第2章 关系数据库理论基础
• 2.1 关系模型
• 2.2 关系代数
• 2.3 关系数据库
• 2.4 函数依赖
• 2.5 关系模式的范式
• 2.6 关系模式的分解和规范化
2.1 关系模型
• 关系模型的基本要素:关系模型的数据结构、关系操作和关系的完整性约束三部分。
• 2.1.1 关系模型的数据结构——关系
定义2.1 令D = D1×D2×…×Dn = {(d1, d2,…, dn) | di ∈Dn , i = 1,2,…,n},即D为D1, D2, …, Dn的笛卡儿积,则D的任何非空子集R都称为D1, D2, …, Dn上的n元关系,其中Di为有限的属性值域,i = 1,2,…,n。
Ø 一个n元关系R通常记为R(D1, D2, …, Dn),R中的任一元素(d1, d2,…, dn)称为n元组,简称元组(Tuple)。元组中的每个值di称为分量。n称为关系的度或元。当n = 1时,R称为单元关系;当n = 2时,R称为二元关系。
Ø 注意,一个关系实际上就是若干元组的集合。一个关系必须是有限元组的集合,无限集合对数据库技术来说是无意义的。
• 笛卡儿积可以用二维表直观地表示。
【例子】 假设笛卡儿积D = D1×D2×D3,D1为学号的集合, D1={201301, 201302},D2为姓名的集合, D2={李思思, 刘洋},D3为英语成绩(简称“英语”)的集合, D3={90, 85, 70}。
D = {201301, 201302}×{李思思, 刘洋}×{90, 85, 70}
= {(201301, 李思思, 90), (201301, 李思思, 85), (201301, 李思思, 70), (201301, 刘洋, 90), (201301, 刘洋, 85), (201301, 刘洋, 70),
(201302, 李思思, 90), (201302, 李思思, 85), (201302, 李思思, 70),
(201302, 刘洋, 90), (201302, 刘洋, 85), (201302, 刘洋, 70)}。

• 由定义2.1,D为一个笛卡儿积,D的任意子集都是三元关系。
【例子】令R = {(201301, 刘洋, 70), (201302, 李思思, 90)},R 为D的一个子集,所以R 为3元关系。
• 这个关系记作R(D1, D2, D3),其对应二维表示如表2.2所示。

• 笛卡儿积D本身也是一种关系,但这种关系由于过于泛化而可能会导致语义上的矛盾,从而失去实际意义。一般来说,只有部分关系有意义,而不是全部。
【例子】 元组(201301, 刘洋, 90)和元组(201301, 刘洋, 85)就是一对矛盾的元组,因为学号“201301”、姓名为“刘洋”的学生的英语成绩不可能同时取90分和85分这两个值。
• 数据库理论中的一些概念;
Ø 关系:一个关系等同于一张二维表,是有限元组的集合;一个数据库可以视为若干关系的集合
Ø 元组:二维表中的一行对应一个元组,也称为记录。
Ø 由表2.2所示,“201301”,““刘洋”和“70”构成的行就是元组(201301,刘洋, 70)。
Ø 属性:二维表中的每一列都称为属性或字段。
Ø 域:即属性的值域,也就是属性的取值范围。
Ø 由表2.2所示,“学号”这个属性的值域为{201301, 201302}。
Ø 分量:一个元组中的一个属性值,也常称为数据项。
Ø 由表2.2所示,“刘洋”、“70”等都是数据项。数据项不能再分了,它是关系数据库中最小的数据单位。
Ø 候选码和主码:如果二维表中存在一个属性或若干属性组合的值能够唯一标识表中的每一个元组,则该属性或属性组合就称为候选码,简称码;如果一个表存在候选码,且从中选择一个候选码用于唯一标识每一个元组,则该候选码称为主码(Primary key)。主码也常称为主健(主关键字段)。
Ø 主属性和非主属性:包含在任何候选码中的属性都称为主属性,不包含在任何候选码中的属性称为非主属性。
• 关系的性质:
Ø 列是同质的,即每一列中的分量是同一类型的数据,它们都是来自同一个域。
Ø 每一列为一个属性,不允许存在相同属性名的情况。
Ø 列(行)的顺序是任意的,列(行)的次序可以任意交换。
Ø 不允许存在两个相同的元组。
Ø 每一个分量都是不可再分的,即不允许表中套表。
定义2.2 假设一个n元关系R的属性分别为A1, A2, …, An,令R(A1, A2, …, An)表示关系R的描述,称为关系模式。
Ø 关系模式是由属性构成,与属性值无关。为了体现关系模式中的主码,对构成主码的属性添加下划线。
【例子】在关系模式R(A, B, C, D, E)中,属性A和B的组合是该关系模式的主码。
Ø 关系模式是描述关系的“型”,即凡是具有相同属性的关系都属于相同的“型”,即它们都属于同一个关系模式。
Ø 一个关系模式可以视为一类具有相同类型的关系集合,属于同一个关系模式的关系都拥有相同的属性(但属性值却不一定相同)。
Ø 一个特定的关系是其对应关系模式的“值”,或者说关系是关系模式这个集合中在某一时刻的一个“元素”。
Ø 关系和关系模式的区别和联系:
• 关系和关系模式之间的联系就好像是数据类型和数据之间的联系。
• 关系模式和关系是有区别的,即前者是后者的抽象,后者是前者的特定实例
• 关系模式是相对稳定的,数据在更新,关系是随时间变化的。但在运用中常常将它们统称为关系,读者可根据上下文来区分。
• 2.1.2 关系操作
• 关系操作的分类:查询操作、更新操作
• 查询操作是最常用和最主要的操作,其包括:
Ø 选择:从关系中检索出满足既定条件的所有元组的集合,这种操作就称为选择。其中,选择的条件是以逻辑表达式给出的,使表示式的值为真的元组被选取。从二维表的结构上看,选择是一种对行的操作。(最常用)
Ø 投影:从关系中选出若干个指定的属性来组成新的关系,这种操作就称为投影。从二维表的结构上看,选择是一种对列的抽取操作。
