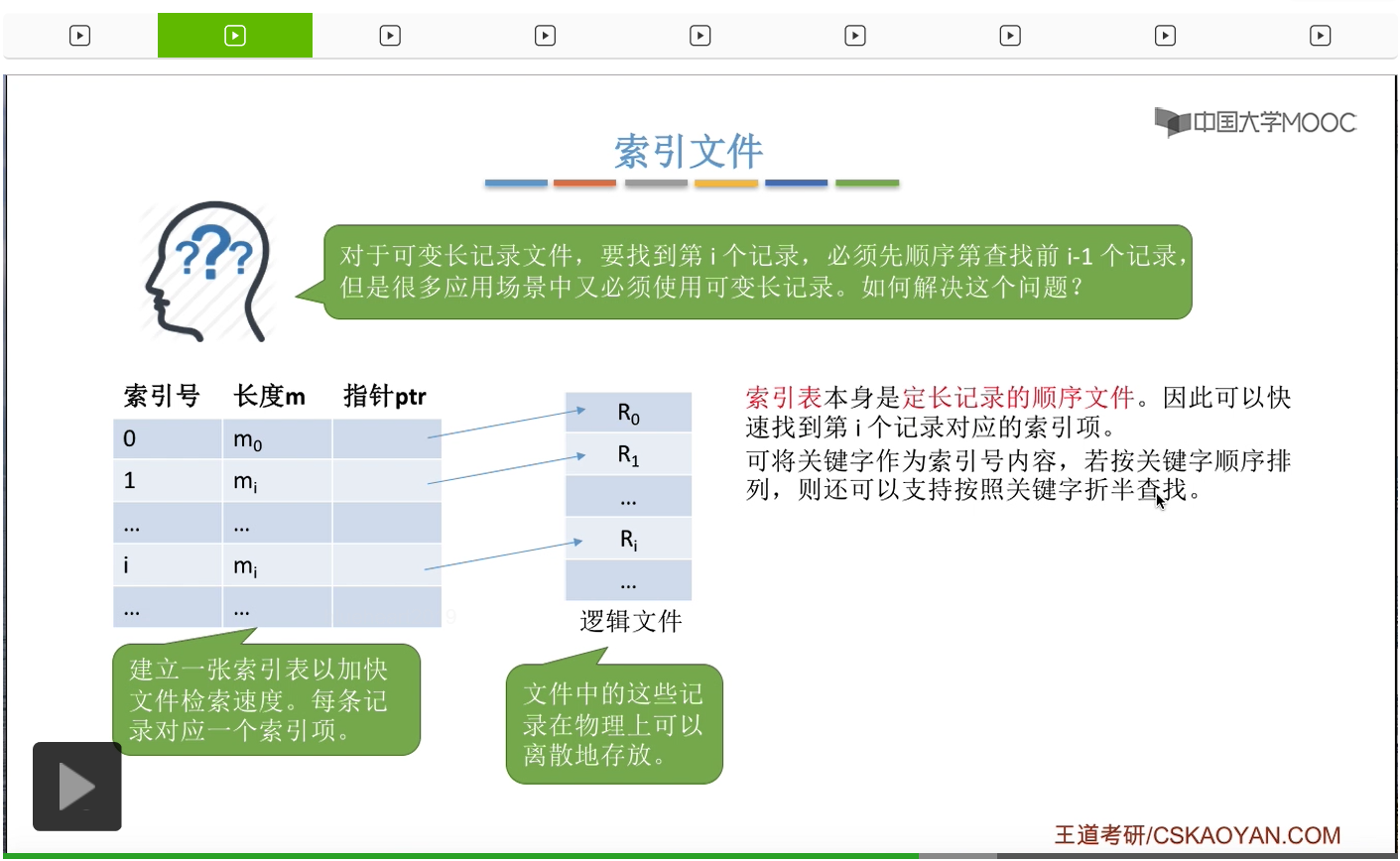
不过既然每一个文件的记录会对应一个索引表项,那么我们要增加或者删除一个记录的时候,当然也需要把对应的这个表项进行相应的处理。那要增加一个记录的时候,也需要增加一个相应的索引表项。要删除一个记录的时候,也需要把它对应的这个索引表项也给删除。那通过之前的讲解我们发现,索引文件这种逻辑结构可以支持很快的检索速度,所以这种逻辑结构主要是用在对于信息处理的及时性要求很高的那种场合。
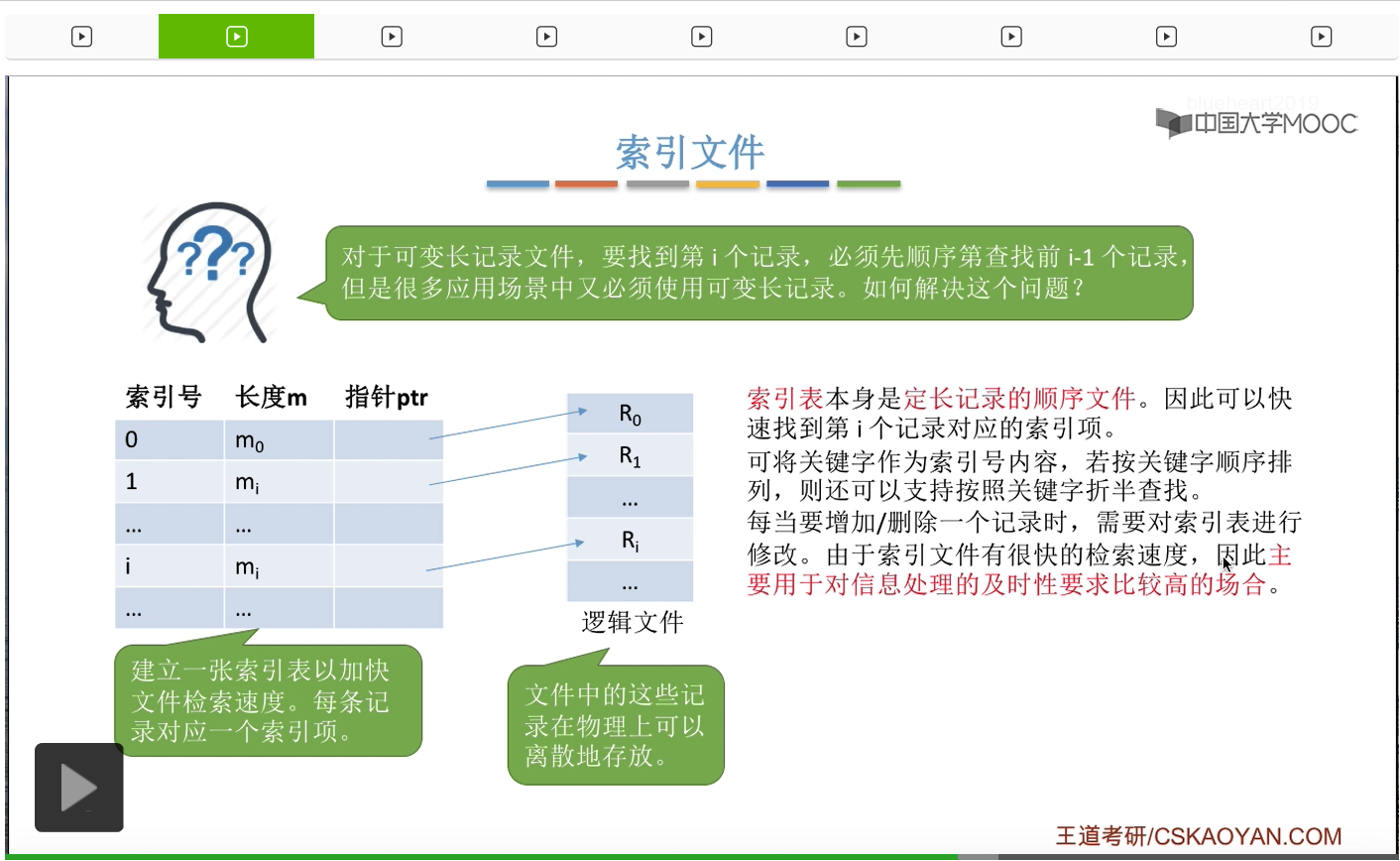
另外呢,除了用这个关键字作为索引号之外,我们还可以用别的不同的数据项作为索引号来为一个文件建立多个索引表。如果学过数据库的同学就知道,在SQL语言当中,就可以用一条SQL语句就完成为某一个字段建立一张索引表的这个功能了。那这是索引文件。
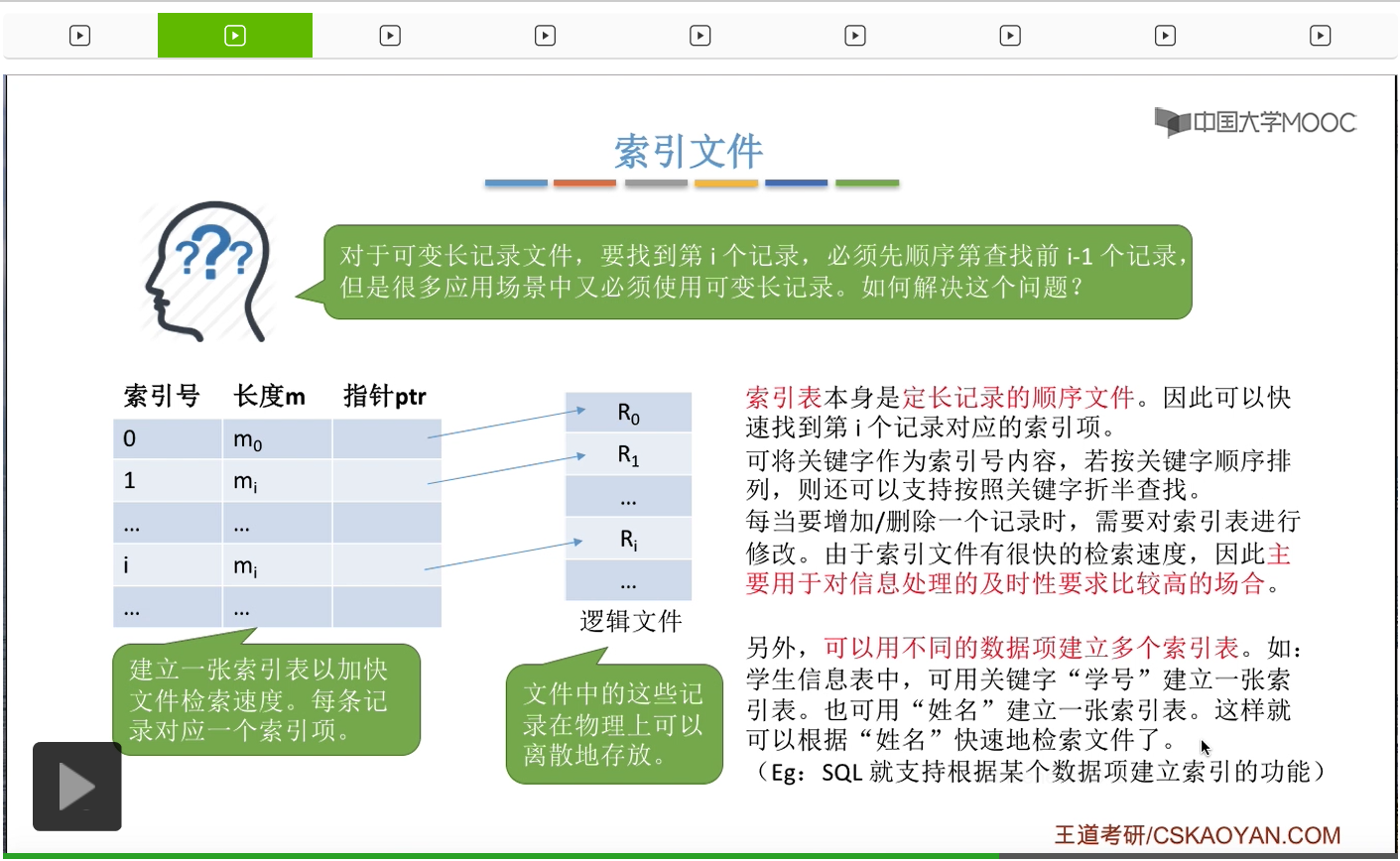
接下来我们再来看最后一种逻辑结构————索引顺序文件。索引顺序文件它是一种索引文件和顺序文件思想的结合。与索引文件类似的是,索引顺序文件当中同样会为一个文件建立一张索引表。但是与索引文件不同的是,

索引顺序文件当中,并不会为每一个记录建立一个对应的索引表项。而是会给这些记录进行分组,然后每一个分组对应一个索引表项。

比如说在这个例子当中,就是按照学生的姓氏把学生记录进行了一个分组,

然后每一个分组会对应一个索引顺序文件的索引项,每一个索引项记录了这个分组的名字还有这个分组存放的一个位置。那从这个地方可以看到,索引顺序文件的索引项并不需要按照关键字的顺序来排列,那这样的话是可以更方便我们对新表项的插入操作的。也就是说索引顺序文件的索引表它其实是一个定长记录的串结构的顺序文件。另外,这样的一个分组就是一个顺序文件。那可以看到,采用索引顺序文件这种逻辑结构之后,索引表的表项是少了很多的。

所以我们完成了刚才提出的那个需求,也就是对索引表进行了瘦身、减肥的工作。那如果采用这样的策略的话,会不会出现检索速度慢的问题呢?

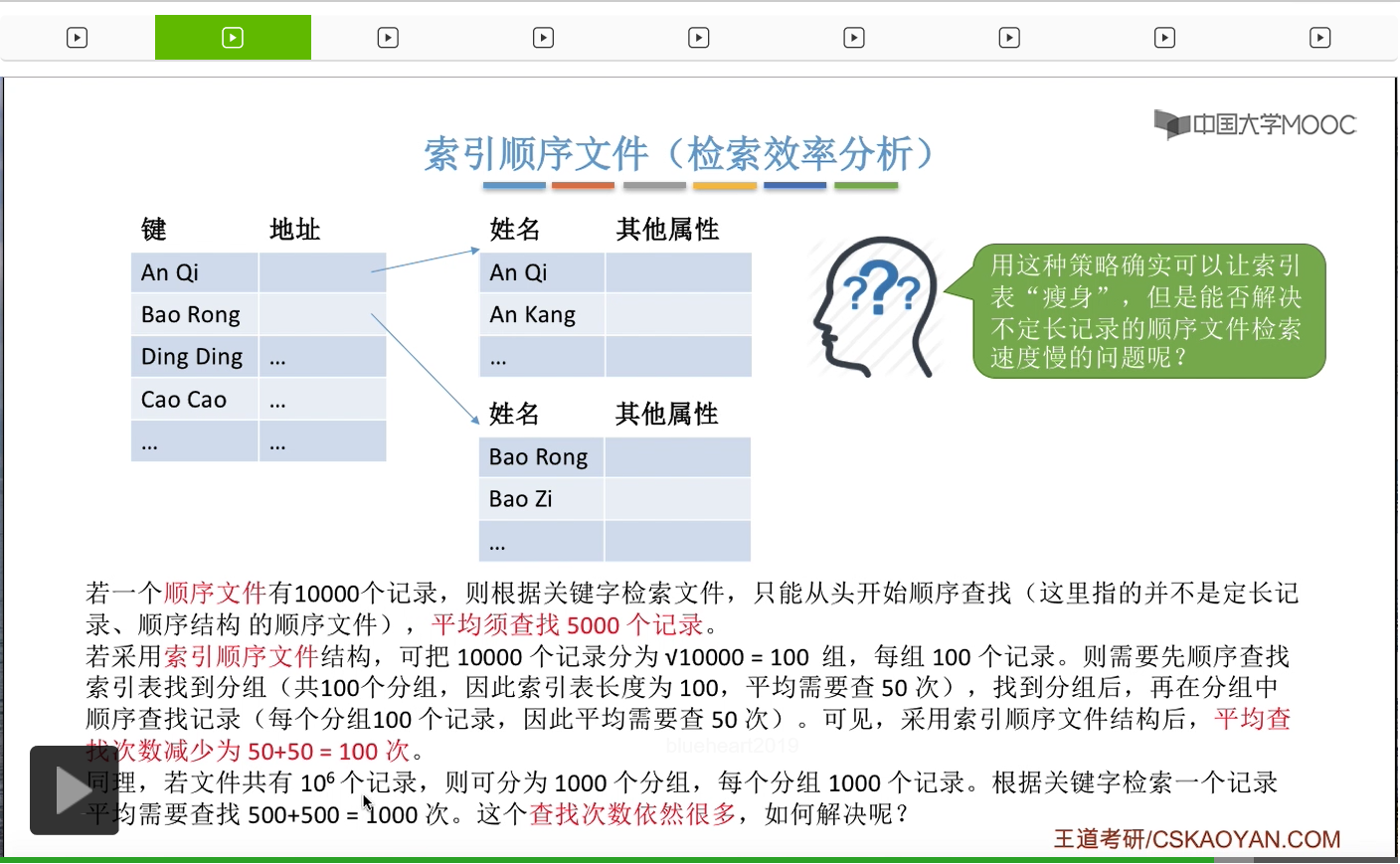
我们来分析一下。那我们要找到这个关键字对应的记录的话,就平均需要查找5000个记录。

但是如果我们把这个文件改造成这种索引顺序文件的这种逻辑结构的话,我们可以把这10000个记录平均分为100组,然后每组100个记录。这样的话我们要查询某一个关键字对应的记录,首先是需要顺序地查找这个索引表,找到这个关键字对应的那个分组,那由于这个索引表只有100个索引项,因此平均只需要查找50次就可以找到一个关键字对应的分组了。那相应的,找到了它对应的分组之后,在这个分组内有100个记录,因此接下来我们需要顺序地查找这100个记录,那平均只需要查找50次就可以找到这个关键字对应的记录存放的位置了。所以其实采用了这种索引顺序文件结构之后,平均的查找次数就减少为了50+50,总共100次。因此这种逻辑结构也是具有比较好的检索性能的。

那同样的道理,如果说一个文件有10^6个记录,那我们可以把它分为1000组,每个分组是1000条记录,根据关键字来检索一个记录,就平均需要500+500总共1000次查询。那这1000次其实查找的次数依然是很多的,那怎么解决这个问题呢?
那我们可以建立多级索引。对于刚才所说的这个例子来说,我们可以为这个文件先建立一张低级索引表,那每一个索引表对应100个表项,每一个表项又对应一个分组,每一个分组当中又是100个记录。那不难算出,我们总共会有100张低级索引表。因此,我们又可以为这100张低级索引表再建立一个顶级的索引表,这样的话就形成了两级索引顺序文件。那顶级索引表中总共有100个表项,低级索引表中每个索引表中也是有100个表项,那每一个表项又会对应一个分组,每一个分组中又会有100个记录。
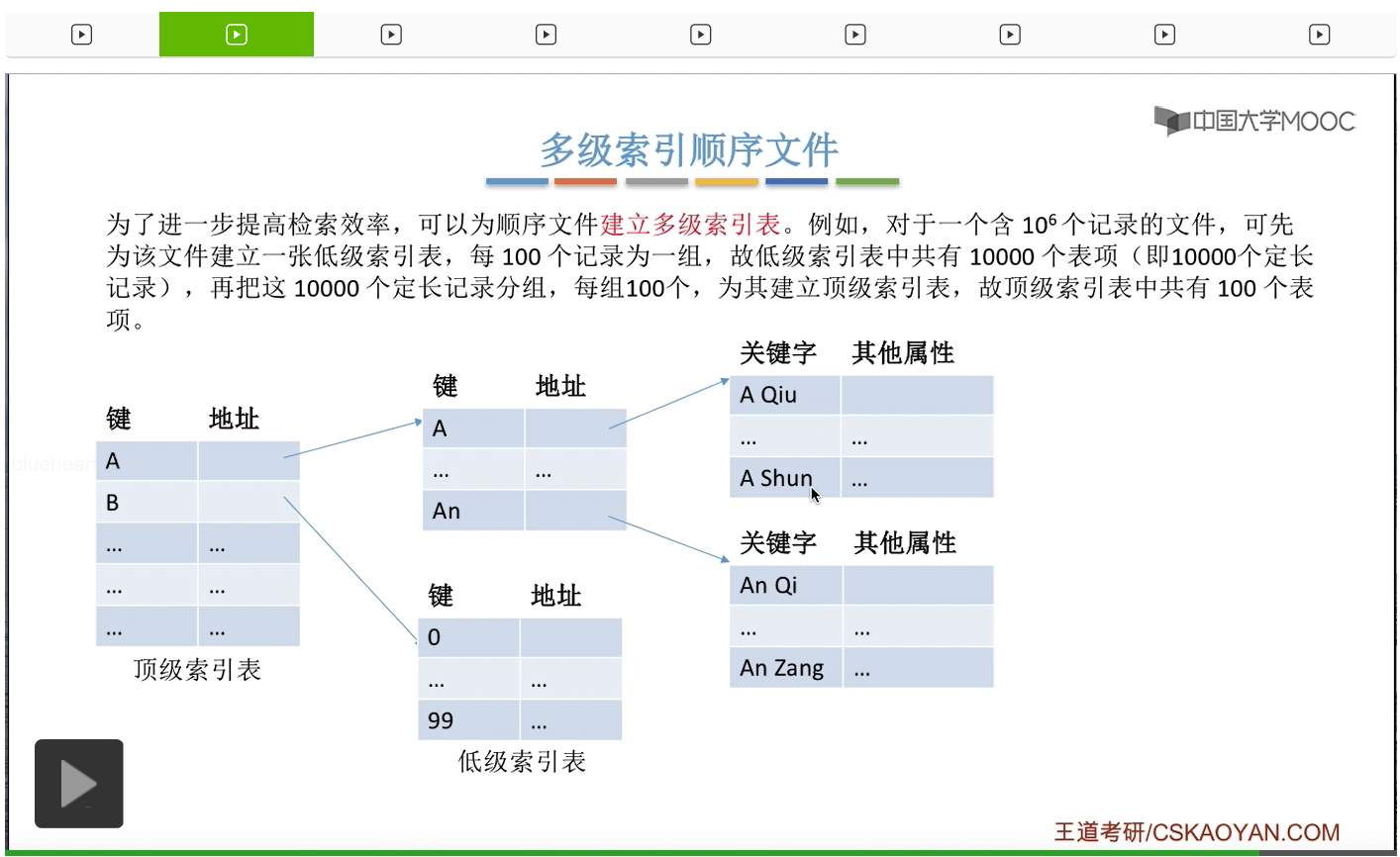
因此,如果我们按照这样分组的话,那根据一个关键字来检索一个记录平均需要查找的次数就是150次。

无结构文件由二进制流或者字符流组成,没有明显的逻辑结构,所以这个地方我们不展开探讨。我们需要重点掌握的是有结构文件的这几种逻辑结构,分为顺序文件、索引文件和索引顺序文件。而有结构文件它是由记录组成的,分为定长记录和可变长记录。
那我们在考试中遇到的所谓的顺序文件,指的是默认各个记录在物理上顺序存储的这种物理结构。

需要重点注意的是,对于可变长记录的顺序文件来说,它是无法实现随机存取的,但是定长记录可以。可变长记录的顺序文件每一次在查询的时候只能从头开始依次往后查找。

第二个需要注意的点是定长记录、顺序结构的顺序文件可以快速检索。所谓的顺序结构就是指这些记录按照关键字的顺序依次排列。所以由于这些记录排列的顺序是有规律可循的,因此我们可以用像折半查找之类的方法来快速地找到一个关键字对应的记录。

那在索引文件这种逻辑结构中我们需要注意的是,索引表本身就是一种定长记录的顺序文件。

而如果说索引表按照关键字的顺序排列,那它同样也可以像之前所说的这样支持快速检索的功能,也就是根据某一个关键字来快速找到某一个记录的功能。那由于快速检索的这个功能和特性,因此索引文件也经常被使用在那些对于检索速度要求很高的那些场景当中。

那在最后我们介绍的索引顺序文件当中,除了要理解它的这一些原理之外,我们还需要会动手计算平均查找次数。

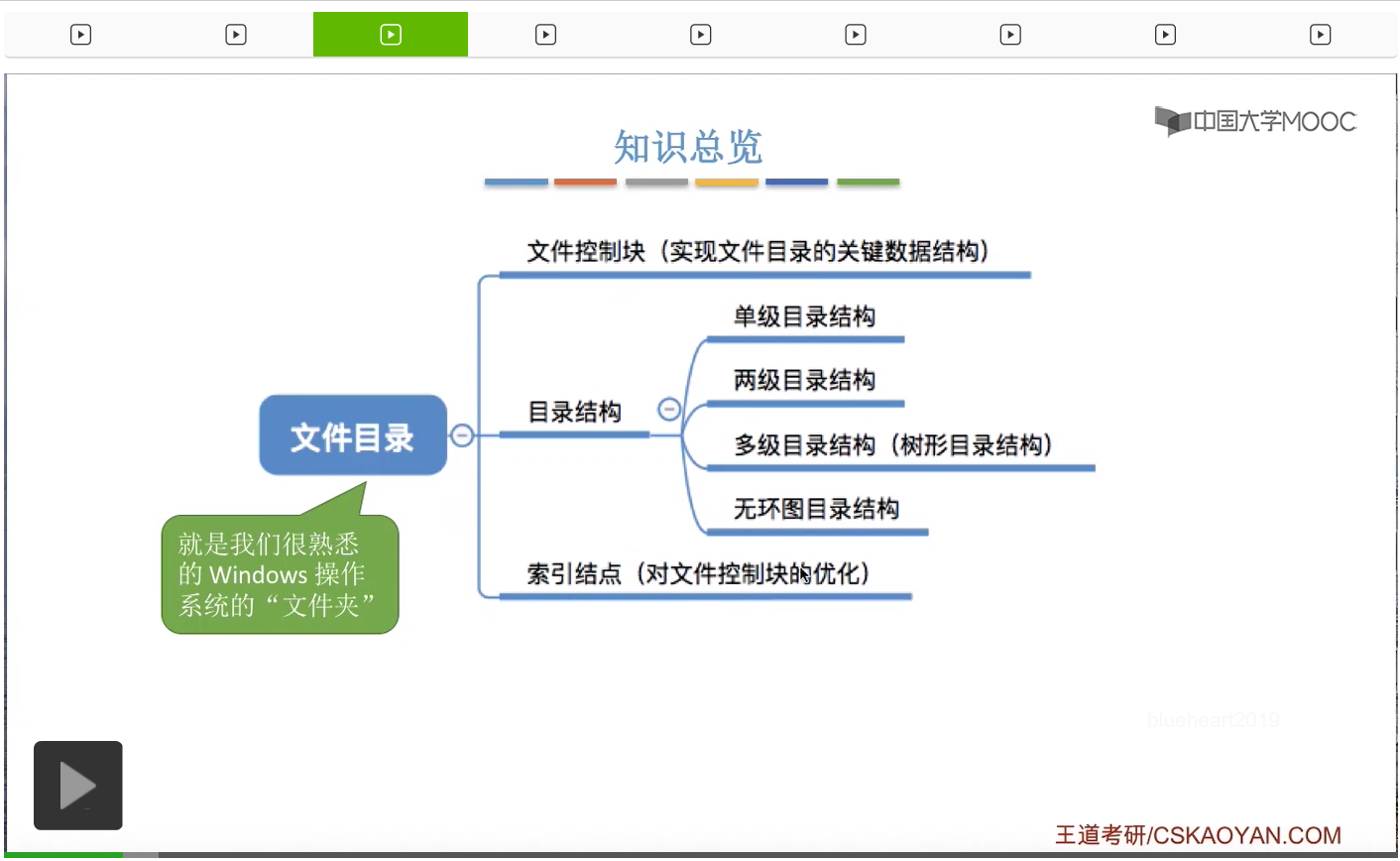
文件目录这个特别重要的知识点。

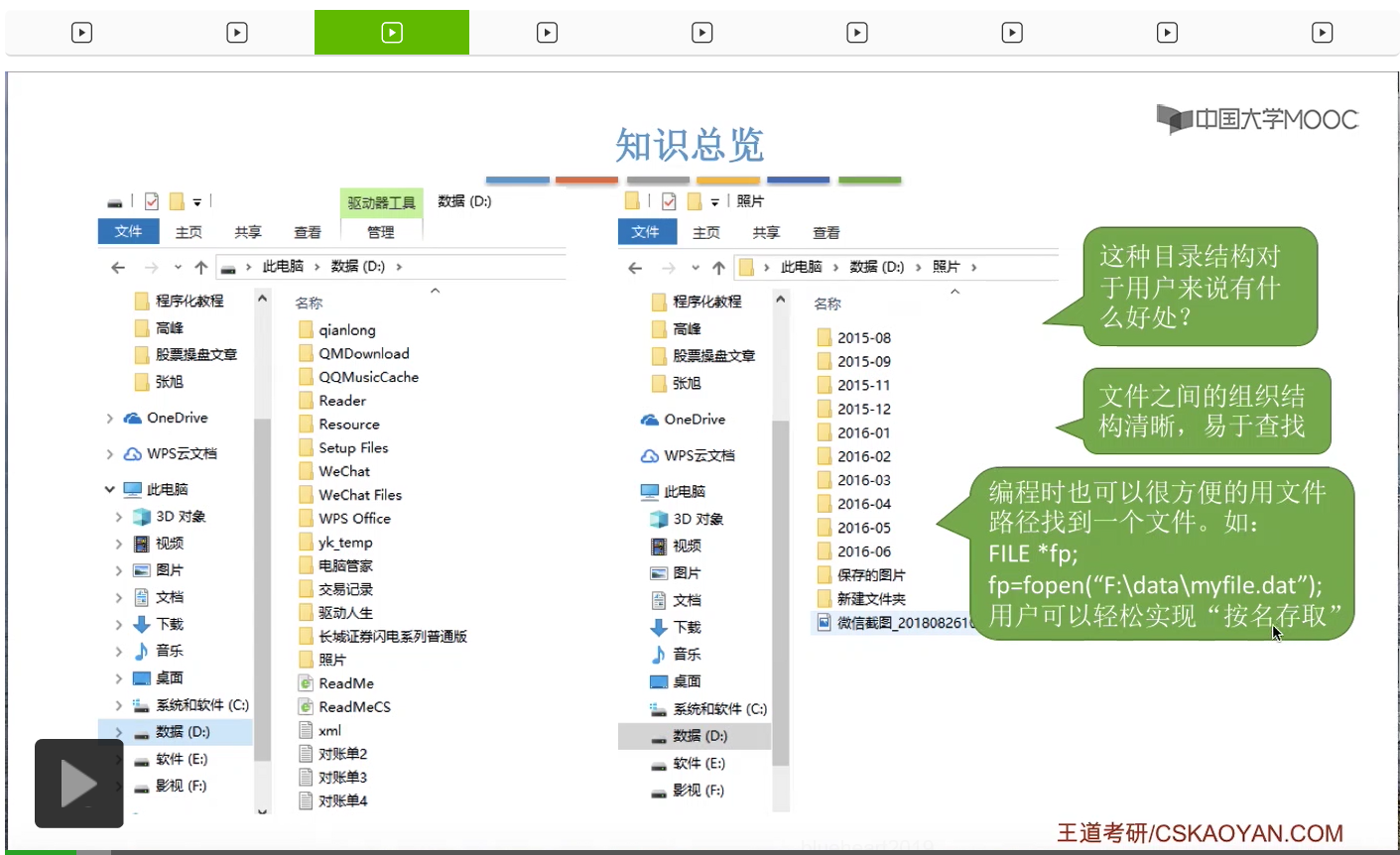
对文件目录的使用其实是很频繁的。比如说像Windows操作系统,我们随便打开一个逻辑磁盘,比如说D盘,里面就有很多各种各样的文件夹或者文件目录,并且在这个D盘下面它也会有一系列的普通的文件。那打开其中的某一个文件夹、文件目录之后,里面还会有更深一级的文件目录还有一些普通的文件。那像这种一层一层的目录结构,对于我们用户来说有什么好处呢?可以使整个文件的存放组织结构非常清晰,易于我们查找。另外,如果有编程经验的同学,应该也写过操作文件相关的一些函数。比如说像打开文件这个操作,它其实就是用我们提供的文件路径名作为参数,然后根据这个路径一层一层往下去找到我们想要让这个程序控制的那个文件的。所以采用这样的目录结构的话,可以让用户很轻松地实现按名存取这件事情。
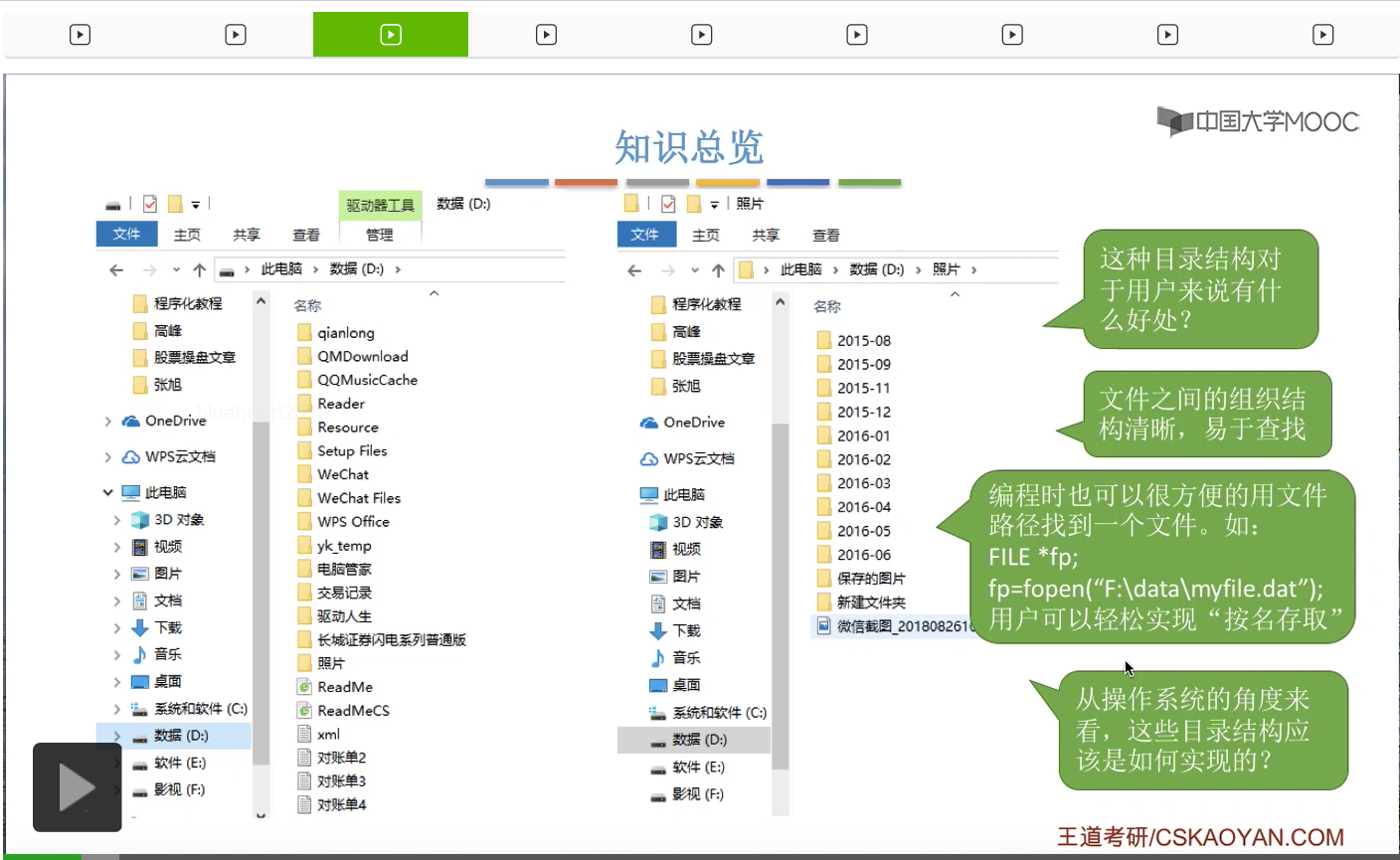
其实就是用一个所谓的目录表来表示这个目录下面它存放了哪些东西。那在D盘当中的每一个文件,每一个文件夹都会对应这个目录表当中的一个表项。
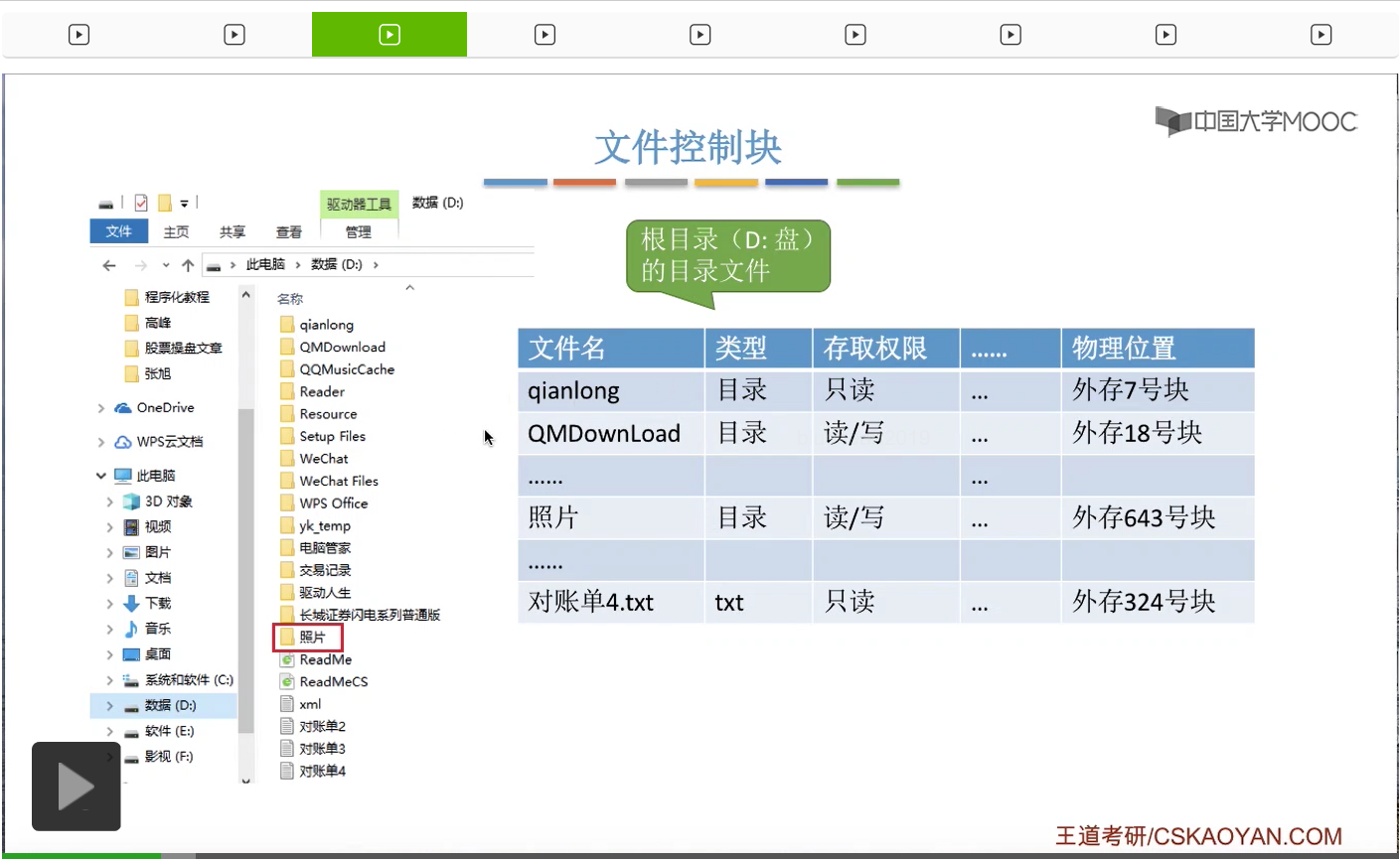
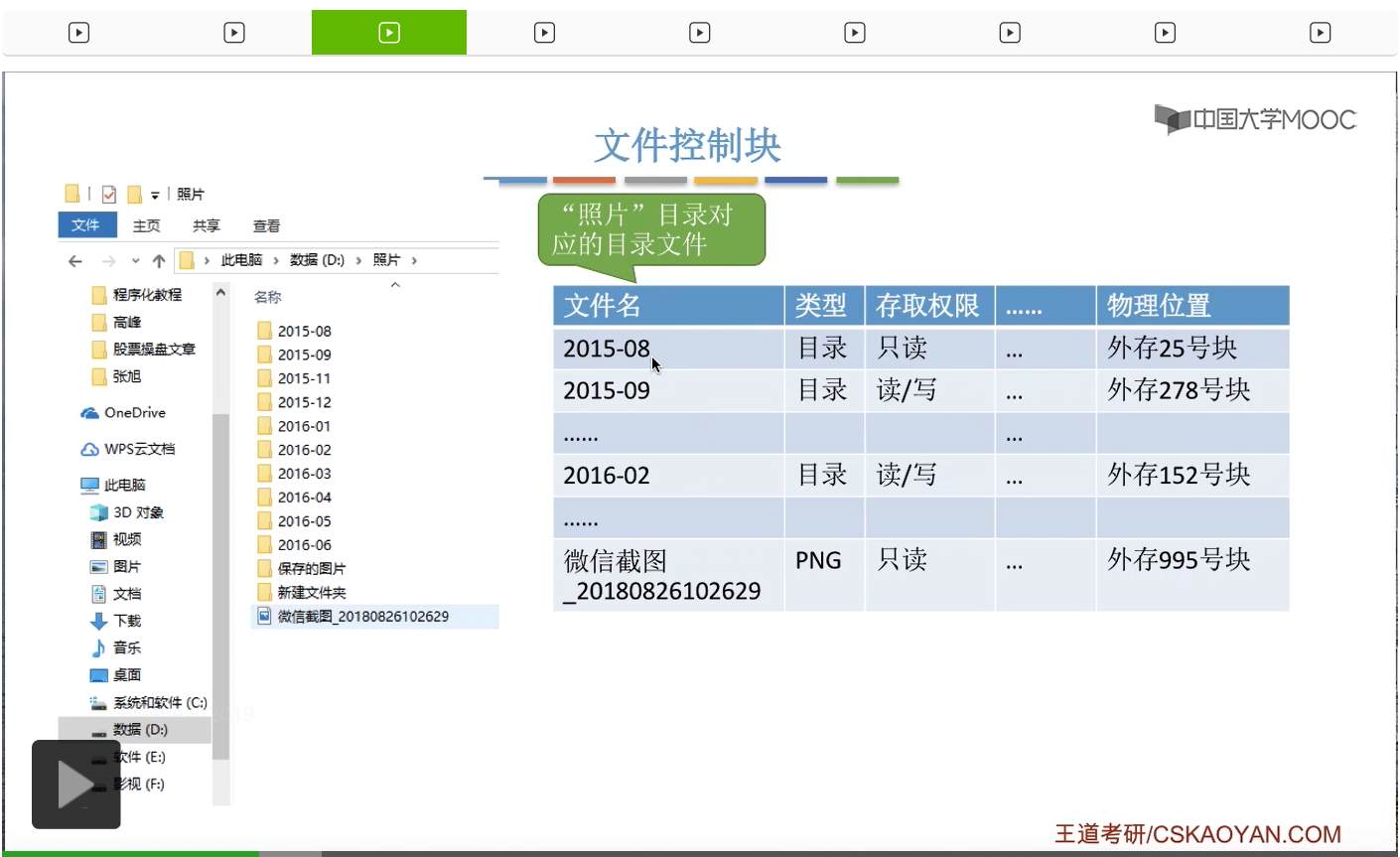
所以其实这些一条一条的目录项,本身就是一个一条一条的记录。所以目录文件其实本身就是一种有结构的文件,它是由一条一条的记录组成的。而每一条记录会对应在这个目录下面的一个文件。因此我们在这个地方看到的目录其实它也是一种特殊的文件。那可以看到,在这个表当中,标识了文件的文件名是什么,还标识了文件类型。比如说像照片这个文件,它其实是一个目录文件,所以它的类型标识是目录。那像对账单这个文件,它的类型就是.txt文件。另外呢,在这个地方,我们还需要注意一个很重要的信息就是,在这个表项当中,记录了这个文件在外存当中存放的物理地址,放在外存中的什么位置。
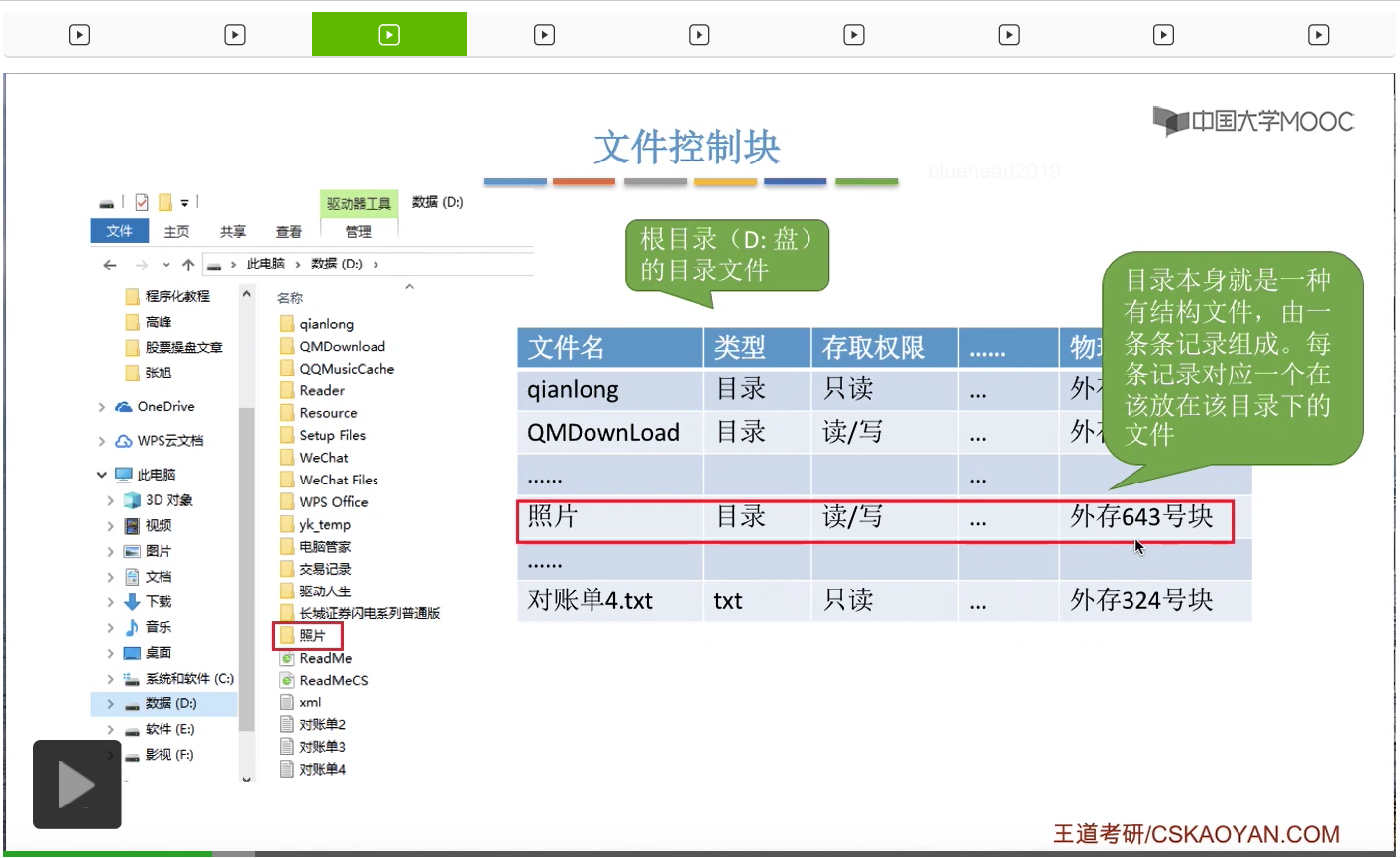
所以其实我们双击打开目录的时候,操作系统在背后做的事情是,它会来查询这个根目录,D盘这个根目录的目录文件,然后找到照片这个文件对应的目录项,之后根据这个目录项当中记录的文件的存放位置,从外存当中读入照片这个目录文件的数据,这样的话就可以知道照片这个目录下面还有哪些内容。那这些内容就可以显示展示在我们用户面前了。

那么同样的,照片这个目录对应的目录文件它也是由一条一条的目录项组成的。每个目录项会对应其中的一个文件。
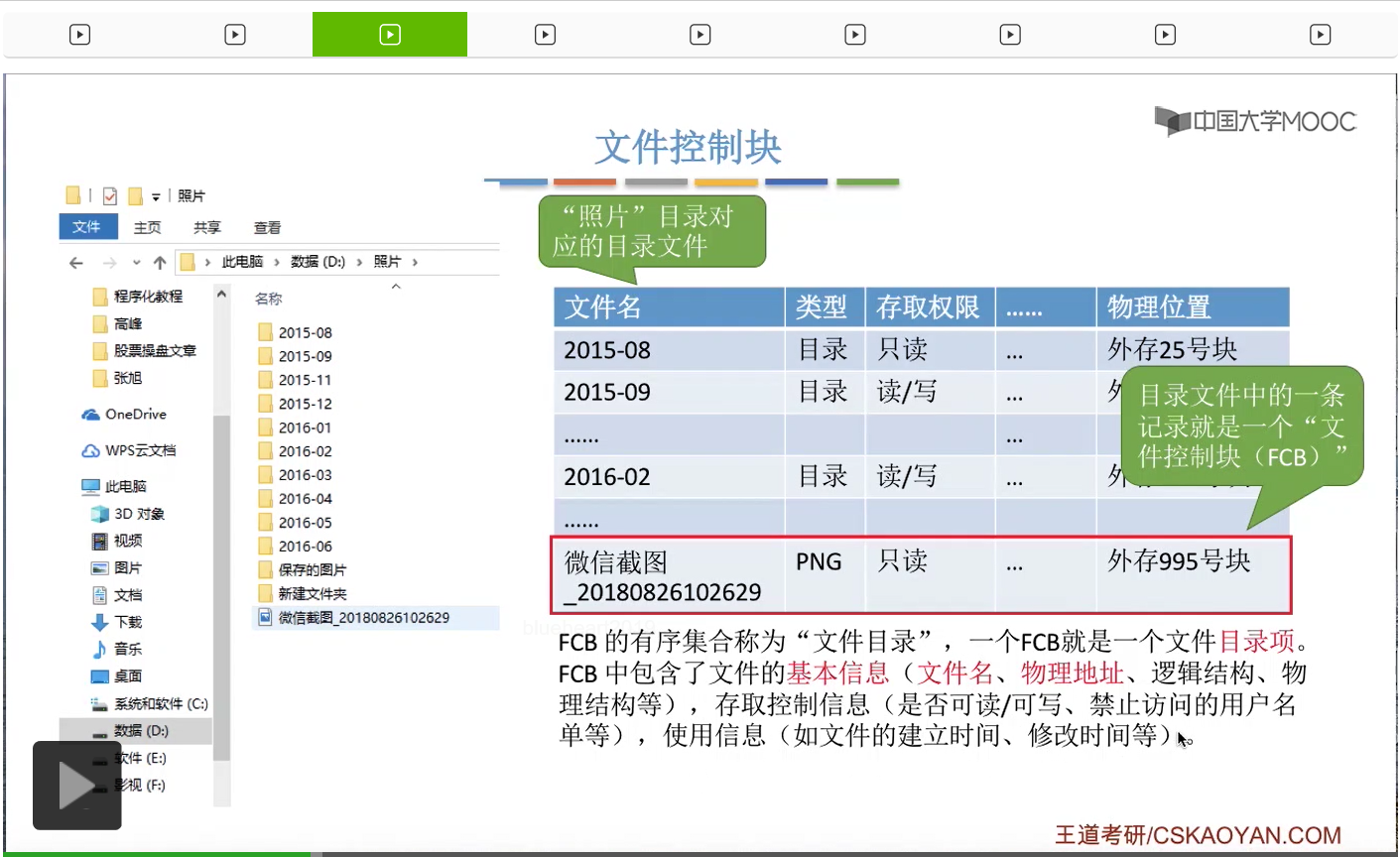
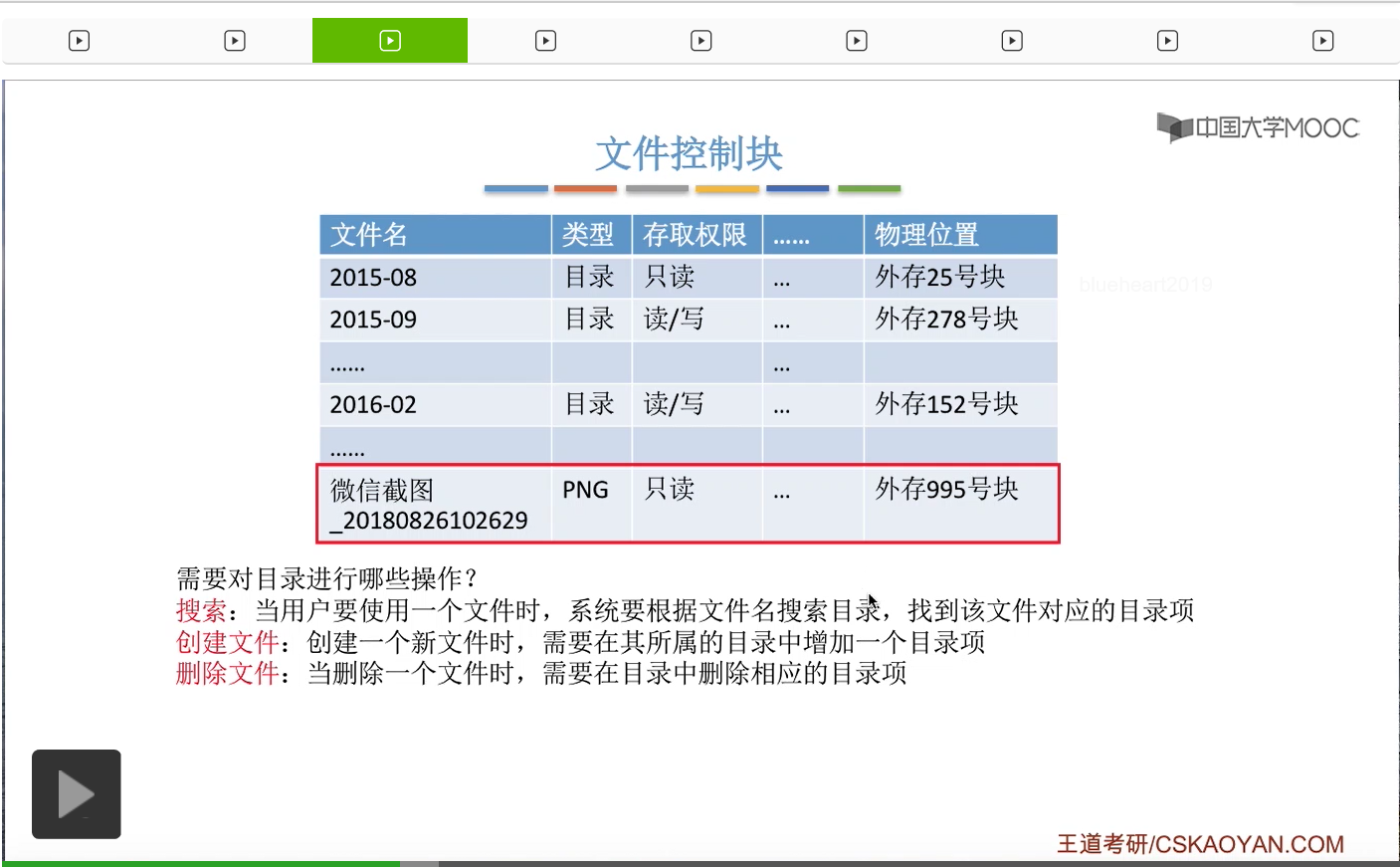
那其实目录文件当中的这样一条记录,它就是一个文件控制块,英文缩写是FCB。

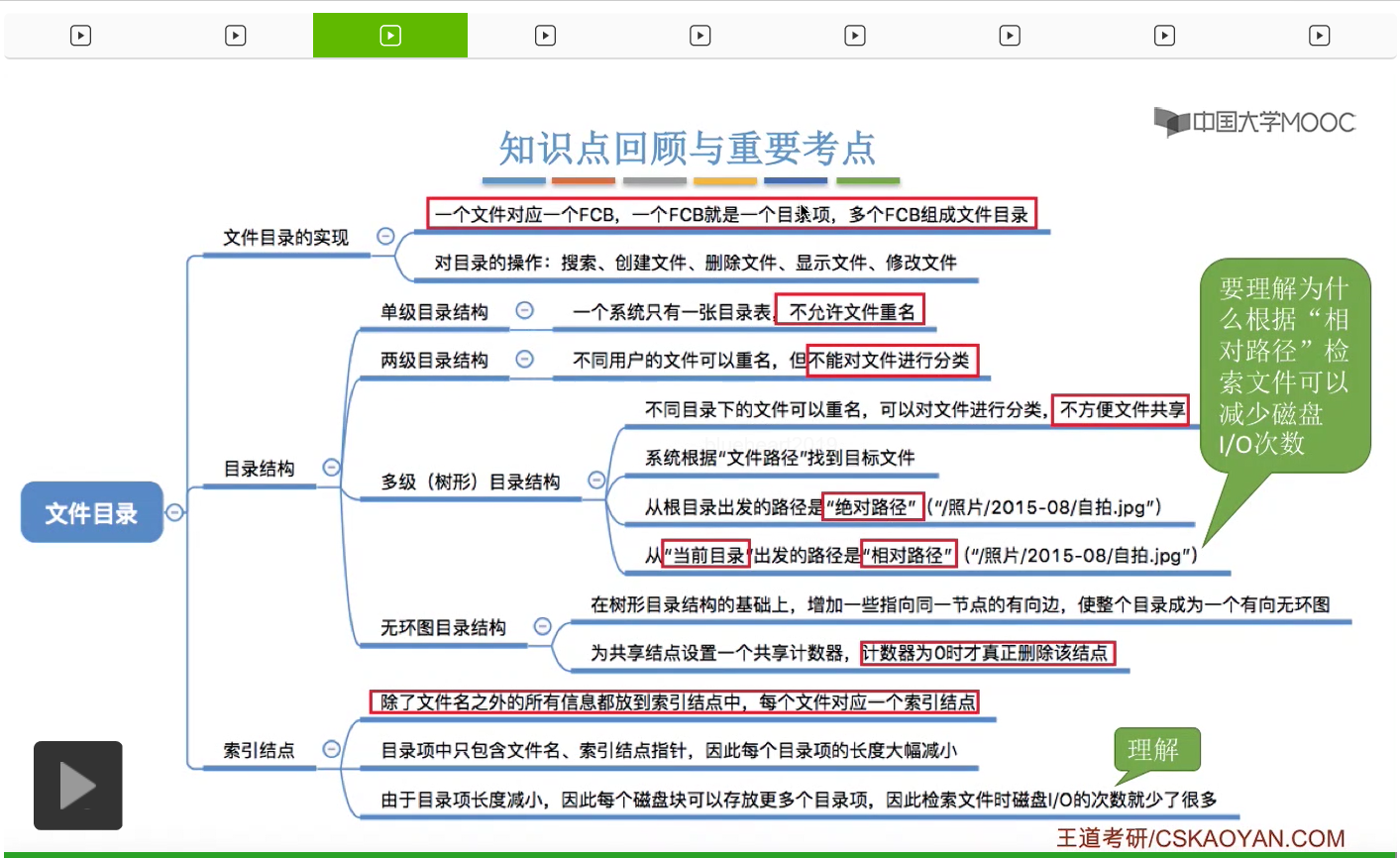
所以其实这些FCB的有序结合,就是所谓的文件目录。而一个FCB,就是一个文件目录项。那很显然,每一个文件都会对应一个FCB。

另外,从这个例子中我们可以看到,FCB中包含了一个文件的基本信息,包括文件名、物理地址还有文件的逻辑结构、物理结构等等一系列的基本信息。另外还会有文件存取权限,存取控制相关的一些信息,包括文件是否可读、是否可写等等。那除了这些之外,还会有文件的一些使用信息,包括文件是在什么时候建立,上次修改的时间是多少等等。
不过所有的这些信息当中,最重要的还是文件名还有文件的存放的物理地址这两个信息。

因为FCB,存在的最重要的一个作用其实是为了实现让用户按名存取,就是按照文件的名字来操作一个文件这样的事情。所以FCB它必须建立起文件名到文件实际存放的物理地址这样的一个映射关系。因此,最重要、最基本的,应该是文件名还有物理地址这样的两个数据。那除了这个地方提到的这些信息以外,其实咱们之前提到过的文件的各种各样的那些属性也可以存放在文件对应的FCB文件控制块当中。

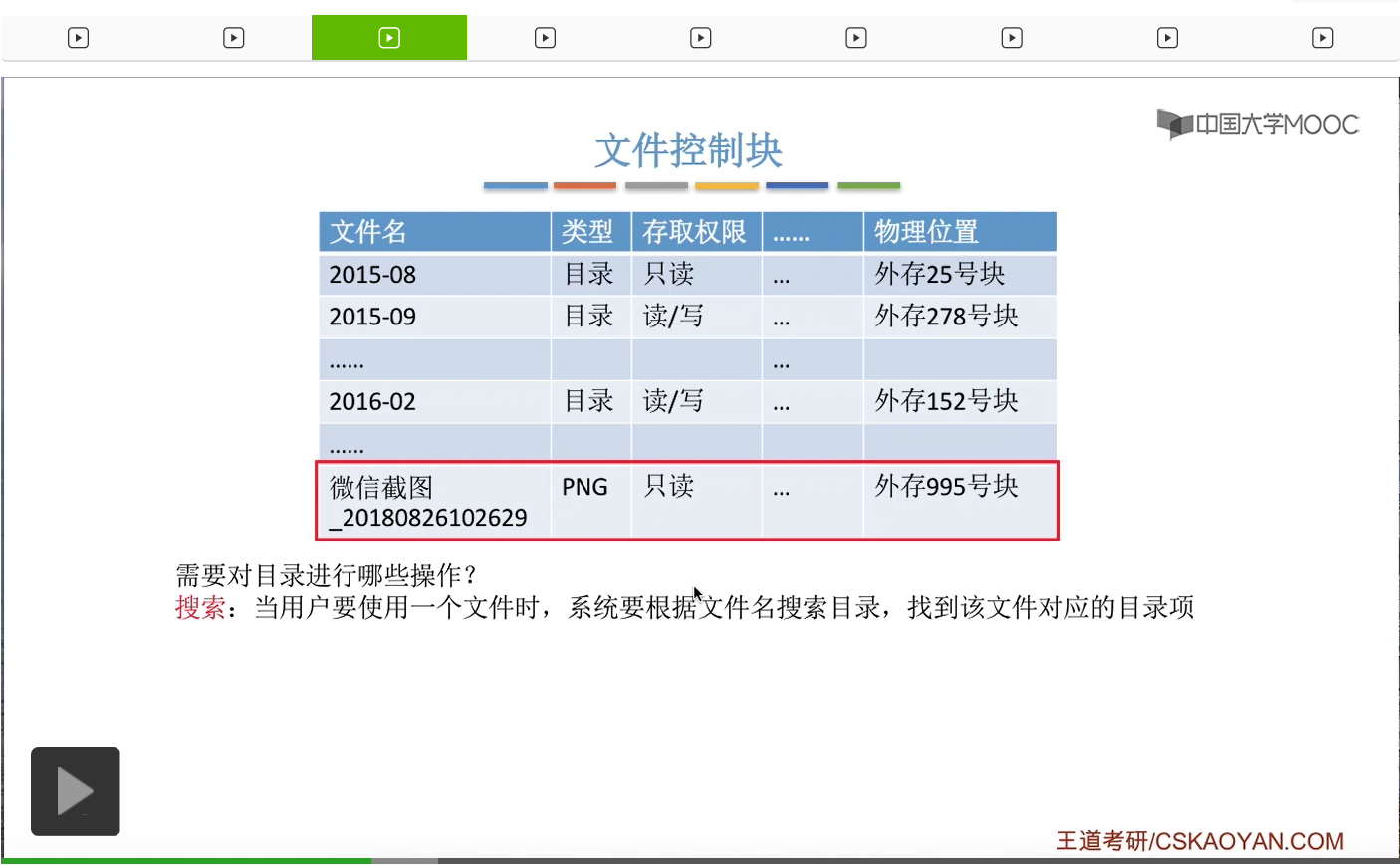
那接下来我们再来看一下,我们需要对文件目录进行哪些操作呢?首先,为了让用户能够实现按名存取,那为了实现这件事,肯定是需要有一个对目录搜索的过程。当用户需要使用一个文件的时候,系统需要根据这个文件名来搜索目录,然后找到这个文件名对应的目录项。
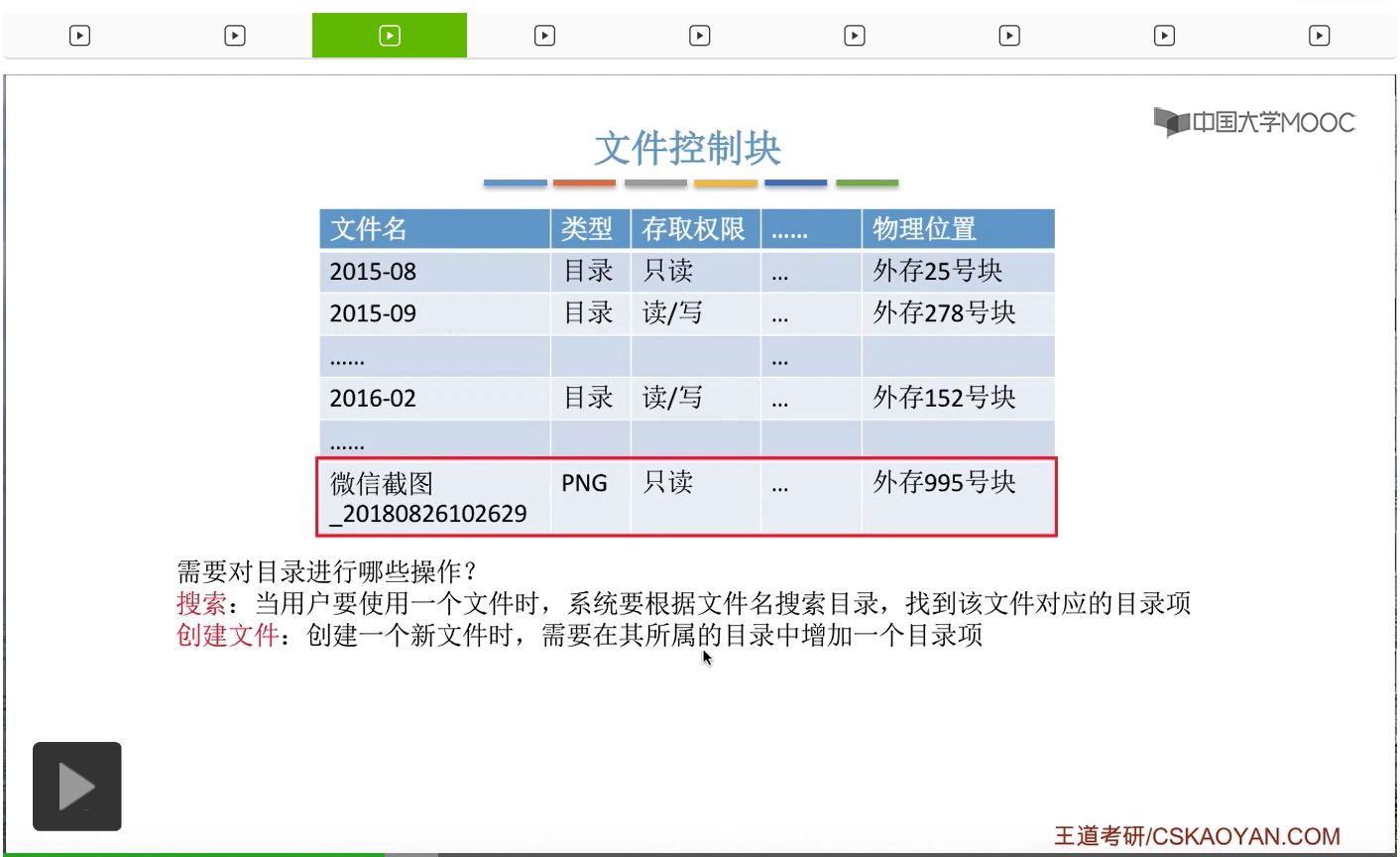
第二,当我们创建一个文件的时候,这个文件肯定是放在某一个目录当中的,所以在这个文件所属的目录当中,就需要增加一个目录项。
那与创建文件相反,当我们删除一个文件的时候,除了删除文件数据本身之外,也需要删除这个文件在目录当中对应的这个目录项。
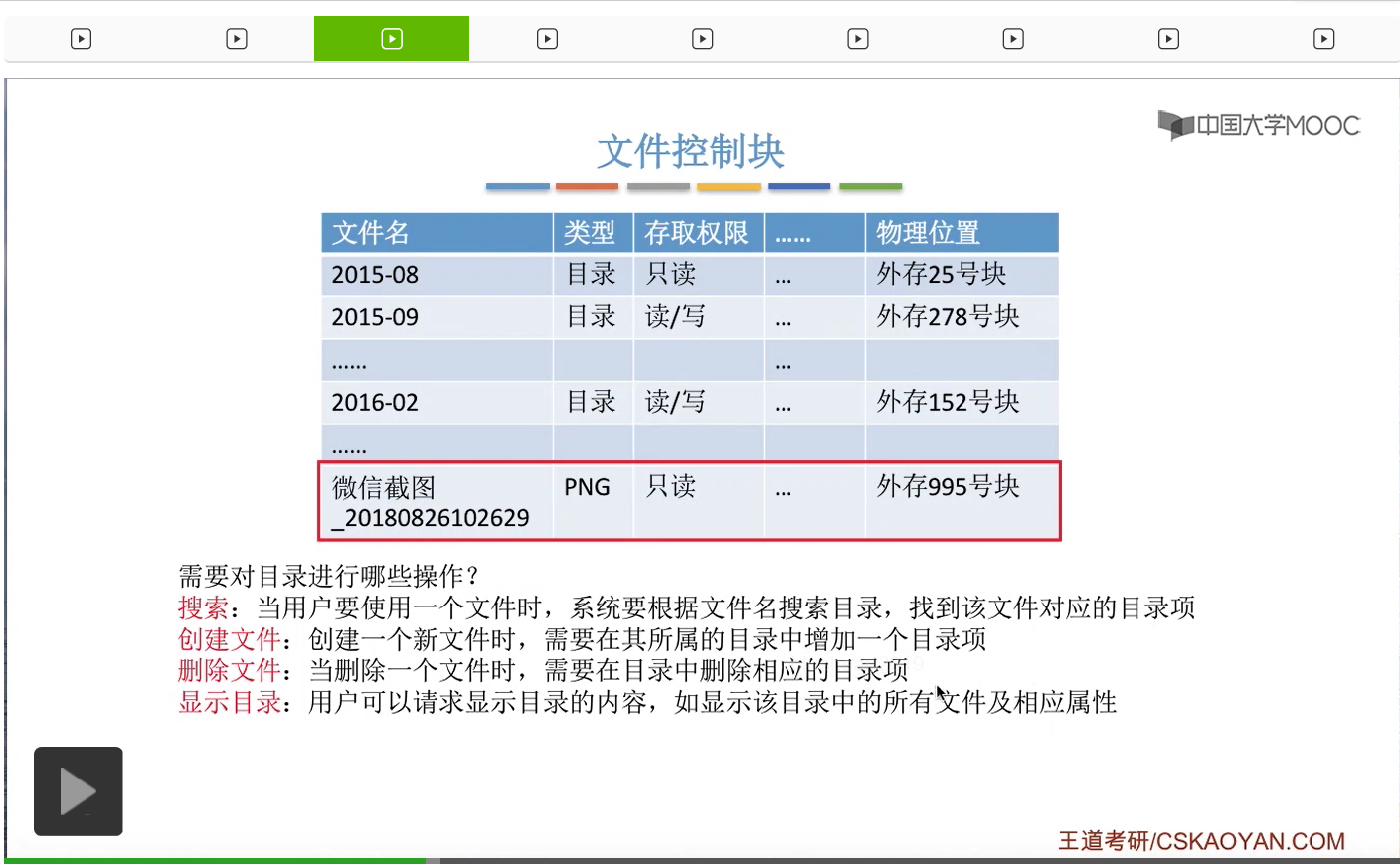
 另外呢,系统还需要提供显示目录的功能。因为用户在查看各级目录的时候,肯定是需要知道这个目录下一级到底还有哪一些文件的一些目录,所以这个功能也是必须实现的。那在显示目录的时候,可以显示与这些文件相关的一些属性,这一点大家可以在自己的Windows电脑上具体去看一下。
另外呢,系统还需要提供显示目录的功能。因为用户在查看各级目录的时候,肯定是需要知道这个目录下一级到底还有哪一些文件的一些目录,所以这个功能也是必须实现的。那在显示目录的时候,可以显示与这些文件相关的一些属性,这一点大家可以在自己的Windows电脑上具体去看一下。
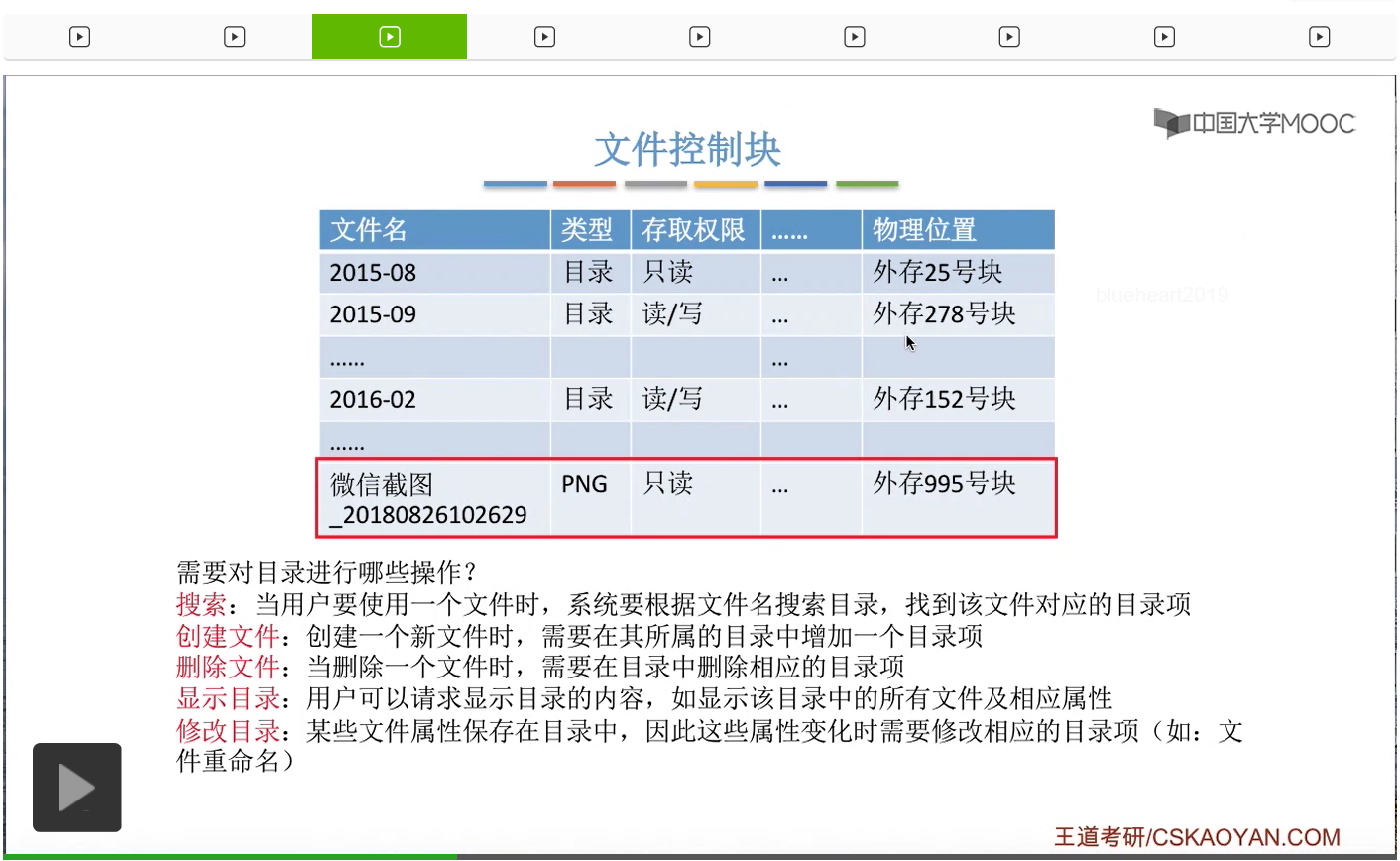
那最后我们需要知道的是,文件的各种属性是保存在目录当中的,所以如果说文件的某些属性发生变化的时候,那相应的肯定需要修改与它对应的那个目录项的内容。比如说我们对一个文件重命名,那么我们就需要把这个文件对应目录项的文件名这个信息给修改掉。那这就是一般来说需要对目录进行的一些操作。那通过之前的讲解我们知道,由文件控制块的有序集合,就组成了文件的目录。
在操作系统发展的过程当中,出现了各种各样的目录结构。在刚开始出现的叫做单级目录结构。早期的操作系统它只会在整个系统当中建立一张目录表,每个文件会占用一个目录表的目录项。

那这种单级目录结构是支持按名存取的,因为这个FCB当中其实也是包含文件名这个关键字。但是单级目录最大的一个缺点就是,不允许文件重名。可以想象一下,各个目录项的关键字是文件名,那么如果说出现了重名文件的话,比如说有一个文件叫A,另一个文件也叫A,那么当我们告诉操作系统,我们要按照文件名A来存取一个文件的时候,那操作系统到底应该选择哪一个文件呢?因此在单级目录结构当中,是不允许文件重名的。

所以我们在创建一个文件的时候,首先需要检查这个目录表当中到底有没有重名的文件,确定不重名之后,才允许建立新文件,并且把新文件对应的那个目录项,也就是FCB,插入到这个目录表当中。

那如果说这个计算机有很多用户在使用的话,那显然不同的用户的文件名是很容易重复的。因此,单级目录结构不适用于多用户操作系统。

那为了解决这个问题,后来人们提出了两级目录结构。在这种目录结构当中,会把目录分为两级。一级是主文件目录,英文缩写是MFD和用户文件目录,英文缩写是UFD。
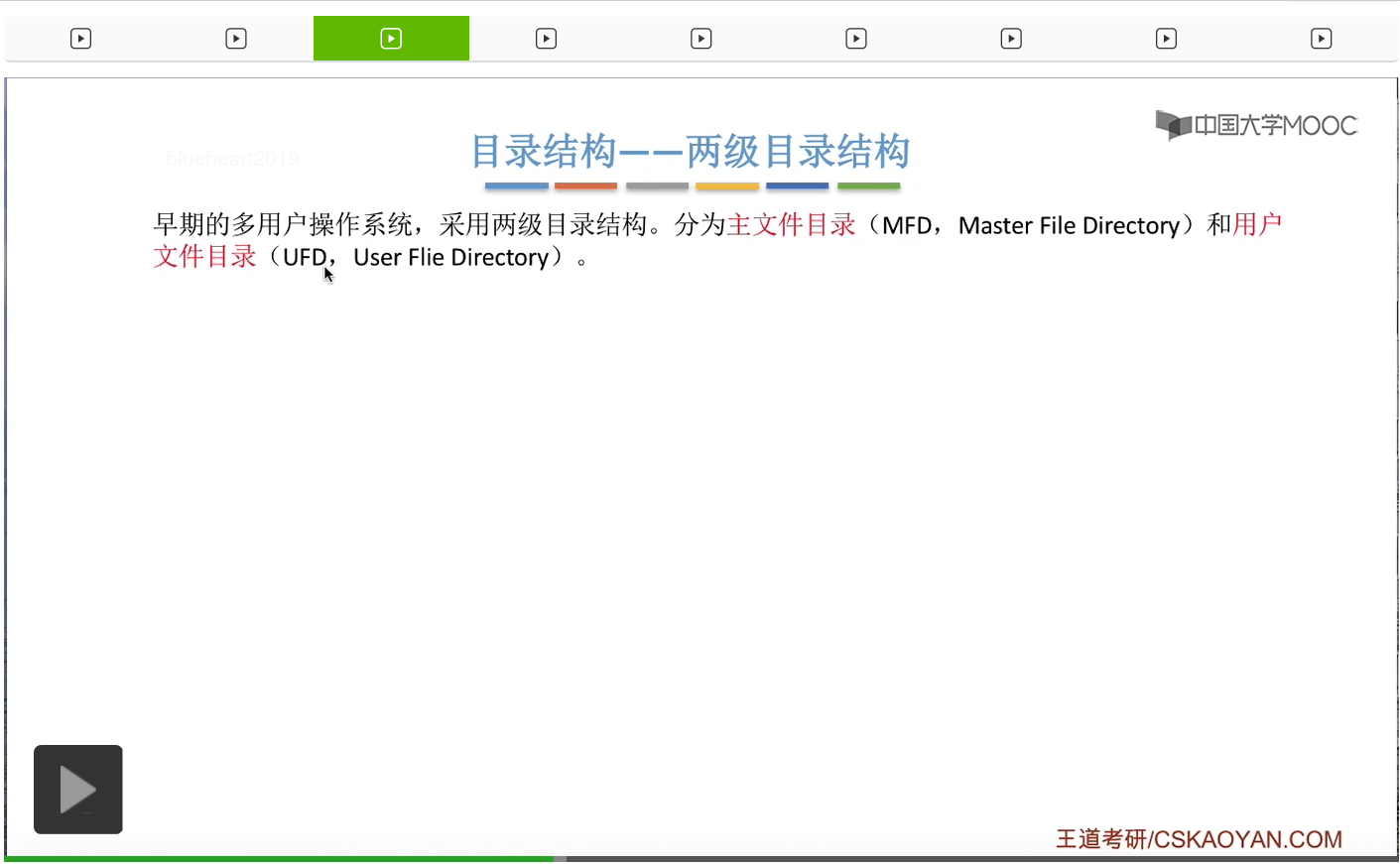
那主文件目录就是记录了用户名还有这个用户名对应的用户文件目录存放的位置。
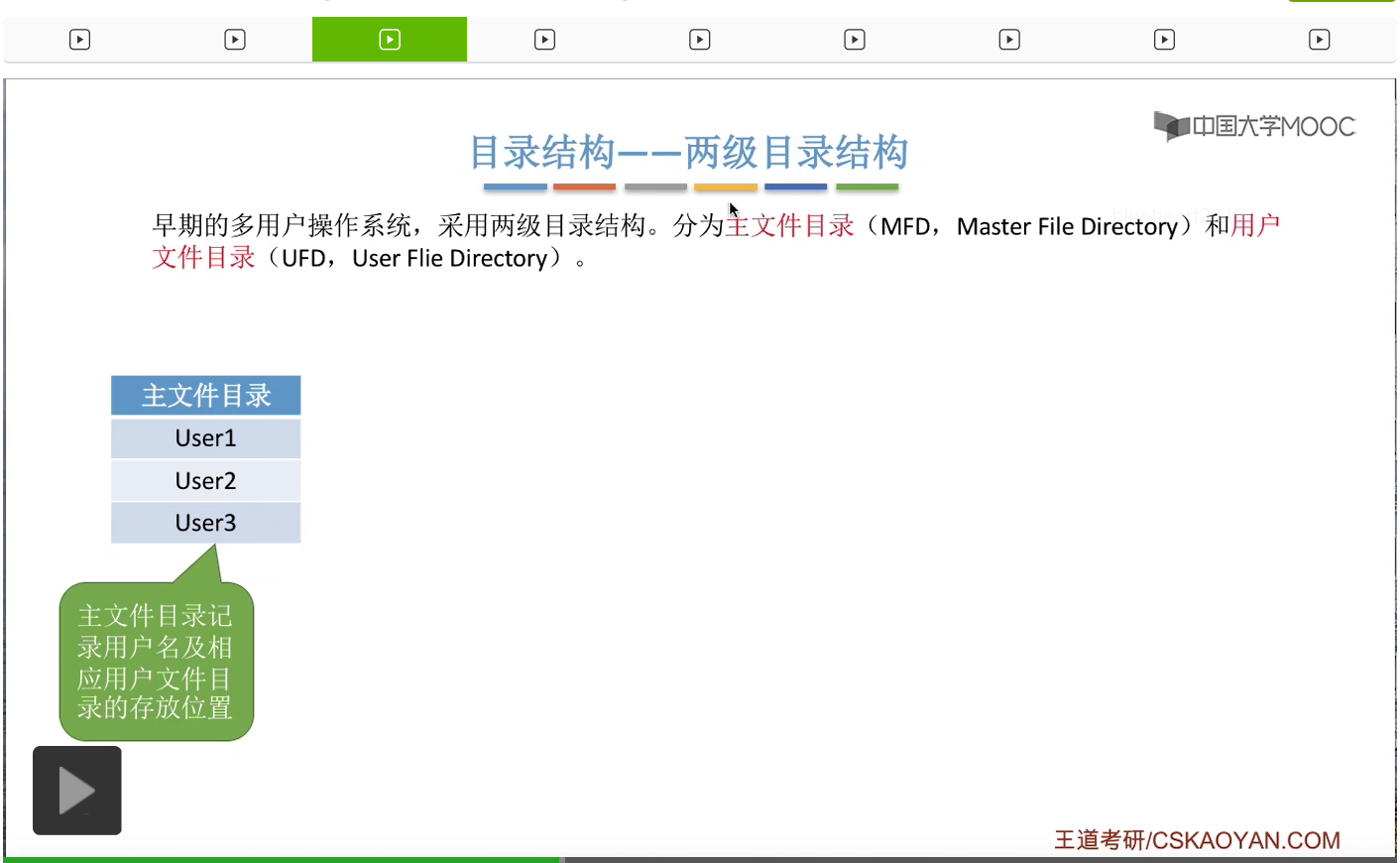
而一个用户文件目录又由这个用户的那些文件对应的FCB组成。
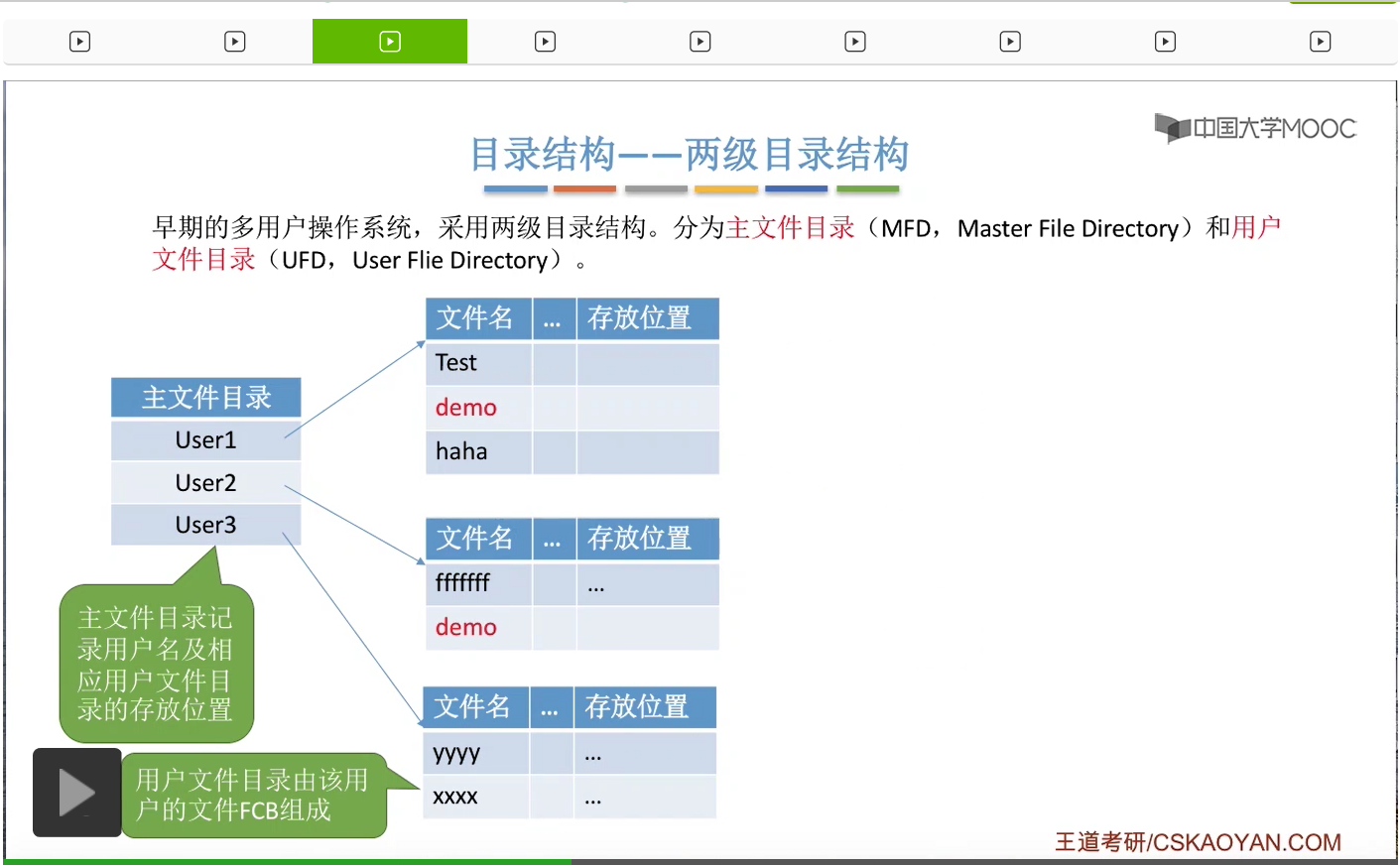
那由于不同的用户文件是存放在不同的用户文件目录下的,所以在这种情况下,不同用户的文件是允许重名的。比如说像User1这个用户,它有1个文件名叫demo的文件。User2这个用户它也有一个文件名叫做demo的文件。不过虽然它们的文件名是相同的,但是它们实际对应的文件数据是不同的两个数据。
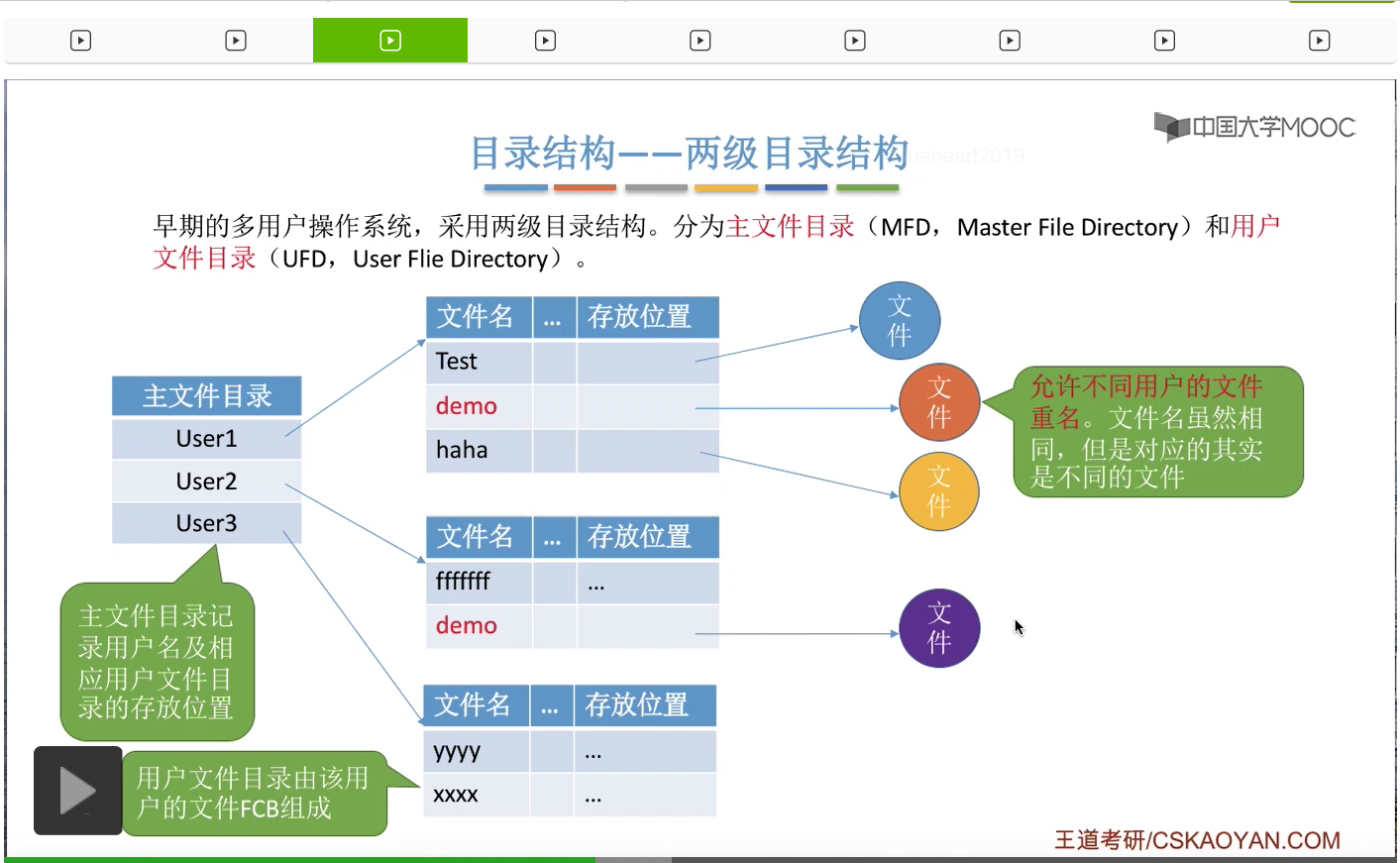
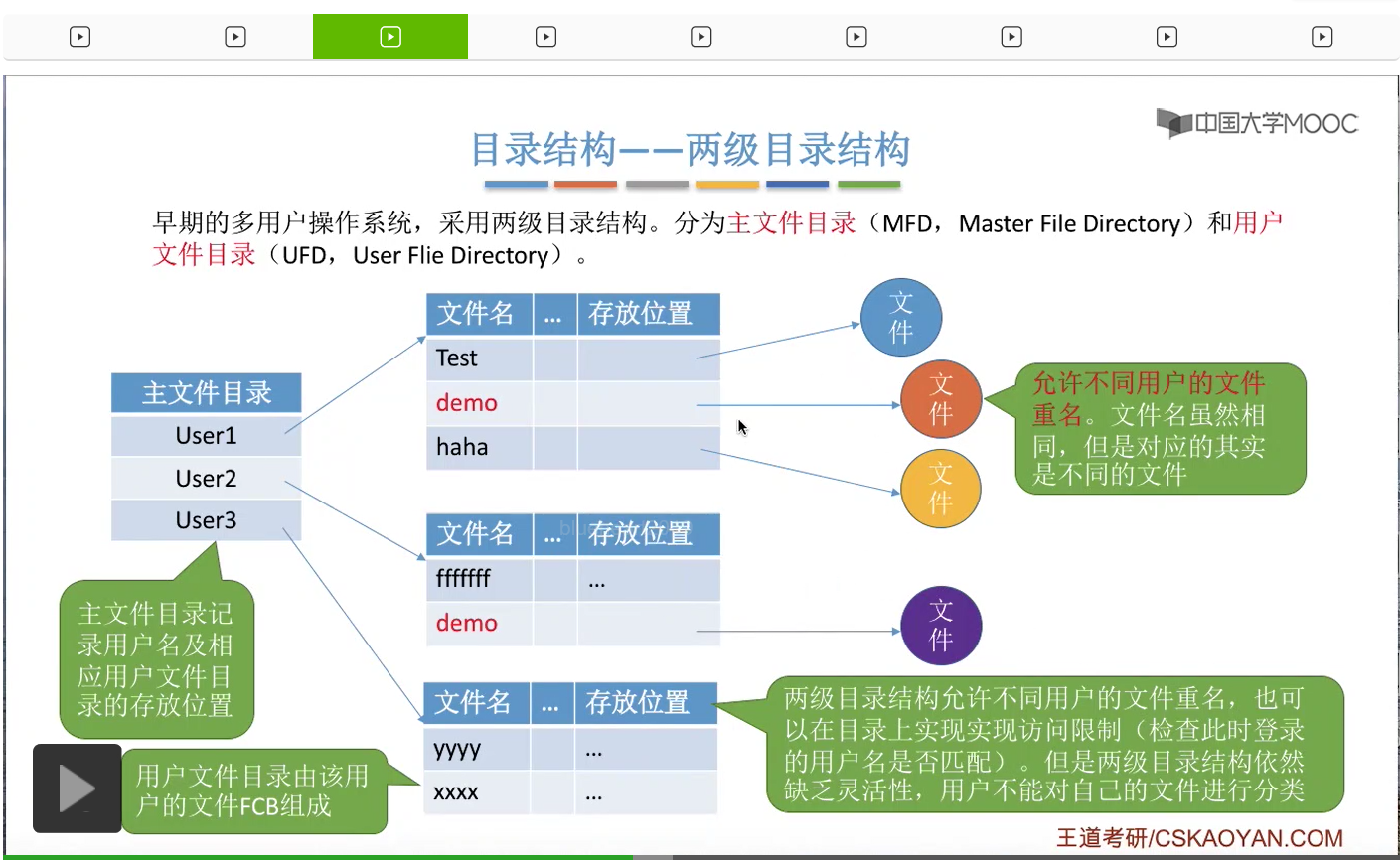
那除了允许不同用户的文件重名之外,在采用了两级目录结构之后,也可以通过目录来实现访问限制。比如说User1想要访问User2的这个用户文件目录的话,那操作系统可以验证一下User1和User2这两个名字是否匹配。那发现它不是User2,就可以拒绝让它访问User2对应的这个用户文件目录。因此采用了这种两级目录结构之后,还是很方便实现这种对于访问的限制的。但是采用这种目录结构的缺点就是,用户不可以把自己的文件进行分类。
因此人们又提出了多级目录结构,又叫树形目录结构。那这也是现代操作系统当中很常用的一种目录结构。每一个目录下面可以有更低一级的目录,同时在各个目录下面也可以有一些不同的文件,并且不同目录下的文件是可以重名的。那和刚才一样,不同目录下的文件虽然说名字是相同的,但是它们实际对应的文件并不是同一个。
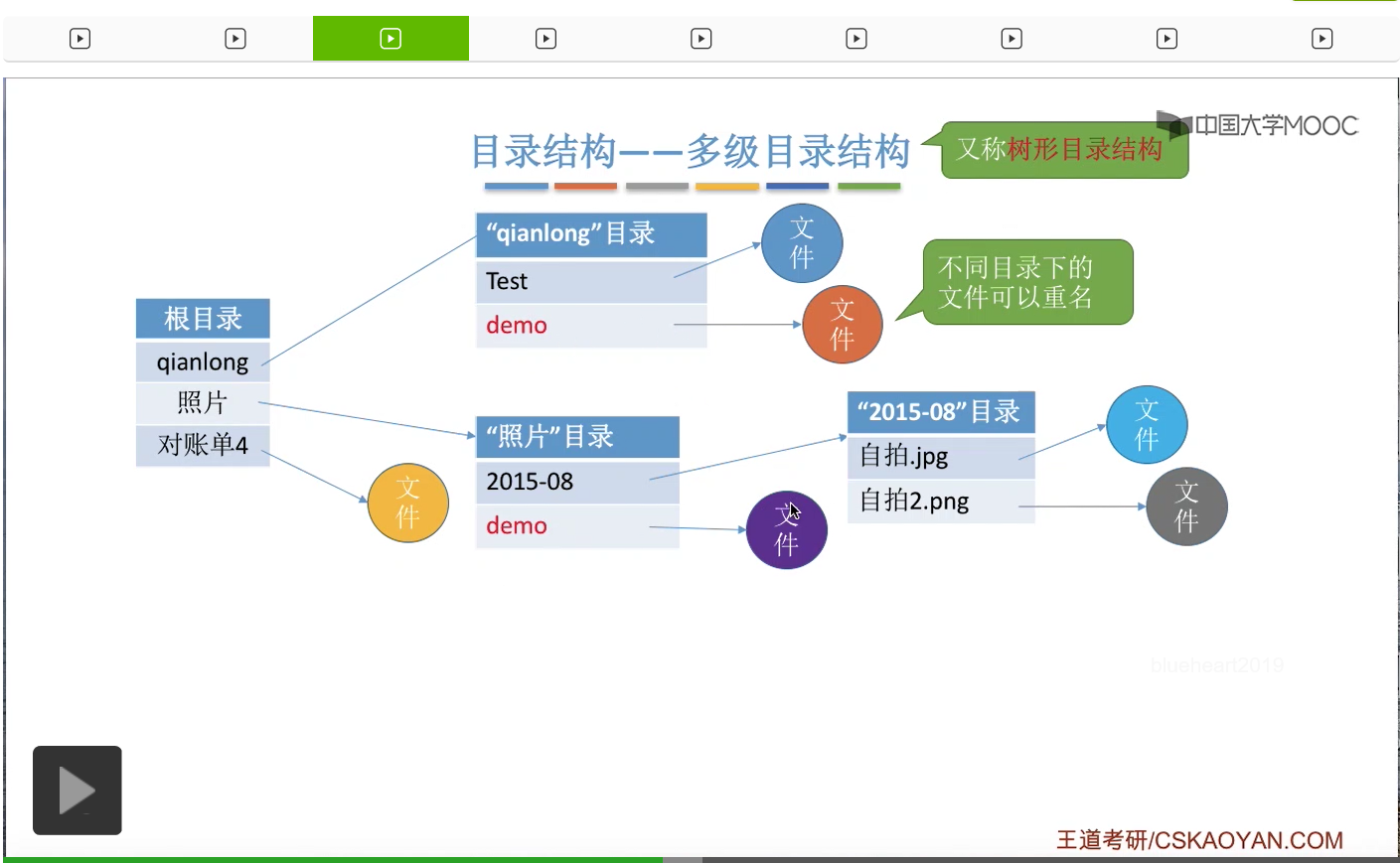
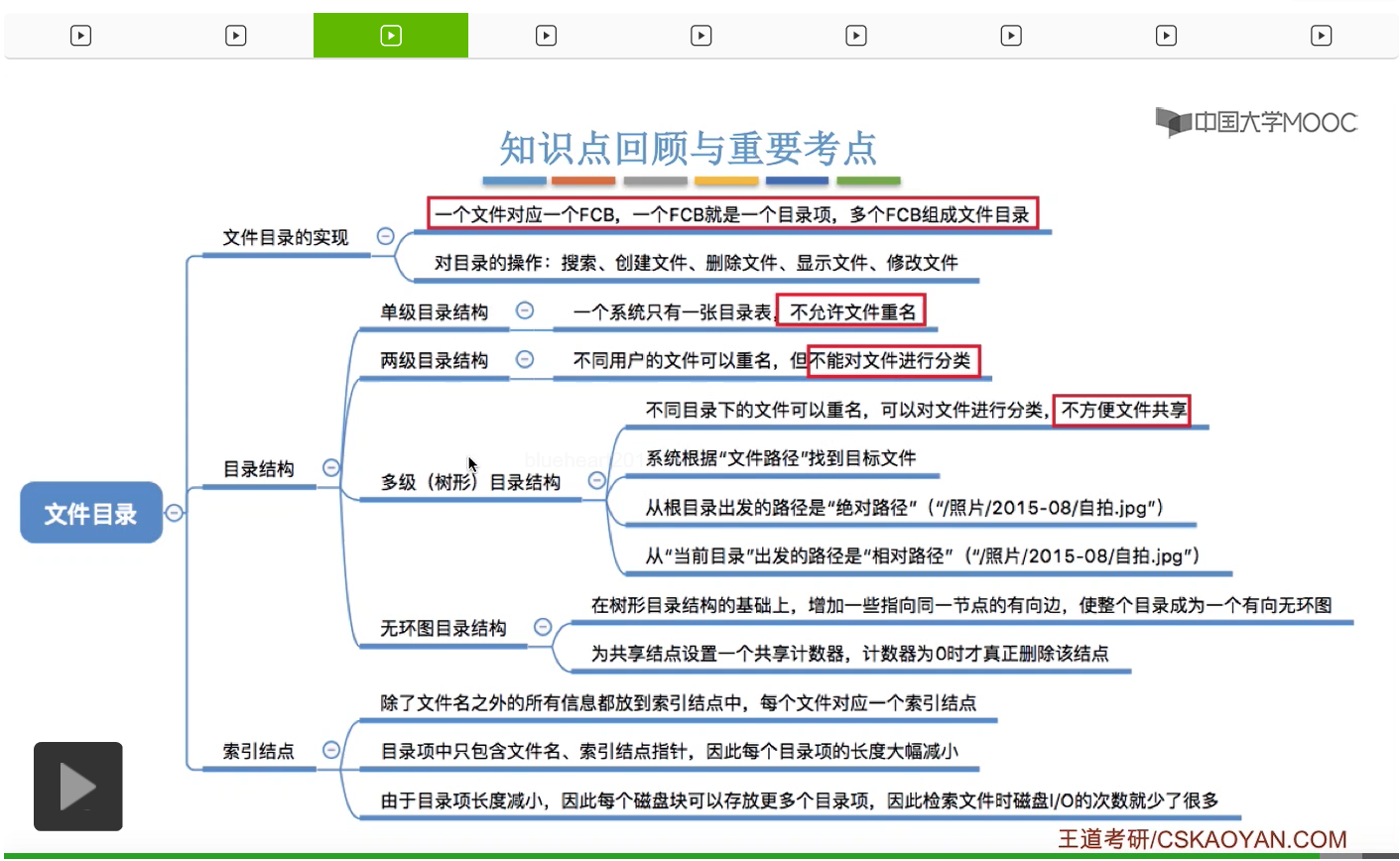
那如果说采用的是多级目录结构的话,用户或者用户进程想要访问某一个文件的时候,就需要用文件的路径名/标识符来让操作系统根据这个文件路径名找到这个文件存放的位置。那各级目录之间一般来说是用这个小斜线来隔开的。从根目录出发的路径,称为绝对路径。