Ø 连接:从两个关系中抽出满足既定条件的元组,并将它们“首尾相接”地拼接在一起,从而形成一个新的关系,这种操作称为连接。
Ø 除:一种行列同时参加的运算。
• 以下三个选择操作的共同特点是,参加运算的两个关系必须有相同的属性个数,且相应属性的取值分别来自同一个域(属性名可以不同):
Ø 并:将两个关系中的元组合并到一起(纵向),从而形成一个新的关系,这种操作称为并。
Ø 交:将两个关系中的共同元组组成一个新的关系,这种操作称为交。
Ø 差:将第一个关系中的元组减去第二个关系中的元组,从而也产生了新的关系,这种操作称为差。
• 更新操作种类:(最常用)
Ø 插入:把一个关系(元组的集合)插入到已有的关系中,形成新的关系。
Ø 删除:从一个关系中删除满足既定条件的所有元组,剩下的元组构成新的关系。
Ø 修改:利用给定的值更改关系中满足既定条件的所有元组的对应分量值,更改后得到新的关系。
• 关系操作的特点:
• 针对集合进行,即操作的对象是元组的集合,操作后所得到的结果也是元组的集合。
• 非关系模型(网状模型和层次模型)的操作对象是一个元组。
• 2.1.3 关系的完整性约束
关系是关系模型的数据结构。关系需要满足一些基本要求——关系的完整性约束。
完整性约束包括:实体完整性约束、参照完整性约束、用户定义的完整性约束。
1.实体完整性
Ø 每一个关系中的主码属性的值不能为空(NULL),能够唯一标识对应的元组。
原因:主码设置的目的是用于区分关系中的元组,以将各个元组区别开来。如果主码中的属性值可以为空,那么在关系中将存在一些不确定的元组,这些元组将不知道是否能够与别的元组有区别(因为空值被系统理解为“不知道”或“无意义”的值),这在关系模型中是不允许的。各个元组在主码上的取值不允许相等,否则就不满足实体完整性约束。
Ø 实体完整性是关系模型必须满足的完整性约束条件。
【例2.1】考虑如表2.3所示的学生关系student(学号, 姓名, 性别, 专业号)和表2.4所示的课程关系course(课程号, 课程名, 学分)。假设学生关系的主码为“学号”,课程关系的主码为“课程号”,那么学生关系的“学号”以及课程关系的“课程号”的取值就不能为空,而且取值不能重复(能唯一标识每一行),否则就不满足实体完整性。
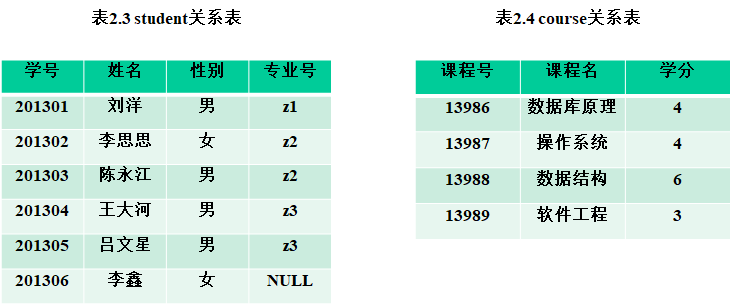
2. 参照完整性
Ø 参照完整性与外码密切相关,这里先介绍外码的概念。
Ø 对于关系R和S,假设F是关系R的一个属性或一组属性,但F不是R的码,K是关系S的主码,且F与K相对应(或相同),则F称为R的外码(Foreign key),R和S分别称为参照关系(Referencing relation)和被参照关系(Referenced relation),如图2.1所示。
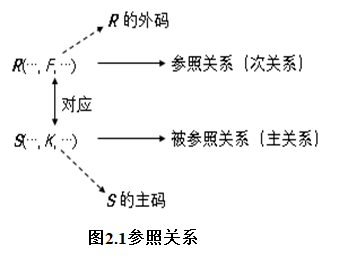
• F与K是相同的属性或属性集,它们的取值范围相同。
• 关系模型的参照完整性约束:外码F中的每个属性值等于主码K的某一个属性值或F的每个属性值均为空值。
• 如果要在关系R中插入一个元组,则该元组在属性F上的取值等于关系S中某一个元组在主码K上的取值或全置为空值,否则不能插入该元组。当关系S为空时,不能向关系R中插入元组;当要删除关系S中的一些元组时,必须先删除关系R中与这些元组相关联的元组。
• 参照完整性也是关系模式必须满足的完整性约束条件。
【例子】选课关系SC(学生编号, 课程编号, 成绩),如表2.5所示。可见属性组{学生编号,课程编号}为该关系的主码。
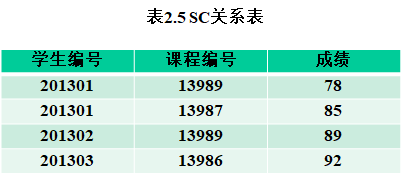
属性“学生编号”是选课关系的外码,它与关系“student(学号, 姓名, 性别, 专业号)”的主码“学号”相对应,选课关系为参照关系,学生关系为被参照关系,“课程编号”同理。
• 外码“学生编号”和“课程编号”共同组成了该关系的主码,这两个属性的取值不能为空,只能为相应被参照关系中相应列中的取值。
【例子】表2.5中“学生编号”列的属性值“201301”必须等于表2.3中“学号”列中的某一个属性值;表2.5中的“课程编号”列的属性值“13989”必须等于表2.4中“课程号”列中的某一个属性值。

• 表2.6所示的专业关系major(专业编号, 专业名),该关系的主码是“专业编号”,且表2.3所示关系“学生”中的“专业号”与该关系中的“专业编号”相对应,即“专业号”是学生关系student的外码。在这种情况下,由于学生关系student中的“专业号”不是该关系的主码,因而“专业号”列的属性值可以取空值。
【例子】表2.3中学生“李鑫”所对应的“专业号”为空值,这表明尚未给该学 生分配专业。

3.用户定义的完整性
l 用户定义的完整性是指由用户定义的、针对某一具体应用需求制定的约束条件,多用于满足数据的一些语义要求。
【例子】在表2.5所示的关系SC中,经常定义这样的约束:成绩的取值必须在0~100之间;又如,某些属性值不能为空或取值必须唯一等。
l 用户定义完整性约束可以有效减少应用程序的负担,关系数据库管理系统都提供定义和检验这类完整性的机制和方法。
2.2 关系代数
l 2.2.1 基本集合运算
基本集合运算是指集合的并、交、差和笛卡儿积运算,这些运算都是二元运算。我们约定:本节中R和S都默认是n元关系,且对应属性取自同一个值域。以下介绍基于关系的基本集合运算。
1. 并∪
Ø n元关系R和S的并是一种新的n元关系,这个新的关系是由R的元组或S的元组组成,记为R∪S,即R∪S = {x | x∈ R∨x ∈ S}
2. 交∩
Ø n元关系R和S的交是一种新的n元关系,这个新的关系是由R和S的共同元组组成,也就是说,由既属于R的元组又属于S的元组组成,记为R∩S,
即R∩S = {x | x ∈ R ∧ x ∈S }
3. 差-
Ø n元关系R和S的差是一种新的n元关系,这个新的关系是由属于R的元组但不属于S的元组组成,记为R-S,即R-S = {x | x ∈ R∧x ∈S}
4. 笛卡儿积
Ø 设R和S分别是n元关系和m元关系,则R和S的笛卡儿积是一种(n + m)元关系,该关系是由R的每一个元组分别与S每一个元组进行“首尾并接”所得到的元组的集合,记为R×S,即R×S = {xr xs| xr ∈ R∧ xs ∈ S}
Ø xrxs是表示由元组xr和元组xs并接而得到的新元组。
【例子】如果xr =(1班,李好,78)且xs =(03987,陈永江,01,3班),
则xrxs =(1班,李好,78,03987,陈永江,01,3班)。
Ø 关系R和S的元组个数分别为kr和ks,则R×S的元组个数为kr×ks。
• 2.2.2 关系运算
关系一些特殊的运算,主要包括选择(σ)、投影(π)、连接(⋈ )、除(/)等。
Ø 先约定一种表示方法:设x为某一个关系R的一个元组,L为R的关系模式的一个子集(即属性子集),则令x(L)表示由元组x在属性子集L上的所有分量构成的新元组。
【例子】对于关系R(A,B,C,D),令x = (a , b ,c , d),则x({A,B,C}) = (a , b , c),x({C,D}) = (c , d),x({B}) = (b),等。
• 选择σ
从关系中筛选出满足既定条件的元组,这些元组组成了一个新的关系,这个操作过程称为选择。
Ø 选择的操作符用σ表示,选择条件则用逻辑公式来表示,用R表示逻辑公式。对关系R的选择运算就可以表示为σt(R),即
σt(R) = {x | x∈R∧t(x) = true}
“t(x) = true”表示元组x满足条件公式t。对于选择运算,关键是设置选择条件t。
在数据查询中,条件公式t通常是由<、>、≤、≥、=、between、∧、∨等连接符号构成的条件表达式或逻辑表达式。
【例子】表2.3所示的学生关系student。令选择条件t = (性别=‘男’∧专业号=‘z3’),则选择运算st(student)表示查找那些专业号为“z3”的男同学,结果如表2.7所示。

2. 投影π
l 投影是指从关系中选出若干个指定的属性来组成新的关系。令投影的操作符为π,L为指定的属性子集,则关系R在属性子集L上的投影就可以表示为πL(R),即 πL(R) = {x(L) | x ∈ R}
x(L)表示由元组x在属性集L上的取值构成的新元组。
l 投影还有一种表示方法就是在投影运算表达式πL(R)中用指定的属性在关系R中的序号来代替L中的属性名。
【例子】对于上述的投影π{姓名,性别} (student)也可以表示为π{2,3}(student)。
l 投影就是从关系表中按指定的属性抽取相应的列,这些列组成一个新的关系。
l 注意,投影运算是对列进行筛选,而选择运算则对行进行筛选。
【例子】对于表2.3所示的学生关系student,令L = {姓名,性别},则学生关系在L上的投影:
πL(student) = {x(L) | x∈ R}
= {x({姓名,性别}) | x∈ R}
= {(刘洋,男), (李思思,女), (陈永江,男), (王大河,男), (吕文星,男), (李鑫,女)}
结果如表2.8所示。

3. 连接 ⋈
连接运算是二元运算,即涉及到两个关系的运算。假设参与运算的两个关系是R和S,则连接运算的结果是R和S笛卡儿积中满足属性间既定条件的元组的集合,即它是R和S笛卡儿积的一个子集。连接运算常用的主要有两种:等值连接和自然连接。
1)等值连接
对于关系R和S,假设F和M分别是关系模式R和S的属性子集,如果按照F和M进行连接,则R和S的等值连接表示为:
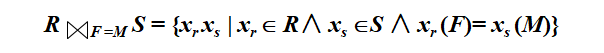
xrxs表示由元组xr和xs连接起来而构成的新元组。等值连接R S是R和S笛卡儿积的一个子集,子集中的元组在F和M上的取值相等。
2)自然连接
自然连接是一种特殊的等值连接,它是在等值连接的基础上加上两个条件:
(1)参与比较的属性子集F 和M 必须是相同的,即F=M;
(2)形成的新关系中不允许存在重复的属性,如果有则去掉。R和S的自然连接可以表示为: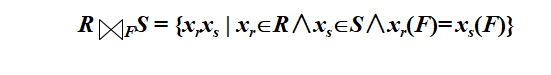
F是关系R和S都包含的属性(组)。
表2.9和表2.10所示的两个关系,分别表示学生的基本信息和学生的考试成绩。

等值连接stu_info⋈ 年龄=高数grade和stu_info⋈ 姓名=姓名grade以及
自然连接stu_info ⋈ 姓名grade的结果分别见表2.11、表2.12和表2.13所示。
从这三个结果的对比中读者不难比较这几种连接的区别。

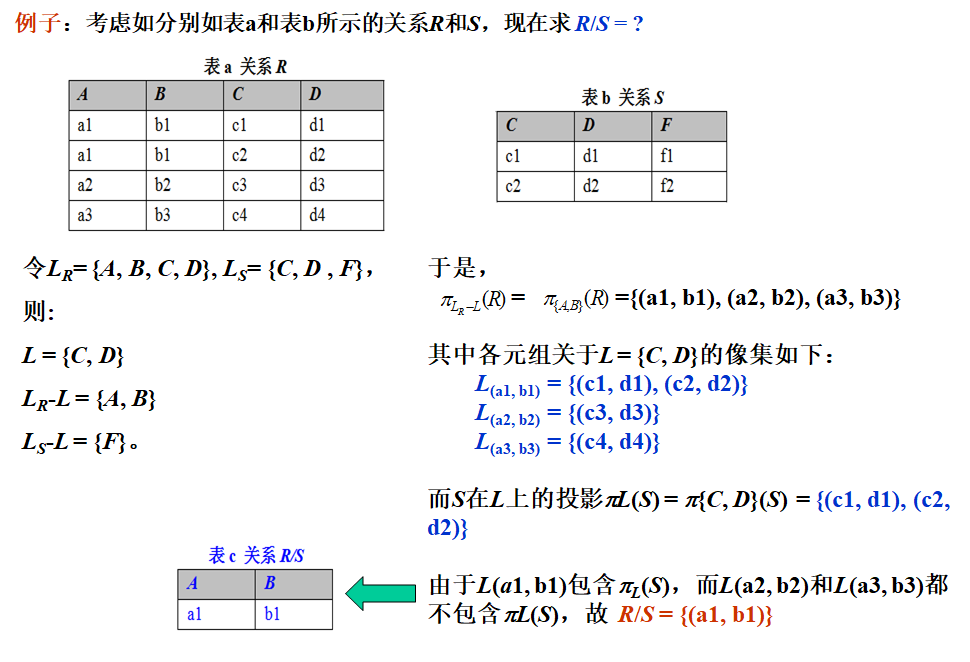
4. 除/
对于关系模式R(LR)和S(LS),约定:
LR --- R的属性集
LS --- S的属性集
L = LR ∩LS (即L表示关系R和关系S的公共属性)
Lx = {t(L) | t∈R∧t(LR-L)=x} (其中,x∈πLR -L(R) ,Lx称为x在R中关于L的像集)
R和S的除运算产生一个新关系R/S:
该新关系由投影 x∈πLR -L(R)中的某些元组组成,这些元组在R中关于L的像集包含S在L上的投影πL(S)。即:
![]()
相同部分所在行
2.3 关系数据库
l 2.3.1 关系数据库的概念
关系数据库(Relation database)是以关系模型为基础的数据库,它是利用关系来描述实体及实体之间的联系。简单地说,一个关系数据库是若干个关系的集合。一个关系可表示为一张二维表(也称数据表),一个关系数据库也可以理解为若干张二维表的集合。