比如说,像自拍.jpg这个文件的绝对路径,也就是从根目录出发的路径,就应该是根目录下面的照片这个目录,然后照片这个目录下面的2015-08这个目录。在20150-08这个目录下面,才可以找到自拍这个文件对应的目录项。

那用户或者说用户进程想要访问这个文件的时候,就需要把这个路径名告诉系统,然后操作系统会根据这个绝对路径一层一层地往下找下一级的目录。刚开始它会从外存当中调入根目录对应的这个目录表也就是这个目录文件,然后找到照片这个目录存放的位置,然后又从外存当中调入照片这个目录文件,然后再从这个目录当中找到2015-08这个目录在外存当中存放的位置。于是还需要从外存调入2015-08这个目录对应的目录表文件。那最后,再查询这个目录表才能找到自拍.jpg这个文件存放的实际位置。所以如果从根目录这个地方开始一层一层往下寻找的话,那整个过程需要3次读取磁盘的I/O操作。

不过在实际生活当中,用户经常会访问同一个目录内的多个文件。比如说一个用户它在连续地查看2015-08这个目录下面的各种各样的照片,那就意味着这个目录当中的那些内容是经常会被访问的。但是如果每一次访问2015-08当中的文件,都需要从根目录开始一层一层地往下寻找的话,那显然每一次都需要3次读磁盘操作,这是很低效的。
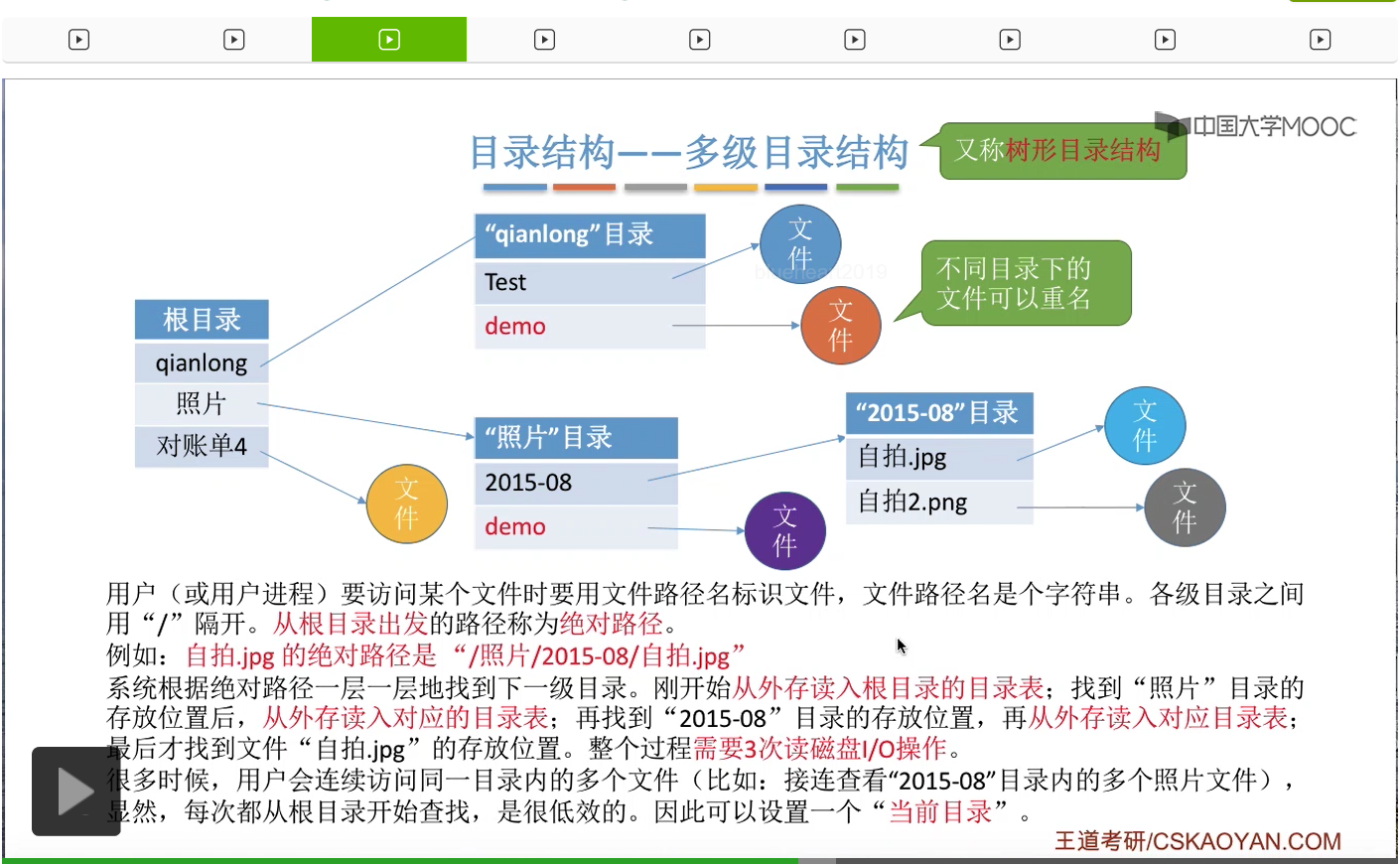
所以我们可以设置一个当前目录。比如说此时我们已经打开了照片这个目录文件,也就是说照片这个目录文件已经是从外存调入内存当中的了。那我们可以把照片这个目录设置为当前目录。当用户想要访问某个文件的时候,就可以从当前目录出发,然后找到自己想要的那个文件。那从当前目录出发的这种文件路径就叫做“相对路径”。

比如说像Linux系统当中,如果说当前目录是照片这个目录,然后我们想要用相对路径来表示自拍.jpg这个文件的话,那么它的相对路径就是当前目录下面的2015-08这个目录下面的自拍.jpg这个文件。所以如果从当前目录出发的话,那么想要找到自拍.jpg存放的位置,我们只需要先查询内存当中当前目录的这个目录表,找到2015-08这个目录文件在外存当中的存放位置,然后把这个目录调入内存。于是再从这个目录当中找到自拍.jpg存放的位置。
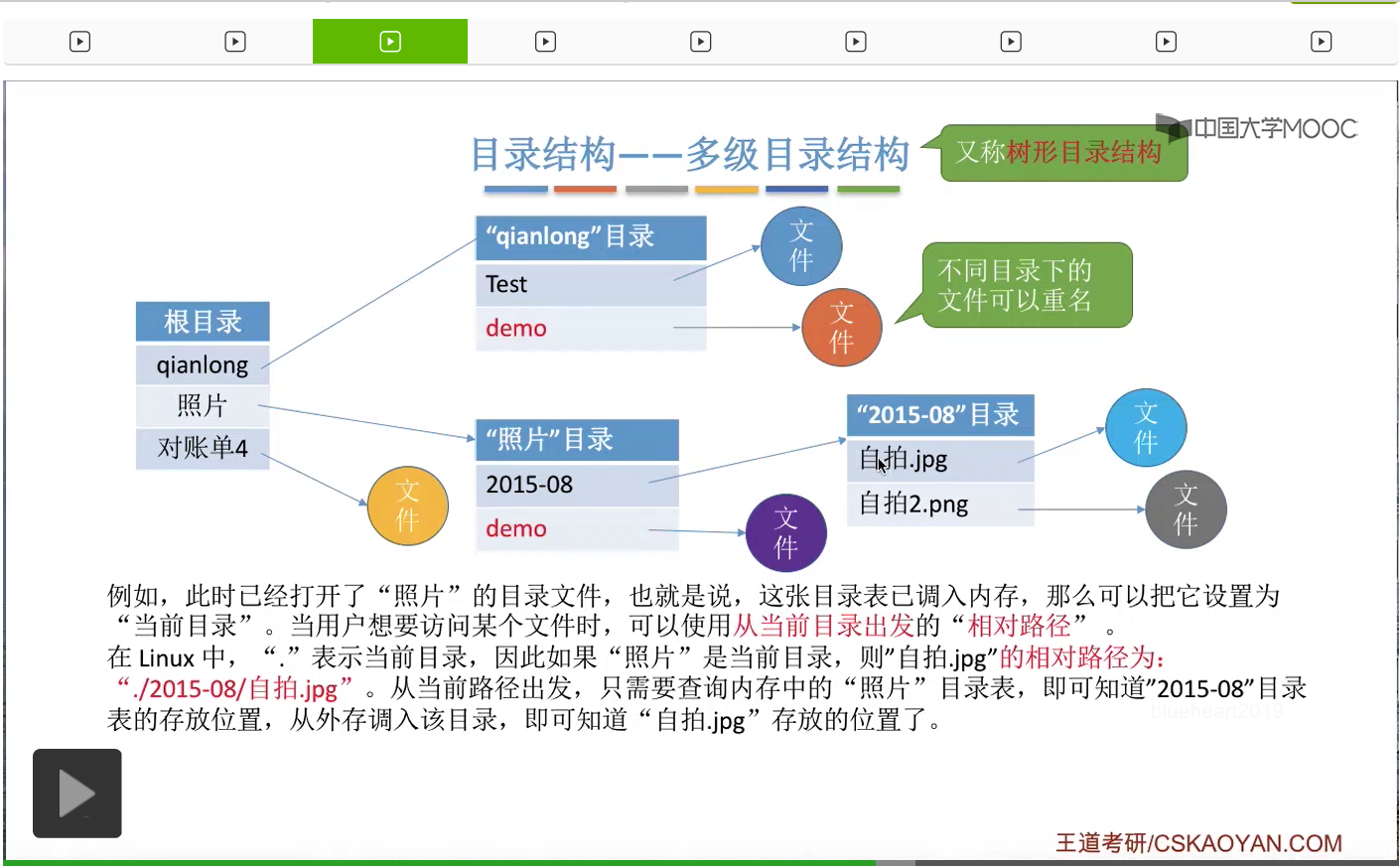
那这样的话整个过程只需要经过一次读磁盘操作就可以知道自拍.jpg存放的位置了。所以可以看到,在引入了当前目录和相对路径这种机制之后,磁盘I/O的次数减少了,这就提升了访问文件的效率。
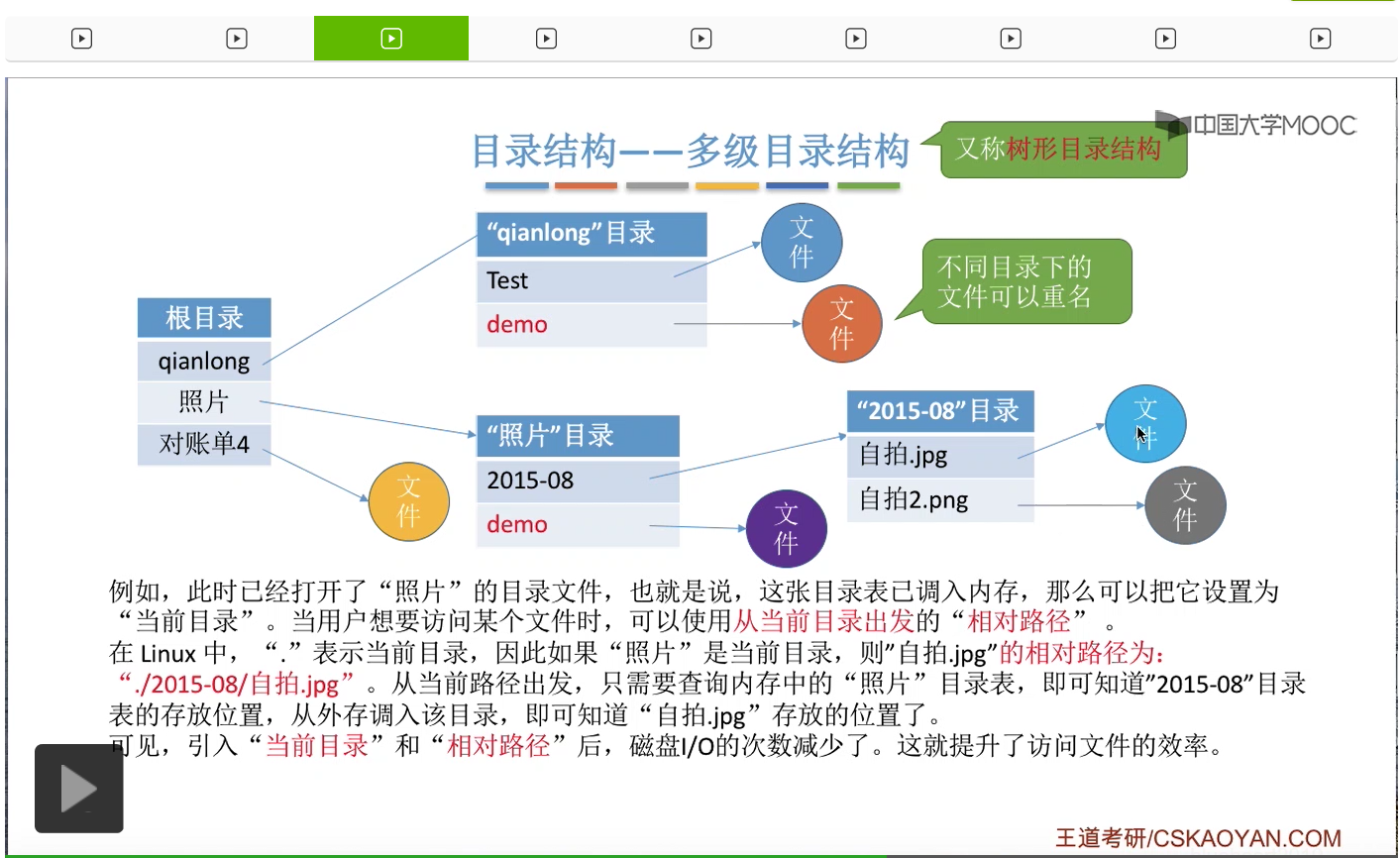
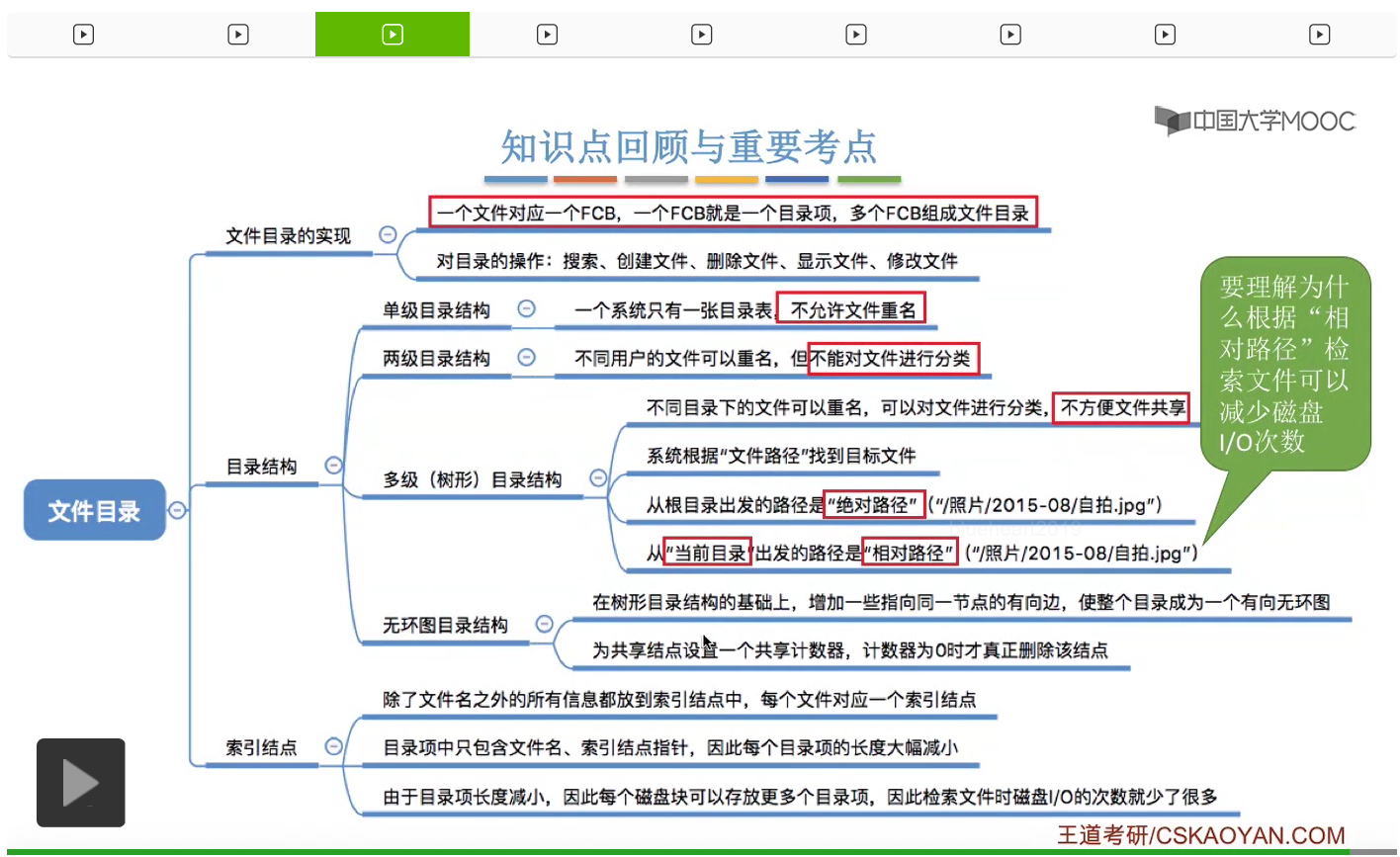
不过树形目录结构也并不是万能的。它可以很方便地对文件进行分类,层次结构清晰,也可以很方便地对文件进行管理和保护。但是树形结构不便于实现文件的共享。那树形目录结构不便于实现文件共享这个知识点也是经常在选择题当中进行考查的。那为了解决这个问题,人们又提出了无环图目录结构。
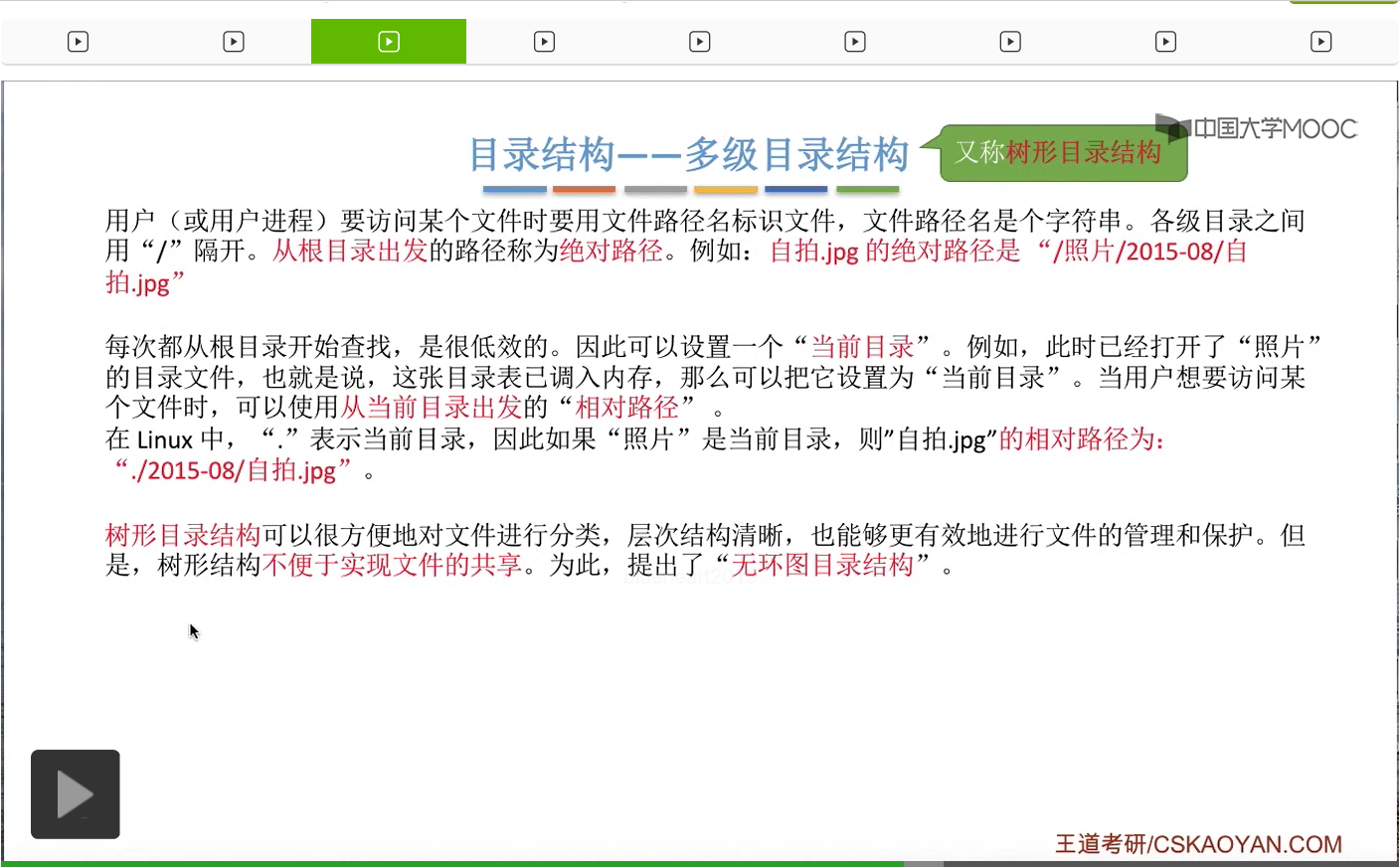
其实无环图目录结构和树形目录结构也比较相似,只不过是在树形目录结构的基础上增加了这样的一些指向同一个节点的有向边,使整个目录的结构看起来是成为了一个有向无环图。那有向无环图相关的知识点是在数据结构当中进行学习的。那这样的话就很方便地可以实现多个用户间的文件共享。
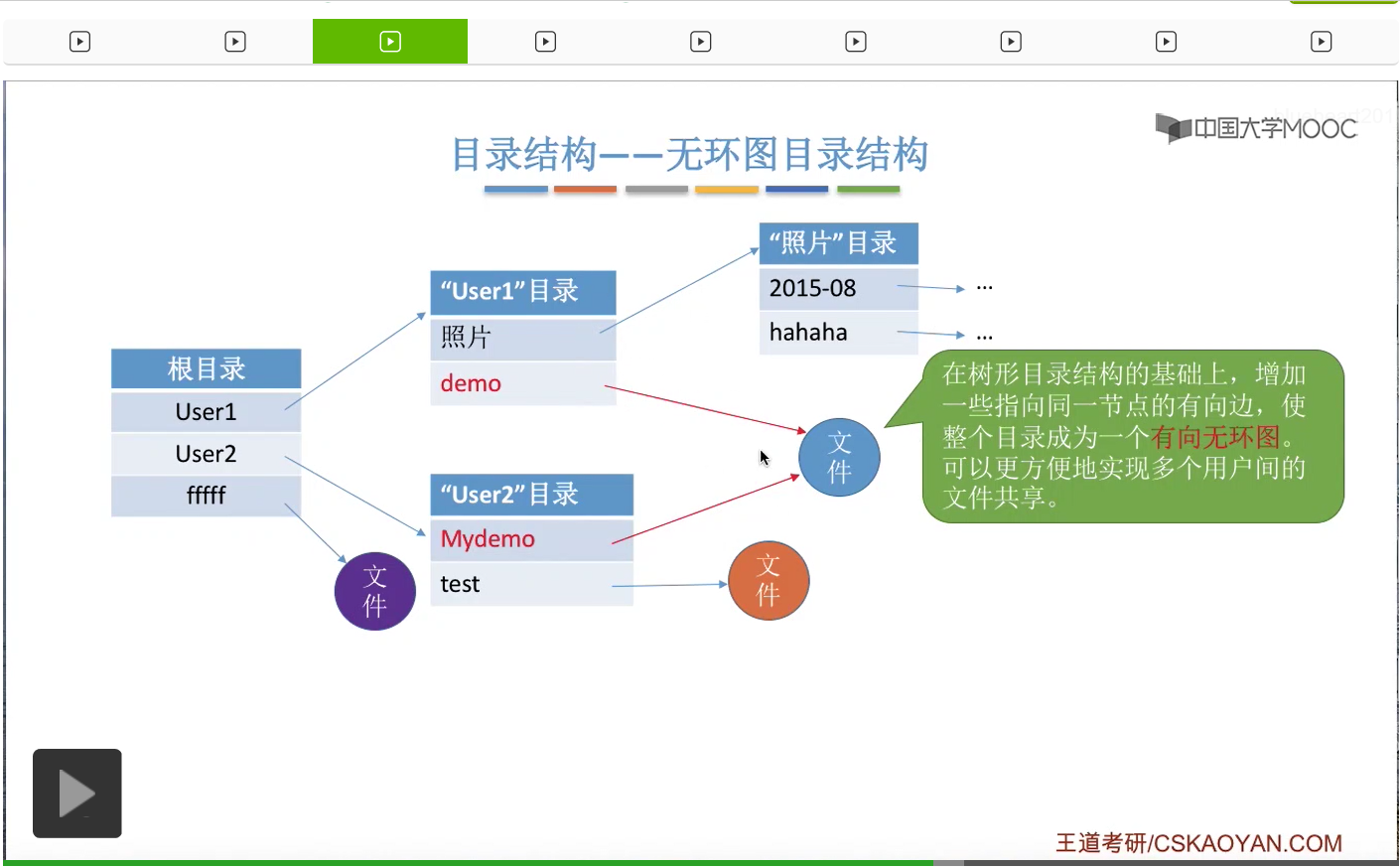
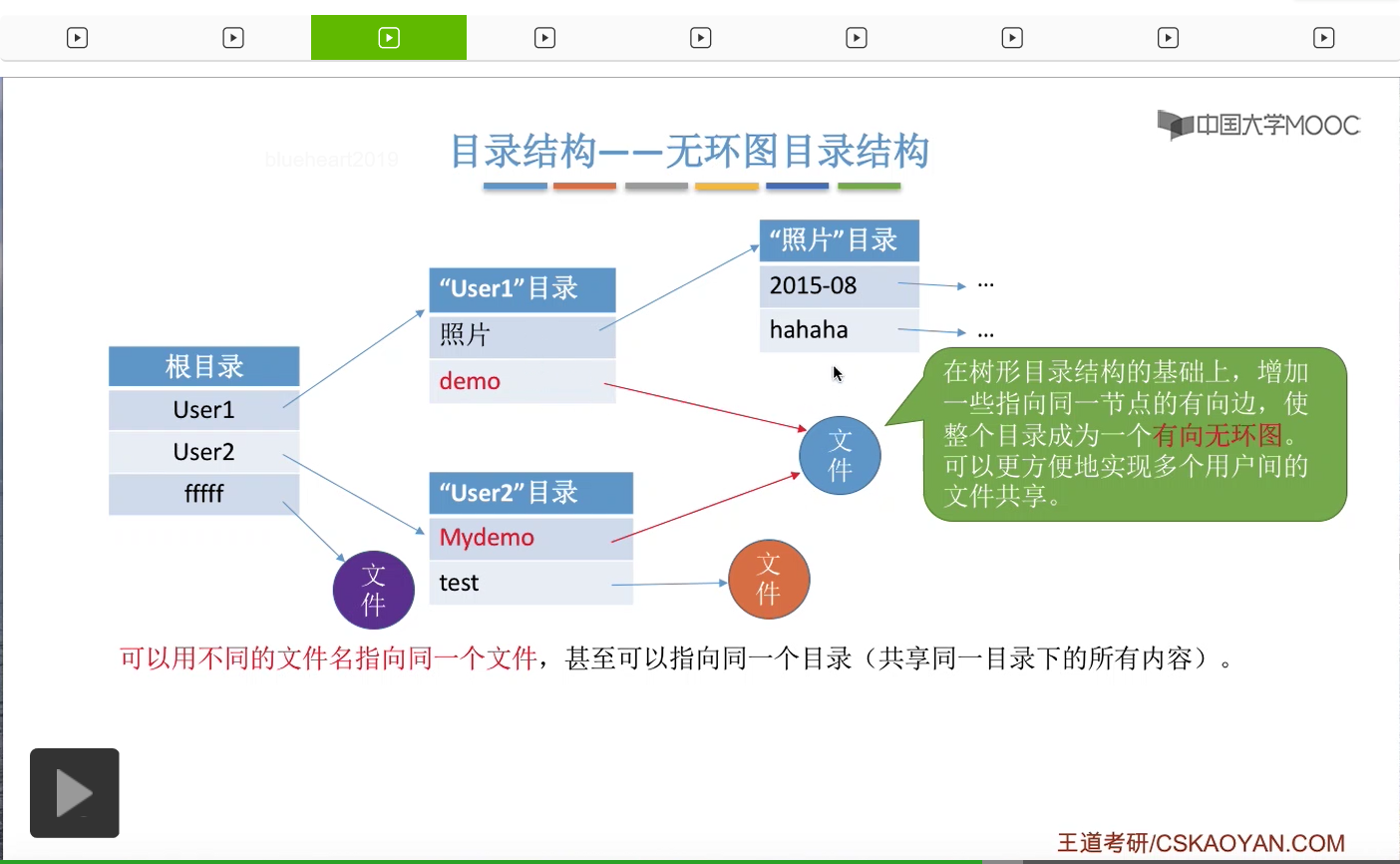
那这个地方大家肯定也会发现,可以用不同的文件名指向同一个文件。也就是说User1这个用户可以用demo这个文件名找到这个文件,而User2这个用户可以用Mydemo这个文件名找到这个文件。它们指向的都是同一个,这个文件是被它俩所共享的。那除了共享一个文件之外,甚至可以共享同一个目录。因为目录其实本身也是一个特殊的文件。在引入了共享功能之后,对于文件的删除就不能像以前那么简单。只要一个用户让删除一个文件,就把这个文件的实际数据给删除,因为这个文件有可能是被多个用户使用的。
所以为了解决这个问题,可以为每一个这种共享节点设置一个共享计数器。比如说此时这个文件是正在被两个用户共享的,那么共享计数器就应该是2。
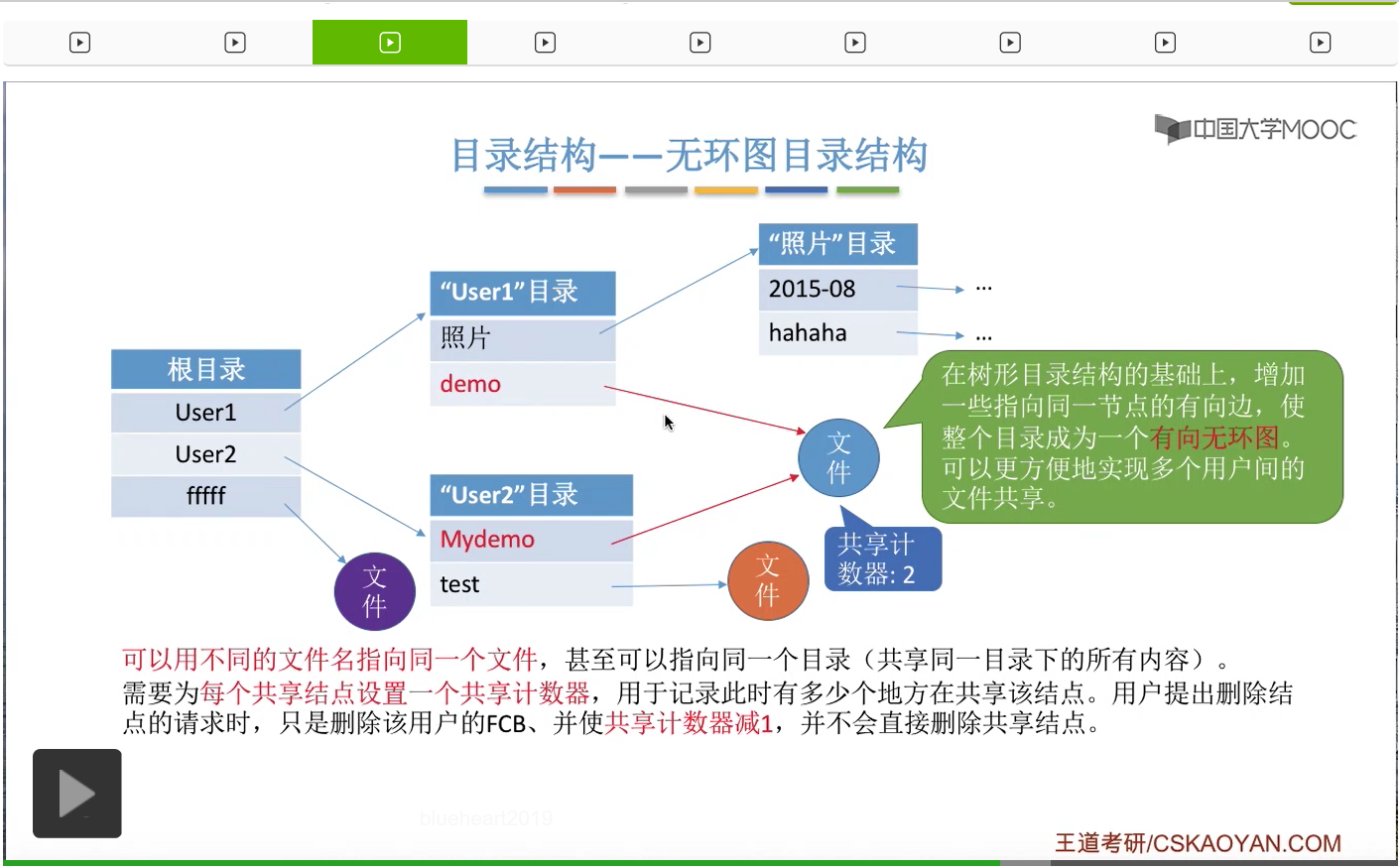
那此时如果用户1提出要删除文件这个请求的话,那其实操作系统只是会把User1对应的这个目录项给删除,并且让共享计数器减1。而这个文件实际的内容并不会被直接删除。

只有这个共享计数器的值减为0的时候,就意味着这个文件不再被任何用户所使用。那在这个时候才可以把这个共享文件真正地删除。

那大家要注意的是,共享文件和复制文件其实并不一样的。如果说User1只是复制了一个User2的这个文件的话,那其实它们俩所拥有的这个文件并不是同一个文件。当User1对自己的这个文件副本进行修改的时候,原来的这个文件的数据并不会被改变。而如果说这个文件是被两个用户所共享的话,那么由于它们指向的其实都是同一份文件的数据,因此只要其中的一个用户对这个文件数据进行更改,那另一个用户那边也是可以看到这个文件数据的变化的。那以上就是我们需要掌握的四种目录结构,单级目录结构,两级目录结构,树形目录结构和无环图目录结构。

那最后我们来介绍一下什么是索引结点。这其实是对FCB这种数据结构的一种改进。通过之前的学习我们知道,由一系列的FCB也就是文件控制块组成了一个一个的文件目录。但是其实操作系统在查找各级目录的过程当中,只需要使用文件名这个信息就可以了。而其他的这些冗余的信息暂时不需要。那只有文件名匹配的时候才需要去关心这个文件存放的物理位置。所以我们可以考虑让这个目录表进行一个简化,来提升这个搜索的效率。那由于按照文件名来搜索目录的时候,并不需要关心除了文件名之外其他的所有的信息。
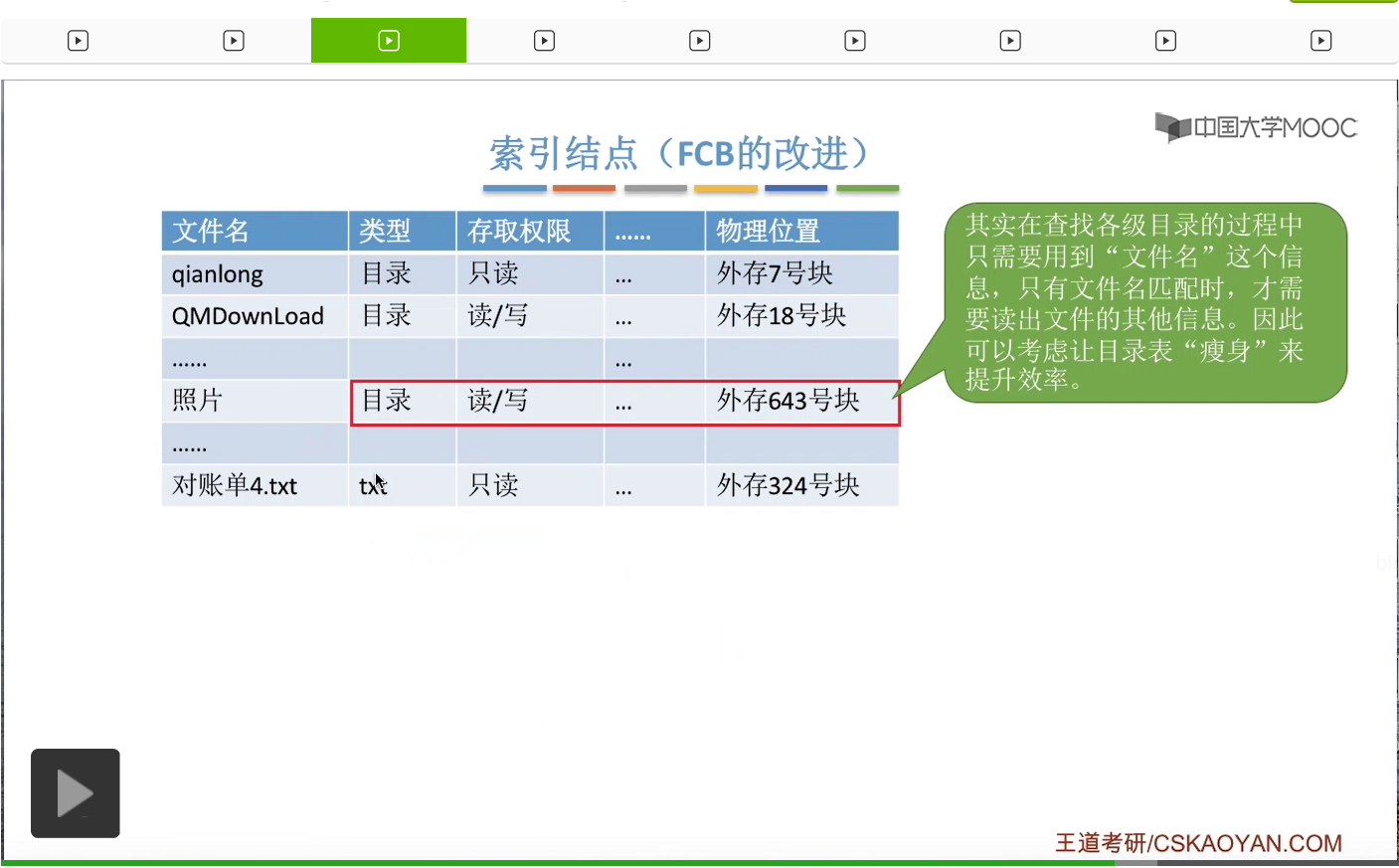
因此可以把其他的这些信息放到另外一个地方,也就是索引结点当中。那除了文件名之外,像文件的类型,文件存放的物理位置等等这些信息,都会放在文件对应的索引结点当中。每一个文件都会有一个唯一的索引结点。而采用了索引结点这种机制之后,目录当中只包含文件名还有指向索引结点的指针这样的两个信息。那这样的话,这个目录表所需要占用的空间就会小很多。那我们来看一下采用这种方式到底是怎么加快我们查找一个文件的效率的呢?
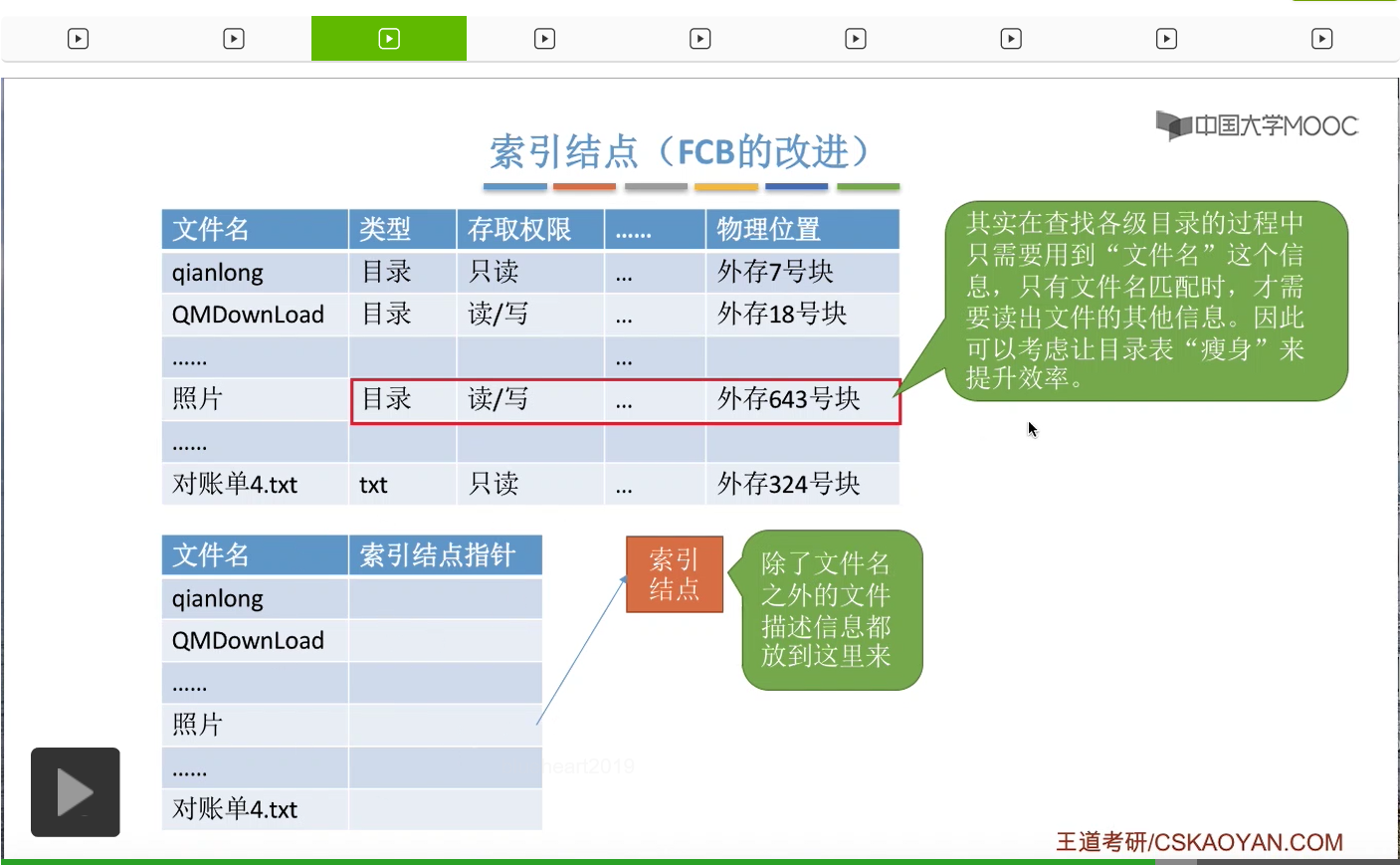
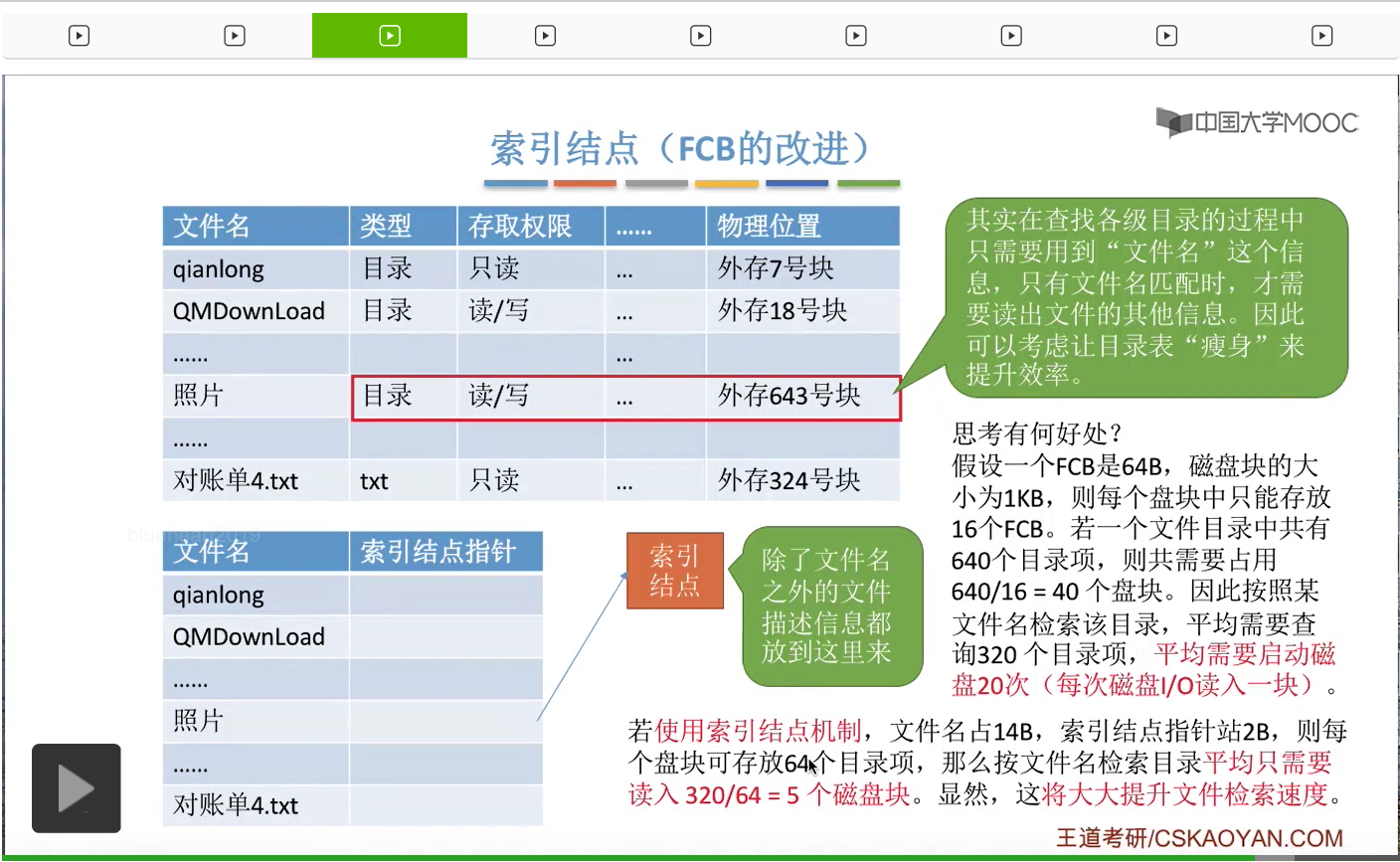
我们假设一个文件控制块是64个字节,一个磁盘块的大小是1KB。那么每个磁盘块只能存放16个FCB。也就是说,每个磁盘块只能有16个目录项。因此,如果一个文件目录当中,总共有640个目录项的话,那么这么多的目录项,总共需要40个磁盘块才能存储。那在这种情况下,我们按照文件名来检索这个目录,平均需要查找320个目录项。那由于320个目录项需要20个磁盘块才可以存放的下,所以平均就需要启动磁盘20次,因为每次启动磁盘的读操作都只能读入一个磁盘块的内容。

但是如果我们采用的是索引结点机制的话,假设文件名只占14个字节,然后索引结点的指针只占两个字节,那么每个磁盘块就可以存放64个目录项,于是我们根据文件名按顺序来检索这个目录的时候,平均需要查询320个目录项,而320个目录项,只需要5个磁盘块就可以存放了。所以如果采用的是这种方式的话,那么只需要5次启动磁盘的操作。那由于I/O操作都是比较耗时的,所以启动磁盘的次数减少了很多,那么在检索文件的时候速度也会提升很多。所以这是把其他的这些冗余信息全部放到索引结点当中所带来的一个好处,就是让文件的检索速度更加的快捷。
那系统根据文件名,找到它所对应的索引结点之后,需要把这个索引结点调入内存。之后再根据这个索引结点当中保存的文件存放位置就可以找到这个文件了。

那在外存当中的索引结点称为磁盘索引结点。当索引结点放入内存之后就称为内存索引结点。相比于磁盘索引结点来说,内存索引结点需要再增加一些信息。比如说记录这个文件是否被修改,或者记录此时到底有几个进程正在访问这个文件等等这一系列的信息。

大家需要理解文件、FCB、目录项还有目录之间的一个组成的关系。
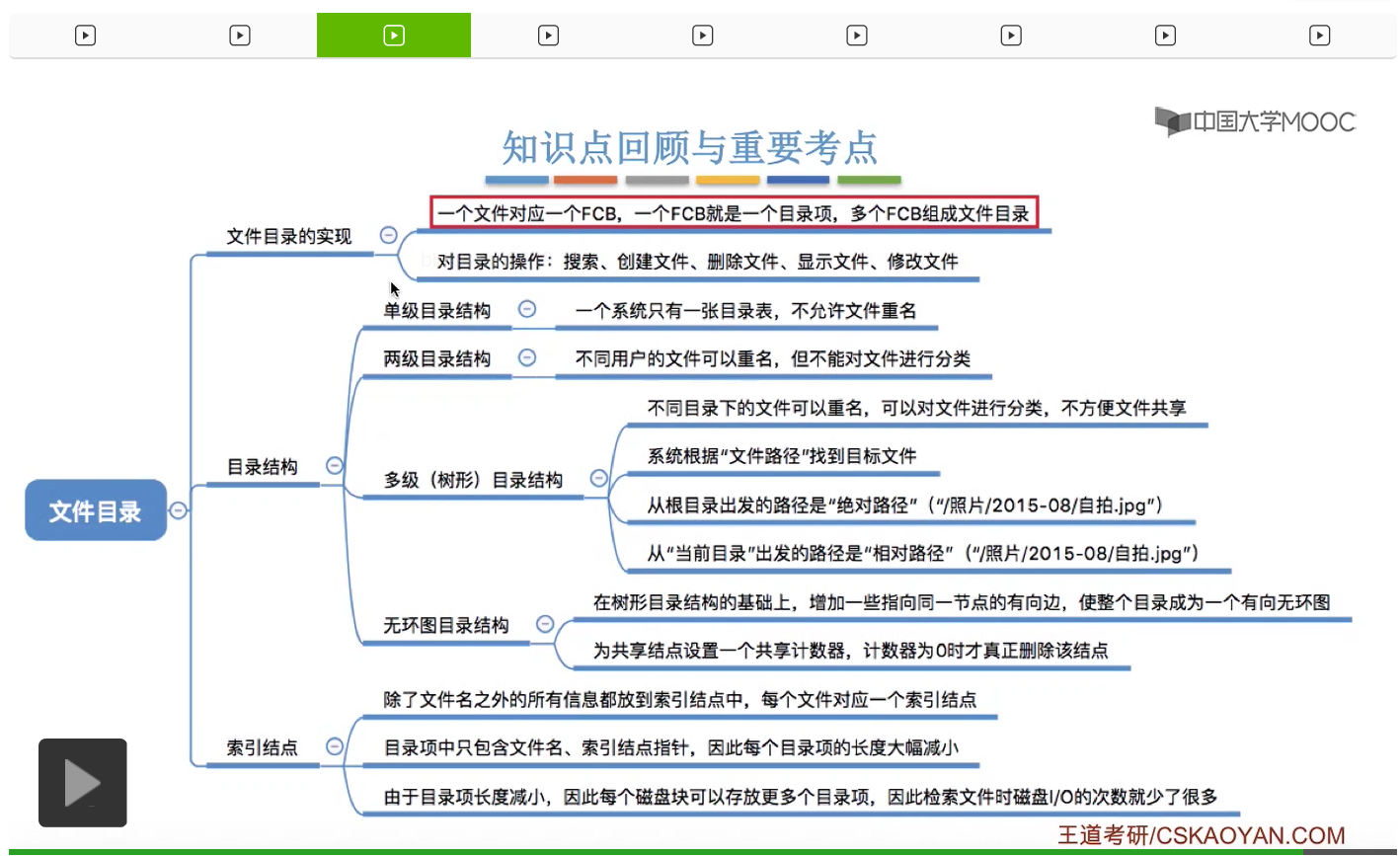
另外,大家也需要理解并记住在单级、两级还有多级目录结构当中,最主要的这个问题、缺点到底是什么。那其实每一种目录结构都是解决了上一种目录结构留下的这个最主要的问题。
那在多级目录结构当中,大家需要注意绝对路径、相对路径还有当前目录这样的几个概念。

并且需要能够理解为什么根据相对路径来检索文件可以减少磁盘I/O的次数。那其实背后的原因在于,每查询下一级的目录的时候,都需要启动磁盘I/O,把下一级目录对应的目录文件从外存调入内存。
那多级目录结构当中不方便实现文件的共享,但是无环图目录结构很方便地可以实现文件共享。但是需要注意的是,每个共享结点会有一个共享计数器。只有这个共享计数器的数值为0的时候,才可以真正地删除这个共享结点。那最后我们介绍了文件目录的一个优化方式,除了文件名之外的所有信息都放到索引结点当中。这样的话就可以让目录表的表项就大幅度地减小,从而每个磁盘块可以存放更多的目录项。因此,我们根据文件名来检索文件的时候就可以有更少的磁盘I/O的次数。
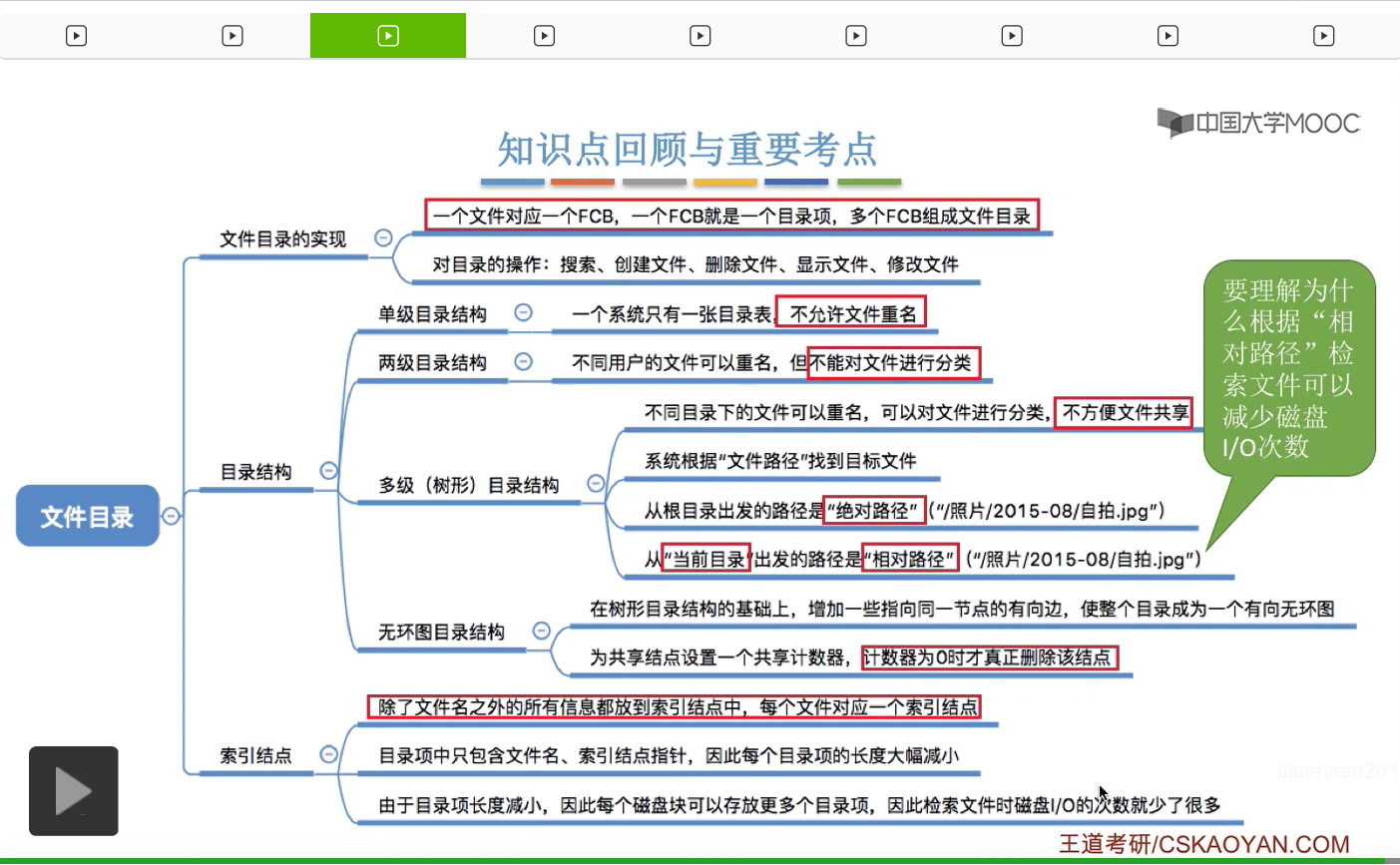
那为什么磁盘I/O的次数会更少,这一点大家也需要理解。那么这个小节的内容十分重要,很容易在选择题当中进行考查。那大家还需要通过课后习题进行进一步的巩固。
开始学习文件的物理结构也就是文件分配方式相关的一系列问题。那么这个小节的内容十分重要,在历年的考试当中都经常出现2-3题的这种选择题,甚至经常会在大题当中进行考查,所以这个小节的内容我们会讲的比较细致,会补充一些课本上没有提到的点。

那么在之前的学习当中我们知道,操作系统它作为最接近硬件的一个软件层次,需要对硬件进行管理,包括外存,也就是磁盘进行管理。那么操作系统对磁盘的管理主要是需要做这样两件事。第一,是需要对非空闲磁盘块进行管理。那么非空闲磁盘块也就是存放了文件数据的那些磁盘块。那这就是这个小节要重点探讨的文件物理结构、文件分配方式的问题。另外呢,还需要对空闲的磁盘块,也就是暂时还没有存放任何数据的那些磁盘块进行管理。那这是咱们之后的小节会探讨的文件存储空间管理的问题。那这个小节我们先看上面这个问题。
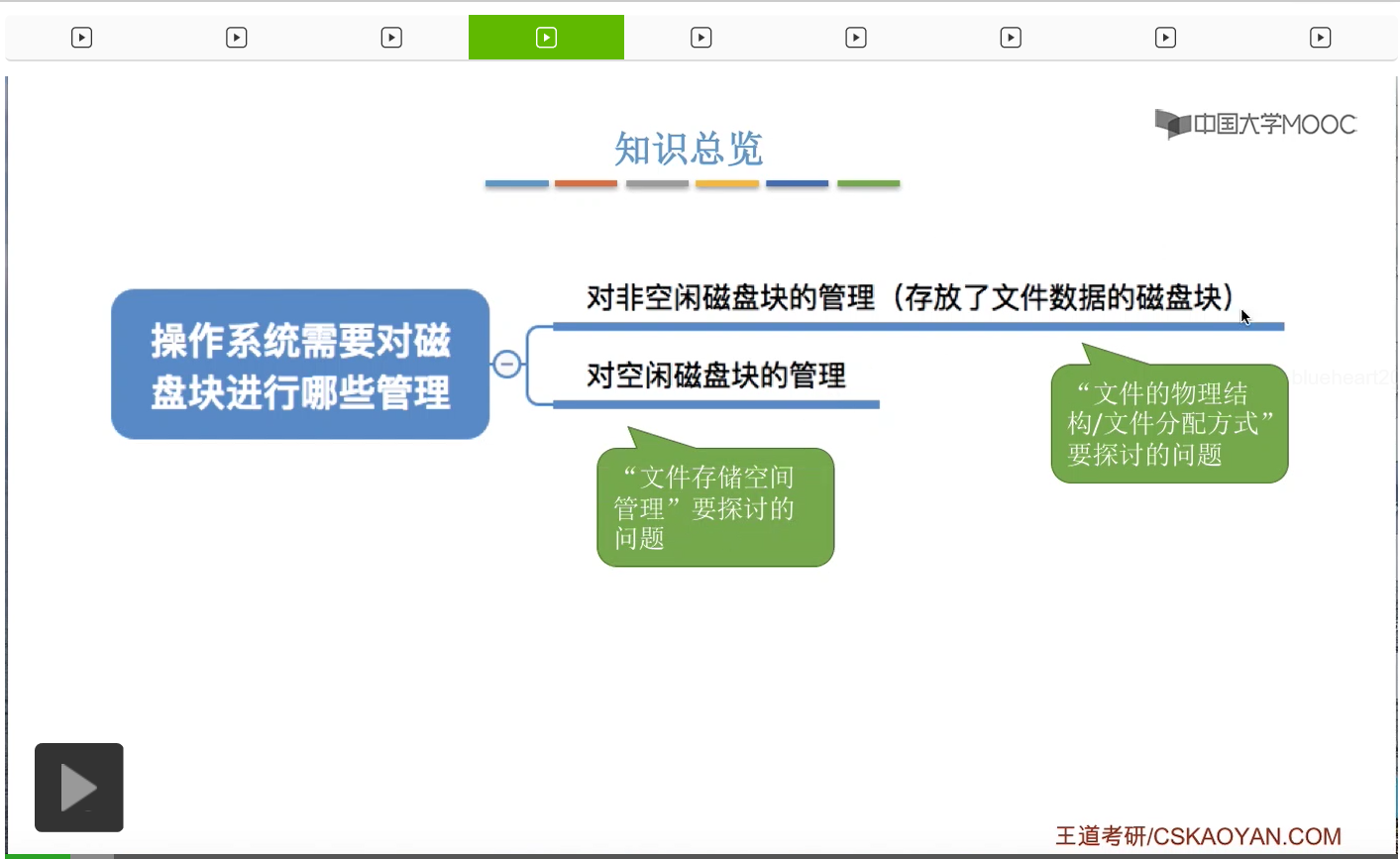
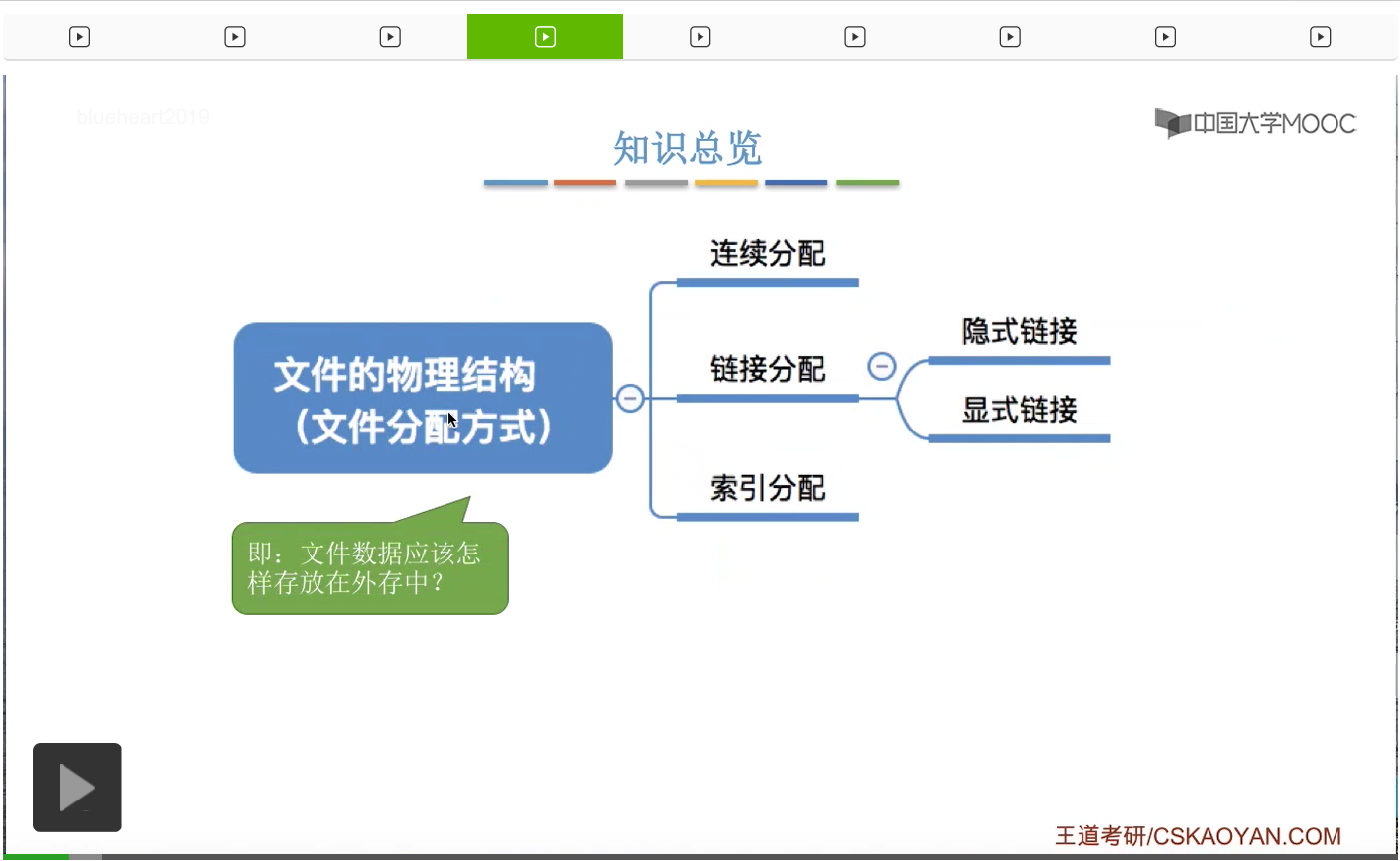
其实文件物理结构或者说文件分配方式要探讨的就是,文件的数据到底应该怎样存放在外存中。这些数据应该被怎样组织起来的一个问题。那总共被分为这样的三个模式,连续分配、链接分配和索引分配。那其中链接分配又可以进一步细分为隐式链接和显式链接这样的两种。在这个视频当中,我们首先探讨连续分配和链接分配这两种方式。那索引分配会在下个小节中再进行讲解。
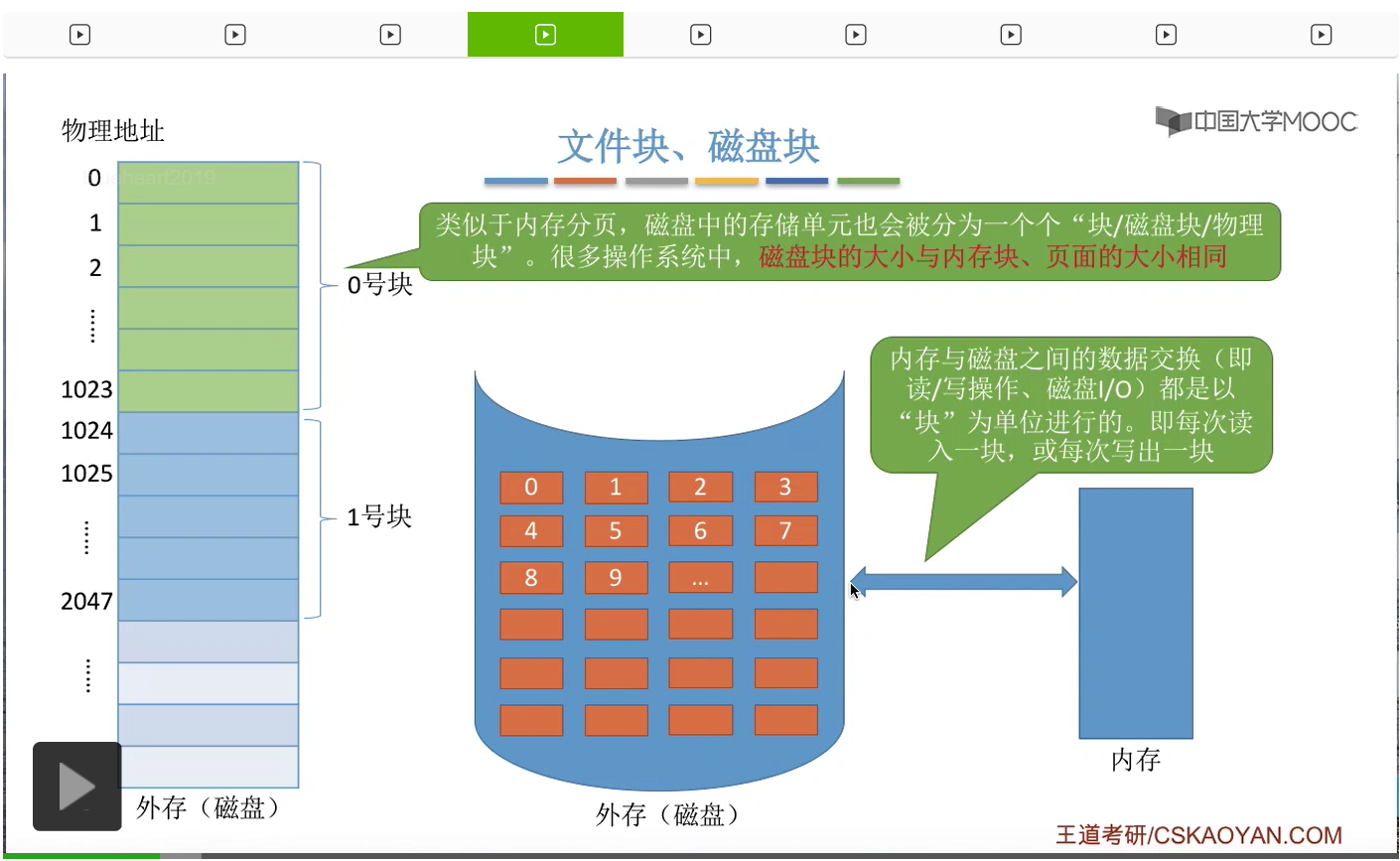
那在正式开始之前我们需要先补充几个比较重要的知识点。在之前我们简单地提到过,类似于内存分页,磁盘中的这些存储单元会被分为一个个大小相等的块。那这些块也可以称为磁盘块或者物理块。相应的,系统也会为这些磁盘块进行一个编号。那像这个是0号块,这个1号块,依此类推。另外,在很多操作系统当中,磁盘块的大小会设置的和内存块、内存页面的大小相同。

那这么做是有好处的。因为内存和外存之间的数据交换,也就是对磁盘的读写操作,都是以块为单位进行的。每次读入一块,或者每次写出一块。那如果说能够保证外存的一个磁盘块和内存的一个内存块的大小是相等的,那么进行这种数据交换的时候就会很方便。
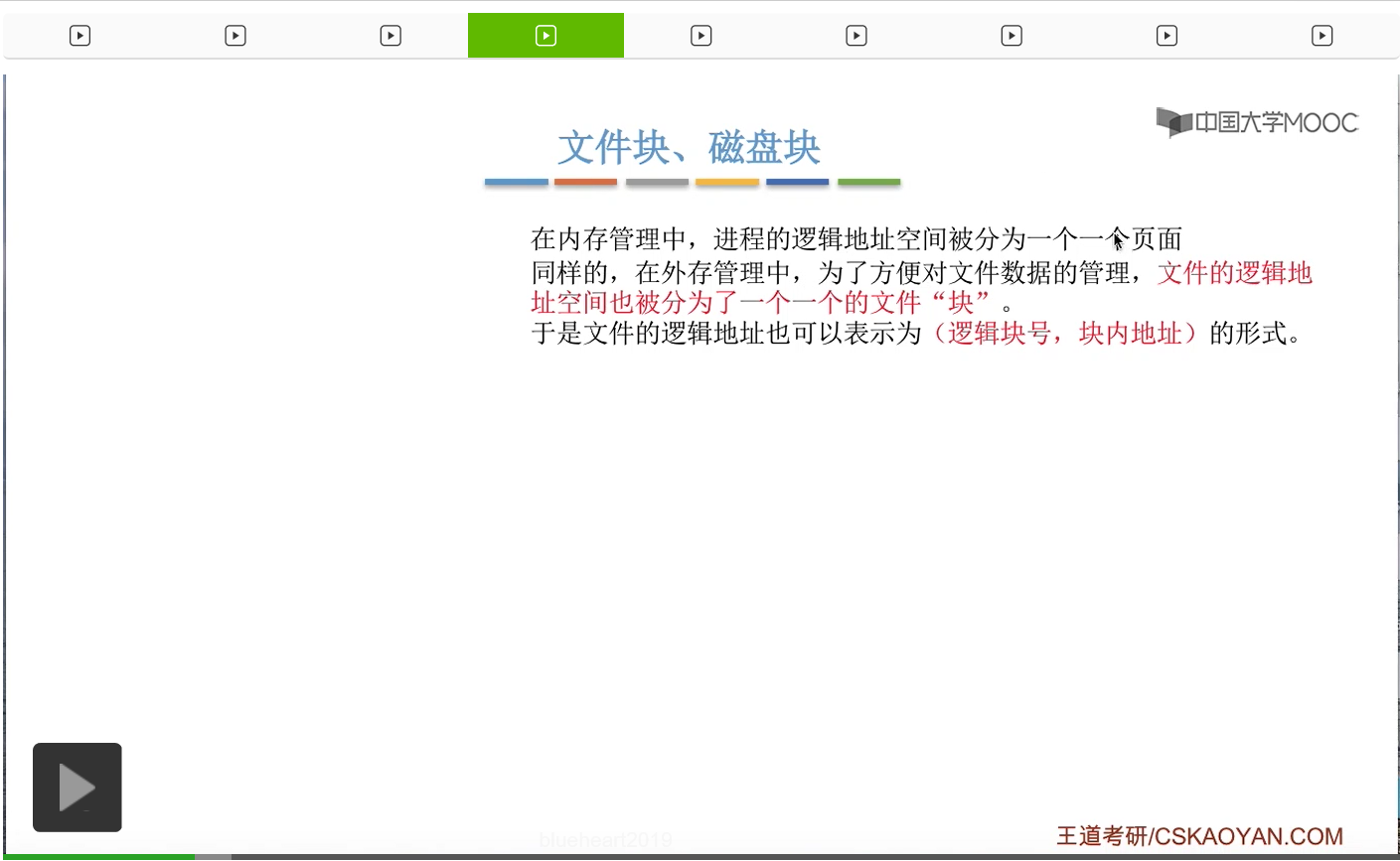
那在之前内存管理那个章节中我们学习过,进程的逻辑地址空间会被划分为一个一个的页面,这样可以方便操作系统对进程进行管理。那相应的,在外存管理当中,为了方便对文件数据的管理,文件的逻辑地址空间,也会被划分成一个一个大小相等的文件快。因此,文件的逻辑地址也可以表示为逻辑块号和块内地址的形式,那这就类似于一个进程的逻辑地址可以表示为页号和页内地址的形式。
就像这个样子。那假设,这个系统当中一个物理块的大小是1KB,那么1个1M字节大小的文件就可以分割为1K个块,所以这个文件的逻辑块号应该是从0到1023,总共1K个块号。并且每一块的大小都是1KB这么大,因此用户在操作自己的文件的时候可以用逻辑块号还有块内地址这样的形式就可以定位到自己文件当中的任何一个位置。
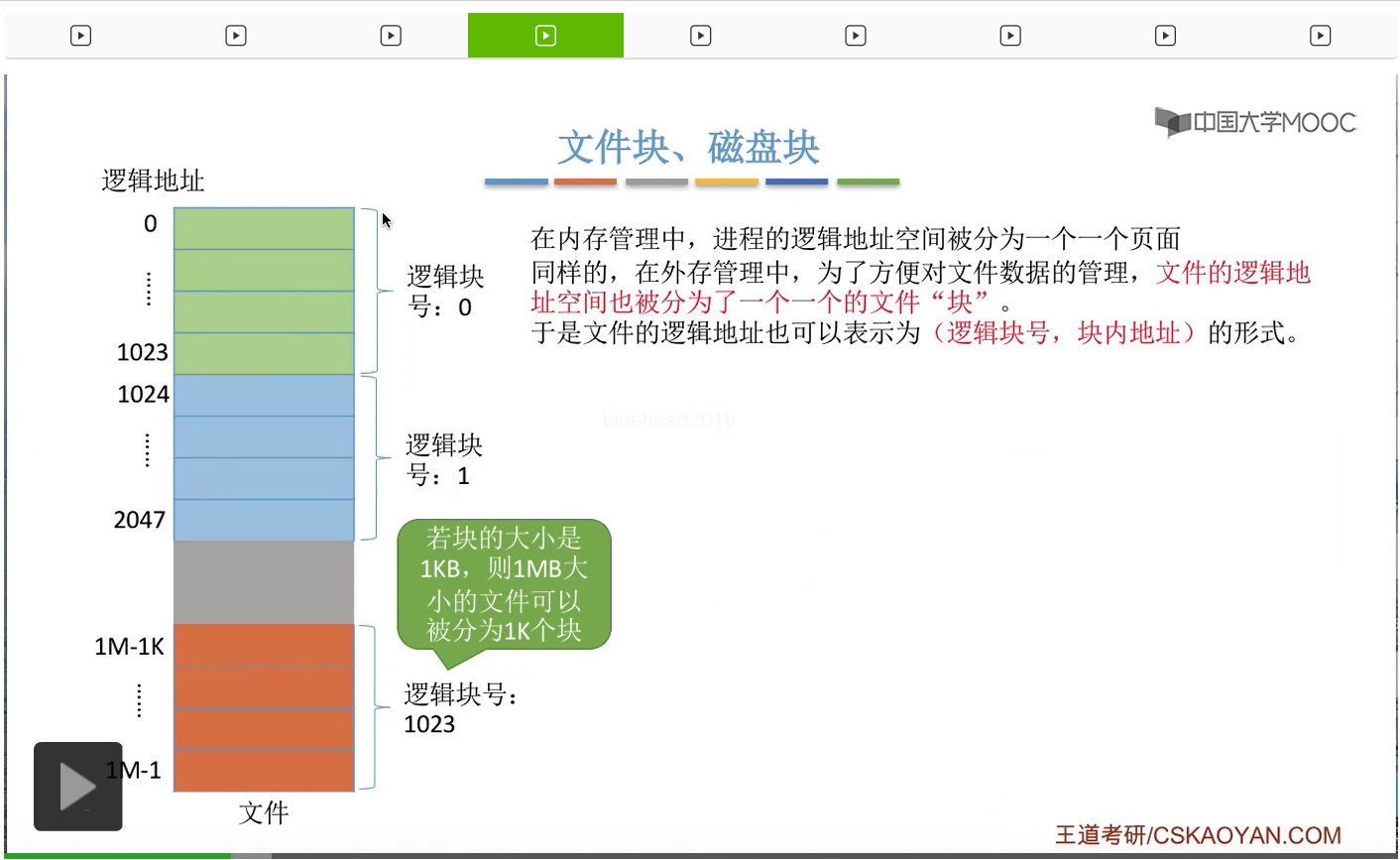
那这个文件的数据被分为一个一个的逻辑块之后,操作系统为文件分配存储空间,也都是以块为单位进行的。

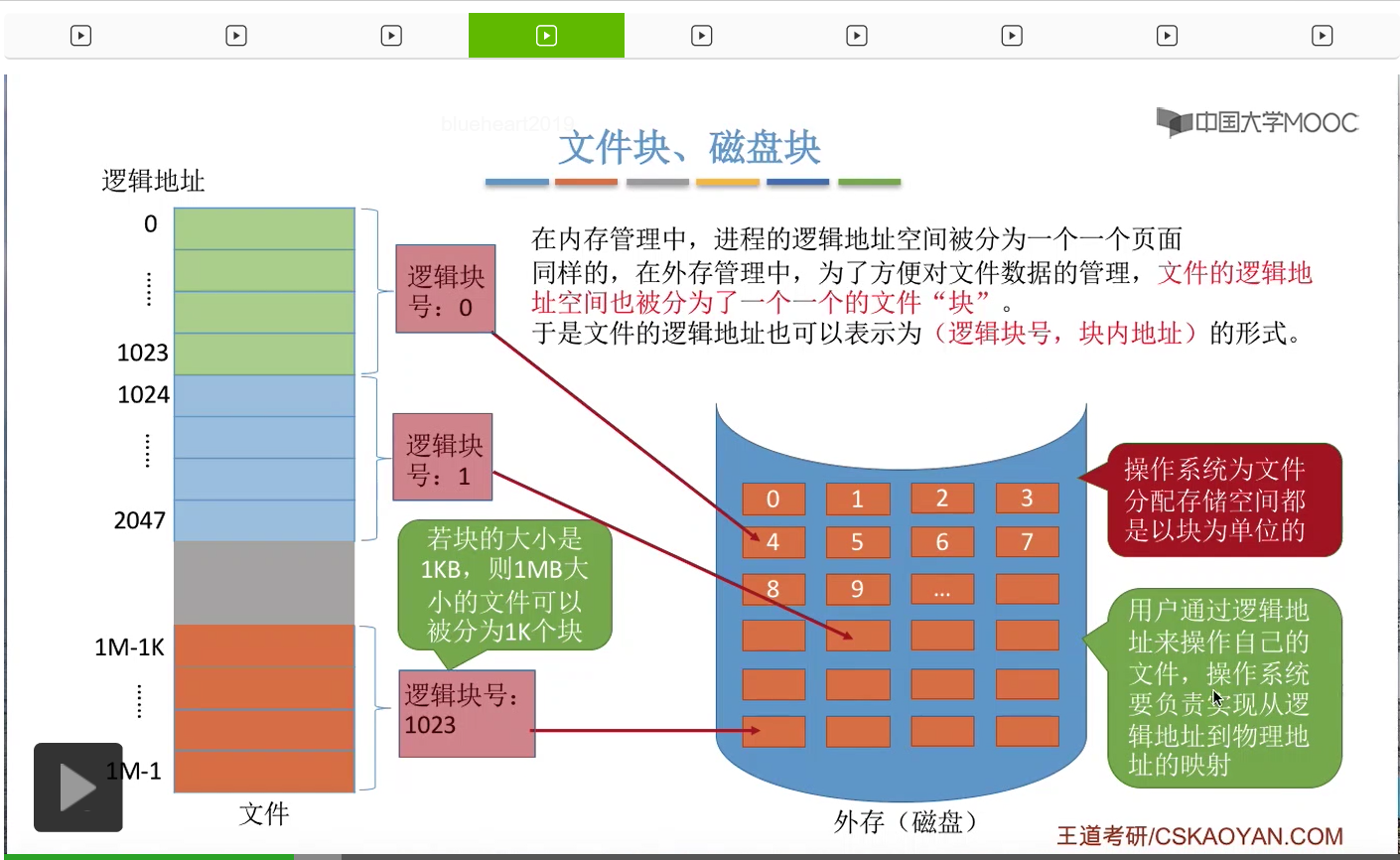
比如说,逻辑块号为0的这个块,被放到了物理块号为4的这个磁盘块当中。然后逻辑块号为1的这个块,放到这个位置。逻辑块号为1023,放到这个位置。不过用户对于自己的文件的这些各个逻辑块到底存放到了什么地方,这个信息用户是不可知的。
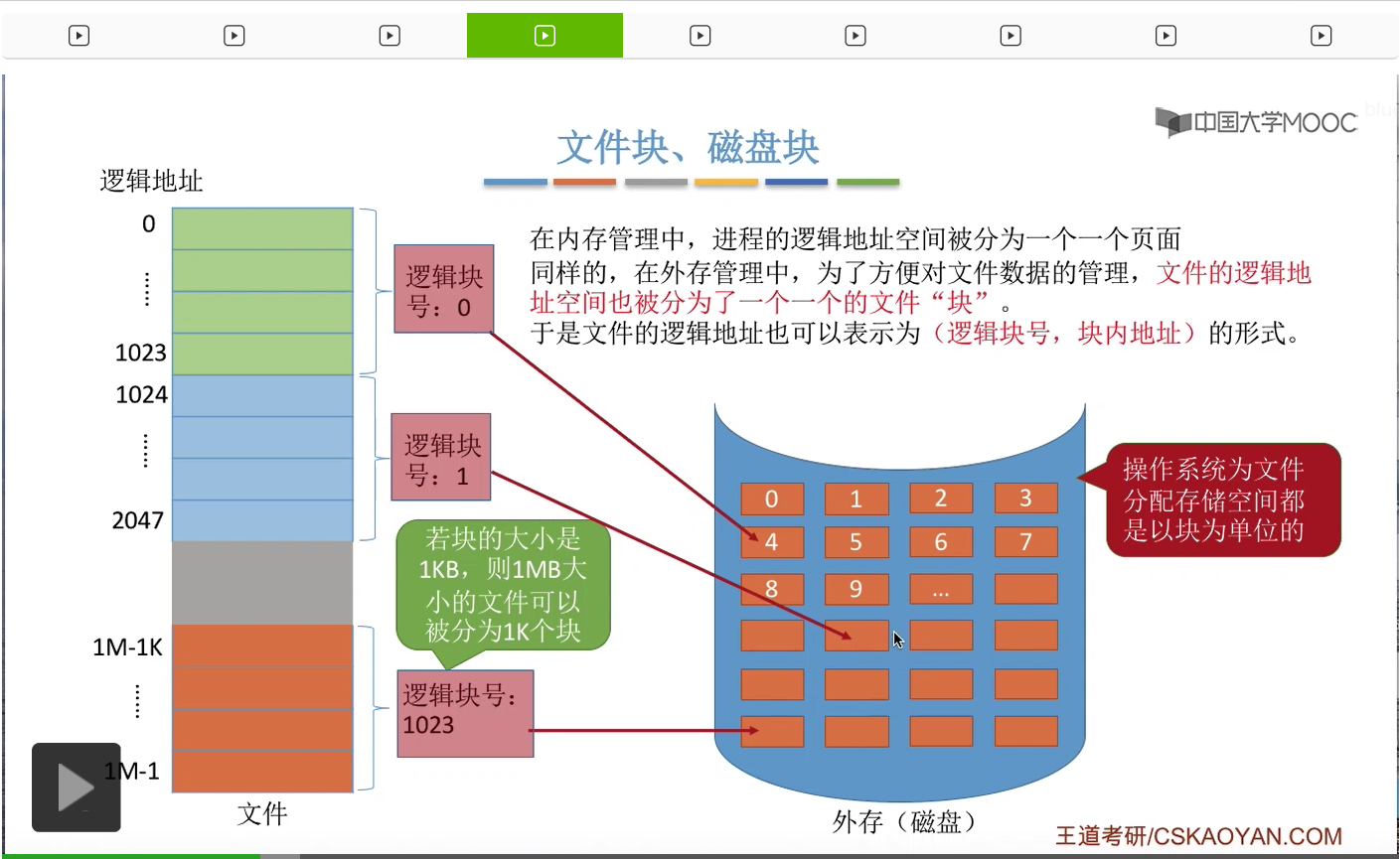
因此,用户在操作自己的文件的时候,是使用的是逻辑块号和块内地址这样的形式。于是操作系统就需要负责把用户提供的这个逻辑块号和块内地址转换为这个文件块实际存放的物理块号和块内地址,那这也是文件的分配方式,文件物理结构这个部分需要重点关注的核心问题——怎么把逻辑块号映射为物理块号。
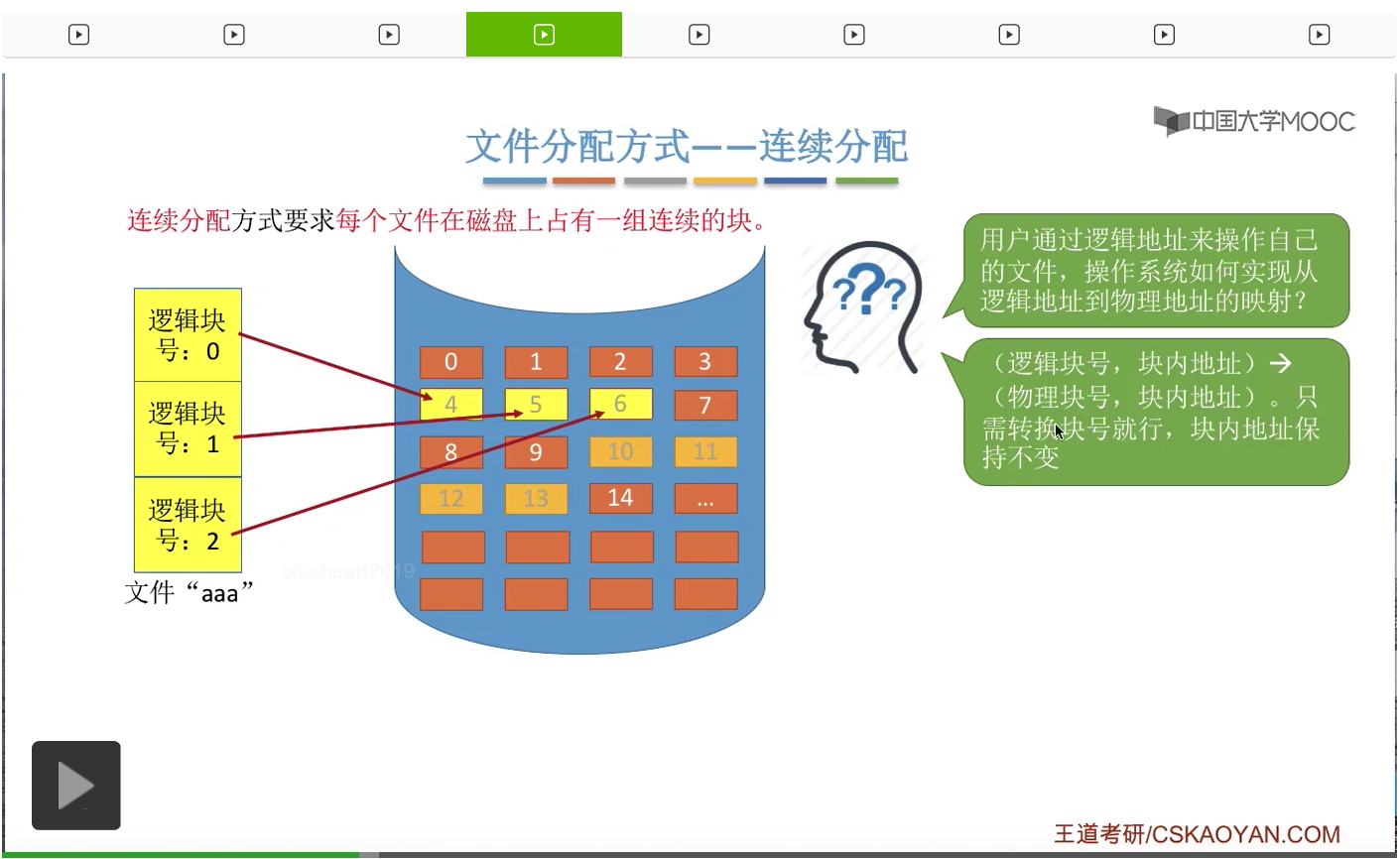
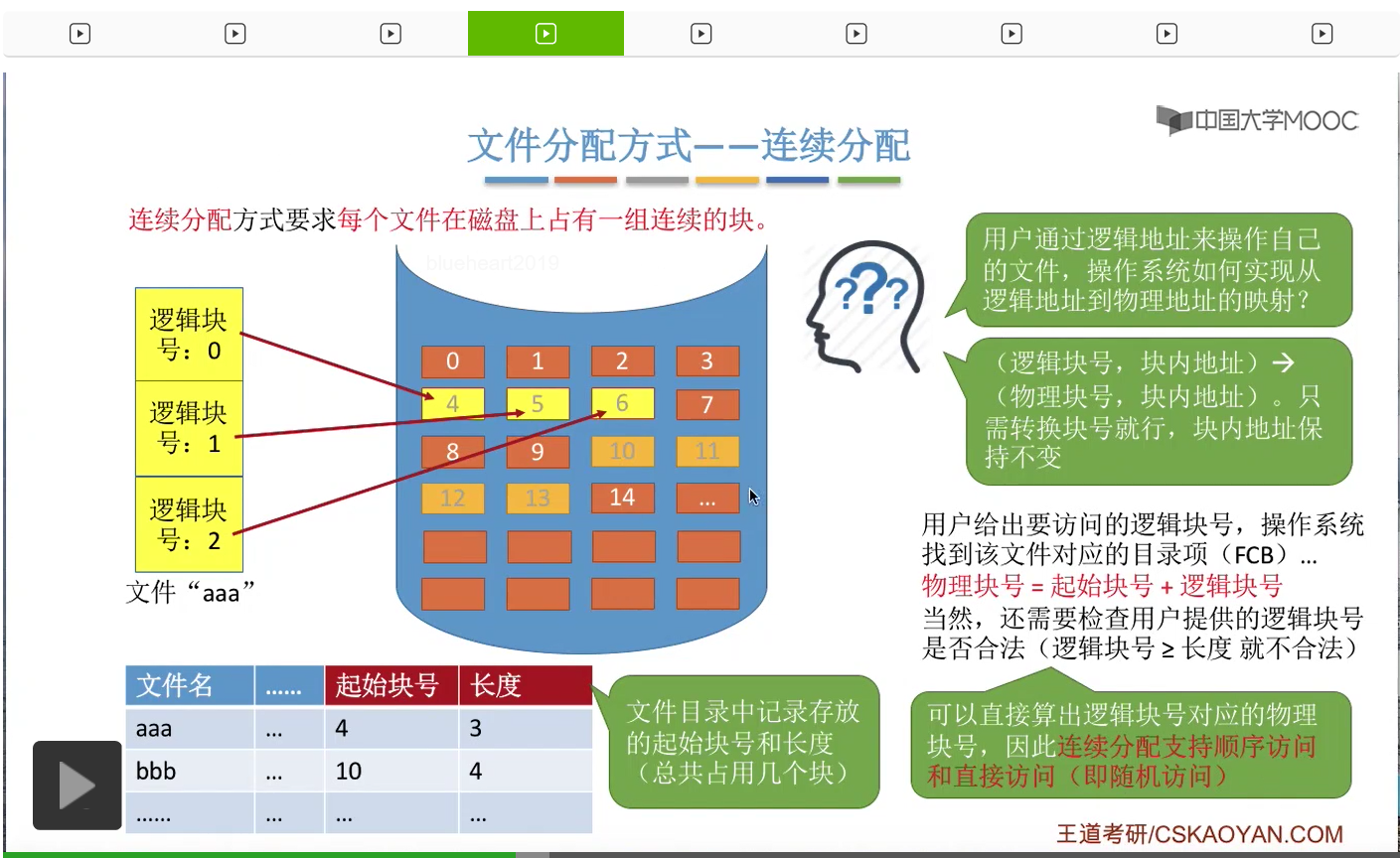
那我们首先来看第一种文件分配方式——连续分配。连续分配方式的思想很简单,要求每个文件在磁盘上占用一组连续的块。比如说一个文件“aaa”它在逻辑上可以分为这样的三个块。
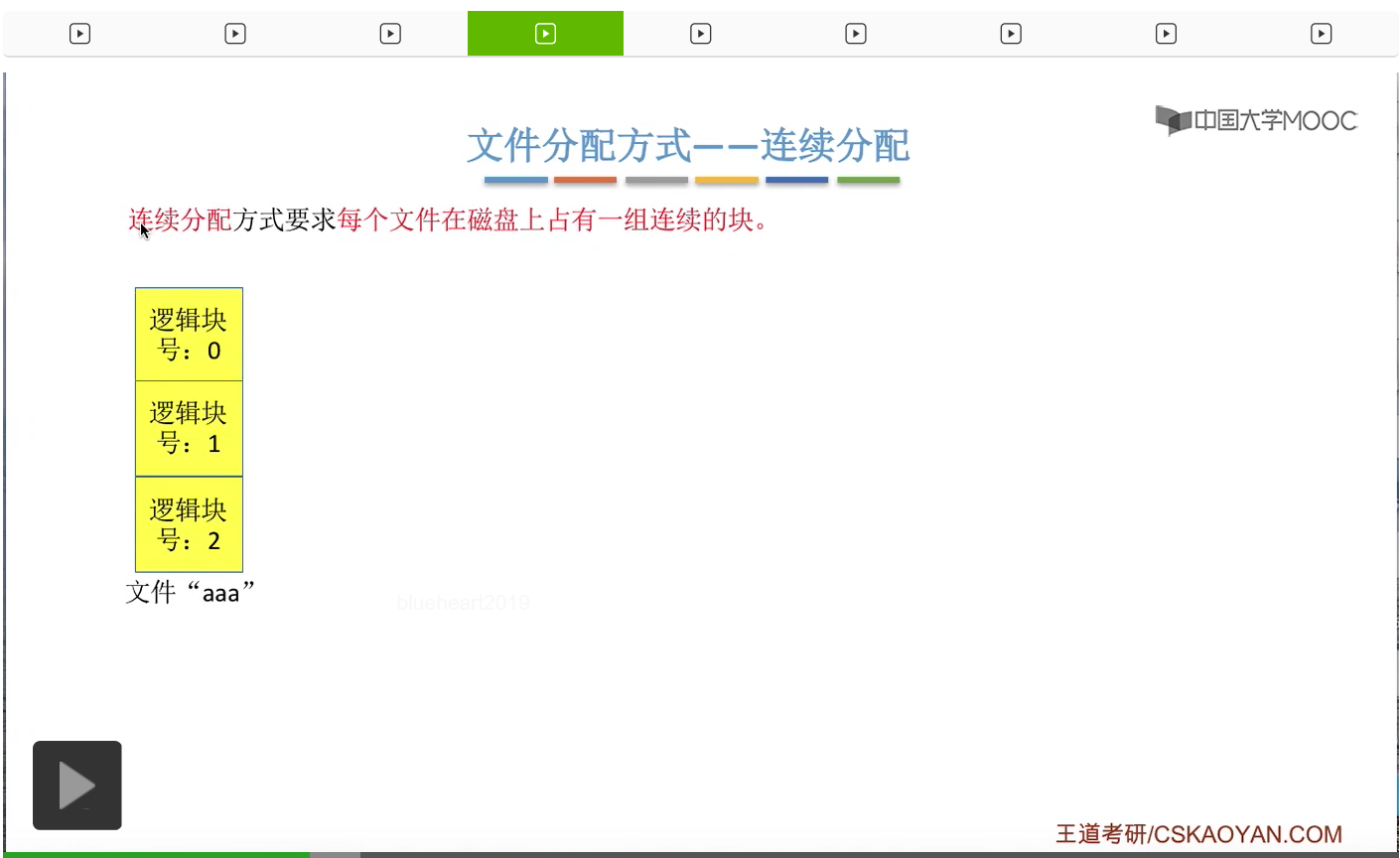
那如果说采用连续分配方式的话,那这些逻辑上相邻的块在物理上也必须相邻,也必须是占用一组连续的块,并且依然需要保持这些块之间的这种相对顺序。比如说0号逻辑块放到了4号物理块当中,1号逻辑块放到了5号物理块当中,2号逻辑块放到6号物理块当中。
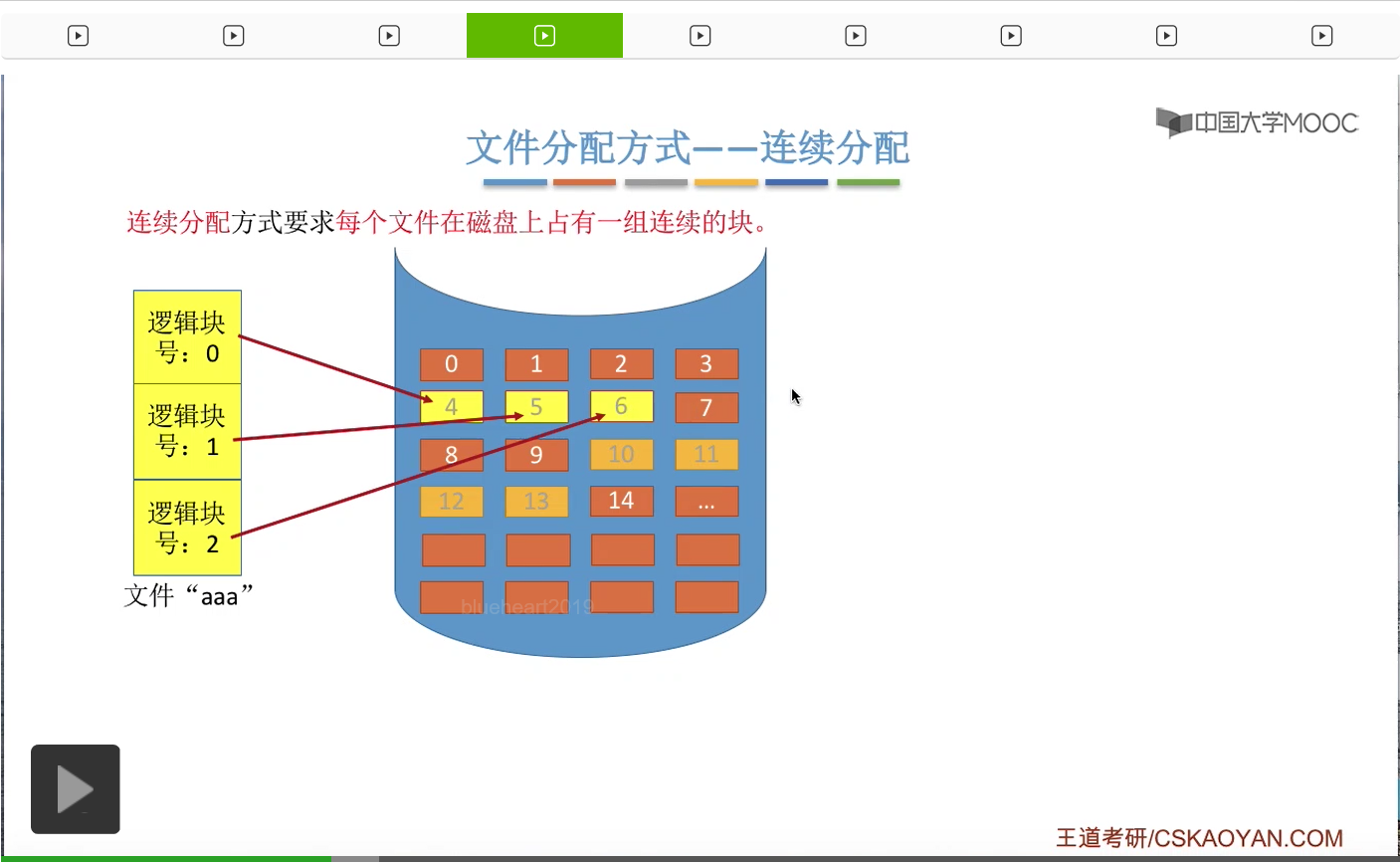
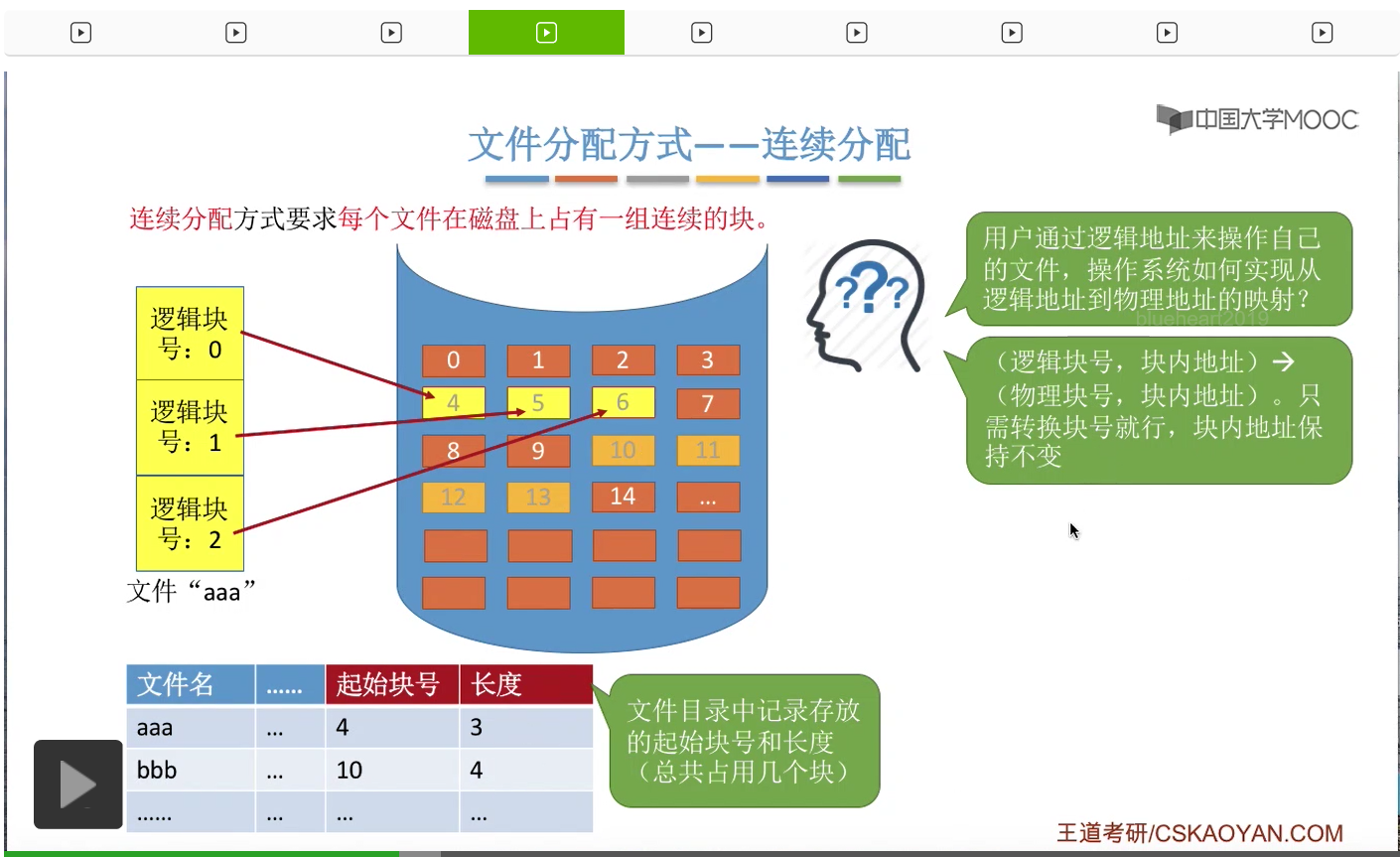
那接下来我们要注意的问题是,如果采用的是这种方式的话,那么操作系统应该如何实现从逻辑块号到物理块号的这种映射和转变呢?那首先我们需要明确的是,用户在操作自己的文件的时候,使用的是逻辑块号、块内地址这样的一个逻辑地址。那其实块内地址是不需要转变,因此操作系统只需要关心逻辑块号到物理块号的映射就可以了。
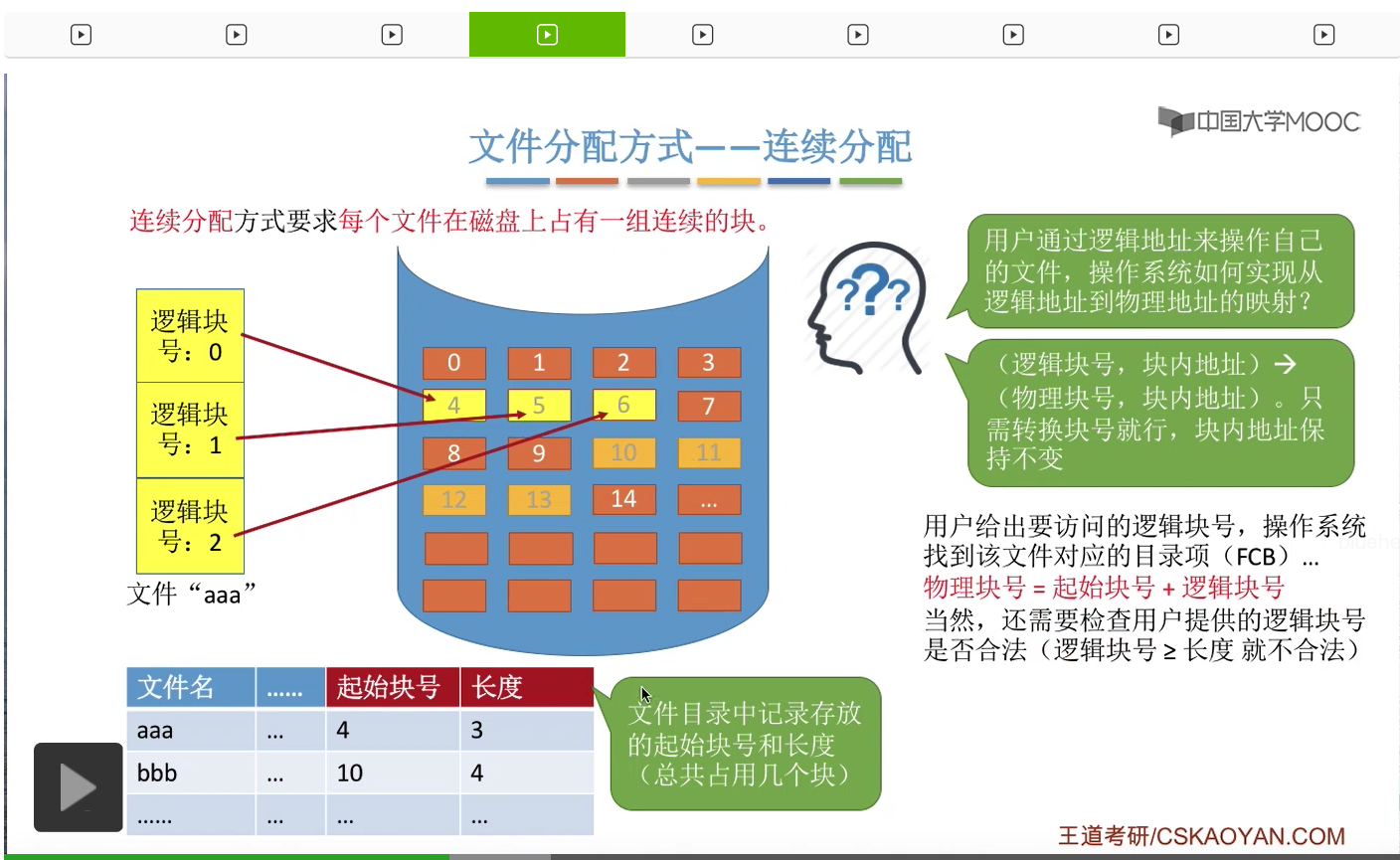
那为了实现这个地址映射的功能,在文件的目录表当中,必须记录两个文件的属性。第一是一个文件存放的起始块号,第二是这个文件的长度,也就是它总共占用了都少个块。比如说像“aaa”这个文件,它的起始块号是4,并且它占用了连续的3个块,因此它的长度是3。而“bbb”另外一个文件,它的起始块号是10,然后它占用了连续的4个块,因此它的长度又是4。那有了这些信息,操作系统就可以完成这个地址转换的事情了。
假设用户给出了他想要访问的逻辑块号,那么操作系统需要先找到这个用户想要访问的文件对应的目录项,也就是FCB。那在这个FCB当中,就可以知道文件存放的起始块号,再用起始块号加上用户提供的逻辑块号就可以得到这个块存放的实际的物理块号了。比如说这个用户想要访问“aaa”这个文件的逻辑块号为2的这个块,那么逻辑块号2加上它的起始块号4就得到物理块号6。那么从这个图当中我们也可以看到,逻辑块号为2的这个块确实是存放在物理块号为6的这个位置的。