Ø 一张数据表是由一系列的记录(行)组成,每一条记录由若干个数据项组成。数据项也是前面讲到的字段值、属性值,是关系数据库中最小的数据单位,不能再分解。
Ø 每一张数据表都有自己的表名。在同一个数据库中,表名唯一。当要访问数据库中的某一个数据项时,先通过表名找到相应的数据表,然后检索到该数据项所在的记录,最后通过记录访问到该数据项。
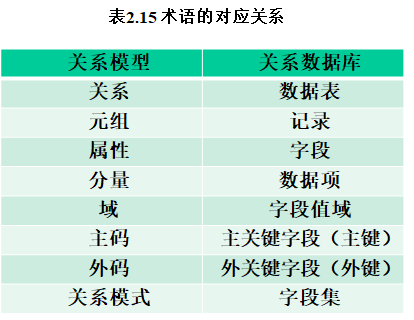
Ø “元组”、“分量”等概念多用于描述关系模型,可理解为理论范畴中的概念;而“记录”、“数据项”则分别是“元组”、“分量”在关系数据库中的映象,理解为它们的实例化对象。它们基本上是对应的。这种对应关系说明如表2.15所示(但这种对应关系不是严格的,在使用中要视上下文而定)。
• 2.3.2 关系数据库的特点
关系数据库的主要特点和优点包括:
Ø 具有较小的数据冗余度,支持创建数据表间的关联,支持较为复杂的数据结构。
Ø 应用程序脱离了数据的逻辑结构和物理存储结构,数据和程序之间的独立性高。
Ø 实现了数据的高度共享,为多用户的数据访问提供了可能。
Ø 提供了各种相应的控制功能,有效保证数据存储的安全性、完整性和并发性等,为多用户的数据访问提供了保证。
2.4 函数依赖
l 2.4.1 函数依赖的概念
定义2.3 设R(U)是属性集U上的一个关系模式,A, B ⊆ U,对于R(U)的任意一个可能的关系r,若关系r的两个元组x1, x2满足x1(A) = x2(A),则必有x1(B) = x2(B),那么A函数决定B,或称B函数依赖于A,记为A→B,A中的每个属性都称为决定因素(Determinant),其中x1(A)表示元组x1在属性集A上的取值。如果A→B且B→A,则记为A↔B;如果A→B不成立,则记为 A![]() B。
B。
Ø 函数依赖不是指关系模式R(U)的某一个或某一些关系满足的约束条件,而是指关系模式R(U)的所有关系均需要满足的约束条件。
【例2.2】表2.3所示的学生关系模式student(学号, 姓名, 性别, 专业号)。学号是不允许重复的,如果学号相同的两个学生元组在其他属性上的取值肯定相同,可以推出{学号} →{姓名}, {学号} → {性别}, {学号} → {专业号}。
l 属性间的这种函数依赖关系跟语义有关,它属于语义范畴的概念。
【例子】 如果不允许出现重名的学生元组,则可以有{姓名} →{学号},进而{学号} ↔ {姓名}。
l 如果属性集是由单个属性构成,标志集合的大括号“{”和“}”可以省略,如“{学号} →{姓名}”可以写成“学号→ 姓名”。
l 注意,在实际数据库开发中,可以从用户提供的需求说明中或是从基本常识中获取函数依赖关系,例如上述“学号→ 姓名”就是一个基本常识。
定义2.4 设R(U)是属性集U上的一个关系模式,A,B ⊆ U。若A→B是一个函数依赖,如果B→A,则称A→B为一个平凡函数依赖;如果B⊄A,则称A→B为一个非平凡函数依赖。
Ø 对于任意B⊆A,显然有A→B,它是一种平凡函数依赖。
【例子】“{学号, 姓名} → 姓名”是一种平凡函数依赖。由于平凡函数依赖没有实际意义,一般不予以讨论,在默认情况下提到的函数依赖均指非平凡函数依赖。
定义2.5 设R(U)是属性集U上的一个关系模式,A, B ⊆ U。若A→B是一个函数依赖,并且对于任意C ⊆ A且C非空,均有C![]() B,则称A→B是一个完全函数依赖(Full functional dependency),即B完全函数依赖于A,记为A
B,则称A→B是一个完全函数依赖(Full functional dependency),即B完全函数依赖于A,记为A B;否则称A→B是一个部分函数依赖(Partial functional dependency),即B部分函数依赖于A,记为A
B;否则称A→B是一个部分函数依赖(Partial functional dependency),即B部分函数依赖于A,记为A![]() B。
B。
【例2.3】表2.5所示的选课关系模式SC(学生编号,课程编号,成绩),{学生编号, 课程编号} 成绩,因为学生编号 成绩且课程编号 成绩。又如,表2.3所示学生关系模式student(学号, 姓名, 性别, 专业号),{学号, 姓名} 性别,确实有{学号, 姓名} → 性别,但学号→性别。
Ø 对于函数依赖A→B,如果A只包含一个属性,则必有A B中,因为这时的A不存在非空真子集。
定义2.6 设R(U)是属性集U上的一个关系模式,A, B, C Í U。若A→B (B⊄A, B ![]() A),且B→C成立,则称C传递函数依赖于A,记为A
A),且B→C成立,则称C传递函数依赖于A,记为A  C。
C。
Ø 注意,此处加上条件B ![]() A,是因为如果B→A,则实际上变为A↔B,即A→C,而不是A
A,是因为如果B→A,则实际上变为A↔B,即A→C,而不是A ![]() C。
C。
【例2.4】 对于关系模式—分班(学号, 班级号, 班长),容易知道学号→ 班级号,班级号→ 班长,又因为班级号![]()
学号,于是学号  班长。
班长。
• 2.4.2 候选码和主码
定义2.7 在关系模式R(U)中,假设A ⊆ U,如果A U,则A称为关系模式R(U)的一个候选码;候选码可能有多个,从候选码中选择一个用于唯一标识关系中的每一个元组,则该候选码称为主码(Primary key)。
Ø 含在任何候选码中的属性称为主属性(Prime attribute),不包含在任何码中的属性称为非主属性(Nonprime attribute)。通常将主码和候选码都简称为码。最简单的情况,单个属性构成码;最极端的情况,一个关系模式的所有属性构成码,称为全码(All key)。
Ø 对于候选码和主码,需要说明几点:
• 为正确理解候选码A,应该紧紧抓住其以下两个特性:
A可以函数决定U,即A→U。