当然,操作系统还需要验证用户提供的这个逻辑块号是否合法,它是否已经超过了这个文件的实际长度。
所以通过刚才的这个分析我们会发现,如果采用的是连续分配方式的话,那么只要用户给出了自己想要访问的逻辑块号,操作系统就可以直接根据逻辑块号算出它对应的物理块号到底是多少。因此,我们说连续分配方式是支持顺序访问和直接访问,也就是随机访问的。那所谓的顺序访问就是指,如果我要访问逻辑块号2的话,那么我必须先顺序地访问逻辑块号0和逻辑块号1,之后才能找到逻辑块号2,这是顺序访问。而所谓的直接访问或者说随机访问就是指,如果我要访问逻辑块号2的话,那我并不需要访问其他的这些块,我可以直接找到逻辑块号2存放的位置,所以这是顺序访问和直接访问的含义。那支持直接访问或者说随机访问也是连续分配方式最大的一个优点。
那我们再来分析连续分配方式的第二个优点,这个地方我们需要用到一个现在暂时还没有讲过的知识点。磁盘这种硬件想要读取一个磁盘块的时候,需要把磁头放到那个磁盘块相应的位置。而访问不同的磁盘块,是需要移动磁头的。并且如果两个磁盘块的距离越远,那么移动磁头所需要的时间就越长。比如说,我现在需要连续地读这三个黄色的块,那么首先是把磁头放到第一个块的位置,之后移动到第二块的位置,再之后再移动到第三个块的位置。所以由于这三个块它们之间在物理上是相邻的,也就是它们相距距离是最短的,因此这个移动的过程其实磁头的移动距离也是最短的。而假如我们此时想要读取的是紫色的这三个磁盘块的话,那么首先需要把磁头移动到第一个这个块对应的位置,读完了第一个块之后,需要移动磁盘而移动到第二个位置。而读完第二个磁盘块之后,也需要再移动磁盘,然后把它移动到第三个块的位置。因此如果这些块不相邻的话,那么读取一个块和下一块之间所需要的移动磁头的时间就会更长。

因此基于这个分析我们知道,如果一个文件采用的是连续分配的方式的话,那么我们在顺序地读取这个文件的各个块的时候,所需要的读写时间是最短的,读写速度是最快的。因为整个过程所需要的磁头移动距离是最短的。那这个知识点咱们还会在之后再进行进一步的探讨。这个地方我们只需要理解,连续分配的文件在顺序读写的时候速度最快,只需要理解这一点就可以了。那这是连续分配方式的第二个优点。

接下来我们来看一下连续分配方式有哪些缺点。
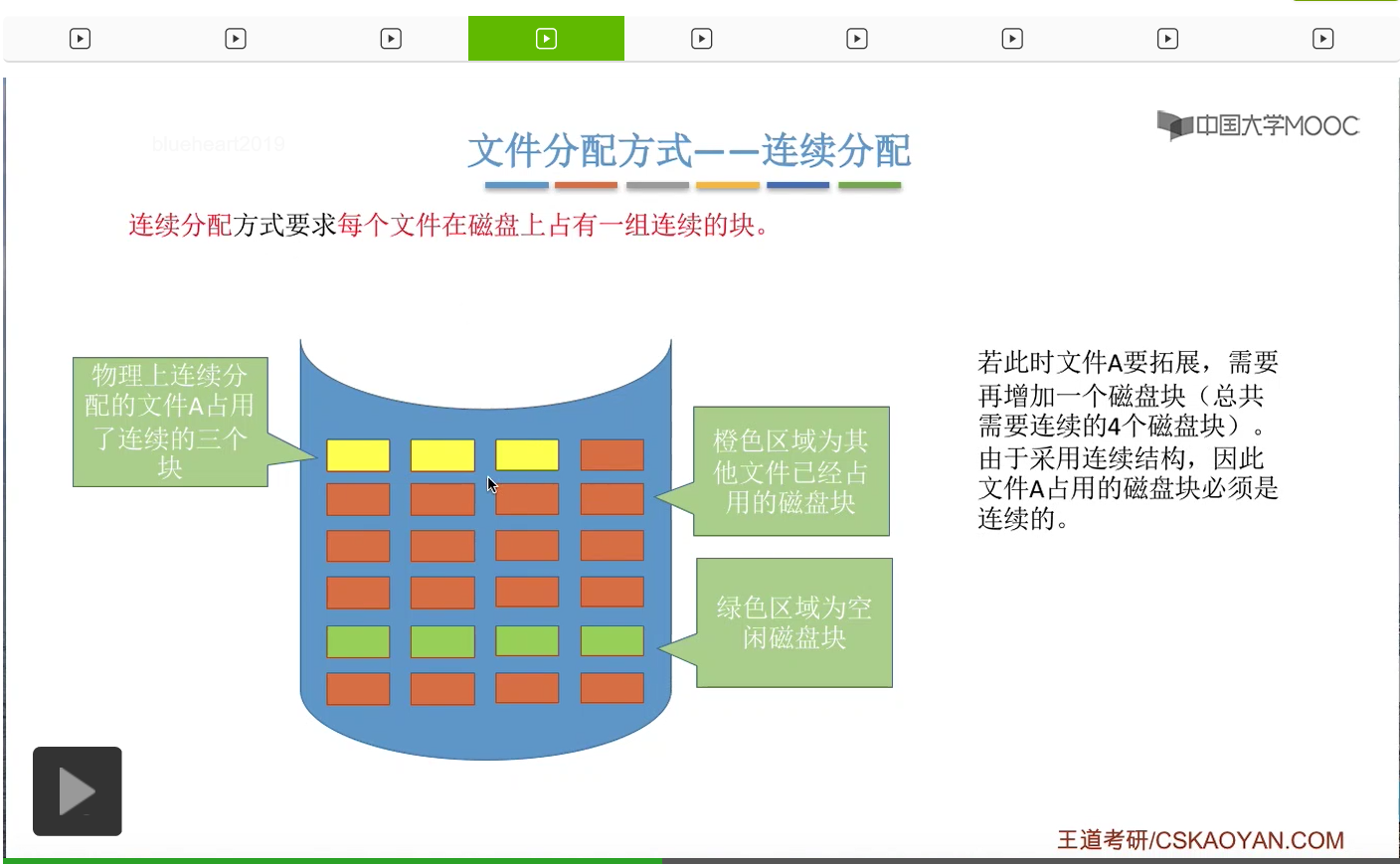
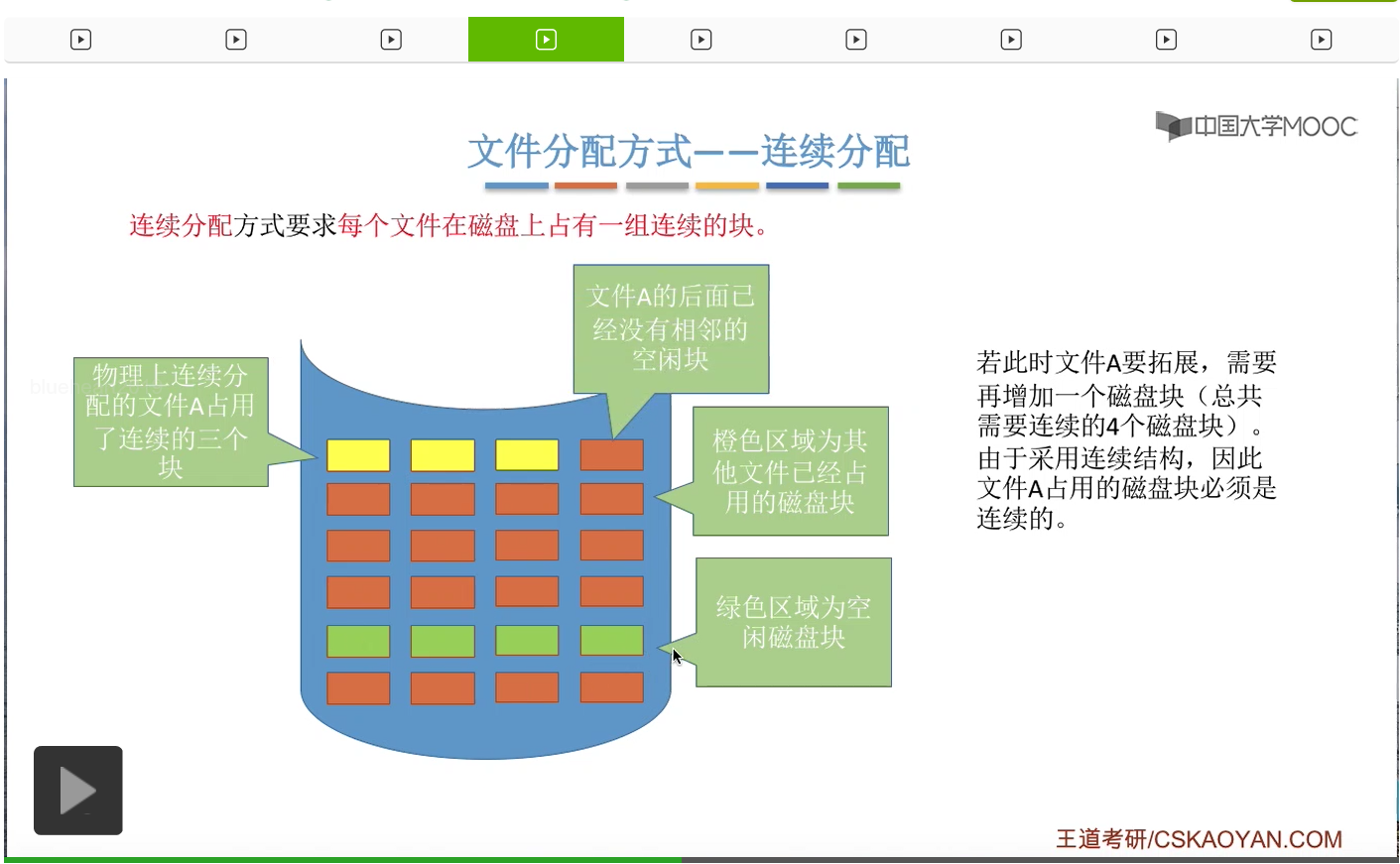
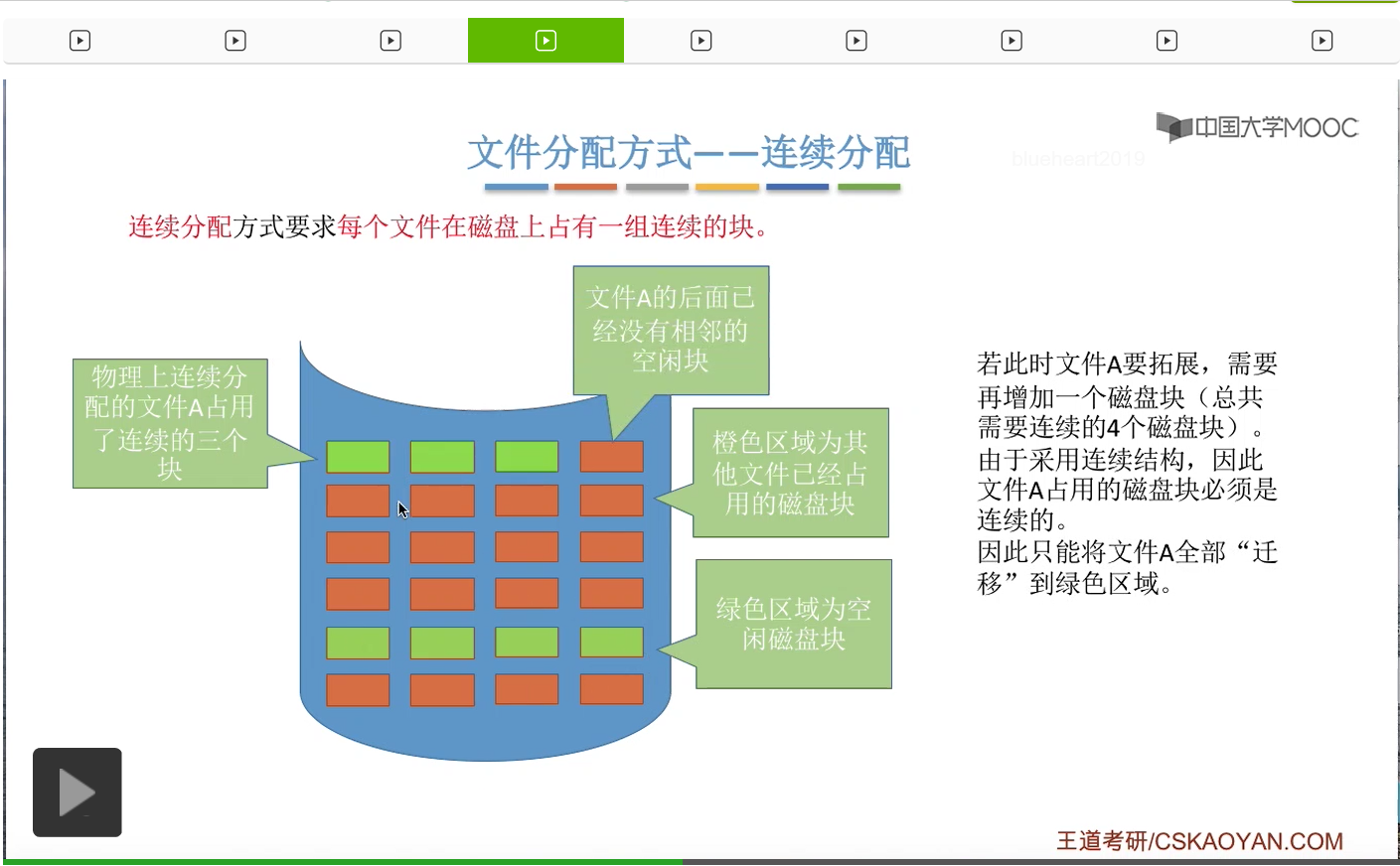
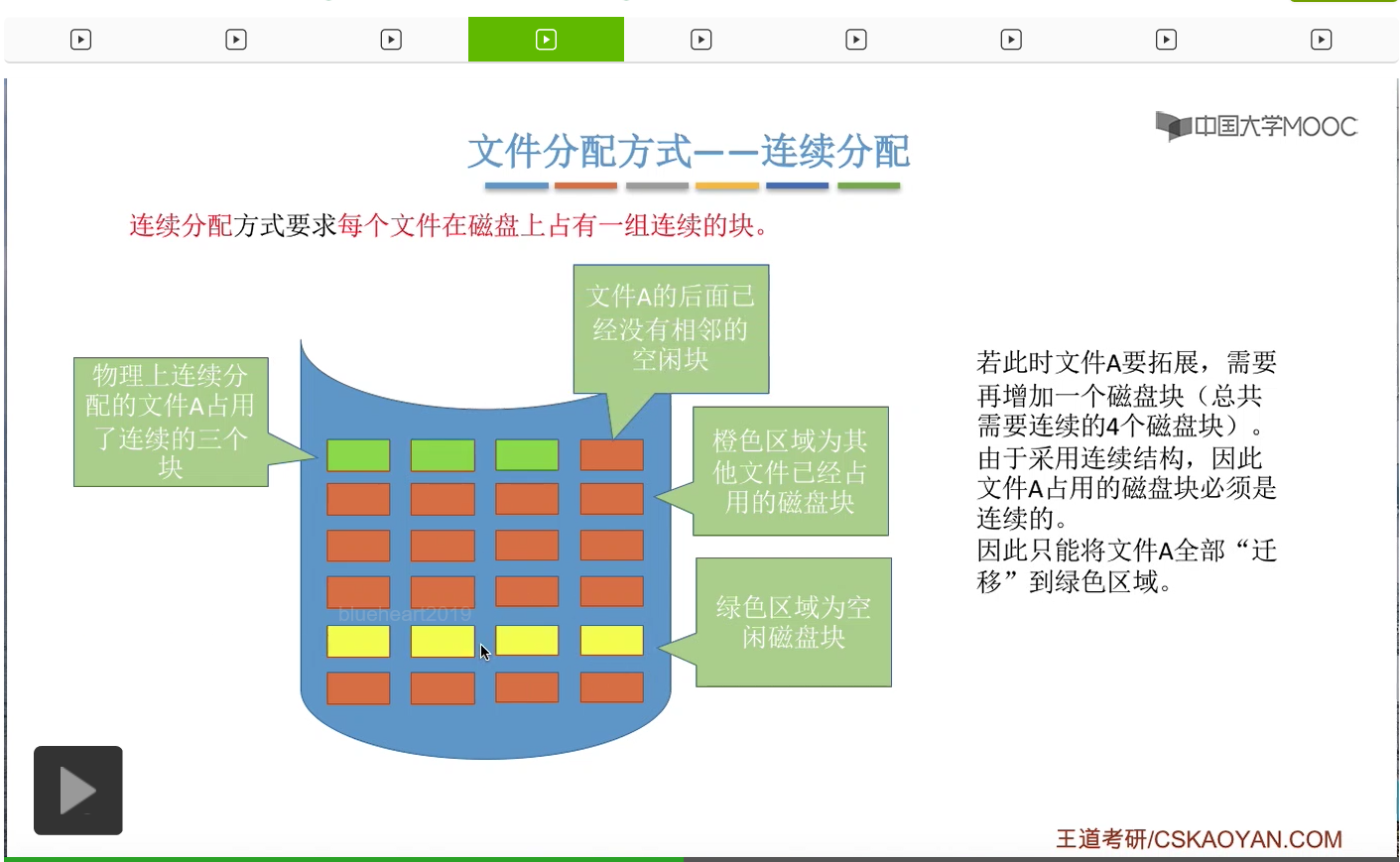
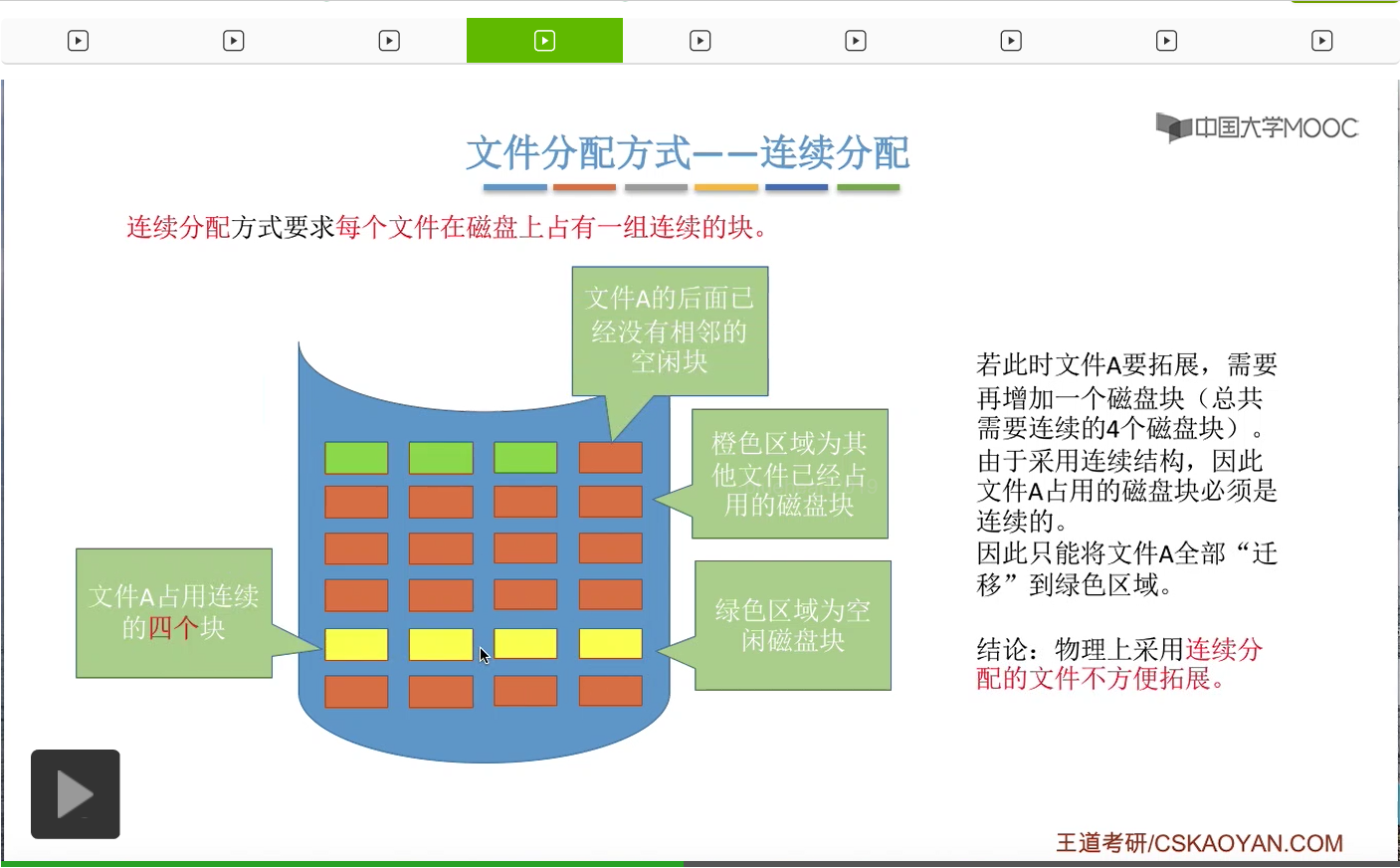
那进行数据迁移的这个过程其实是需要耗费很大的那个开销的,所以我们得出一个结论:由于连续分配方式要求文件在磁盘上占有的必须是一组连续的块,因此对文件的拓展是很不方便的。那这是它的一个缺点。

再来看第二个缺点。假设此时在这个图当中,
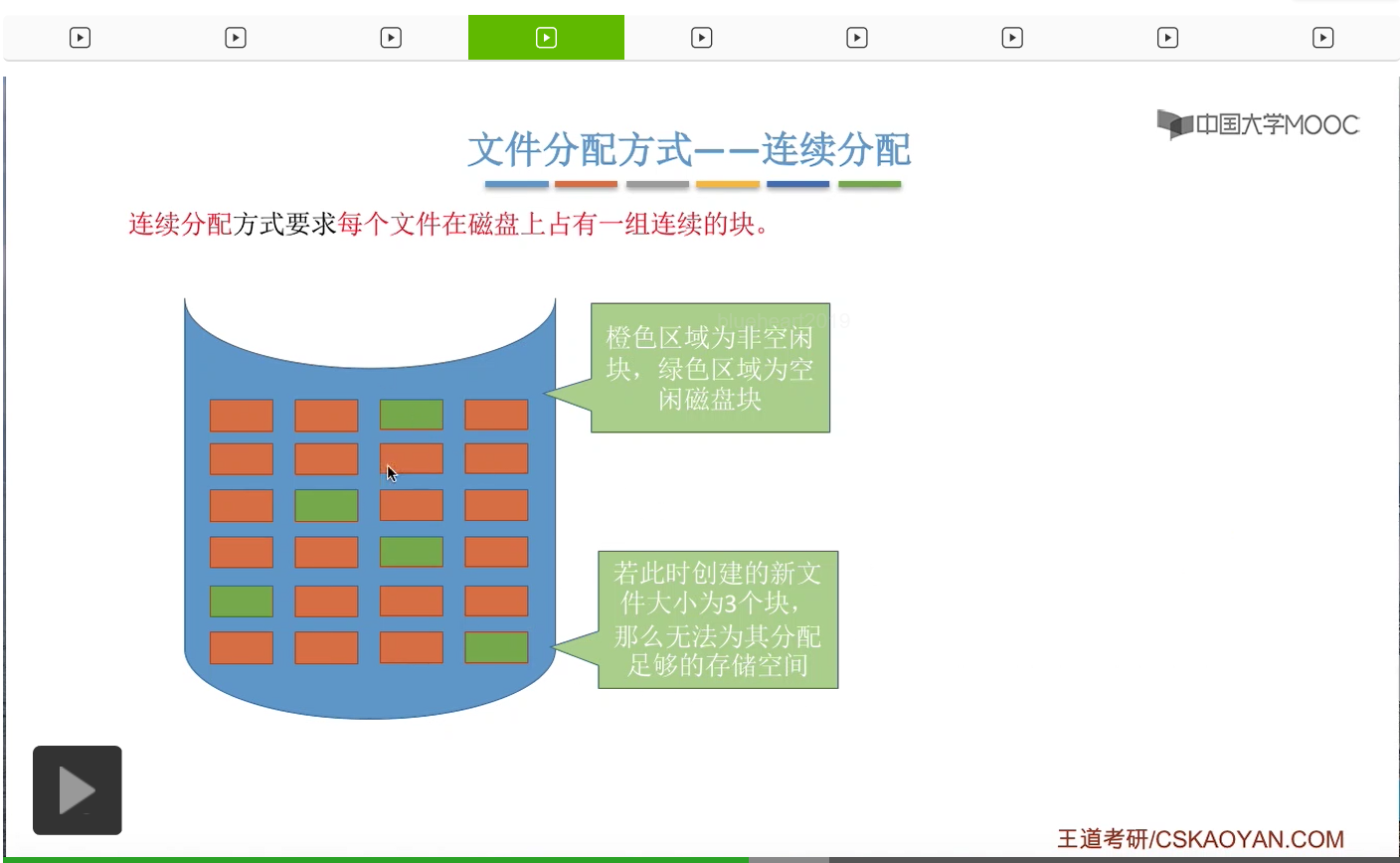
而这些磁盘碎片就有点类似于咱们在之前内存管理当中讲过的那种外部碎片。那处理这些碎片的方式,也和处理外部碎片的思想是一样的。可以用紧凑的方式来解决。不过紧凑就意味着需要移动大量的这些磁盘块的内容,那这个过程是需要花费很大的时间代价的。因此会产生磁盘碎片这个问题,也是连续分配方式一个很明显的缺点。
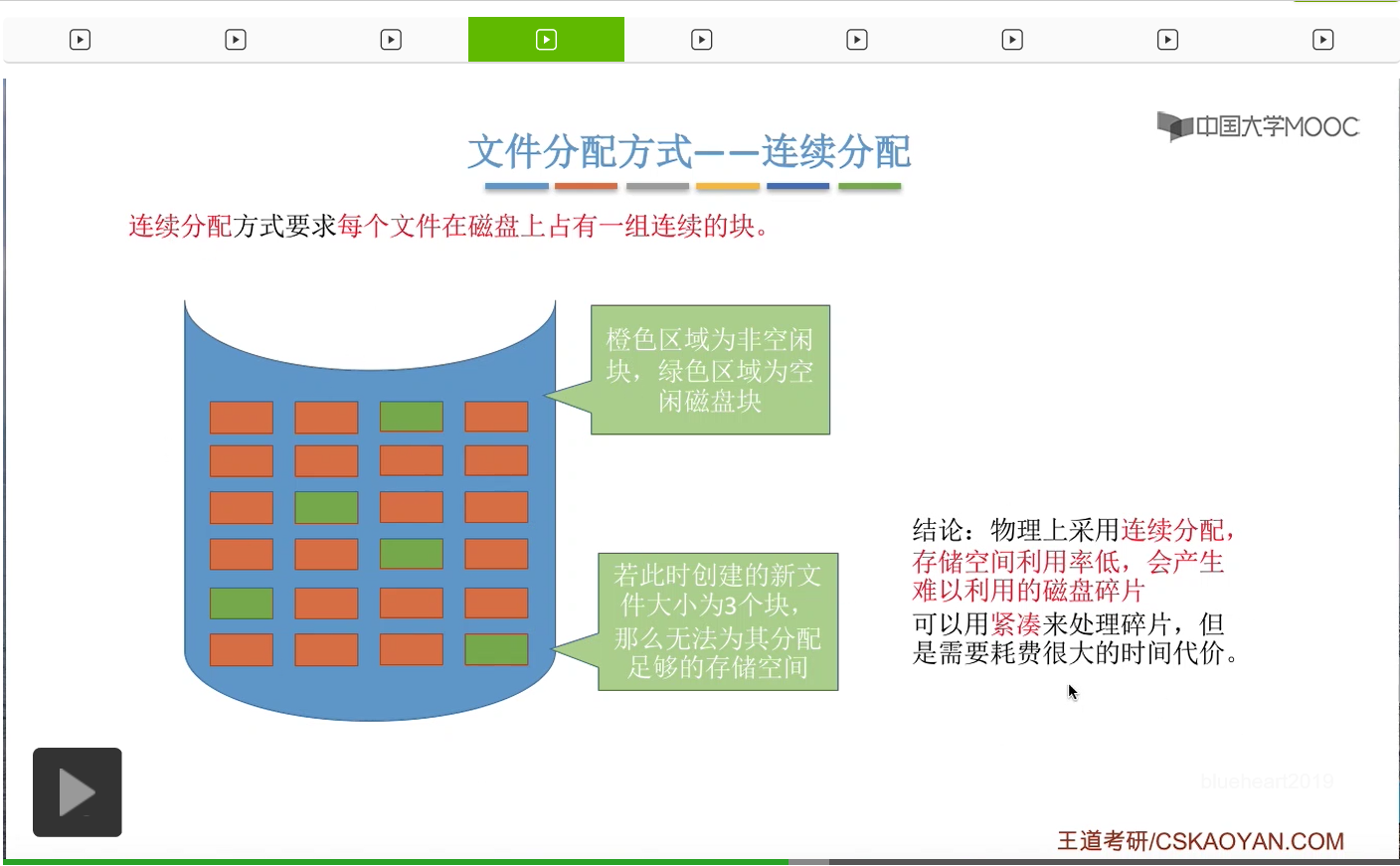
所以连续分配方式要求每个文件在磁盘上占用一组连续的块。它的优点是支持顺序访问和直接访问也就是随机访问,并且连续分配的文件在顺序访问时速度是最快的。但是它也有一些缺点,就是不方便文件的拓展,存储空间利用率低,会产生磁盘碎片。那这是连续分配方式我们需要掌握的一些知识点。

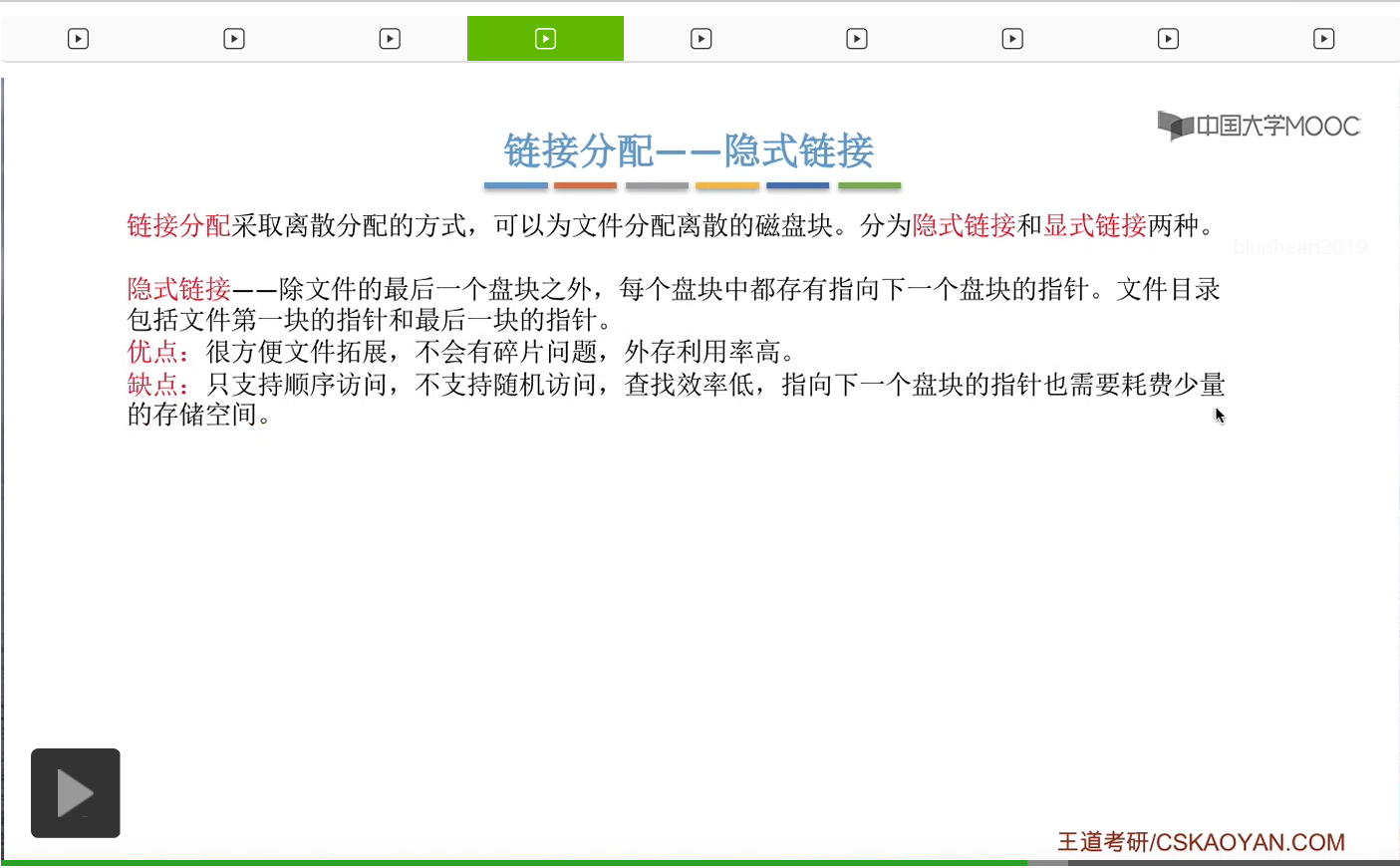
那接下来我们再来看第二种文件分配方式——链接分配。链接分配采取的是离散分配的这种思想,可以为文件分配离散的磁盘块,然后用指针链接的方式把它们、把这些磁盘块都给串联起来。而链接分配方式又可以进一步分为隐式链接和显式链接两种。
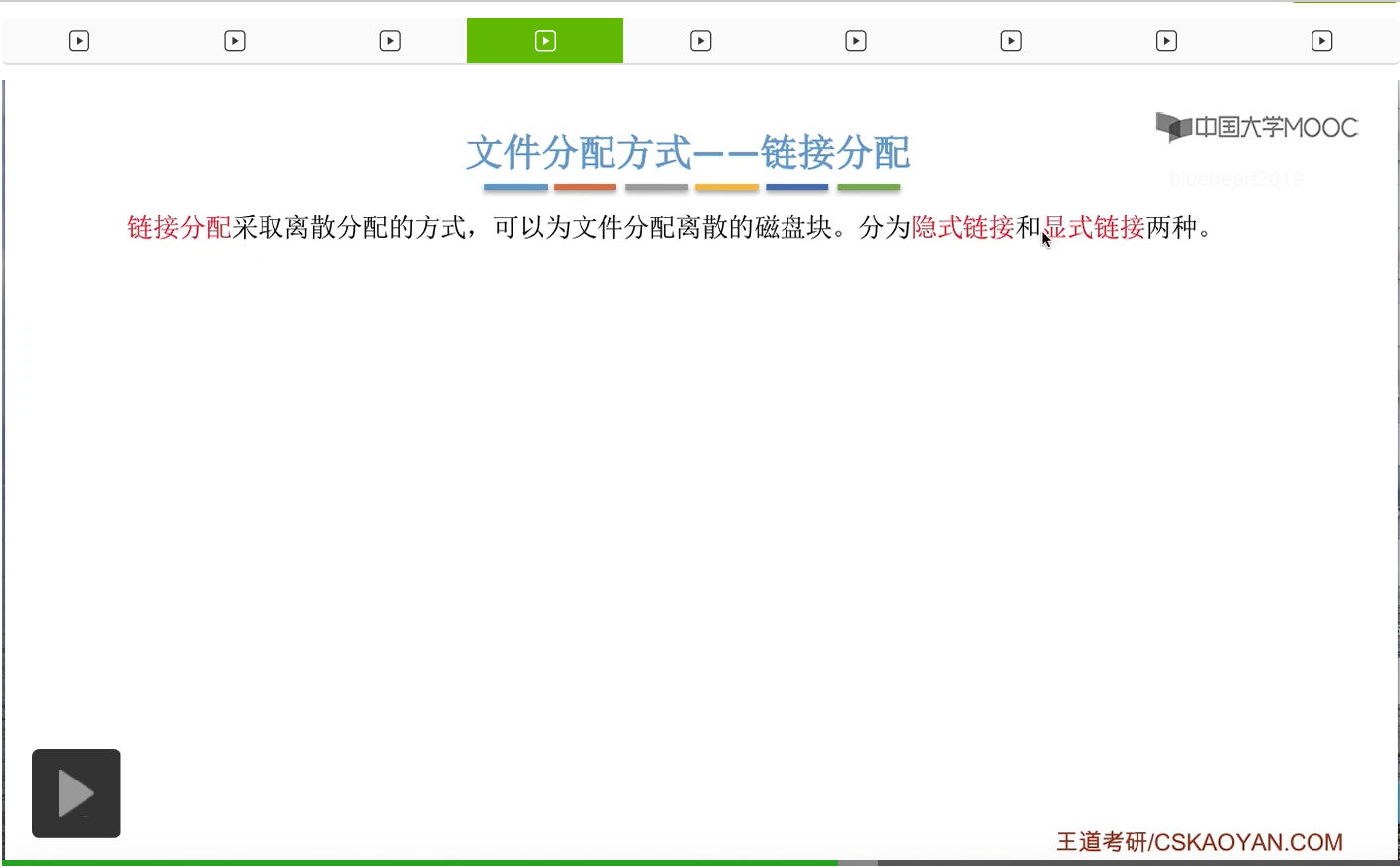
我们首先来看隐式链接这种方式。如果采用的是这种方式的话,那么在文件的目录项,也就是文件的FCB当中,需要记录这个文件的起始块号还有结束块号。另外,各个块之间都会有一定的存储空间存储指向下一块的这个链接指针,当然最后一个块是没有指向下一块的链接指针的。而这些指针对于用户来说是透明的。
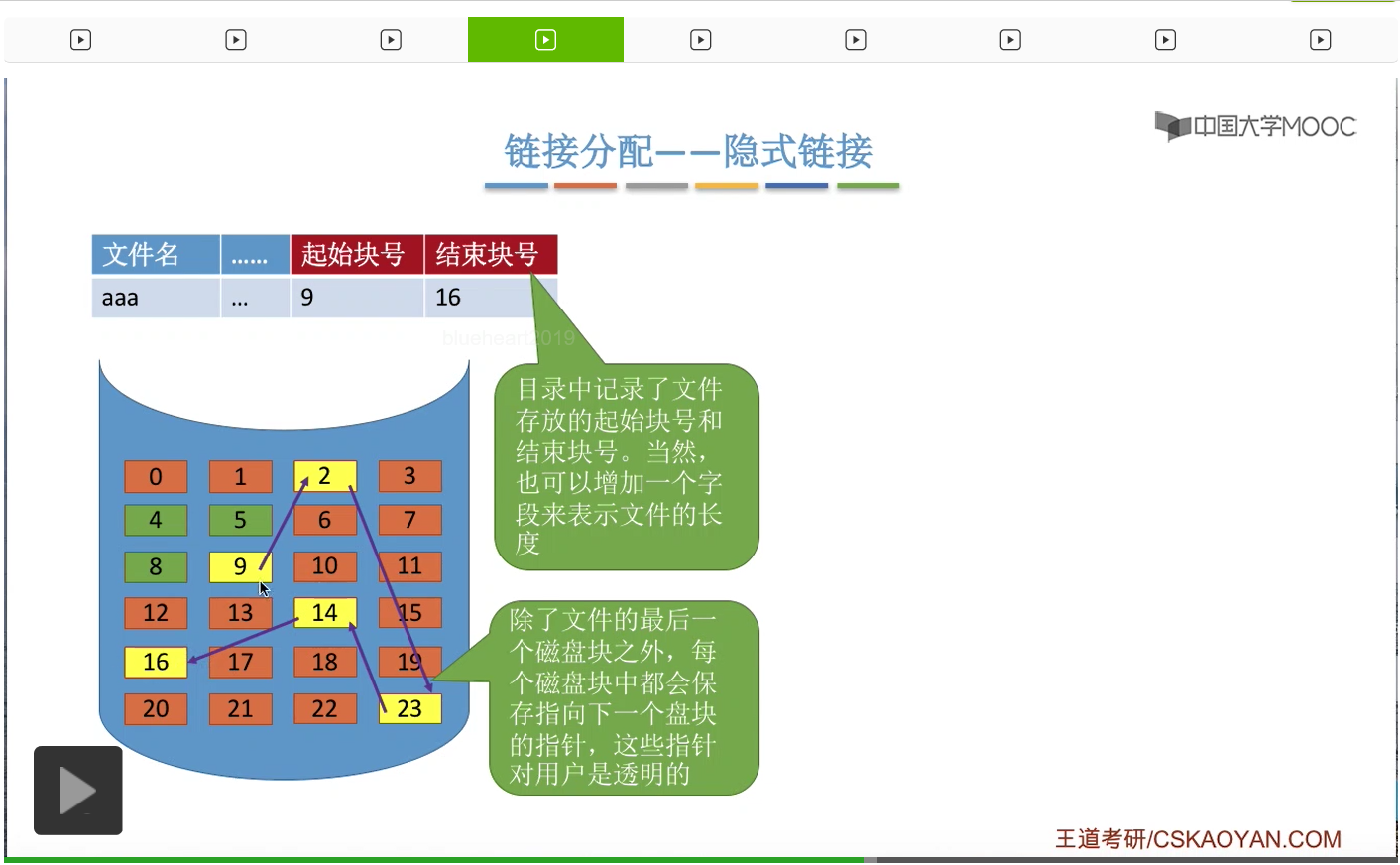
那采用这种方式的话,怎么实现逻辑块号到物理块号的转变呢?用户首先给出它要访问的逻辑块号i,然后操作系统会根据文件名找到它对应的FCB这个目录项,找到这个文件的起始块号。
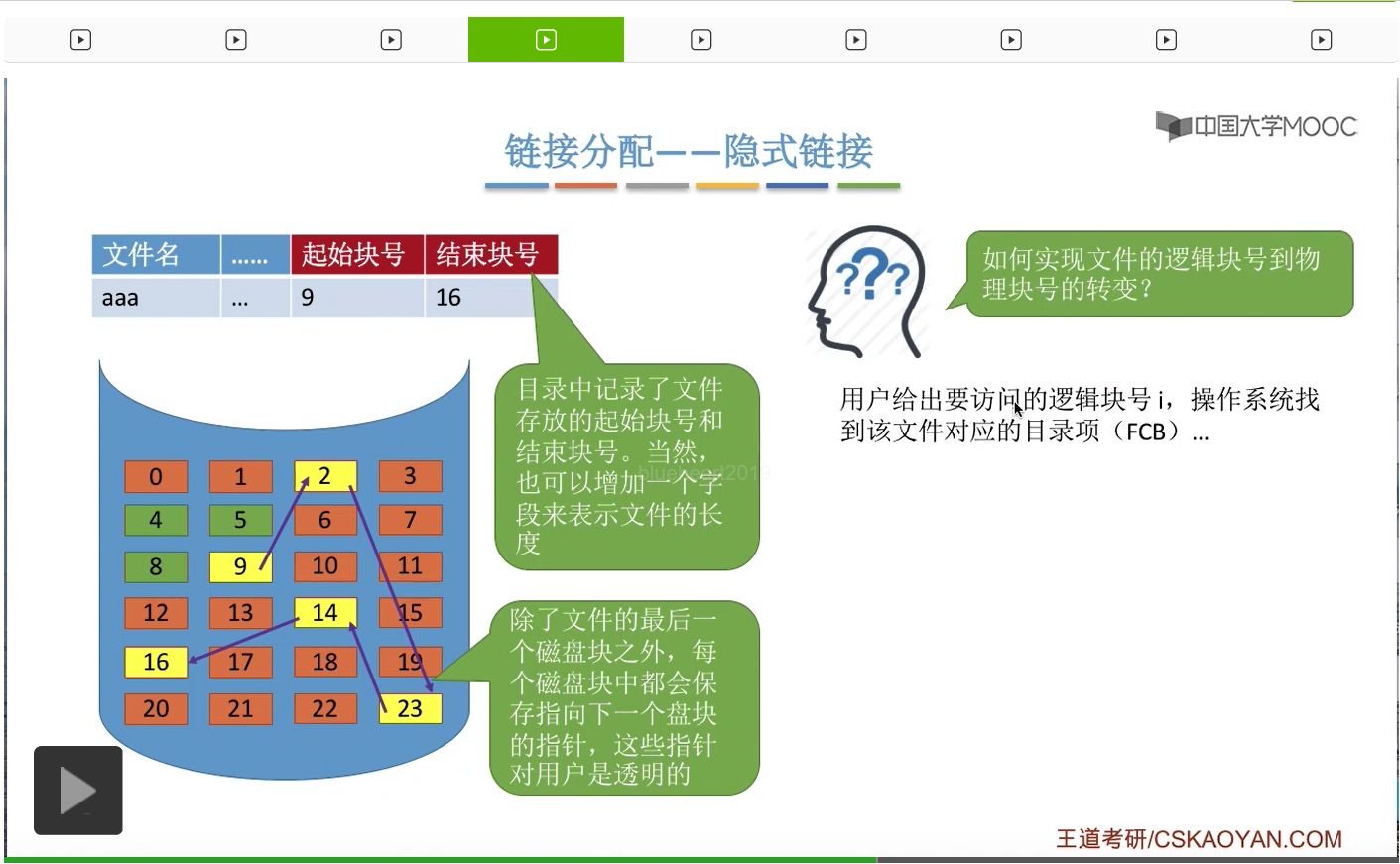
于是操作系统可以先读入这个文件的起始块,而这个块就是逻辑上的0号块。因为只有把这个块读入内内存之后,才可以知道这个块指向下一块的指针的数据到底是多少。那只有这样才可以再调入下一个块。于是下一个块调入内存之后,也可以再继续知道再下一个块存放的位置,于是再读入再下一个块,然后依次类推。

因此,如果说我们想要访问逻辑块号为i的这个逻辑块的话,那操作系统首先需要先依次地读入0号到i-1号逻辑块才可以找到i号块存放的位置。因此,访问i号逻辑块总共需要i+1次磁盘I/O操作。
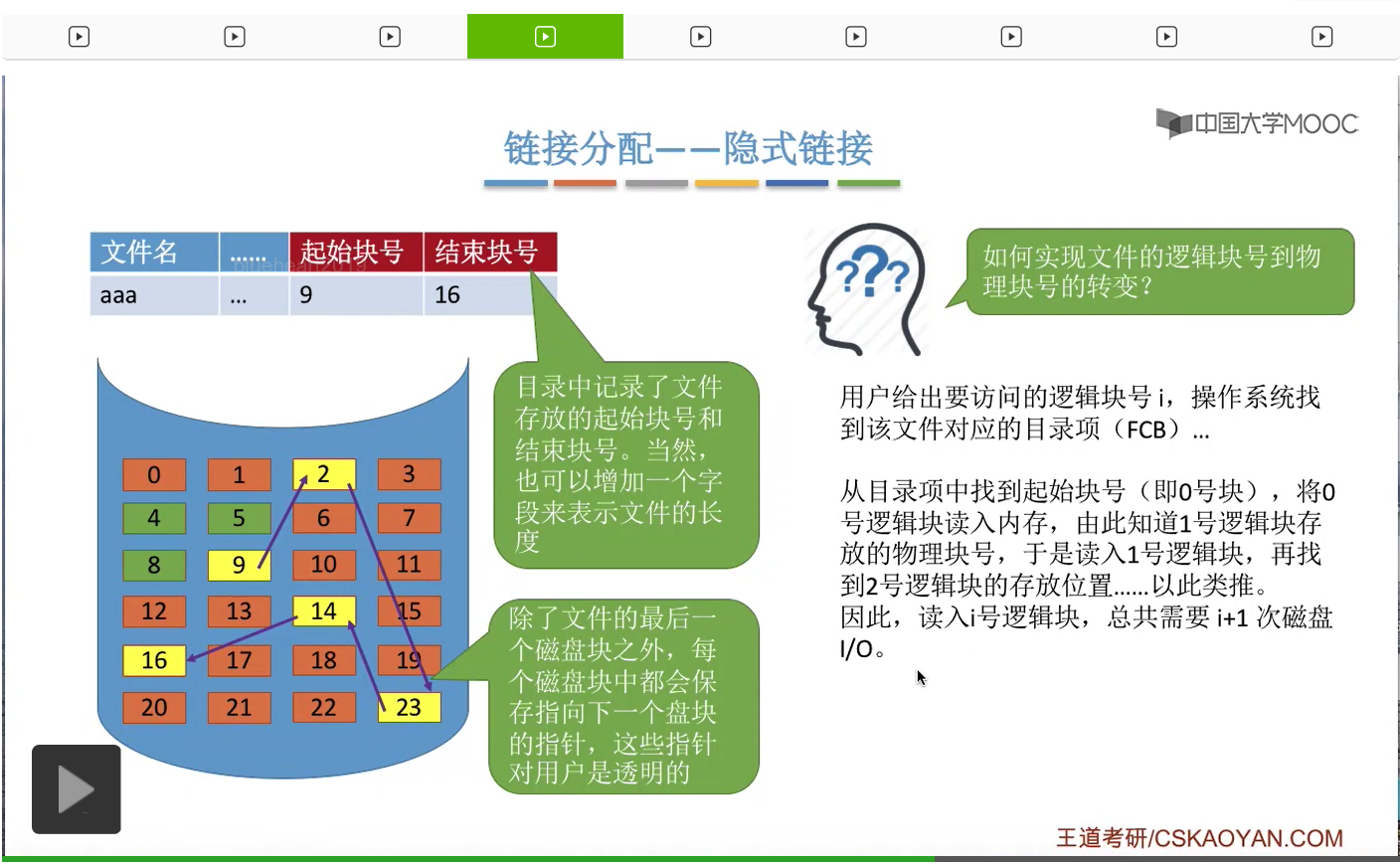
因此,我们得到的结论是,如果采用的是链接分配(隐式链接)的这种方式的话,那么这种文件它只支持顺序访问不支持随机访问。也就是说如果想要访问i号逻辑块的话,那我只能先顺序地访问0到i-1号块才可以。因此,这种方式带来的问题就是,查找的效率很低。另外呢,每一个块当中也需要耗费一定少量的存储空间来存放指向下一个块的这个指针内容。

那接下来我们考虑下一个问题。像这种方式是否方便拓展文件呢?假设此时这个文件需要拓展,也就是需要再给它分配一个新的磁盘块。
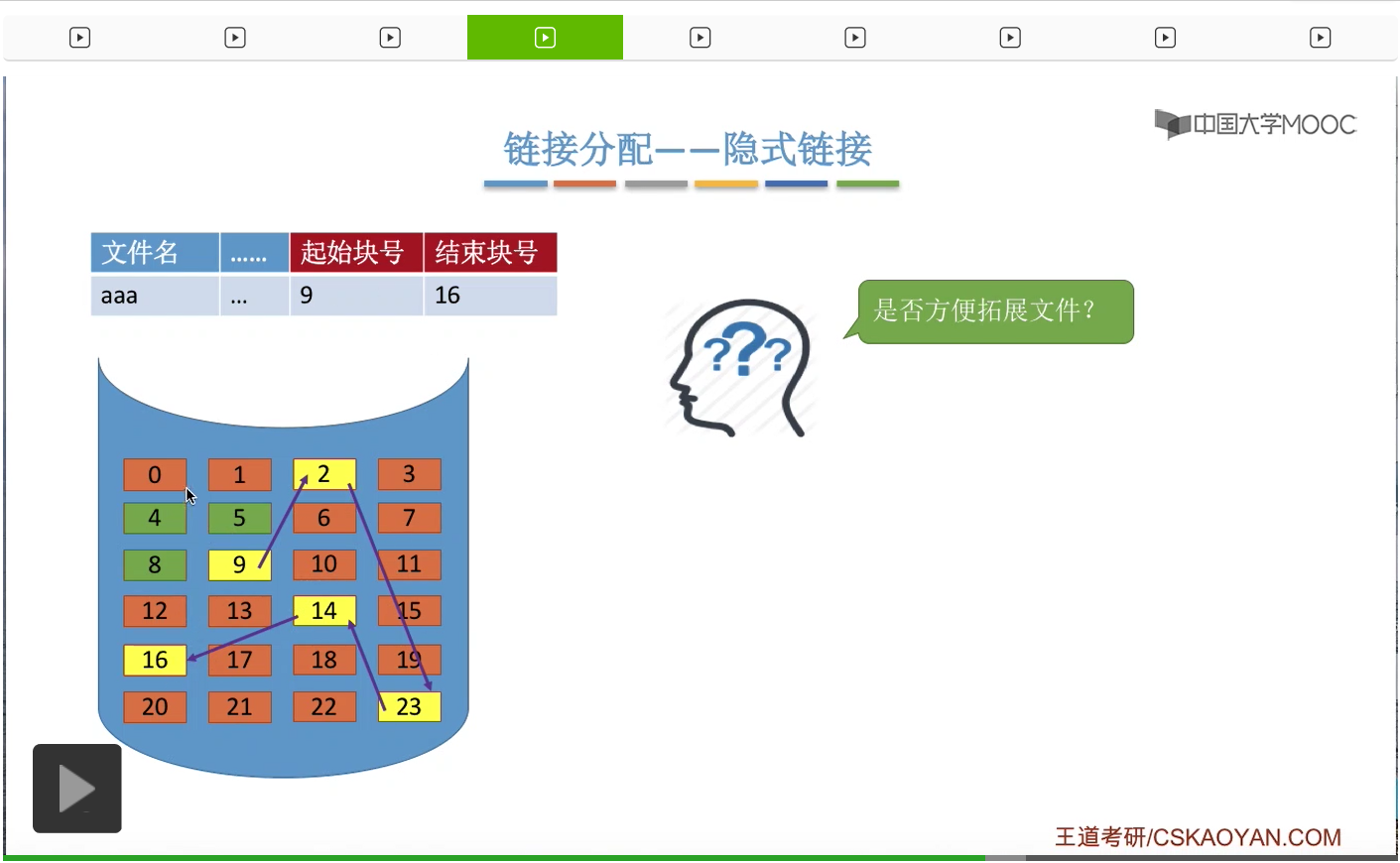
那由于这个文件的这些块可以是离散分配的,因此只需要从这个磁盘中随便找出一个空闲的块把它挂到这个文件的链尾就可以了。比如说此时我们给文件再新分配了一个8号块,于是把8号块挂到这个链的链尾,
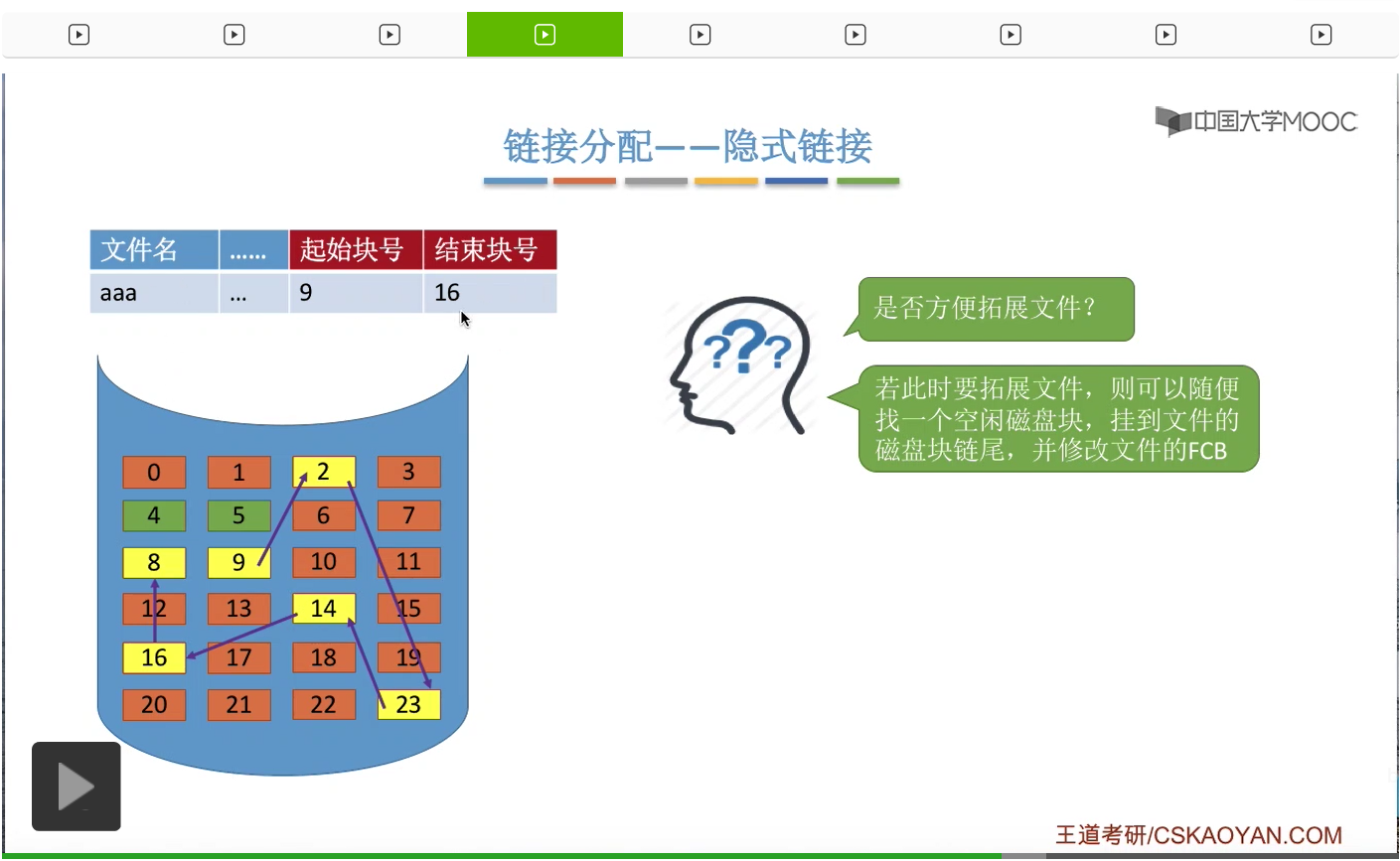
然后操作系统会修改这个文件FCB的结束块号这个内容,结束块号设为8号。
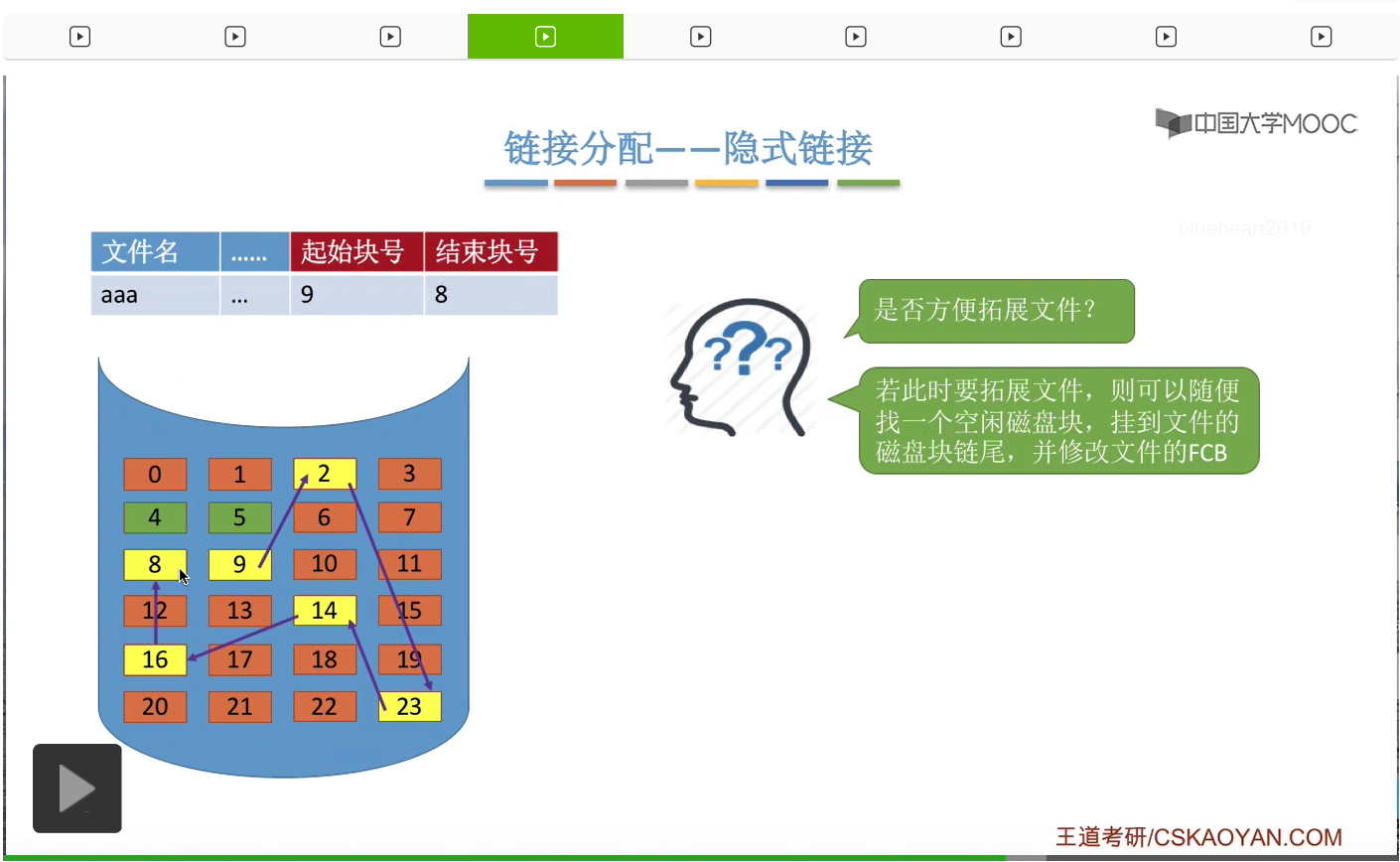
所以可以看到,采用这种方式的话,那么文件的拓展是很方便的,并且这种方式不会产生碎片问题,外存的利用率很高。

那么经过刚才的这个分析,我们知道了隐式链接的链接分配有这样的一些优点和缺点。这就是刚才咱们得到的结论,这儿就不再赘述。
接下来我们再来看显式链接的链接分配方式。这种方式会把用于链接各个文件物理块的指针显式地存放在一张表当中,这个表就被称为文件分配表,英文缩写是FAT(File Allocation Table)。磁盘当中的各个块的先后顺序都是统一记录在文件分配表当中的。所以一个磁盘它有多少个块,那在这个文件分配表当中就相应地会有多少个表项。

假设现在有一个新创建的文件,文件名是“aaa”,它依次占用了2、5、0、1这样的几个物理块。
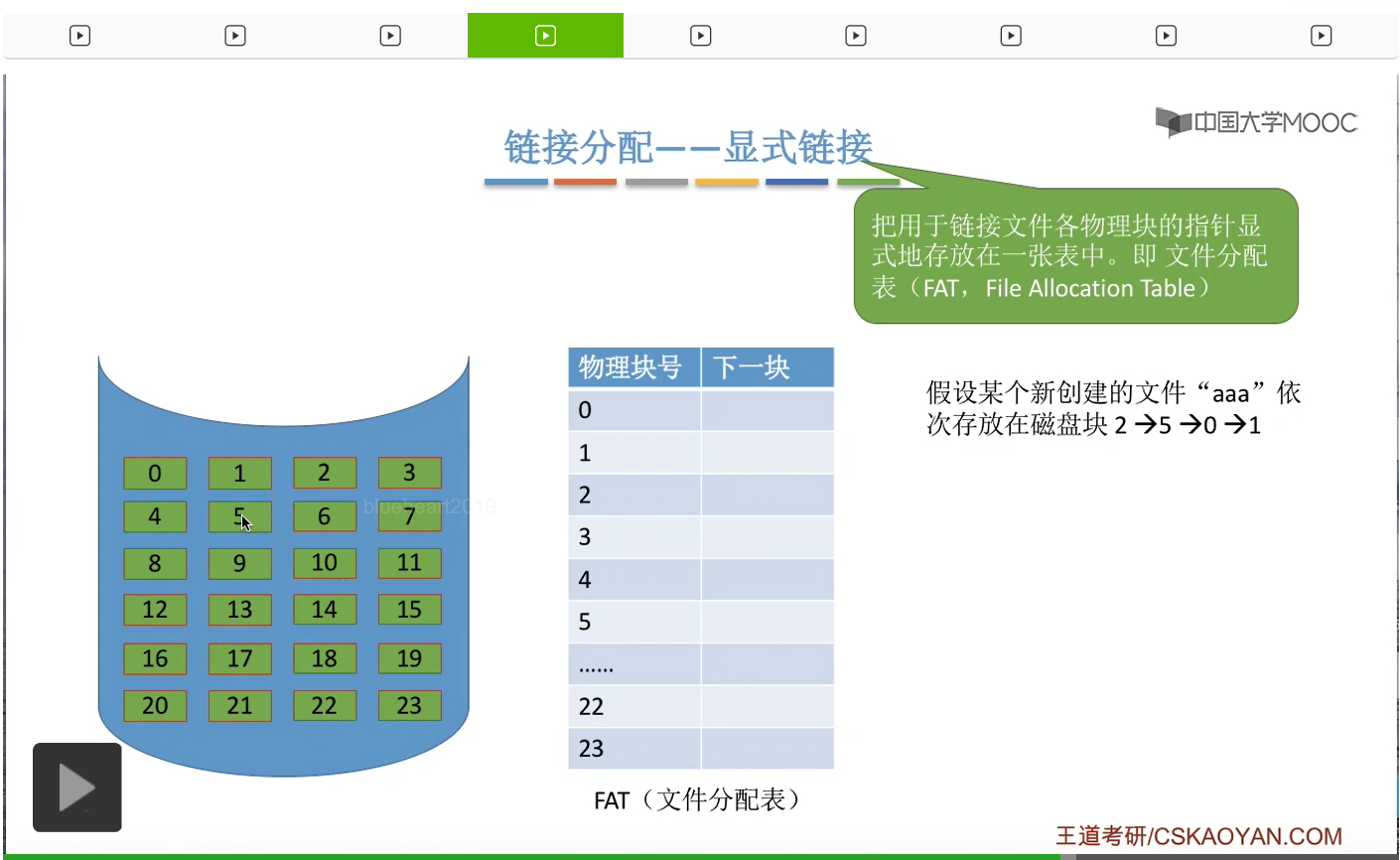
那么,在“aaa”这个文件的FCB,也就是目录项当中,需要记录这个文件“aaa”它存放的起始块号,起始块号是2号块。另外呢,在这个文件分配表当中,会显式地记录文件“aaa”它这几个物理块的一个链接关系。
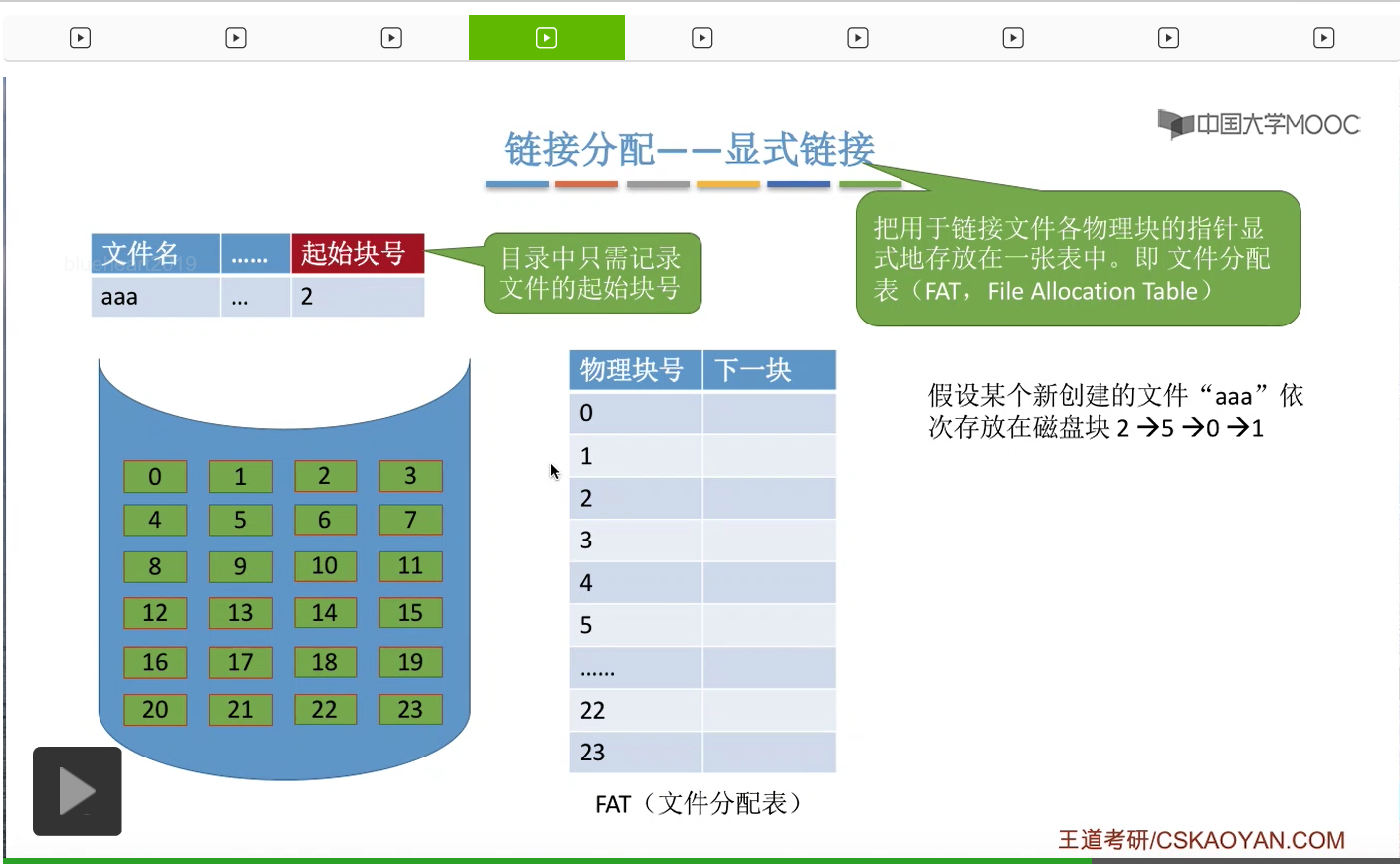
比如说2号块是起始块,2号块的下一块是5号块,所以FAT的这个表项,2号块的下一个块就应该记录为5。那这样的话就完成了2、5、0、1这样一个顺序的记录。
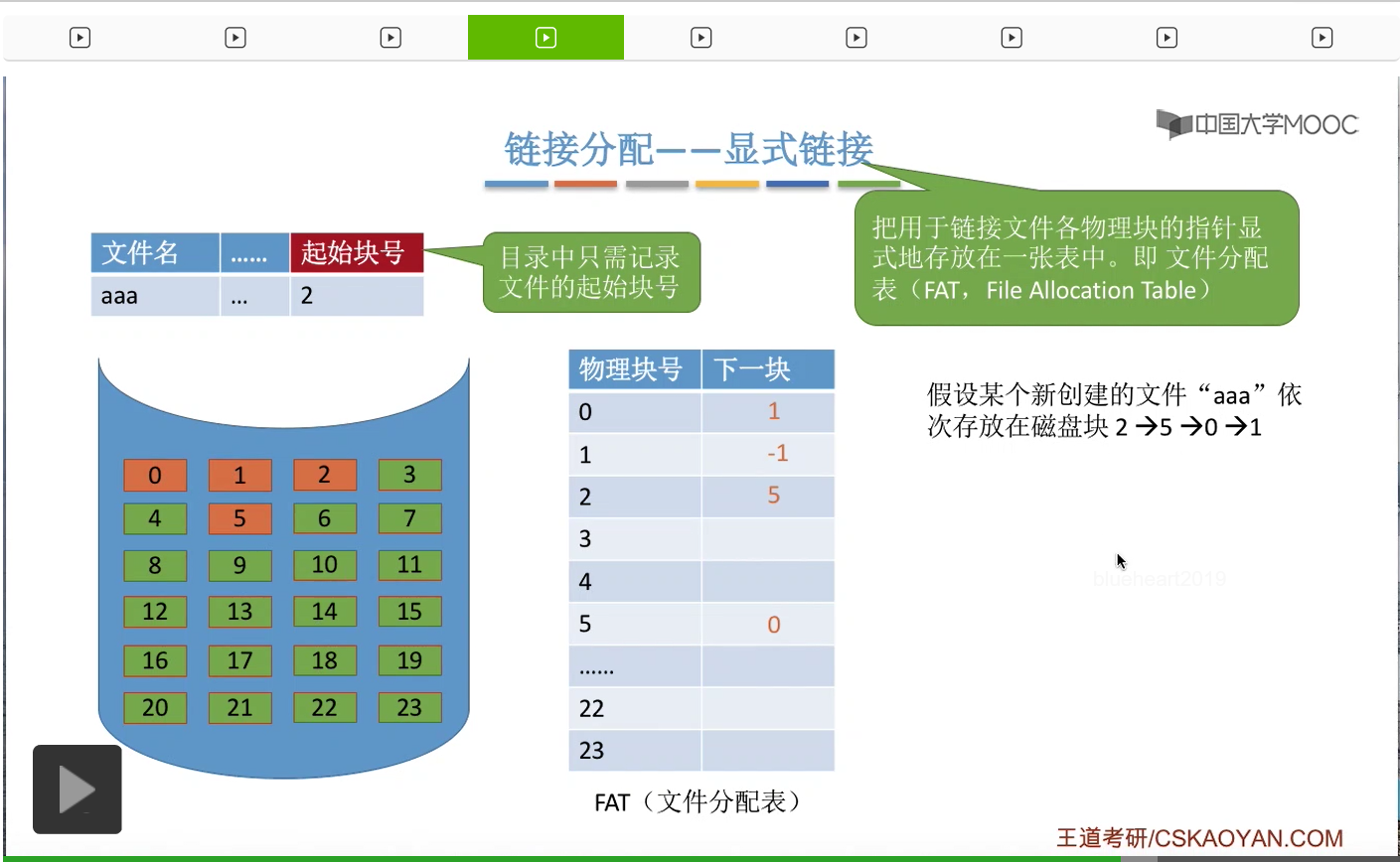
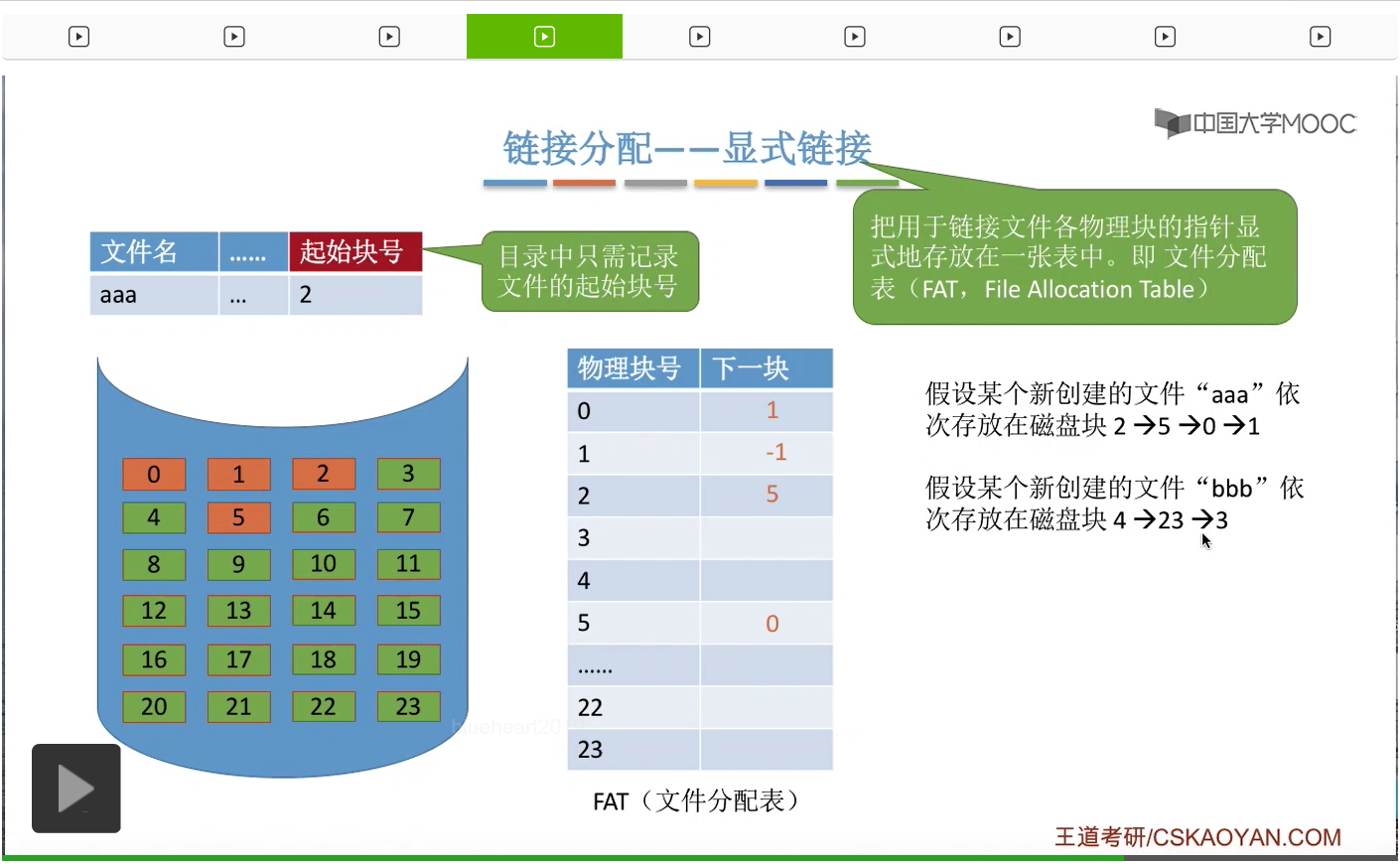
那么“bbb”这个文件对应的FCB当中,需要记录它的起始块号是4号块。然后4号块的下一个块是23,
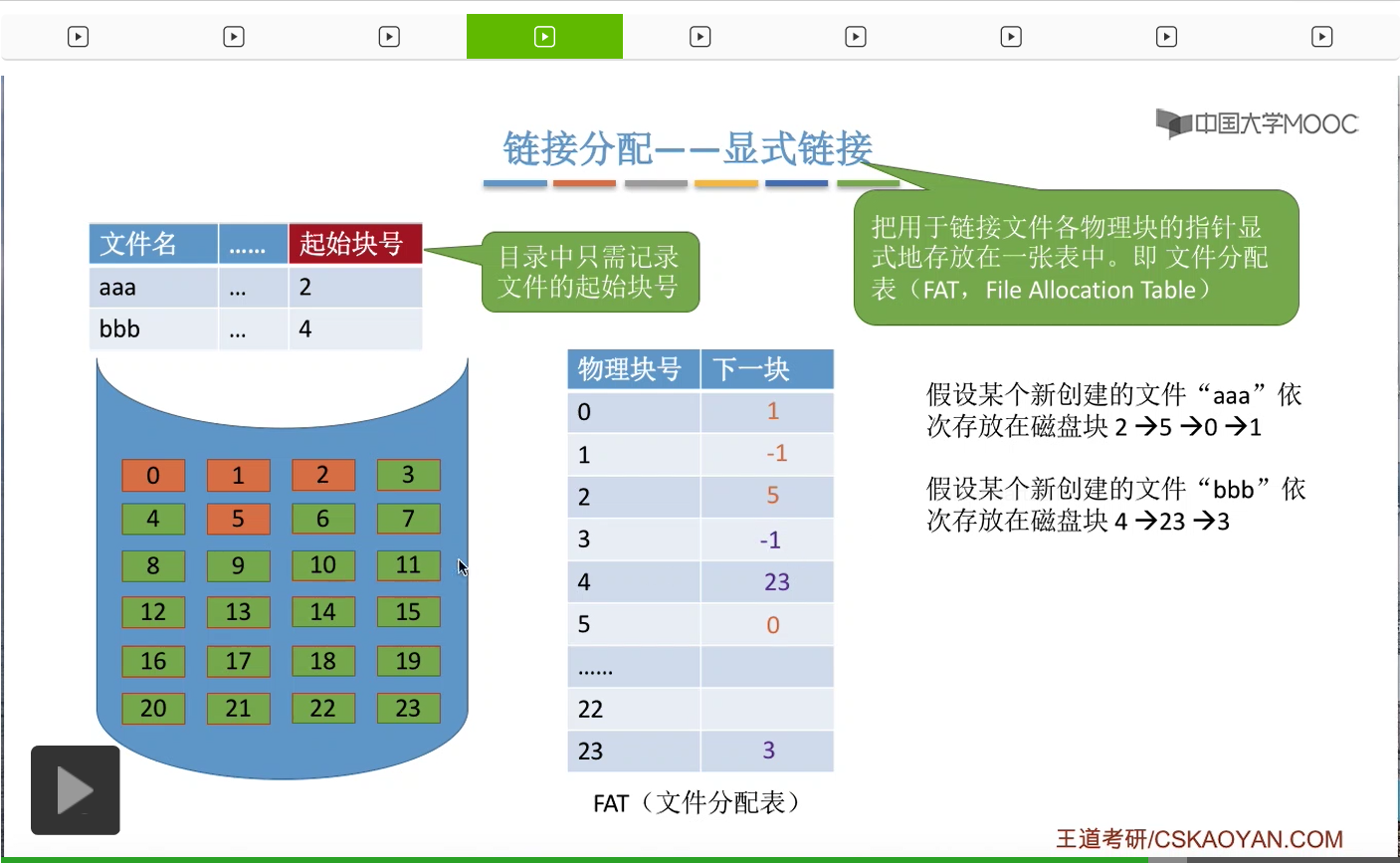
那这样的话也完成了“bbb”这个文件4->23->3这样的一个顺序的记录。所以这种方式把每个文件的各个盘块的链接信息显式地统一地放在了这样的一个文件分配表FAT当中,所以这是它为什么称作显式链接的一个原因。

那从这个地方我们也可以看到,一个磁盘仅需要设置一张FAT就够了。每个文件的这些盘块的先后顺序都是统一地存放在这张表当中的。并且在我们开机的时候,FAT文件分配表它会被读入内存,并且会一直常驻内存。而FAT的这些一个一个的表项,在物理上是需要连续存储的,并且每一个表项的长度相同。比如说下一块这个数据我们可以用四个字节来表示,所以物理块号这个字段可以是隐含的。
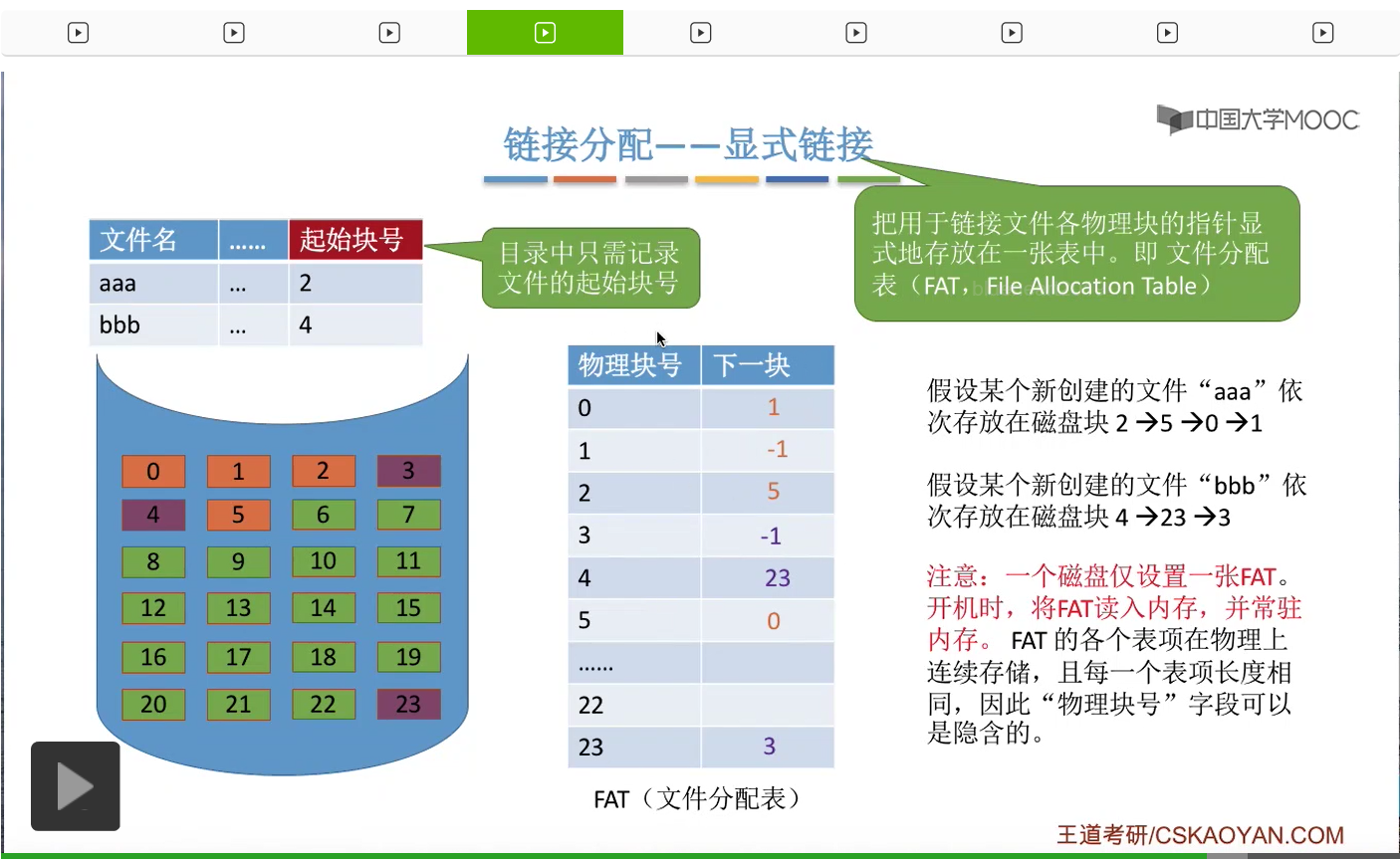
那接下来我们再来看一下,采用这种方式的话怎么实现文件逻辑块号到物理块号的一个转变呢?一个用户给出他想要访问的逻辑块号i,然后操作系统首先需要找到这个文件对应目录项也就是它的FCB,找到这个文件的起始块号,起始物理块号。那比如说,一个用户想要访问的是文件“aaa”的2号逻辑块,那么操作系统首先找到“aaa”这个文件的0号逻辑块存放的物理块号是2,那接下来系统会查询内存当中的文件分配表。那找到这个表项就可以知道,0号逻辑块的下一个块,也就是1号逻辑块,应该是存放在5号物理块当中的。那接下来会继续查询这个表项,发现1号逻辑块的下一块也就是2号逻辑块它是存放在0号物理块当中的。于是查询到这个位置,就可以知道这个用户想要访问的“aaa”这个文件的2号逻辑块存放的物理块号了。那由于FAT它是常驻内存的,因此查询这个FAT的过程并不需要读磁盘操作。

所以通过这个分析我们得出这样的结论,采用显式链接的链接分配方式的话,那么这种文件它既然支持顺序访问,也支持随机访问。我们想要访问i号逻辑块,并不需要顺序地依次访问0-i-1号逻辑块,我们可以直接通过FAT表查到i号逻辑块存放的地址。并且由于这个查询的过程并不需要访问磁盘,所以相比于隐式链接的那种方式来说,采用显式链接访问速度会快很多。

那显然,这种方式也不会产生外部碎片。并且可以很方便地实现对文件的扩展。

因此通过这一系列分析我们知道了显式链接的优点和缺点。我们需要特别注意的是,一个磁盘只会对应一张文件分配表,并且在开机的时候这个文件分配表就会被读入内存,并且常驻内存。因此查询文件分配表的过程并不需要读磁盘的操作。所以,这也造就了显式链接方式支持随机访问并且在这个地址转换的过程当中访问效率更高的一个特点。不过它的缺点呢就是这个文件分配表它需要占用一定的存储空间。

那大家需要注意的是,如果题目当中没有明确地告诉我们到底是显式链接还是隐式链接,那么如果它只是简单地提到链接分配的文件,那我们默认它指的是隐式链接的链接分配方式。我们介绍了连续分配和链接分配两种方式。链接分配又可以进一步分为隐式链接和显式链接。那所有知识点的总结我们会放到下个小节介绍完索引分配之后再统一地进行。

继续学习文件的物理结构也就是文件分配方式相关的问题。

连续分配要求给文件分配的必须是一些连续的磁盘块,而链接分配允许为文件分配的是一些离散的磁盘块。那和链接分配类似的是,

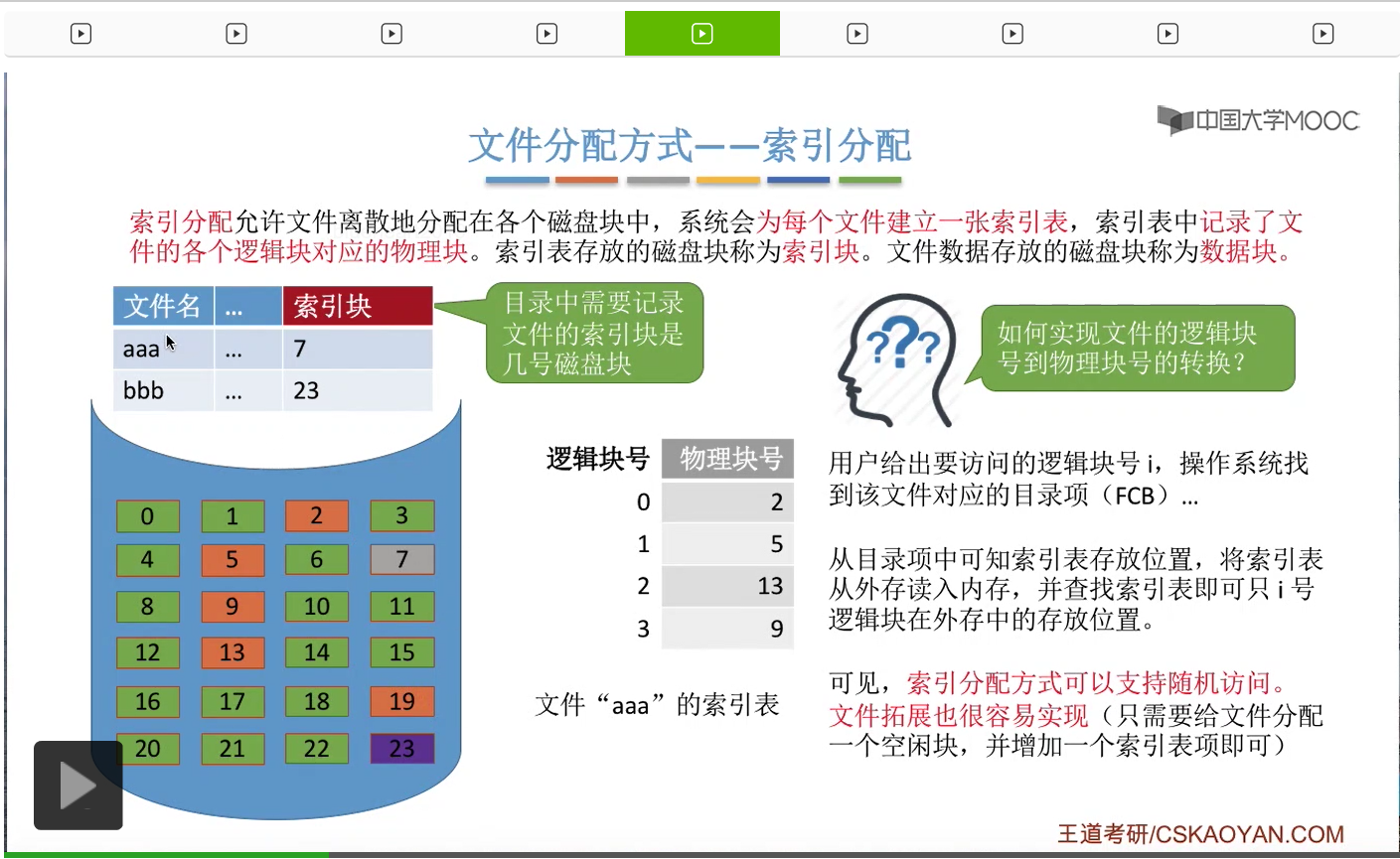
索引分配这种第三种分配方式它同样允许给文件分配的是一些离散的磁盘块,系统会为每一个文件建立一张索引表,而索引表当中记录了文件的各个逻辑块对应的物理块。所以这个地方大家会发现,索引表的功能,其实有点类似于我们内存管理当中的页表的功能。页表是建立了逻辑页面到物理页之间的一个映射关系。那磁盘当中用于存放索引表的那个磁盘块就称为文件的索引块,而用于存放文件实际数据的那些磁盘块就称为数据块。
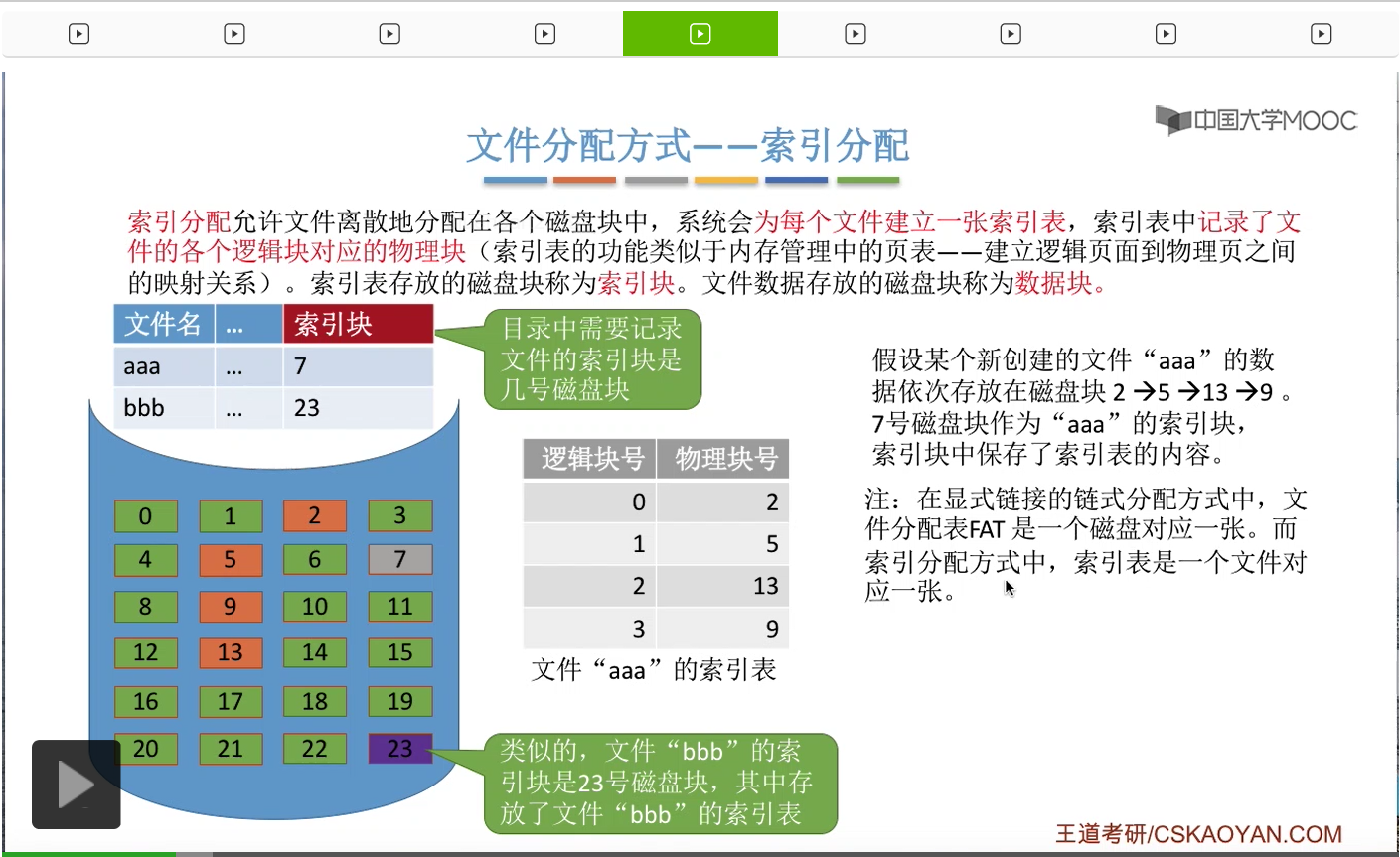
这个索引表记录了“aaa”的这些逻辑块和物理块之间的一一对应的这种映射关系。那么如果说这个“aaa”文件的索引表是存放在7号磁盘块当中的,那么7号磁盘块就是“aaa”的索引块。而2、5、13、9这几个磁盘块是“aaa”的数据块。

那采用索引分配方式的这些文件,需要在自己的目录项也就是FCB当中记录自己的索引块到底是哪一块。那索引块当中存放的是索引表,因此系统可以根据这个索引块的这个块号找到它的索引表,接下来就可以找到这些各个逻辑块对应的物理块号了。