A具有极小性,即A的任何真子集都不可能函数决定U。
• 候选码可能有多个。如果有多个候选码,则它们的地位是平等的,任何一个都可以被设置为主码。在应用当中,一般是根据实际需要来将某一个候选码设置为主码。
定理2.1 在关系模式R(U)中,对任意A, B ⊆U且A ∪ B = U,如果A B,则有A U,从而A是关系模式R(U)的一个候选码。
【例2.5】 考虑如表2.16所示的学生成绩关系模式,其中U = {学号, 姓名,系别,成绩}。对于属性“学号”,容易验证:学号 {姓名,系别,成绩},而{学号}∪{姓名,系别,成绩} = U。根据定理2.1,“学号”是学生成绩关系模式的一个候选码。
• 2.4.3 函数依赖的性质(Armstrong公理系统)
Ø 1974年Armstrong首次提出了这样的一套推理规则,由此构成的系统就是著名的Armstrong公理系统。
Ø 在关系模式R(U)中,假设A, B, C, D为U的任意子集。在Armstrong公理系统中,基于函数依赖集F的推理规则可以归结为以下3条:
ü 自反律:若C ⊆ B,则B→C为F所蕴含(平凡函数依赖)。
ü 增广律:若B → C为F所蕴含,则B∪D→C∪D为F所蕴含。
ü 传递律:若B→C且C→D为F所蕴含,则B→D为F所蕴含。
Ø 基于上述的推理规则,进一步得到下列的推理规则:
ü 自合规则:B→B。
ü 合并规则:若B→C且B→D,则B→C∪D。
ü 分解规则:若B→C∪D,则B→C且B→D。
ü 符合规则:若A→B且C→D,则A∪C→B∪D。
ü 伪传递规则:由B→C,A∪C→D,有A∪B→D。
定理2.2 在关系模式R(U)中,B及B1, B2,…, Bn是U的子集,则B→B1∪B2∪…∪Bn成立的充分必要条件是B→Bi成立,其中i = 1,2,…,n。
2.5 关系模式的范式
Ø 范式一共分为六个等级,从低到高依次是第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、BC范式(BCNF)、第四范式(4NF)和第五范式(5NF)。
Ø 高等级范式是在低等级范式的基础上增加一些约束条件而形成的,等级越高,范式的约束条件就越多,要求就越严格。各种范式之间的包含关系可以描述如下:
5NF ⊆ 4NF ⊆ BCNF ⊆ 3NF ⊆ 2NF ⊆ 1NF
Ø 通过模式分解,可以将一个低级别的范式转化为若干个高一级的范式,而这种转化过程称为规范化。
• 2.5.1 第一范式(1NF)
定义2.8 设R(U)是一个关系模式,U是关系R的属性集,若U中的每一个属性a的值域只包含原子项,即不可分割的数据项,则称R(U)属于第一范式,记为R(U)∈1NF。
【例子】表2.17所示。该数据表所对应的关系模式不属于第一范式,因为其中每个元组在“学生人数”属性上的属性值都不是原子项,它们都可以再分,实际上它们都是由两个原子项复合而成。为将其转化为第一范式,需要将复合项(非原子项)分解为原子项即可,结果如表2.18所示。

【例2.6】假设有一个研究生信息管理系统,该系统涉及的信息主要包括导师信息、研究生信息以及所选课程信息(supervisor, student, course)等。设计了如下的一个关系模式: SSC(学号, 姓名, 系别, 导师工号, 导师姓名, 导师职称, 课程名称, 课程成绩) 。
根据常识可以知道:
• 一位研究生只有一位导师(不含副导师),但一位导师可以指导多位研究生;
• 一位研究生可以选修多门课程,一门课程也可以被多位研究生选修;
• 一位研究生选修一门课程后有且仅有一个成绩;
• 不同的课程,课程名是不相同的,即课程名是唯一。
基于以上语义信息可以知道:
• 学号→{姓名, 系别}
• 学号→导师工号
• 导师工号→{导师姓名, 导师职称}
• {学号, 课程名称}→课程成绩
Ø根据Armstrong公理及定理2.2可以推知:
{学号, 课程名称}→{学号, 姓名, 系别, 导师工号, 导师姓名, 导师职称, 课程名称, 课程成绩}
Ø且可以进一步推知:
{学号, 课程名称} {学号, 姓名, 系别, 导师工号, 导师姓名, 导师职称, 课程名称, 课程成绩}
Ø根据定义2.7,{学号, 课程名称}是关系模式SSC的候选码,实际上是唯一的候选码,所以故只能选择它为模式的主码。
关系模式SSC存在的缺点:
• 数据冗余
关系中每个元组既包含研究生信息,也包含导师信息以及所选课程的信息。一位导师可指导多名研究生,每个研究生对应的元组都包含同一个导师的相同信息。一位导师带有多少名研究生就有多少条重复的导师信息。造成了数据冗余,如果数据量很大,就会浪费大量的存储空间,为这些数据的维护付出巨大的代价。
• 插入异常
假设某个老师刚刚被聘为研究生导师,但还没有招收学生(这种情况经常出现),这时也就没有他的研究生信息和研究生选修课程的信息,意味着“学号”和“课程名称”等属性的属性值为空(null)。如果这时在关系SSC中插入该导师的信息,则会产生异常。因为属性“学号”和“课程名称”是主码,其取值不能为空。这种异常就是插入异常。插入异常的存在使得添加导师信息的操作无法完成。
• 删除异常
假设某个导师刚招收了两名研究生,但过了一个学期以后,这两个研究生都因出国而注销学籍了。注销时,将这两个研究生对应的元组从关系SSC中删除(全部删除)。由于删除操作是以元组为单位进行的,所以导师信息也将全部被删除,以后就无法使用该导师的信息了,称为删除异常。
关系模式SSC还容易产生数据不一致等其他的一些问题。仅满足第一范式的关系模式确实还存在许多问题。人们在第一范式的基础上增加一些约束条件,从而得到第二范式。
2.5.2 第二范式(2NF)
定义2.9 设R(U)是一个关系模式,如果R(U)∈1NF且每个非主属性都完全函数依赖于任一候选码,则称R(U)属于第二范式,记为R(U)∈2NF。
l 第二范式是在第一范式的基础上,增加了条件“每个非主属性都完全函数依赖于任一候选码”,它比第一范式具有更高的要求。
l 如果一个关系模式的候选码都是由一个属性构成,该关系模式肯定属于第二范式,此时每个非主属性都显然完全函数依赖于任一候选码。
l 如果一个关系模式的属性全是主属性,则该关系模式也肯定属于第二范式,此时不存在非主属性。
【例2.7】例2.6中的关系模式SSC(学号, 姓名, 系别, 导师工号, 导师姓名, 导师职称, 课程名称, 课程成绩)。该关系的唯一候选码为{学号, 课程名称},因此“姓名”, “系别”, “导师工号”, “导师姓名”, “导师职称”, “课程成绩”等6个属性为其非主属性。不存在“学号”相同而“姓名”不同的研究生元组,“姓名”函数依赖于“学号”,即“学号→ 姓名”。非主属性“姓名”并非完全函数依赖于码{学号, 课程名称},此关系模式不属于第二范式。
Ø 因为关系模式SSC仅属于第一范式而不属于第二范式,这决定了它还存在数据冗余、插入异常和删除异常等问题。我们通过模式的投影分解,将之分解为若干个子模式,使得每个子模式都属于第二范式,从而解决上述问题。
Ø 先考察关系模式SSC中的函数依赖:
ü 学号→姓名
ü 学号→系别
ü 学号→导师工号
ü 导师工号→导师姓名
ü 导师工号→导师职称
ü {学号, 课程名称} 课程成绩
l 由于“学号”和“导师工号”都是单属性,因此上述函数依赖都是完全函数依赖,一共有三种类型,因此在进行投影分解后可得到如下的三个关系模式:
Ø Student(学号, 姓名, 系别, 导师工号)
Ø supervisor(导师工号, 导师姓名, 导师职称)
Ø course(学号, 课程名称, 课程成绩)
l 这三个关系模式的码分别为学号、导师工号和{学号, 课程名称},每个关系模式中非主属性都完全函数依赖于码。这三个关系模式都属于第二范式。
l 利用基于外码的自然连接可以将这三个关系合成原来的关系SSC,即 SSC = student⋈ 导师工号supervisor ⋈学号course。外码的设置如:“导师工号”是student的关于supervisor的外码,“学号”是course的关于student的外码。
l 一个关系模式的码都是由一个属性构成,该关系模式肯定属于第二范式,因为这时每个非主属性都显然完全函数依赖于码。
【例2.8】设有关系模式teacher(课程名, 任课教师名, 任课教师职称),表2.19为关系模式teacher的一张关系表。假设每名教师可以上多门课,每门课只由一名教师上,请问关系模式teacher属于几范式?
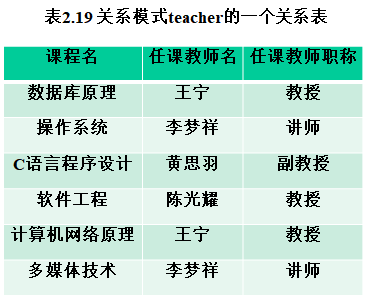
关系模式teacher的候选码只有“课程名”,而“任课教师名”和“任课教师职称”都是非主属性。显然有函数依赖集{课程名→任课教师名, 任课教师姓名→任课教师职称, 课程名任课教师职称},即每个非主属性都完全依赖于候选码,故关系模式teacher属于2NF。
上例中关系模式teacher属于2NF,仍存在数据冗余和插入、删除操作异常。
【例子】若某任课教师上多门课,则需要在teacher表中存储多次该教师的职称信息(数据冗余);对于一个新来教师,如果其还没有排课,那么将无法输入该教师的信息,因为课程名作为主码不能为空(插入异常);又如删除一个任课教师的所有任课记录,则找不到该任课教师姓名和职称信息了(删除异常)。导致这种数据冗余和操作异常的原因在于该关系模式中存在传递函数依赖,这将在2.5.3节举例说明。
2.5.3 第三范式(3NF)
定义2.10 设R(U)是一个关系模式,如果R(U)∈2NF且每个非主属性都不传递函数依赖于任一候选码,则称R(U)属于第三范式,记为R(U)∈3NF。
注意,如果一个关系模式的属性全是主属性,那该关系模式肯定属于第三范式,因为该关系模式不存在非主属性。
【例2.9】假设有一个关于学生选课信息的关系模式——s_c(学号, 课程号, 名次),其相关语义是:学号和课程号分别是学生和课程的唯一标识属性,每一名学生选修的每门课程有一个名次,且名次不重复。
Ø 其函数依赖包括:{学号, 课程号} → 名次,{课程号, 名次} → 学号。{学号, 课程号}和{课程号, 名次}是此关系的候选码。其所有的属性都是主属性,此关系模式属于第三范式。
l 第三范式是在第二范式的基础上,增加了条件“每个非主属性都不传递函数依赖于任一候选码”而得到的。
【例2.10】假设有一个关于员工信息的关系模式:emp_info(Eno, Ename, Dept, Dleader)。其中,Eno为员工编号,Ename为员工姓名,Dept为员工所在部门,Dleader为部门领导。请说明该关系模式属于第几范式以及它存在的问题。
Ø 员工编号是唯一的,每个员工只属于一个部门,每个部门只有一个领导(这里假设领导不属于员工范畴,且不考虑纵向领导关系)。员工编号(Eno)为唯一的码,由此容易推出:
Eno → Ename
Eno → Dept
Eno → Dleader
Ø 显这些函数依赖都是完全函数依赖。这些函数依赖说明了所有非主属性都完全函数依赖于码Eno,所以关系模式emp_info属于第二范式。但该关系模式还存在下列的函数依赖:
Eno→Dept
Dept→Dleader
Eno→Dleader
l 上述说明非主属性Dleader传递函数依赖于码Eno,即关系模式emp_info中存在传递函数依赖,它不属于第三范式。传递函数依赖的存在同样会导致一定程度的数据冗余以及插入异常和删除异常等问题。这体现在:
Ø 一个部门有多个员工,每一个员工在关系emp_info中都形成一个元组。该元组除了包含员工编号和姓名外,还包含所在部门和部门领导的信息。后两项信息会多次重复出现,重复的次数与部门的员工数相等。这是数据冗余的根源。
Ø 数据冗余的存在导致数据维护成本增加。