那像这个例子当中,“aaa”的索引表是存放在7号块当中的,它的这些实际数据是依次存放在2、5、13、9这么几个块当中的。

类似的,假如说有另外一个文件“bbb”,它的索引块是23号块,那么“bbb”的这个索引表就应该是存放在这个地方。

所以这个地方大家会发现,如果采用的是索引分配方式的话,那么每一个文件都会有一张自己的索引表。而之前咱们介绍的显式链接的链接分配方式当中,文件分配表也就是FAT是一个磁盘只对应一张FAT,所以这是它们俩的一个小小的区别。
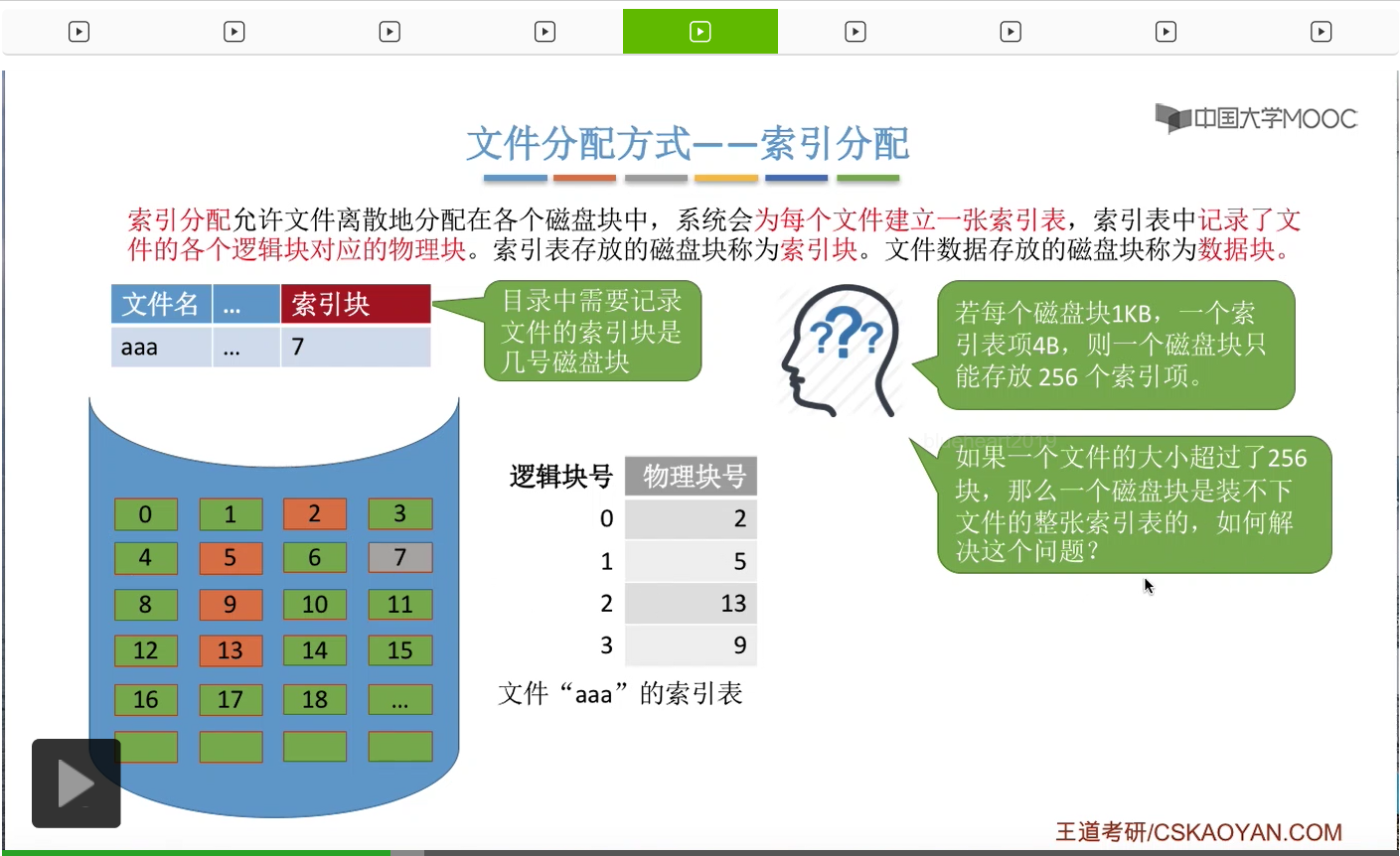
另外呢我们可以用固定长度、固定字节的存储空间来表示这些物理块号也就是索引表的这些表项。比如说像一个磁盘的总容量假如说是1TB,也就是2^40个字节,并且磁盘块的大小是1KB,那么这么大的磁盘就可以被分为2^30个磁盘块,因此,要表示这么多个磁盘块,只需要用30个二进制位就可以了。那么,4个字节的空间可以包含32个二进制位,它是足够表示2^30个磁盘块的块号的。因此,我们可以让这个索引表的块号每一个表项占4个字节。
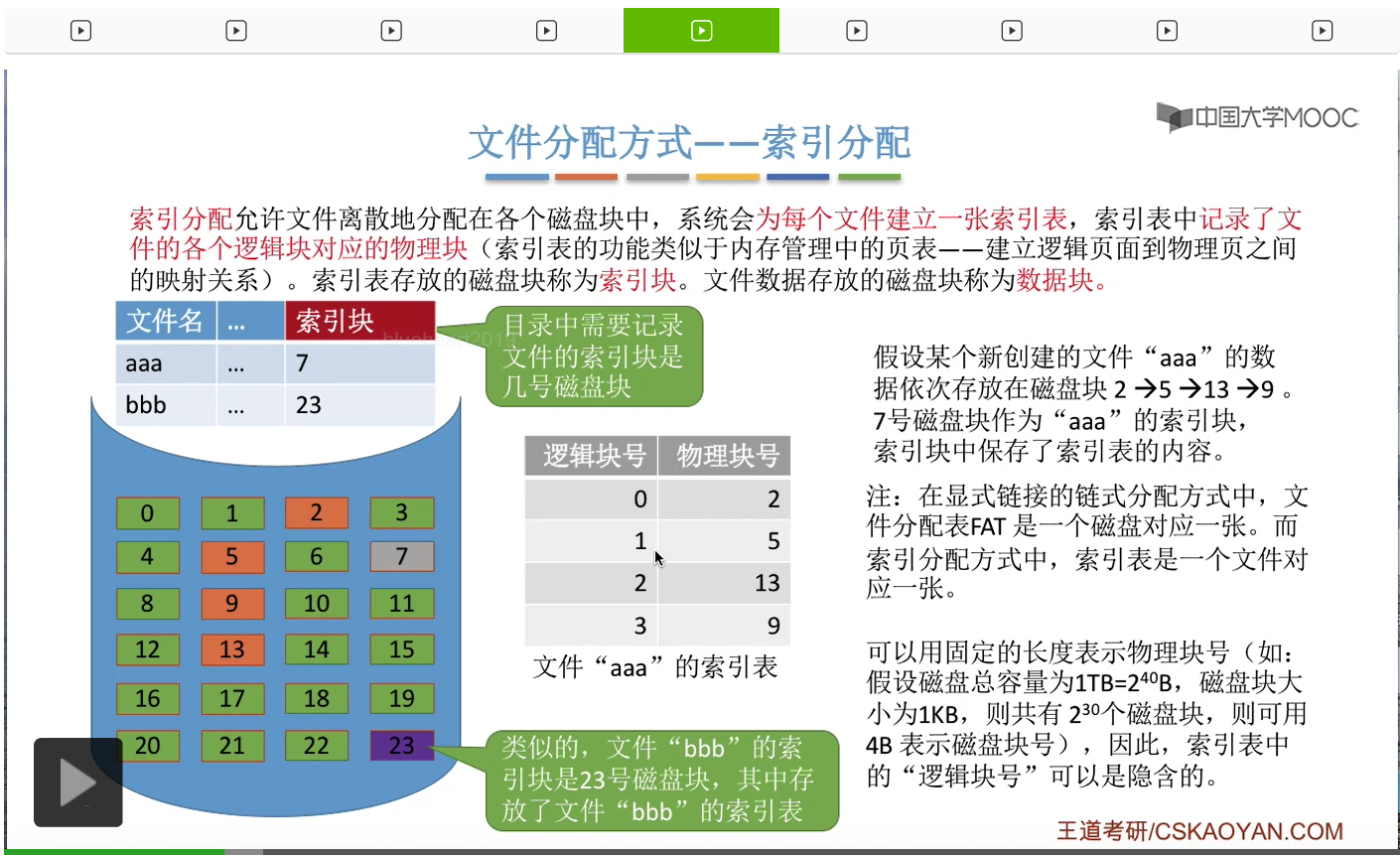
那索引表当中的这个逻辑块号这些数据就可以是隐含的。因为这个索引表的表项,每一行占的是4个字节,所以只要我们知道这个索引表的起始位置,那么我们就可以直接根据逻辑块号直接计算出某一个逻辑块号对应的那个表项到底是在什么位置了。

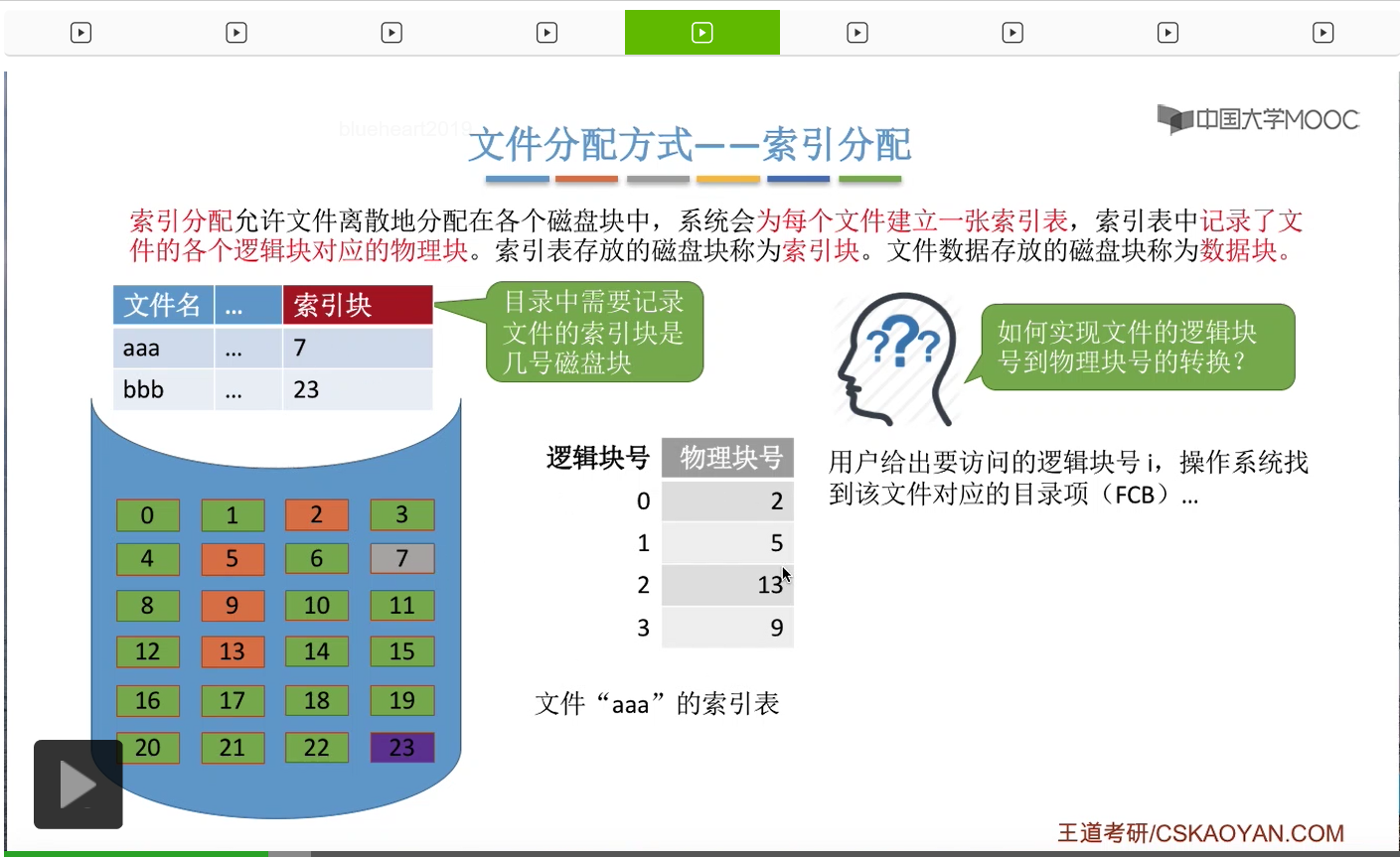
那接下来我们要探讨的问题是,采用索引分配方式,应该怎么实现逻辑块号到物理块号的转变。假设此时用户想要访问的是逻辑块号i,那么操作系统首先需要找到这个文件对应的目录项也就是它的FCB,从中找到这个文件的索引块的块号。再从这个索引块当中读出这个文件的索引表的内容。
那么接下来就只需要通过逻辑块号来查询这个索引表,就可以找到某一个逻辑块号对应的物理块号到底是多少了。那这个查表的方式其实和咱们内存管理当中介绍的,通过逻辑页号来查询页表项的那种方式是很类似的。所以从这个过程分析我们可以看到,如果我们想要访问逻辑块号为i的这个逻辑块的话,那么我们并不需要顺序地访问前面的0-i-1号块,我们可以直接找到i号块存放的物理块号。
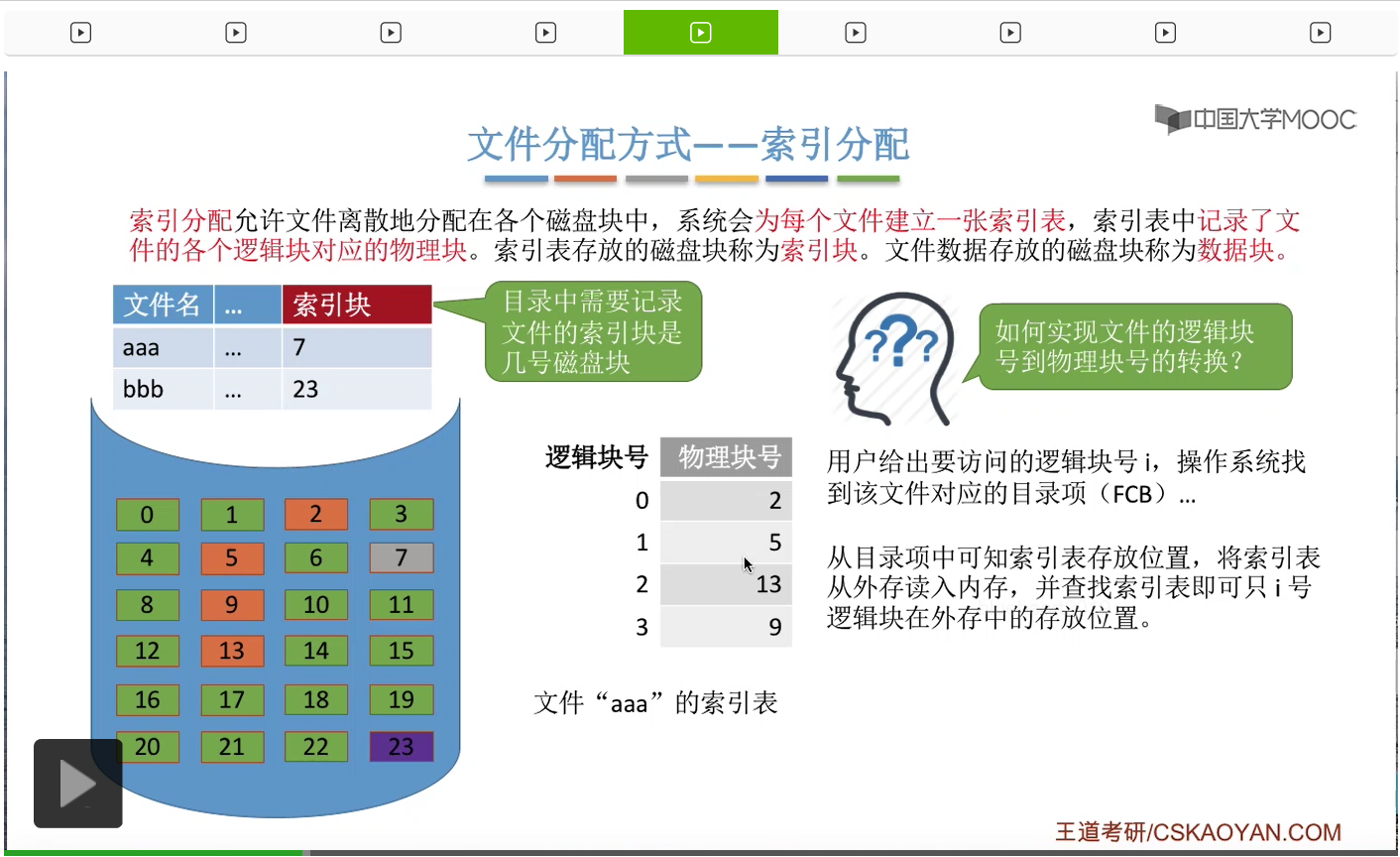
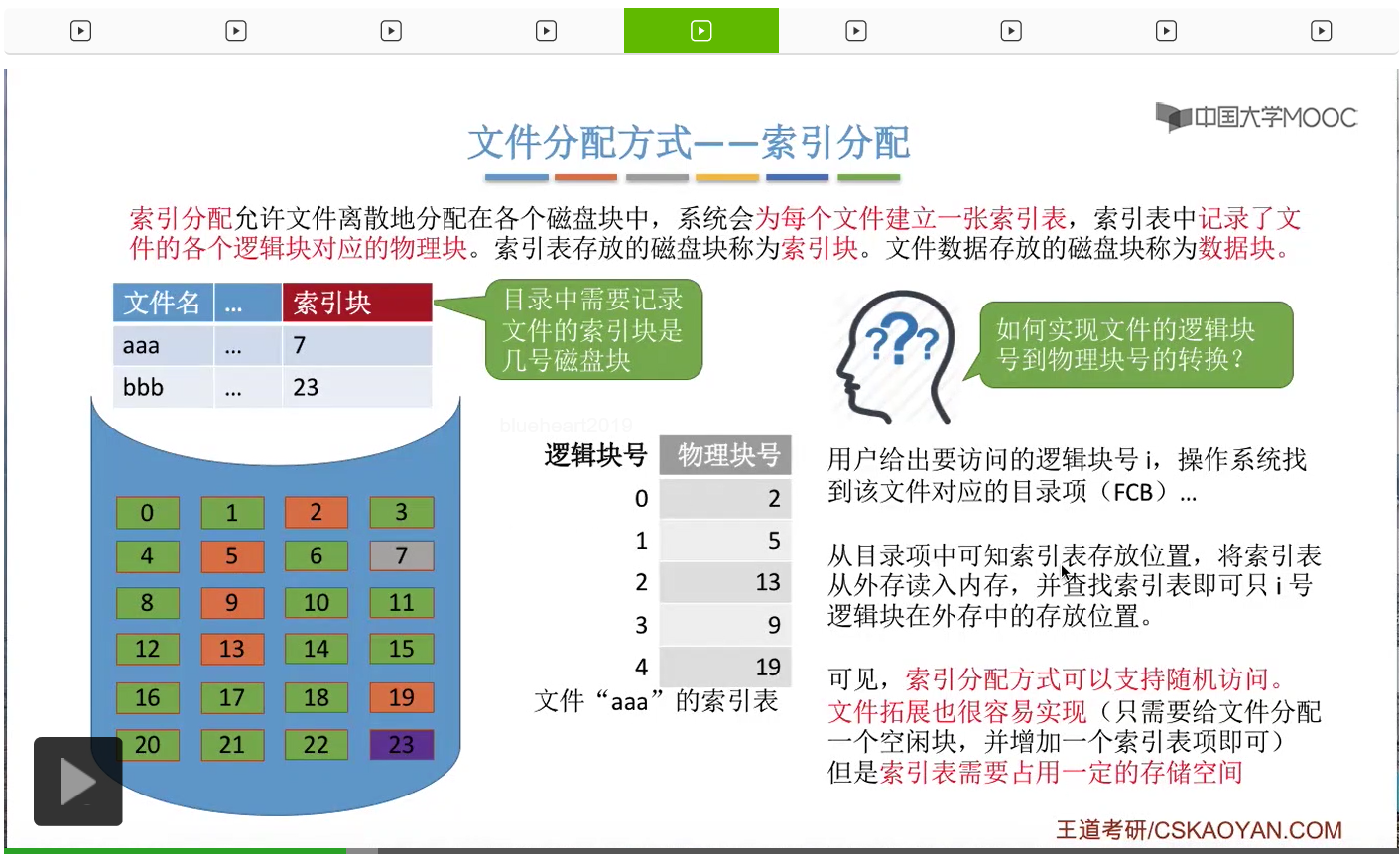
因此,索引分配这种方式是支持随机访问的。那另外呢,索引分配这种方式也很容易实现这个文件的拓展。
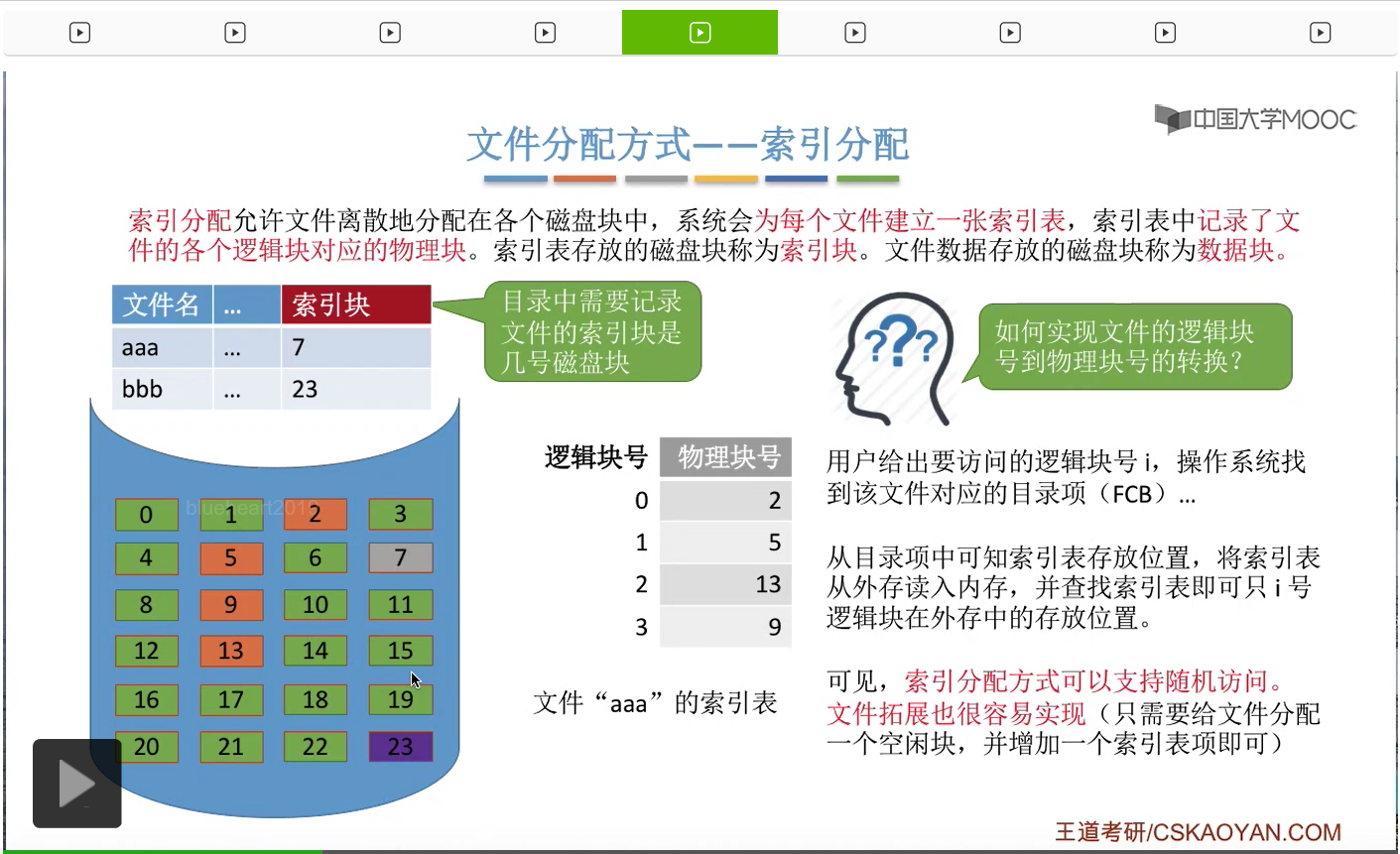
比如说,像“aaa”这个文件现在想要继续拓展,也就是再分配一个物理块、数据块的话,那么只需要随便找一个空闲的磁盘块,比如说是19号磁盘块,把它分配给“aaa”,
然后再在“aaa”对应的这个索引表当中增加相应的表项,这就完成了文件的拓展。

因此索引分配方式中,文件的拓展也是很容易实现的。不过索引分配方式的这个索引表需要占用一定的存储空间,这是它的一个小小的缺点。
那接下来我们再来考虑下一个问题。那假如说有一个文件它的大小已经超过了256个块,那也就意味着这个文件它对应的索引表肯定也要超过256个索引项。那既然如此,这么大的索引表肯定是没办法在一个磁盘块中就可以装的下的。也就是说,一个很大的文件它对应的索引表在一个磁盘块下肯定存不下。那么我们怎么解决这个问题呢?
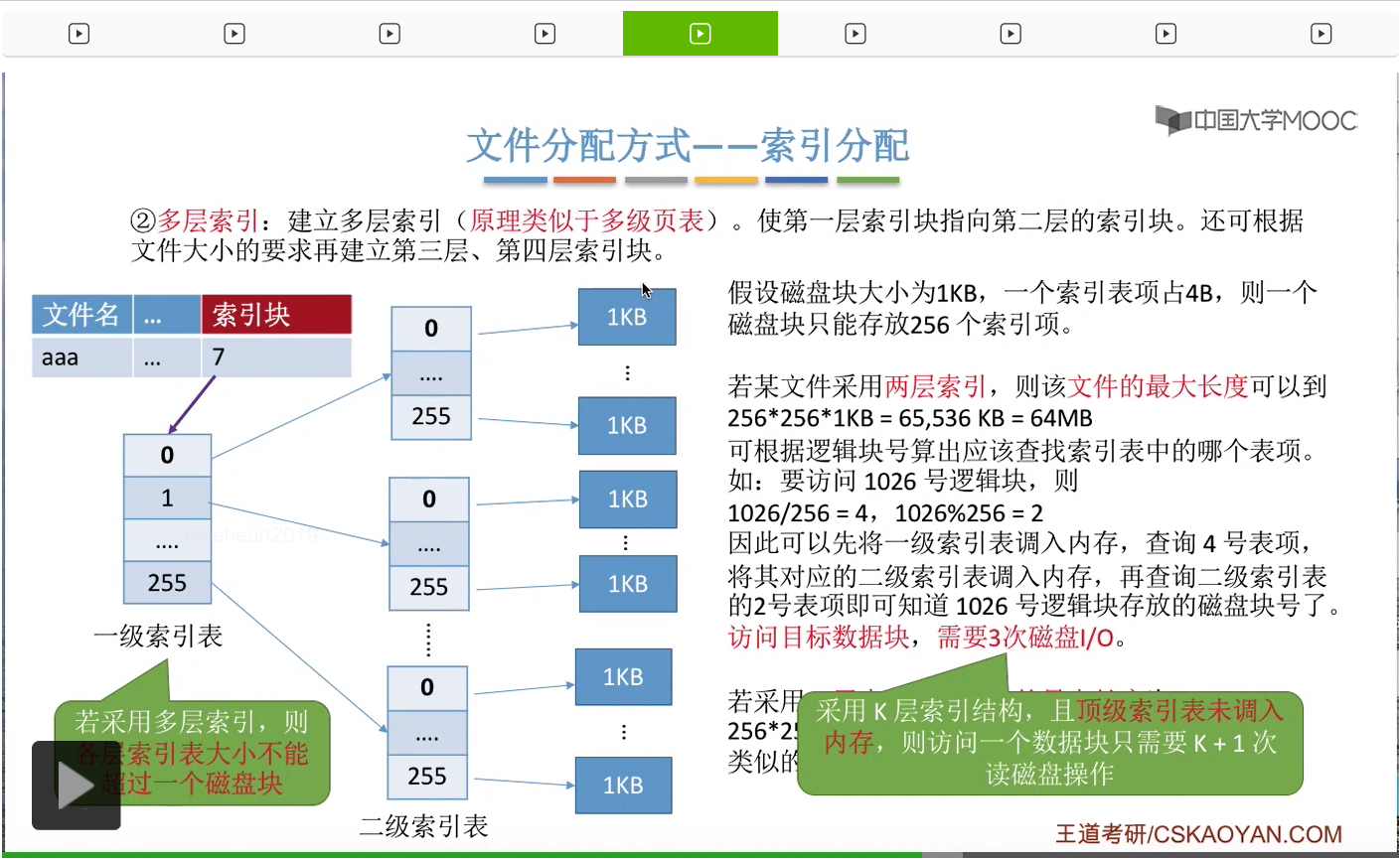
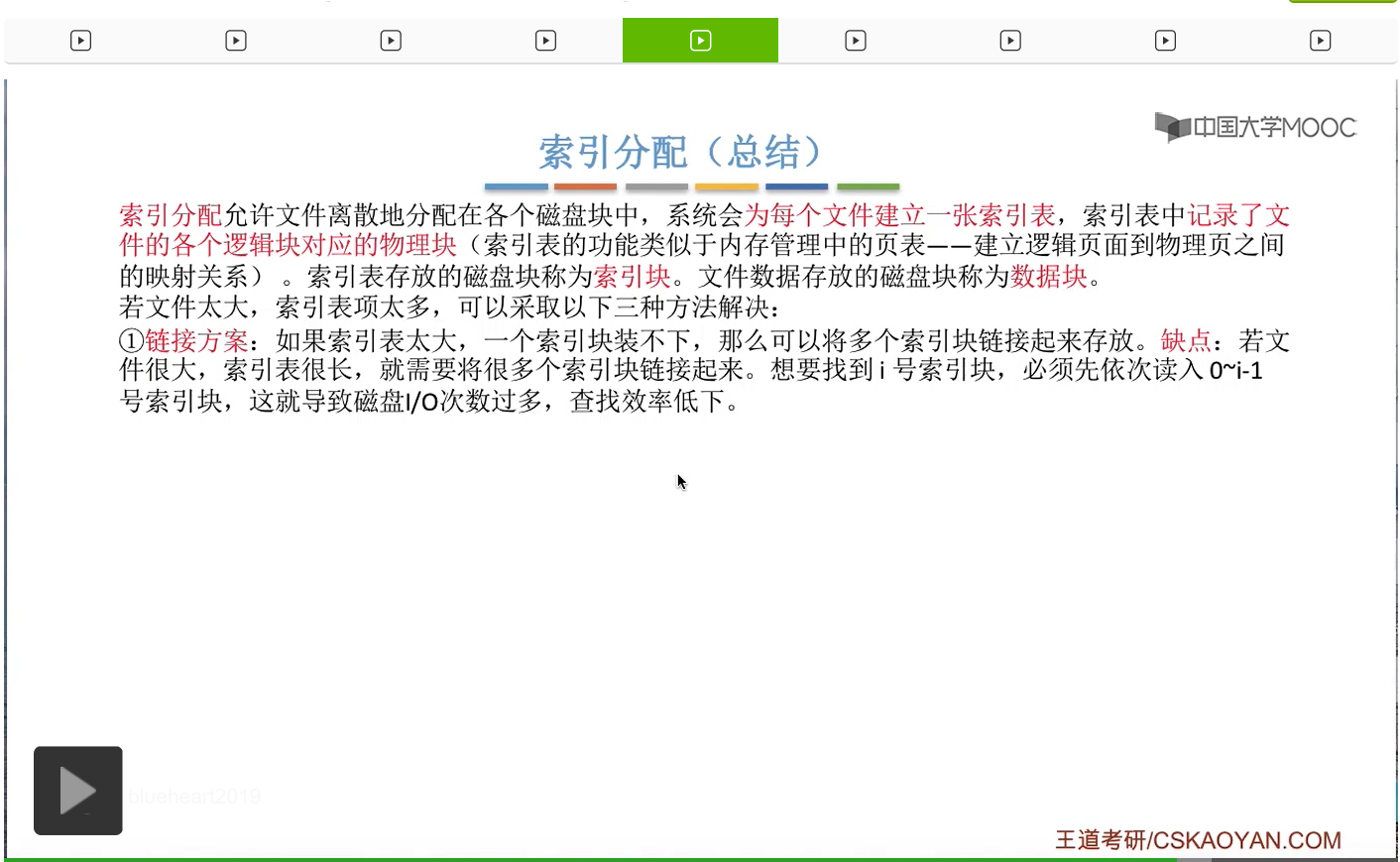
一般来说有这样的三种解决方案。第一种叫做链接方案,第二种叫做多层索引,第三种叫混合索引。我们会依次介绍。

那首先来看链接方案。如果说一个文件的索引表太大,那么可以为这个文件的索引表分配多个索引块,并且用链接的方式把它们链起来。那还是接着刚才的那个条件往下分析,假设一个磁盘块只能存放256索引项,那么如果一个文件的大小超过了256块的话,那么就意味着这个文件的索引表它的索引项肯定也超过256个。因此可以把这个索引表拆分,为这个文件分配多个索引块,每一个索引块当中存放256个索引项,并且在每一个索引块当中用一定的空间存储指向下一个索引块的一个指针。那这样的话就可以把一个很长的索引表拆分成不同的部分,并且用这种链接的方式把它们链起来了。那如果采用的是链接方案的话,文件的FCB当中只需要记录它的第一个索引块的块号。像文件“aaa”就只需要记录它的第一个索引块也就是7号块。那假设现在用户想要访问的是“aaa”的逻辑块号为256的那个逻辑块的话,那为了查到256号逻辑块对应的物理块号,那就肯定需要找到“aaa”的第二个索引块。而由于各个索引块之间是用这种链接的方式把它们链起来的,所以为了找到第二个索引块的块号,那操作系统首先需要把第一个索引块读入内存,然后才能根据这个索引块当中的指针,找到第二个索引块的块号,并且把第二个索引块读入内存。只有这样才能找到256这个逻辑块号对应的物理块号到底是多少。因此可以看到,如果说用户要访问的那个逻辑块号对应的索引项是在这个索引表当中的第二个部分的话,那么系统首先必须先顺序地读取索引表的第一部分,之后才能找到索引表的第二部分。
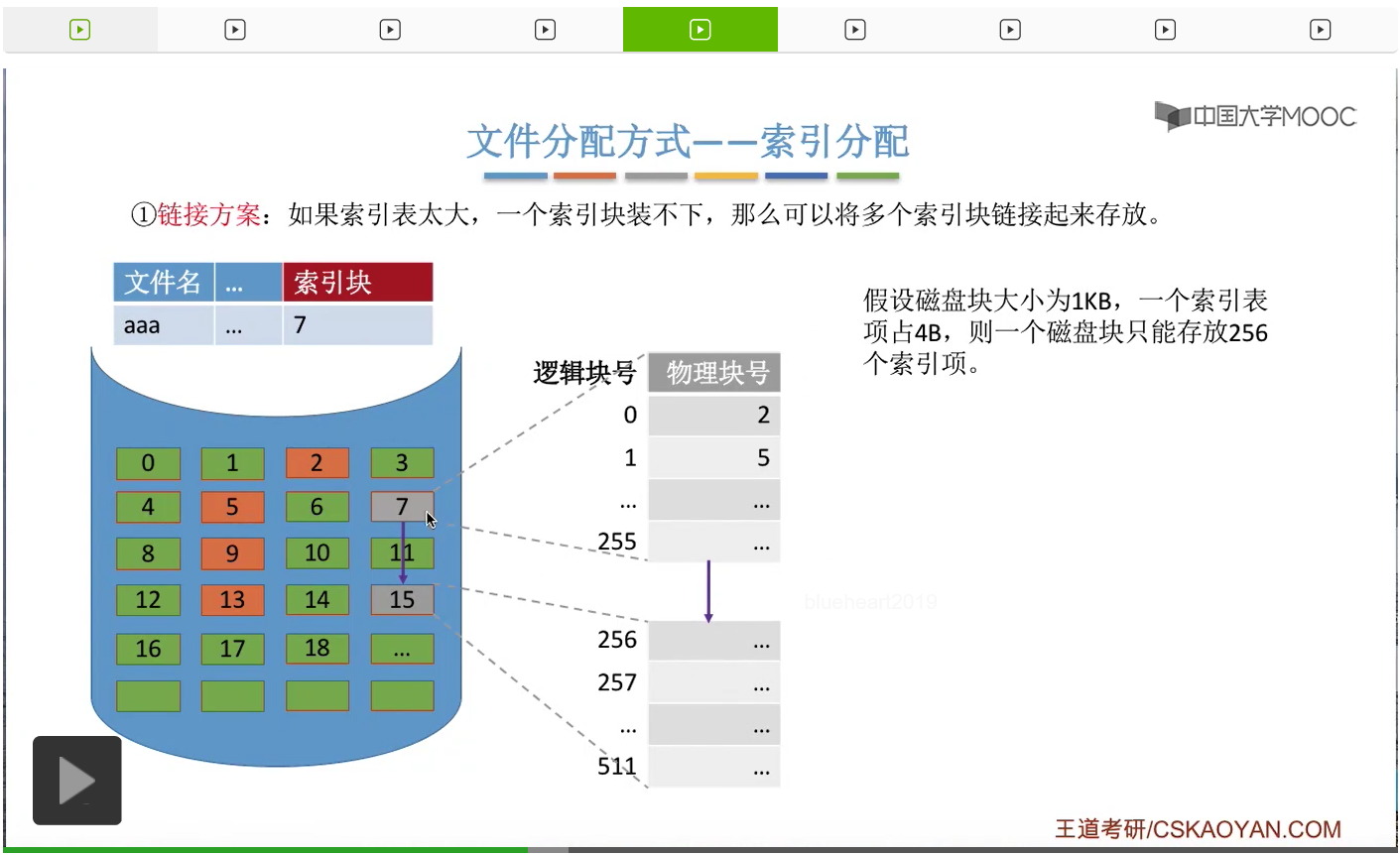
那这个特点就造成了一个问题。假设一个文件的大小是64兆字节,那也就是256*256个KB。那由于说每个磁盘块的大小是1KB,所以这个文件应该占用256*256个磁盘块,也就需要对应同等数量的索引项。而每一个磁盘块每一个索引块当中,只能存放256个索引项。因此,这么多的索引项,就需要用256个索引块来存储。并且如果采用的是链接方案的话,那这些索引块之间是用这种链接的方式把它们链起来的。所以如果说一个用户想要访问这个文件的最后的一个逻辑块的话,那么就必须找到这个文件的最后一个索引块。那通过刚才的分析我们知道,如果要找到最后一个索引块的话,那么必须先依次地读入前面所有的那些索引块。所以可以看到,如果采用的是链接方案的话,那么为了找到文件的某一个逻辑块对应的物理块号,光是这个地址转换的过程就可能需要200多次读磁盘的操作,那这显然是很低效的。这也是链接方案所存在的最大的一个问题。那怎么解决这个问题呢?

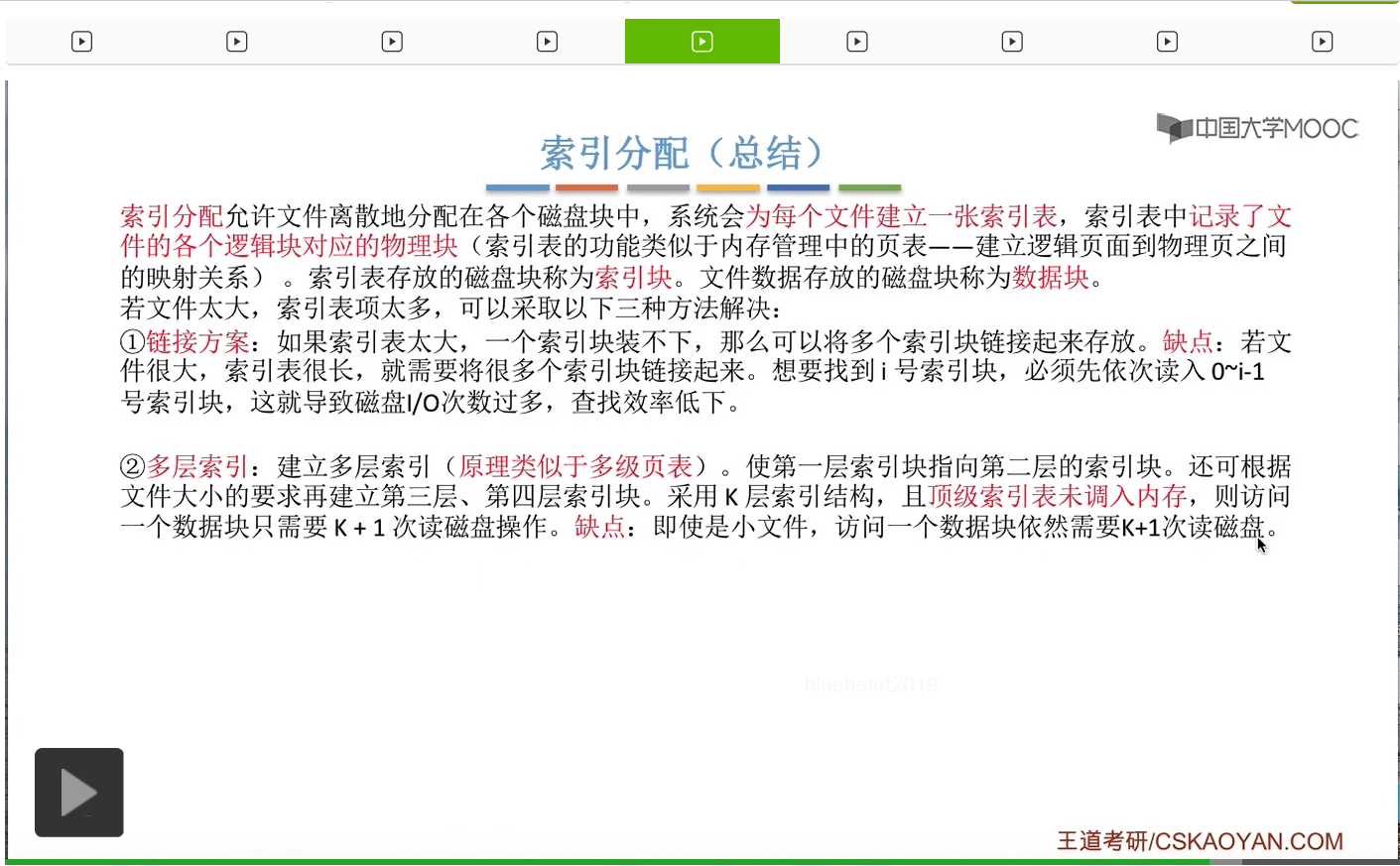
为此,人们提出了多级索引这种解决方案。多层索引的这种解决方案就有点类似于咱们之前学习过的多级页表的那种原理。就是要建立多层的索引表,使第一层索引块指向第二层索引块。如果说文件很大的话,甚至还可以建立第三层、第四层索引块。
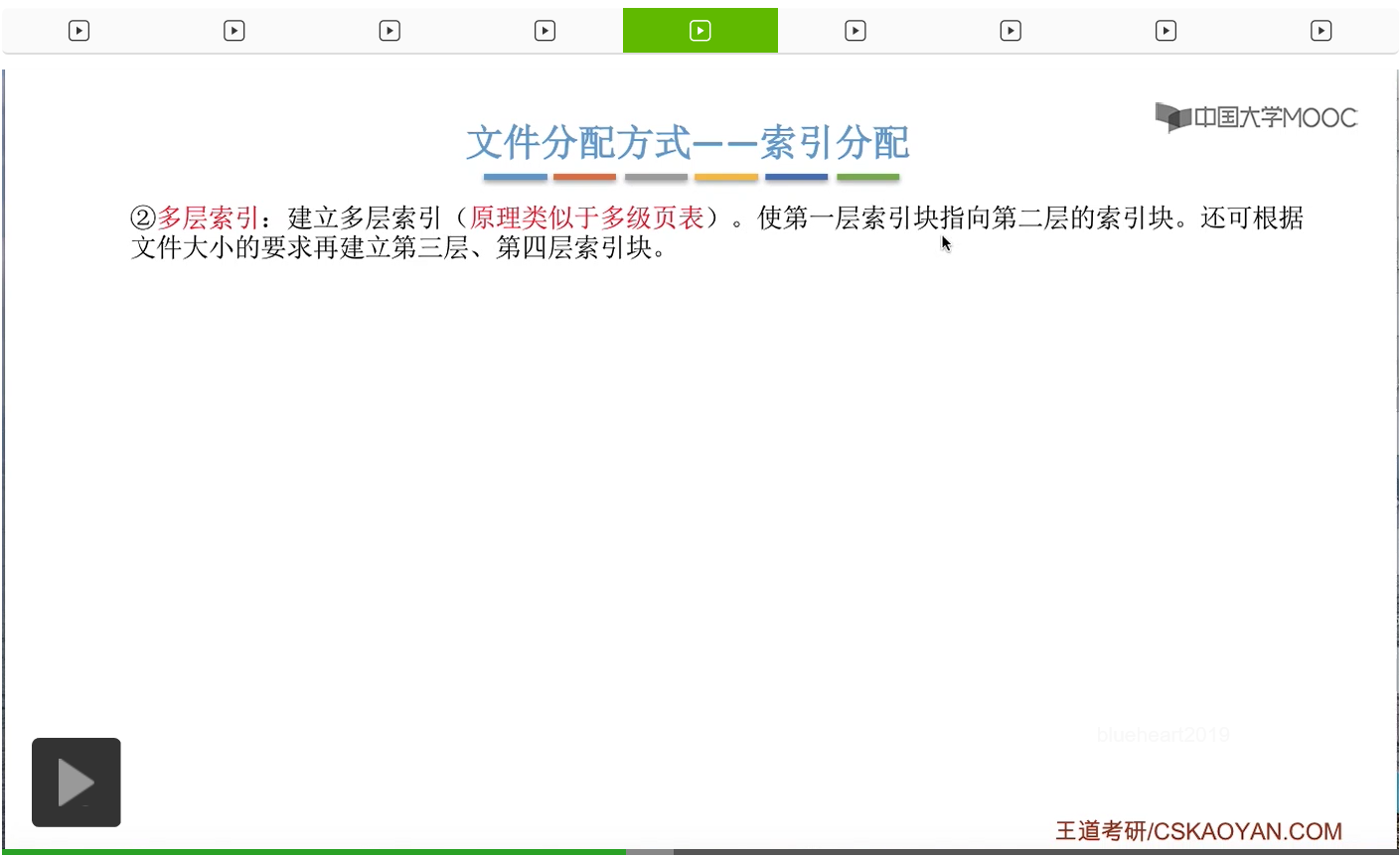
那还是用刚才的那个条件继续分析。假设一个磁盘块只能存放256个索引项,并且一个文件的大小是256*256个块的话,那么这个文件可以为它建立两层索引。第一层的索引块总共有256个索引项,第二层的索引块每一块也有256个索引项,然后每一个索引项再指向某一个数据块。

那在文件的目录表也就是FCB当中, 只需要记录它的顶级索引表存放的这个索引块号到底是多少就可以了。

那如果说我们采用的是这种两层索引的结构的话,那文件的最大长度可以达到256*256*1KB=64兆字节。

这是因为如果我们采用了多级索引的结构的话,那么各层索引表的大小不能超过一个磁盘块。也就是说,第一级的这个索引表,最多只会有256个索引项,也就是会分别指向256个第二级的索引表。而第二级的索引表大小仍然不能超过一个磁盘块,所以第二级的索引表最多也只会含有256个索引项。那每个索引项又会分别指向一个数据块,每一个数据块的大小就是1KB这么大。因此,如果采用两层索引的话,那么文件的最大长度是64兆字节。这个条件十分重要,在考试当中经常会遇到让我们计算文件最大长度的这种类型的题。那接下来我们来看一下,如果采用多级索引的话,怎么实现逻辑块号到物理块号的转变。

那假设此时用户要访问的是1026号逻辑块,那么1026/256=4,也就是说1026号逻辑块对应的那个索引项应该是4号二级索引表当中存放的。而4号二级索引表存放的位置操作系统只需要从这个一级索引表当中找到4号索引项对应的那个物理块就可以知道了。那在读入了四号二级索引表之后,接下来应该查询4号二级索引表当中的哪一个表项呢?1026%256=2说明此时需要查询的是4号二级索引表当中的2号表项。那找到2号表项之后,就可以找到1026号逻辑块对应的物理块到底是多少了。
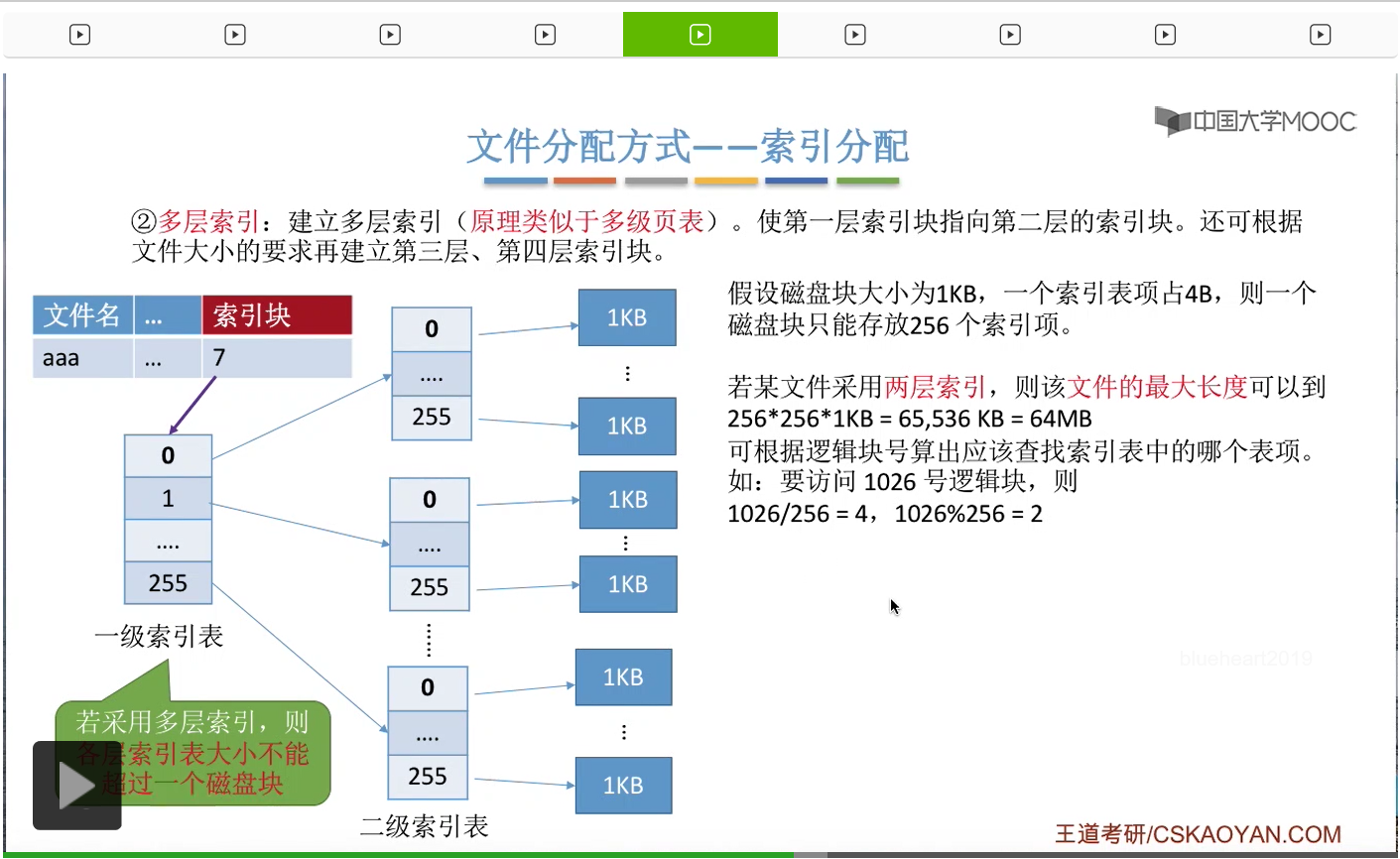
所以如果采用这种两层索引的方式的话,那么操作系统首先是需要根据这个FCB当中记录的顶级索引块的块号来找到顶级索引表,先把顶级索引表读入内存,然后查询相应的表项之后又找到相应的二级索引表存放的物理块号,接下来再把二级索引表读入内存。最后再查询二级索引表就可以找到我们最终想要访问的逻辑块到底存放在哪个物理块当中了。所以这整个过程,访问目标数据块总共进行了3次读磁盘操作。第一次是读入了一级索引表,第二次是读入了对应的二级索引表,第三次才是读入我们最终要访问的数据块。
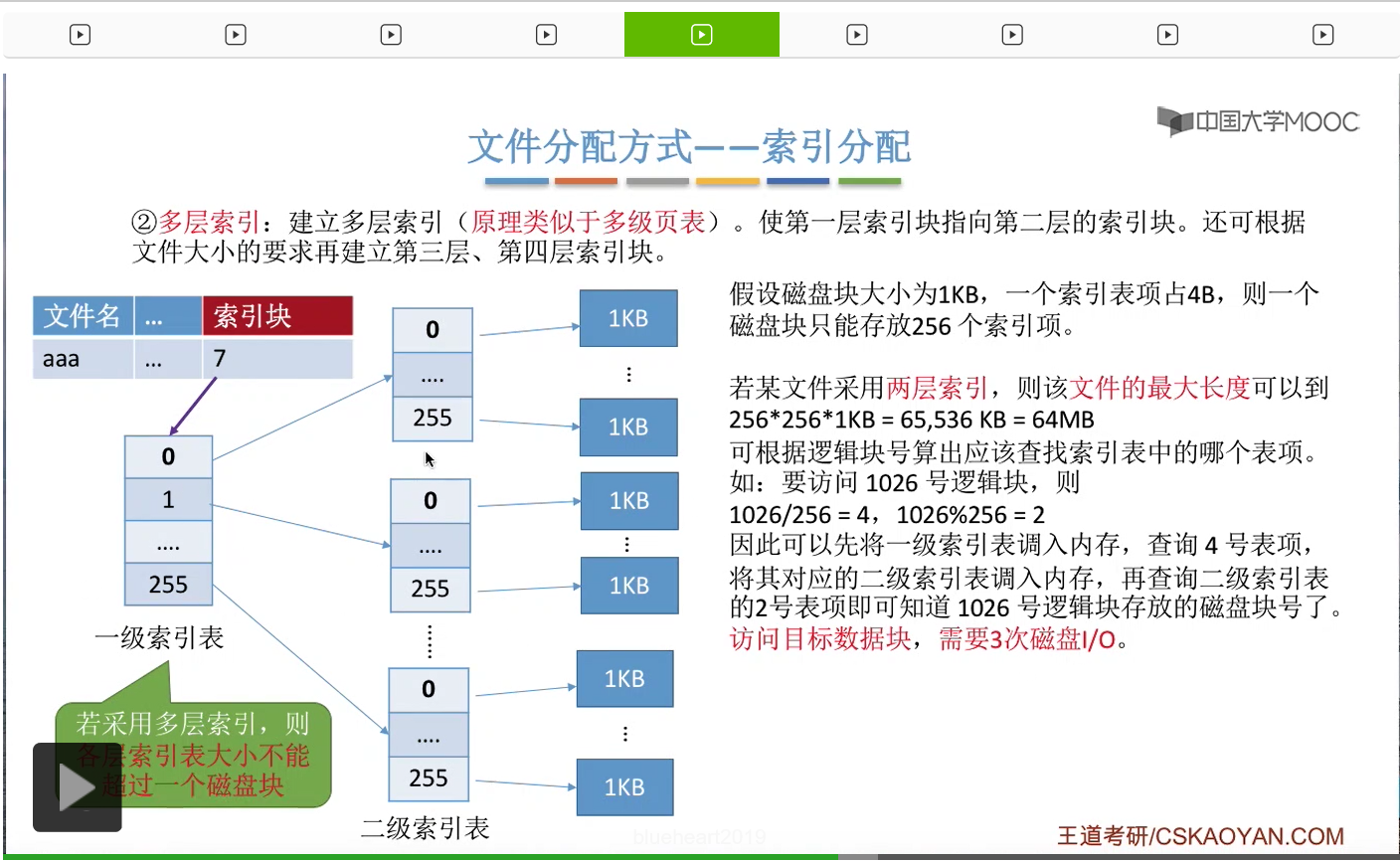
那类似的,如果我们采用的是3层索引的结构的话,那么文件的最大长度应该是256*256*256*1KB=16GB。
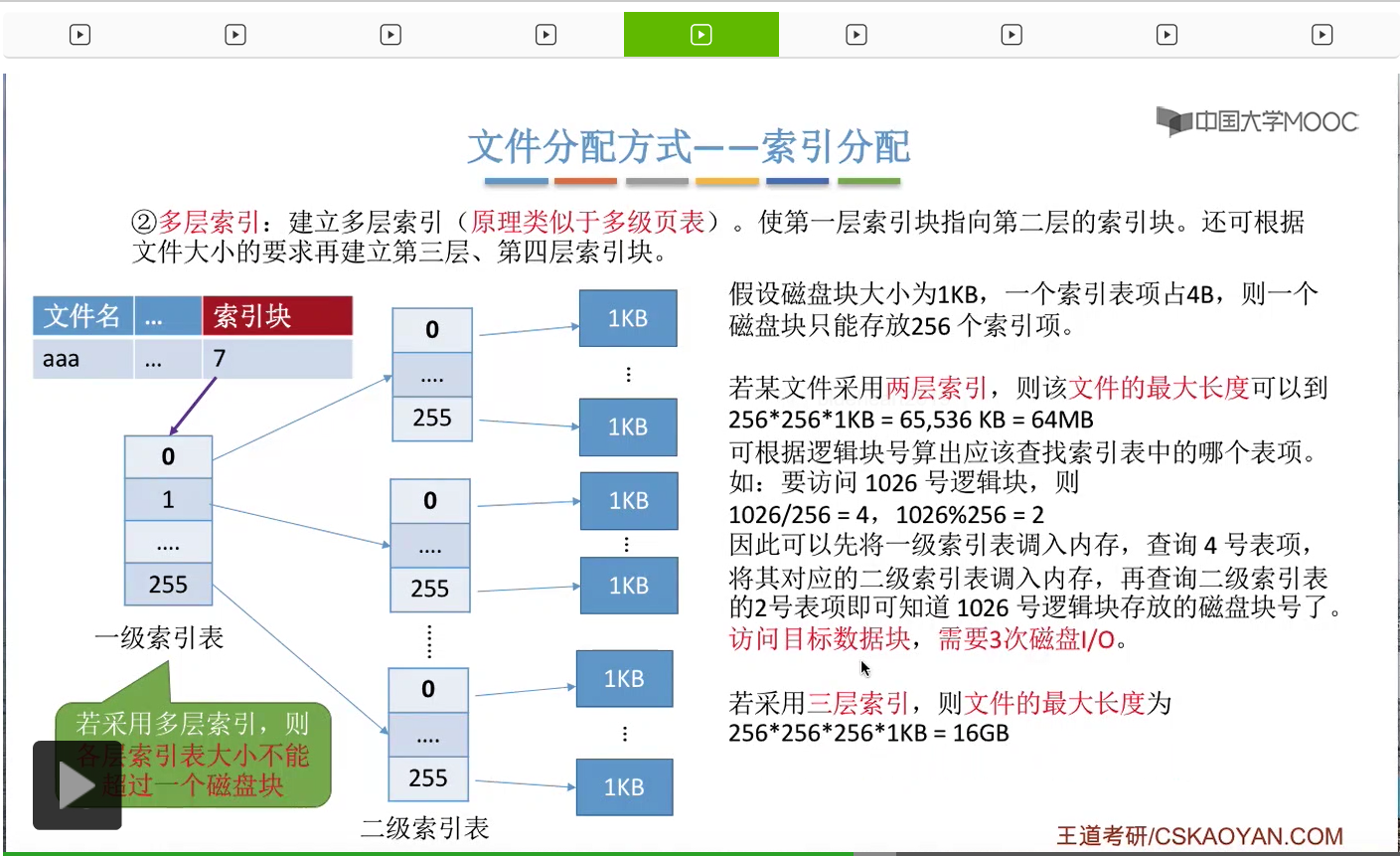
那如果采用3层索引结构的话,那访问一个目标数据块总共需要4次读磁盘的操作。

所以我们得到这样的一个结论。如果我们采用的是K层索引结构,并且顶级索引表的数据还没有调入内存的话,那么根据一个逻辑块号访问一个数据块总共需要K+1次读磁盘操作才可以完成。那相比于之前的那种链接方案来说,这个读磁盘的操作已经是少了很多很多了。那这是多层索引需要注意的问题。第一大家需要学会计算文件的最大长度到底是多少,第二大家还需要学会分析这个访问一个数据块到底需要多少读磁盘操作。不过多层索引的方式也存在一个小小的问题。假如一个文件本来很小,它的数据块只有1KB这么大。但是这个文件如果在物理上采用的是两层索引的这种结构的话,那么读入这个文件1KB的内容依然需要1次读磁盘、两次读磁盘、三次读磁盘操作。那可不可以用某种方式来解决这个问题呢?
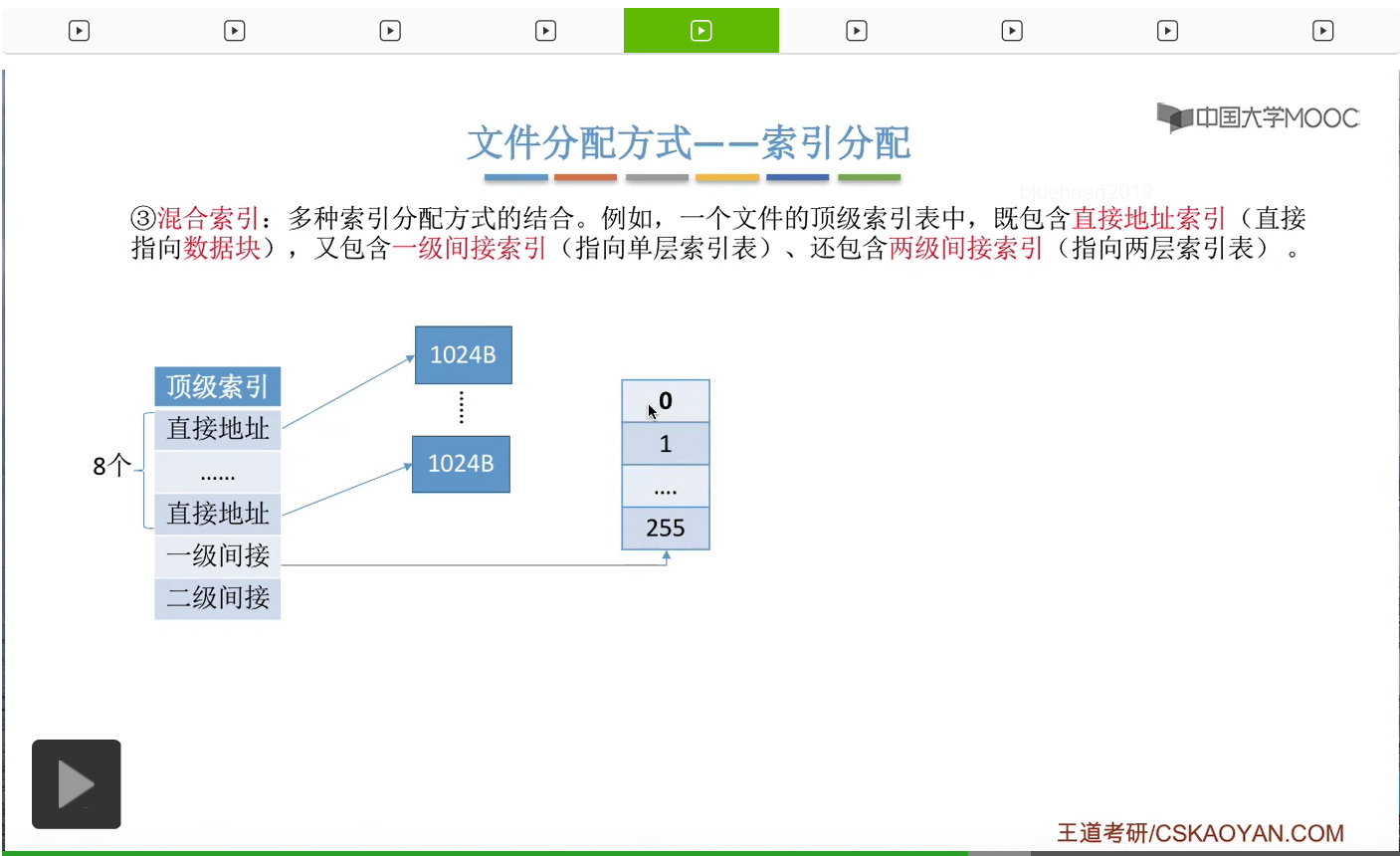
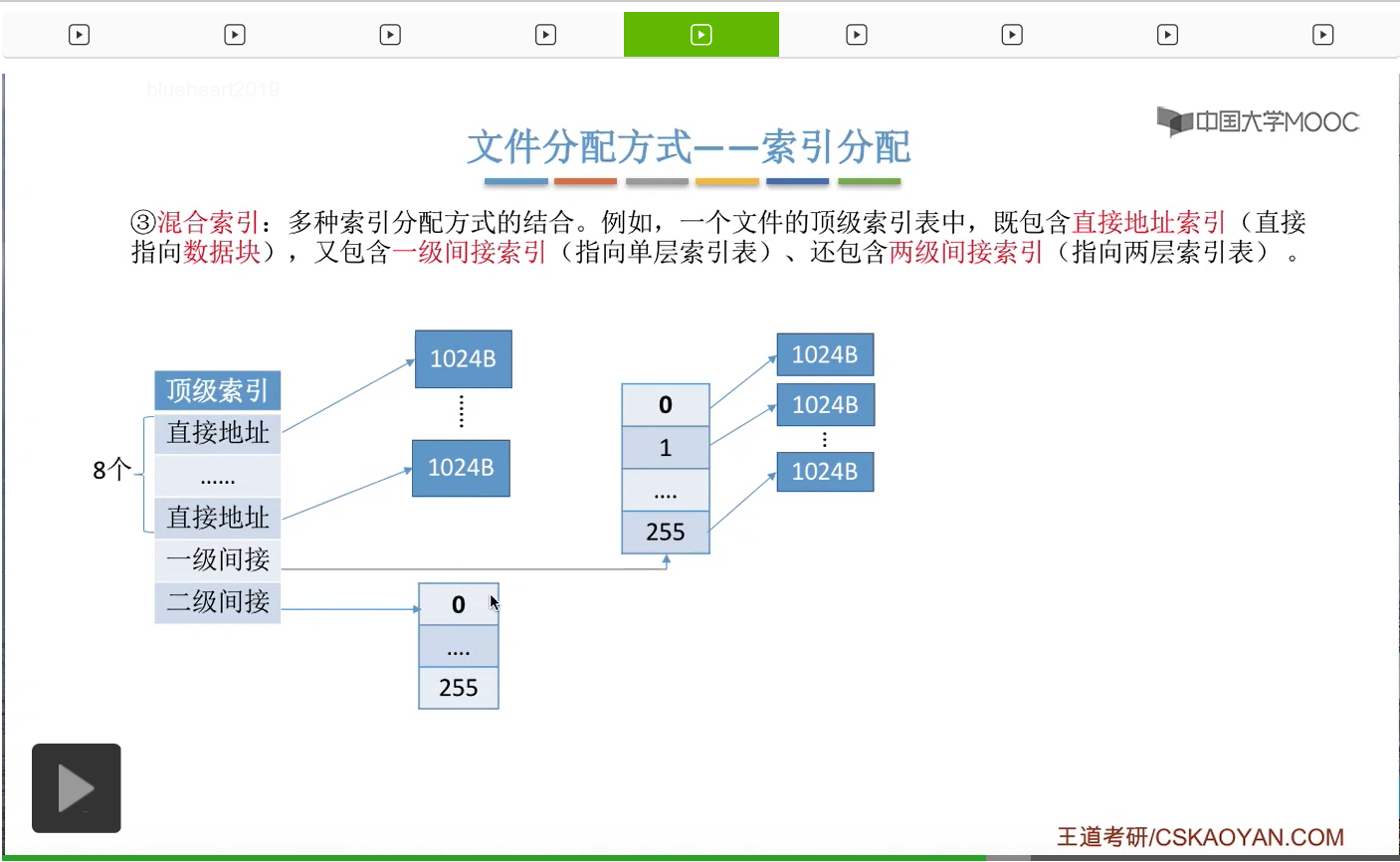
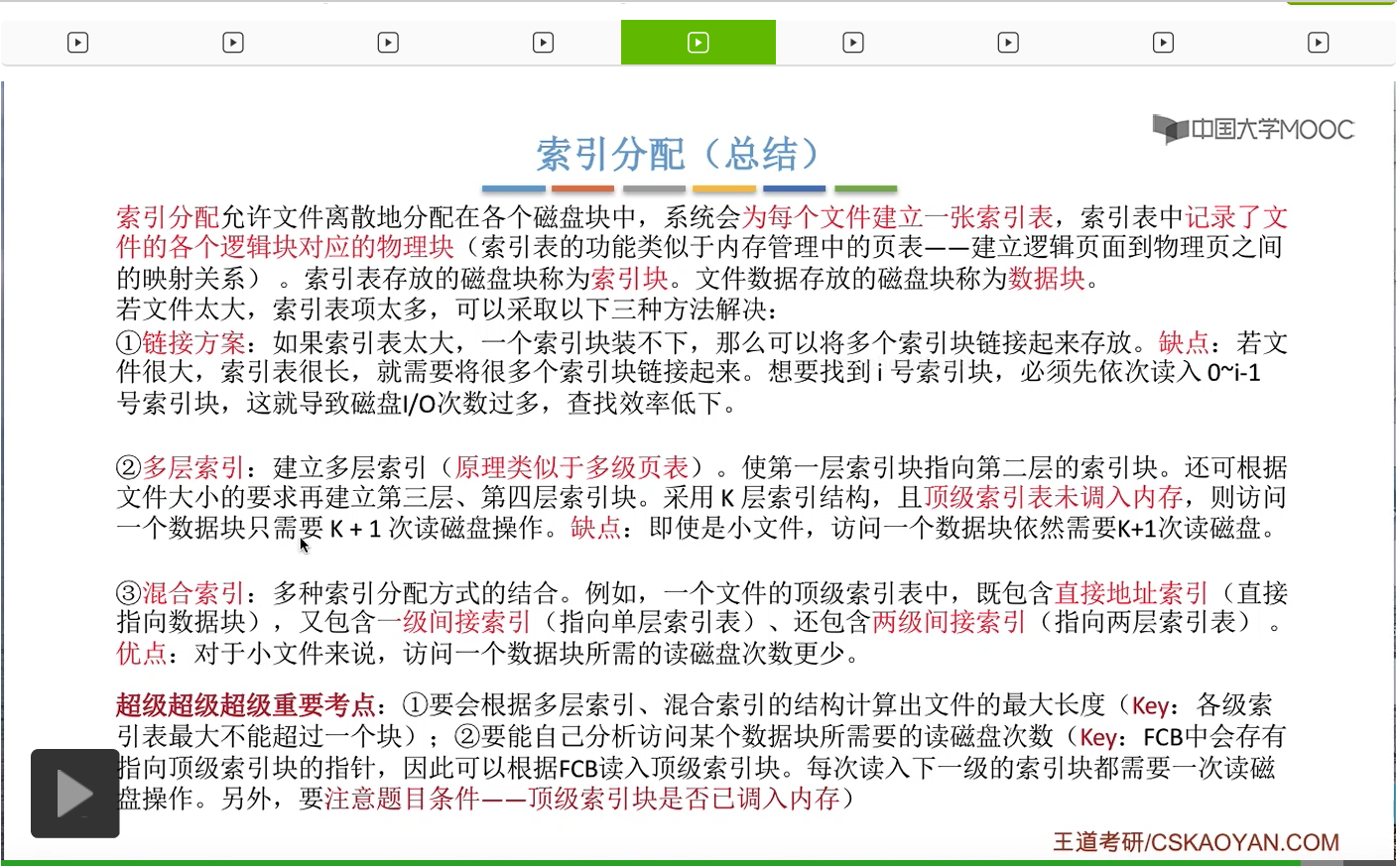
为此,人们又提出了混合索引的这种方案。那混合索引它是多种索引分配方式的一种结合。

比如说一个文件的顶级索引表当中,它可能会包含一些直接地址索引,比如说8个直接地址索引。那所谓的直接地址索引就是指,这些索引项是直接指向了一个数据块,所以8个直接地址索引会对应8个数据块。另外呢,这个顶级索引表当中还有可能会包含一些一级间接索引。

这个一级间接索引会指向一个单层索引表,
那这个单层索引表的各个索引项又会分别指向一个数据块,每个数据块是1KB。
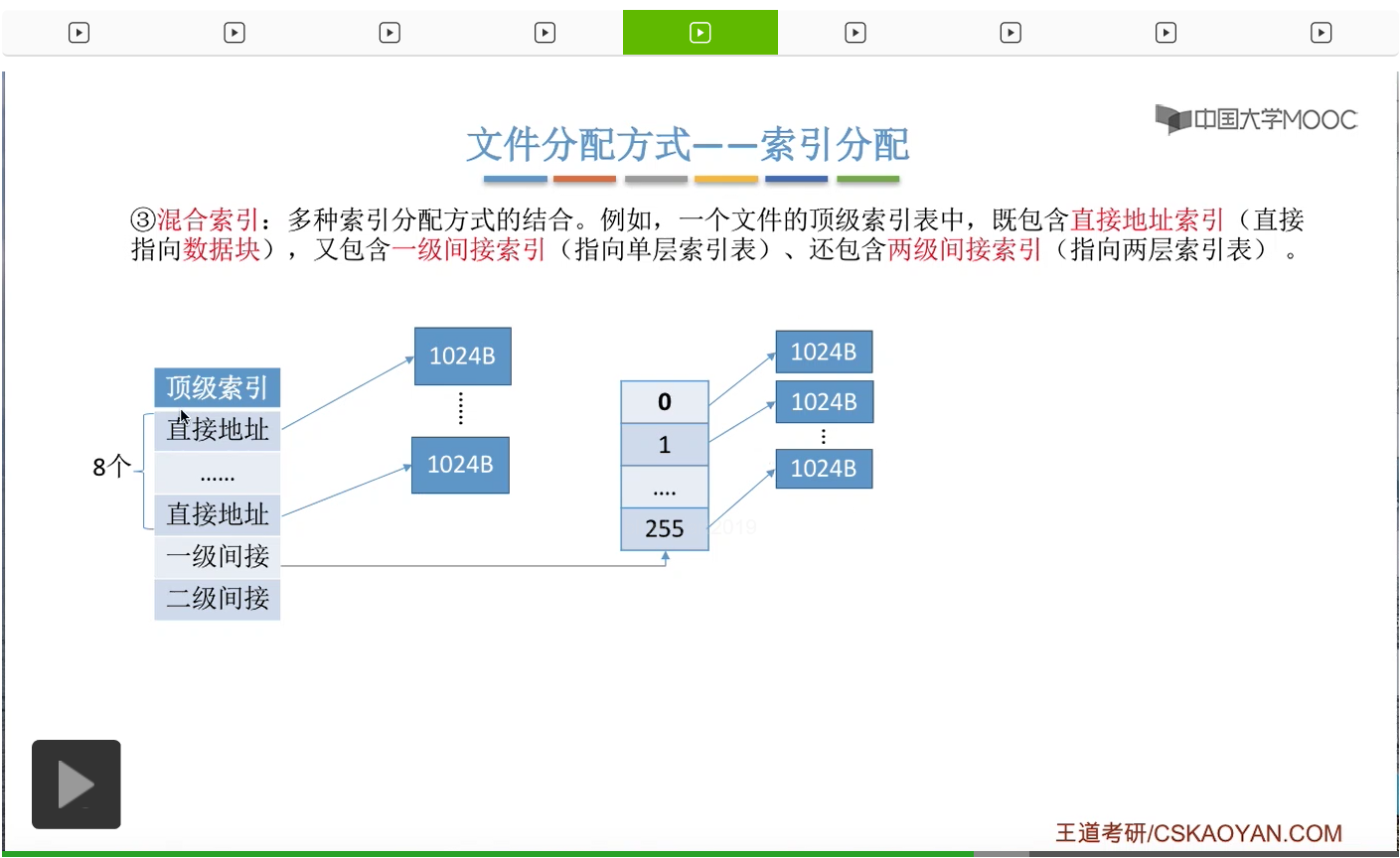
另外,这个顶级索引表还有可能会包含一些二级间接索引。
那这个二级间接索引会指向一个两层索引表,
那这个索引表的各个表项又依次指向了一个下一级的索引表。

而第二层的索引表的各个表项又分别指向一个一个的数据块。
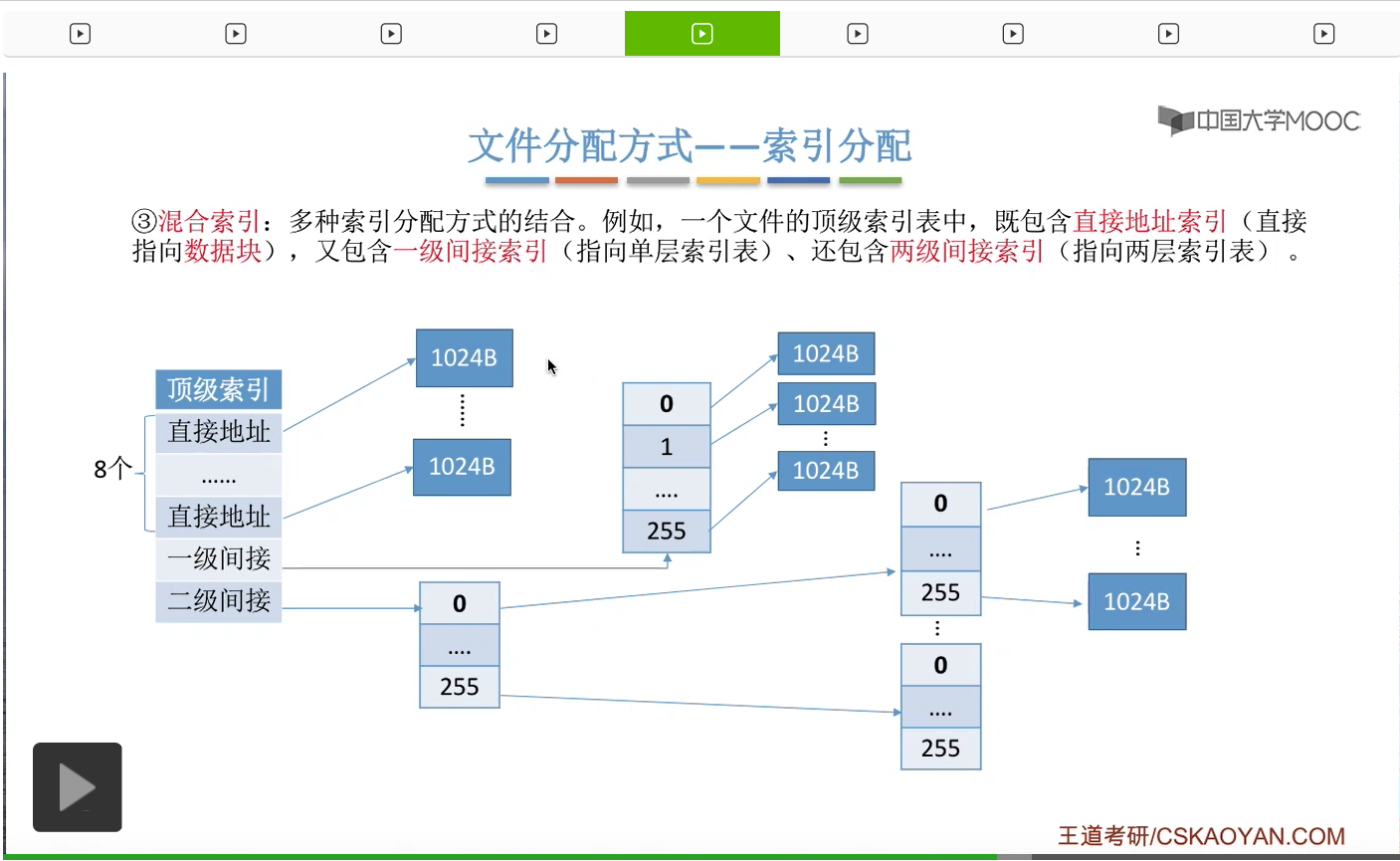
所以如果有8个直接地址索引的话,那它们会分别指向8个数据块。一个一级间接索引会指向一个单层的索引表,
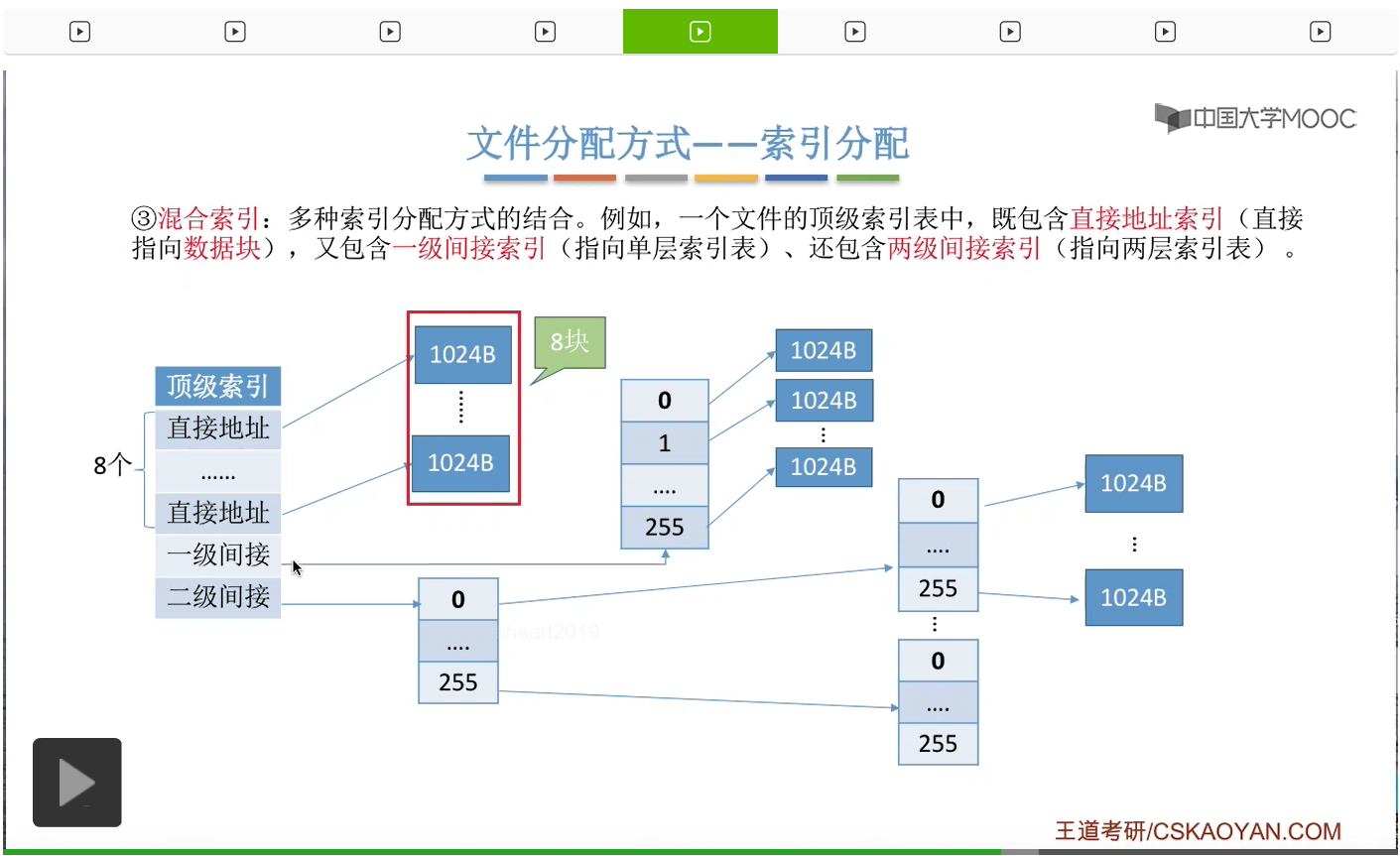
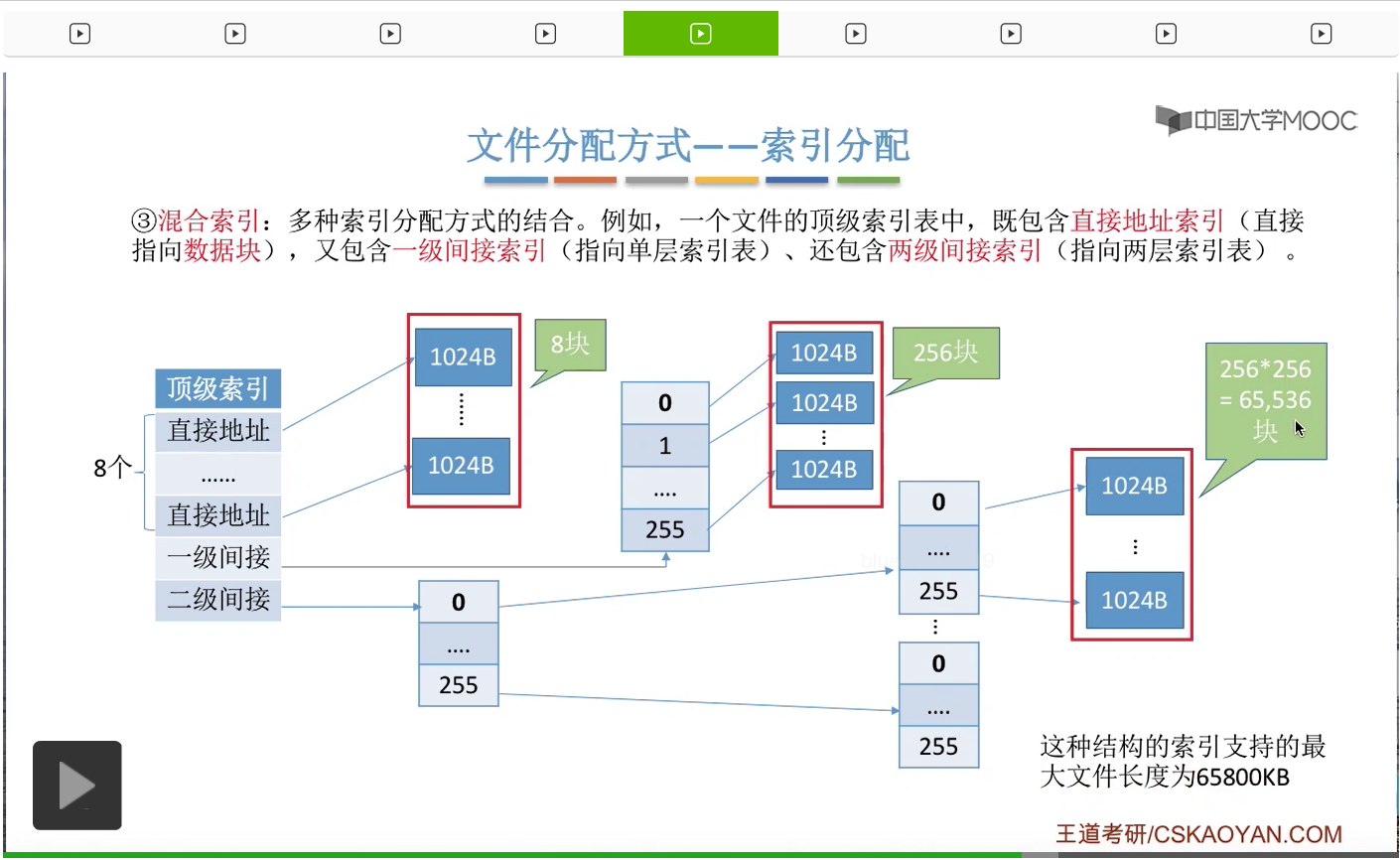
而每个索引表最多只会有256个表项。因此这个索引表最多只会对应256个数据块。

那相应的,二级间接索引最多会指向256*256也就是这么多个数据块。

因此,如果一个文件它的混合索引的顶级索引表是这样的结构的话,那么这个文件的最大长度可以有8+256+256*256=65800KB这么多。那根据顶级索引表的这些结构来计算一个文件的最大长度,这种题型在考试当中也是很常见的,大家需要重点把握。
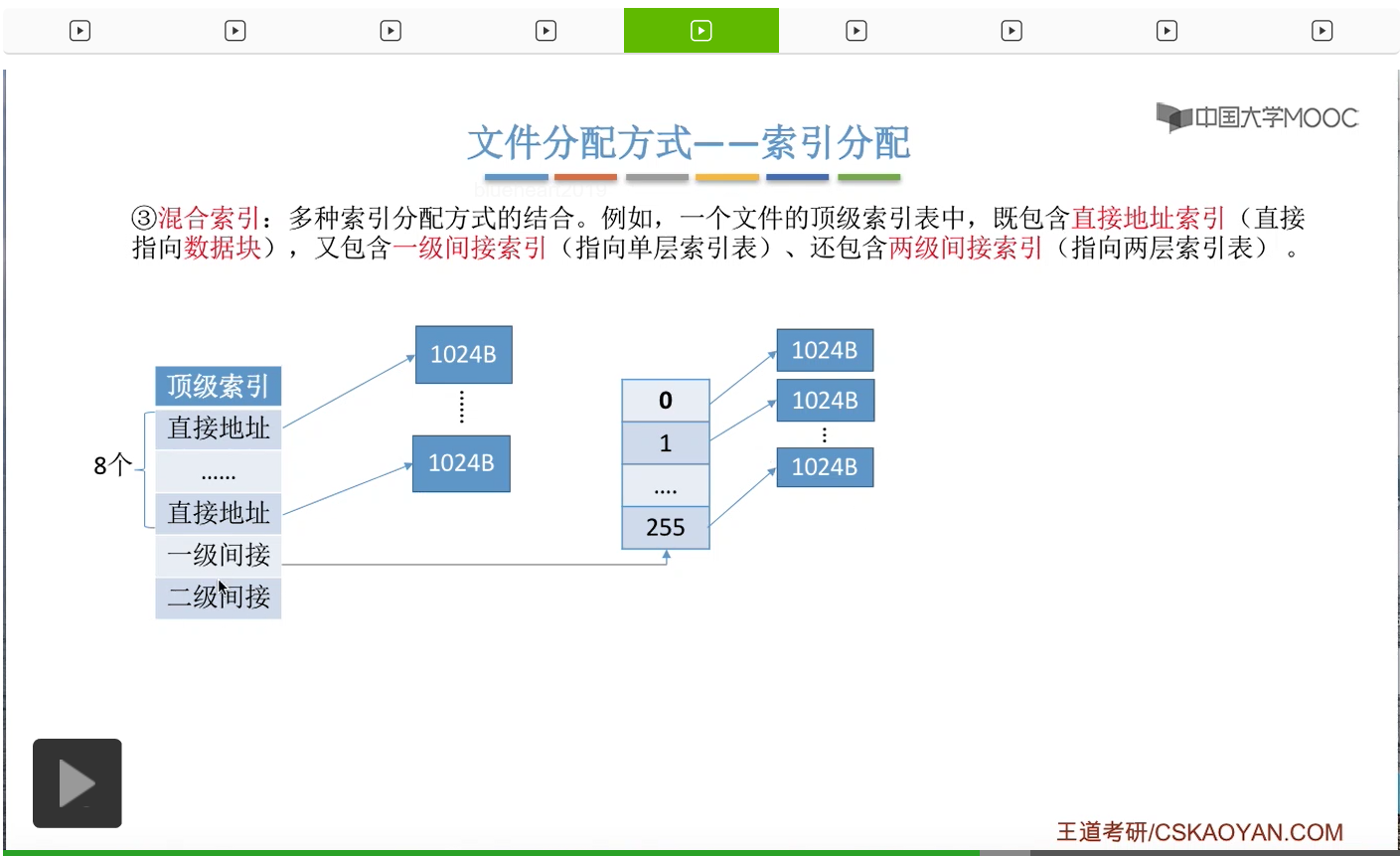
接下来我们来分析一下,如果要访问某一个逻辑块那么需要几次读磁盘操作呢?
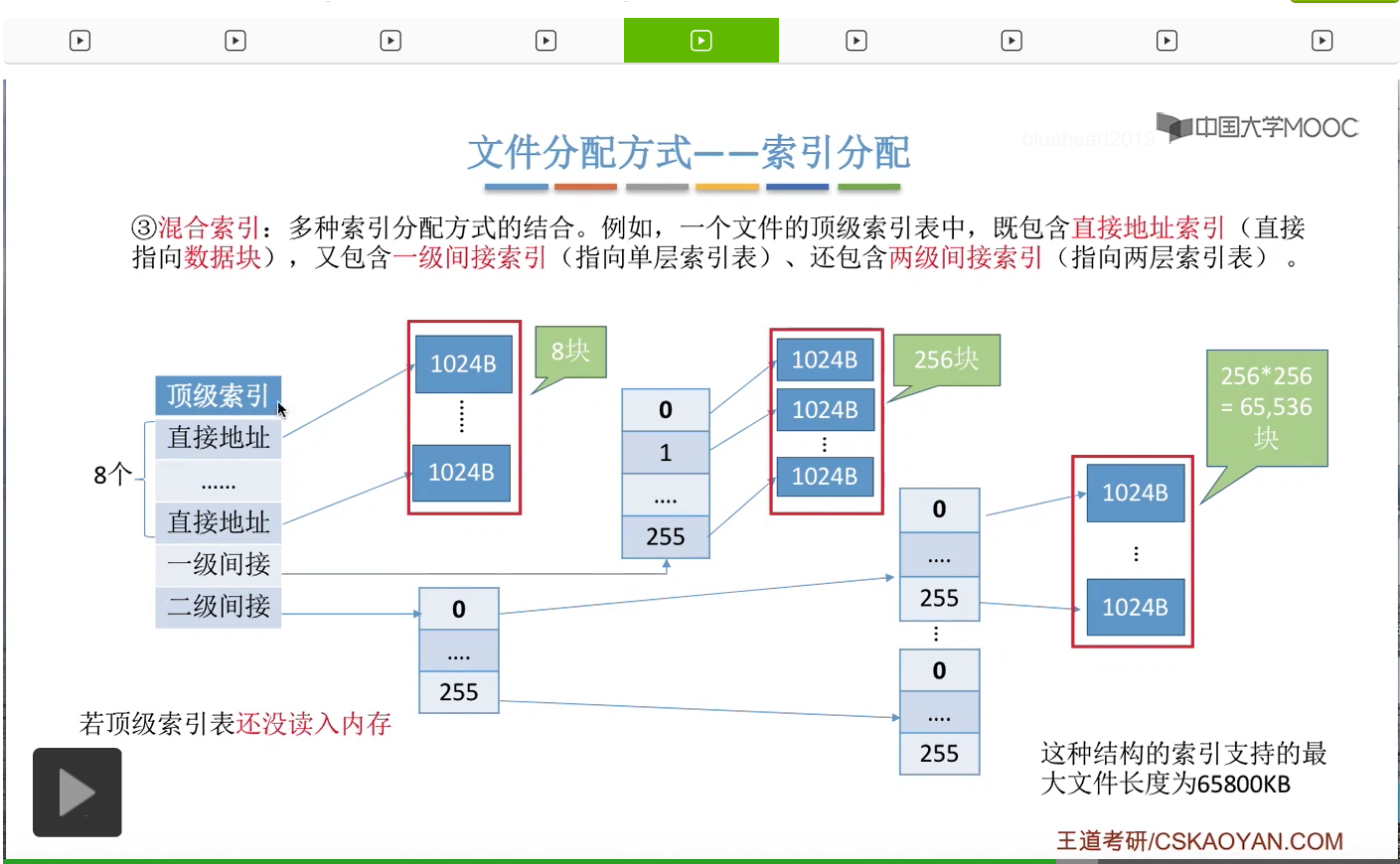
假设此时这个顶级索引表还没有读入内存,那么如果说我们要访问的是0-7号逻辑块,也就是要访问的是这个部分的话,那么我们总共需要两次读磁盘操作。第一次是读入顶级索引表,第二次是根据顶级索引表当中的某一个直接地址找到我们的目标数据块存放的位置,然后再把这个目标数据块读入内存,所以总共需要1次读磁盘、两次读磁盘操作。
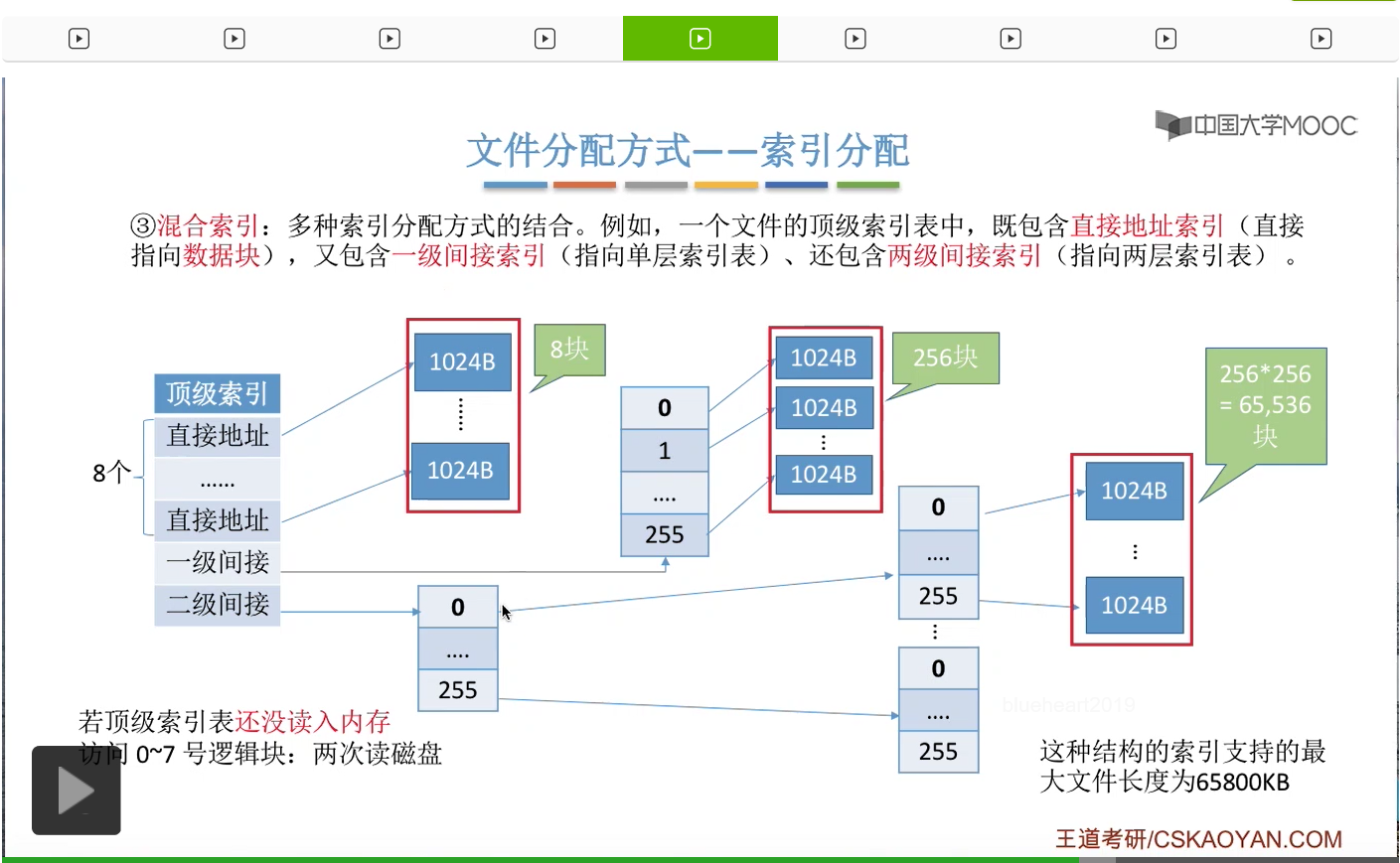
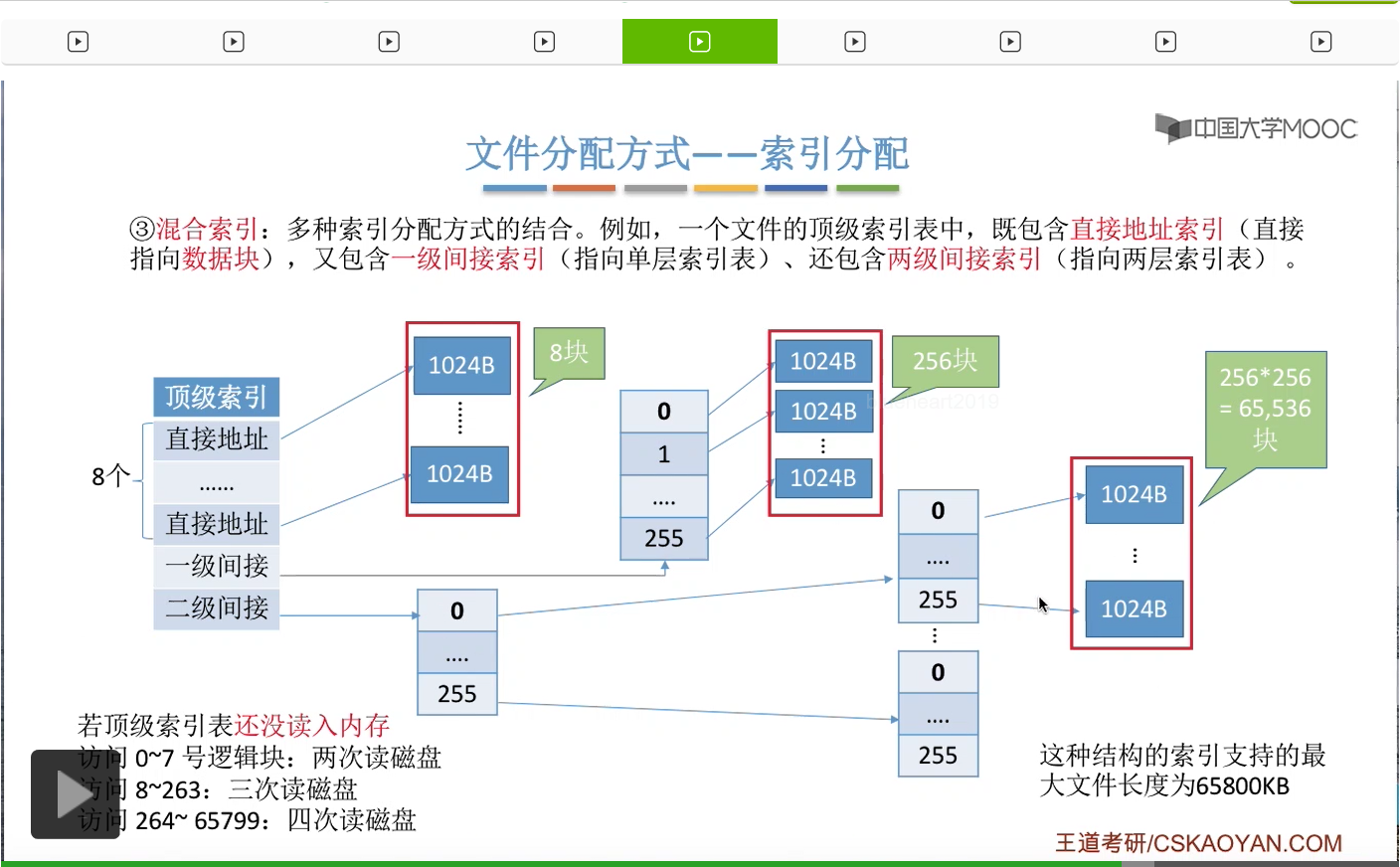
那如果说我们要访问的是8-263号逻辑块,也就是要访问的是这些逻辑块的话,那么总共需要第一次读磁盘操作是读入顶级索引表,第二次是根据这个一级间接索引找到这几个索引表,然后把这个索引表读入内存。第三次是根据这个索引表的内容再找到我们的目标数据块存放的位置,然后再把目标数据块读入内存,所以总共需要1次读磁盘、两次读磁盘操作、三次读磁盘操作。

那相应的,如果我们要读的是这个范围的逻辑块,也就是这些磁盘块的话,那么总共需要1次、两次、三次、四次读磁盘操作。
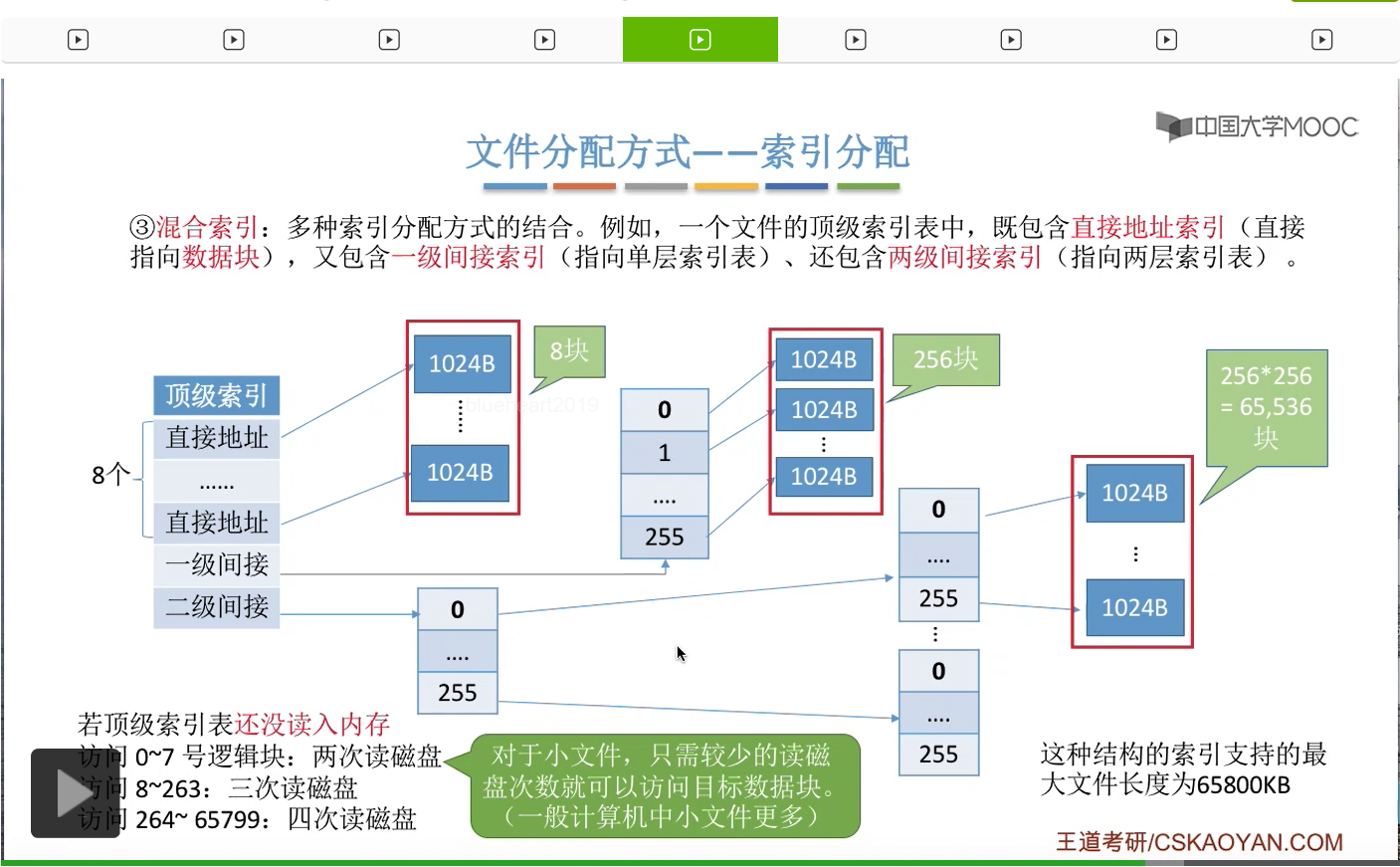
所以可以看到,采用混合索引的一个好处就是,对于小文件来说,它可能只需要占用前面的这几个块就可以了。那小文件的读取,只需要访问比较少的读磁盘的次数。那一般来说,我们计算机当中小文件是更多的,所以这是混合索引这种方式带来的一个好处。
好的,那么我们介绍了当文件太大、索引表项太多的时候可以采取的三种解决方案。第一种链接方案,就是把各个索引块用链接的方式把它连起来。但是它所带来的缺点就是,如果一个文件很大,索引表很长的话,那么想要找到i号索引块就必须先依次读入0-i-1号索引块,这就导致要查询一个索引项的时候,磁盘I/O次数可能会很多的问题。所以这种方案查找效率低下。
为此,我们可以建立多级索引。就有点类似于我们在内存管理当中采用的多级页表那样,然后第一层的索引块会指向第二层的索引块,如果说一个文件很大的话,甚至还可以建立三层、四层的索引块。那如果我们采用的是K层索引结构,并且顶级索引表还暂时没有调入内存的话,那么访问一个数据块只需要K+1次读磁盘的操作。但是这种方式的缺点呢就是即使是小文件,访问一个数据块依然是需要K+1次读磁盘操作。
所以人们又提出了混合索引这种方式。一个文件的顶级索引表当中,可以既包含直接地址索引,也包含一级间接索引,也包含二级间接索引。那直接地址索引会直接指向一个数据块。而一级间接索引会指向一个单层的索引表,这个索引表呢再依次又指向各个数据块。而两层间接索引是指向一个两层的索引表。那如果采用这种混合索引的方式的话,对于小文件来说,访问一个数据块所需要的读磁盘次数就可以变得更少了。

那索引分配方式在考试当中是经常进行考查的。无论是小题还是大题。所以大家需要重点掌握的是这样的两个点。第一,要学会根据多级索引或者混合索引的那种结构来计算出一个文件的最大长度是多少。那要计算最大长度,大家最关键的是需要理解各级索引表最大是不能超过一个块的,要知道这个条件。第二个大家要学会的是要能够自己分析访问某一个数据块或者说访问某一个逻辑块号对应的物理块所需要的读磁盘次数到底是多少?那操作系统需要从外存当中依次地读入顶级索引块,然后再下一级的索引块,再下一级的索引块,依次类推。那大家需要注意的是题目当中的条件,顶级索引块到底是不是已经调入内存了。那这个部分的内容十分重要,特别是混合索引相关的知识点,很容易综合地来考查大家,所以大家还需要根据大量的课后习题来进行进一步的巩固。
那这个地方我们再把上个小节和这个小节的内容进行一个汇总、总结。我们需要掌握各种分配方式的一个思想。像顺序分配就是要求为文件分配的必须是连续的磁盘块,而链接分配又分为显式链接和隐式链接两种,它们都可以为文件分配离散的磁盘块。而隐式链接是把每个磁盘块都用链接指针的方式把它们链起来。显式链接的话是为磁盘建立一个文件分配表,然后在这个表当中记录各个磁盘块的先后关系。并且这个文件分配表是在开机的时候就会调入内存,并且之后会一直常驻内存。而索引分配方案会为文件的数据块建立一些索引表。而如果文件的索引表太大的话,又可以采用链接方案、多层索引和混合索引这几种方式来解决。那采用不同的分配方式,在文件的目录项FCB当中,所需要记录的这些信息也是有一定的区别的。另外,大家还需要理解这些各种分配方式的优点和缺点。各种分配方式的优点和缺点很容易在选择题当中进行考查。那最后还需要强调一遍,如果说题目当中只是简单地告诉我们一个文件采用的是链接分配方式,而并没有告诉我们它到底是隐式还是显式链接的话,我们一般都是默认为它指的链接分配是隐式链接的方式。

开始学习文件存储空间管理相关的知识点,

那在之前的小节中我们学习了文件的物理结构,也就是对非空闲磁盘块的管理。
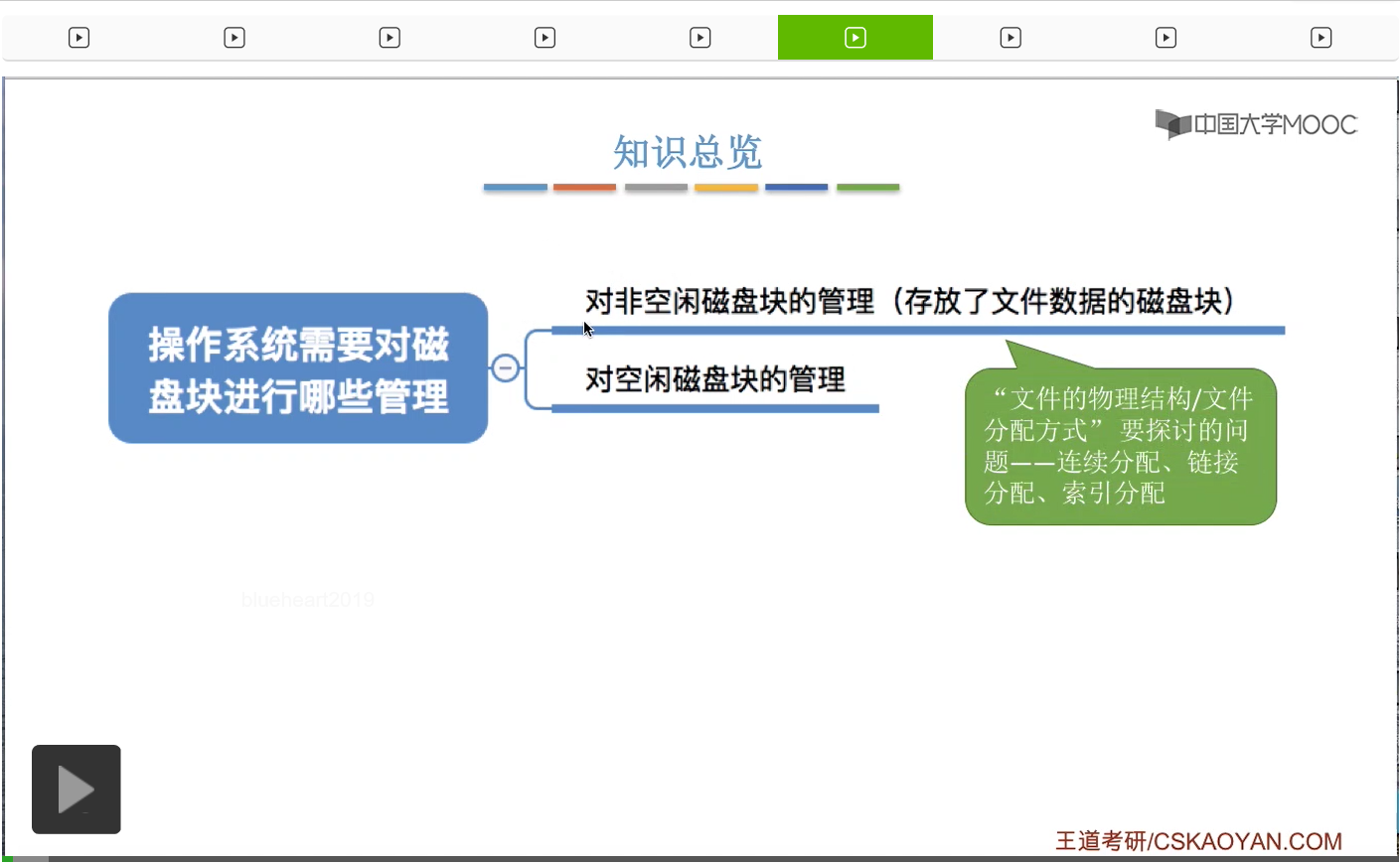
那在这个小节中学习的对存储空间的管理其实就是对空闲的那些磁盘块的管理。

那么这个小节我们首先会介绍存储空间的划分和初始化,要介绍几个比较重要的概念,文件卷、目录区和文件区。之后这个小节的重点内容是要介绍这个存储空间管理的几种方法。空闲表法,空闲链表法,位示图法和成组链表法,我们会按照从上至下的顺序依次讲解。那在学习这几种管理方法的时候,大家需要从这样的三个角度进行理解和记忆。第一,这样的方法是用什么样的数据结构、什么方式来记录那些空闲的磁盘块的。第二,要注意的是用某一种方法是怎么分配磁盘块的。第三个是要注意怎么回收磁盘块。
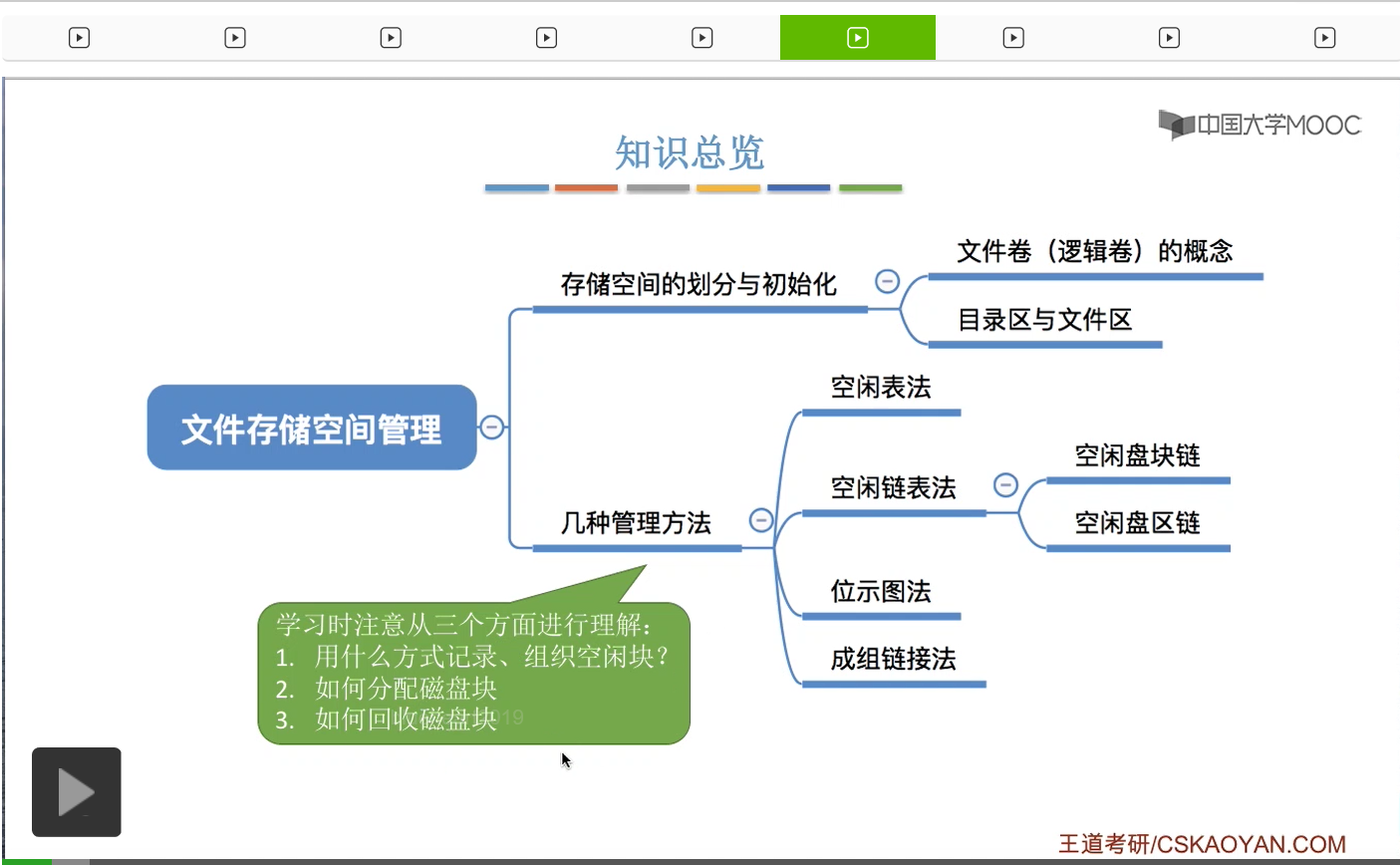
那我们首先来看存储空间的划分与初始化。那我们的一些文件就是存放在这些各个文件卷里的。
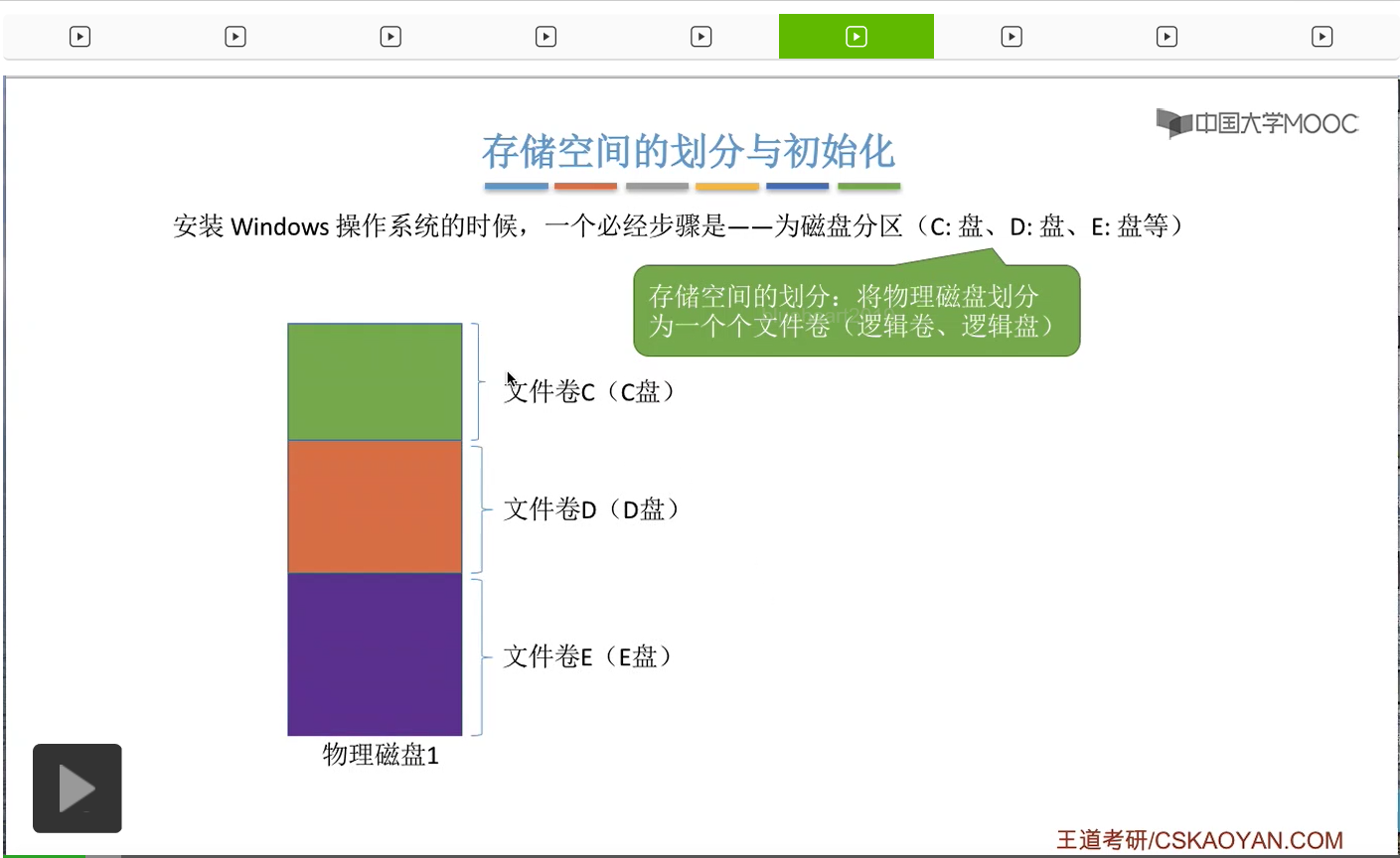
另外,在存储空间的初始化的过程当中,也需要把这些文件卷进行进一步的划分,划分为目录区和文件区。


其中目录区主要是用于存放文件目录相关的一些信息,像咱们之前学过的文件目录项FCB还有索引结点这些就是存放在目录区当中的。另外呢,用于磁盘存储空间管理的那些信息、那些数据结构也是存放在目录区当中的。就比如说咱们这个小节接下来会学习的什么空闲表啊还有位示图啊之类的这些数据结构,就是要存放在目录区当中。
 那文件区呢就是用来存放普通的文件数据。所以这是文件区和目录区的区别。
那文件区呢就是用来存放普通的文件数据。所以这是文件区和目录区的区别。
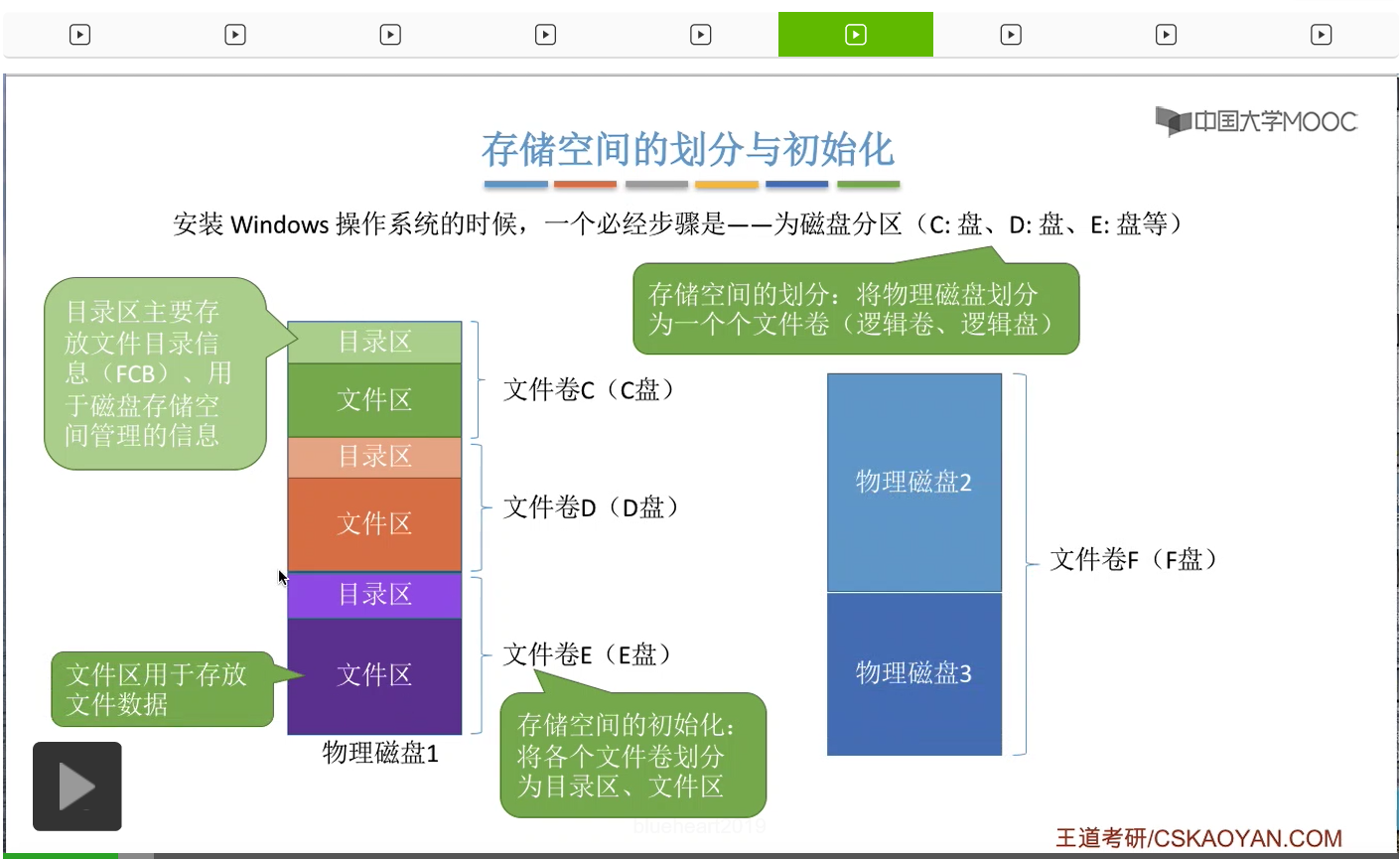
另外,在有的支持超大型文件的那些操作系统当中,也支持多个物理磁盘组成一个文件卷。那像平时咱们自己使用的电脑都是把一个物理磁盘划分成多个这种逻辑磁盘,但是在有的系统当中可以把多个物理磁盘合并成一个逻辑磁盘,一个文件卷。那这是存储空间的划分与初始化需要注意的几个知识点。首先需要知道什么是文件卷或者叫逻辑卷、逻辑盘。另外呢我们需要知道文件卷会划分目录区和文件区。也还需要知道文件区和目录区分别是用于存放什么数据的。另外我们需要注意的是,文件卷是可以由多个物理磁盘组成的。
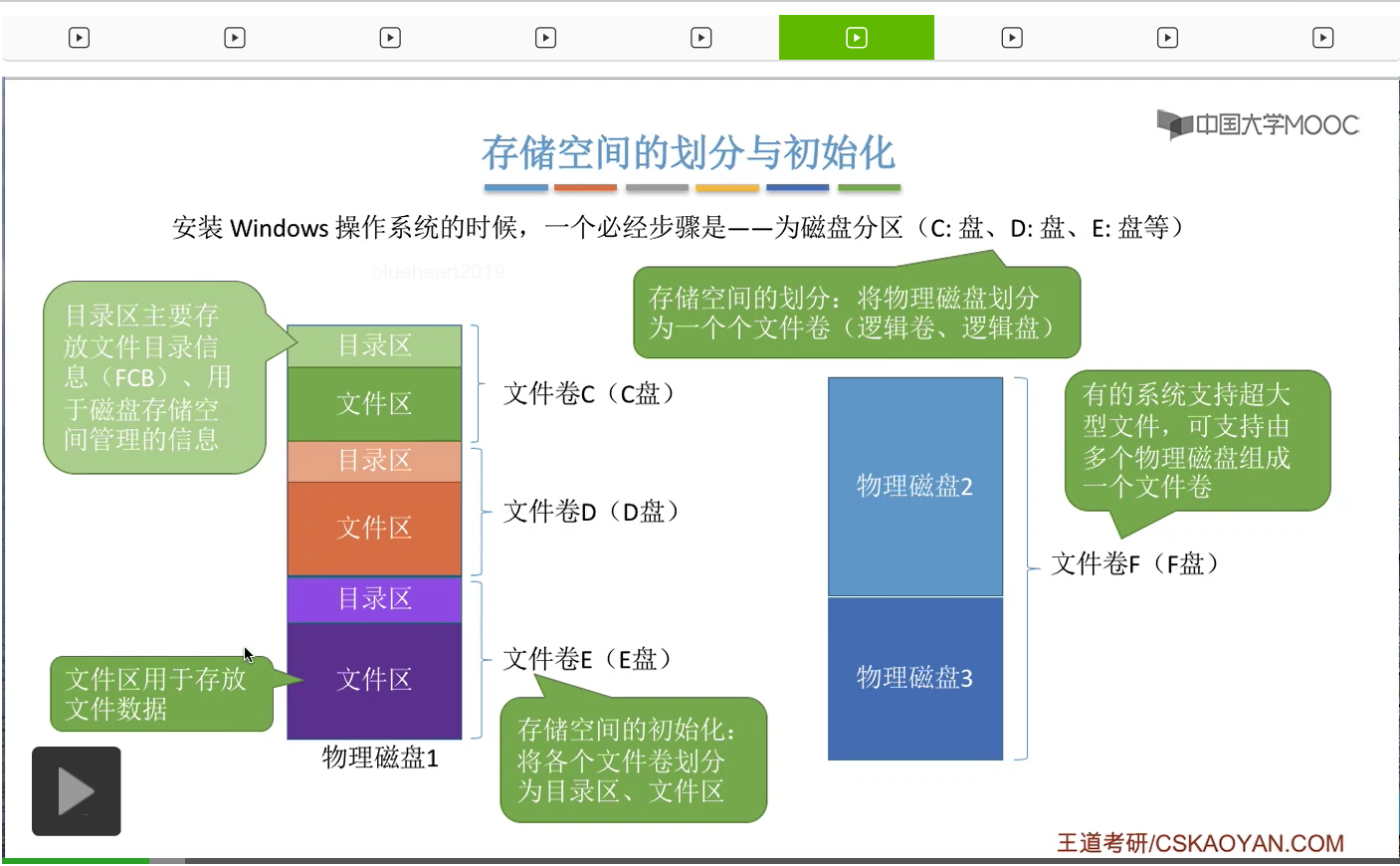
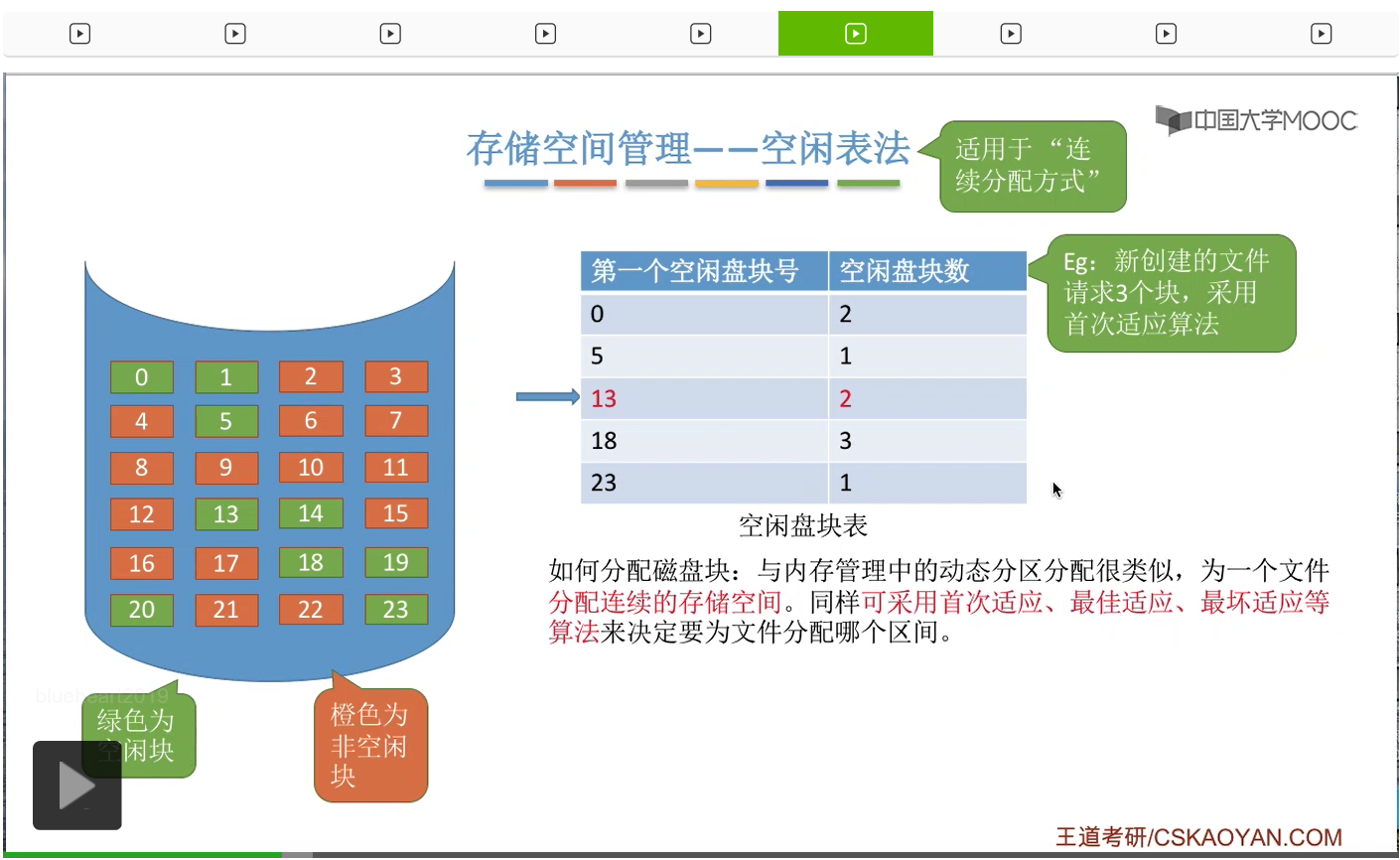
那接下来我们来看第一种存储空间的管理方法——空闲表法。其实这个空闲表和我们在内存管理的动态分区分配当中学习过的空闲表是极其类似的,它就是记录了每一个空闲区间的起始位置还有这个空闲区间的长度这两个信息。那空闲表法一般来说适用于文件的物理结构是连续分配的这种场景下。
 那接下来我们要探讨的问题,采用这种方法应该怎么分配磁盘块。其实和内存管理的动态分区分配是很类似的,我们首先需要知道的是,采用这种方式的话,那为文件分配的是一个连续的存储空间。那我们同样可以采取像首次适应、最佳适应、最坏适应这些算法来决定到底要为文件分配哪一个空闲区间。
那接下来我们要探讨的问题,采用这种方法应该怎么分配磁盘块。其实和内存管理的动态分区分配是很类似的,我们首先需要知道的是,采用这种方式的话,那为文件分配的是一个连续的存储空间。那我们同样可以采取像首次适应、最佳适应、最坏适应这些算法来决定到底要为文件分配哪一个空闲区间。
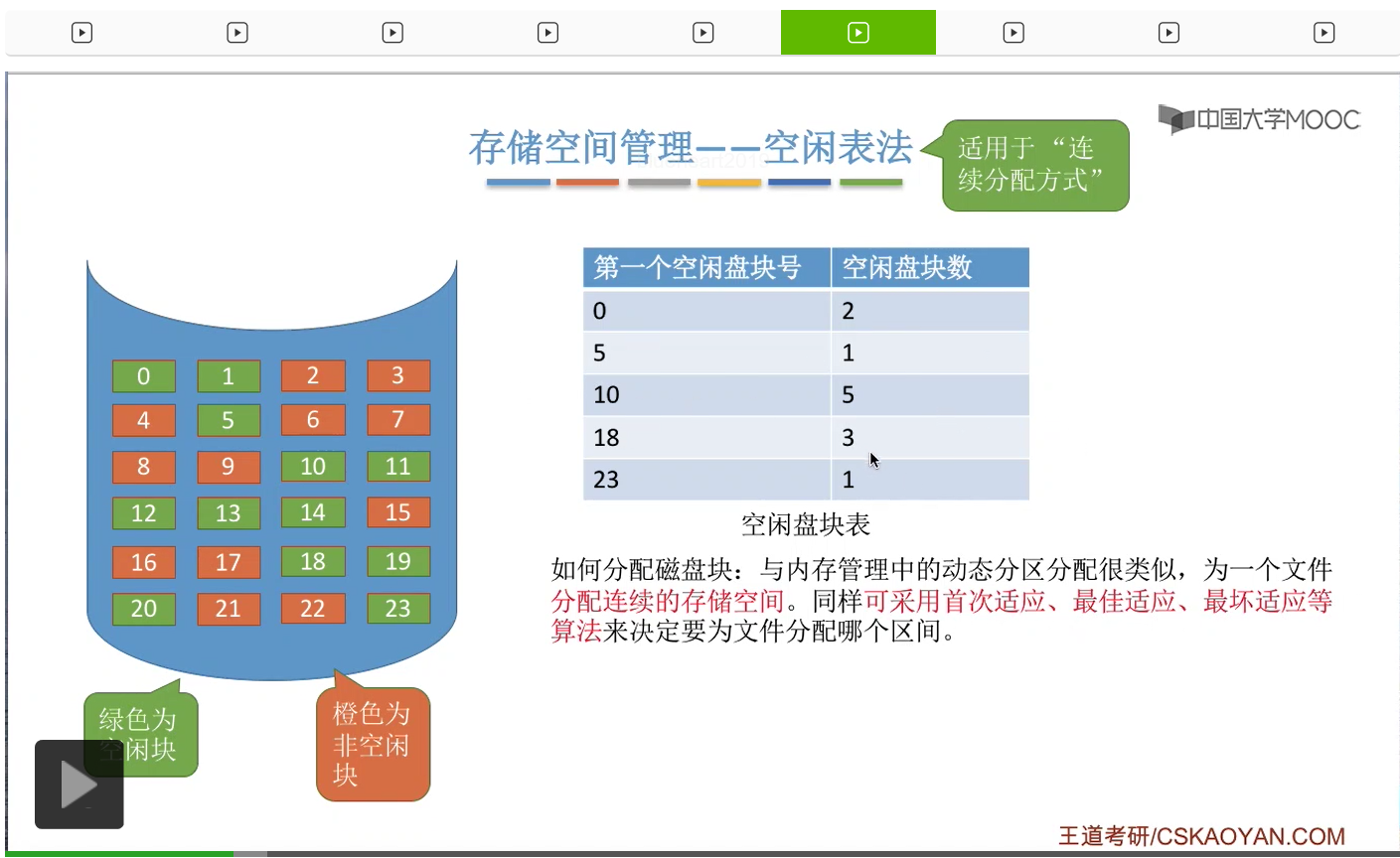
那我们直接来举一个例子。
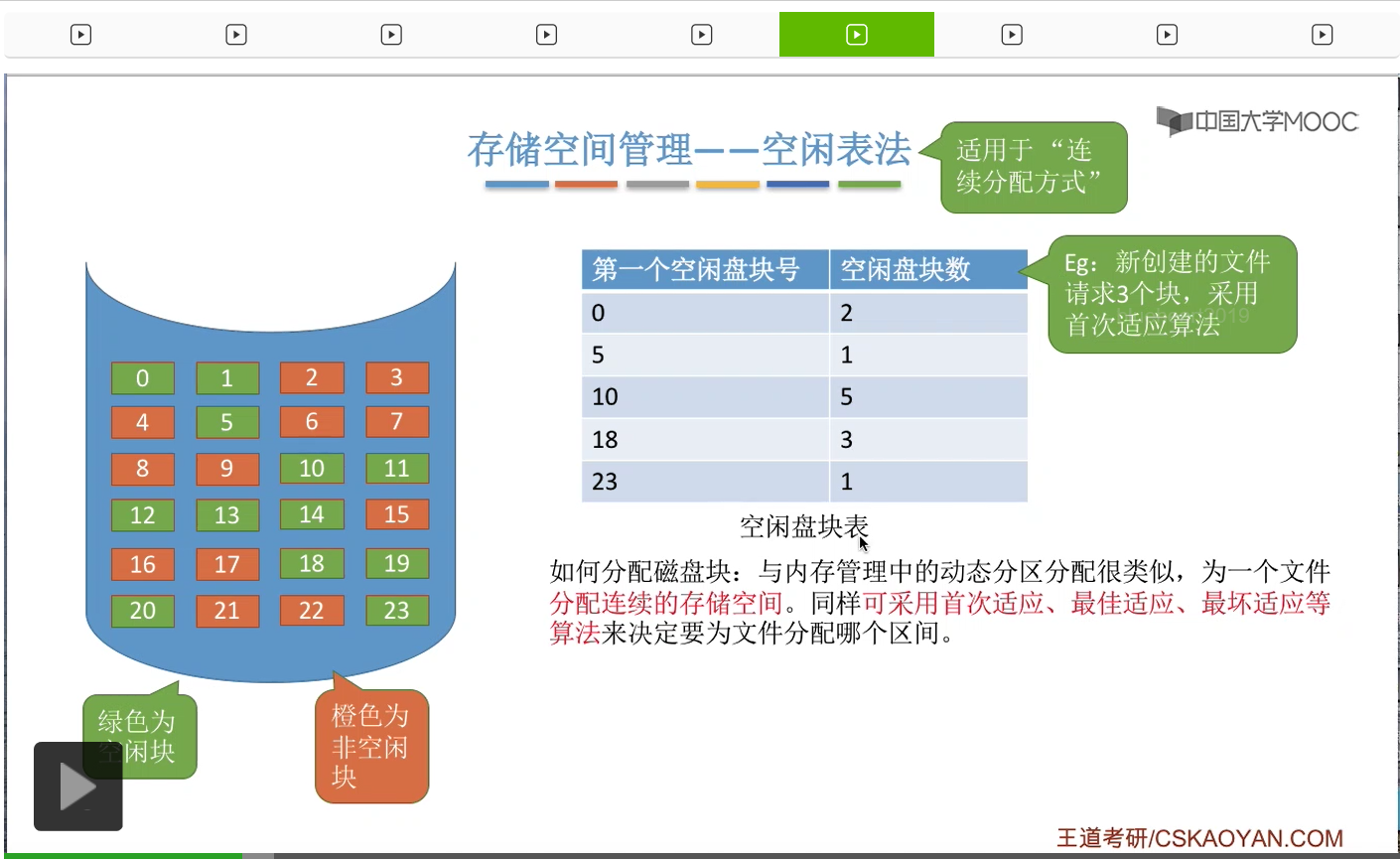
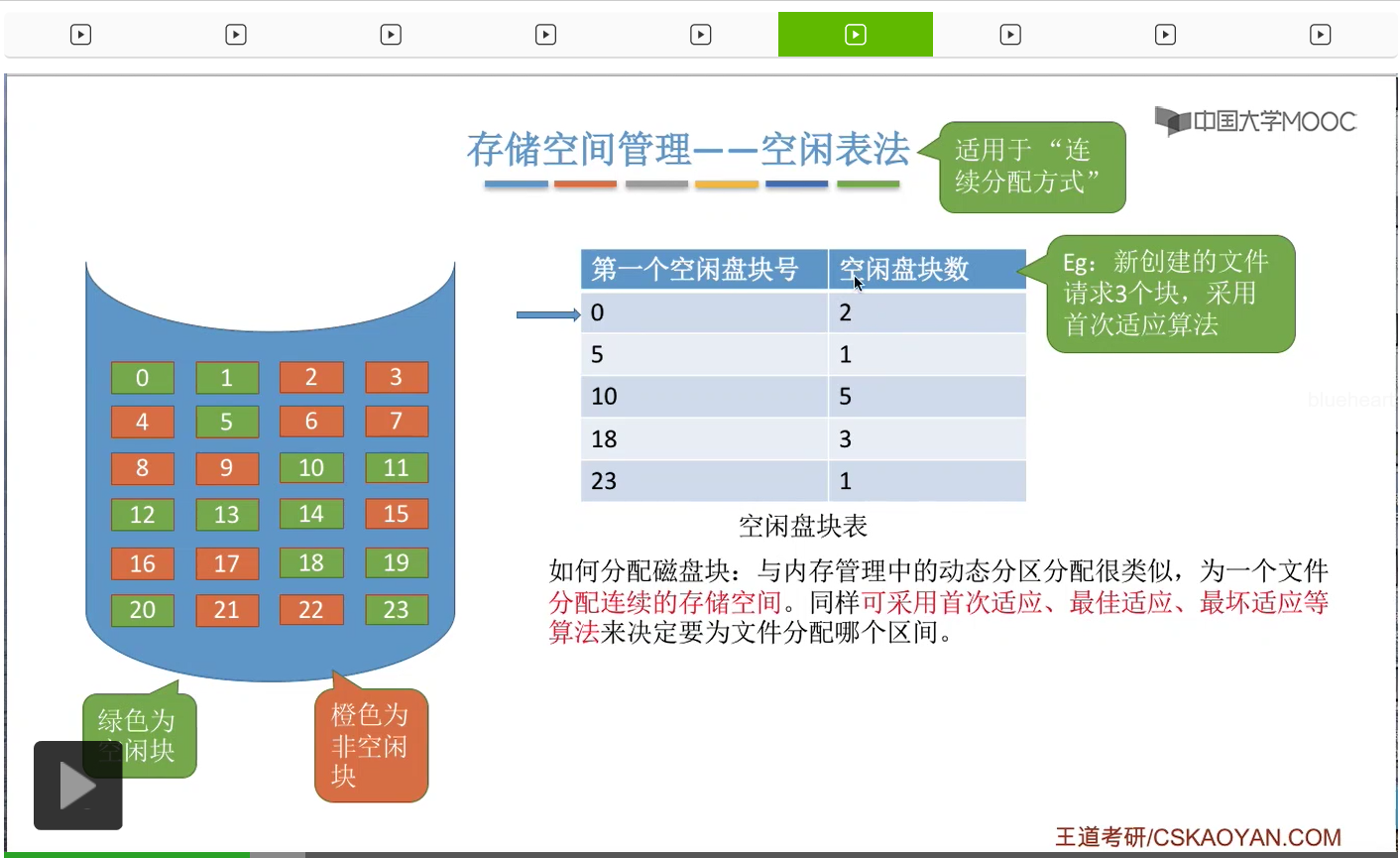
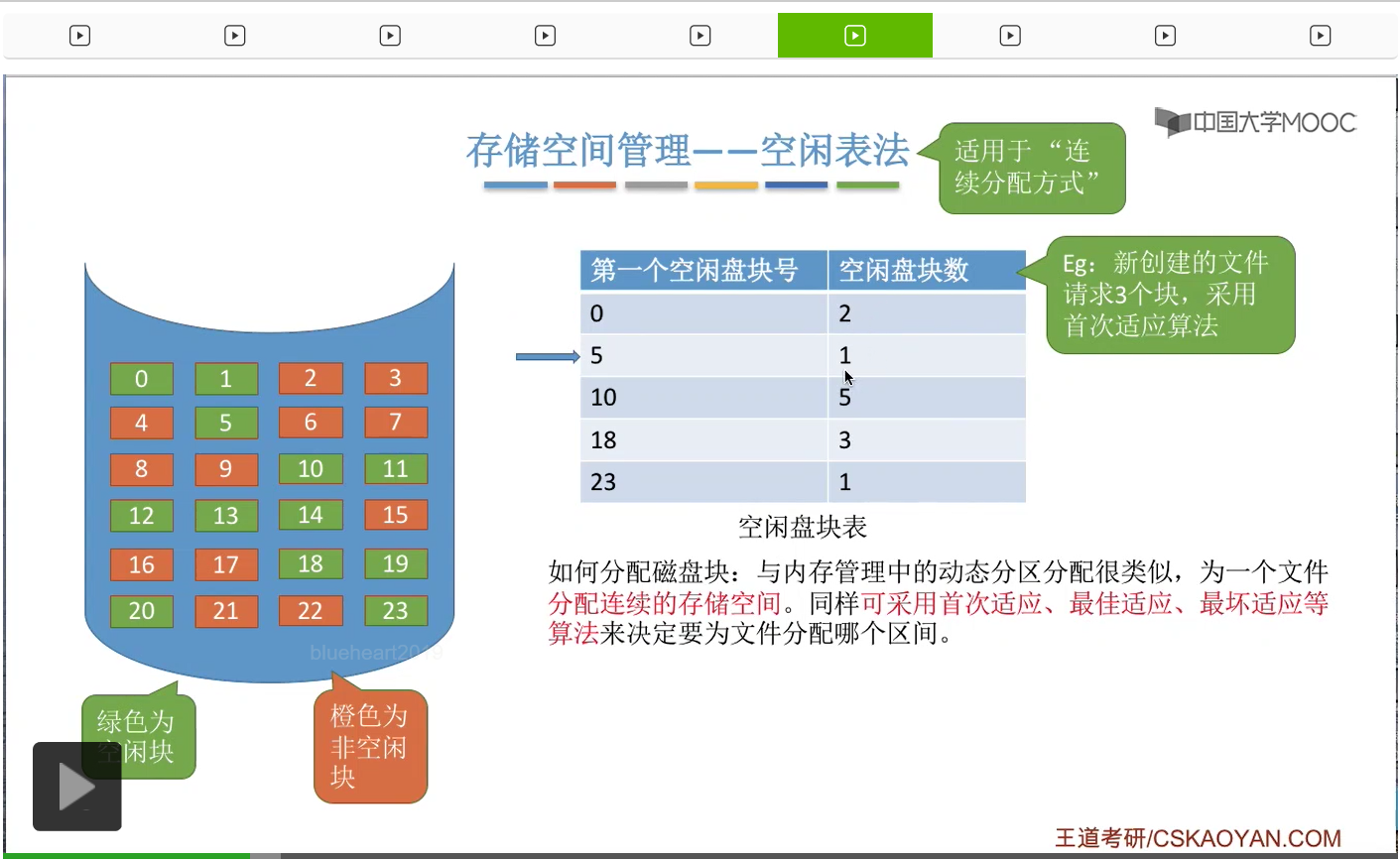
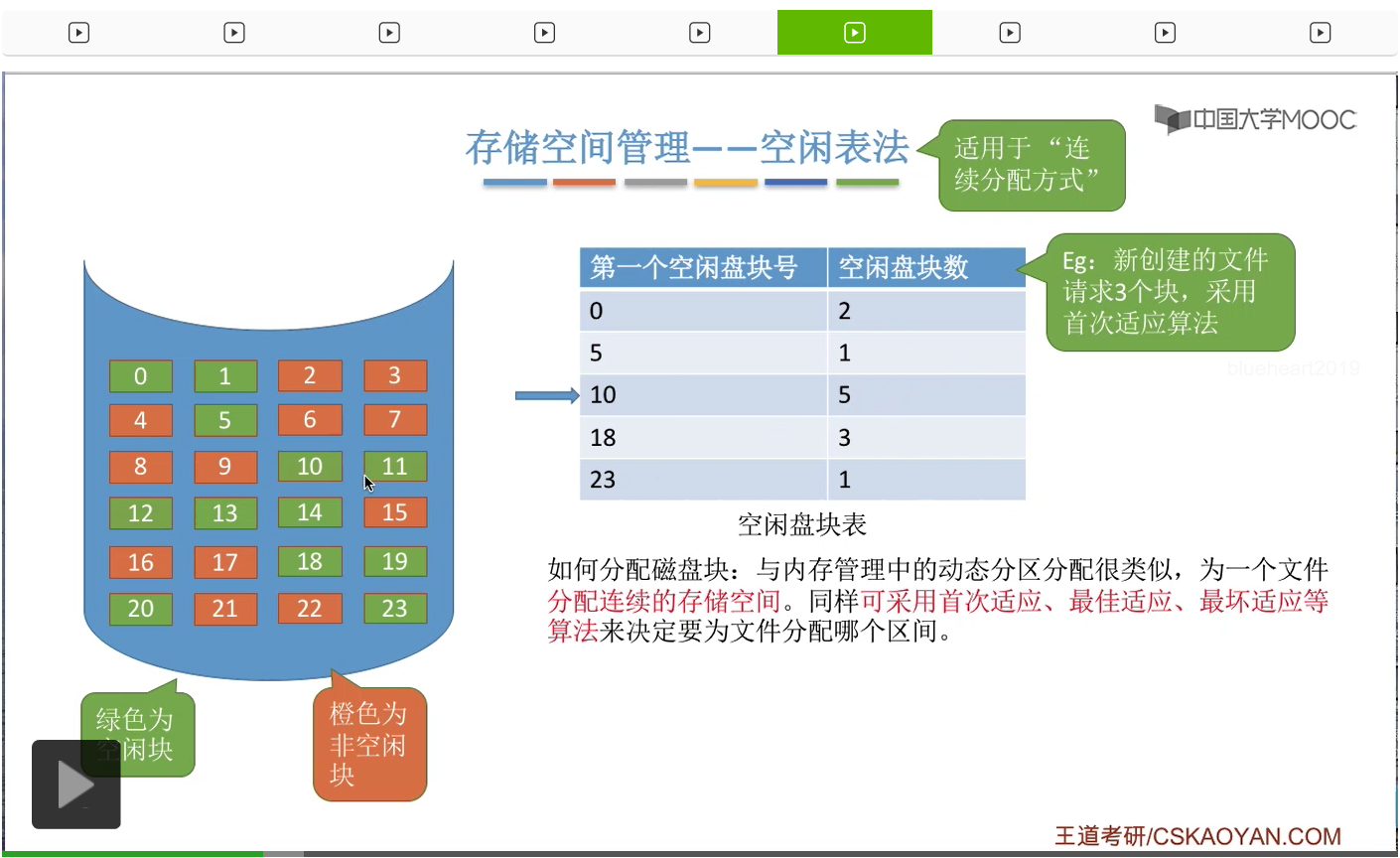
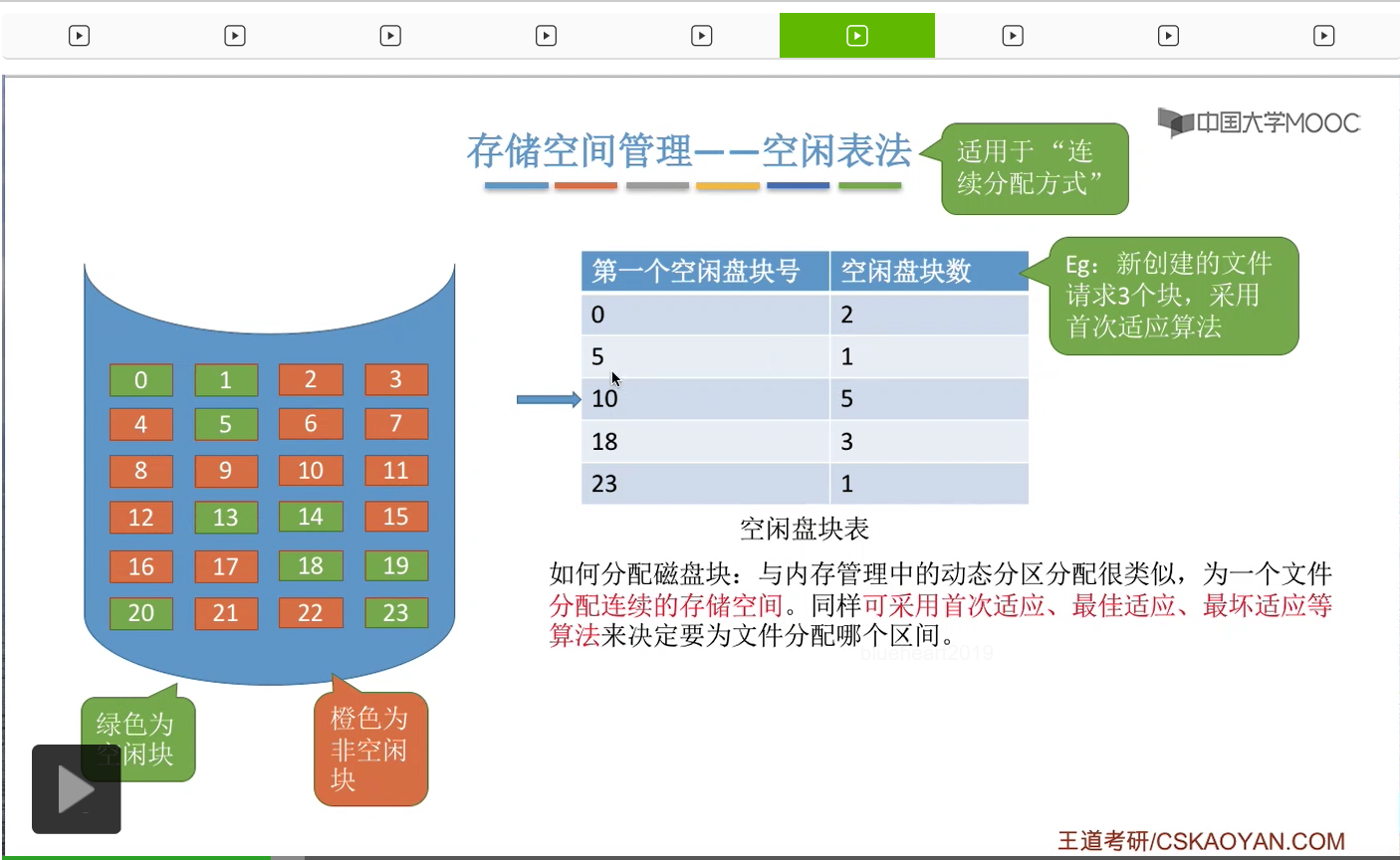
那这是首次适应算法的一个例子。那最佳适应和最坏适应其实和咱们之前在内存管理当中介绍过的思想是一样的。最佳适应就是要找到一个能够满足它的这个要求并且最小的一个空闲区间进行分配,那最坏适应的话就是找到一个能够满足它需求并且最大的一个连续的空闲区间进行分配。那因为学习过内存管理,所以这些应该都不难理解,这就不再展开。
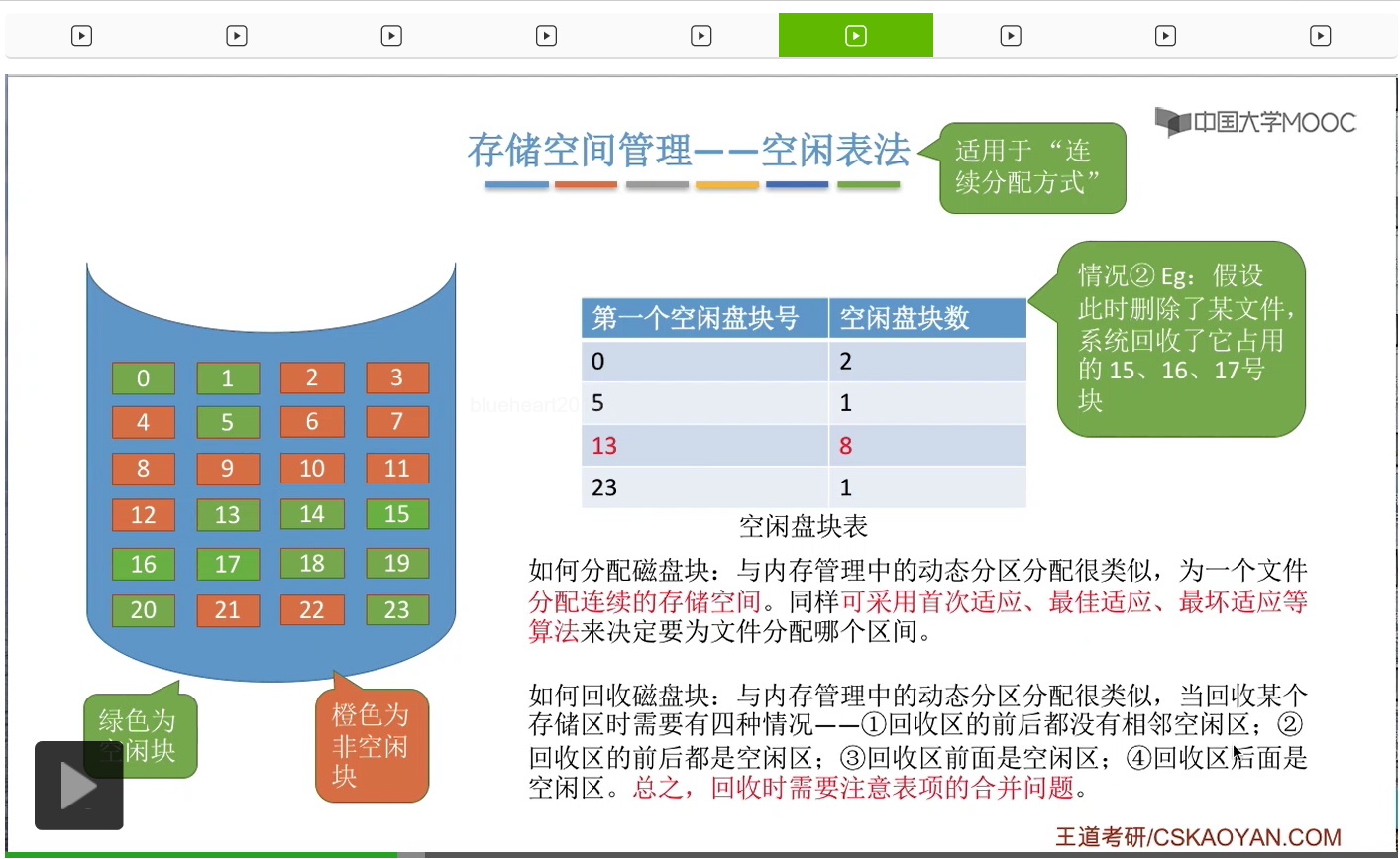
那接下来我们要探讨的问题是,我们应该如何回收磁盘块。其实和动态分区分配依然是很类似的。当我们回收某一个存储区的时候,回收某一些磁盘块的时候,我们需要注意的就是表项合并的问题。需要注意我们可能会遇到这样四种情况。一种情况是回收区的前后都没有相邻的空闲区。那这种情况下就是会在空闲表当中新增一个表项。第二种情况,回收区的前后都是空闲区。那这种情况需要把它前后的空闲区,还有这个新回收的区域,把它合并成同一个空闲区。因此,如果发生第二种情况的话,那么表项的数量是会减少一个的。那第三种情况回收区的前面是空闲区,第四种情况回收区的后面是空闲区。3、4这两种情况并不会导致空闲表的这个表项的数量有所改变。那我们直接来看第二个情况的例子,就是回收区前后都是空闲区的这种例子。
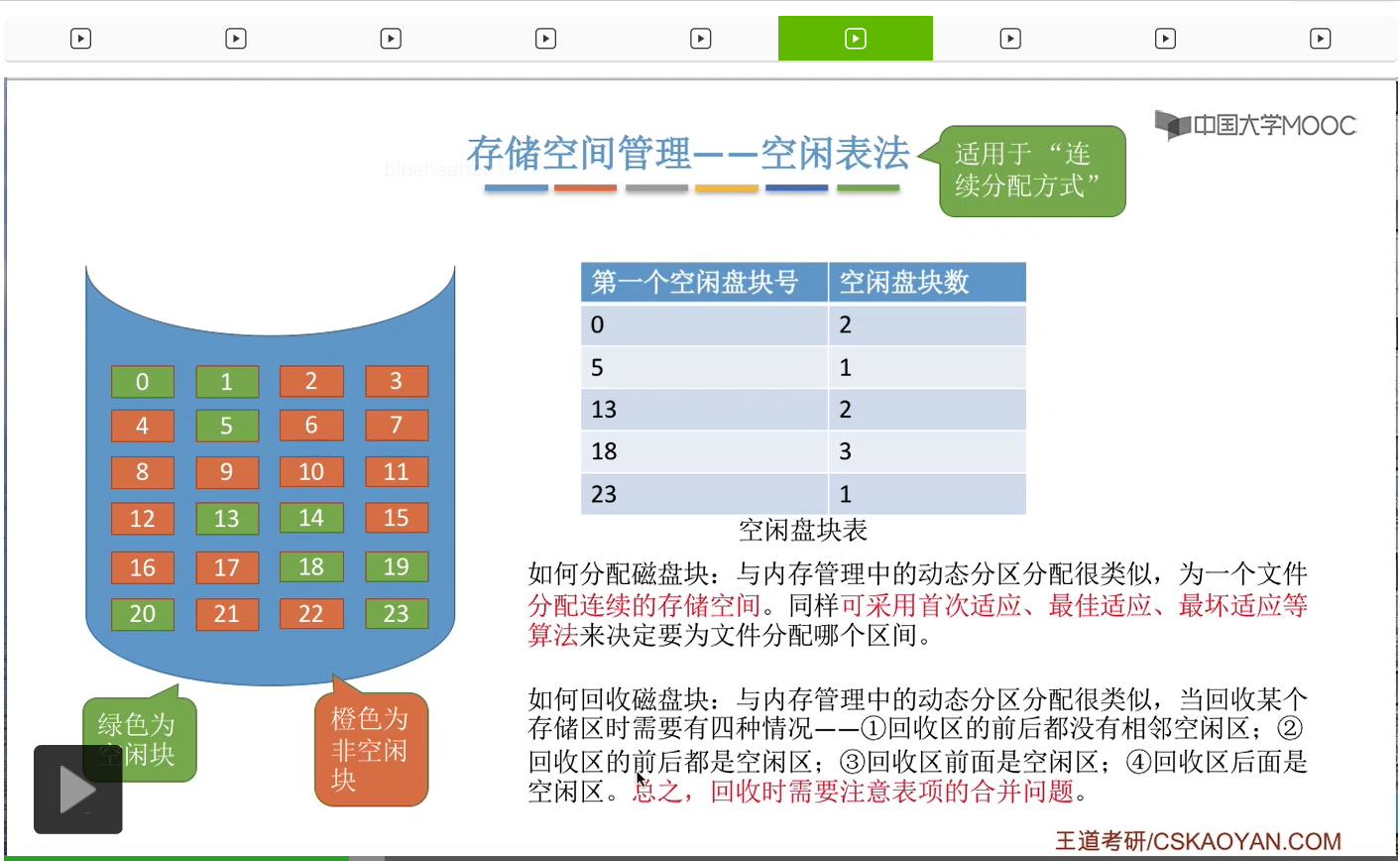


那以上就是空闲表法需要注意的一些问题。第一个需要注意的就是系统是怎么记录这些空闲区间的信息的。第二个问题我们需要注意的是应该怎么进行磁盘块的分配。第三个我们需要注意的是应该怎么回收这些磁盘块。那接下来的一些存储空间管理方法需要注意的也是这样的三个问题。
看第二种方法——空闲链表法。所谓的盘区就是一些连续的空闲盘块可以组成一个盘区。那这是空闲盘块链和空闲盘区链的一个区别。那接下来我们来看一下采用这两种方式的话,对这个磁盘块的分配与回收有什么区别。
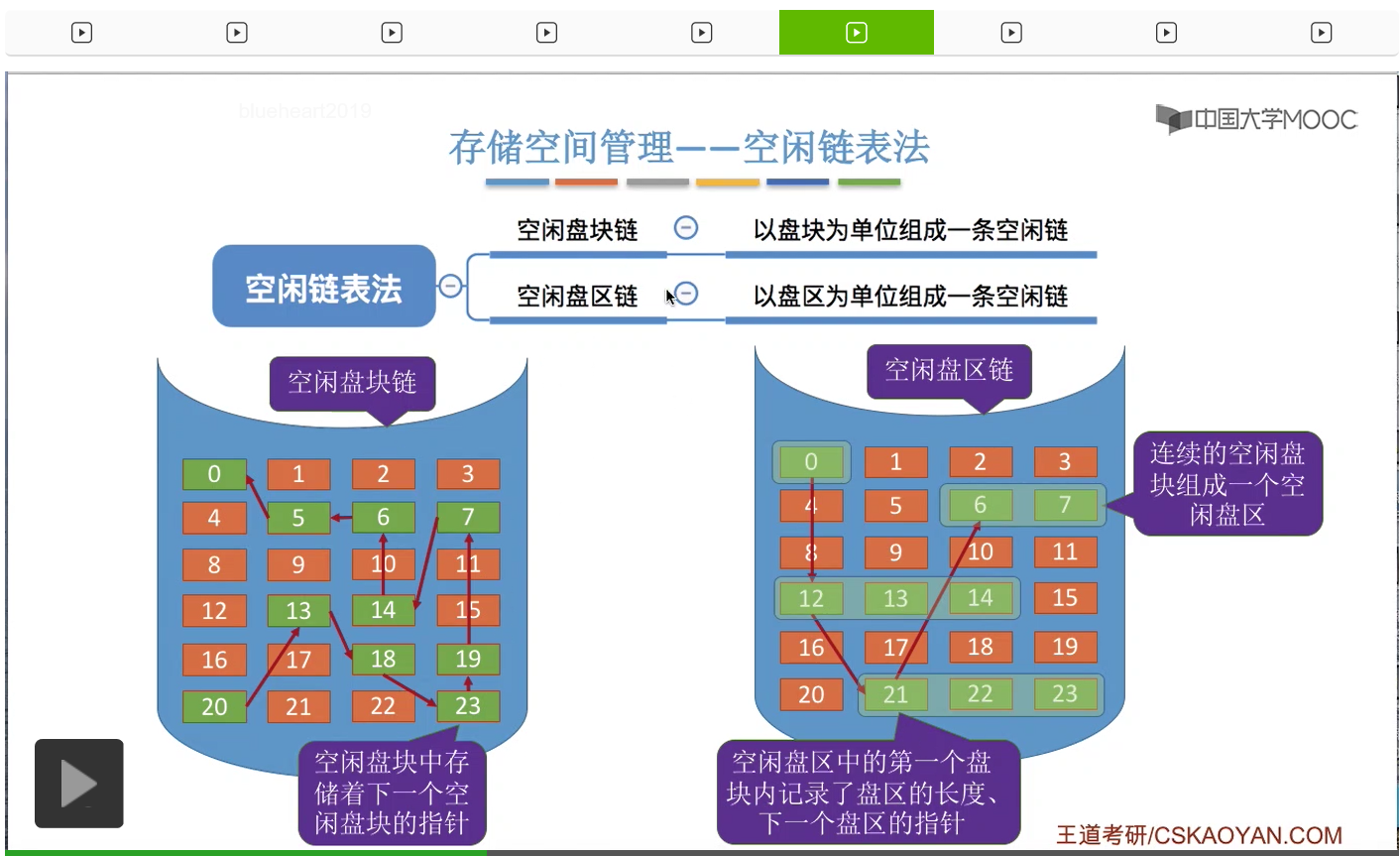
所以这就是空闲盘块链进行分配和回收的时候需要做的事情。
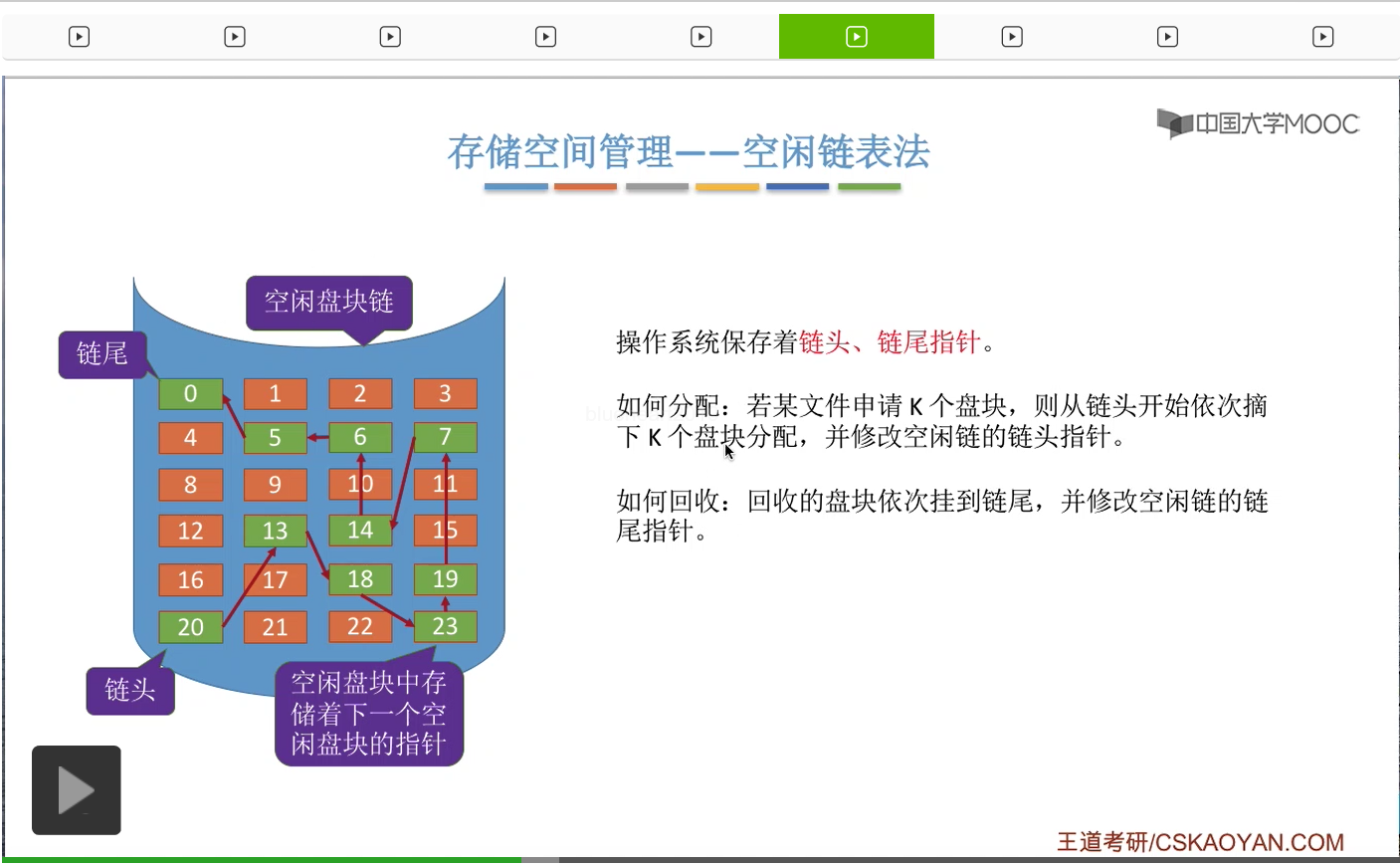
那从空闲盘块链的这个分配与回收的过程我们也可以看到,这种方式一般来说是适用于离散分配的物理结构。

那如果说要回收一些磁盘块的话,那和咱们之前介绍的空闲表法一样,我们主要需要注意的是这个回收区和空闲盘区的一个合并的问题。如果说此时回收的这几个空闲盘块,没有与它们相邻的这种空闲盘区的话,那么这个回收区就会作为一个单独的空闲盘区挂到这个链的链尾。
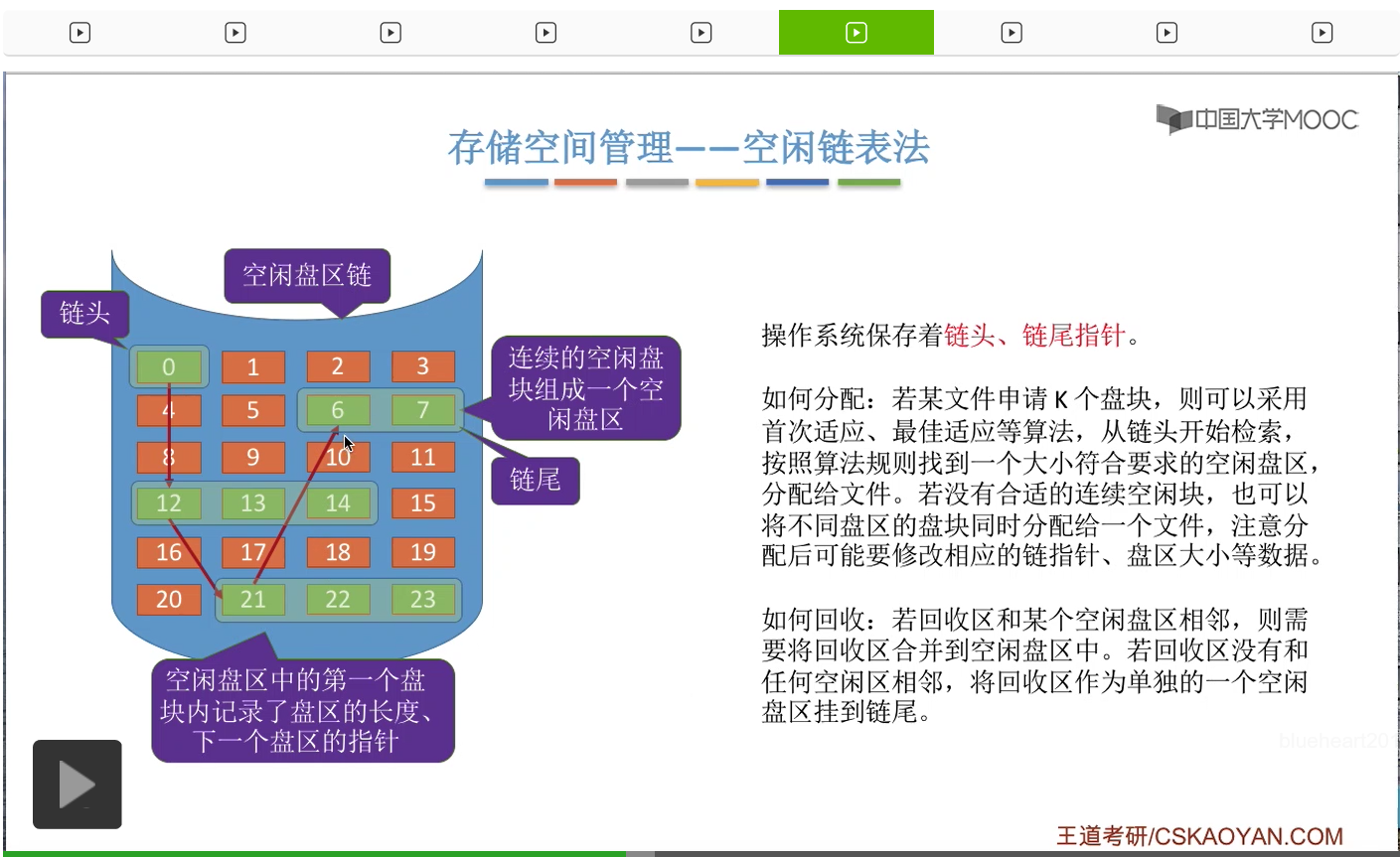
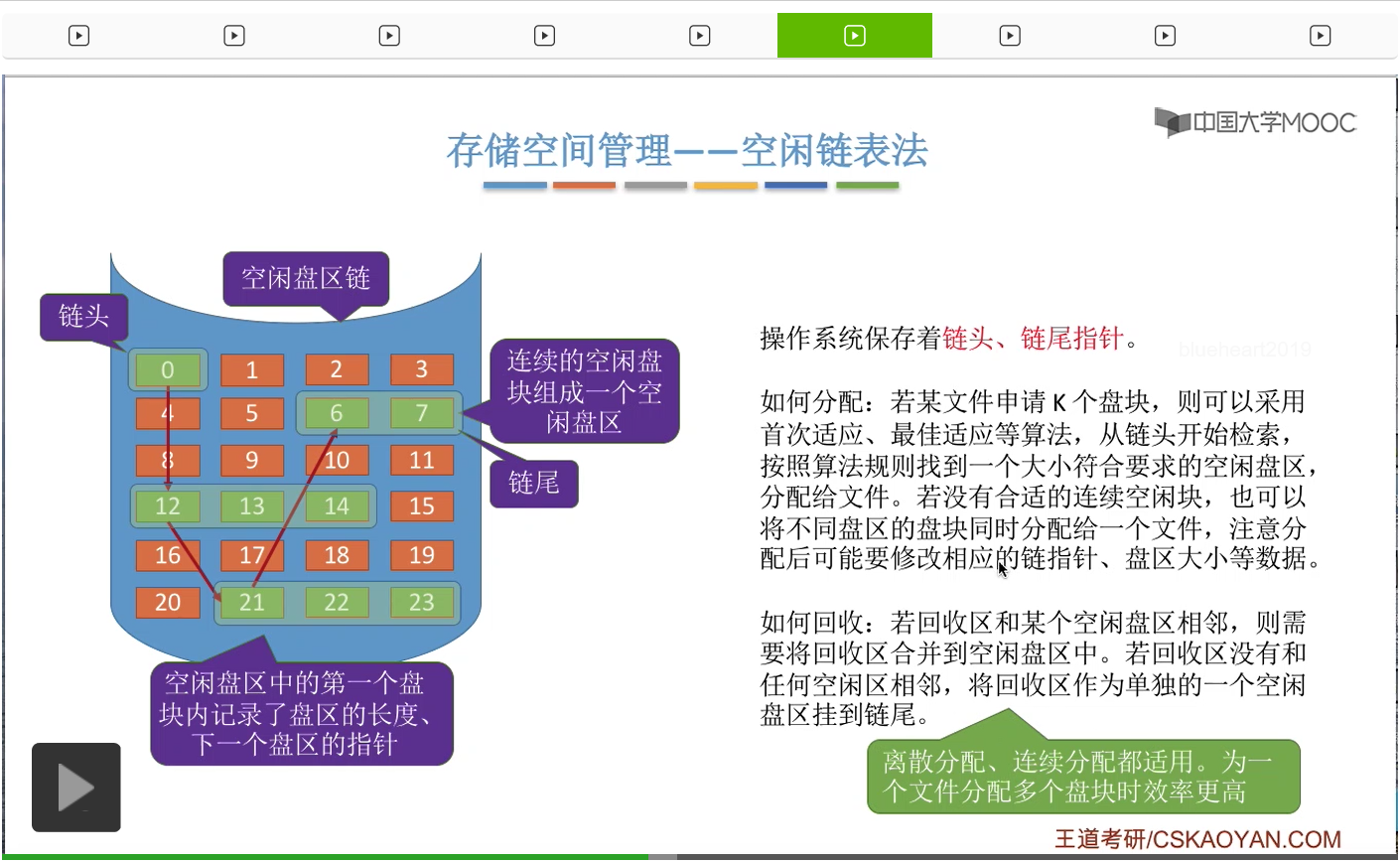
那这种空闲盘区链既适用于离散分配,也适用于连续分配。并且比起空闲盘块链来说,它给一个文件分配多个盘块的时候效率要更高。因为空闲盘块链只能从这个链当中一个一个一个一个地把这些磁盘块摘下来,而空闲盘区链可以一次摘出一大片连续的空闲区间,所以它在分配多个磁盘块的时候效率是要更高的。
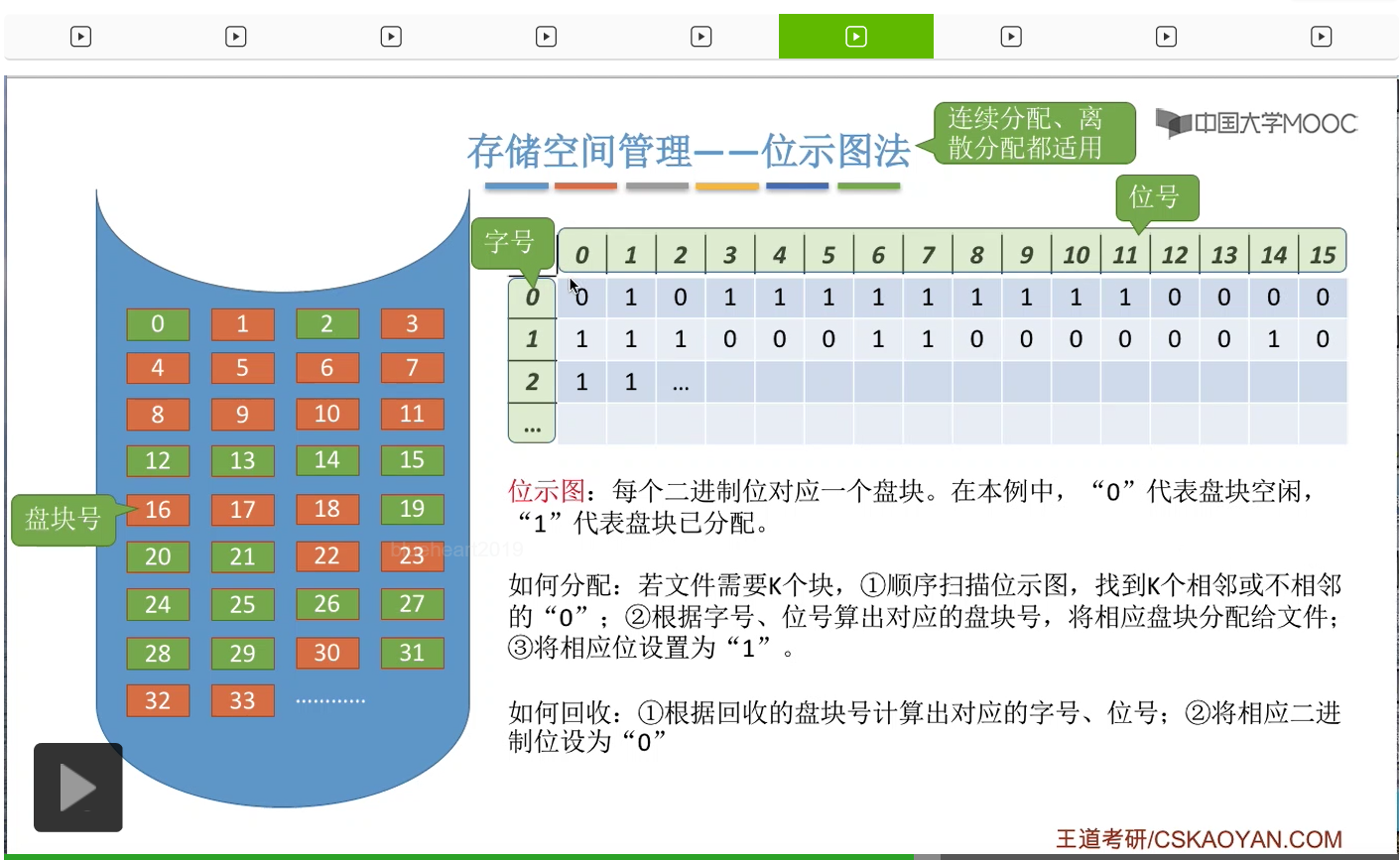
那接下来我们再来看第三种存储空间的管理方法——位示图法。这是咱们在考试当中最常考的一种方法。那这种方法的原理其实也很简单。所以位示图法的这种原理并不难理解。那一般来说这个位示图的数据在系统当中存储的时候都是会存储成一系列连续的字。

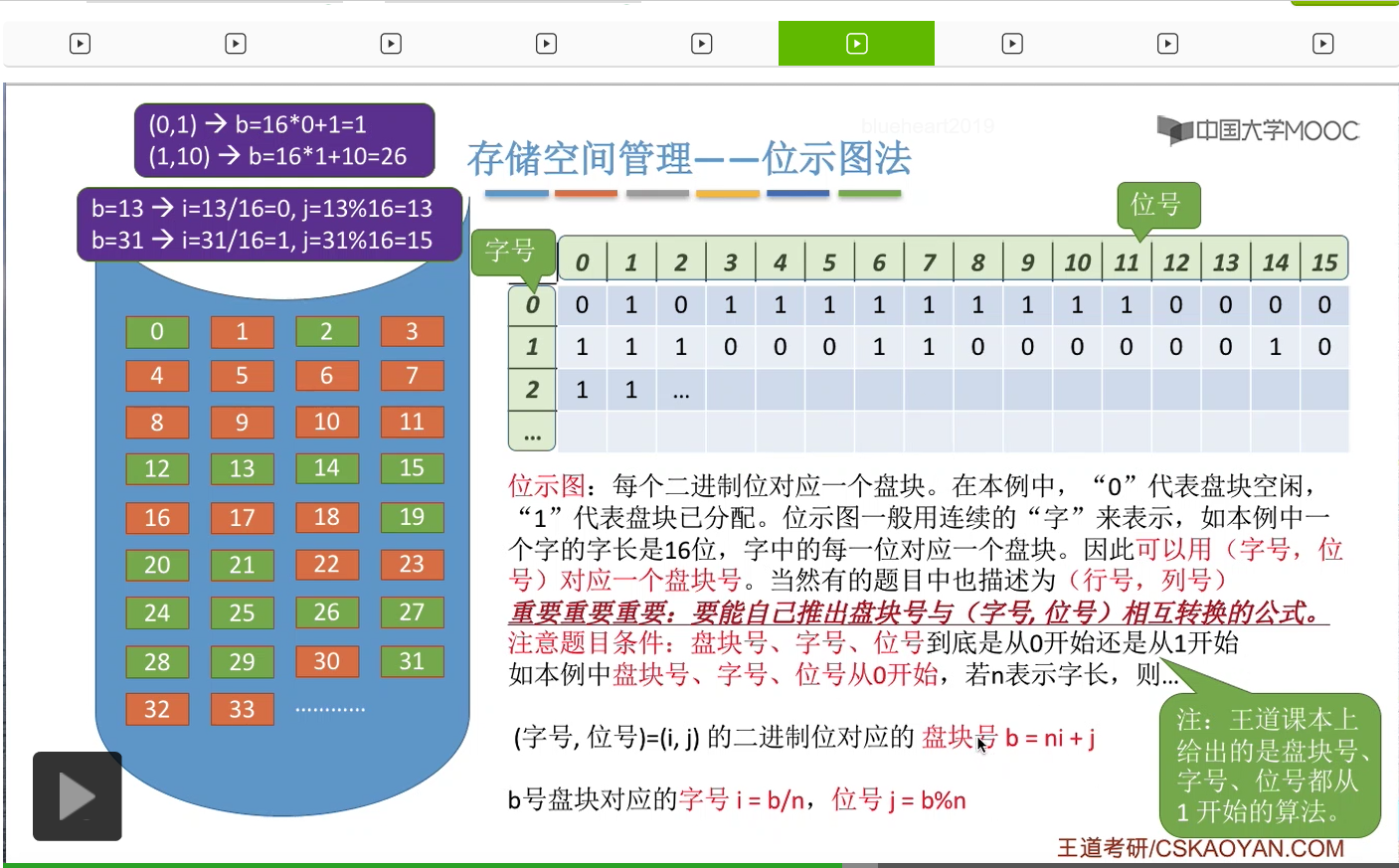
那比如说在这个例子当中一个字的字长是16位,也就这样的一行是16位。那每一个字由16个二进制位组成。

因此我们可以用字号和位号这样的二元组来定位到其中的某一个二进制位。

所以考试当中经常考查的内容就是,怎么从字号和位号推算出它所对应的盘块号。或者怎么从盘块号逆推出这个盘块号所对应的字号和位号。那这也是我们需要重点掌握的内容。

那在做这个类型的题目的时候大家一定需要注意题目的条件,盘块号、字号、位号这些到底是从0开始的,还是从1开始的。像这个例子当中,盘块号、字号、位号都是从0开始的。那如果说我们用n表示字长的话,那这个字号、位号=(i,j)转换成对应的盘块号的公式就可以写成ni+j。


字号为0,位号为1的这个二进制位,也就是这个二进制位,它所对应的盘块号是多少呢?所以这个二进制位所对应的盘块号应该是1号块。

所以字号为1,位号为10的这个二进制位对应的是26号磁盘块。那这是字号和位号转换成盘块号的一个算法。

那如果说要用盘块号推出字号和位号怎么算呢?字号i等于盘块号b除以字长n,然后取整数部分。然后位号等于盘块号对n取余,所以在这个例子当中如果说盘块号为13的话,那么它所对应的字号和位号就分别是0和13,也就是对应的是这个二进制位。
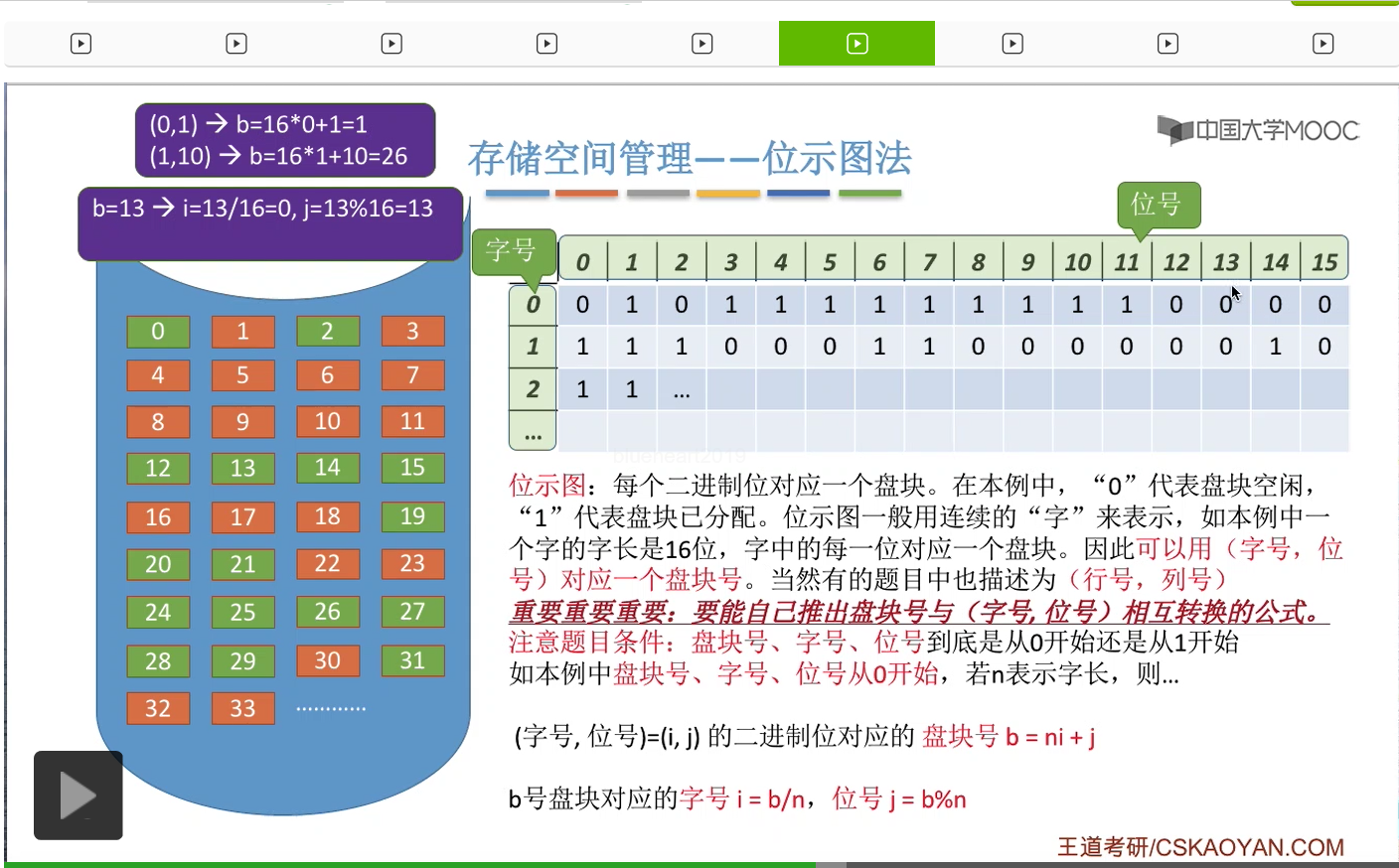
那如果说盘块号为31的话,它所对应的就应该是字号为1,位号为15也就是字号为1,位号为15,也就是这个二进制位。所以它和31号块是相对应的。这个大家也可以自己数一下。
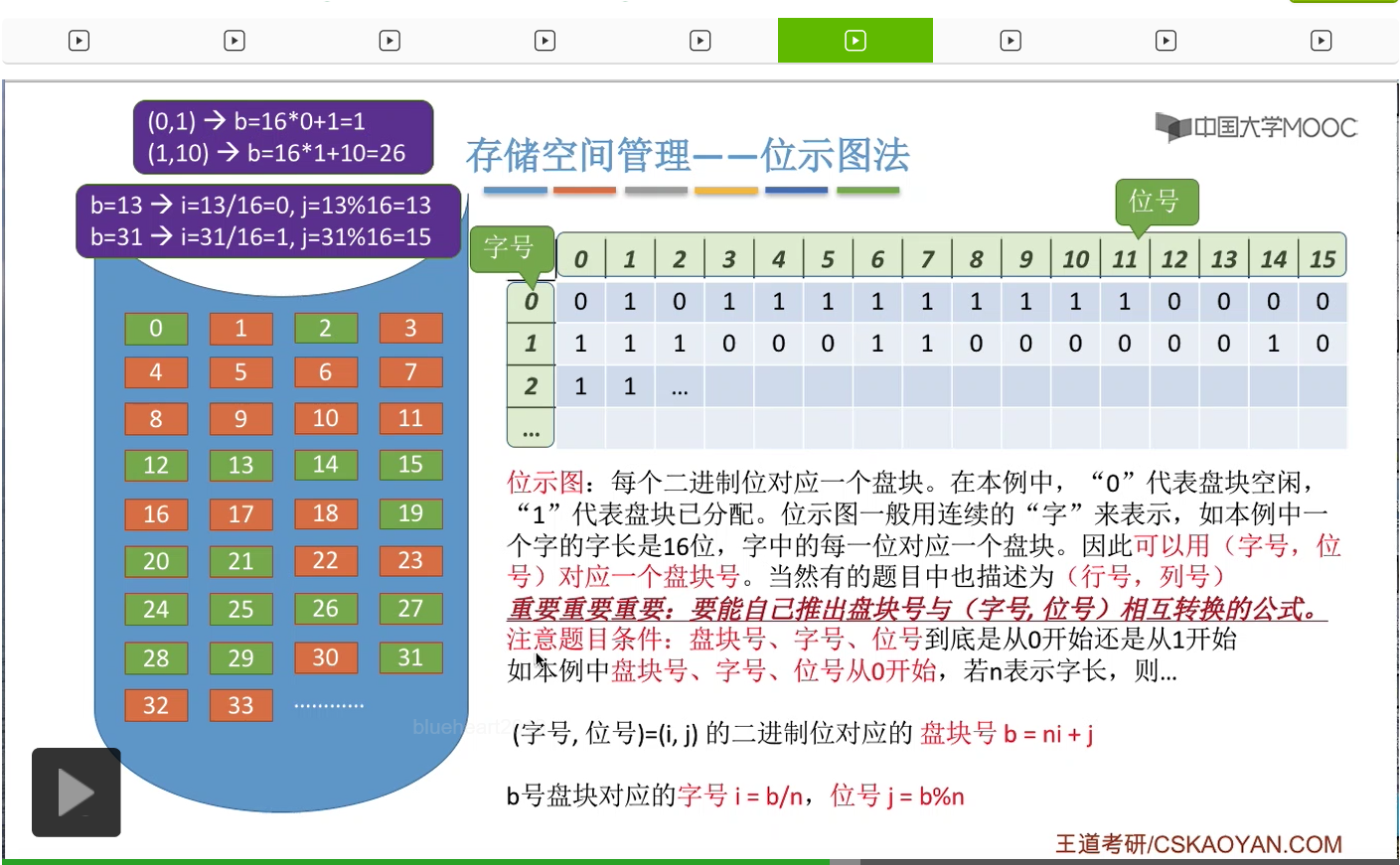
那这个例子当中我们给出的是盘块号、字号、位号都是从0开始的情况。在咱们王道书上给出的是这几个数据都是从1开始的一个算法。但是不管是从0开始还是从1开始,大家都需要能够自己推出来,这个并不需要死记硬背。
那接下来我们要考虑的问题是,采用位示图法的话怎么进行磁盘块的分配和回收。

因为“0”代表的是空闲块嘛,另外呢需要用这些“0”对应的字号和位号计算出它们所对应的盘块号到底是多少,然后把这个盘块分配给文件,并且要把相应的位设置为“1”也就是设置为已分配的状态。
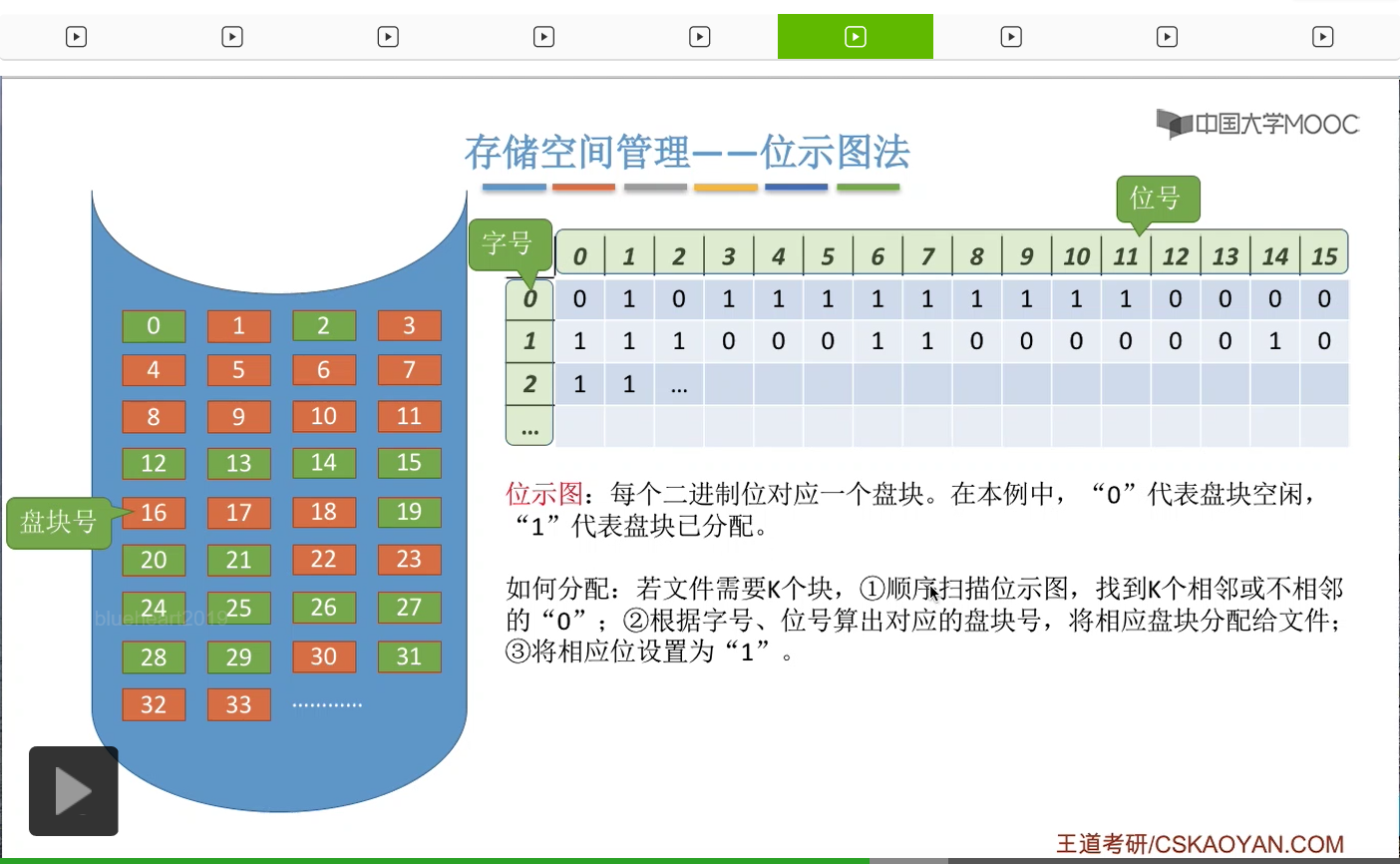
然后再用字号和位号找到相应的二进制位,把那个二进制位设置为“0”。因此,从这个分配和回收的过程也可以看到,用字号和位号转换成盘块号还有用盘块号转换成它所对应的字号和位号,这个是十分重要的。
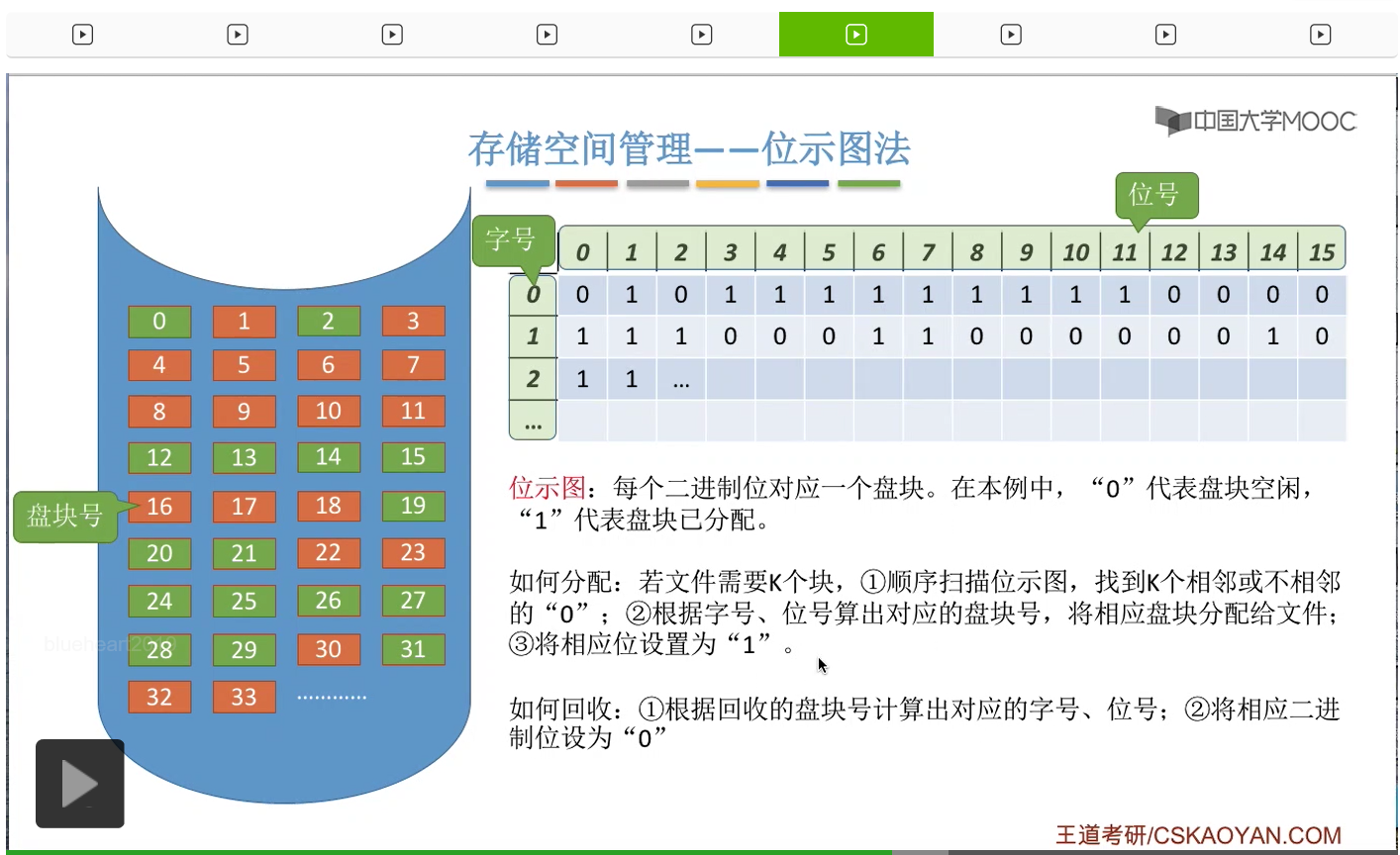
那如果说采用的是位示图法的话,在连续分配和离散分配的这种场景下都适用。假如说是要求离散分配的话,那么我们在扫描这个位示图的时候就可以尝试找到连续的K个块,而如果说采用的是离散分配的方式的话,那么在找这K个块的时候就不需要一定要找到连续的K个“0”。那这是位示图法需要注意的一系列事情。
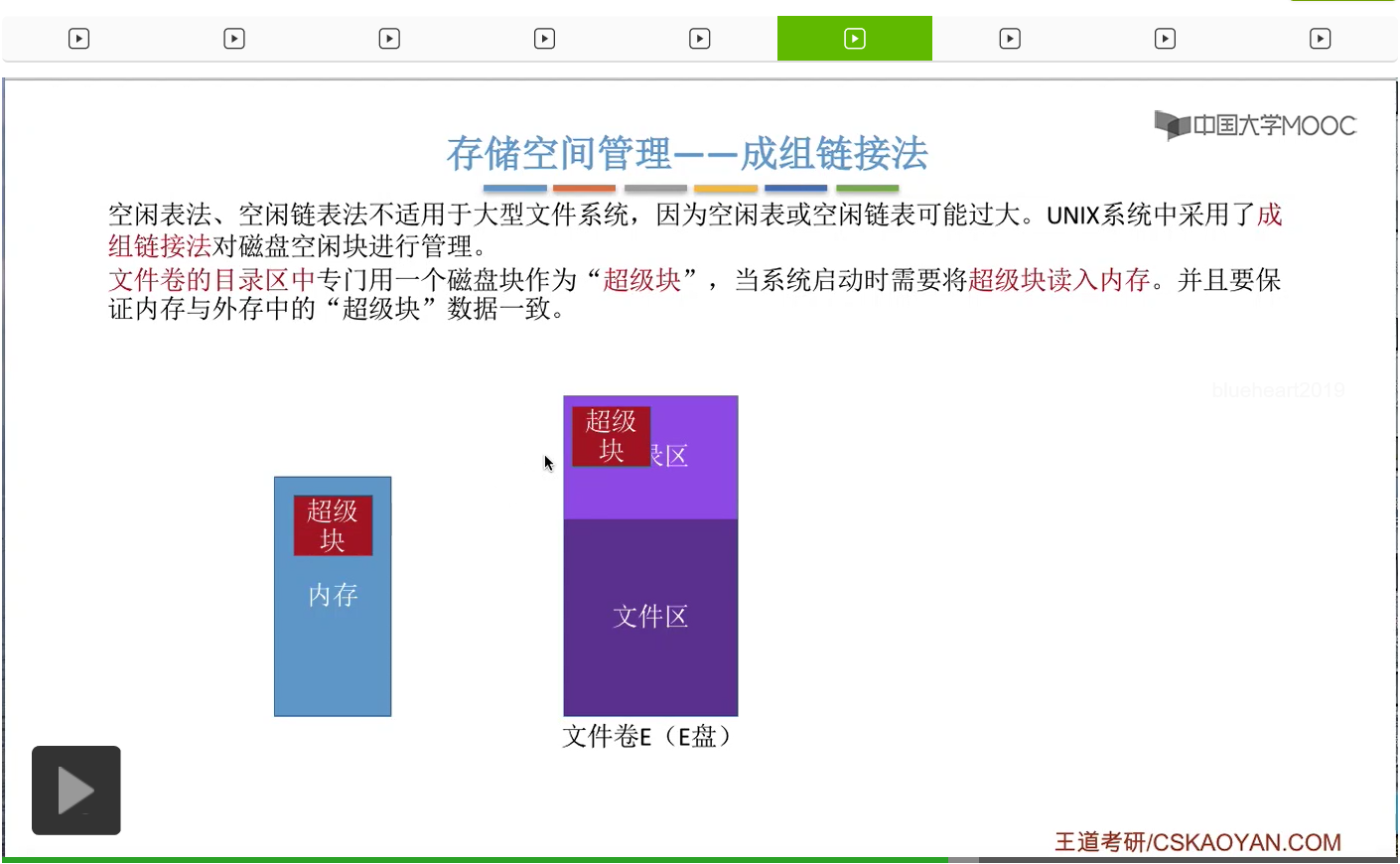
那接下来我们来看最后一种存储空间的管理方法——成组链接法。咱们之前介绍的空闲表法还有空闲链表法是不太适合于大型的文件系统的。因为在大型文件系统中空闲表和空闲链表有可能会很长很大。那在UNIX系统中,采用的是成组链接法对这个磁盘的空闲块进行分组的管理。
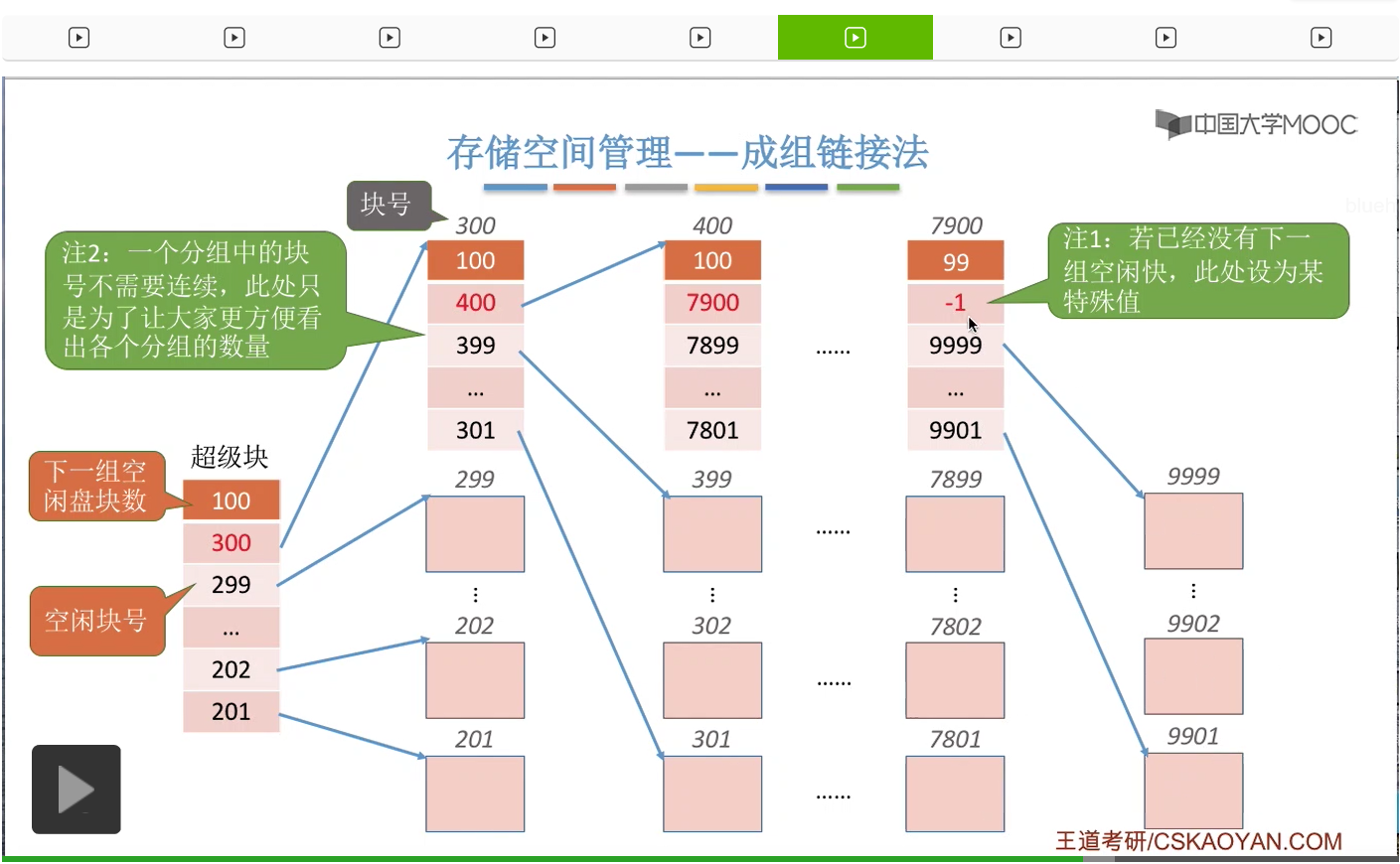
那这个“超级块”的作用咱们一会再解释。