Ø 当一个部门刚成立时,如果还没有招员工,那么将无法输入部门和部门领导的信息(主码Eno的输入值不能为null)。这就造成了插入异常。
Ø 出于某些原因,部门的员工可能全部辞职,或者暂时全部转到其他部门去时,需要将所有的员工信息全部删除,这时部门和部门领导的信息也将被删除。这就导致了删除异常。
l 为消除传递函数依赖,可以使用投影分解法将关系模式分解成相应的若干个模式
【例子】根据存在的传递链“Eno→Dept→Dleader”,可以从节点“Dept”上将此传递链切开,形成以下两个模式:
emp_info2(Eno, Ename, Dept)
dept_info2(Dept, Dleader)
关系模式emp_info2的码为Eno,dept_info2的码为Dept。
l 在消除传递函数依赖后得到的两个关系模式emp_info2和dept_info2都属于第三范式,它们当中都不存在传递函数依赖。
【例子】可以在没有员工信息的前提下插入部门信息;可以删除所有的员工信息而不影响部门信息;数据冗余度也有所降低了,从而也简化了其他的一些操作等。
l 属于3NF的关系模式主要是消除了非主属性对于候选的传递函数依赖和部分函数依赖,但并没有考虑主属性和候选码之间的依赖关系。它们之间存在的一些依赖关系也会引起数据冗余和操作异常等问题。人们提出了更高一级的范式——BC范式。
2.5.4 BC范式(BCNF)
定义2.11 设R(U)是一个关系模式且R(U) ∈1NF,如果对于R(U)中任意一个非平凡的函数依赖B→C,B必含有候选码,则称R(U)属于BC范式,记为R(U)∈BCNF。
l 如果要求B→C为非平凡的且完全的,则要求该函数依赖的决定因素为候选码即可。
l 在BC范式的定义中并没有明确提出其中的关系要属于3NF,但是该定义确实保证了“其非主属性既不部分函数依赖于候选码,也不传递函数依赖于候选码”,因而BCNF为3NF的一个子集,即BCNF⊆3NF。
对于BC范式中的每一个关系R(U),它们具有下列的性质:
u R(U)中的每一个非主属性都完全函数依赖于任何一个候选码。假设存在一个非主属性attr部分函数依赖于一个候选码B0,即B0 →^p attr。由部分函数依赖的定义,必存在B0的一个真子集B0′,使得B0′→attr。由于B0′→attr是一个非平凡函数依赖。根据BCNF的定义,B0′必包含某一个候选码C0。由于候选码B0的真子集包含该候选码C0,所以B0也包含C0且C0异于B0。这说明一个候选码包含一个异于自己的另外一个候选码,这是不可能的。
u R(U)中的每一个主属性完全函数依赖于任何一个不包含它的候选码。假设存在一个主属性attr并非完全函数依赖于某一个不包含它的候选码B0。当选择该候选码B0为主码时,attr也不完全函数依赖于主码B0。这与主码的定义相矛盾。
u R(U)中没有属性完全函数依赖于非候选码(包括主码)的属性集。假设存在一个异于任何一个候选码的属性集B0和某一个属性attr,使得属性attr完全函数依赖于B0,即B0 attr。但由于B0 →^f attr,所以显然有B→attr。由BCNF的定义,B0必包含某一个候选码C0。因为B0异于任何一个候选码,所以B0≠C0,因而B0真包含C0,C0为B0的一个真子集。由于C0为候选码,所以C0→attr。这说明,存在B0的一个真子集C0,使得C0→attr。但这与B0 →^f attr相矛盾。
定理2.3 设R(U)是一个关系模式,且R(U)Î3NF,如果R(U)只有一个候选码,则R(U)ÎBCNF。
证明:对于R(U)中任意一个非平凡函数依赖C→D,假设R(U)唯一的候选码为B,只要证明C包含B即可。
假设C不包含B,即B ⊄ C。由于B为候选码,所以B →^f U,进而可知B→U。因为C和D都为U的子集,所以由Armstrong公理,U→C,U→D,于是B→C,B→D;由于C→D为非平凡函数依赖,所以D ⊄C;由于C是任意的,所以C B;加上条件假设B Ë C,于是:
D ⊄ C,B ⊄ C,C →/ B
B→C
C→D
B→D
D传递依赖于B,这与R∈3NF矛盾。证毕。
特别地,在一个属于3NF的关系中,当仅有一个属性能够唯一标识每个元组时,则这个关系属于BCNF,且该属性为唯一的候选码(也只能以它为主码)。
【例2.11】观察例2.10中分解后形成的关系模式:emp_info2(Eno, Ename, Dept)
u 该关系模式中既没有部分函数依赖也没有传递依赖,所以属于3NF。且由于仅有唯一的属性Eno能够唯一标识每一个元组,所以这个关系属于BCNF。
u 定理2.3看起来非常简单,但它非常有用。在许多情况下,设计的关系往往都是有且仅有一个能够唯一标识每一个元组的属性,这时只要保证不存在对该属性的部分函数依赖和传递函数依赖即可保证该关系属于BCNF,而不用对BCNF的定义进行验证,从而避免了复杂的验证过程,提高设计效率。
u 定理2.3中的条件只是一个关系属于BCNF的充分条件,但不是必要条件。也就是说,满足该定理条件的关系必属于BCNF,但不满足该定理条件的关系也可能属于BCNF,如例2.12。
【例2.12】 对于学生住宿关系模式StuDom(学号, 姓名系别, 宿舍)而言,假定“姓名”属性也具有唯一性,那么关系模式StuDom拥有两个由单属性组成的候选码,分别是“学号”和“姓名”。由于非主属性,即“系别”和“宿舍”,不存在对任一候选码的部分或传递函数依赖,所以关系模式StuDom属于第三范式。同时关系模式StuDom中除“学号”和“姓名”外没有其它决定因素,所以StuDom关系模式属于BC范式。
u此例中,关系模式StuDom有两个候选码,分别是“学号”和“姓名”,而不是只有一个候选码(不满足定理2.3的条件),但它却属于BC范式。
u那么有没有属于第三范式的关系模式却不属于BC范式的情况呢?