当系统启动的时候需要把这个“超级块”读入内存。
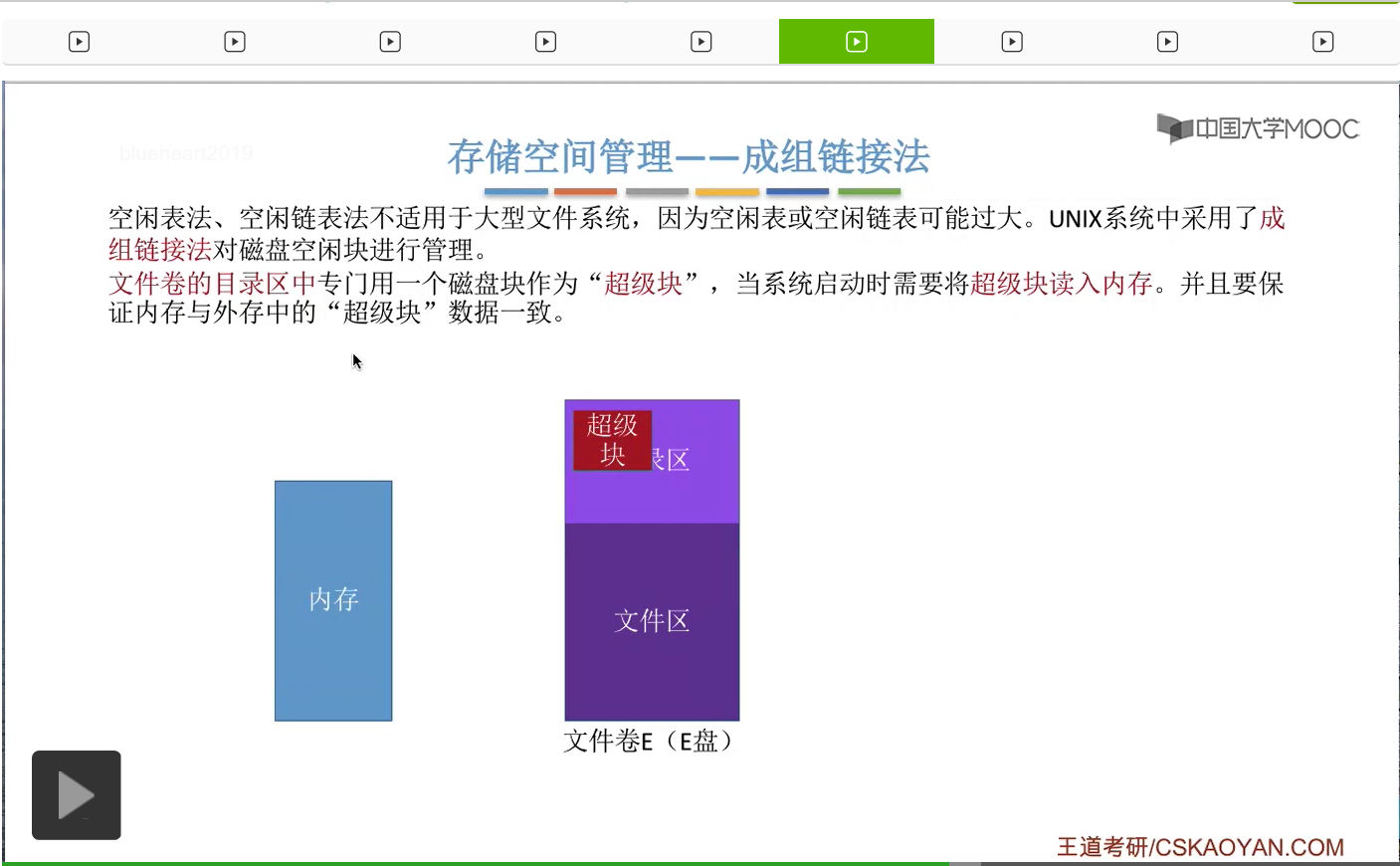
并且在整个过程当中需要保持内存和外存当中“超级块”的数据一致。
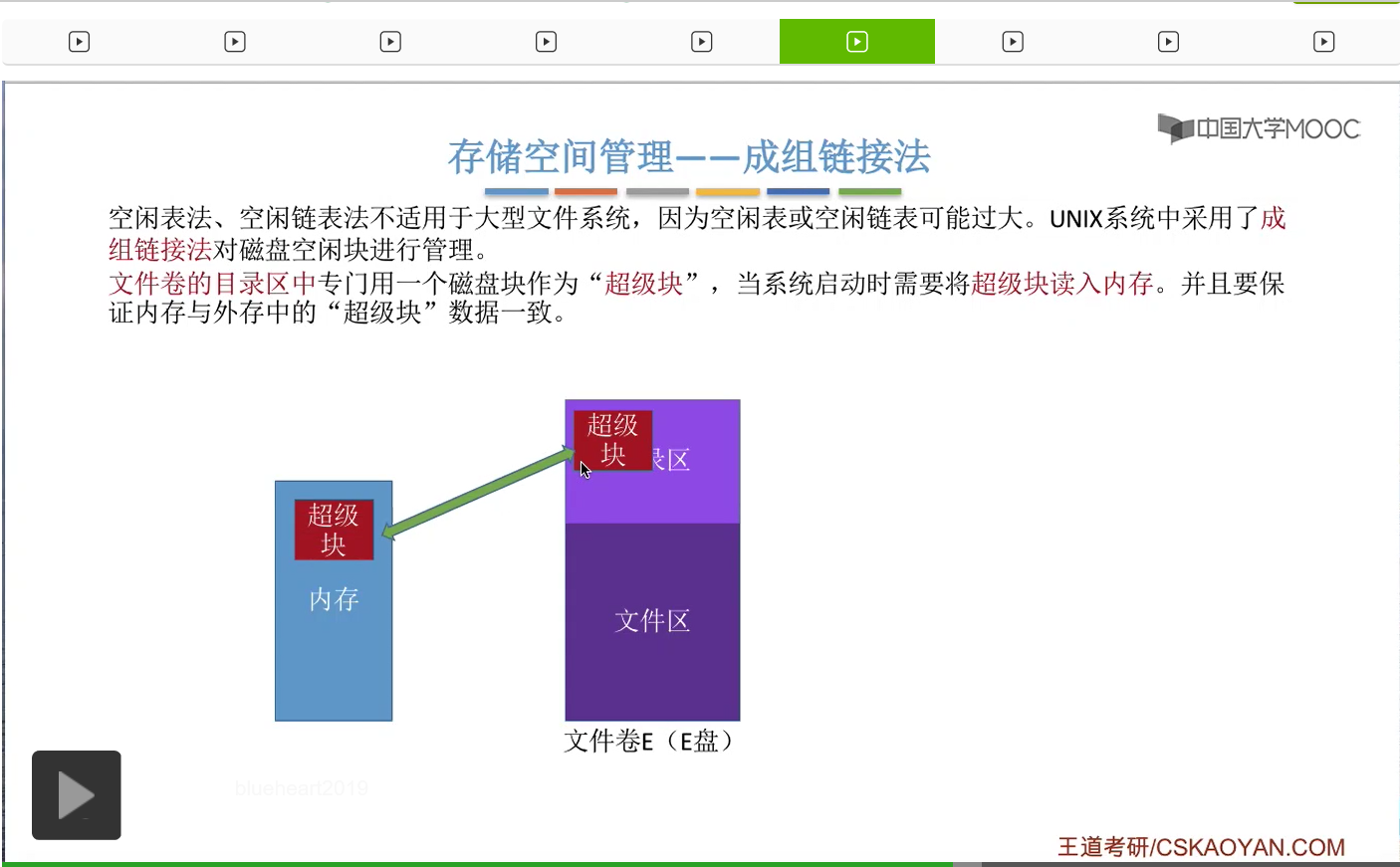
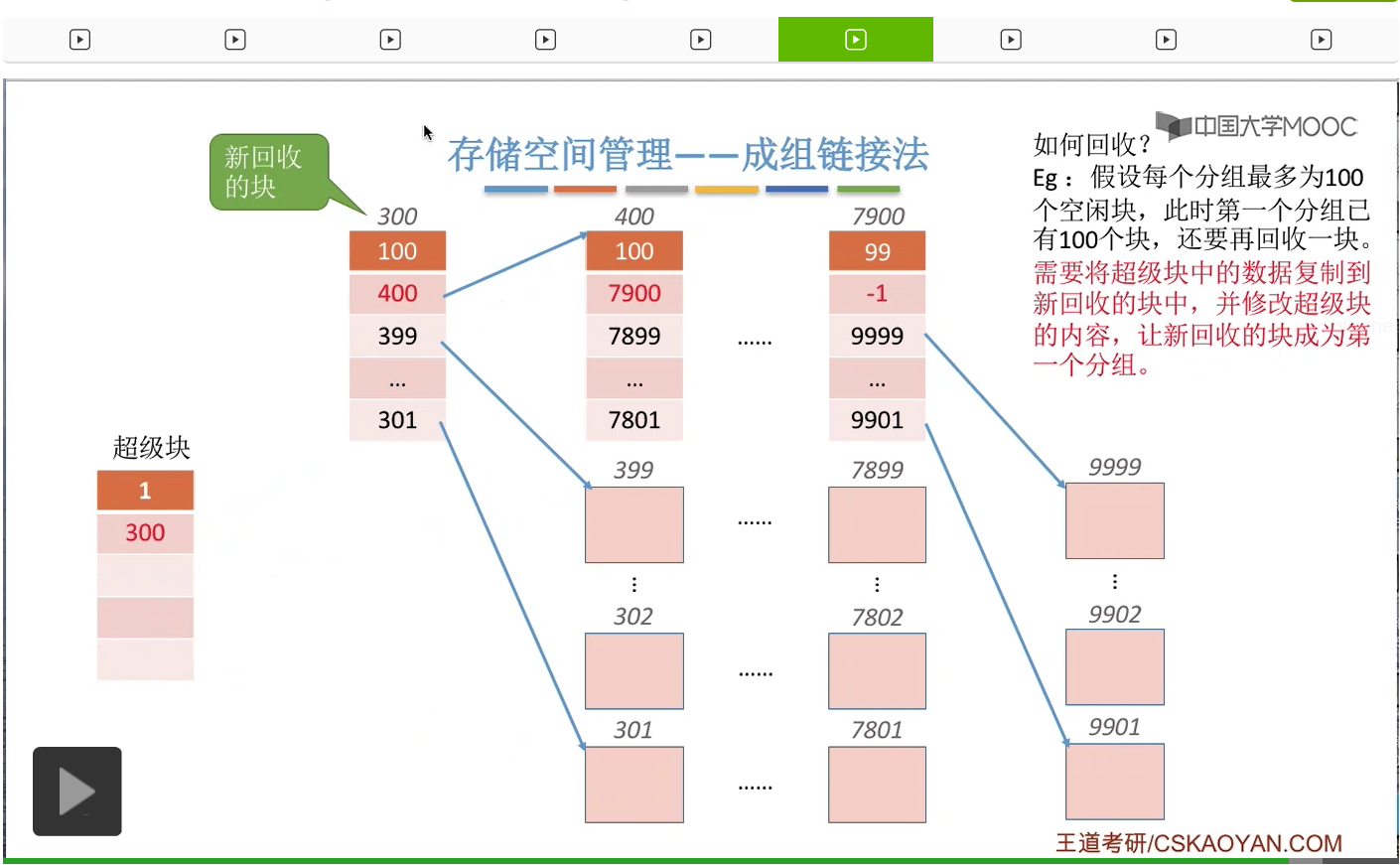
那接下来我们来看一下这个“超级块”到底有什么作用。在“超级块”当中记录了下一组空闲盘块的数量,比如说下一组总共有100个空闲盘块。另外,它还需要记录这个100个空闲盘块的盘块号分别是多少。

那通过这些盘块号我们就可以依次找到下一个分组的各个盘块了。所以这是第一个空闲盘块的分组,总共有100个,它们分别是201号磁盘块一直到300号磁盘块。那这个地方需要注意的一点是,300号磁盘块它作为这个分组的第一个磁盘块,也就是这个位置对应的磁盘块,在这个块当中还需要记录下一组空闲盘块的一些信息。同样的,这个地方100表示的是下一个空闲盘块的分组总共有100个空闲盘块。那这些数字就是代表了下一个分组当中各个盘块的盘块号。
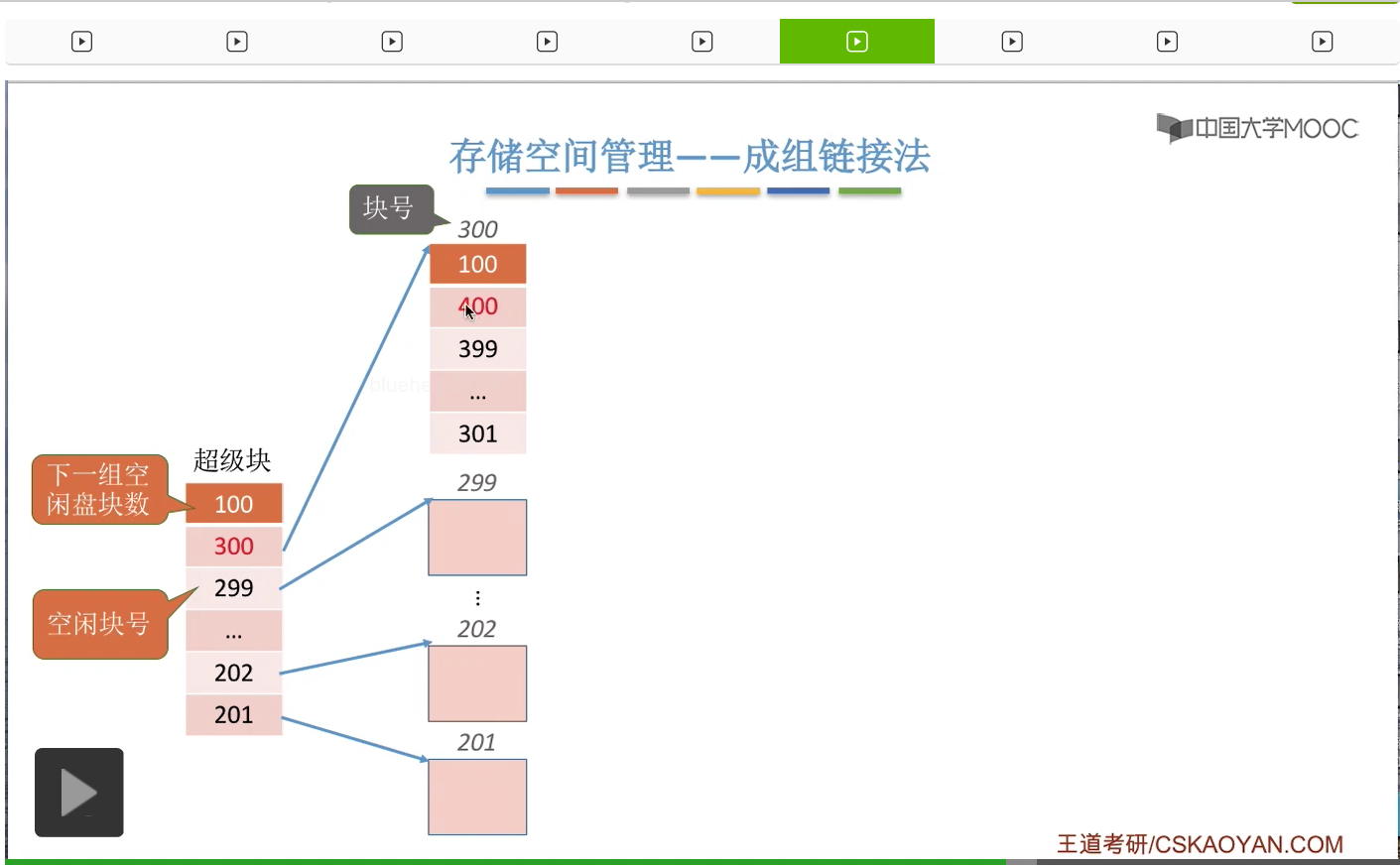
所以通过这些盘块号我们又可以找到再下一个分组的盘块分别是哪些。那同样与之前类似,在这一个分组当中,400号盘块它是这个分组当中的第一个盘块,所以400号盘块也会再记录再下一个分组的盘块数量还有这个各个盘块的这个盘块号。那用这种方式我们就可以把整个系统当中所有的空闲盘块给一一链起来了。
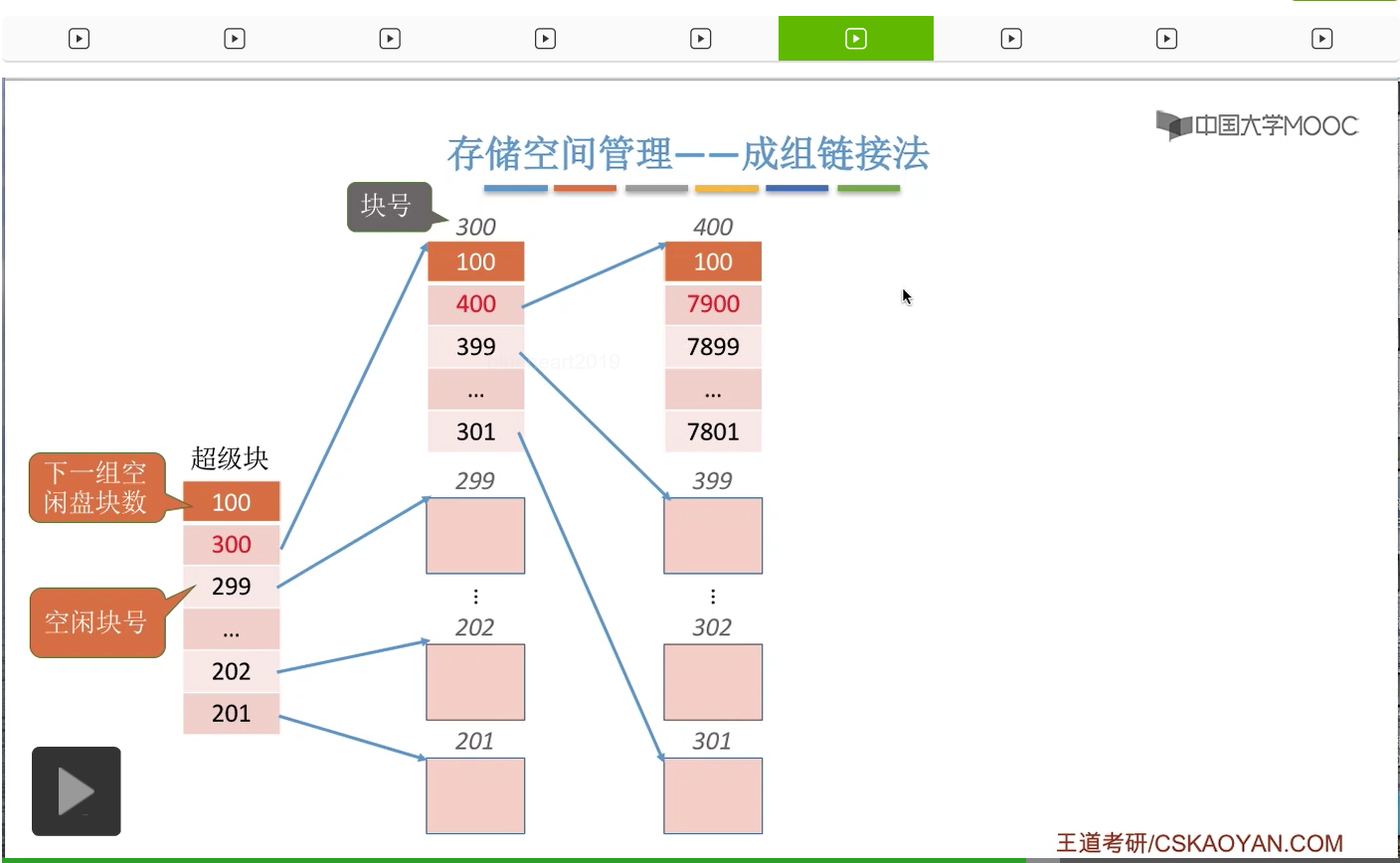
那在倒数第二个分组的第一个盘块这儿,我们可以把这个数字设置成一个特殊的值,-1,就代表再下一个分组已经是最后一个分组了。
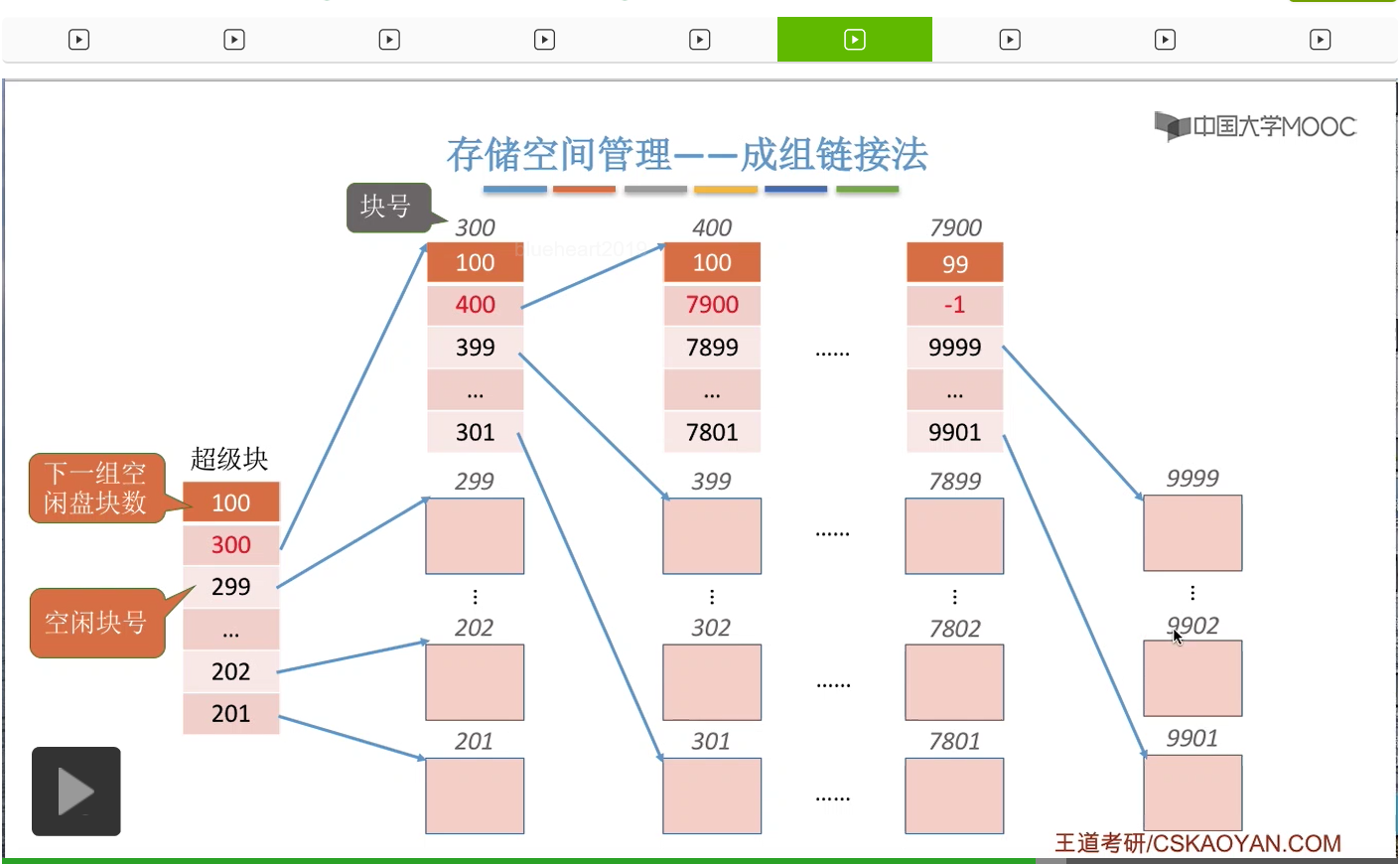
所以如果找到这个值为-1的这个结点的话,那么就证明在之后已经没有更多的分组了。

另外,大家需要注意的是,其实每一个分组的这些盘块号并不要求连续,这个地方我把这些数字设置成连续的原因是为了让大家更方便地看出每一个分组到底有多少个盘块。那像这个分组201-300总共100个数也就对应100个盘块。那这和这个地方记录的这一组的盘块数量刚好是对应的,只是为了让大家方便看出这件事情。另外呢大家需要注意的是,在成组链接法当中,每一个分组的盘块数量有一个上限,像这个例子当中,每个分组最多只有100个盘块。另外一个大家需要注意的是,最后一个分组的盘块数是要比其他的这些分组更少的,更少一块,那原因是出在这个地方。
那接下来我们要探讨的是怎么进行磁盘块的分配。假设此时某一个文件需要分配一个空闲块,
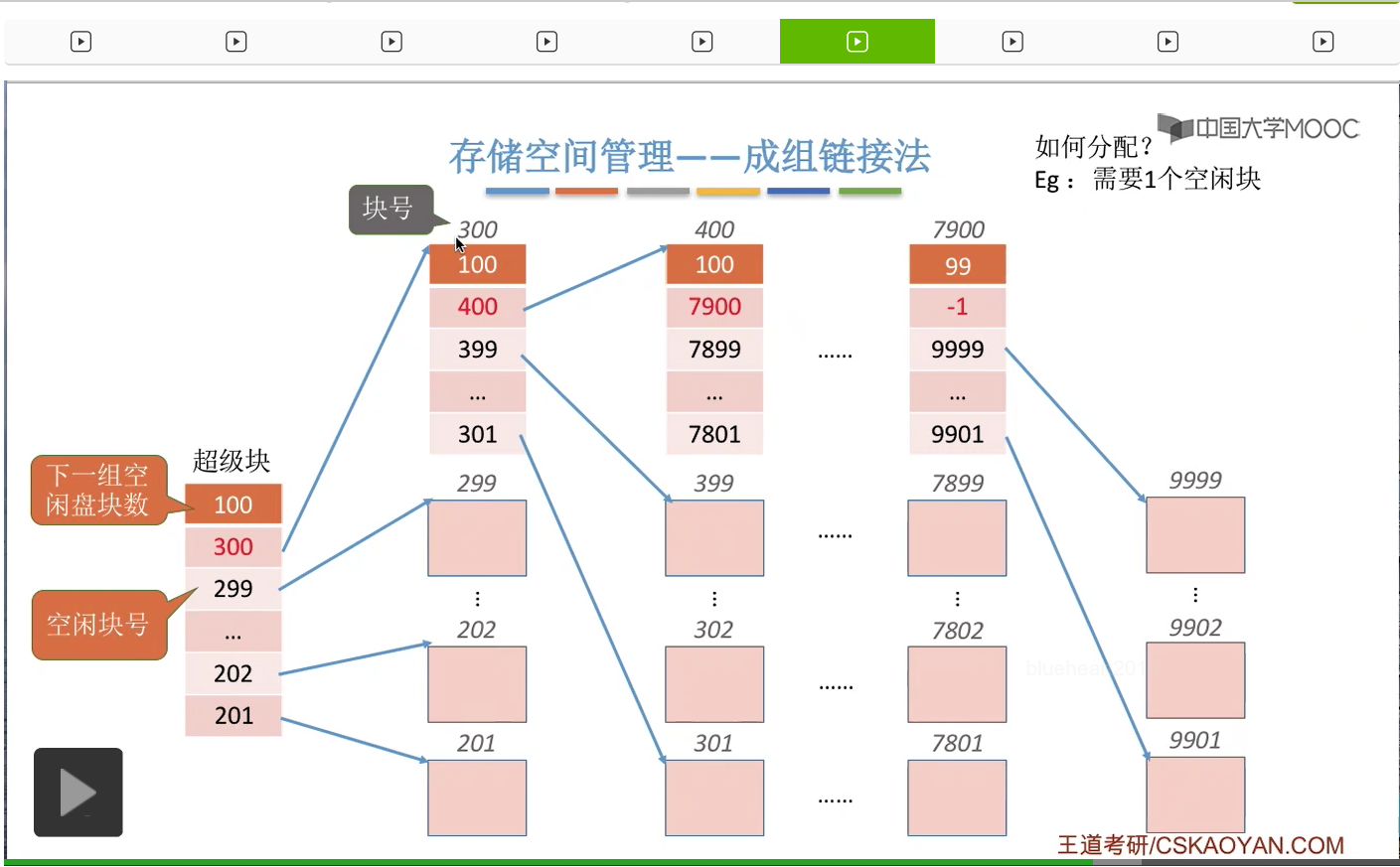
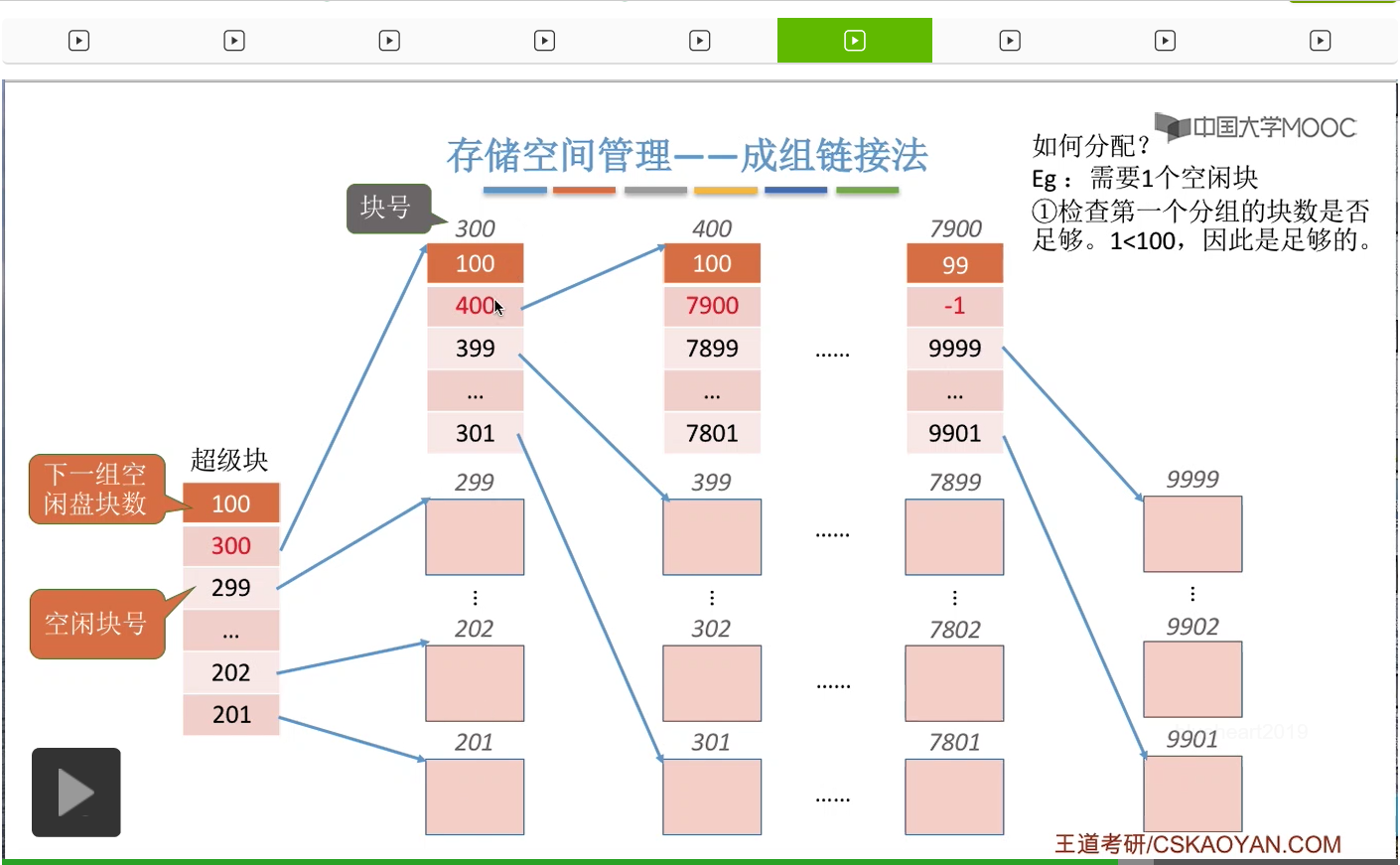
那首先是需要检查第一个分组当中的盘块到底够不够这个文件的需求。那由于此时“超级块”已经是读入内存的了,所以我们在进行这个检查的时候并不需要读磁盘操作,我们只需要找到内存当中“超级块”的这些数据并且检查一下下一组的这个空闲盘块数是否大于此时要求得到的这个空闲盘块数。那由于1是小于100的,所以说明这个第一个分组当中的这些空闲盘块是足够分配的。
那接下来就会把这个分组当中的最后的这个盘块分配给这个文件,也就是201号盘块。
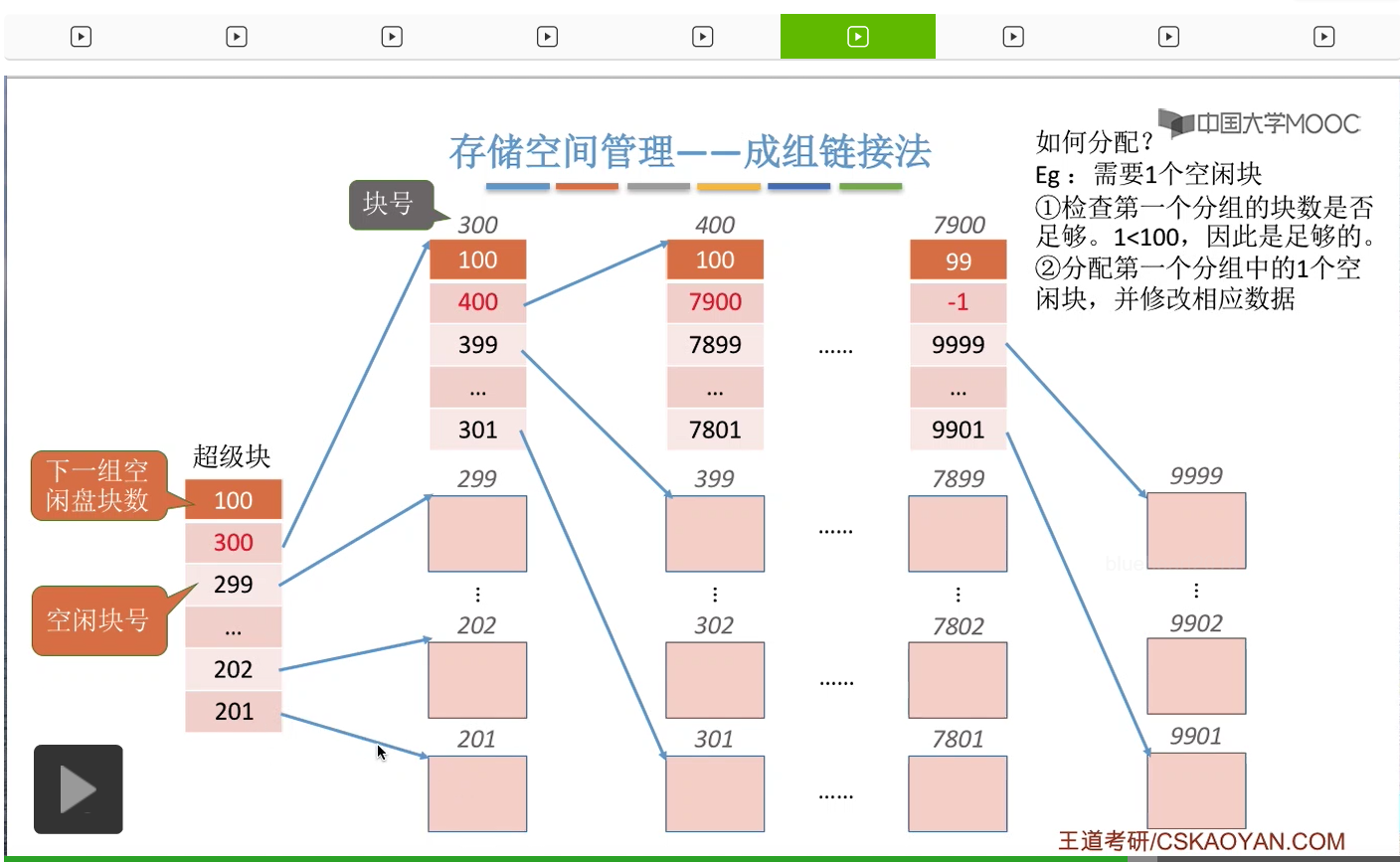
那这个盘块分配出去之后就需要把这个地方的数据删除,
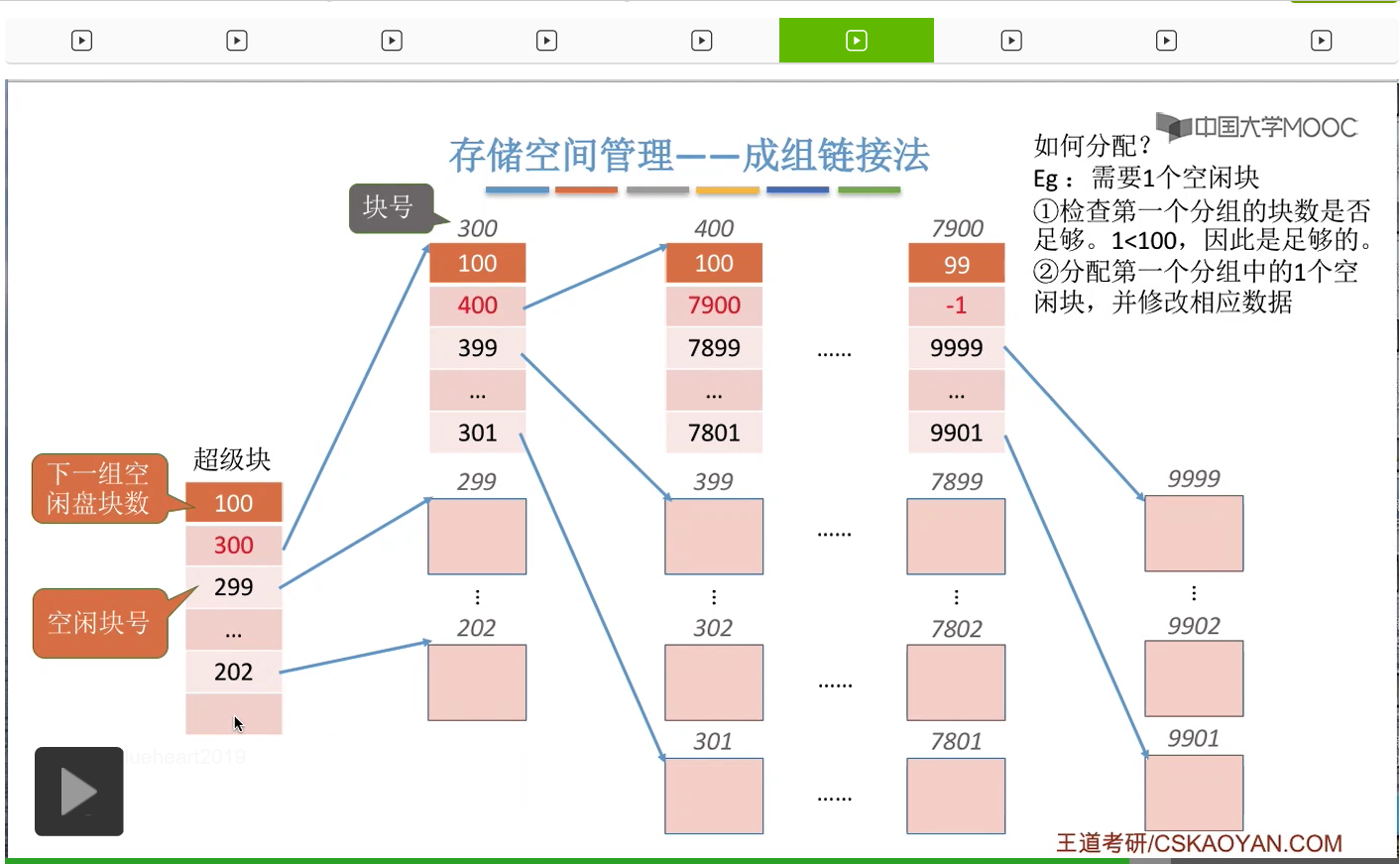
并且要把下一个分组的空闲盘块数把它减1,也就是从100变成99。那这样的话就完成了分配一个空闲块这件事情。
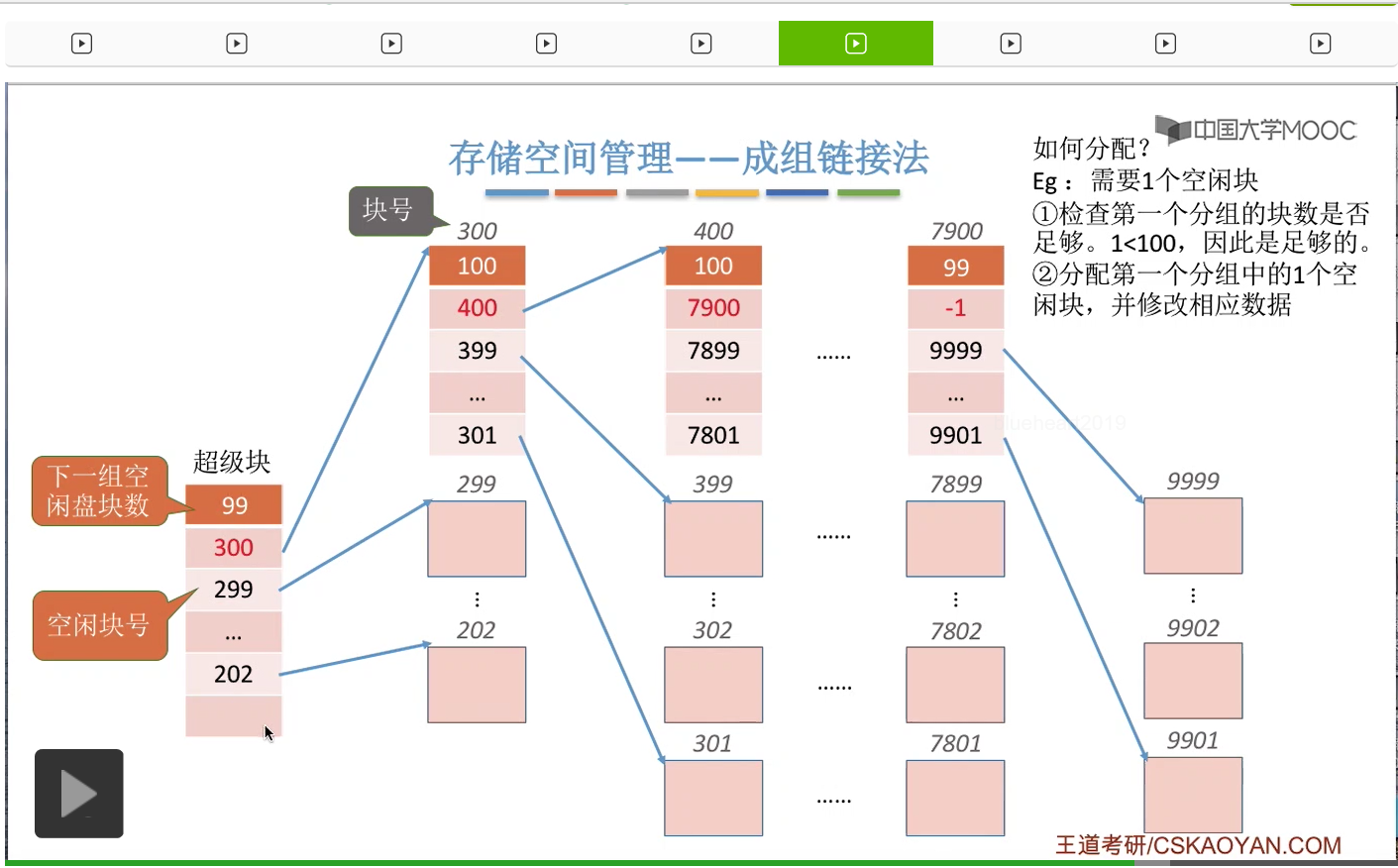
那接下来我们再来看如果说此时是需要分配100个空闲块的话,怎么办呢?

首先第一件事也是检查第一个分组到底够不够分配。那由于此时第一个分组的数量总共有100个空闲盘块,因此第一个分组是足够的。因此接下来我们会把第一个分组的这100个磁盘块全部分配出去,不过这个地方需要注意的是,300号磁盘块存储了再下一个分组的这些磁盘块的信息,因此如果我们把300号磁盘块直接分配给那个文件不做任何处理的话,那和下一组的这些链接的信息就断掉了。

因此,在我们把300号磁盘块正式分配给文件之前,我们需要把300号磁盘块当中的这些数据把它复制到这个超级块当中。
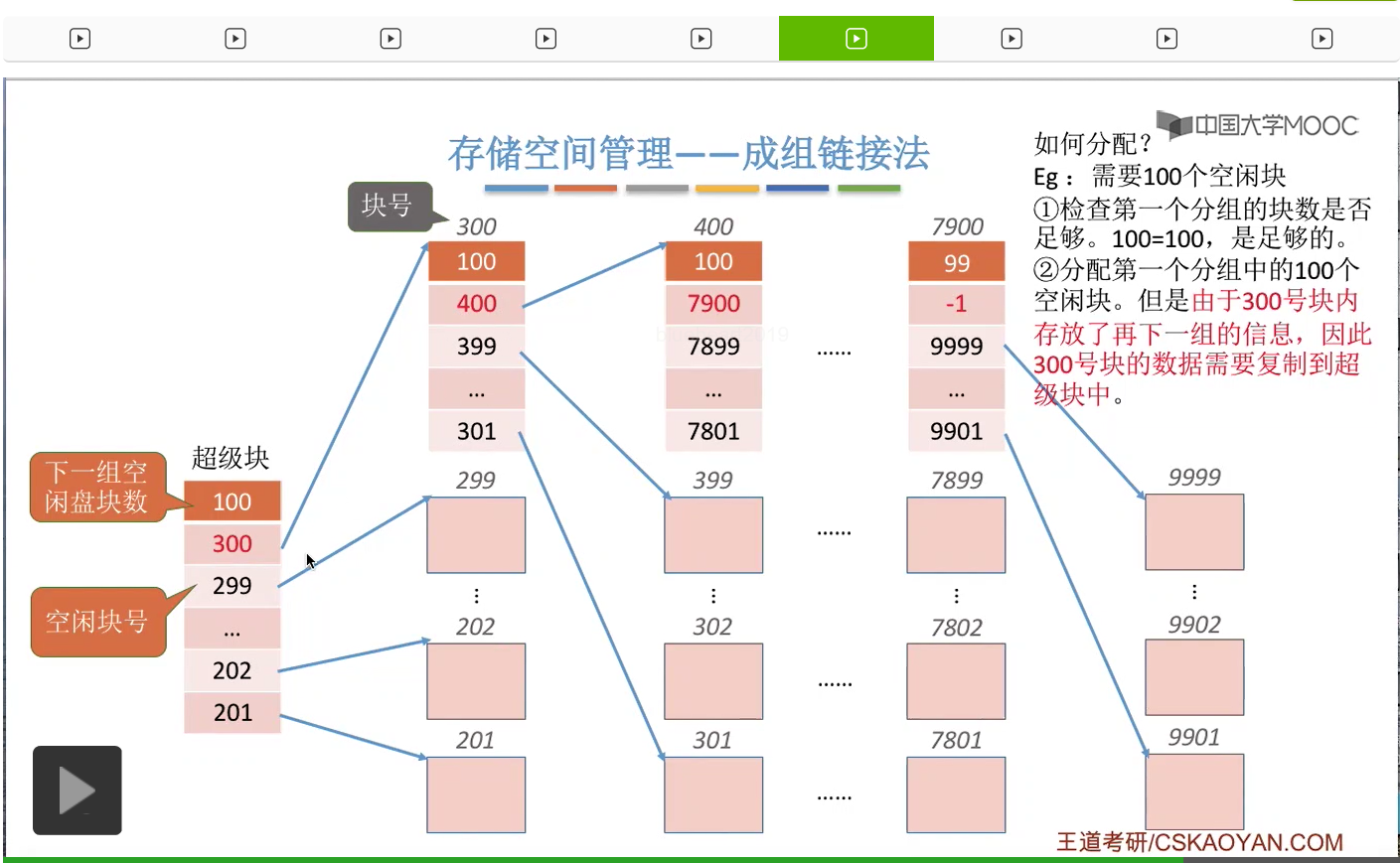
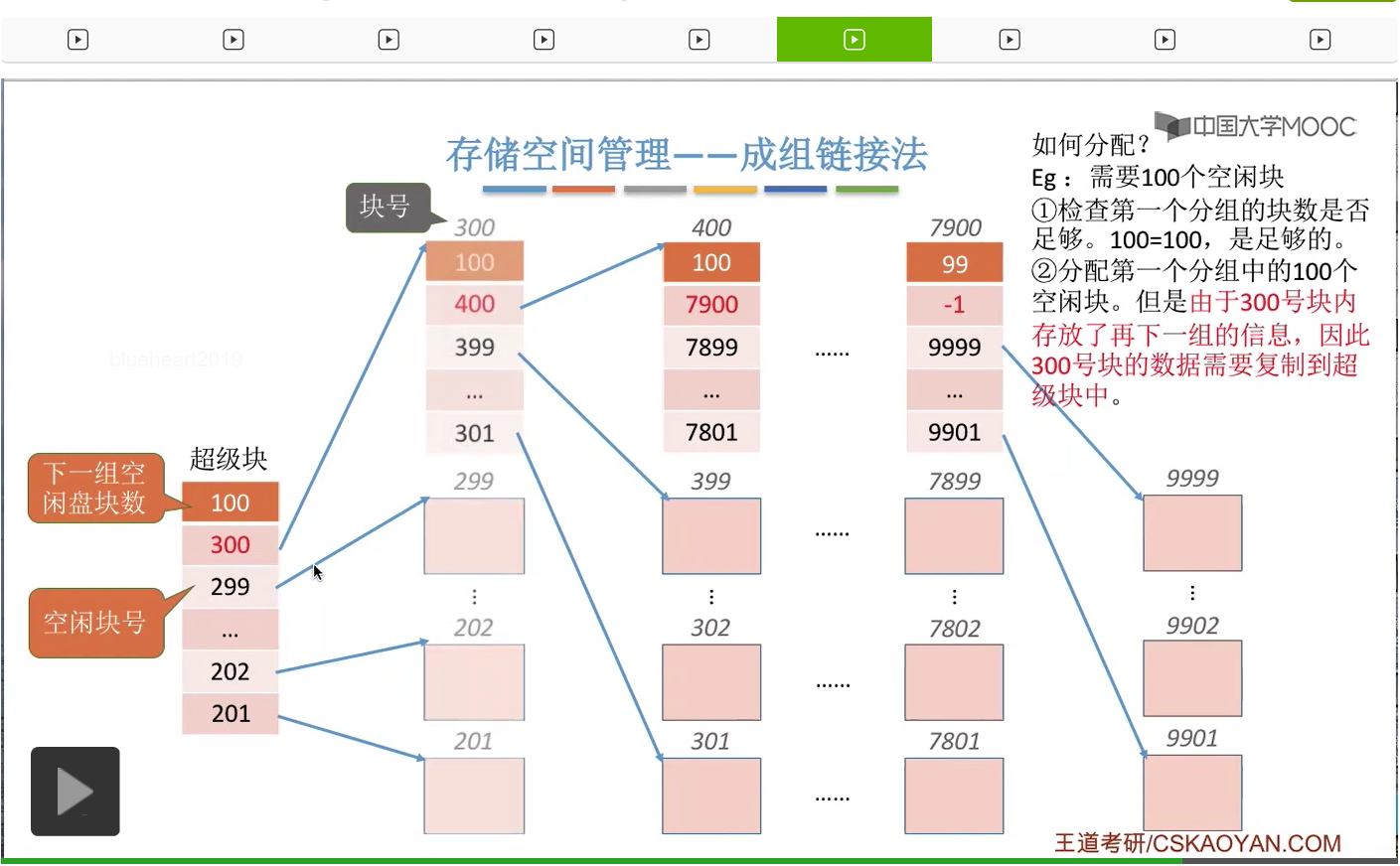
那这样的话就可以保证,虽然这个分组已经全部分配给这个文件了。
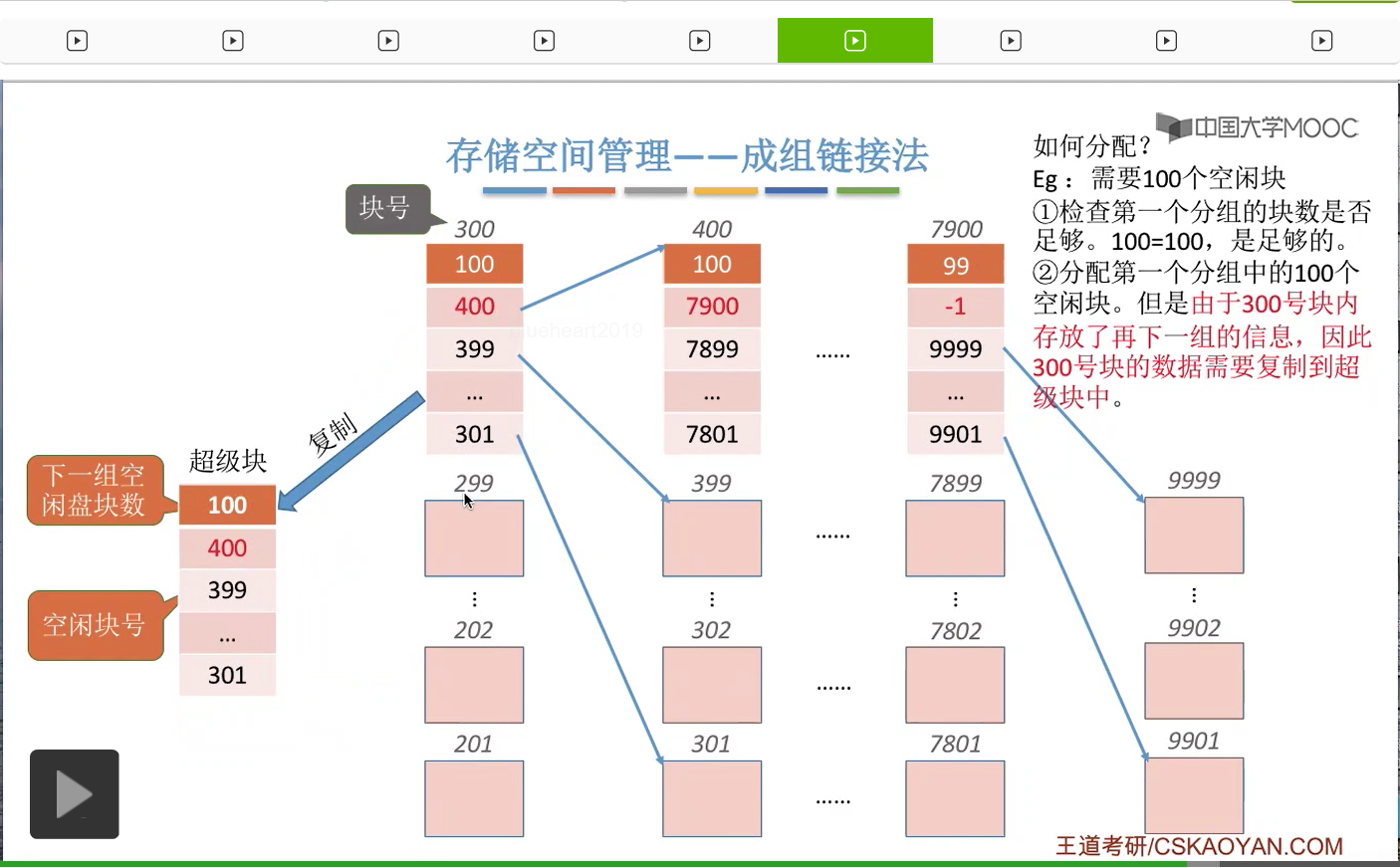
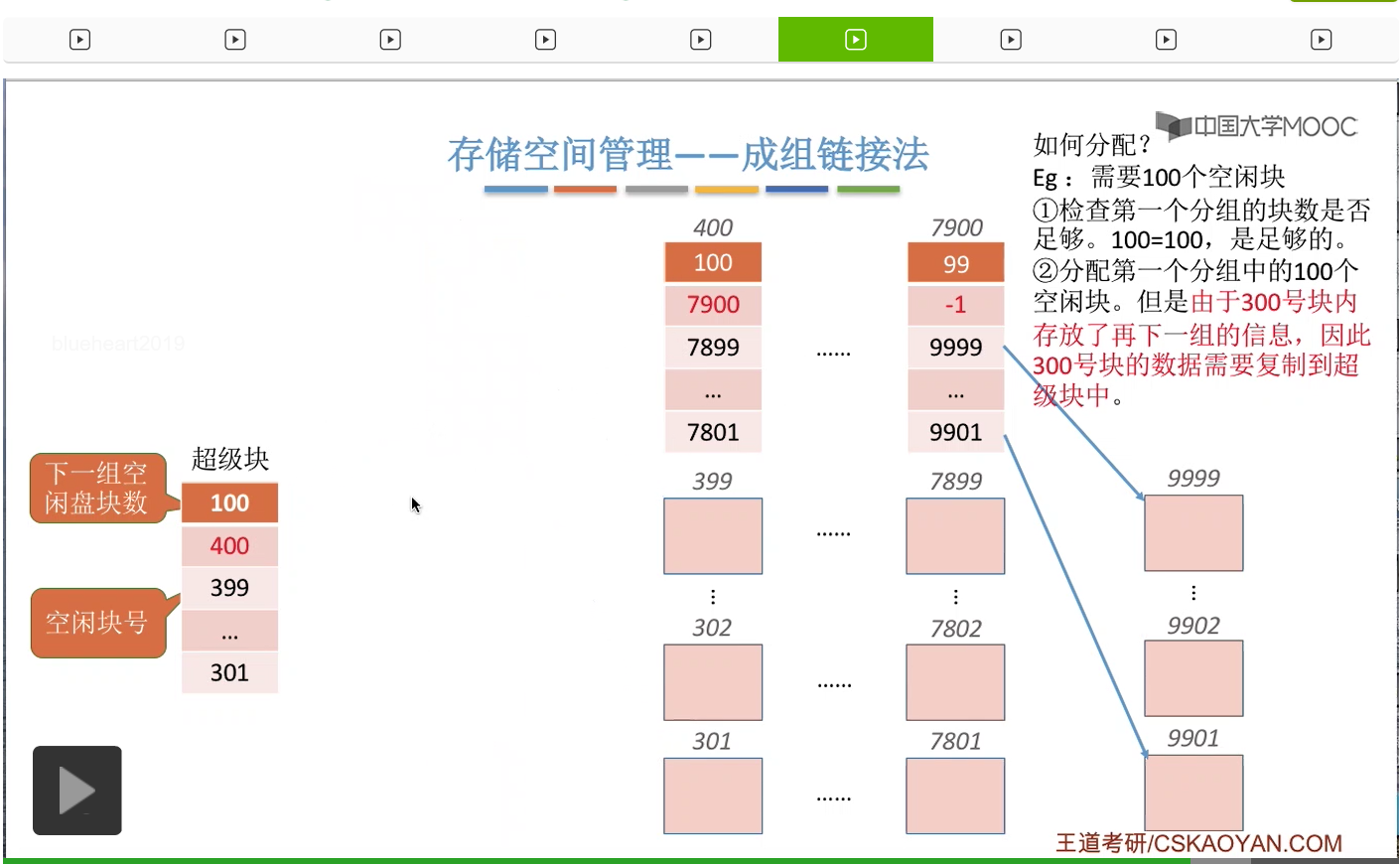
但是下一个分组的这些链接信息我们依然是保存在超级块当中的。那如果说文件要求的是更多数量的空闲块的话,那么我们依然是可以用同样的方式把这些分组一个一个一个地全部分配出去。不过需要注意的就是,每一个分组支持直接分配出去之前,需要把这个分组指向下一个分组的那些链接信息都先复制到超级块当中。所以超级块其实就充当了一个链头的作用。在这个链头当中永远要保持指向下一个分组的一些信息。

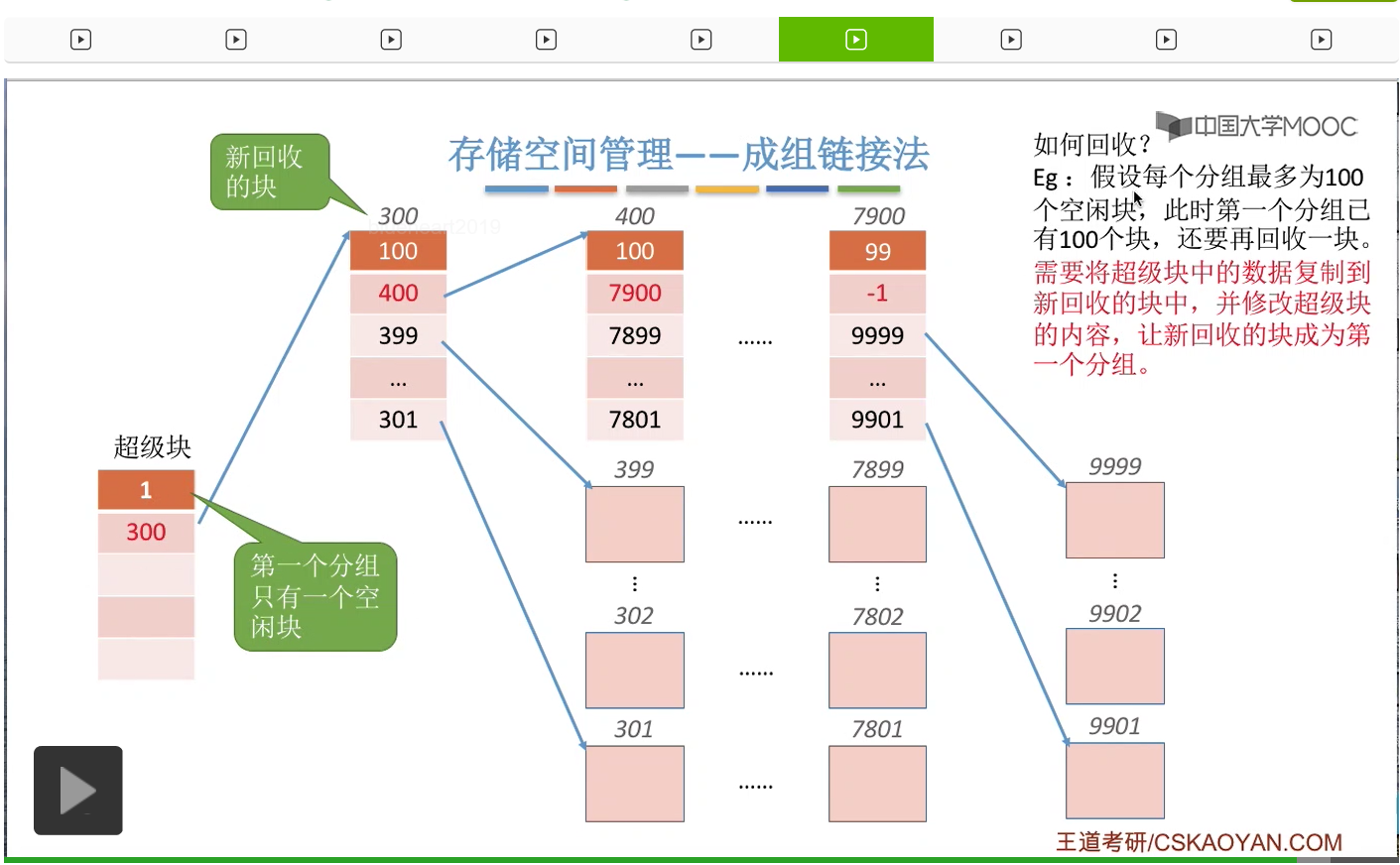
那接下来我们再来看一下怎么回收一个空闲块。假设每个分组的磁盘块上限是100块,而第一个分组此时只有99块。

那么假如此时还要再回收一个空闲块的话,那由于此时第一个分组还没满,所以我们可以把这个空闲块把它插到第一个分组当中。
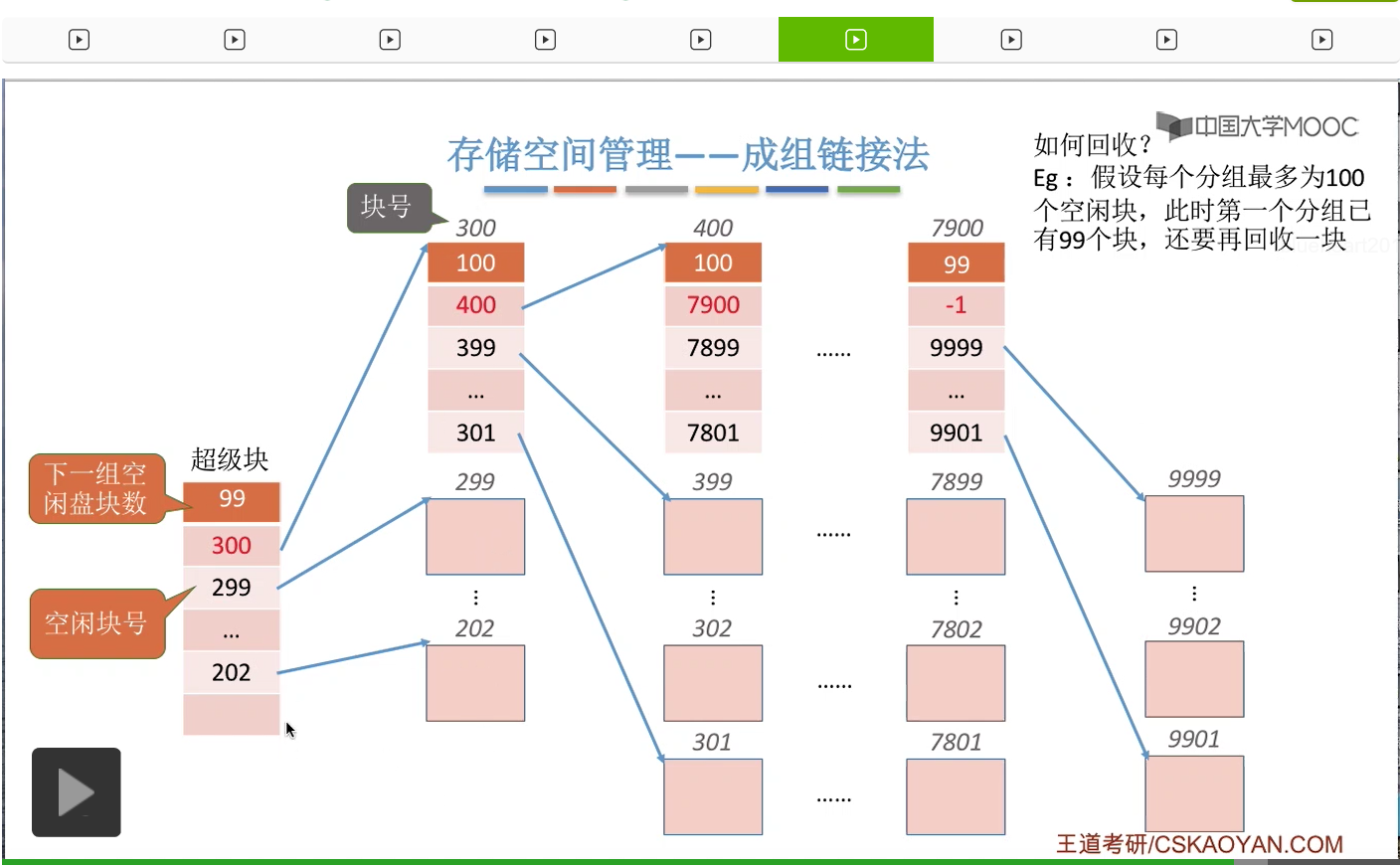
比如说我们回收的是201号块,那么我们可以把201号块的这个链接信息把它放到超级块当中,并且把超级块当中的这个下一组的空闲盘块数从99+1变成100那这是第一种情况。如果分组没满的话那么可以把这个回收的空闲块插到第一个分组当中。

那再来看第二种情况。假设此时第一个分组已经满了,总共有100个块。那如果此时还要再回收一个空闲块的话应该怎么处理呢?那由于这个分组已经满了,显然这个空闲块不能把它放到这个分组当中。
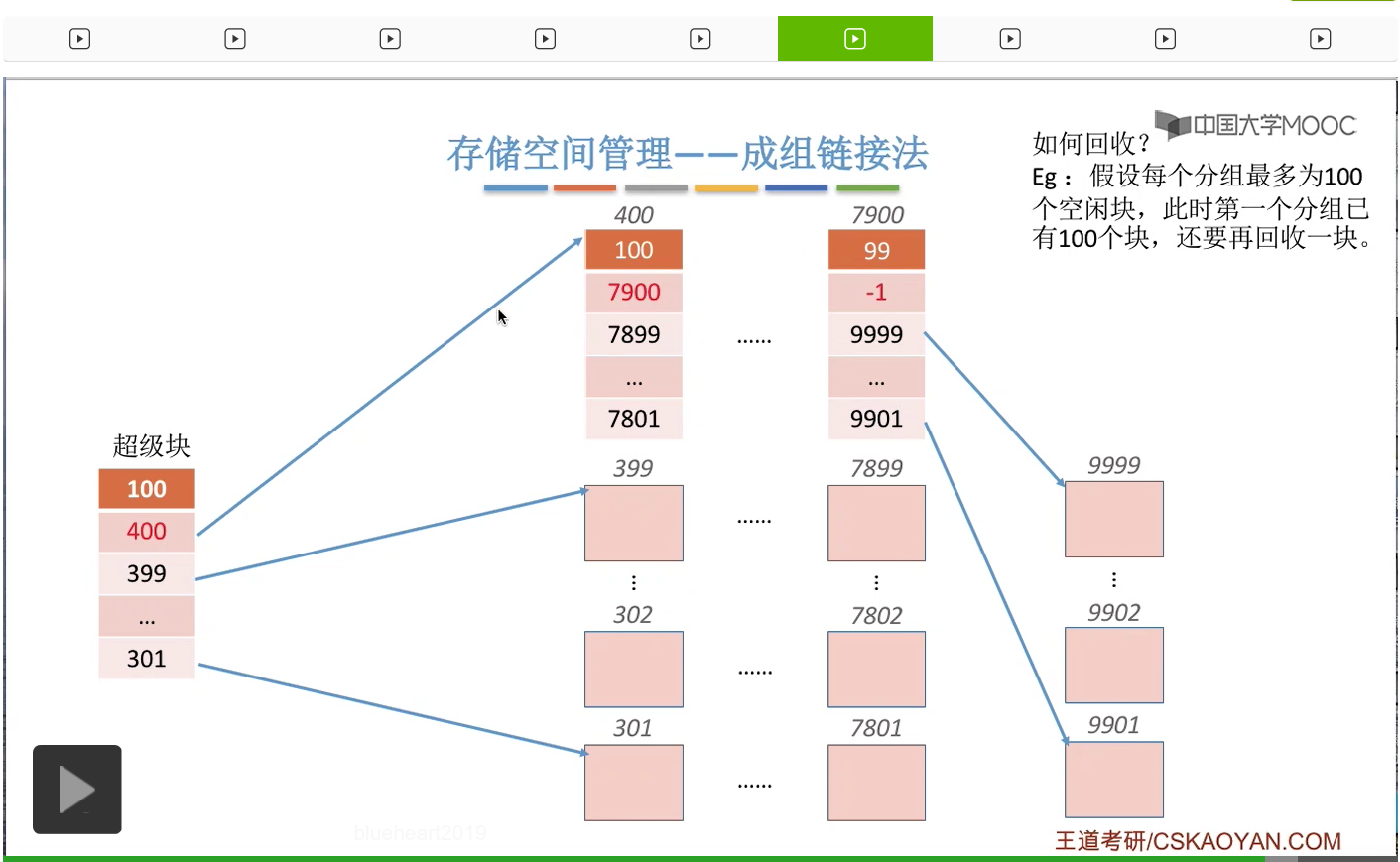
所以我们可以把这个新回收的空闲块作为一个新的分组。
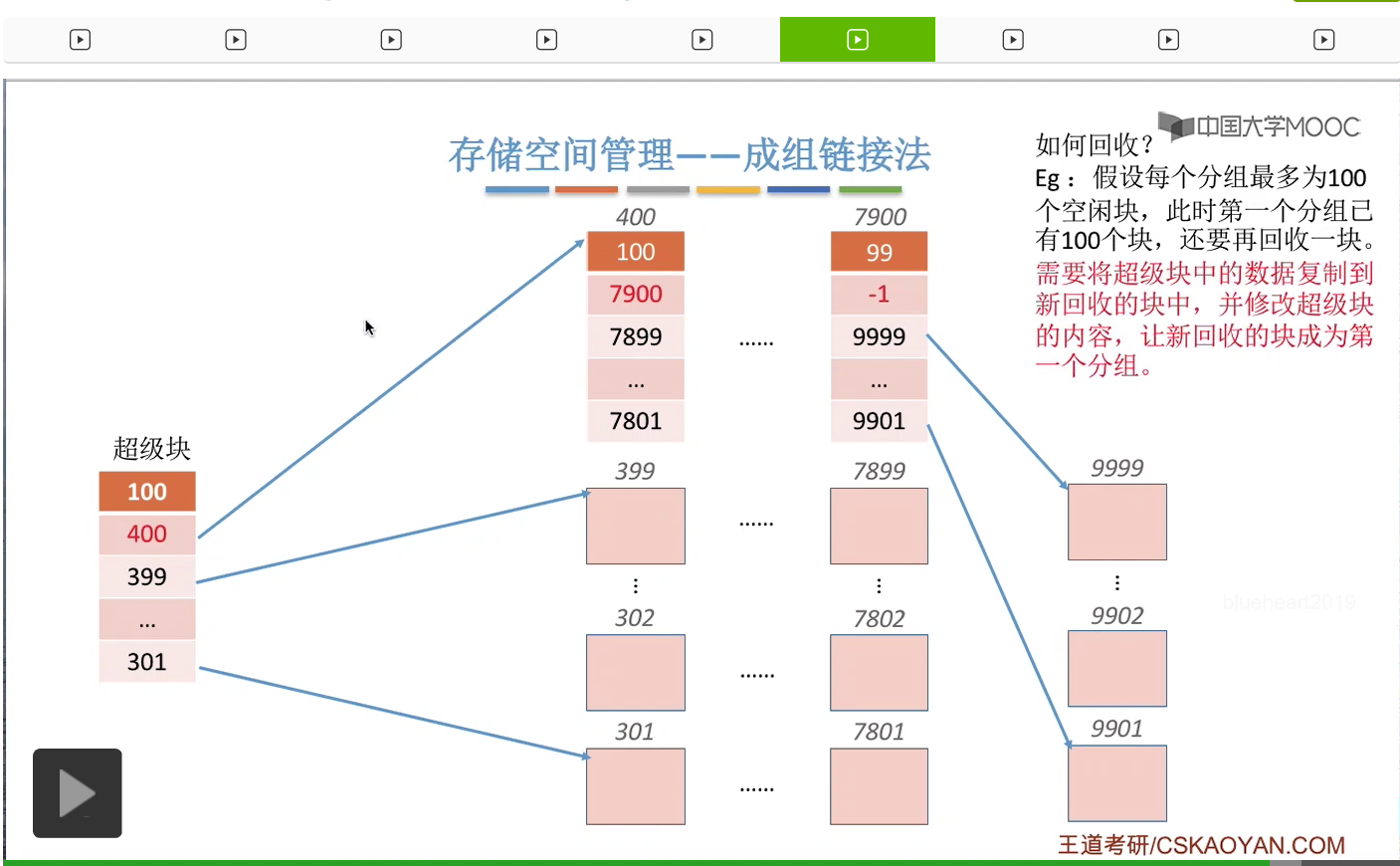
不过需要注意的是,我们需要把这个“超级块”当中的内容复制到这个新回收的块当中。
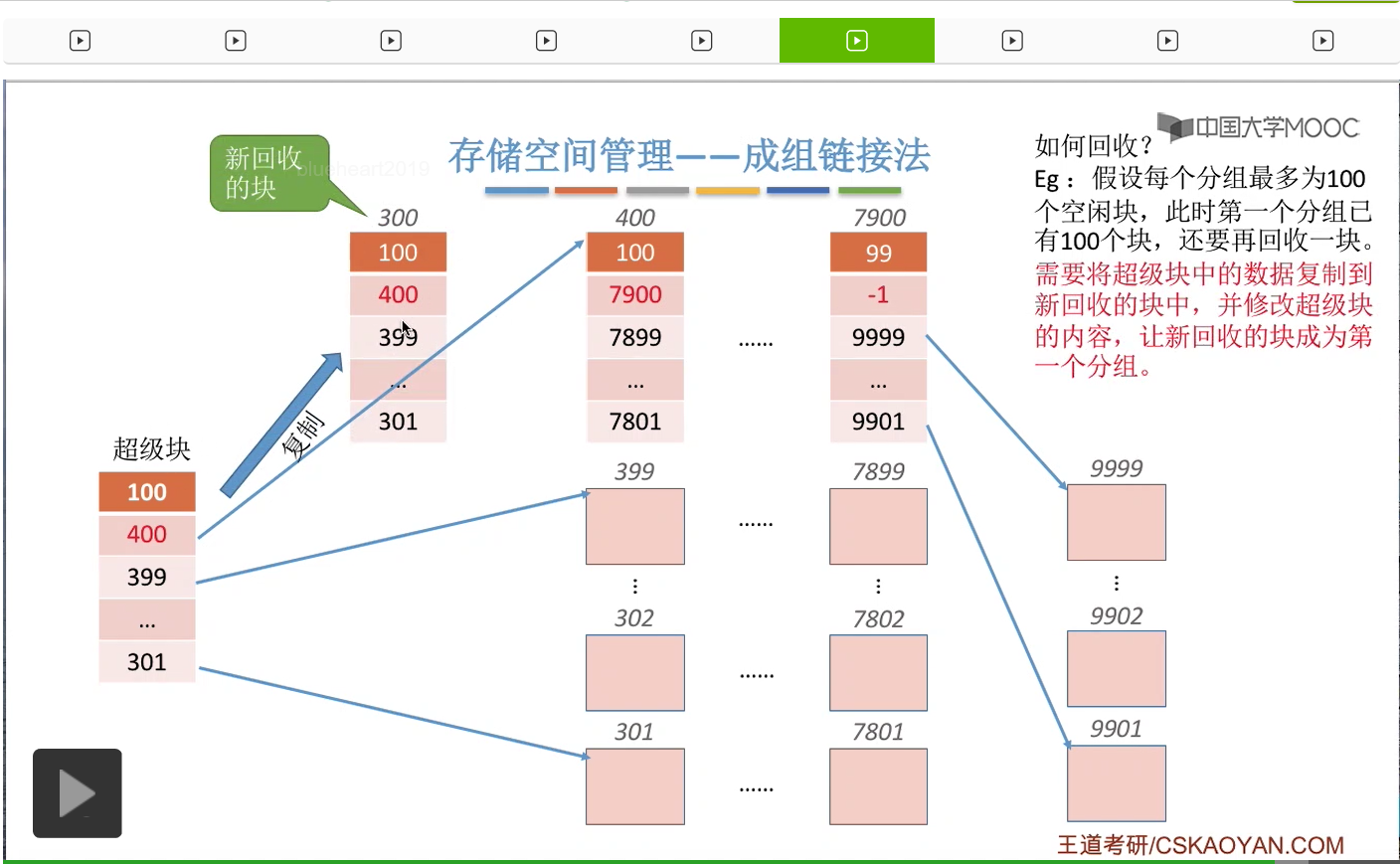
这样的话这个新回收的块它作为一个新的分组,它就拥有了指向下一个分组的这些链接的指针。
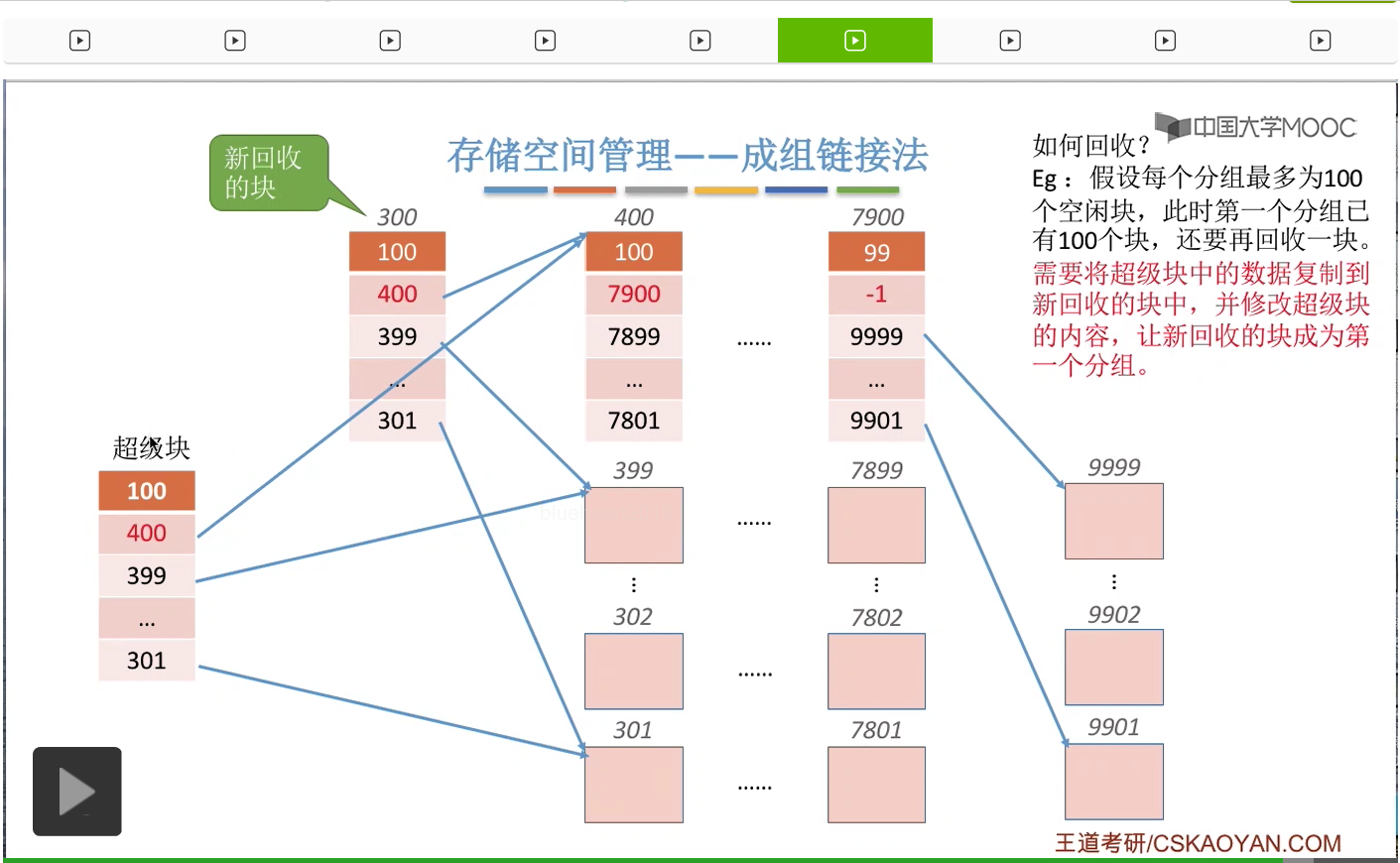
而由于我们的“超级块”永远是要指向第一个分组的,所以超级快的数据就需要进行修改,
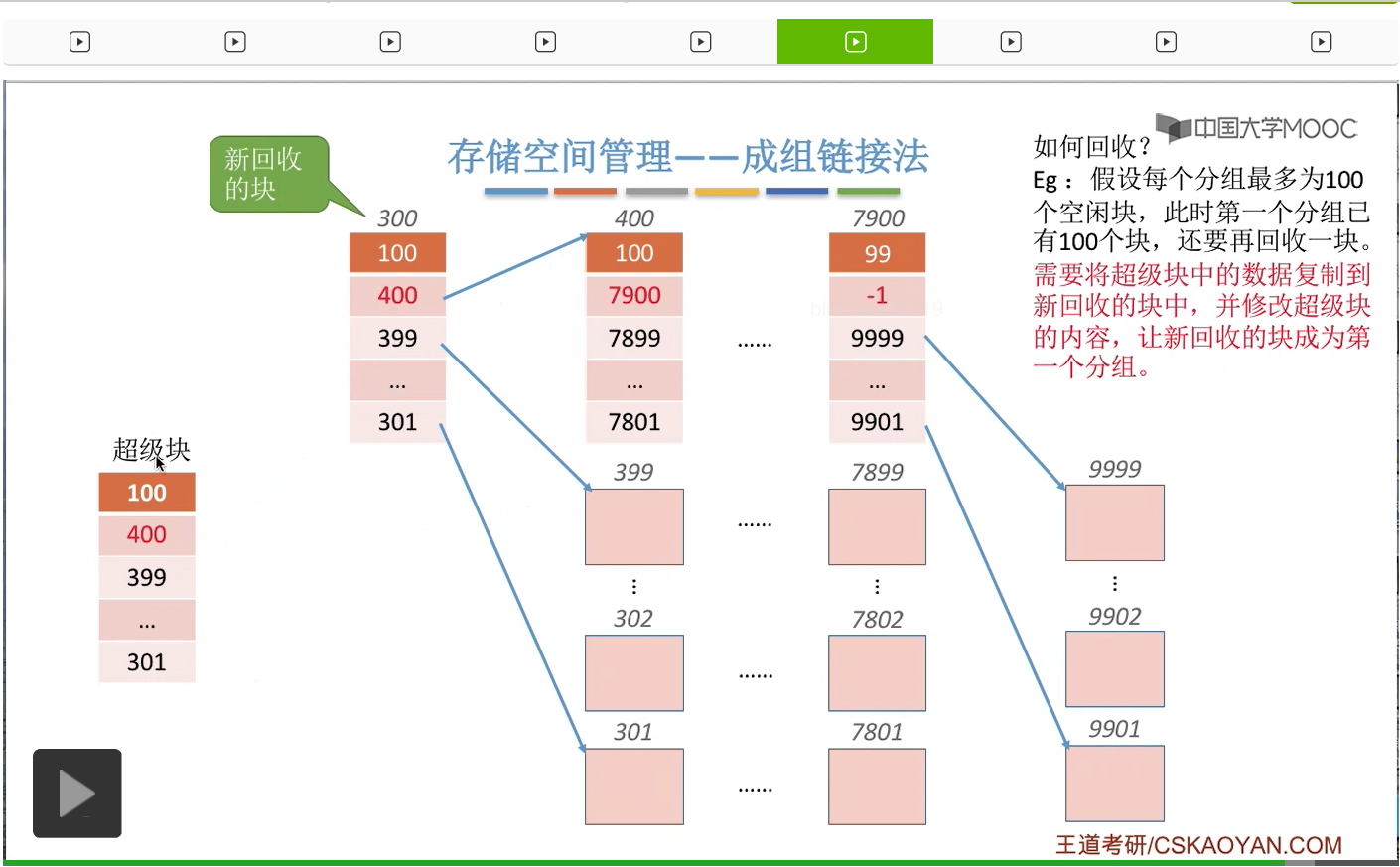
让它指向第一个分组也就是新的这个回收块组成的这个新分组。
那由于这个新分组当中此时只有1个空闲块,所以这个地方数据是1,然后指向它的块号也就是300。那这是回收的时候遇到的第二种情况。
介绍了文件存储空间管理相关的知识点。刚开始我们介绍了文件卷、目录区、文件区的概念。这些概念大家需要结合我们的生活经验什么C盘、D盘、E盘那些进行理解和记忆。

另外大家需要注意的是,一个文件卷当中,目录区中会包含文件目录,还有像空闲表啊、位示图啊、超级块啊这些用于文件管理相关的这些数据。而文件区就是用于存放普通的文件数据的。

那之后我们介绍了四种存储空间管理的方法,空闲表法有可能结合首次适应、最佳适应、最坏适应等等这些算法来进行考查,那这个大家还需要回顾咱们在内存管理那个章节当中学习过的这些算法的策略。那在空闲表法当中我们需要注意,在回收的时候是不是应该对表项进行合并呢?
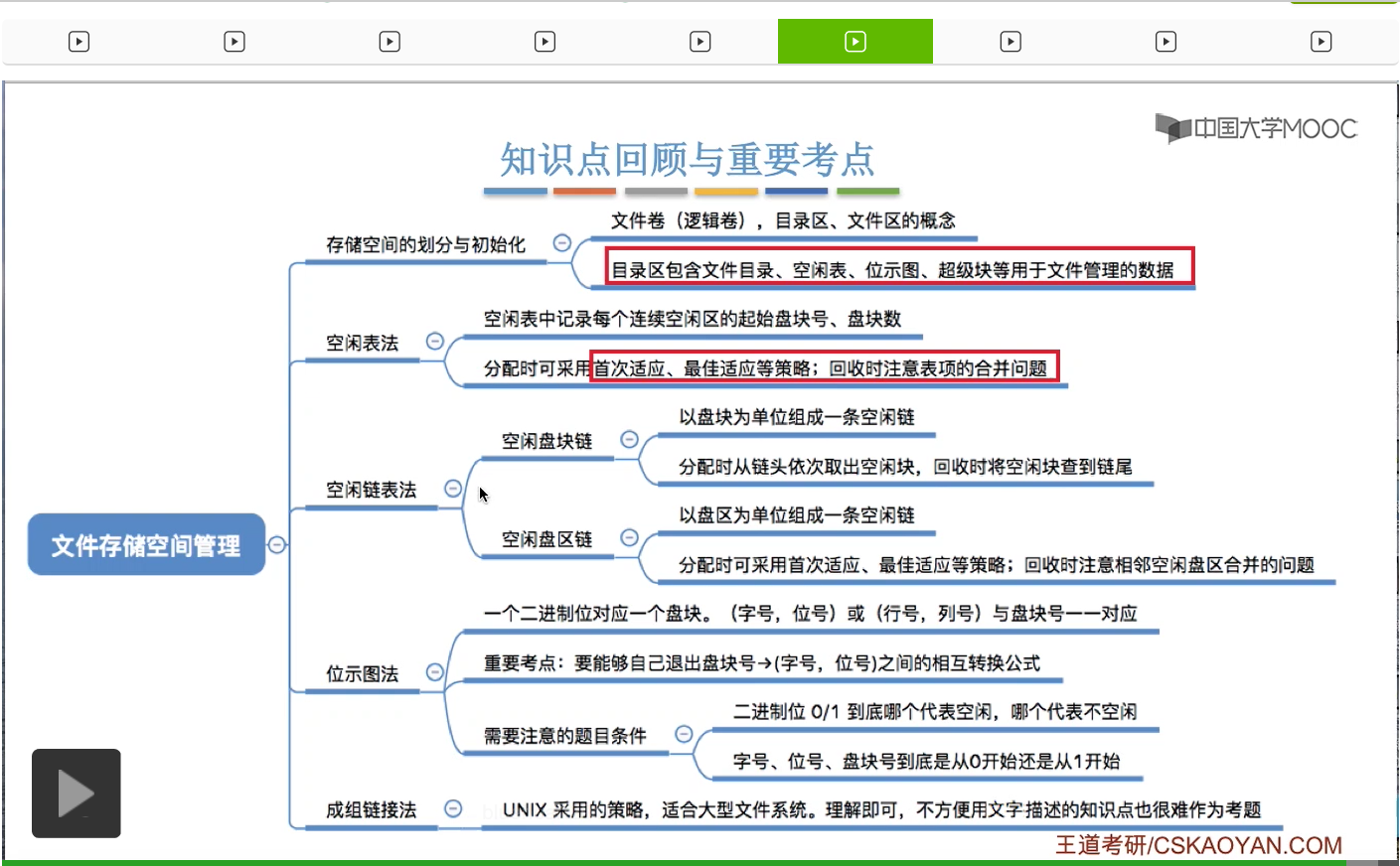
那接下来我们又介绍了空闲链表法,它又进一步可以细分为空闲盘块链和空闲盘区链。空闲盘块链是以盘块为单位组成一个空闲链,而盘区链是以盘区为单位组成一个空闲链。

要注意它们俩的区别。

那第三种位示图法这是咱们在考试当中最常考查的一个考点。大家要能够自己推出盘块号还有字号、位号之间的这种转换的公式。

另外呢,在做题的时候需要注意,二进制0和1到底哪一个是代表盘块空闲,哪一个是代表不空闲。还要注意字号、位号、盘块号到底是从0开始的还是从1开始的。

那最后我们介绍了成组链接法,这是UNIX系统采用的一种策略,适合于大型文件系统。那成组链接法的规则比较复杂并且不太方便用文字进行描述,所以这个知识点也很难作为考题进行考查。不过只要理解了刚才咱们分析的那些过程,那即使考到了,其实也没有关系,肯定是可以做出来的。

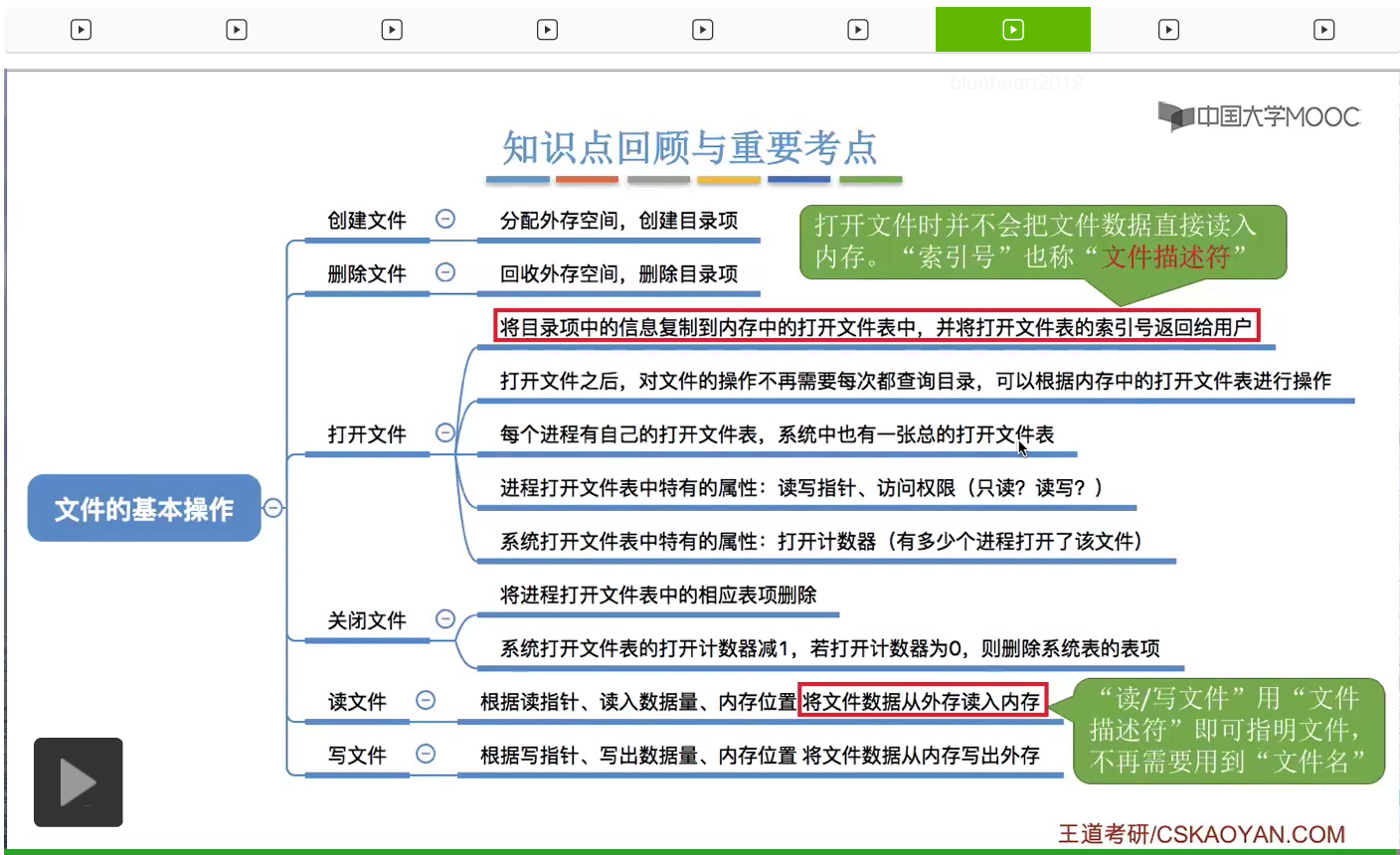
文件的几种基本操作。
包括创建文件、删除文件、读文件、写文件、打开文件和关闭文件。这些操作在背后到底做了一些什么事情。那么其他的一些复杂的操作也可以由这些基本操作来组合地完成,但是在考试当中,最经常考的还是这几种。

那在Windows操作系统当中我们点击右键新建一个文本文档的时候它在背后会帮我们自动地填写这些参数,然后文件名是默认填写为“新建文本文档.txt”。那操作系统在接收到我们的系统调用请求的时候它在背后需要主要做这样的两件事情。第一,需要在外存当中找到这个文件所申请的这么一些磁盘块、磁盘空间。那这个地方可以结合上个小节我们学习的空闲表法、空闲链表法、位示图法、成组链接法等等这一系列的管理策略来思考一下为文件分配存储空间到底是什么样一个流程。当然根据不同的这种存储空间管理策略有不同,在分配存储空间的时候所需要做的事情、算法也是不一样的。这个是上个小节介绍的内容。那这是系统需要做的第一个事情。
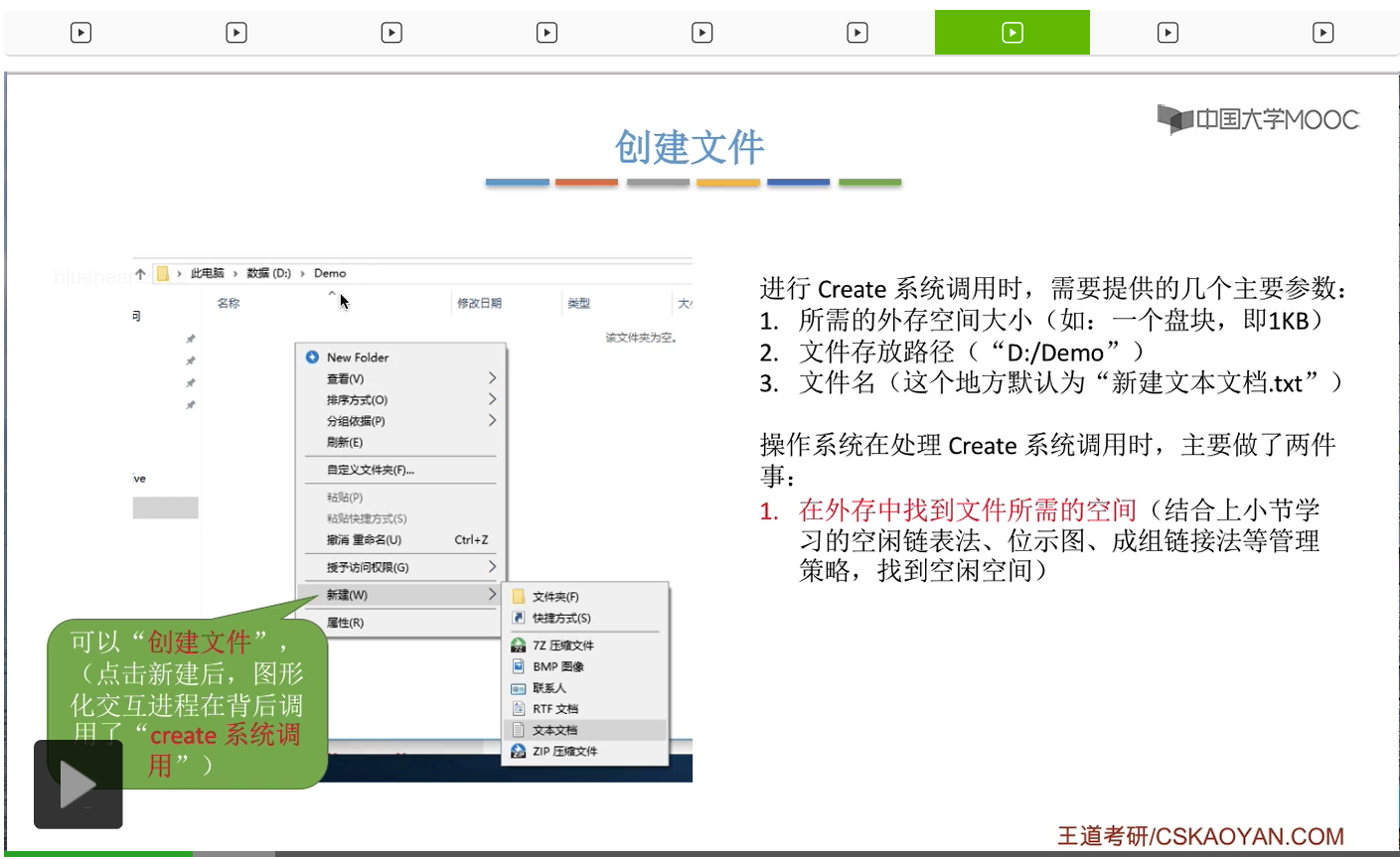
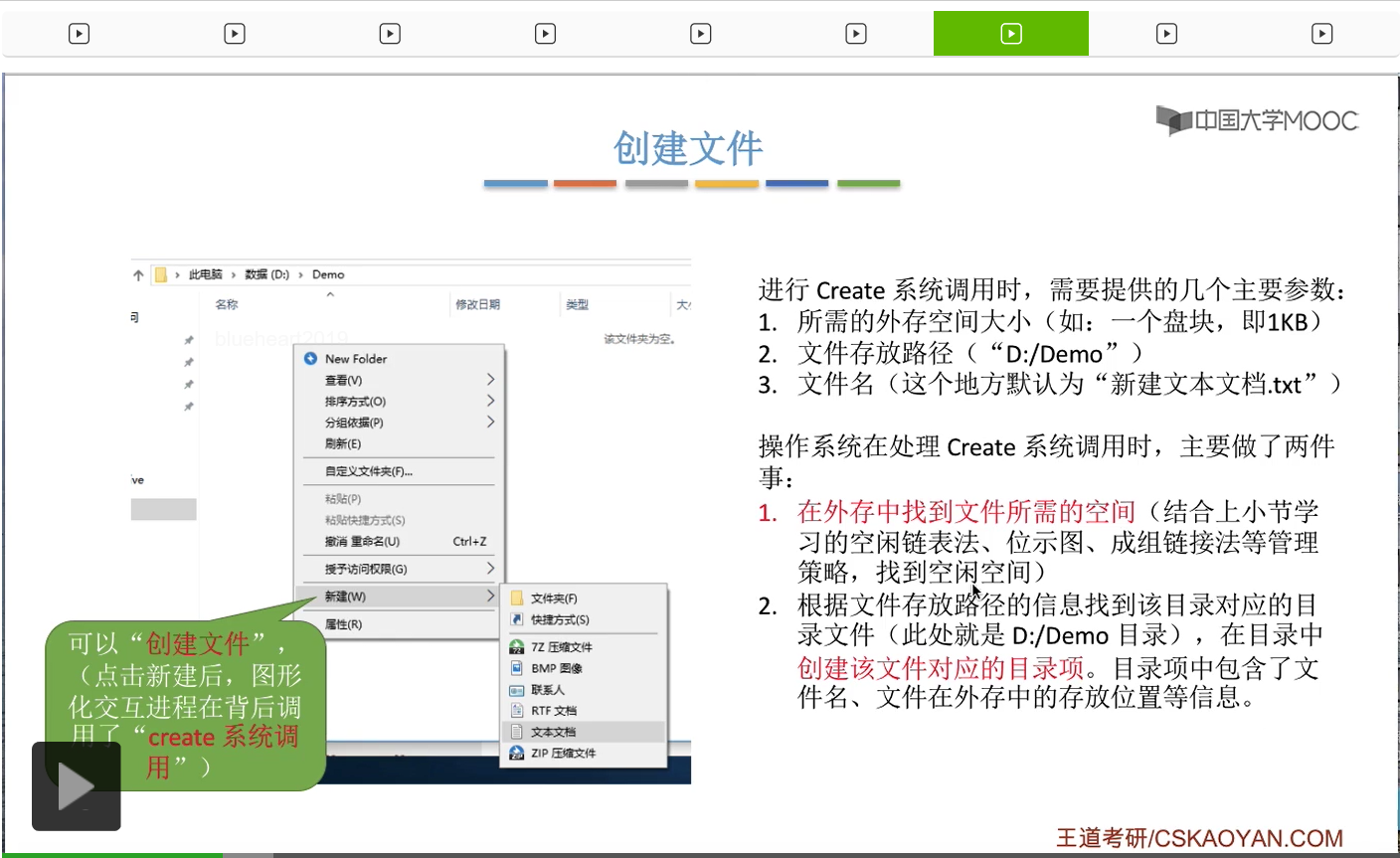
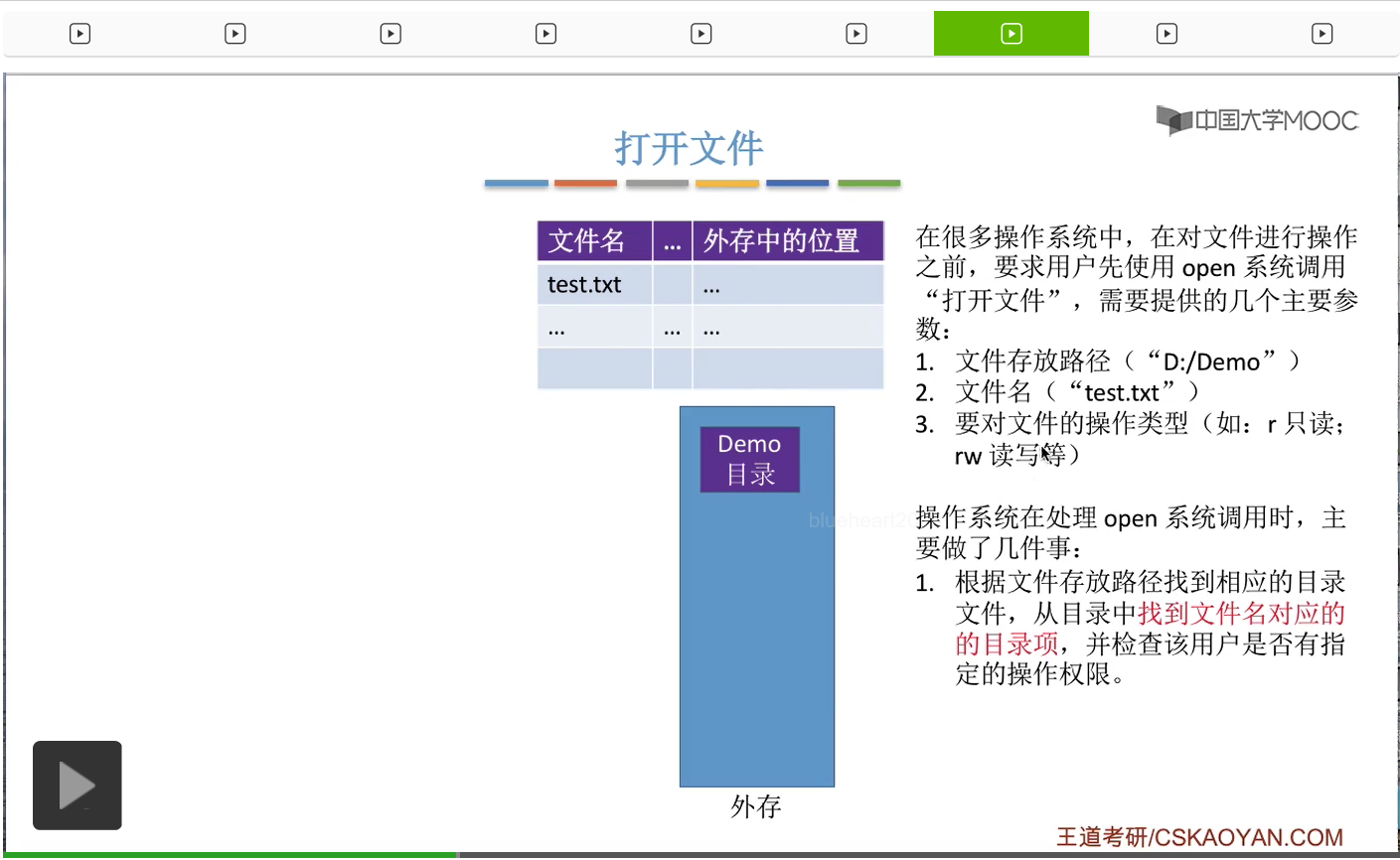
那操作系统在接收到这个系统调用请求的时候,会根据存放路径这个参数来找到Demo这个目录对应的目录表,那接下来可以根据这个文件名找到目录表当中对应的目录项。
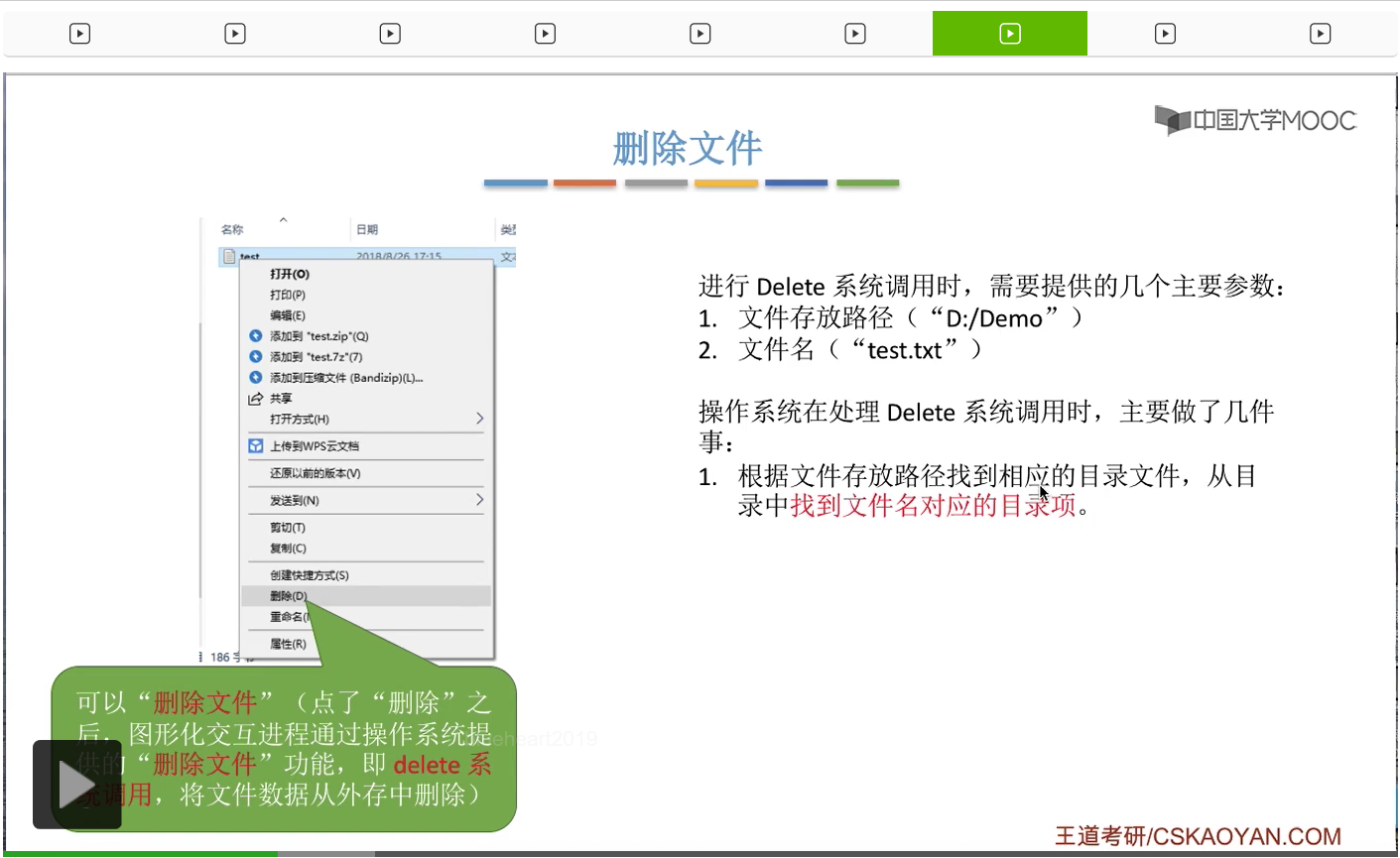
那既然找到了目录项我们就可以知道这个文件在外存当是存放在什么位置,它占用了多少磁盘块这些信息。那于是根据目录项当中记录的这些信息,操作系统就可以回收文件占用的这些磁盘块了。那在回收这些磁盘块的时候又根据空闲表法、空闲链表法、位示图法、成组链接法等等这些存储空间管理的策略不同,也需要做不同的处理。这也是咱们上个小节介绍过的内容。
第三,当文件占用的磁盘块全部被回收之后,需要把文件在目录表当中对应的目录项也给删除。那这是删除文件的时候所需要做的一些事情。
第一,会根据我们提供的文件存放路径,在外存当中找到这个目录对应的目录表。那在这个地方就是Demo目录对应的目录表。另外呢,不同的用户对文件的操作权限是不一样的。有的用户可能只可以读这个文件,而有的用户既可以读文件,也可以写文件。而这些用户对文件的这些访问权限的信息其实也是记录在这个目录项当中的。所以可以根据这个目录项,来检查此时用户请求的这个操作到底是否合法。那如果说用户没有这种操作的权限的话,那就可以拒绝用户打开这个文件,就终止处理。
而如果用户是有这种操作权限的话,

那么接下来操作系统会把这个文件对应的目录项
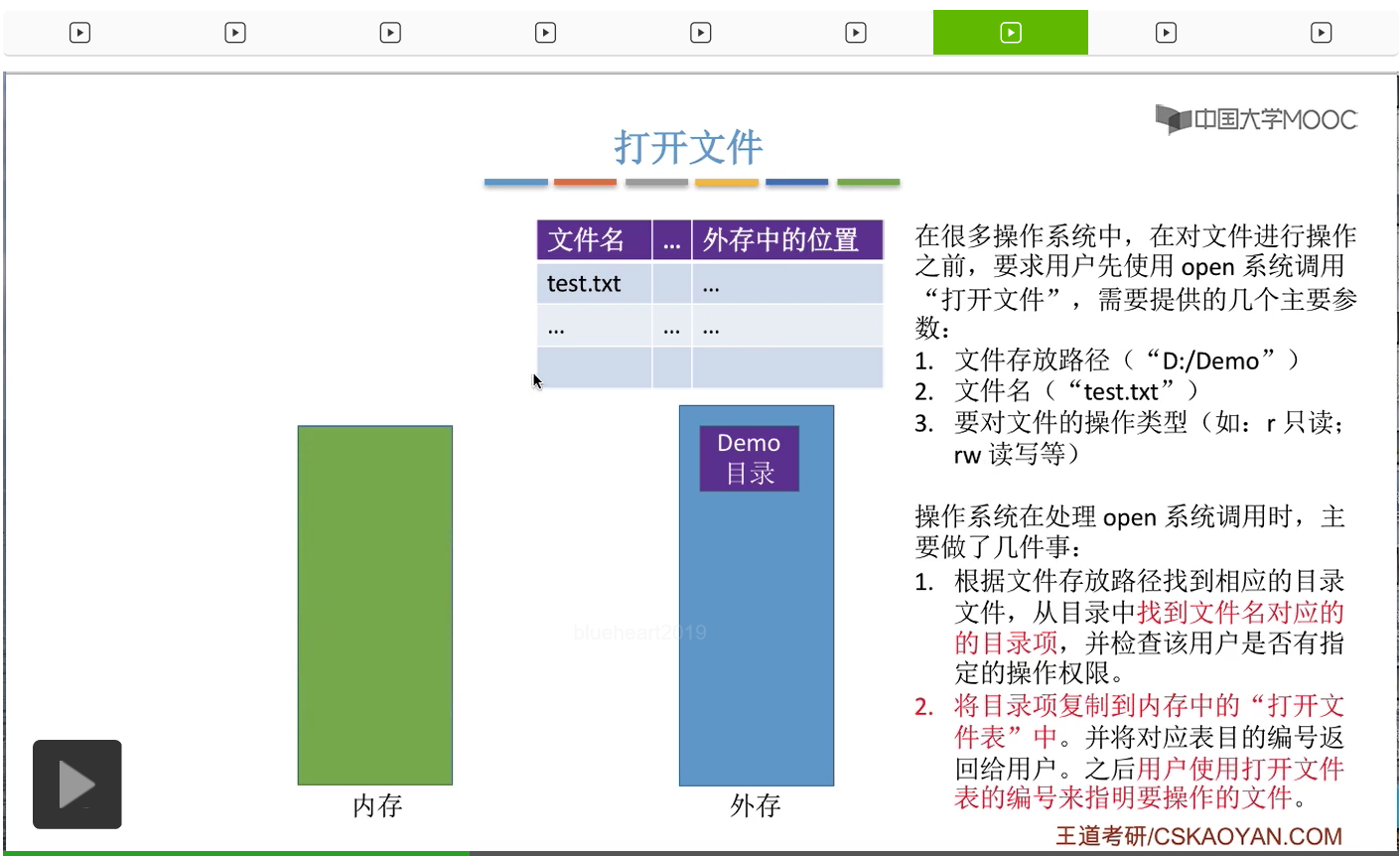
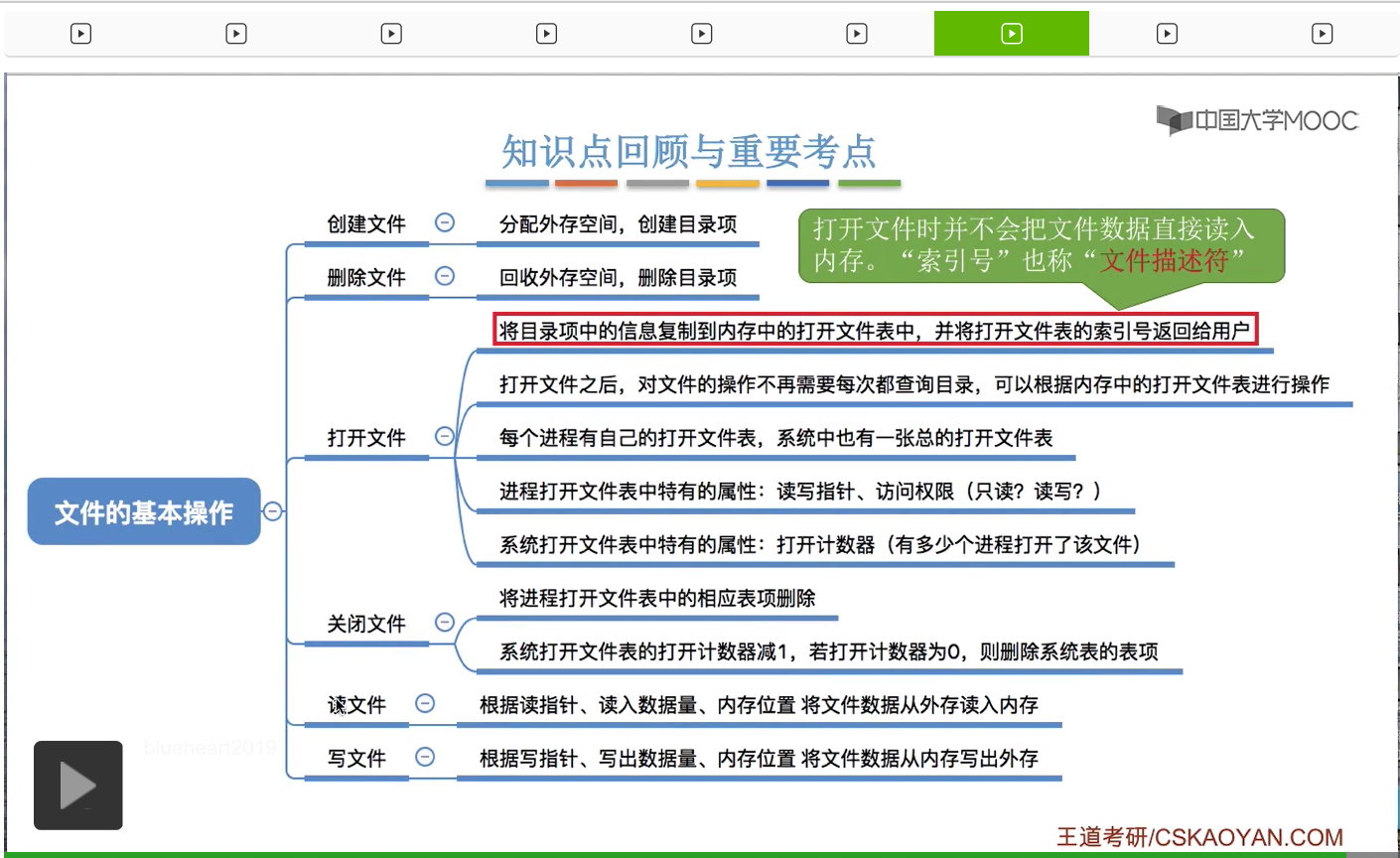
复制到内存当中的打开文件表当中。也就是说,在用户打开了一个文件之后,这个文件相关的那些信息就已经放到内存当中了。那之后用户想要再操作这个文件,只需要根据这个打开文件表的这个编号就可以找到自己想要操作的这个文件的一切信息。
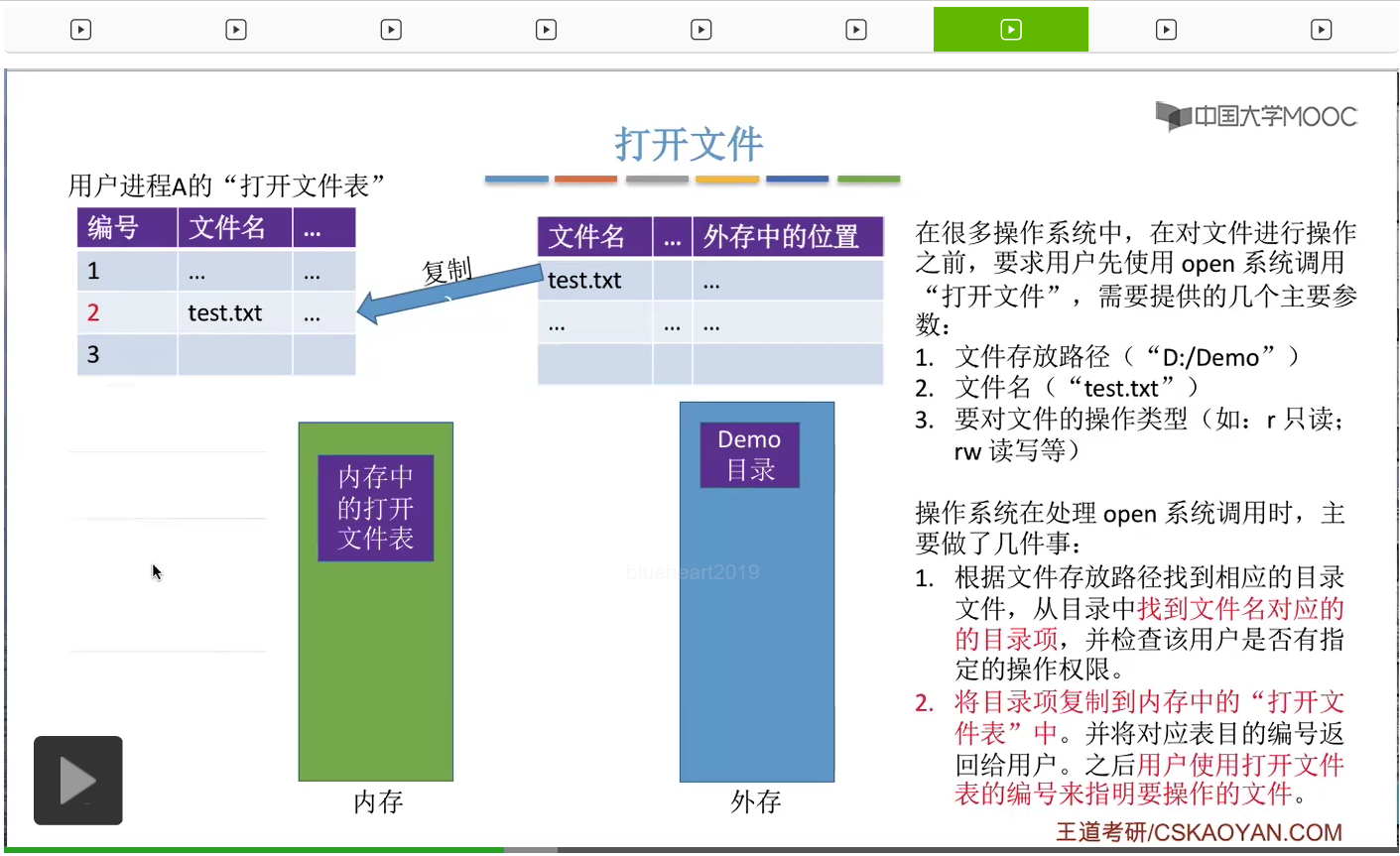
这样的话就不需要每次查文件的时候都重新访问目录了。因此,把目录项复制到打开文件表当中是可以大幅度地提升文件访问的速度的。那这是打开文件的时候需要做的一些事情。

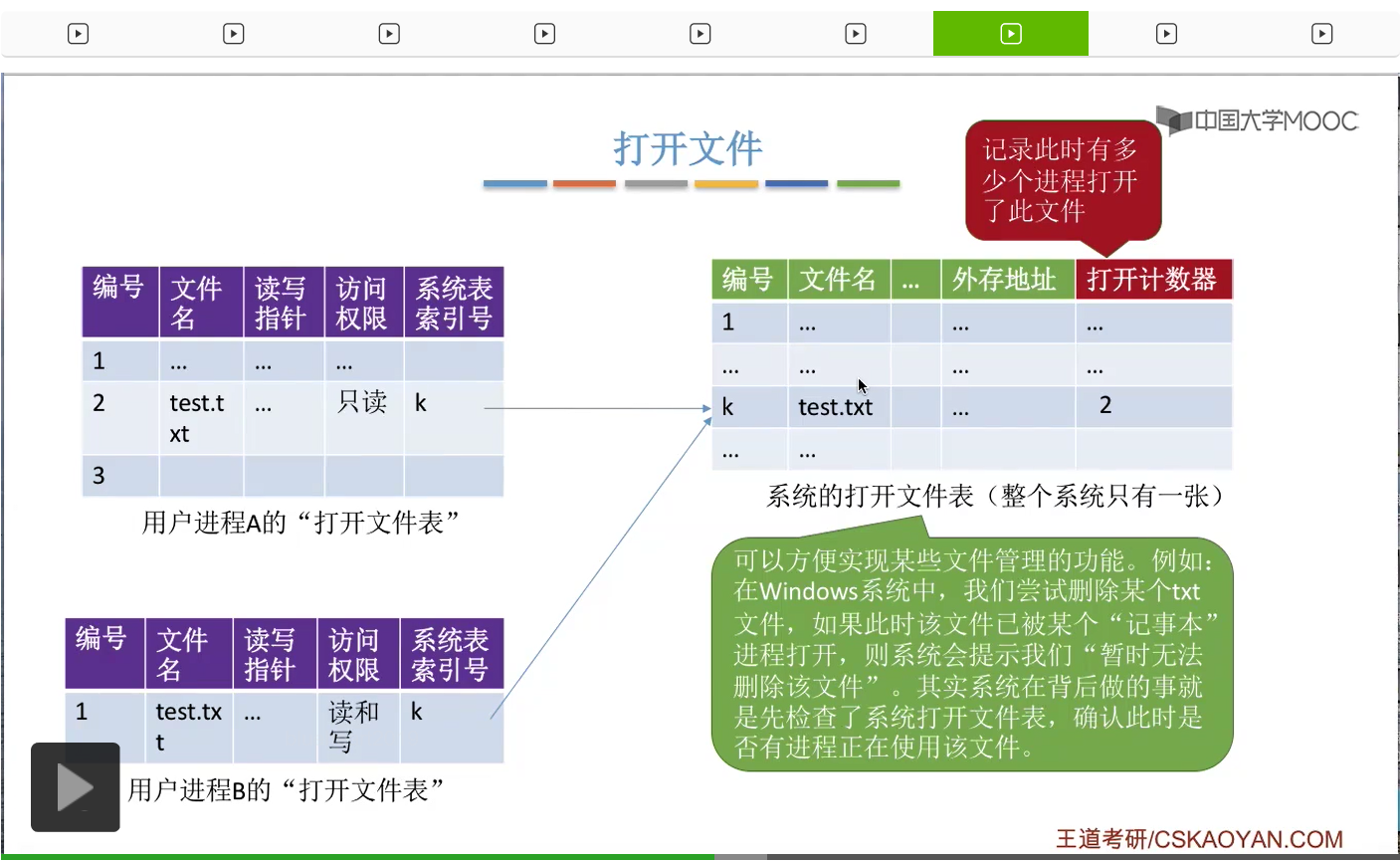
另外大家需要注意的是,有两种打开文件表。一种是系统的打开文件表,整个系统只有一张。然后这个打开文件表当中会记录所有的正在被其他进程使用的文件的一些信息。另外,每个进程也会有一个自己的打开文件表。这张表当中记录了自己的这个进程此时已经打开的文件到底是哪些。那在进程的打开文件表当中会有一个系统表的这个索引号,比如说test.txt这个文件在系统表当中编号是k这个表项。那么这个地方的k就是指向了这个表项。

那同样的,如果另一个进程B也打开了“test.txt”这个文件,那它同样也会指向这个系统的打开文件表。那这个地方大家需要注意的是,在系统的打开文件表当中有一个字段叫做打开计数器,就是用来记录这个文件此时已经被几个进程打开了。

那此时如果有两个进程打开了这个文件的话,那这个打开计数器就应该修改为2这样的数值。

所以像打开计数器这个字段是系统的打开文件表当中所特有的一个字段。

那其实在整个系统当中设置一个打开文件表的总表,这样的方式是比较方便实现某一些文件管理功能的。比如说我们在使用Windows操作系统的时候,所以如果我们在系统当中设置了一个这样的总表的话,那么对于一些文件管理的功能是很方便实现的。
另外在进程的这个打开文件表当中,大家会发现有两个比较特殊的字段。第一是叫读写指针。它其实就是记录了这个进程对文件进行读写操作此时进行到了什么位置。
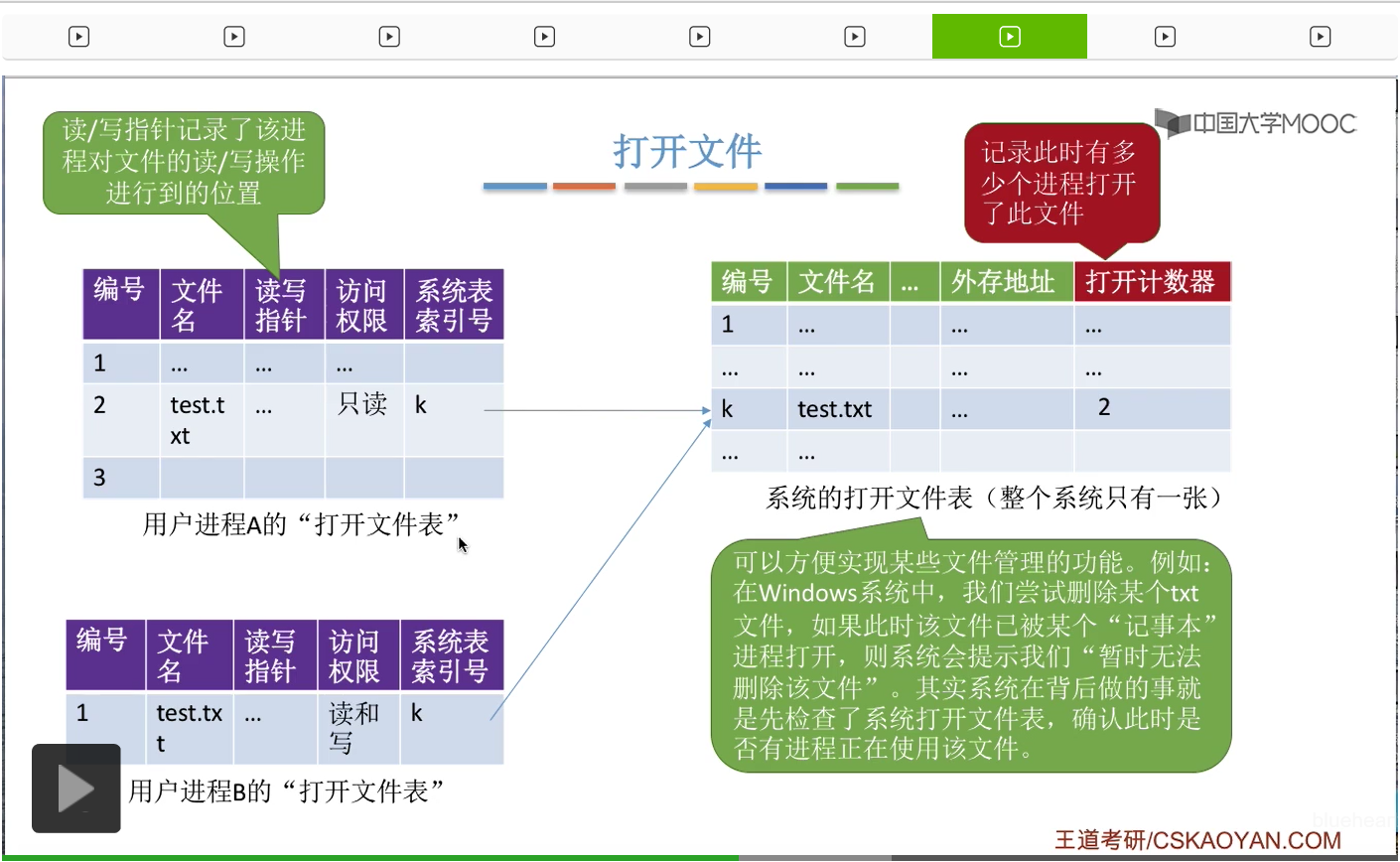
第二在进程的打开文件表当中,还需要标明这个进程对文件的访问权限。所以在进程的打开文件表当中,比较特殊的是读写指针和访问权限这两个字段。不同的进程对一个文件进行读写操作,进行到的位置是不一样的,所以不同进程的读写指针也是应该不一样。另外,不同的进程在打开一个文件的时候所申请的这种访问类型也是不一样的。因此,访问权限这个字段也应该放在进程的打开文件表当中。当然,除了这个地方列出的这些字段之外,在进程的打开文件表当中还会有其他的一些文件的信息,这儿就没有全部列举。


那相应的需要回收分配给这个文件的内存缓冲区等等一系列的资源。

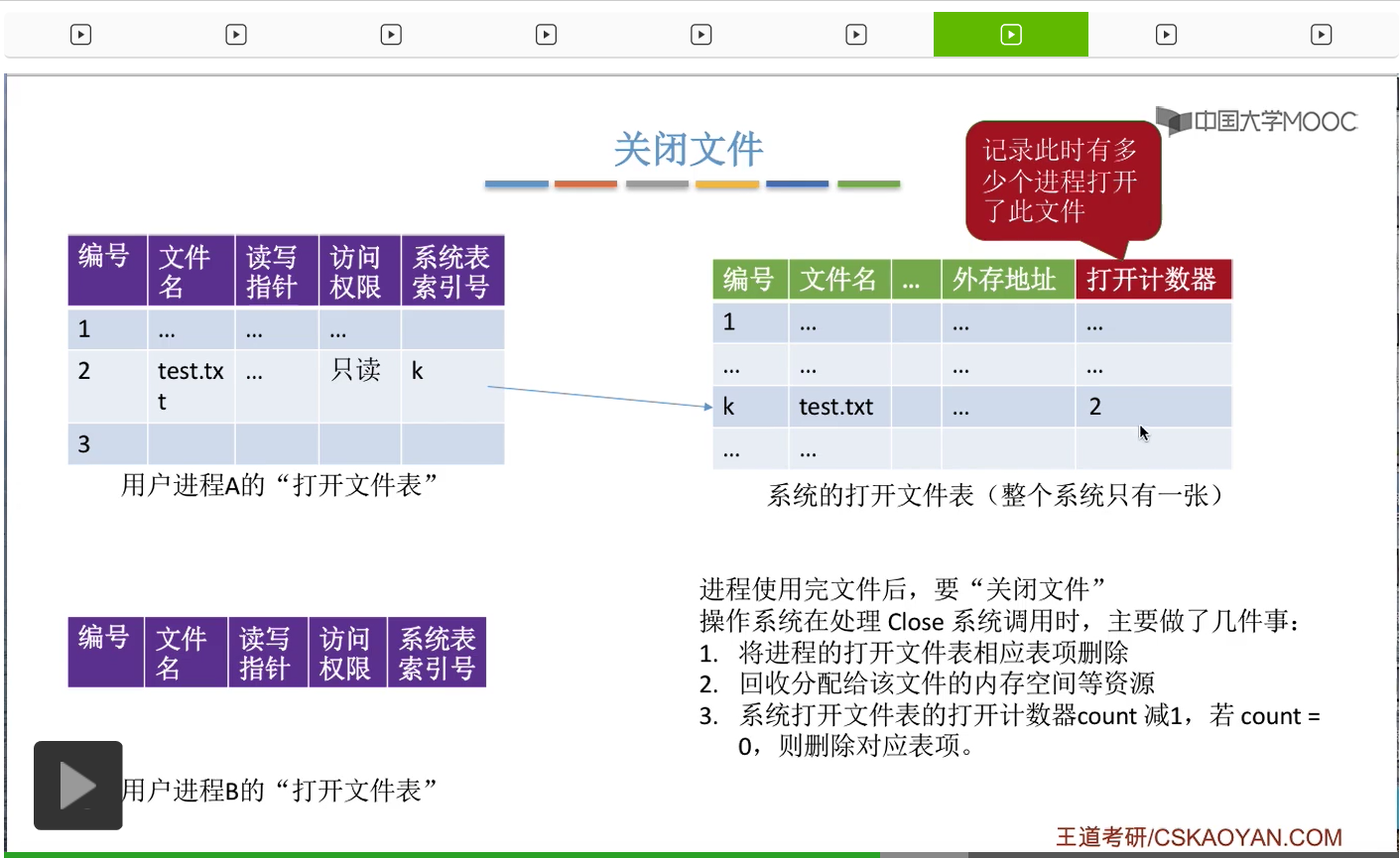
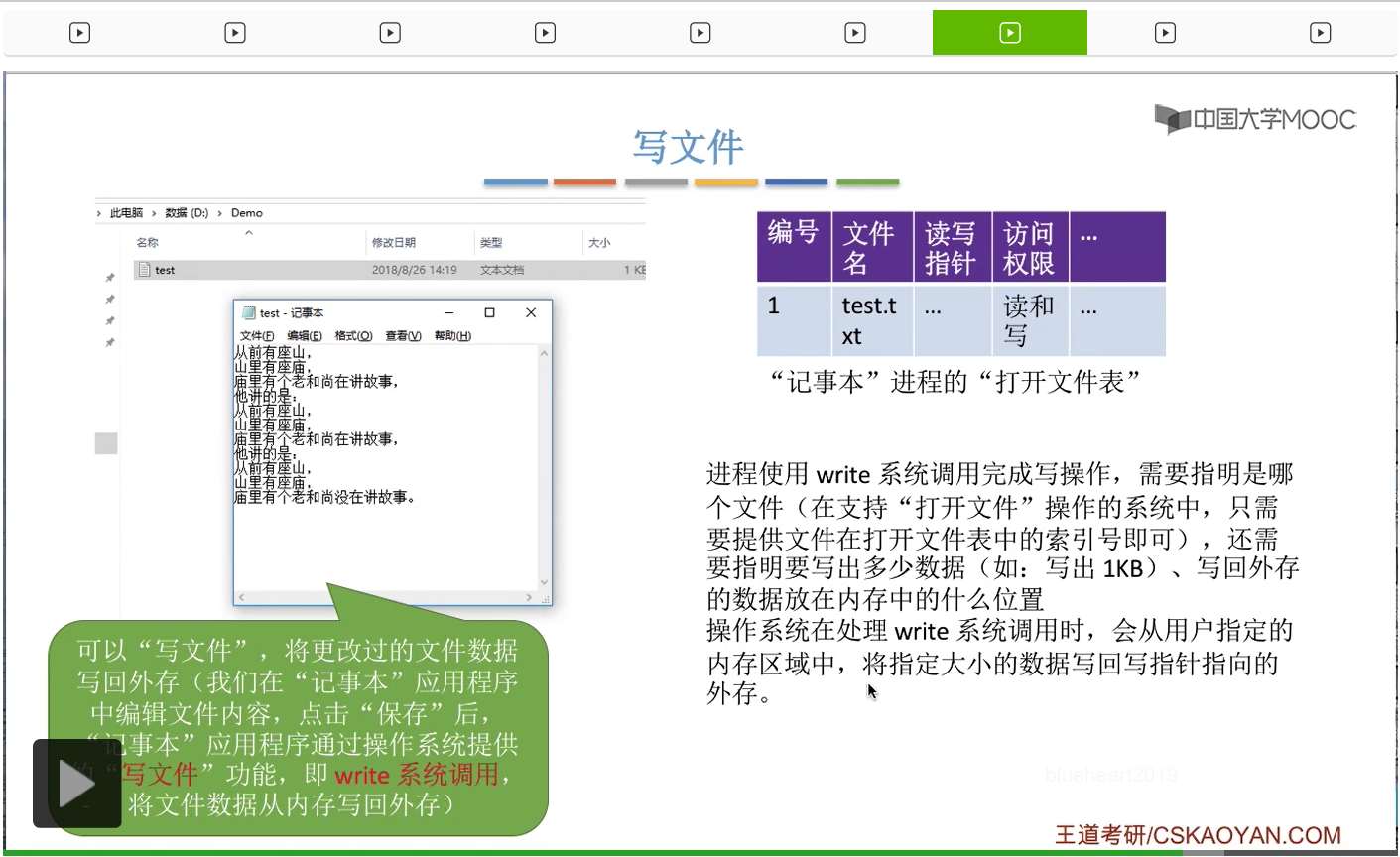
那由于此时这个打开计数器依然是大于0的,所以说明此时这个文件还在被其中的某一些进程所使用。因此,系统打开文件表当中的这个表项暂时不能删除,只有打开计数器为0的时候才需要删除系统打开文件表当中的这个表项。那这是关闭文件的时候需要做的一些事情。

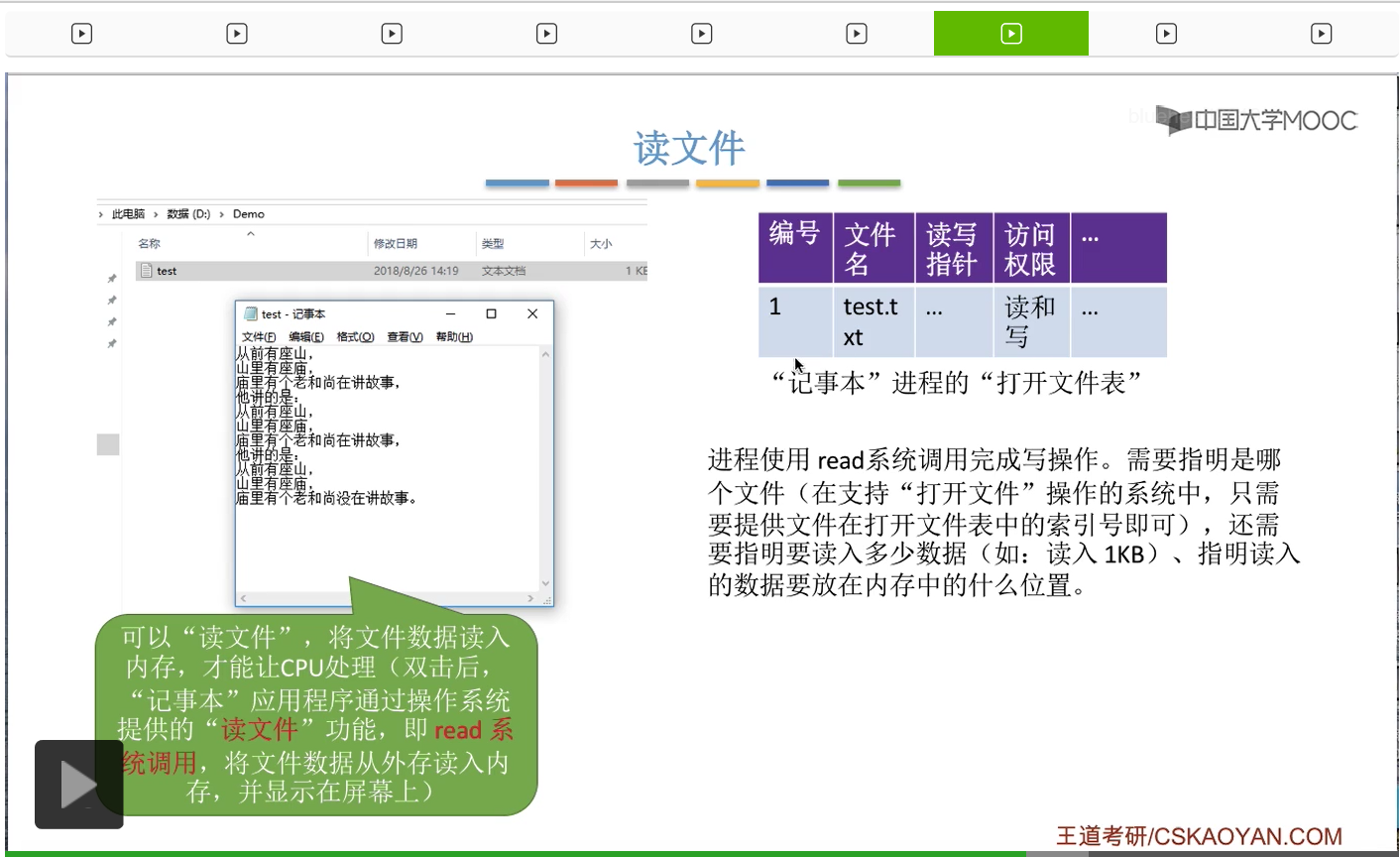
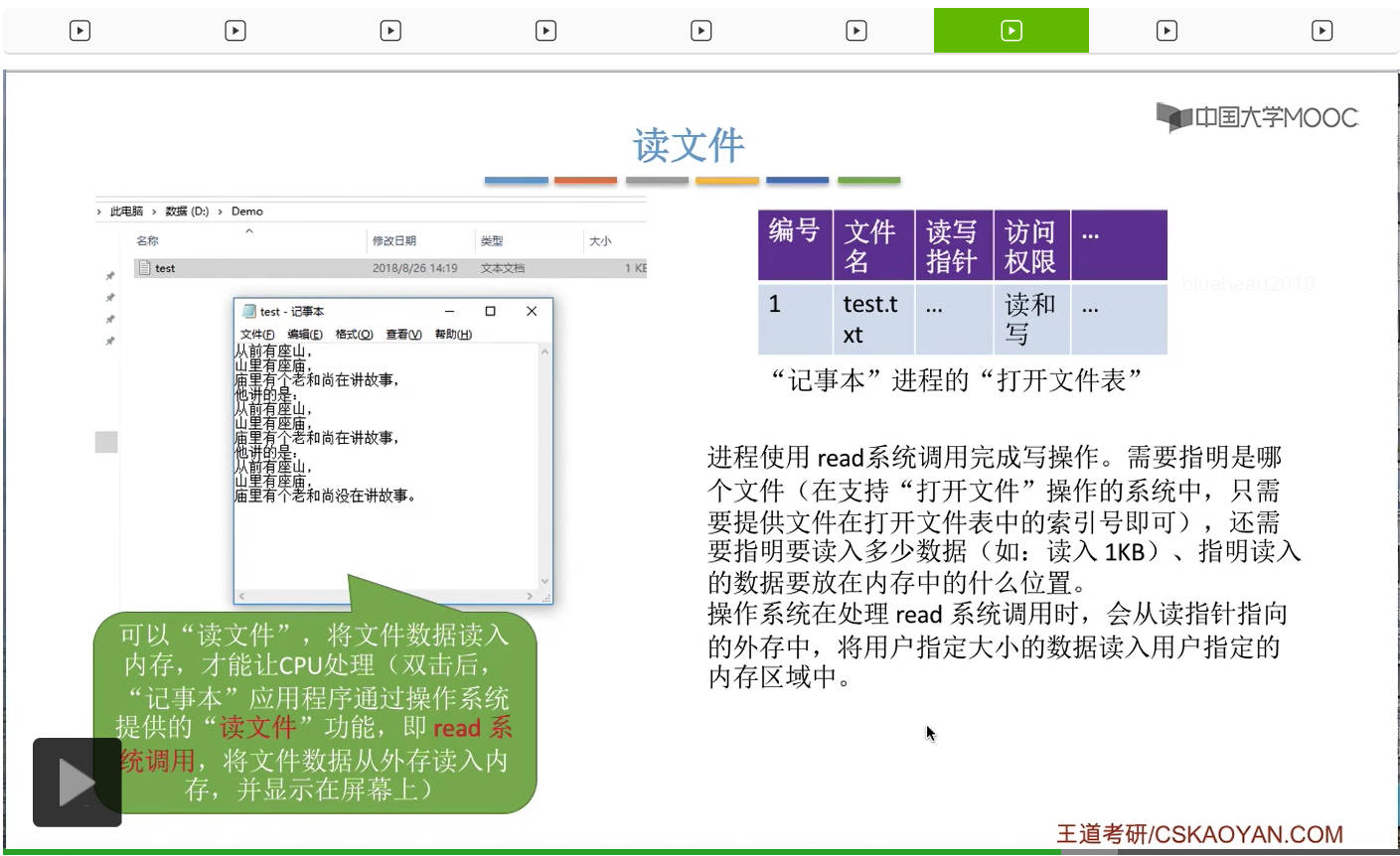
不过通过之前的讲解我们知道,在对文件进行读写操作之前,一定要先打开文件。所以其实在正式开始读文件的时候,记事本这个进程的打开文件表当中,已经有了这个文件对应的一个表项了。因此,记事本这个进程在读文件的时候只需要指明自己要读的这个文件它对应的打开文件表的编号到底是多少就可以了。那这是读文件的时候需要提供的第一个参数,就是要指明到底要读的是哪一个文件。第二,在读文件的时候还需要指明此时需要读入的是多少个数据。比如说此时是要把这个文件全部1KB的内容都读入内存,那么就需要指明此时需要读入的是1KB这么多。另外,还需要指明这个读入的数据到底是要放在内存当中的什么位置。那这些参数的填充都是记事本这个进程在背后为我们完成的事情。
那操作系统在处理这个read系统调用的时候,会根据打开文件表当中读写指针这个读指针所指向的外存地址那个地方,读入用户指定的大小的这么多的数据,然后放到用户指定的那个内存区域当中。这是读文件需要做的事情。
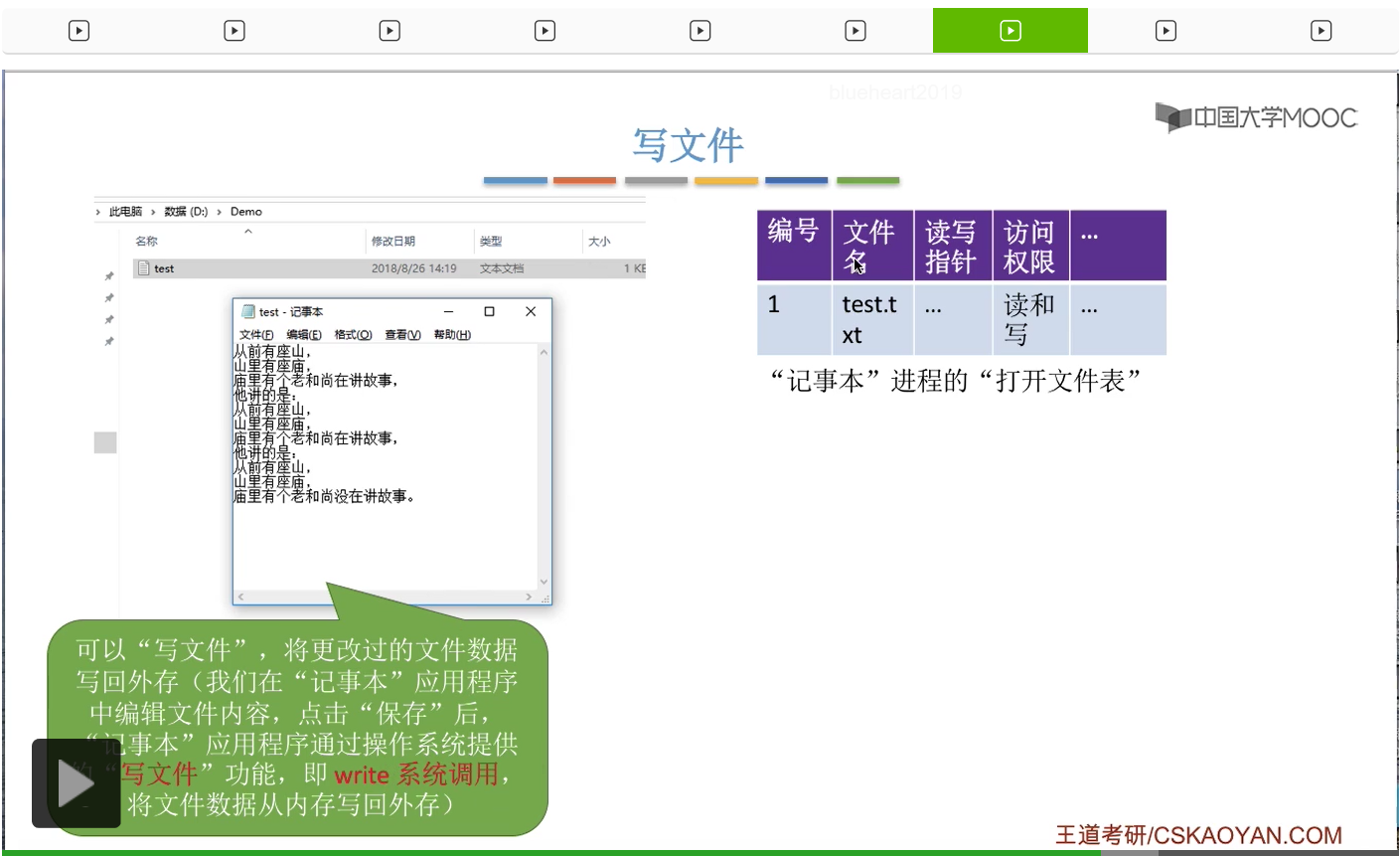
而写文件的操作其实和读文件是很类似的,在我们编辑完一个文本文档之后,我们可以点击文件保存这样一个功能,那点击保存之后其实记事本这个应用程序在背后是帮我们调用了操作系统提供的“写文件”功能,也就是write系统调用。这个系统调用的作用就是把这个文件在内存当中的数据再写回到外存,保存到外存当中。
比如说要把这个内存当中的1KB全部写回外存,那么我们指明要写回的是1KB。

那操作系统根据write系统调用的这些参数会从用户指定的这个内存区域当中,读出指定大小的那些数据,然后写回这个写指针所指向的外存区域当中。所以这是写文件要做的事情,它和读文件很类似。
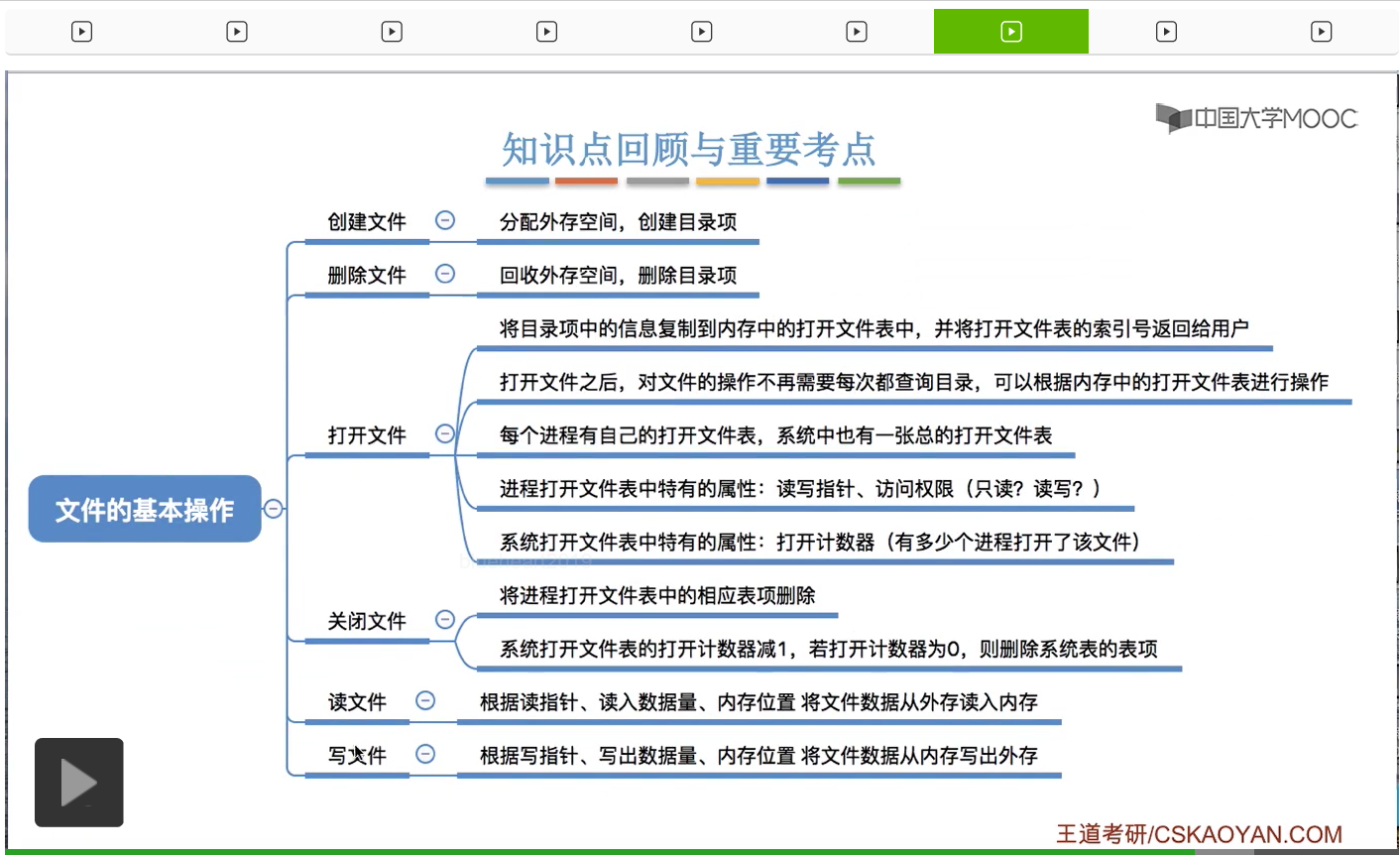
介绍了文件的几种基本操作,包括创建文件、删除文件、打开文件、关闭文件、读文件和写文件。
那我们最需要注意的是打开文件这个操作。另外大家需要知道,内存中有两种打开文件表,一种是系统的打开文件表,另外一种是进程打开文件表。系统的打开文件表当中,包含了所有的正在被使用的文件信息,而进程的打开文件表当中,只包含了这个进程本身打开了的那些文件信息。
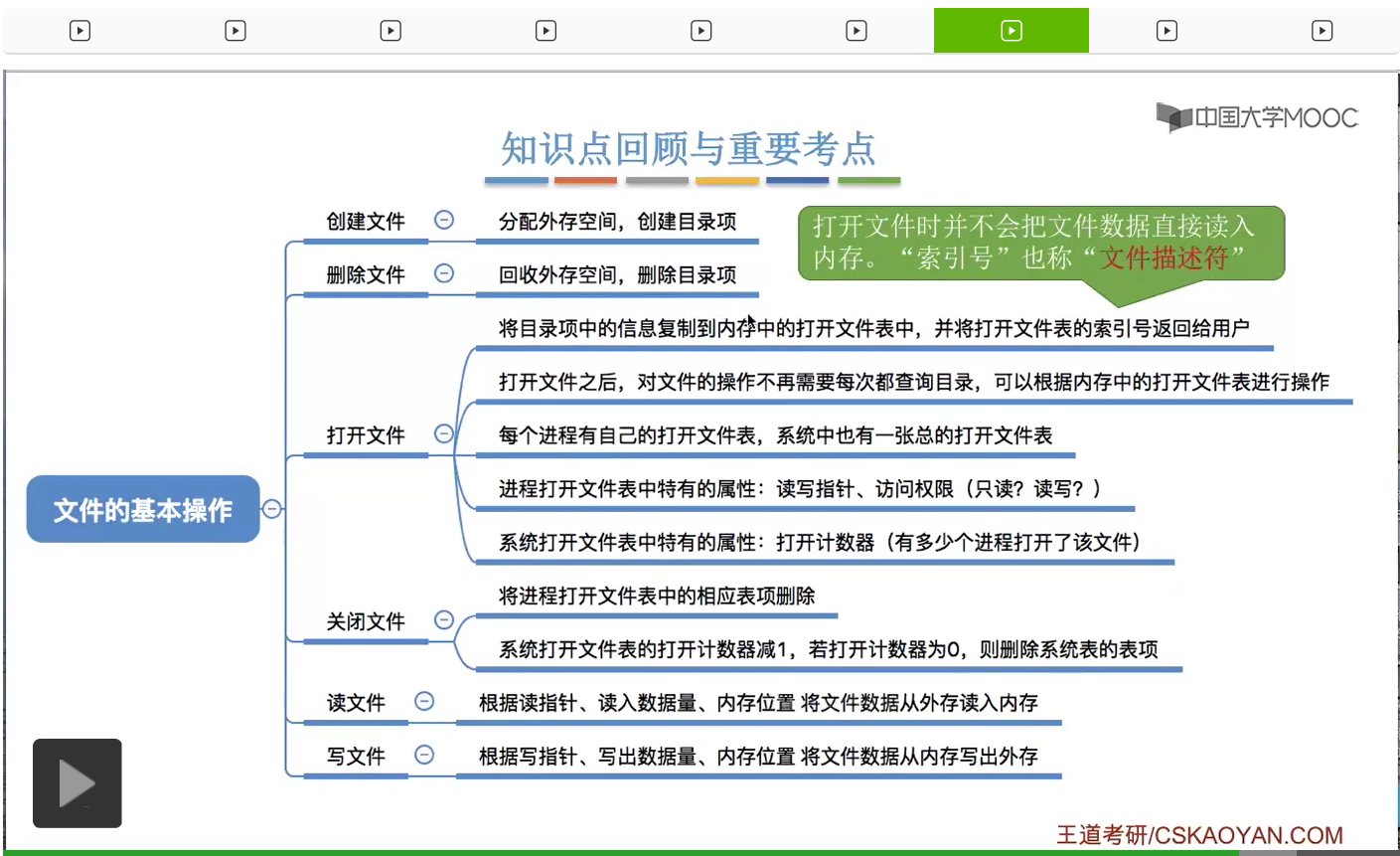
那需要注意的是,在打开文件的时候,并不会把文件的数据直接读入内存。只是把文件的目录项给复制到了内存的打开文件表当中,那这一点也是很容易混淆的一个点。另外呢,系统会把打开文件表当中的索引号返回给用户,那之后用户就可以根据这个索引号来查询打开表,然后直接操作自己的文件,而不再需要每一次都查询目录。这个地方的索引号在有的教材上也称为“文件描述符”,那这个概念在咱们的考试当中也出现过,所以“文件描述符”这个术语大家也需要注意一下。它指的其实就是打开文件表的一个序号。另外呢,大家需要注意的是,在进程的打开文件表和系统的打开文件表当中,都会有一些各自特有的属性。而一个文件总共被多少个进程打开了,这个数据肯定是需要放在系统的打开文件表当中。
那比较容易和打开文件混淆的是读文件这个操作。只有读文件的时候,才会把文件的数据真正地从外存读入内存。

而对文件进行读写操作的时候,用户不需要再提供文件名、文件路径这些信息,只需要提供文件描述符也就是这个文件在打开文件表当中的索引号,操作系统就可以知道我们要读要写的到底是哪个文件了。那打开文件和读文件这两个操作是最容易在选择题当中进行考查的,大家需要重点关注。
操作系统应该怎么实现文件共享的功能。


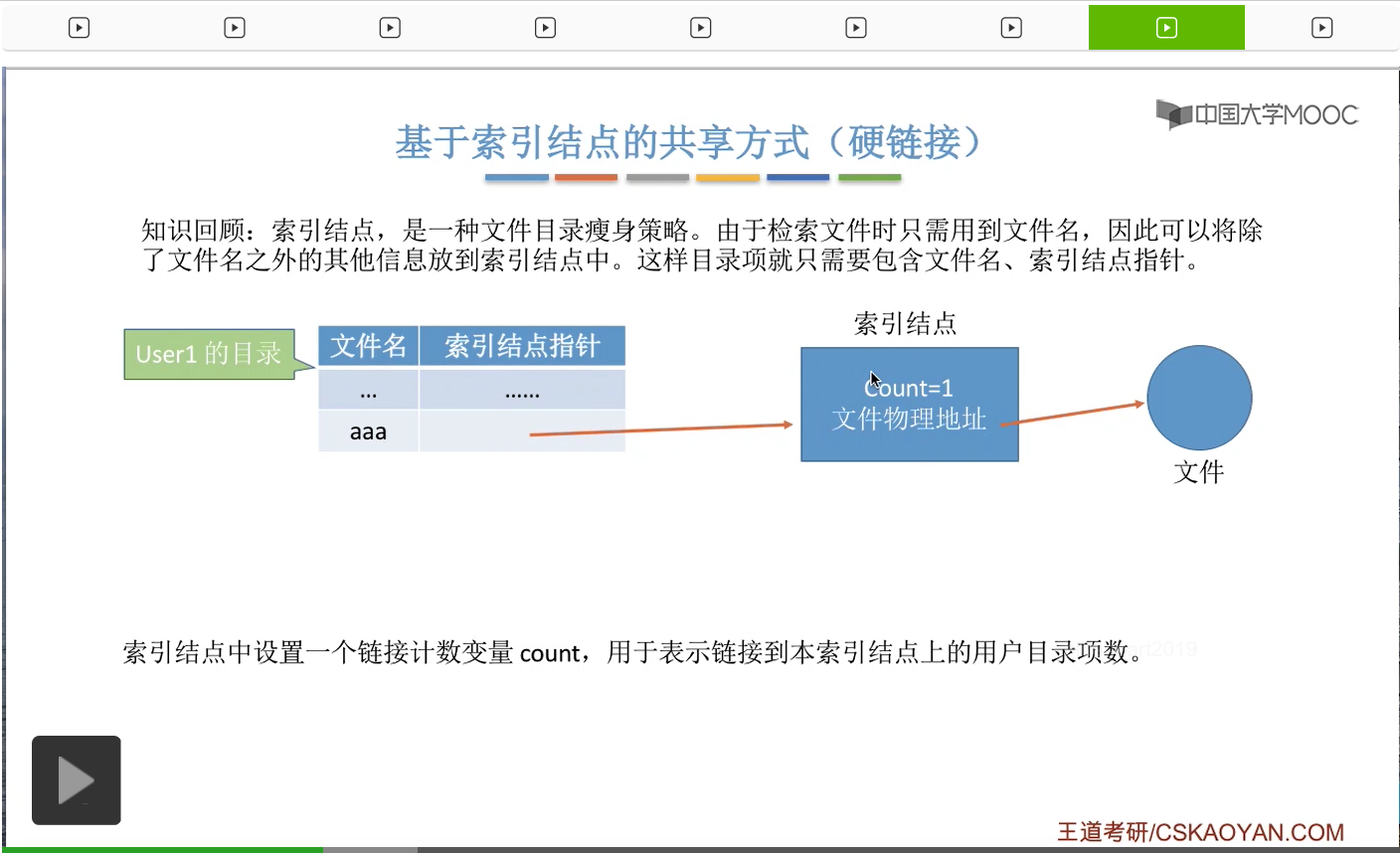
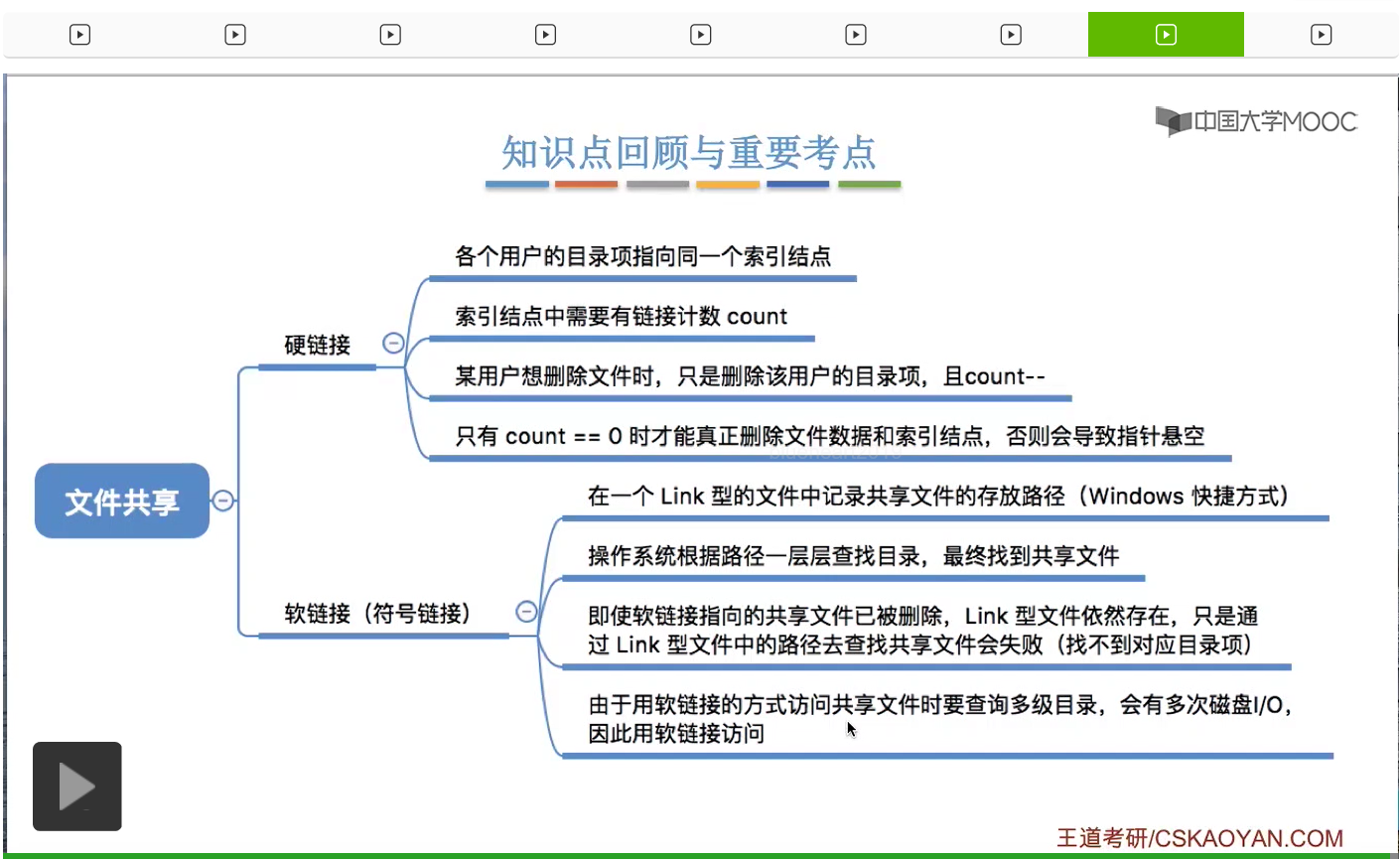
那接下来我们来介绍实现共享的第一种方式,也就是基于索引结点的共享方式,硬链接的方式。

那采用索引结点的这种策略能够带来什么好处呢?假设此时有一个用户User1他创建了一个新的文件叫做aaa,那么这个文件会对应一个索引结点,并且这个索引结点当中会会包含这个文件的物理地址啊还有这个文件相关的其他的一些属性也是包含在索引结点当中的。
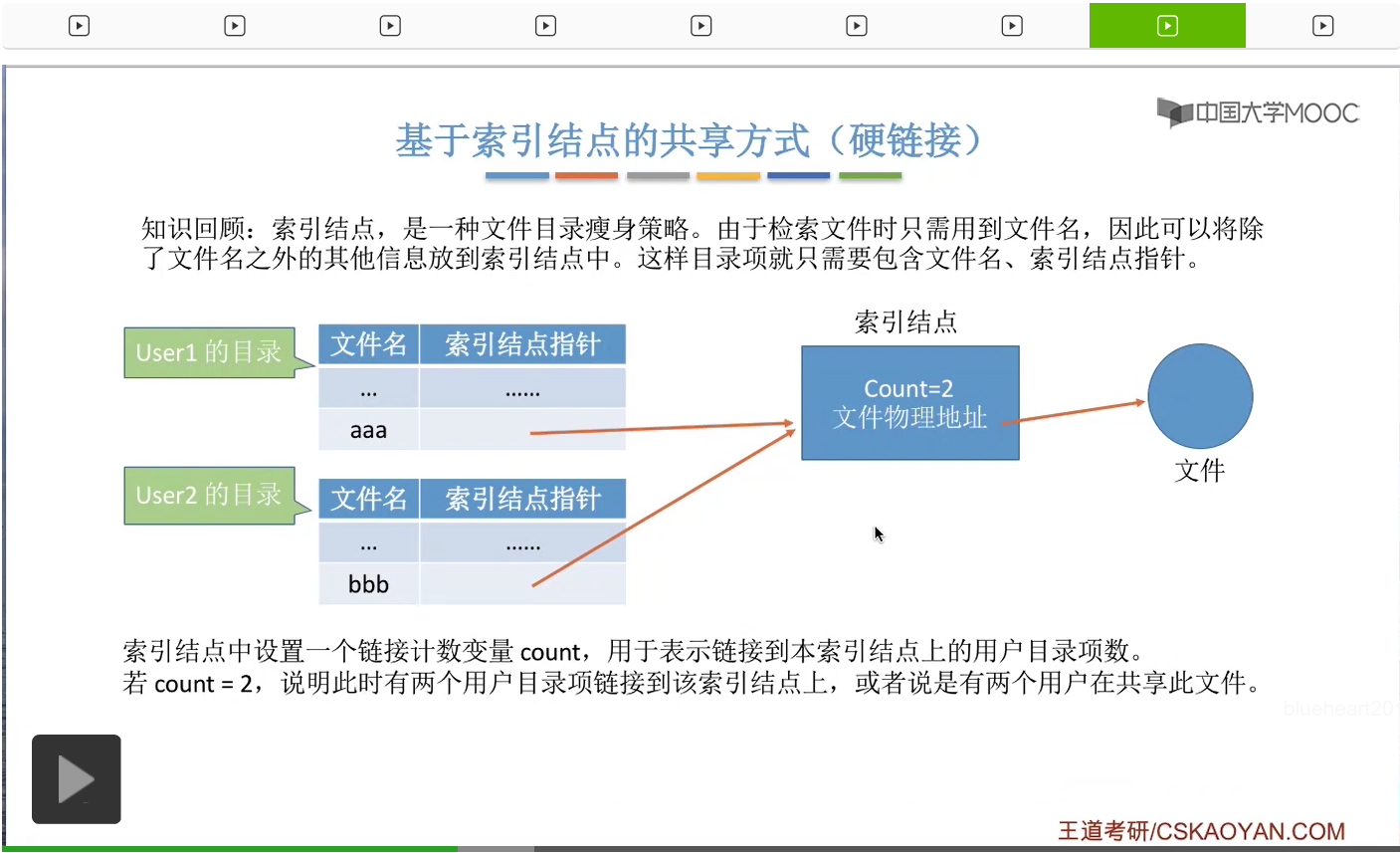
假设此时有第二个用户User2,他想共享地使用这个文件,那么这个用户的目录当中,也会有一个目录项是指向这个文件的索引结点的。那由于此时有两个目录项是指向这个索引结点的,所以这个Count的值应该加1。
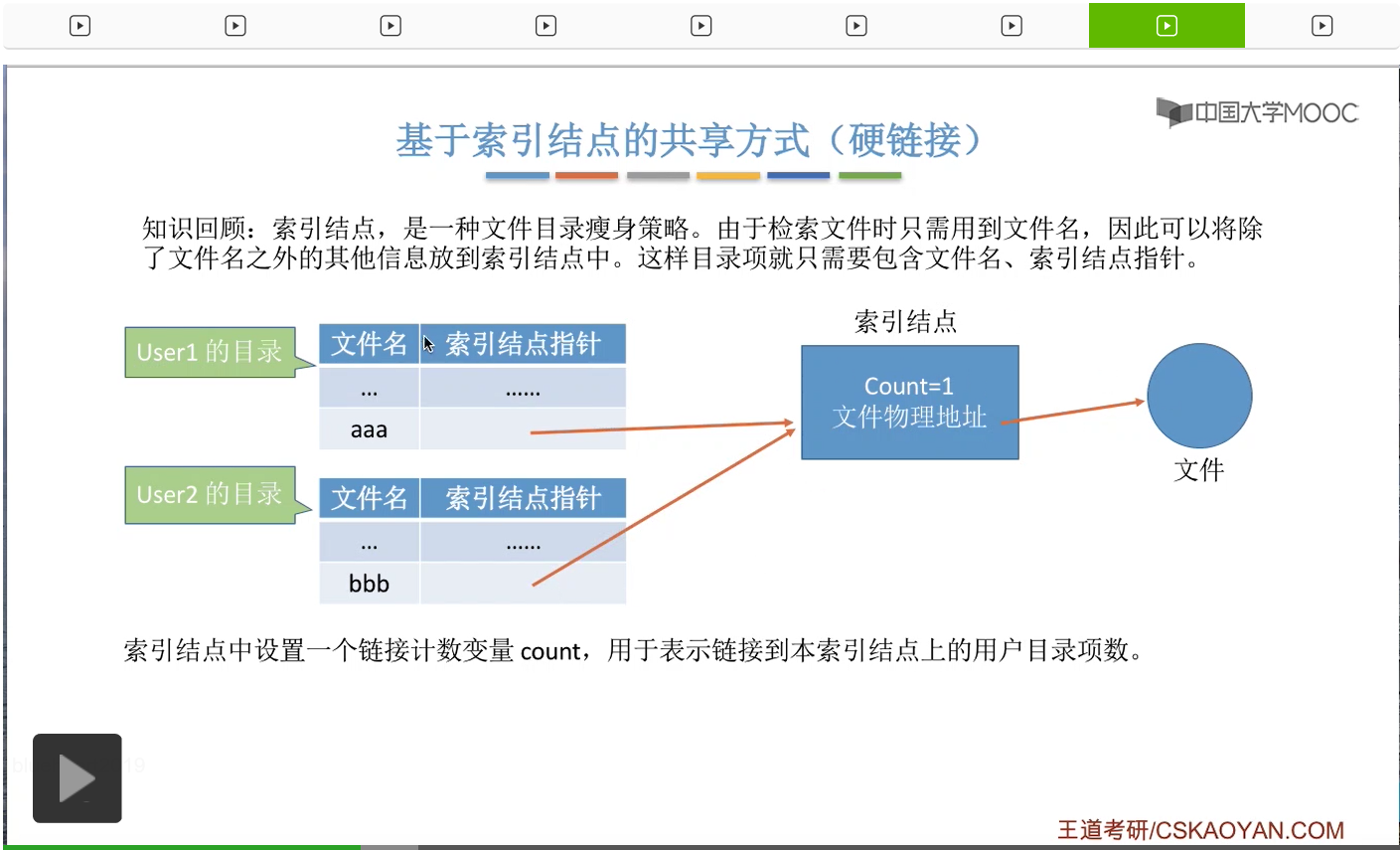
也就是变成2。Count=2也就说明此时有两个用户正在共享地使用这个文件。那这就是基于索引结点的共享方式,就是要让不同用户的目录项指向同一个文件的索引结点。并且在这个地方大家会发现,不同用户对于这个文件起的名字其实是可以不同的。在用户1的目录下,这个文件名叫aaa,而用户2的目录下这个文件名叫bbb。
那如果说采用的是这种共享方式的话,在删除文件的时候需要注意一些小细节。如果一个用户决定删除这个文件,那么其实系统在背后做的
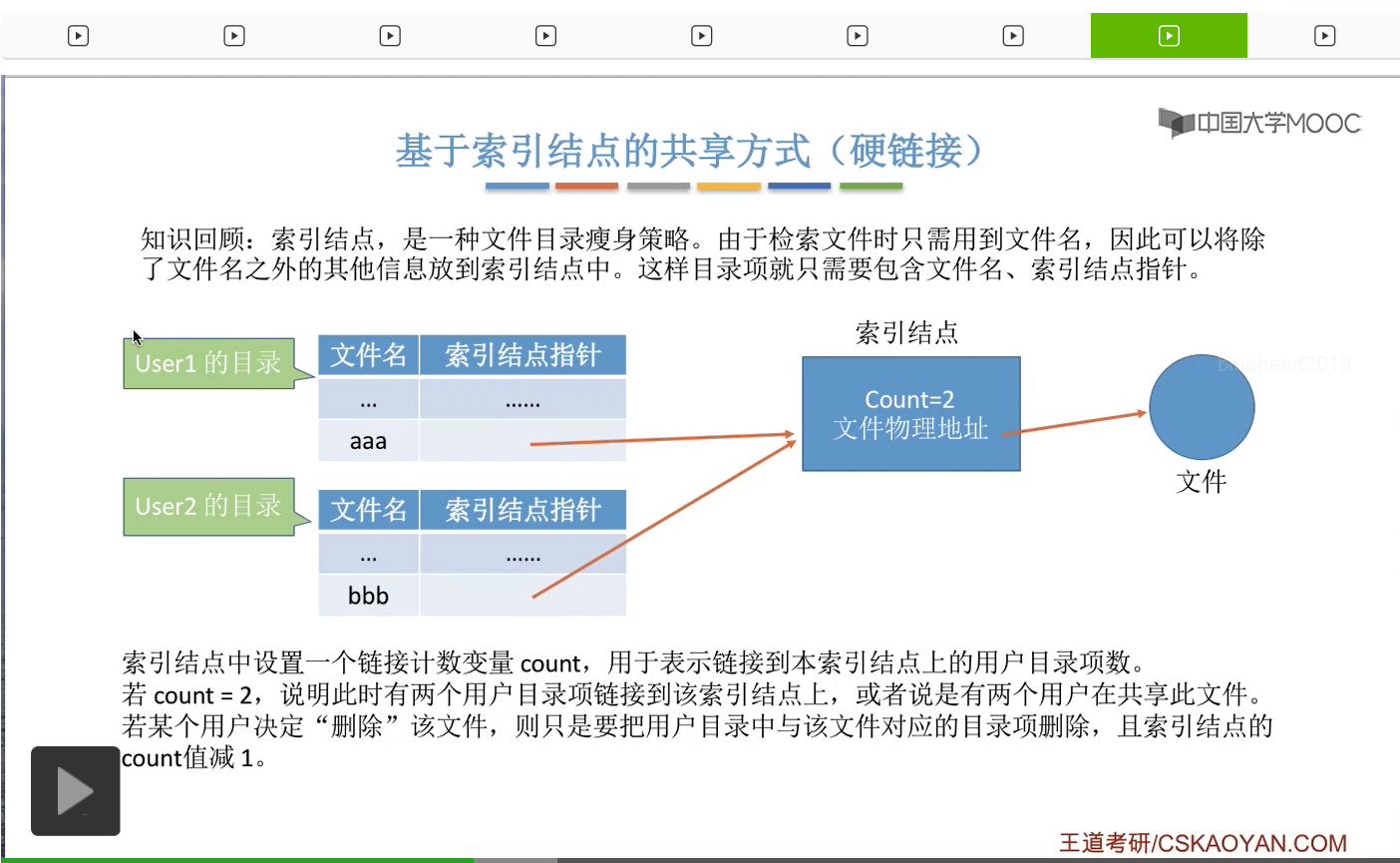
只是删除了这个用户对应的这个文件的目录项,然后把这个链接给断掉。
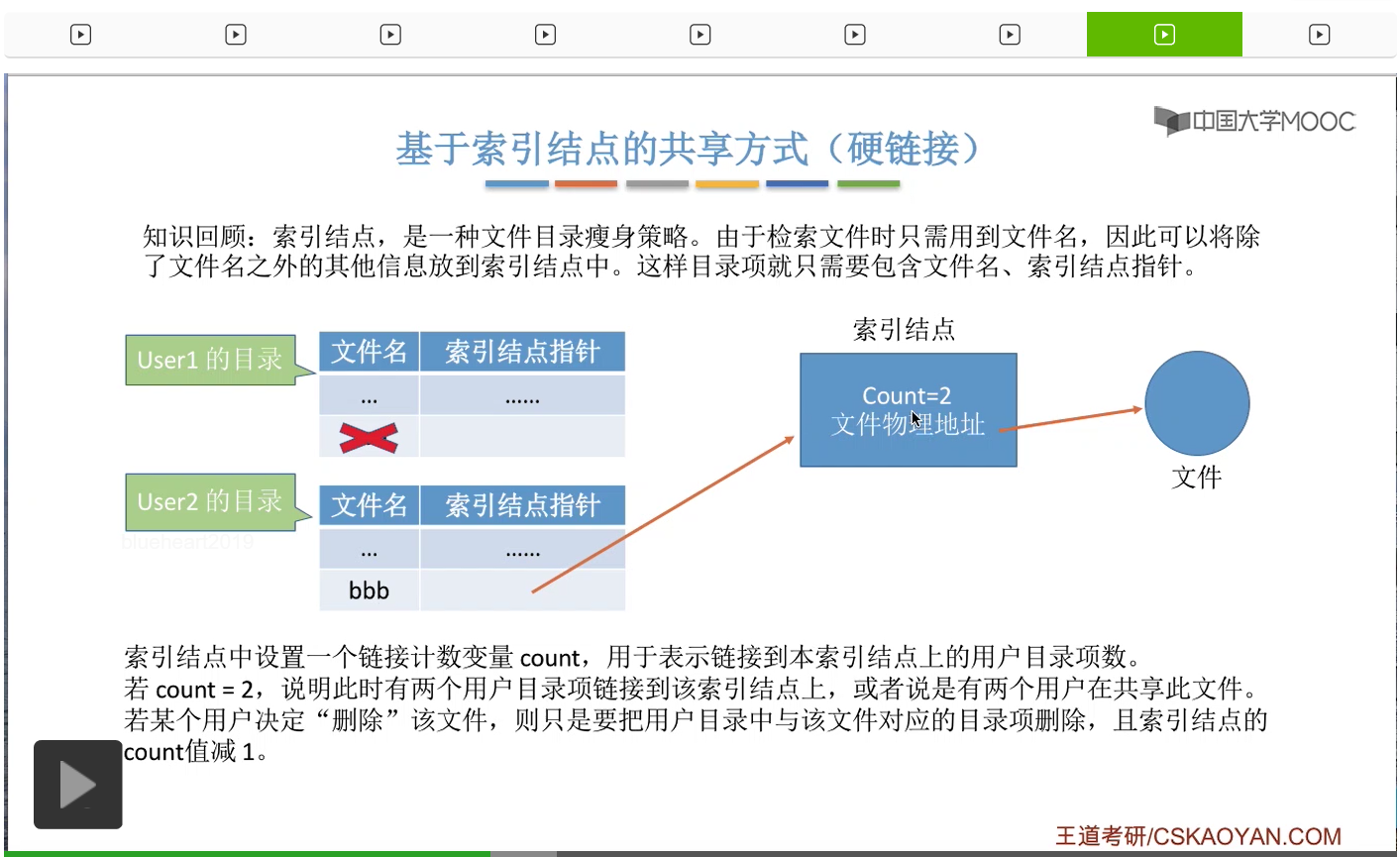
那相应的索引结点的Count值也需要减1。
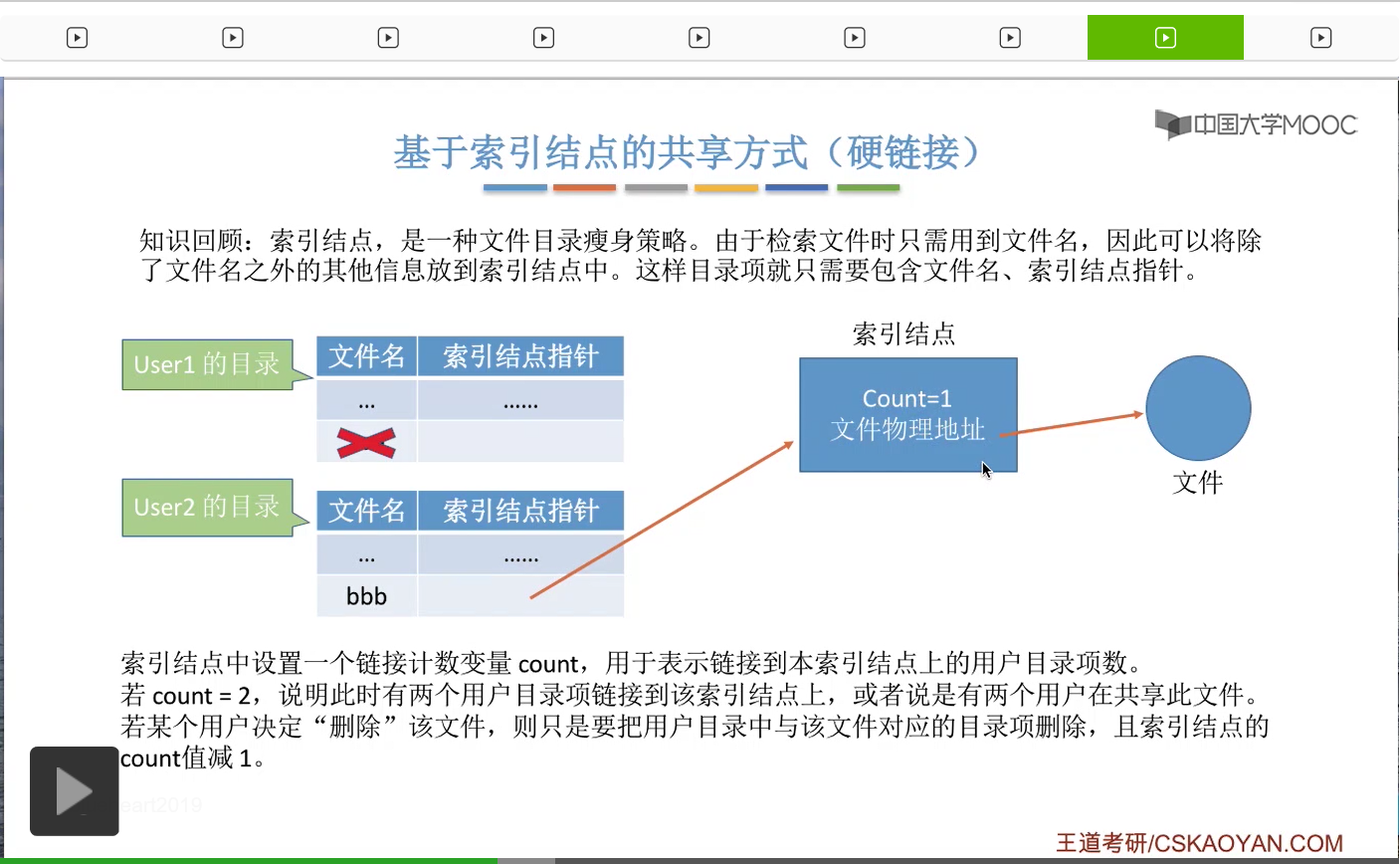
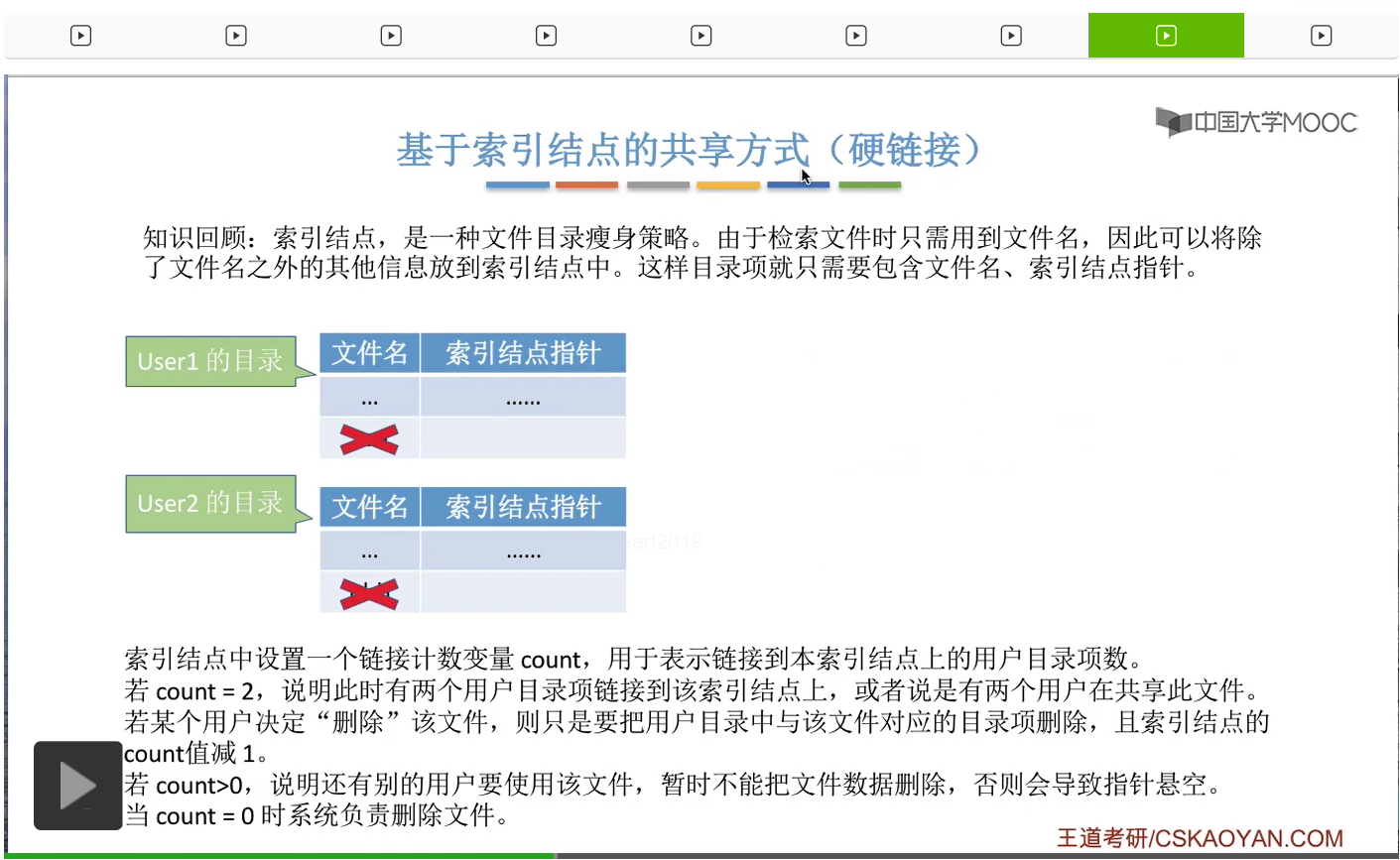
不过由于此时Count的值是大于0的,说明此时还有别的用户正在使用这个文件。因此并不可以直接把这个文件的数据给干掉。


那除非这个Count值变为了0的时候,这个文件还有它的索引结点

这些数据才可以真正地从系统当中删除。所以这是硬链接的共享方式当中在删除文件的时候需要注意的一个细节。
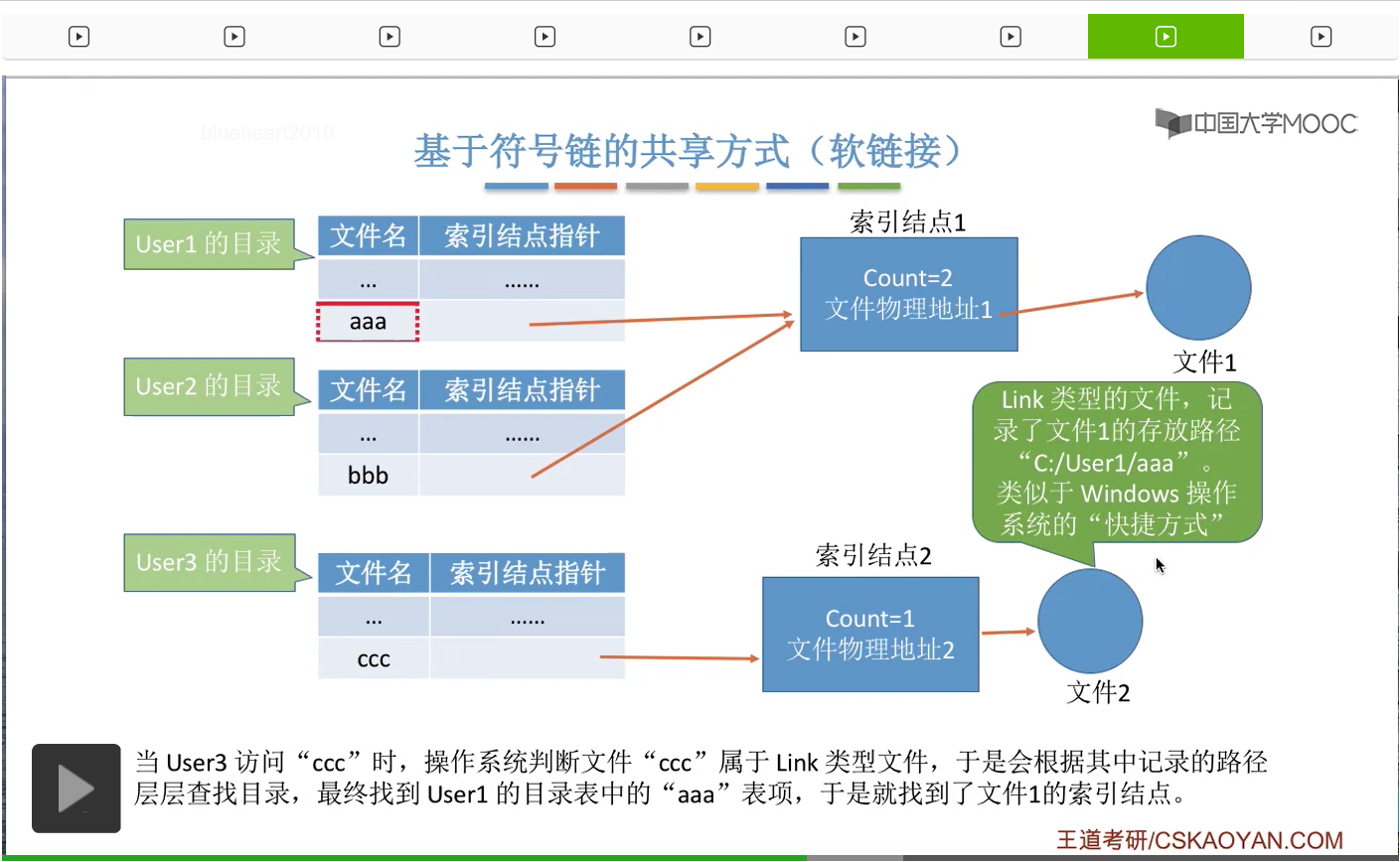
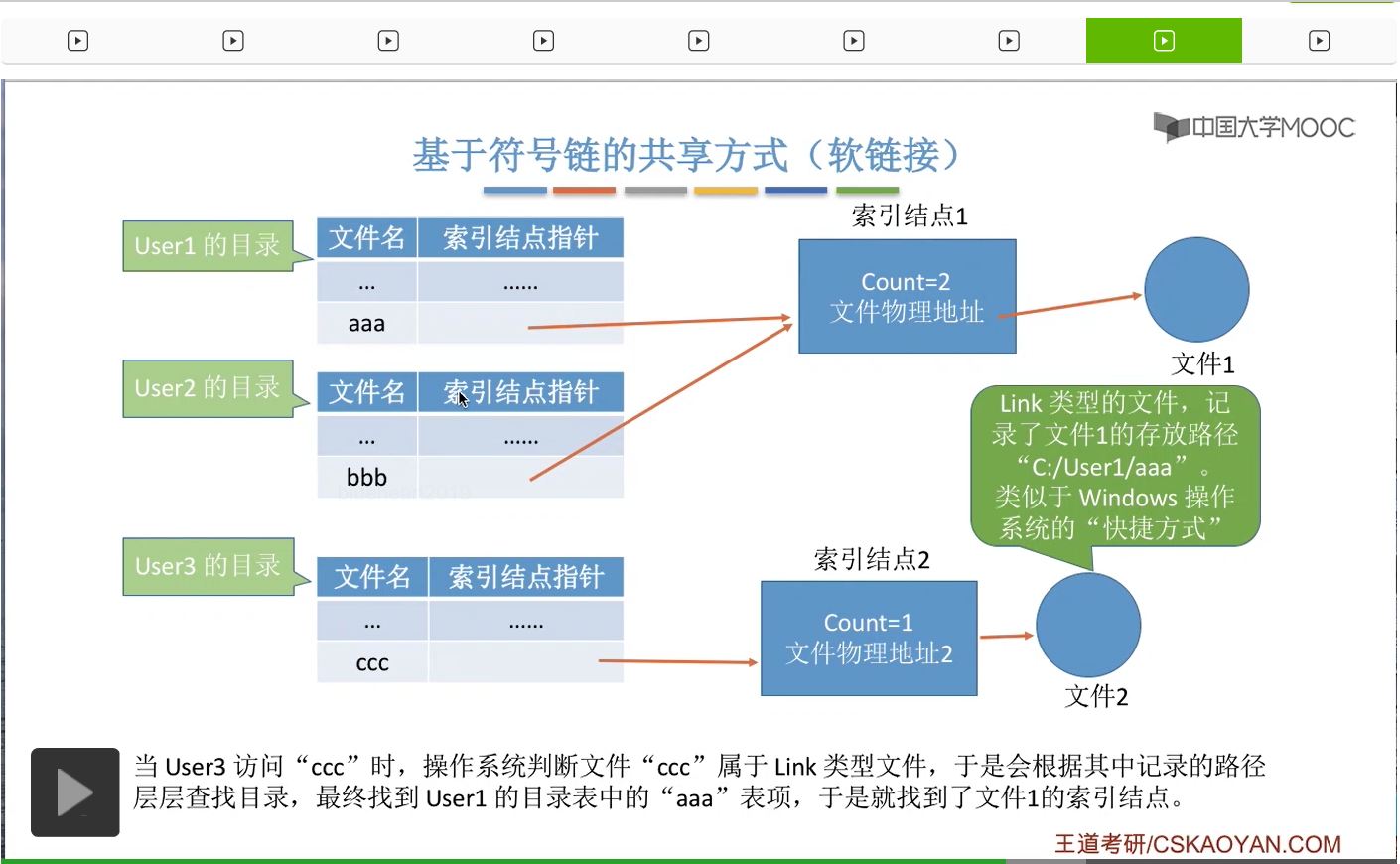
那接下来我们来看第二种,基于符号链的这种共享方式,又叫软链接的共享方式。
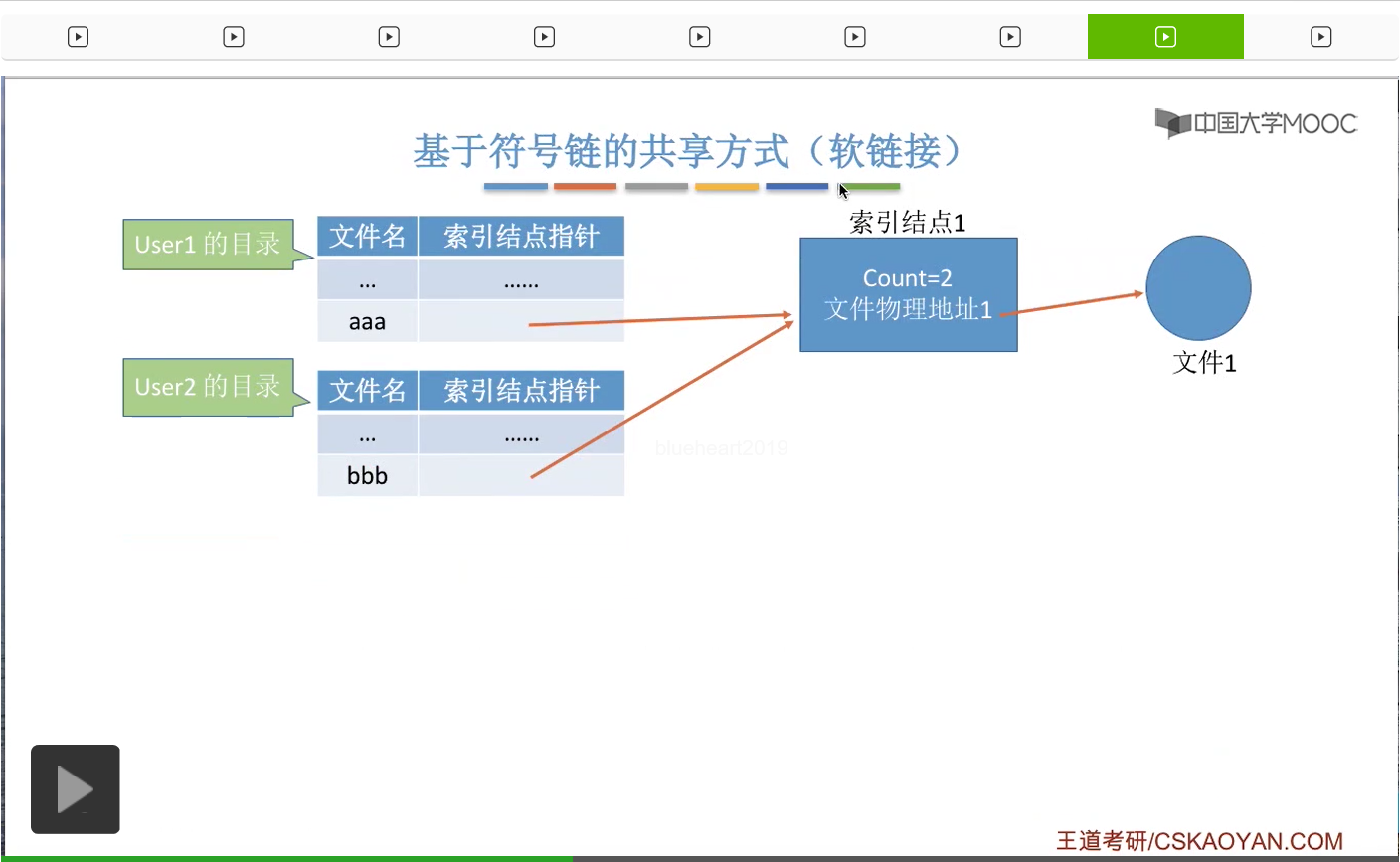
假设此时系统当中有两个用户User1和User2正在使用硬链接的方式在共享地使用文件1。