【例2.13】对教学关系模式Teach(学生, 教师, 课程),若每一名教师只教授一门课,每门课可由多名任课教师教授,某一名学生选定某门课即对应一个固定的教师。得到下述函数依赖集:
{学生, 课程}→教师
{学生, 教师}→课程
教师→课程
Ø {学生, 课程}和{学生, 教师}均是候选码。因为没有任何非主属性对码的传递函数依赖或部分函数依赖,故关系模式Teach属于三范式。关系模式Teach不属于BC范式,因为函数依赖“教师→课程”的决定因素——“教师”不含任一候选码。
u 如果一个关系模型中的关系模式都属于BCNF,则称该关系模型满足BCNF,称基于该关系模型的关系数据库满足BCNF。
u 一个满足BCNF的关系数据库已经极大地减少数据的冗余,对所有关系模式实现了较为彻底的分解,消除了插入异常和删除异常,已经达到了基于函数依赖为测度的最高规范化程度。
2.6 关系模式的分解和规范化
l 2.6.1 关系模式的规范化
Ø 关系模式的规范化实际上就是通过模式分解将一个较低范式的关系模式转化为多个较高范式的关系模式的过程。
从范式变化的角度看,关系模式的规范化是一个不断增加约束条件的过程;
从关系模式变化的角度看,规范化是关系模式的一个逐步分解的过程。
Ø 关系模式的分解是关系模式规范化的本质问题,其目的是实现概念的单一化,即使得一个关系仅描述一个概念或概念间的一个种联系。通过分解可以将一个关系模式分成多个满足更高要求的关系模式,这些关系模式可以在一定程度上解决或缓解数据冗余、更新异常、插入异常、删除异常等问题。
Ø 关系模式分解实际上又是一个关系模式的属性投影和属性重组的过程,又称投影分解。投影和重组的基本指导思想是逐步消除数据依赖中不适合的成分,结果将产生多个属于更高级别范式的关系模式。
u 投影分解的步骤就是低级范式到高级范式转化的步骤,具体步骤是:
Ø 基于消除关系模式中非主属性对候选码的函数依赖的原则,对1NF关系模式进行合理的投影(属性重组),结果将产生多个2NF关系模式。
Ø 基于消除关系模式中非主属性对候选码的传递函数依赖的原则,对2NF关系模式进行合理的投影,结果将产生多个3NF关系模式。
Ø 基于消除关系模式中主属性对候选码的传递函数依赖的原则,对3NF关系模式进行合理的投影,结果将产生多个BCNF关系模式。
2.6.2 关系模式的分解
• 连接无损分解
定义2.12 假设一个关系模式R(U)被分解成n个子关系模式:R1(U1),R2(U2),…, Rn(Un),其中U = R1(U1)∪R2(U2)∪…∪Rn(Un),并假设r, r1, r2,…, rn分别属于关系模式R(U)及n个子关系模式的关系(二维表),如果这n个子关系的自然连接与原关系r相等,即r = r1 ⋈ r2 ⋈ … ⋈ rn,那么这种分解称为(自然)连接无损分解,其中ri是r在Ui上的投影, i = 1,2,…n。
Ø 分解的基本思想之一是消除对候选码的部分函数依赖和传递函数依赖。我们可以先在待分解的关系模式中找出这些部分函数依赖和传递函数依赖以及完全函数依赖,然后“分解”部分函数依赖和传递函数依赖,使得这些函数依赖最终都变成完全函数依赖,最后将这些完全函数依赖所涉及的属性分别投影成新的关系即可。
【例2.14】对于例2.6中的关系模式SSC(学号, 姓名, 系别, 导师工号, 导师姓名, 导师职称, 课程名称, 课程成绩),请运用模式分解方法将其转化为若干个属于BC范式的关系模式。
Ø 关系模式SSC中唯一的候选码为{学号, 课程名称}。我们先找出对候选码的所有完全函数依赖、部分函数依赖和传递函数依赖:
• {学号, 课程名称} 课程成绩
• {学号, 课程名称} {姓名, 系别}
• {学号, 课程名称} 导师工号
• 导师工号 {导师姓名, 导师职称}
• {学号, 课程名称} {导师姓名, 导师职称}
u 以下找出部分函数依赖中的完全函数依赖:
由“{学号, 课程名称} {姓名, 系别}”得到“学号 {姓名, 系别}”
由“{学号, 课程名称} 导师工号 ”得到“学号 导师工号”
u 我们根据以上所有的完全函数依赖初步设定分解成的各关系模式(原则是“一个完全函数依即为一个关系模式”):
Ø T1(学号, 课程名称, 课程成绩)
Ø T2(导师工号, 导师姓名, 导师职称)
Ø T3(学号, 姓名, 系别)
Ø T4(学号, 导师工号)
u 为了减少数据冗余和减少数据维护的复杂性,可以将关系模式T4(学号, 导师工号)并到T3(学号, 姓名, 系别)中,从而形成新的关系模式——T3′(学号, 姓名, 系别, 导师工号)。这样,就得到如下的分解结果:
Ø T1(学号, 课程名称, 课程成绩)
Ø T2(导师工号, 导师姓名, 导师职称)
Ø T3′(学号, 姓名, 系别, 导师工号)
u 由定理2.3稍加分析可以知道,以上三个关系模式均属于BC范式,而且上述的分解是连接无损分解。
定理2.4 假设S和T为关系模式R分解后所得到的两个关系模式,则该分解为连接无损分解的充分必要条件是:(S∩T) → (S-T)或(S∩T) → (T-S)
2. 保持函数依赖的分解
定义2.13 设R(U)是一个关系模式,F为R(U)的一个函数依赖集,B,C为R(U)所涉及的属性集的子集。如果利用Armstrong公理系统中的推理规则能够从函数依赖集F中推出B→C,则称F逻辑蕴涵B→C。F所逻辑蕴涵的函数依赖的集合称为F的闭包,记为F+。
定义2.14 设一个关系模式R(U)被分解成n个关系模式:R1, R2,…, Rn,F为R(U)的属性间函数依赖的集合,F1, F2,…, Fn分别为F在R1, R2,…, Rn上的投影。对于任意F所逻辑蕴涵的函数依赖B→C,总存在某一个Fi,使得Fi逻辑蕴涵B→C,则这种分解称为保持函数依赖的分解。
3. 既保持函数依赖又具有自然连接无损的分解
Ø 连接无损分解和保持函数依赖的分解是两个相互独立的模式分解。但它们的优缺点具有一定的互补性。
Ø 连接无损分解可以保证分解所得到的关系模式经过自然连接后又得到原关系模式,不会造成信息的丢失。这种分解可能带来数据冗余、更新冲突等问题。
原因:连接无损分解不是按照关系模式所蕴涵数据语义来进行分解。而保持函数依赖的分解则正好是按照数据语义来进行分解,它可以使分解后的关系模式相互独立。避免由连接无损分解带来的问题,但它在某些情况下可能造成信息丢失。一个自然的想法就是构造这样的分解:该分解既是保持函数依赖的分解,又具有自然连接无损的特性。这种分解就称为既保持函数依赖又具有自然连接无损的分解。
【例2.15】 考虑例2.10中的关系模式:emp_info(Eno, Ename, Dept, Dleader)
Ø Eno为员工编号,Ename为员工姓名,Dept为员工所在部门,Dleader为部门领导。如果将该关系模式分解为:emp_info1(Eno, Ename, Dept)和emp_info2(Eno, Dleader)。易验证,这种分解虽然是连接无损分解,但会造成数据冗余、更新异常等问题。进一步分析还可以发现,该分解不保持函数依赖。例如,函数依赖Dept→Dleader既不被emp_info1的函数依赖集所逻辑蕴涵,也不为emp_info2的函数依赖集所逻辑蕴涵。
Ø 现在我们将关系模式emp_info(Eno, Ename, Dept, Dleader)分解成如下的两个模式:
emp_info2(Eno, Ename, Dept)
dept_info2(Dept, Dleader)
Ø 可以验证,这种分解方法保持了函数依赖,同时又具有自然连接无损的特性,它是既保持函数依赖又具有自然连接无损的分解。