而另一个用户User3想要使用软链接的方式来共享这个文件1。那么User3会建立一个新的文件,
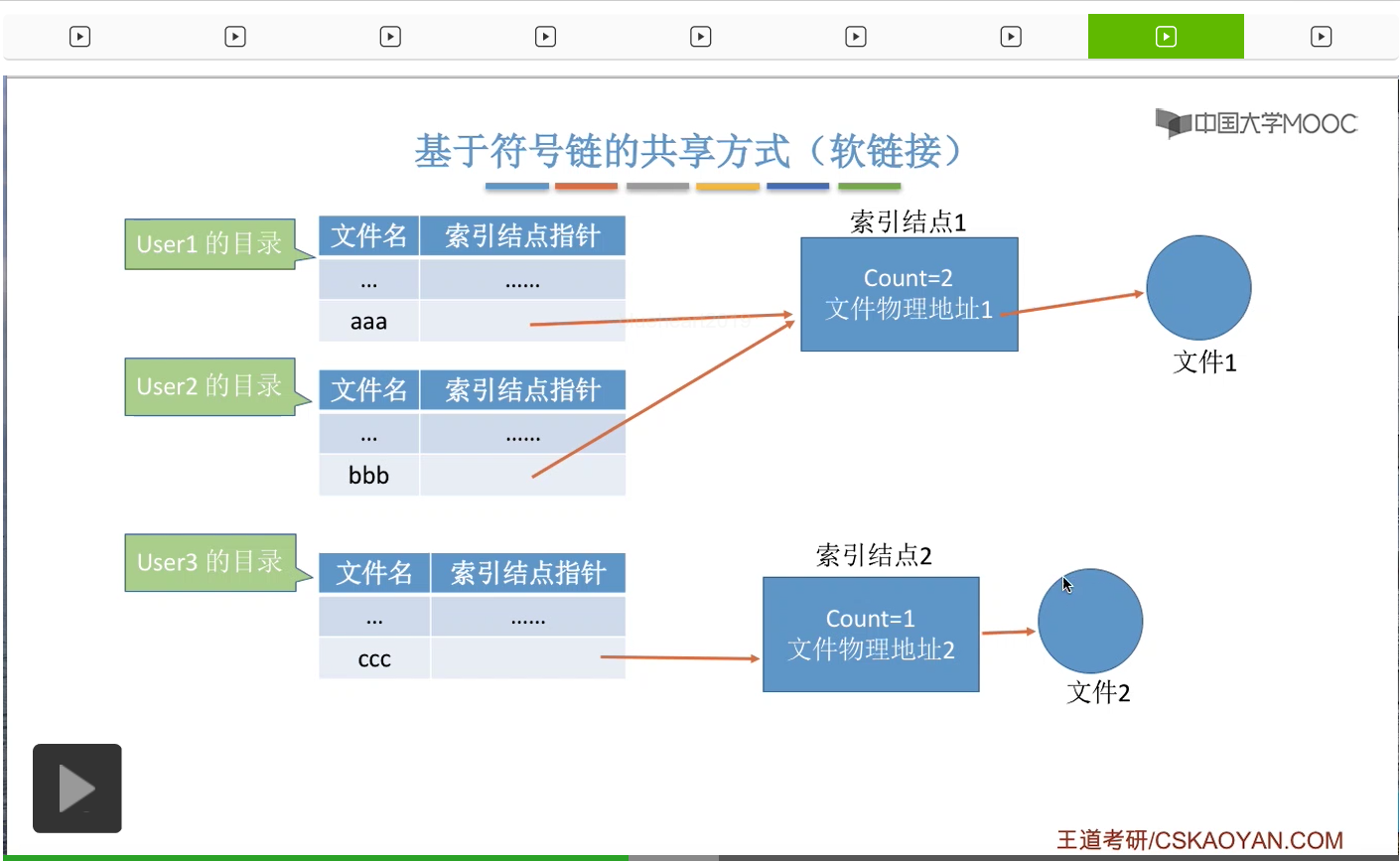
这个文件是一种特殊的Link型的文件。这个文件记录了文件1的存放路径,
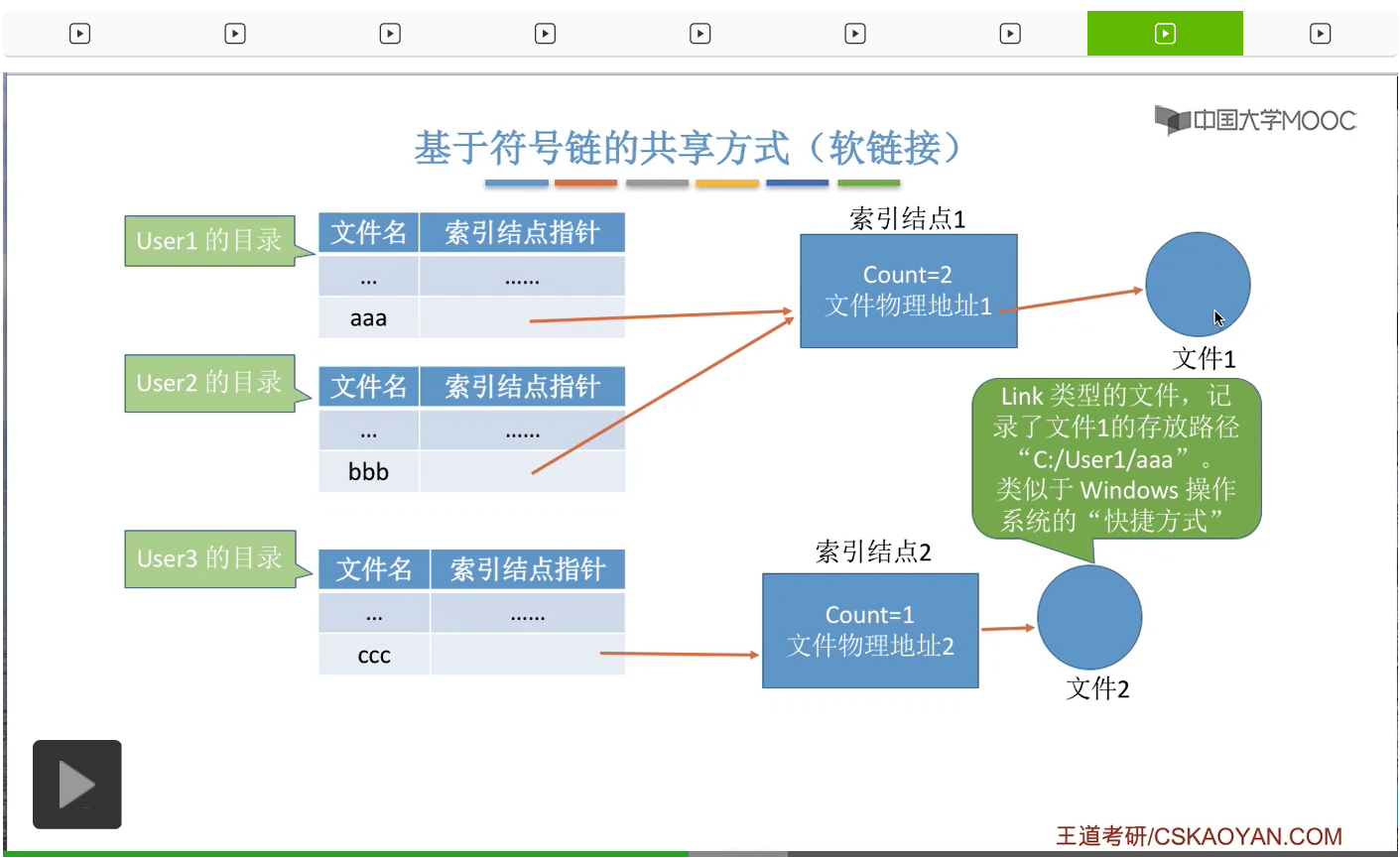
那其实这种Link类型的文件就有点类似于Windows操作系统当中的快捷方式,那User3想要访问“ccc”这个文件的时候,操作系统首先是判断“ccc”它属于Link类型的文件,于是会根据这个文件当中记录的这个路径的信息一层一层地来查找目录,然后最终找到“aaa”这个目录项,于是就可以开始访问文件1了。因此,如果采用的是软链接的共享方式的话,那并不是把自己的目录项直接指向这个文件的索引结点,而是创建了一个新的Link型的文件,然后Link型的文件当中记录了这个文件的存放路径,之后操作系统会根据这个路径来找到想要共享的那个文件。
那我们来看一下Windows操作系统当中快捷方式的例子。
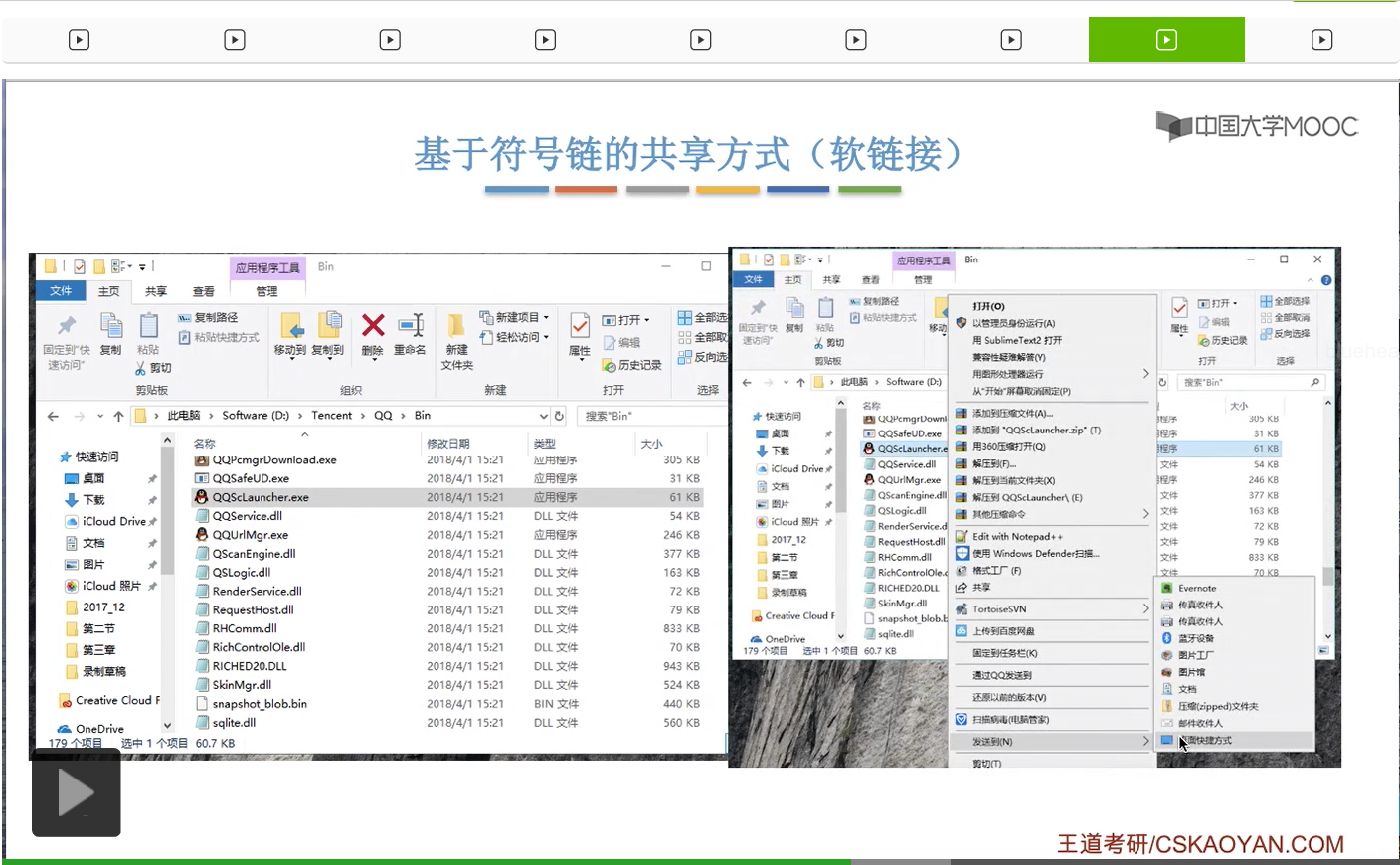
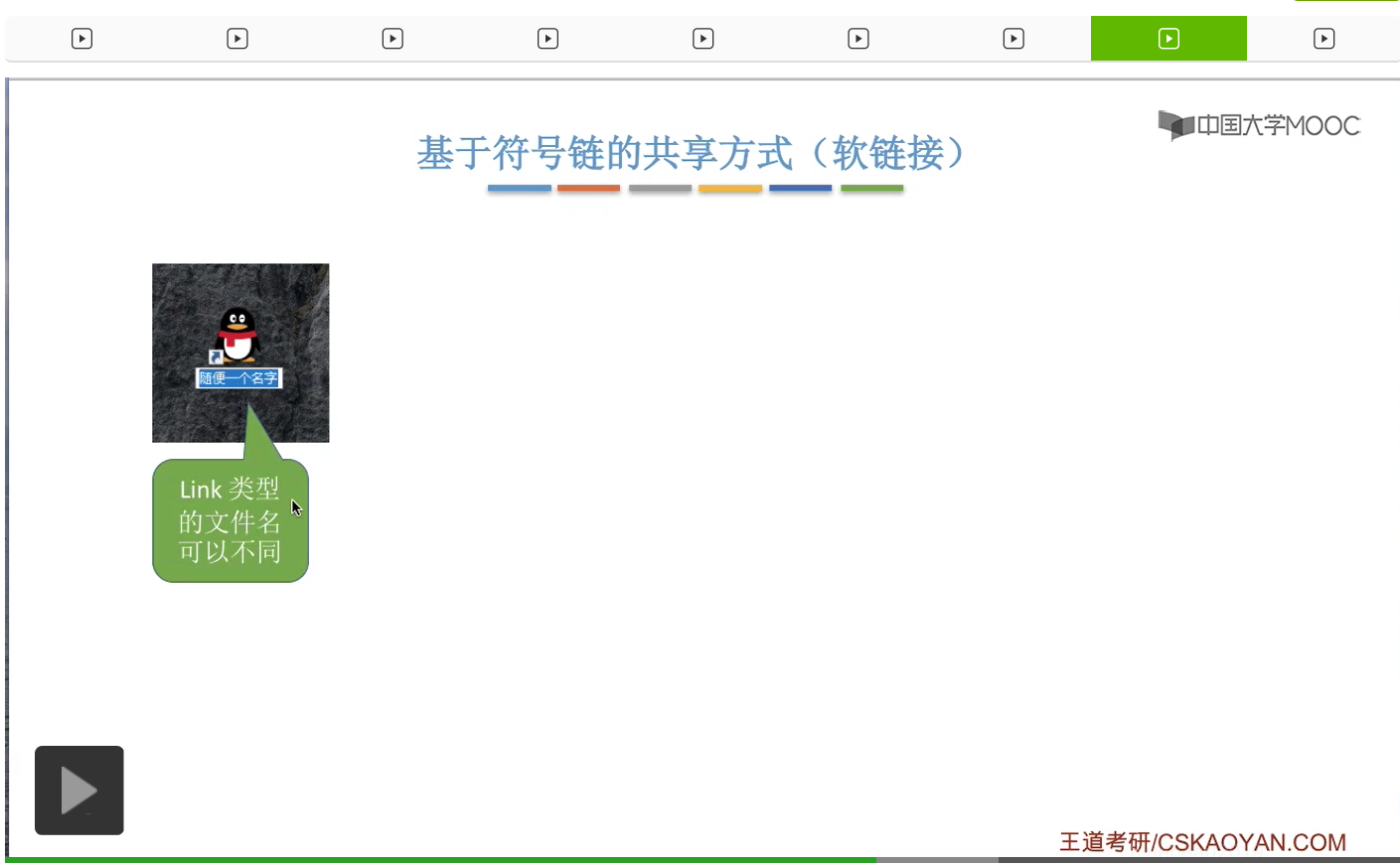
这个快捷方式其实就是用软链接,也就是用一个路径的方式把它链接到了QQ的那个启动程序那个地方。


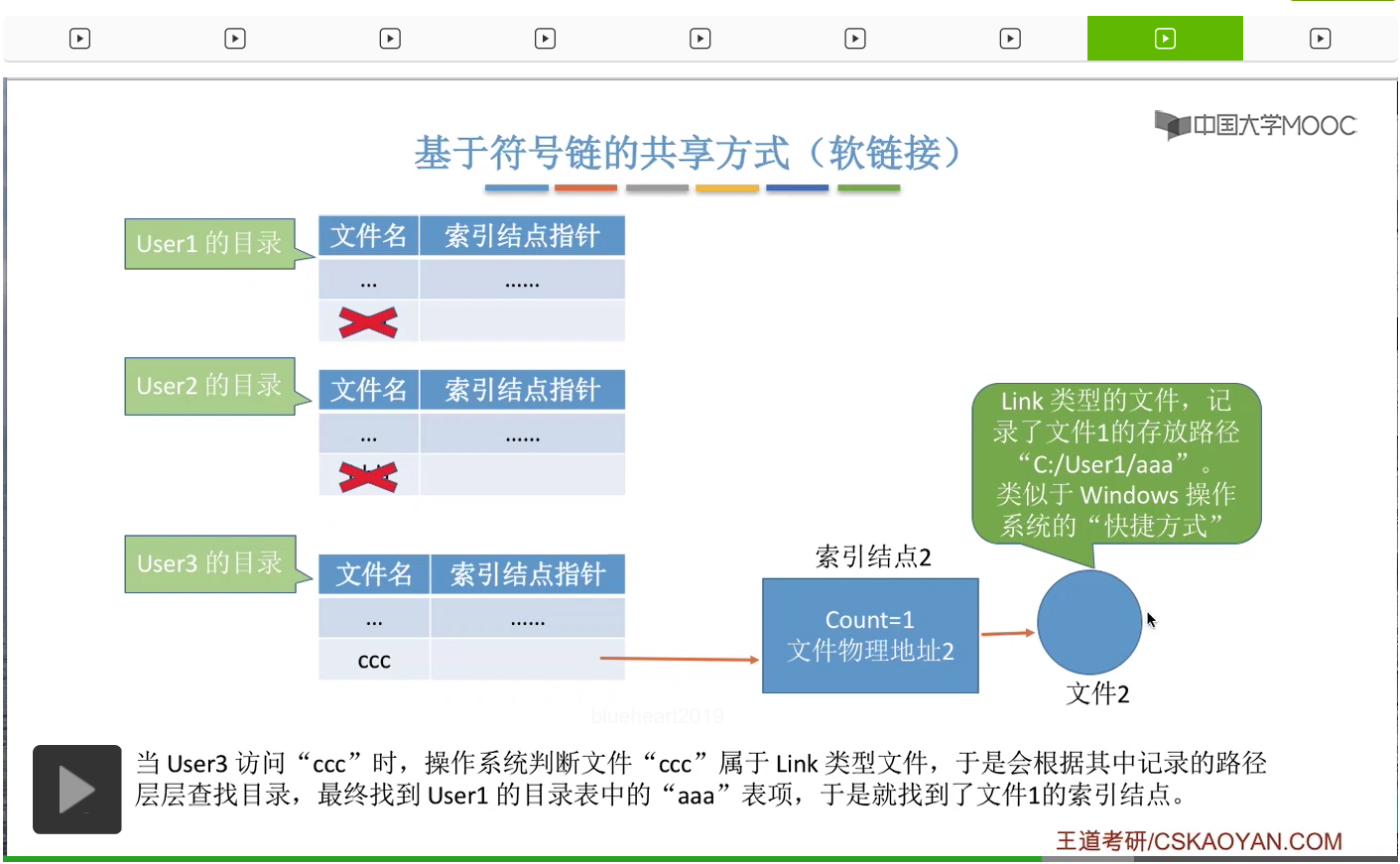
那接下来我们再分析一下,如果采用软链接的方式共享文件的话,删除一个文件会不会对软链接造成什么影响呢?
假设此时User2和User1都不再需要使用文件1,那由于此时这个Count值变为了0,

因此这个文件还有它的索引结点就可以直接被干掉了。
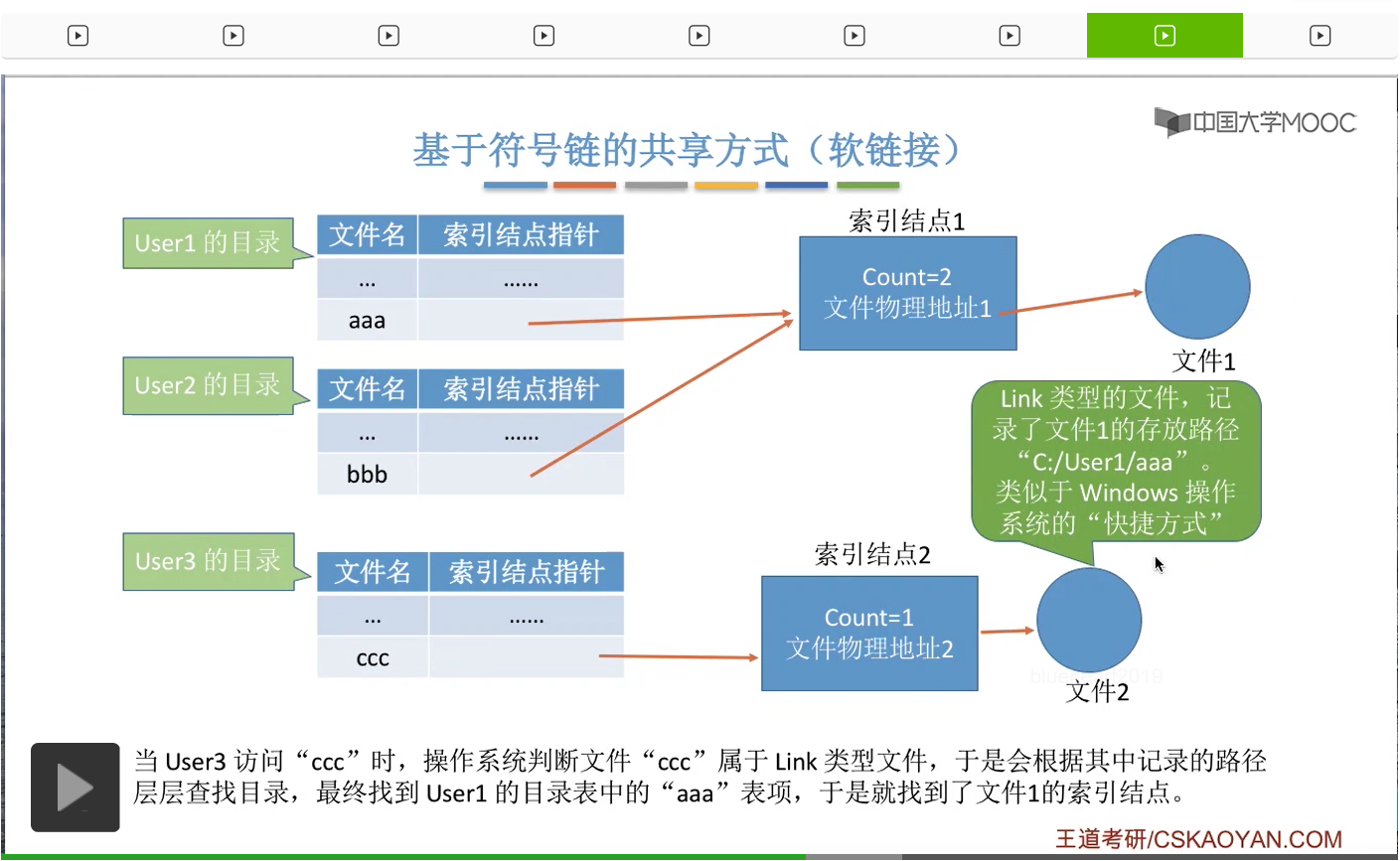
那此时如果User3访问ccc这个Link型的文件,那同样的,操作系统首先会检查C盘下面的User这个目录,然后尝试从中找到aaa这个文件对应的目录项。

但是由于此时aaa这个目录项已经被删除了,所以通过这个路径其实已经找不到文件1了,因此这个软链接就失效了。
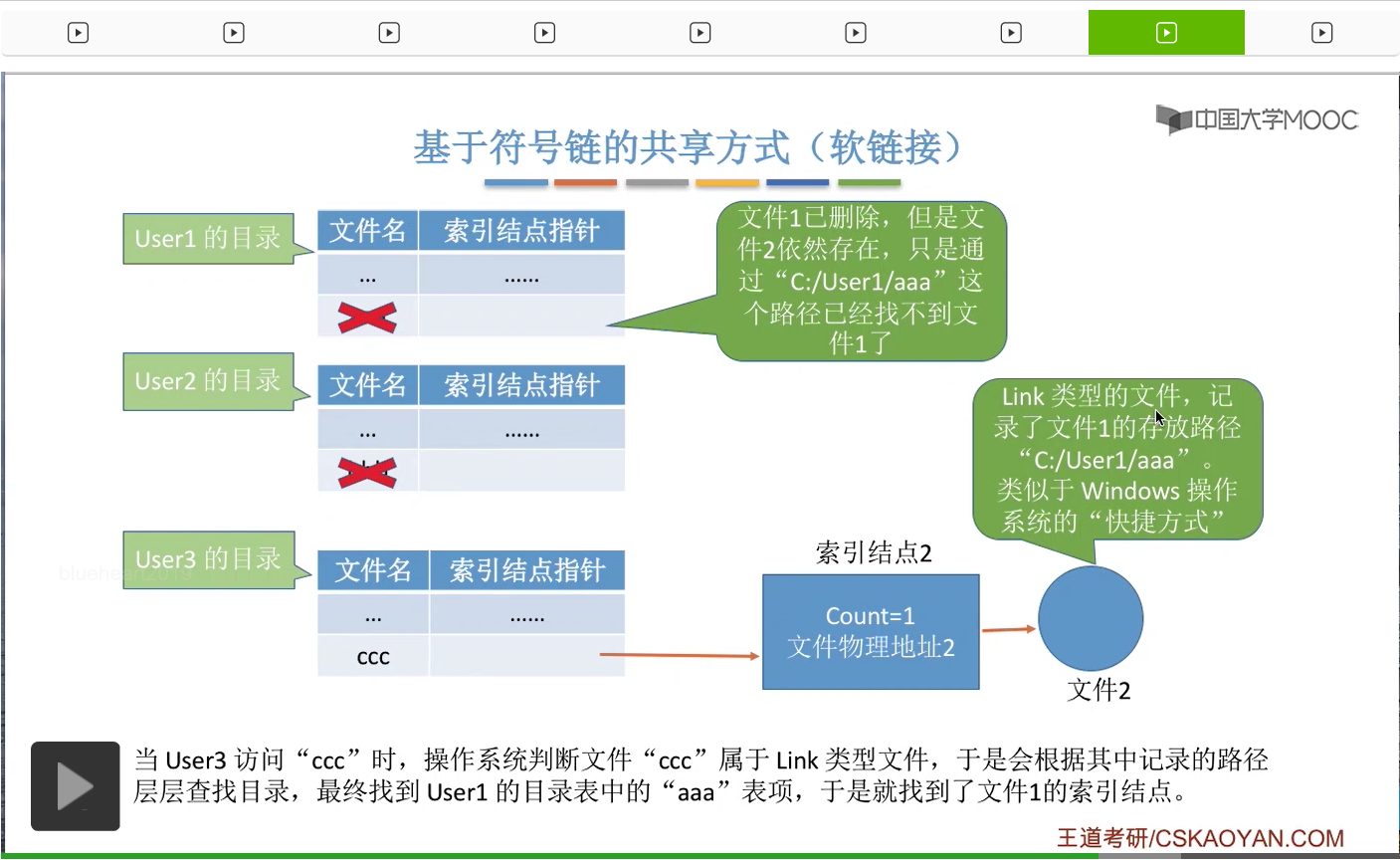
那我们还是结合Windows操作系统为例。也就是说通过这个软链接当中记录的路径已经找不到这个文件了,这个文件已经被删除了。因为这个文件名对应的目录项已经没了。
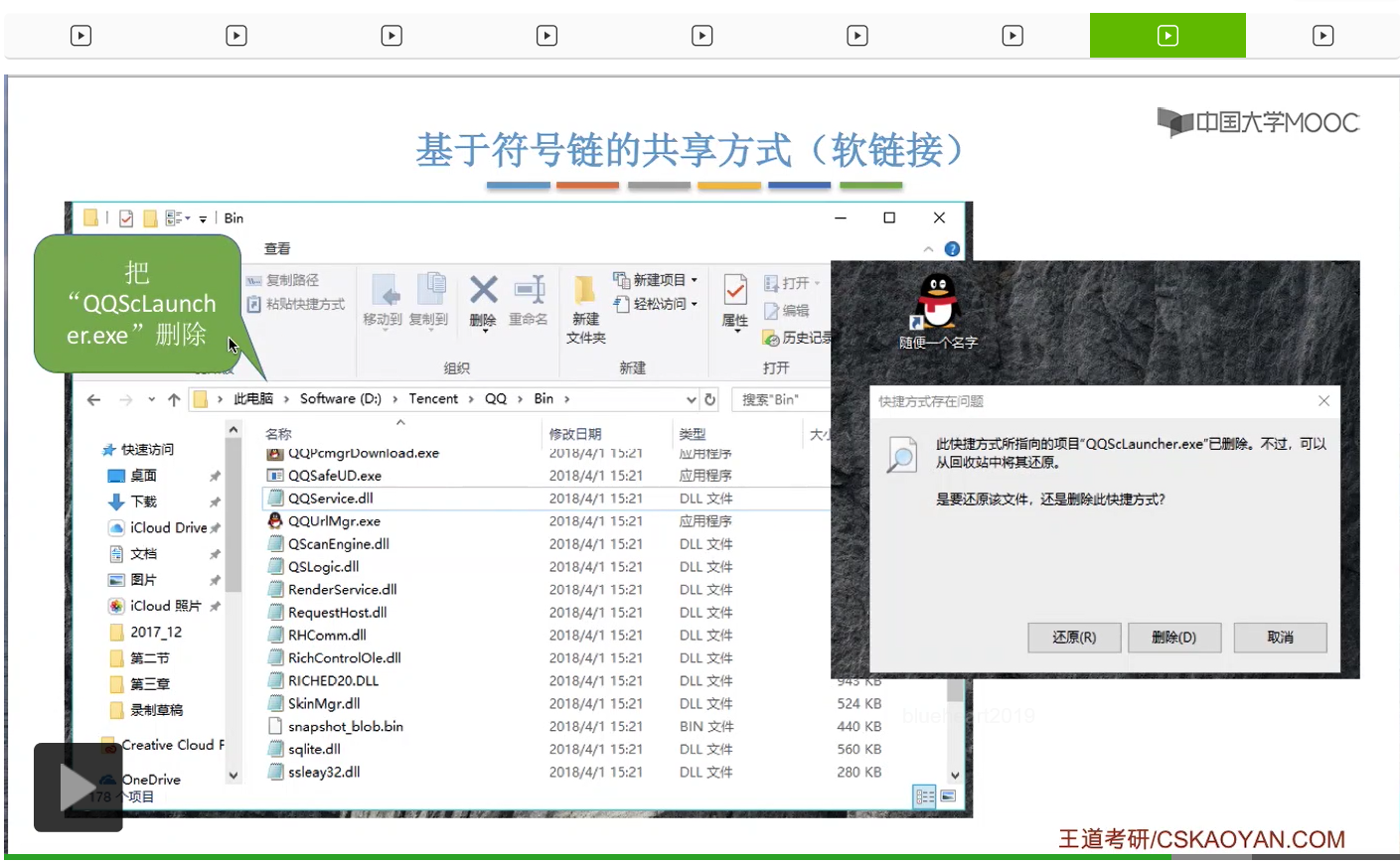
好的那么这就是硬链接和软链接这两种文件共享方式。那大家需要重点理解的是,硬链接这种共享方式在删除文件的时候需要注意的一些事情。只有Count的值变为0的时候才可以真正删除文件的数据还有文件的索引结点,否则会导致指针悬空的情况。而软链接或者叫符号链接的这种共享方式,大家只需要自己回去玩一下自己的Windows操作系统的快捷方式其实就可以理解了。它无非就是在Link型文件当中记录了我们要共享的那个文件存放的路径到底是什么,然后操作系统会根据这个路径一层一层地查找目录,最终就可以找到需要共享的文件。不过需要注意的是,如果软链接所指向的那个共享文件已经被删除的话,那么这个Link型的文件其实依然是存在的。只不过通过这个文件当中记录的路径,再去查找那个共享文件的时候就会发现查找失败的情况,因为此时已经找不到那个共享文件所对应的目录项了。另外由于软链接这种方式每一次在访问共享文件的时候,都需要一层一层地去查询目录。那通过之前的讲解大家也知道,在一层一层地查询目录的这个过程当中,其实是需要磁盘的I/O操作的。因此通过软链接的方式去访问一个共享文件的速度是会比硬链接要更慢。
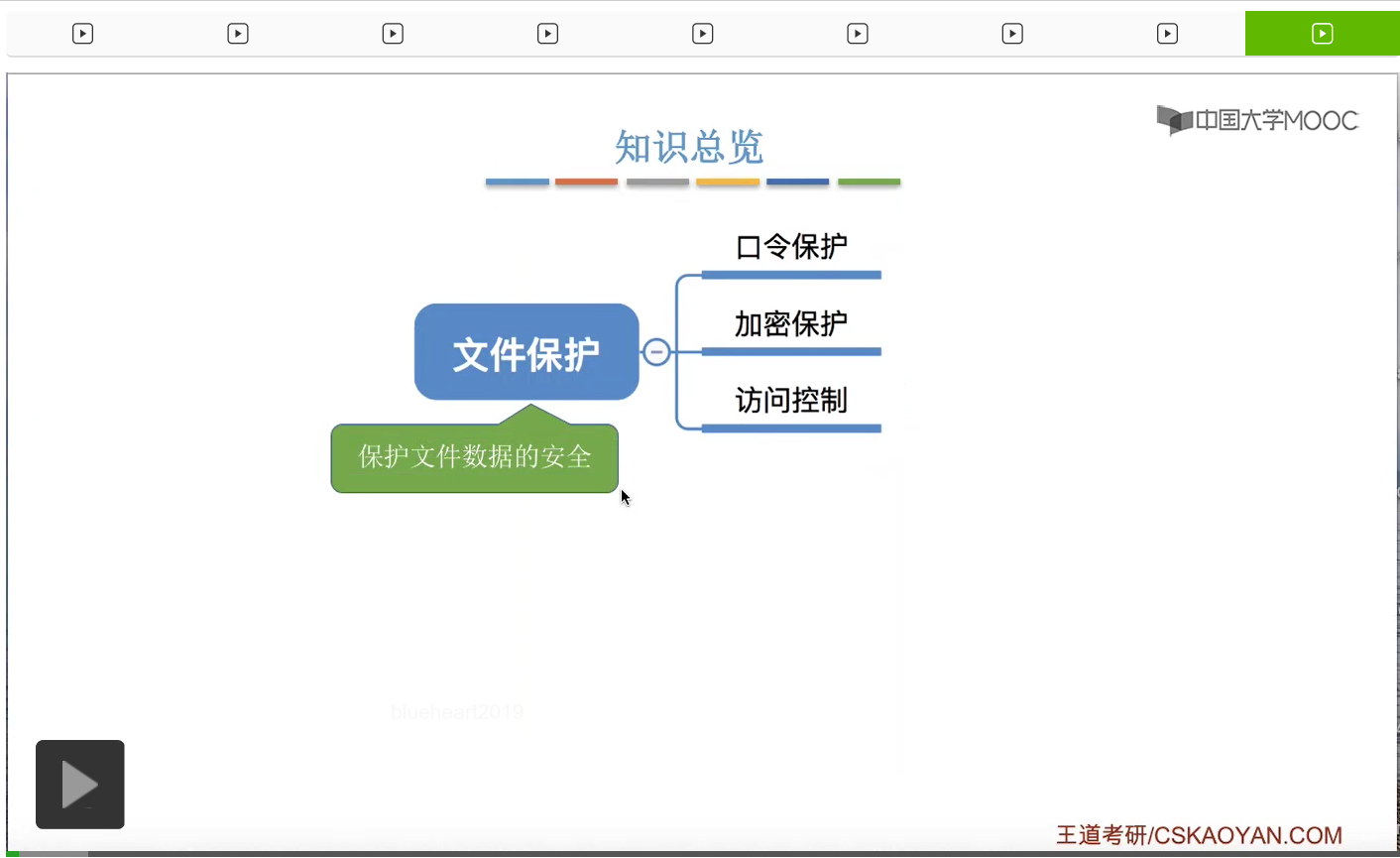
学习文件保护相关的知识点。

那操作系统需要保护文件数据的安全,那一般来说可以采用这样的三种方法——口令保护、加密保护和访问控制。那我们会按从上至下的顺序依次来学习。
比如说一个用户为自己的文件设置了一个口令,这个口令是abc112233。那其他的用户想要访问这个文件的时候就必须提供这个相同的口令。那操作系统会负责验证这个用户提供的口令是否正确。那一般来说这个正确的口令是存放在与文件相对应的FCB或者索引结点当中的。所以,操作系统会从FCB当中读出正确的口令,并且和用户提供的这个口令进行对比,如果这个口令正确那么就允许这个用户访问文件。

所以这种文件保护方式的优点就是开销小。首先是保存这个口令带来的空间花销是很小的,也就是保存这样一个字符串。另外当一个用户想要访问一个文件的时候,那操作系统无论如何肯定是要找到这个文件对应的FCB或者索引结点的。那从FCB或者索引结点当中取出这个口令,并且进行对比其实是不需要花太多的时间的。因此,验证口令的时间开销也会比较小。


那第二种方式是加密保护。学过计组的话大家对异或运算应该是很熟悉的。



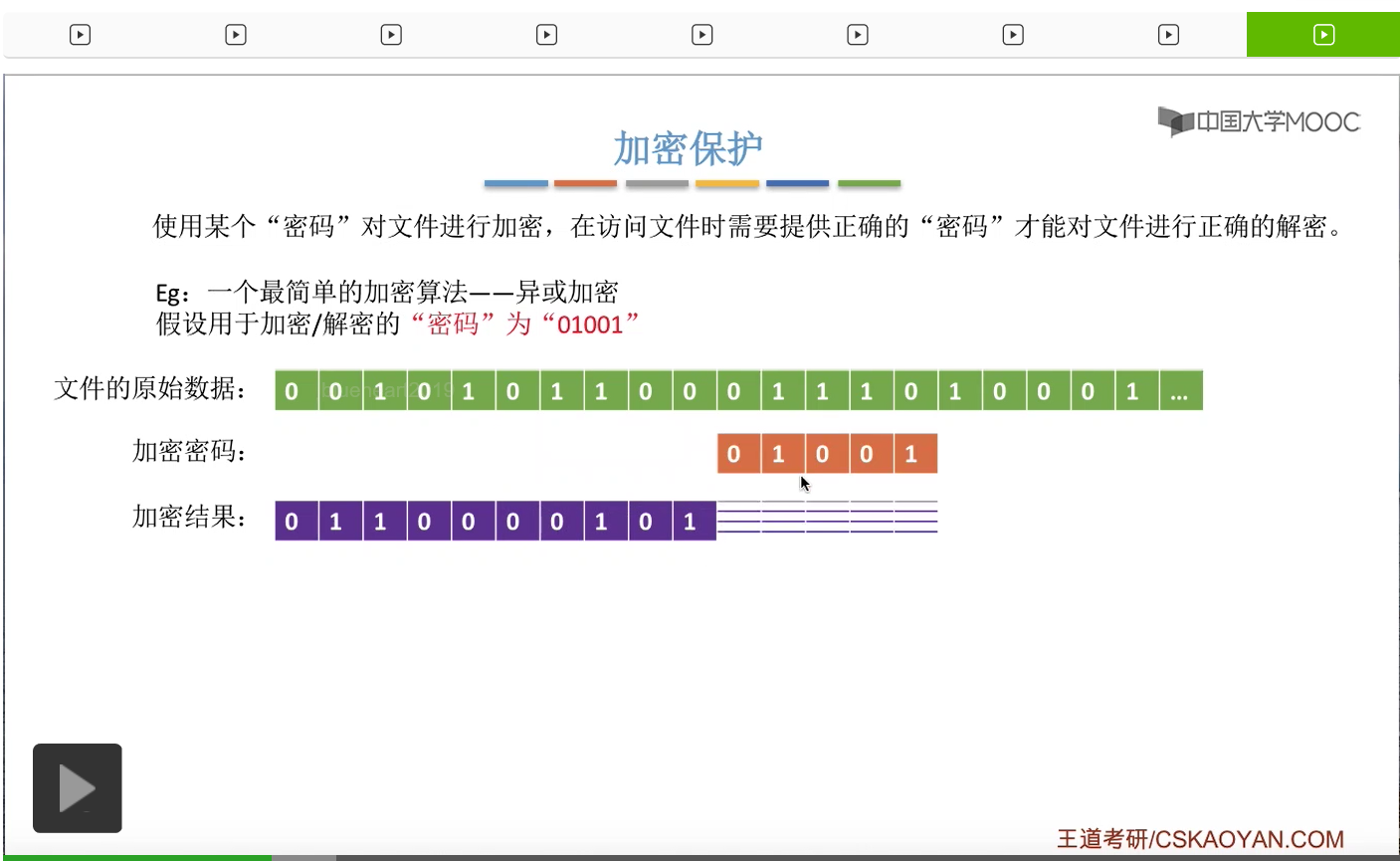



这样的话我们就可以把整个文件的数据都进行加密,所以其实系统当中保存的并不是文件的原始数据,而是保存了对文件进行加密之后的这一份数据。所以如果一个用户想要访问这个文件的话,那么必须对这个文件进行解密才行,不然的话读出来其实就是一串没有意义的乱码。

那解密的过程其实也是用这一串密码对这些二进制位进行异或运算,









那这个地方大家会发现,如果在加密的时候使用的密码和解密的时候使用的密码是一致的话,那么加密和解密之后这个文件的数据其实是完全一样的,大家可以自己动手尝试一下,并且对比一下文件的原始数据还有解密之后的这个结果是否一致。总之如果用户能够提供相同的、正确的密码的话,那么是可以把这个加密的文件给它解密成原有的那种数据形式的。


但是如果用户使用一个错误的密码进行解密的话,会发生什么情况呢?我们来看一下。假设用户用








那大家可以对比一下,它和文件的原始数据是不一样的。因此,如果一个用户不知道这个文件的加密、解密密码的话,那么它是没办法正常地访问这个文件数据的。用户只需要自己记住自己的密码是多少就可以了。那如果说它想要别的用户也可以访问自己的这个文件的话,那它只需要把自己的密码告诉别的用户就可以。不过这种方式的缺点也很明显。

第三种实现文件保护的方式叫做访问控制。那需要注意的是,每一个文件都会有一张自己的访问控制表。
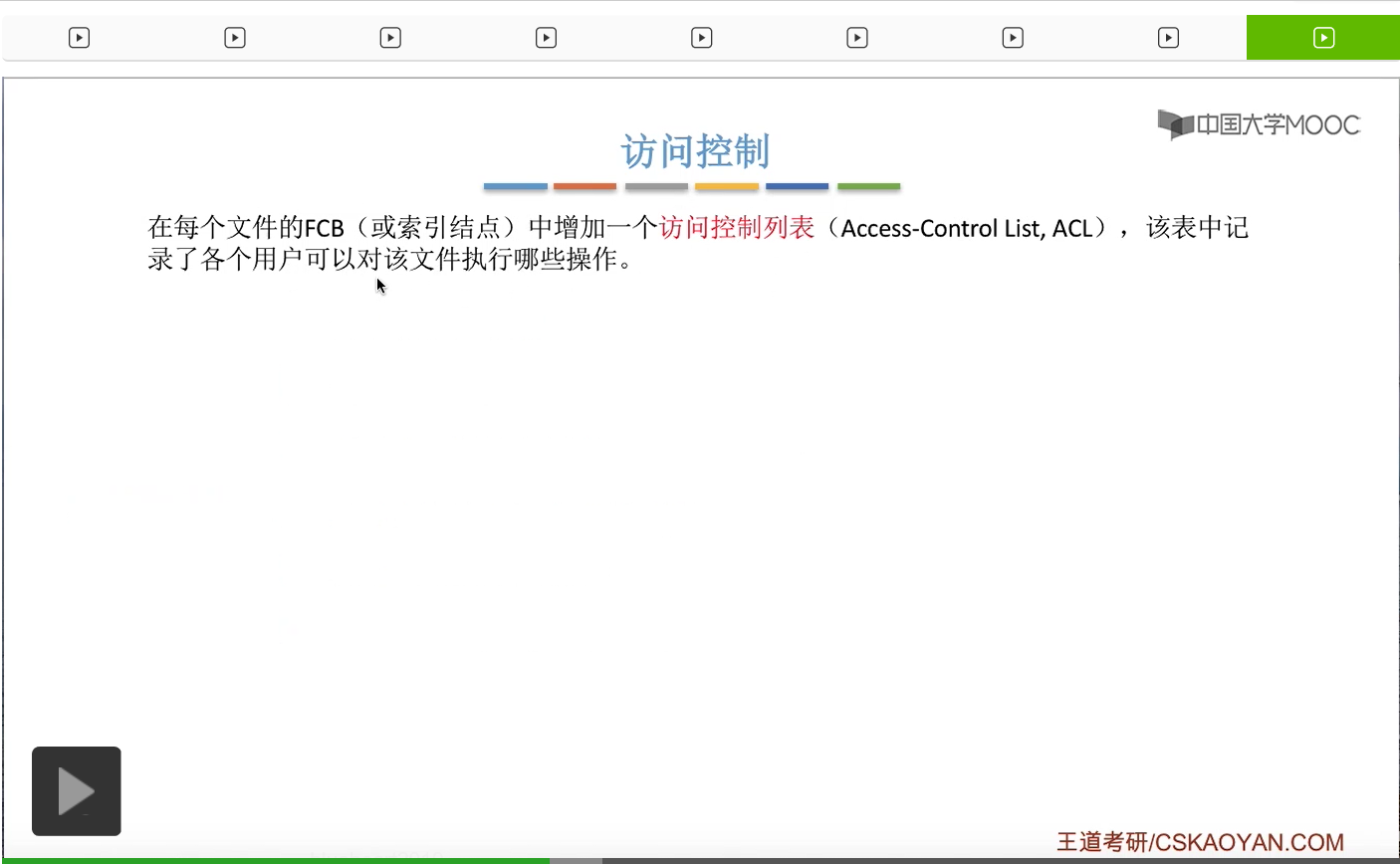
那用户对文件执行的操作可以分为这样的一些类型:读、写、执行、添加、删除、列表清单等等。那不同的系统对这种操作类型的划分不一样。这个地方不是很重要,大家自己看一下就可以了。
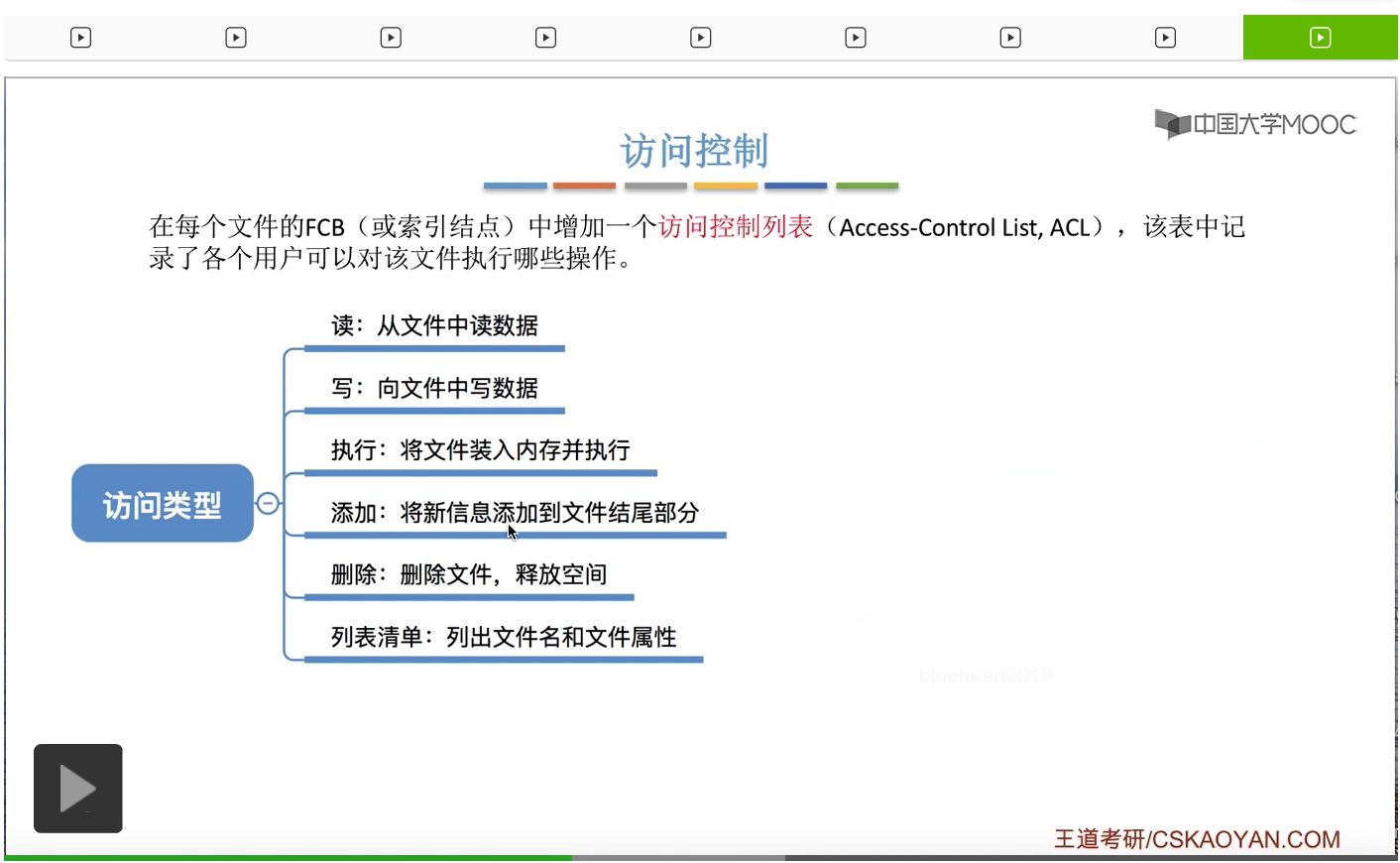
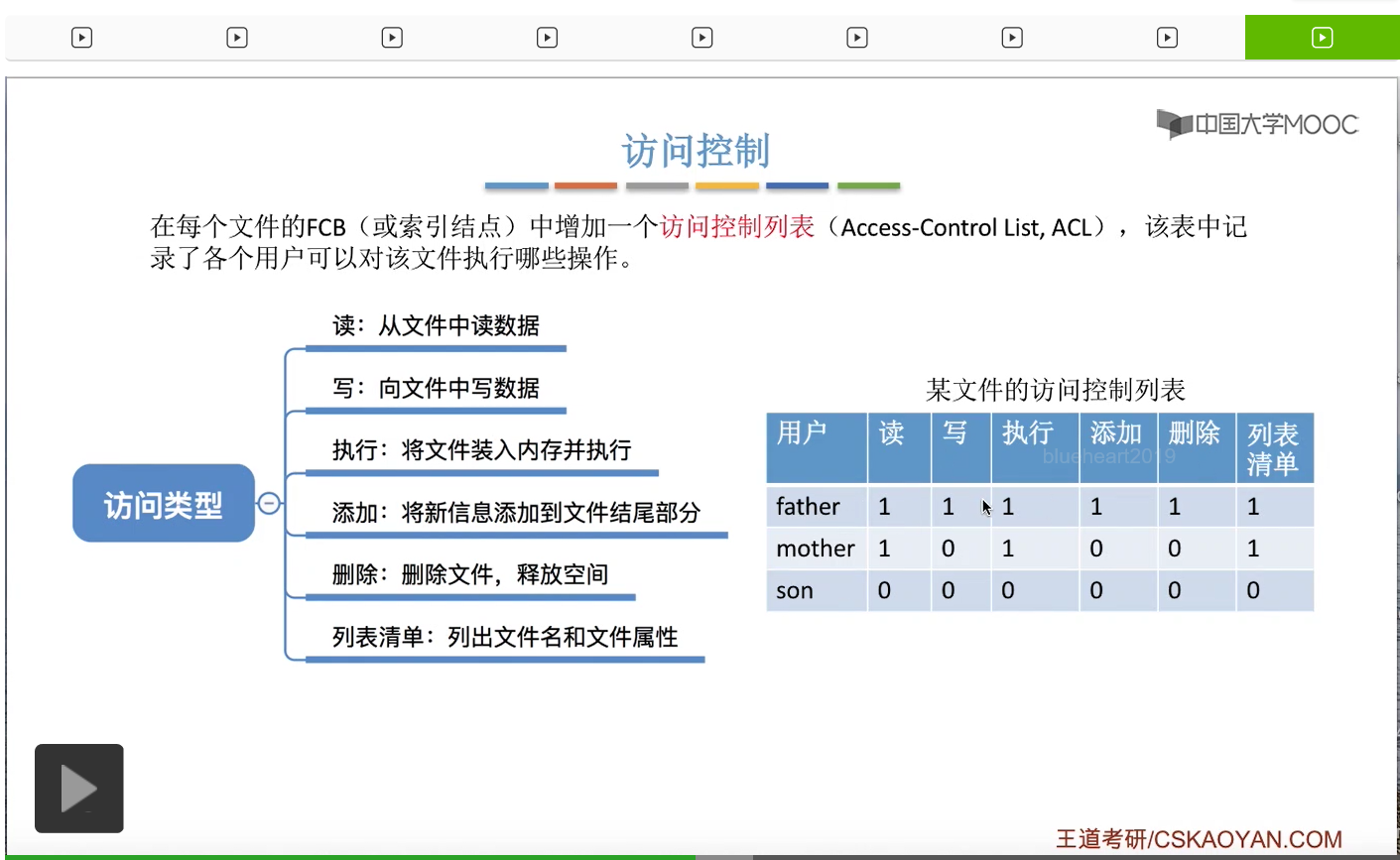
这个地方的1表示允许,0表示拒绝。所以父亲这个用户可以对这个文件进行读、写、执行、添加、删除、列表清单等等这一系列的操作。

那么每个用户都会从属于其中的一个或者两个分组。
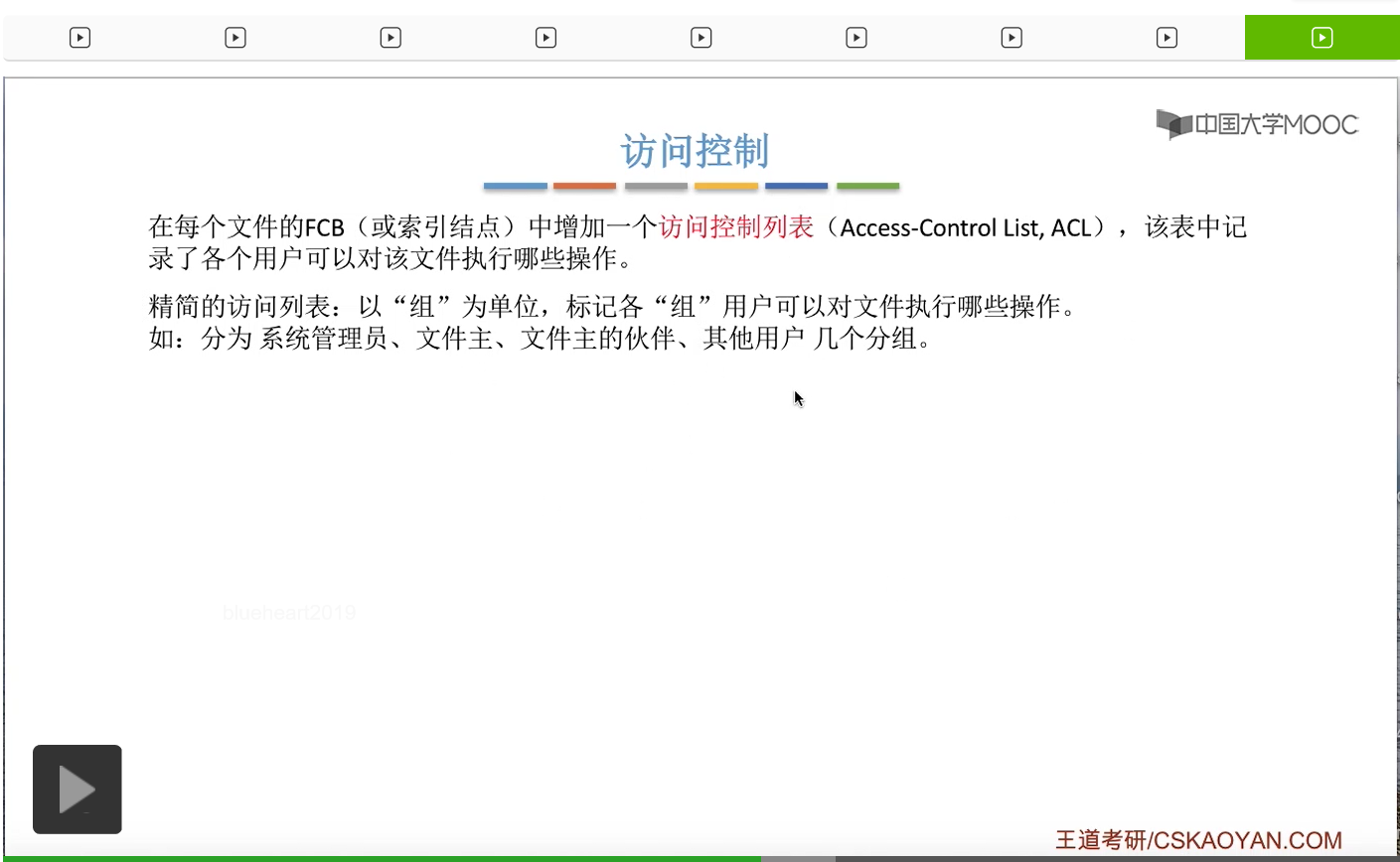
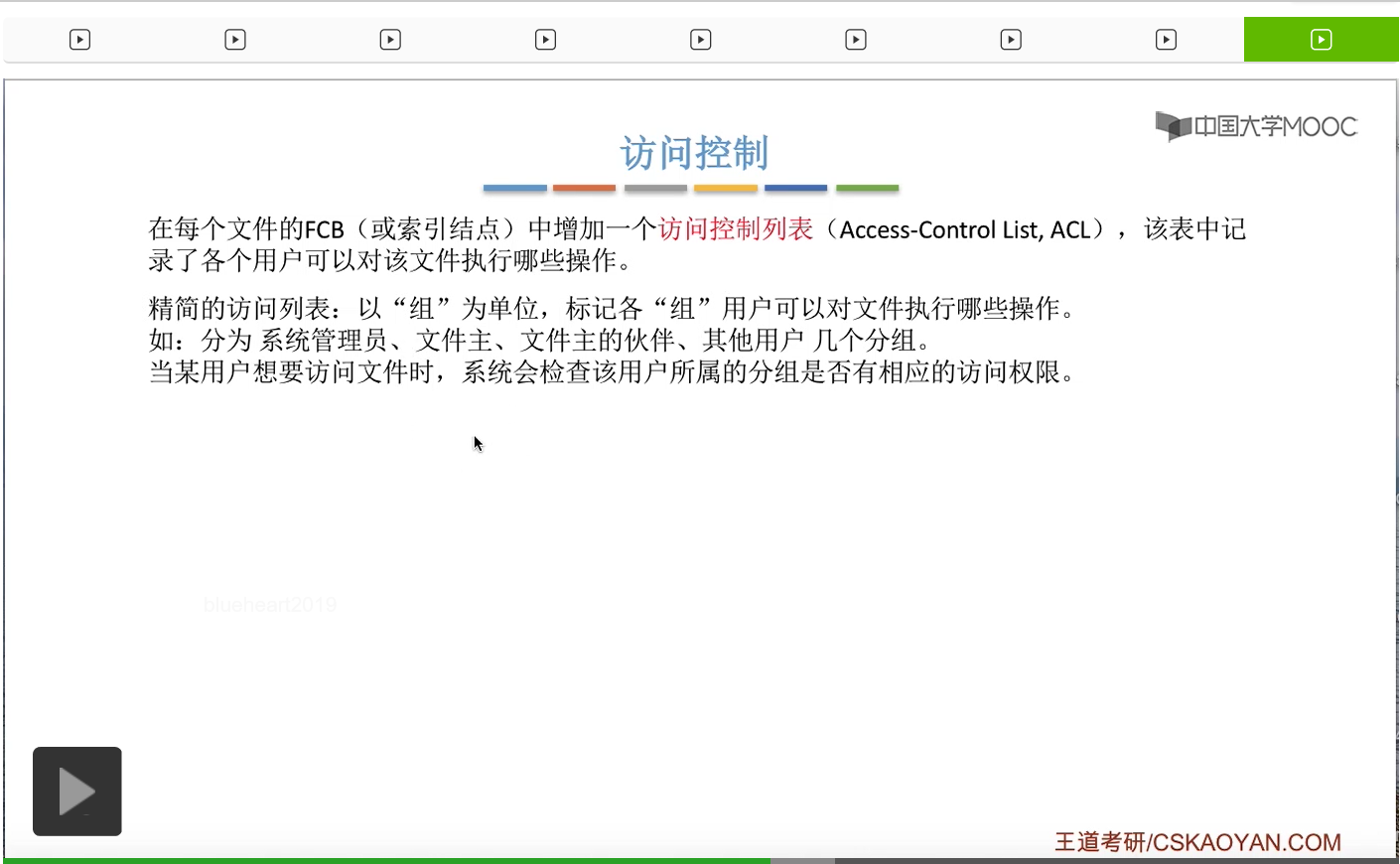
所以其实操作系统也需要管理这些用户分组的信息。它需要记录哪个用户是属于哪个分组。
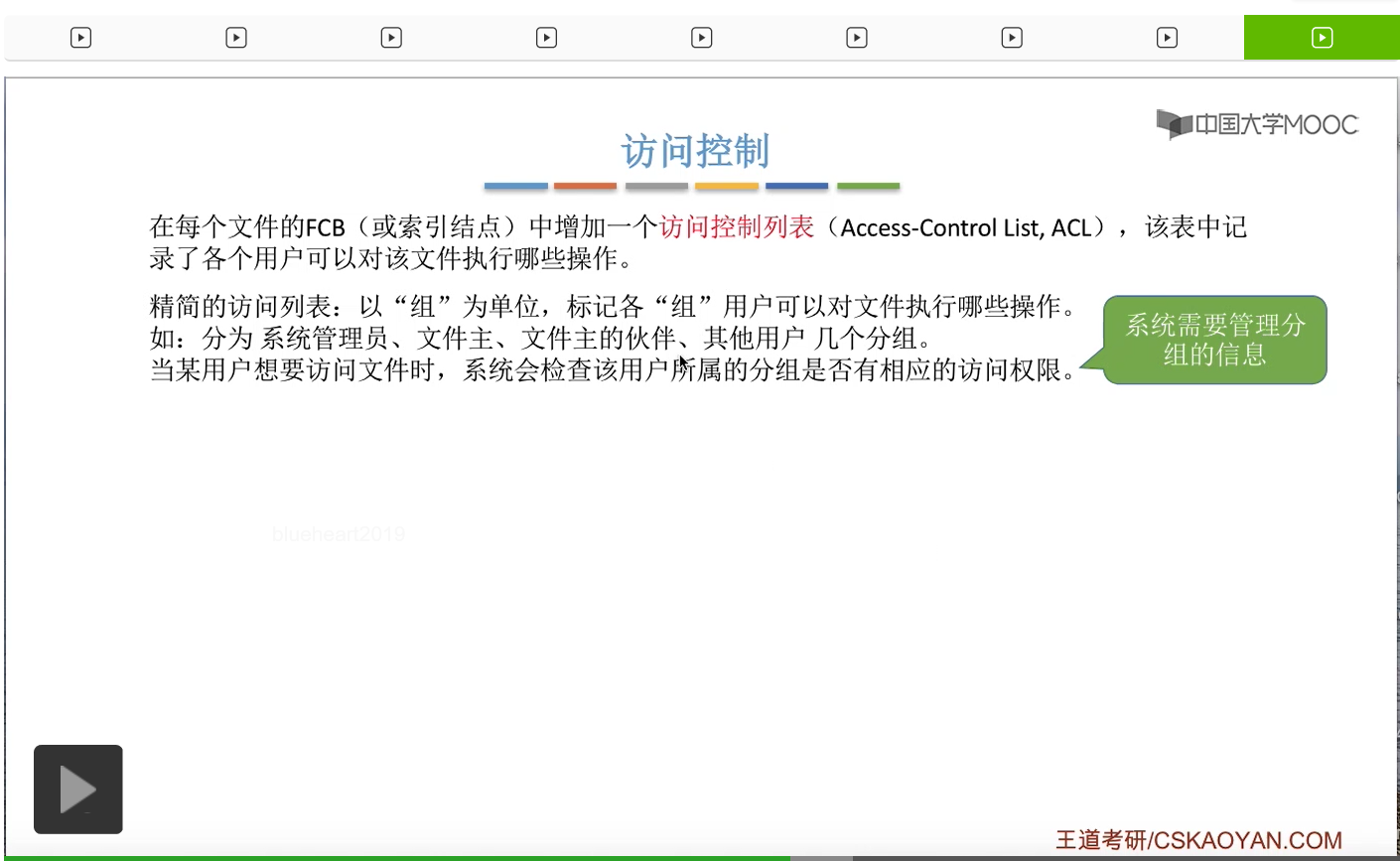
那精简的访问列表就可以表示成这个样子。那么在这个地方同样是1表示允许,0表示拒绝。那可以看到,如果说一个用户是属于其他用户这个分组的话,那么它既不可以读这个文件,也不可以写这个文件。
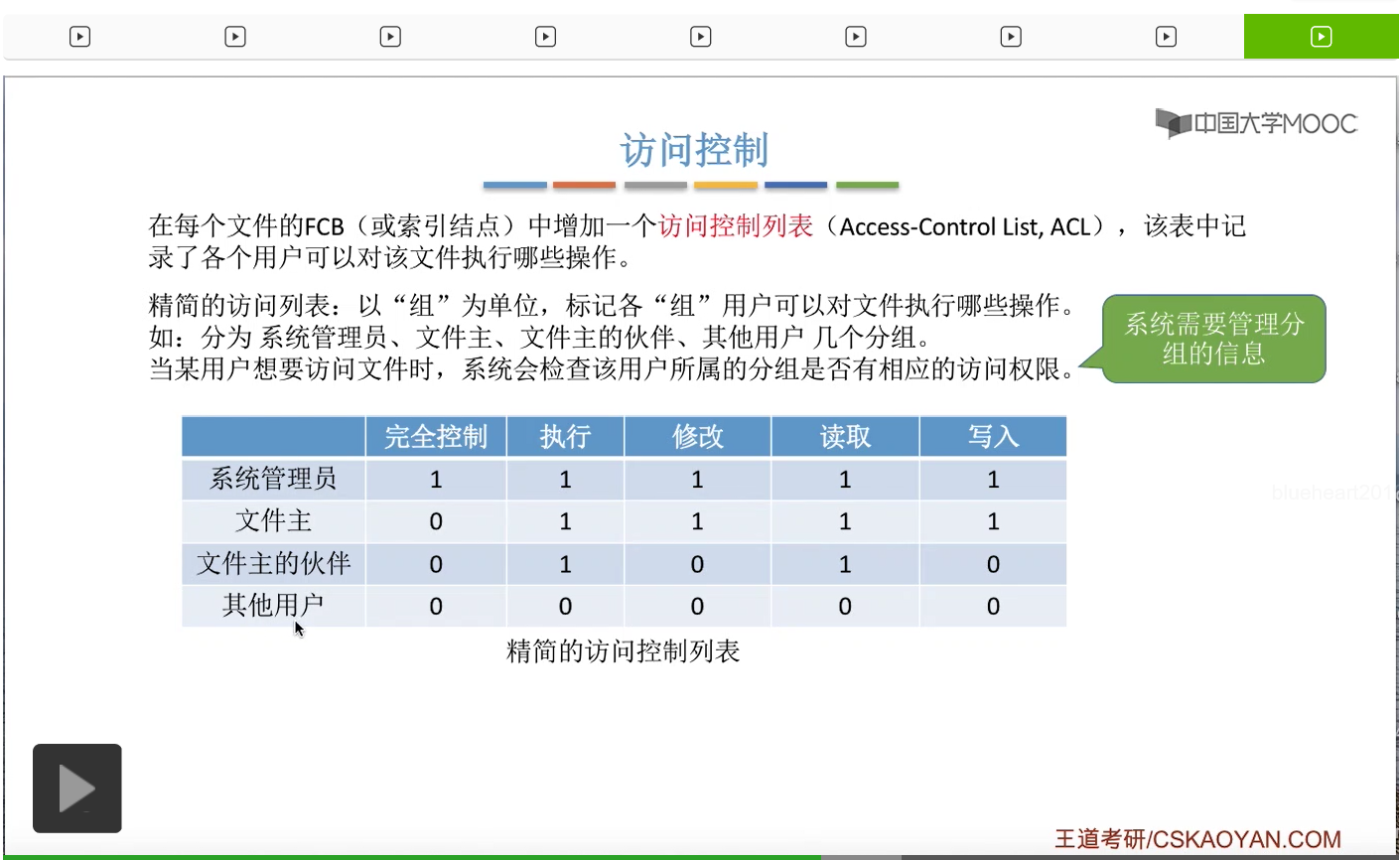
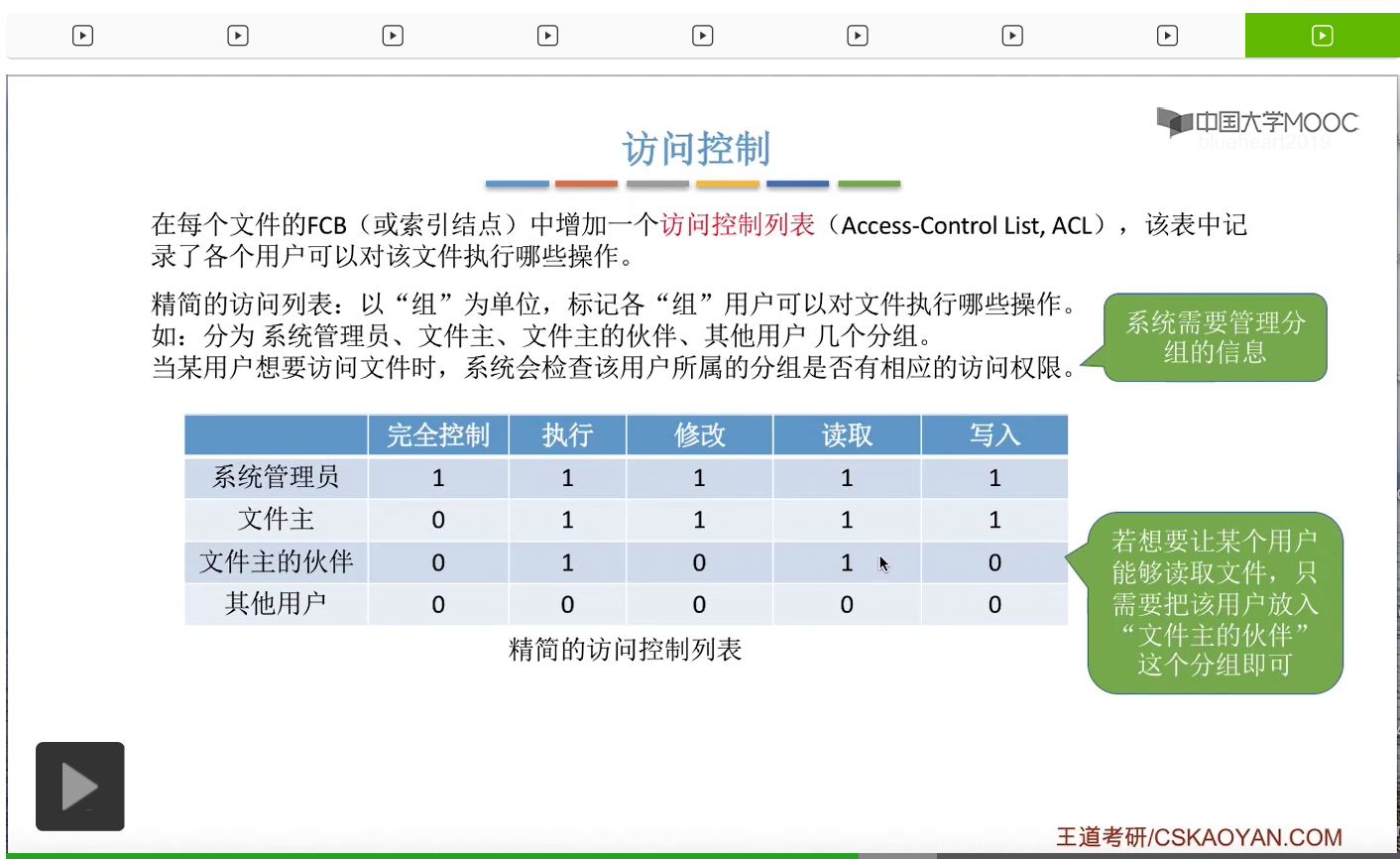
那如果说这个文件主想要给某个用户也拥有读的权限的话,那么就可以由文件主把这个用户放到文件主的伙伴这个分组当中,那这样的话这个用户就可以对文件进行读的操作了。
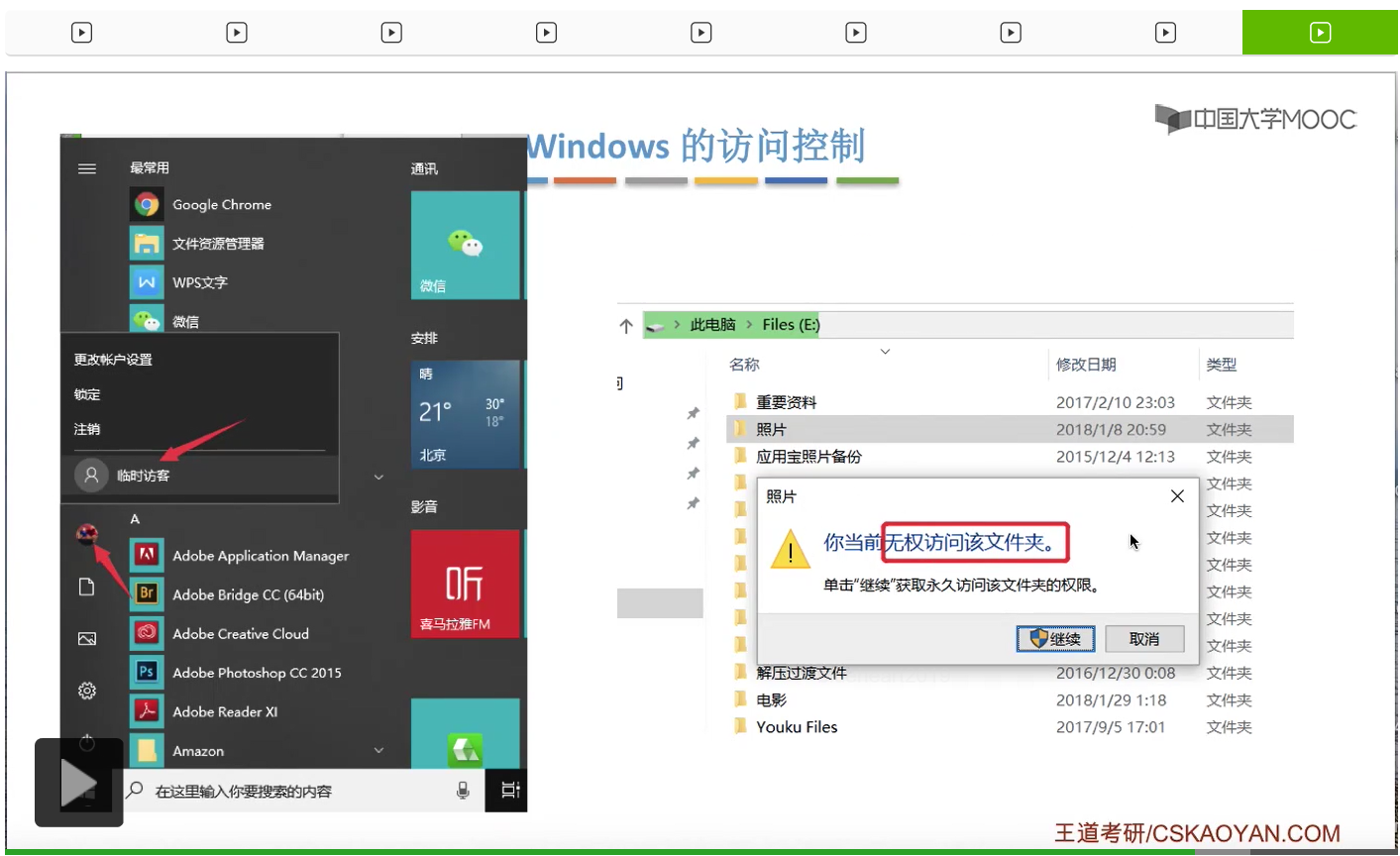
那接下来我们来看一下Windows操作系统它是怎么实现访问控制的。


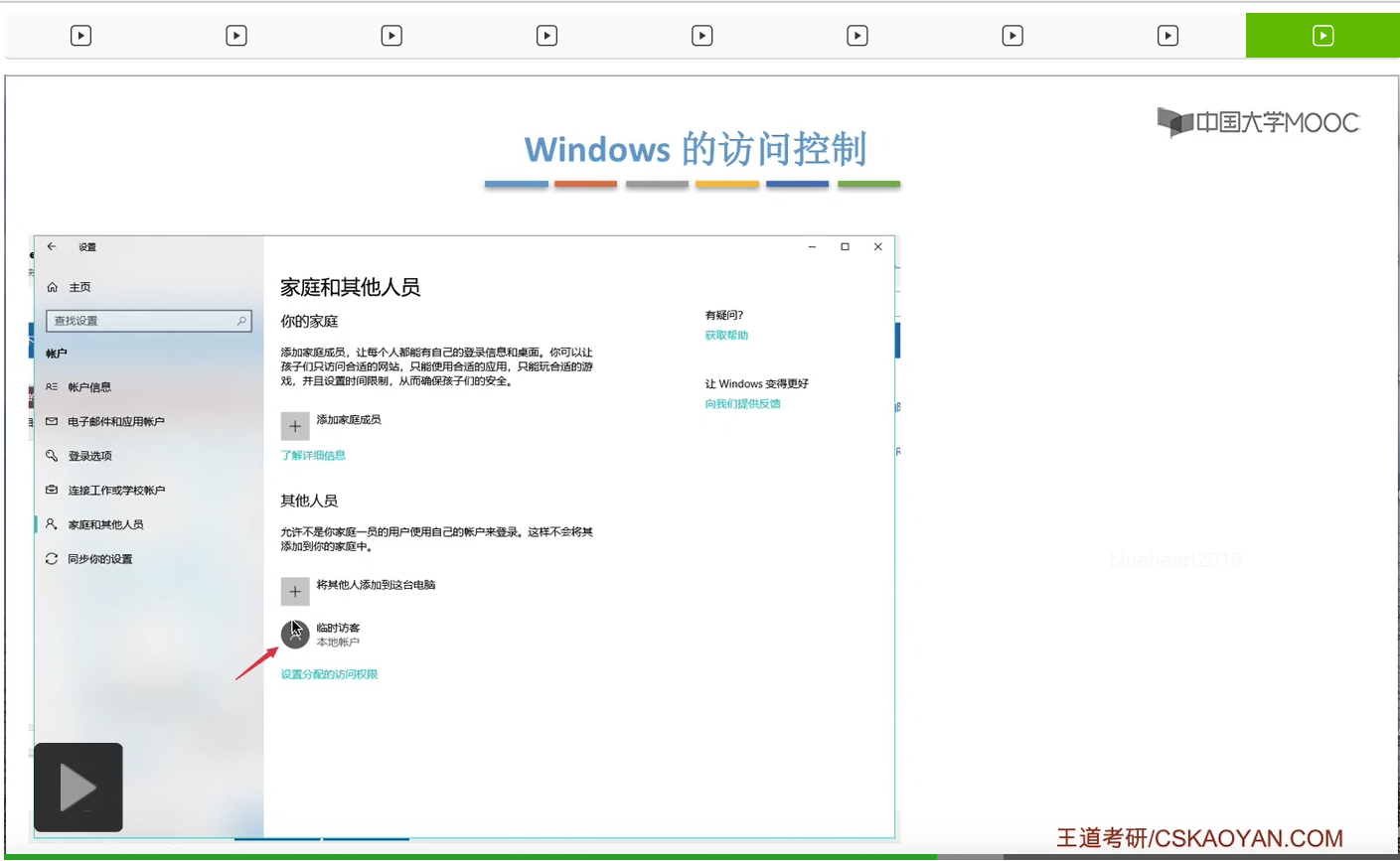
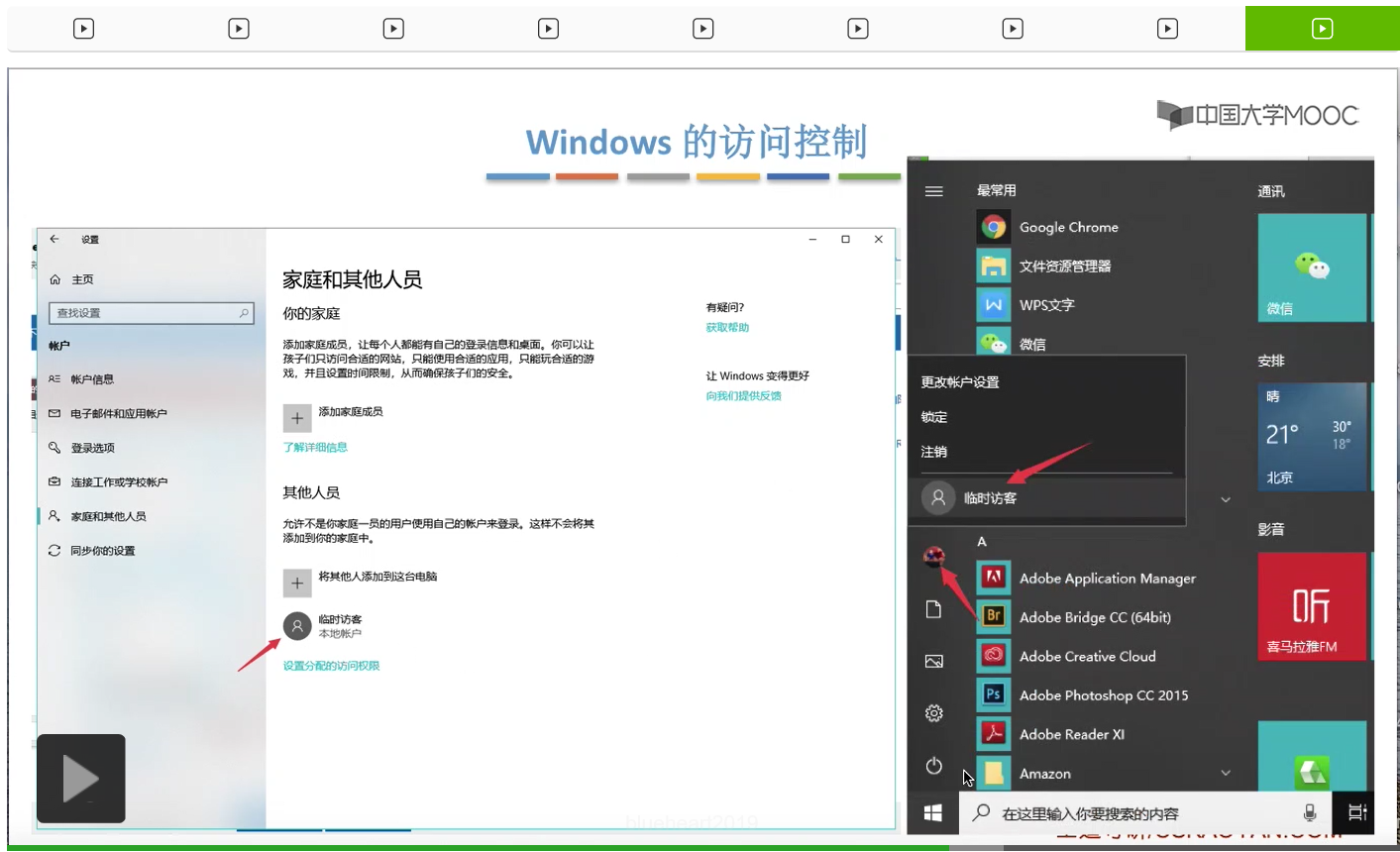
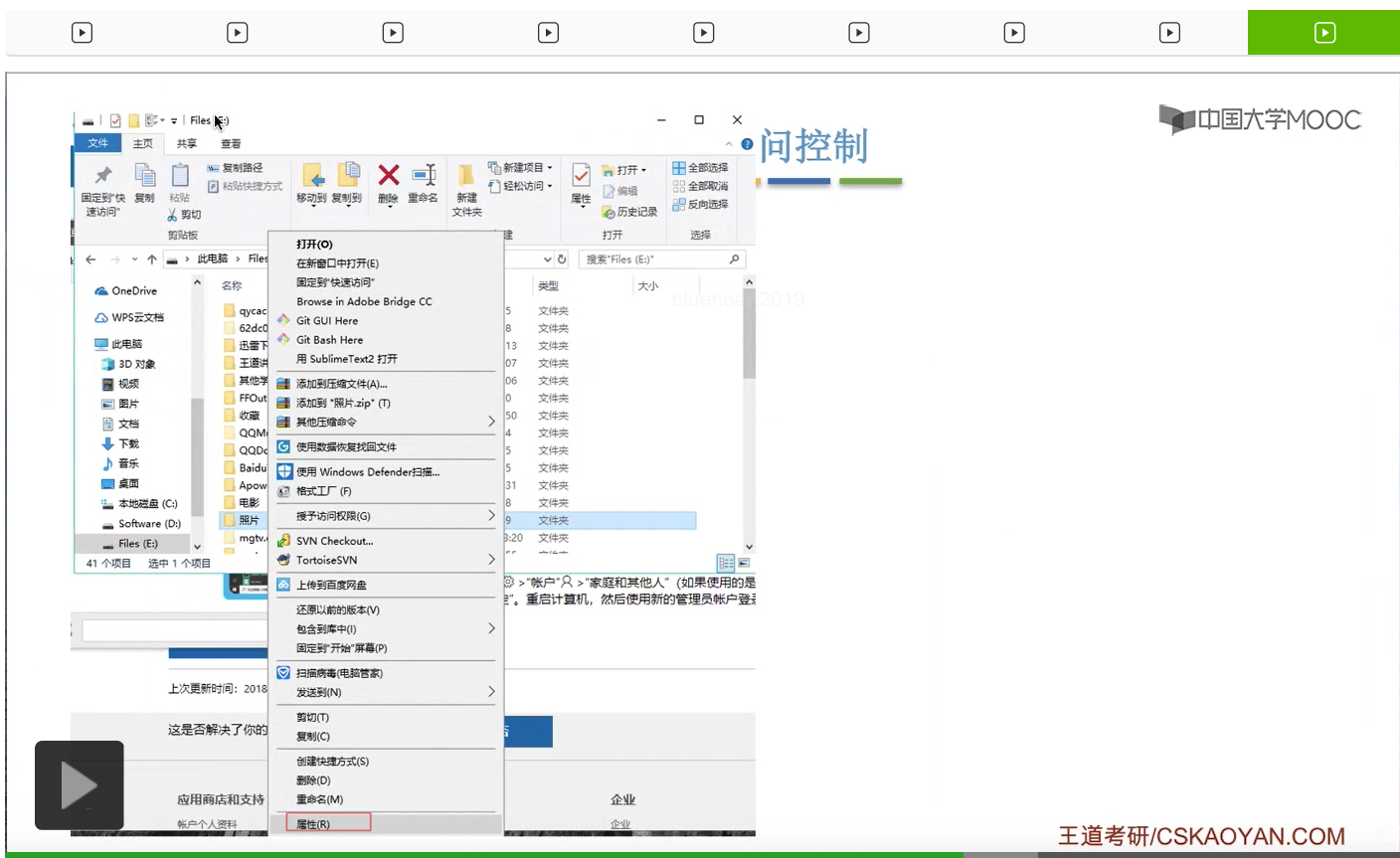
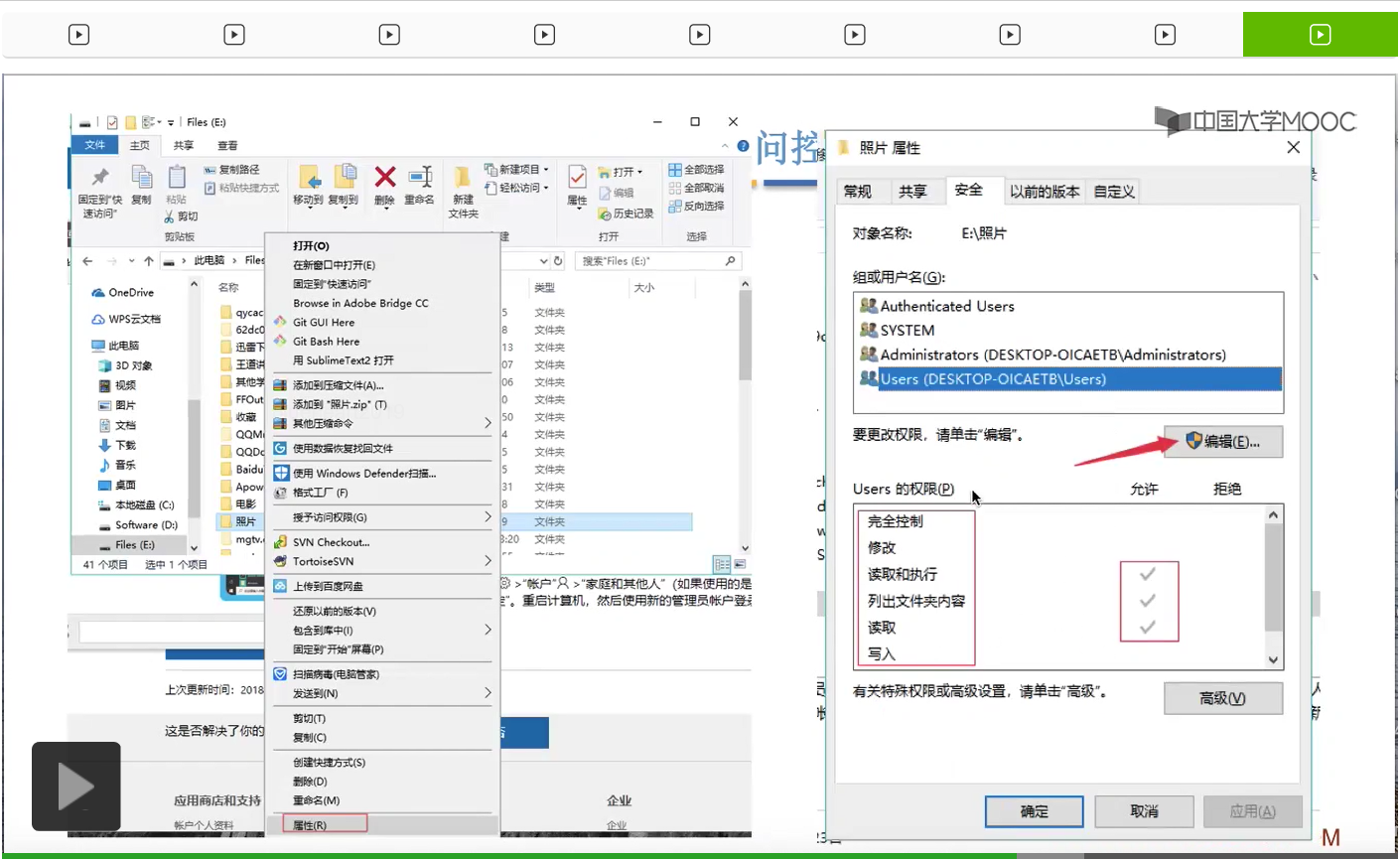

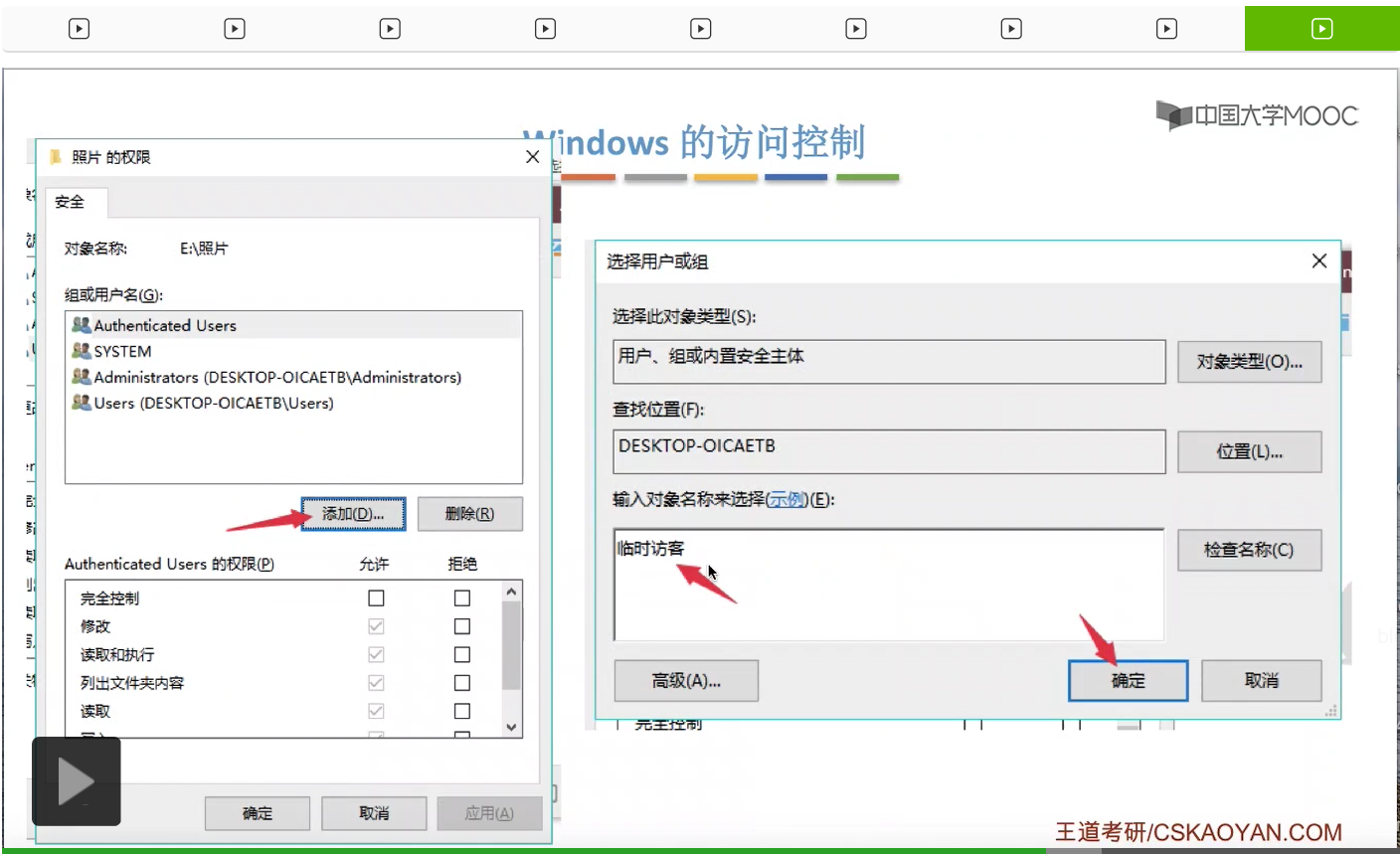
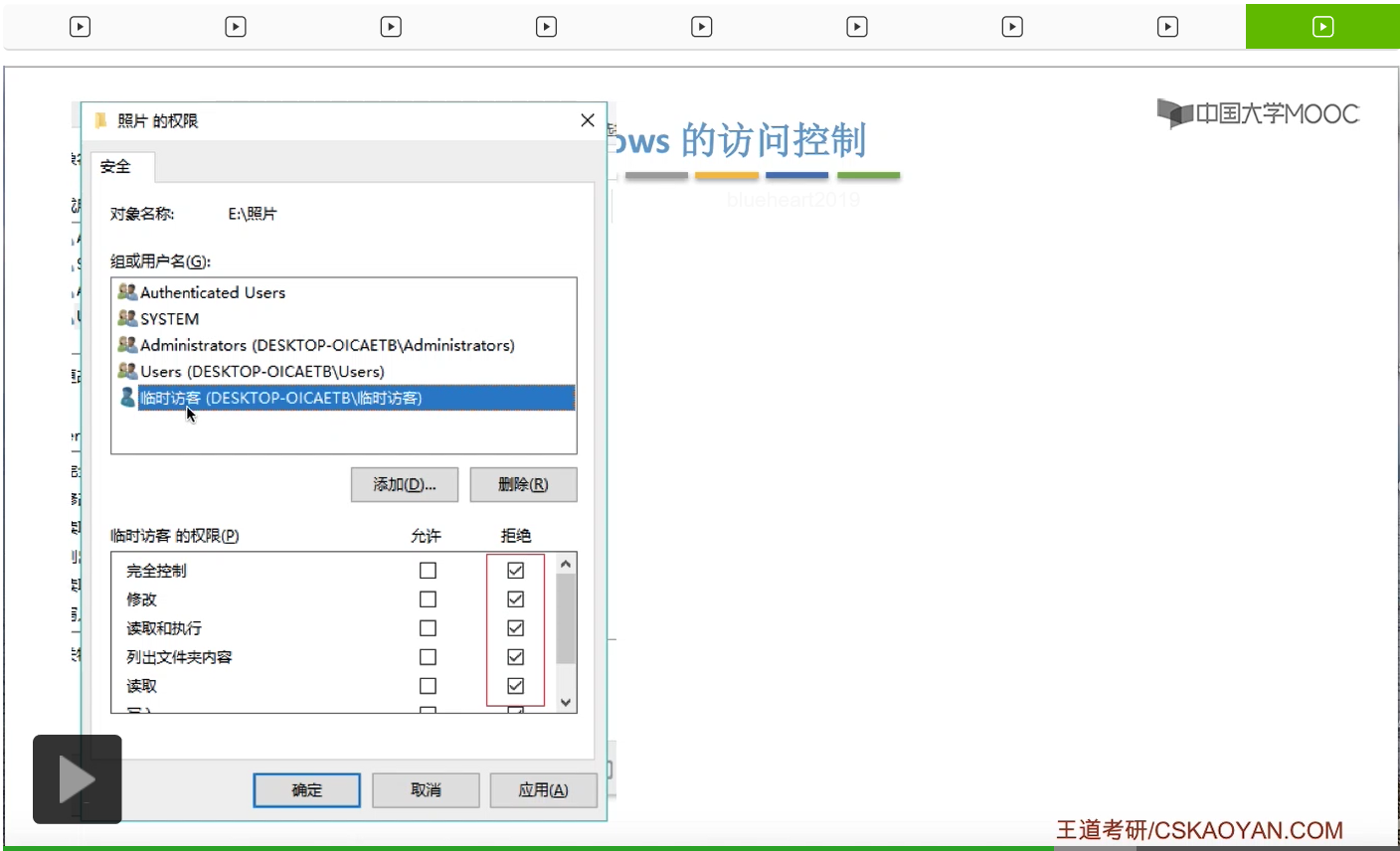
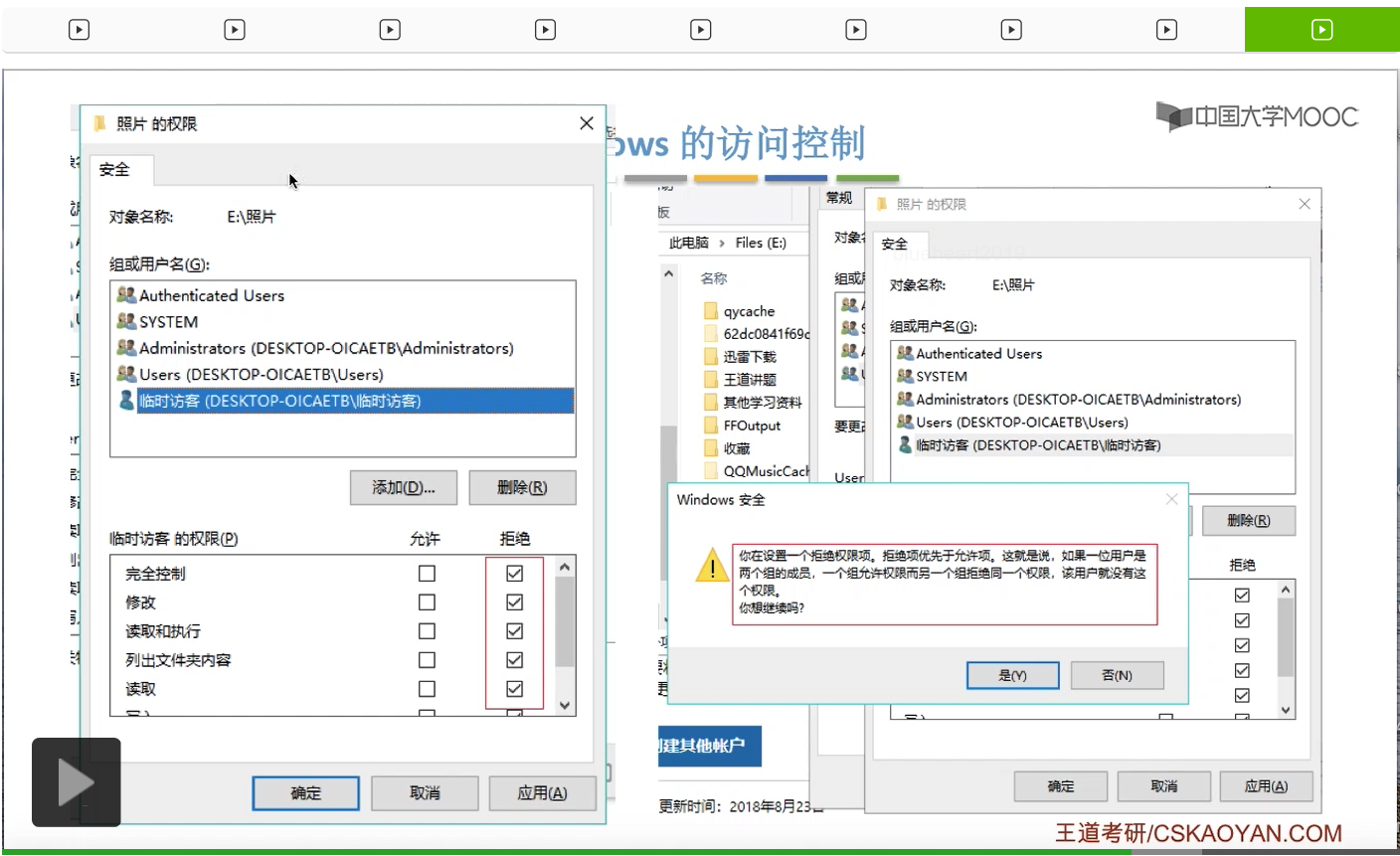
那其实系统在背后做的事情就是,找到了照片这个目录文件对应的FCB,然后根据FCB当中记录的访问权限相关的一些信息来判断临时访客这个用户到底有没有权限访问这个文件夹。最后发现这个用户是没有权限访问的,于是就弹出了这样的一个提示框。
学习了三种文件保护的方式——口令保护、加密保护和访问控制。那口令保护和加密保护是比较容易混淆的。口令保护的这个口令是存放在系统当中的,然后系统会验证用户提供的口令是否正确。如果正确的话,才允许用户访问这个文件。而加密保护其实,这个密码不需要保存在系统当中,只有用户自己知道。那另一个用户想要访问一个加密的文件的话,那它需要使用相同的密码才可以对文件进行正确的解密。所以加密保护的安全性要比口令保护要更高一些。但是它所带来的加密、解密的开销又需要花费一定的时间。那最后我们介绍了访问控制这种文件保护方式。绝大多数的现代操作系统都支持访问控制这种方式来保护文件,那大家也可以自己动手去Windows操作系统下面去看一下各个文件的安全属性然后再动手调试一下就可以对这个部分的内容有更深的理解。那像口令保护和加密保护这两种方式的话,只要用户知道了口令或者知道了密码,那用户就可以对这个文件执行所有类型的操作。但是对于访问控制这种方式来说,它可以实现更复杂的文件保护功能。它可以把用户对文件的操作分为各种不同的类型,然后不同的用户可以执行不同类型的操作。所以访问控制这种方式实现的文件保护其实也是要更灵活一些。

那再一个大家需要注意的是,如果对某个目录进行了访问权限的控制,那么也需要对这个目录下面的所有文件进行相同的访问权限控制。就像刚才咱们举到的那个照片文件夹的例子一样,一个用户不允许访问照片那个文件夹那个目录,那它同时也不允许访问这个目录下的所有的文件。
