第7章 数据库的创建和管理
• 7.1数据库和数据库文件
7.1.1 数据库的组成
从操作系统的角度看,作为存储数据的逻辑对象,数据库最终是以文件的形式保存在磁盘上。这些文件就是所谓的数据库文件。数据库文件又分为数据文件和日志文件。
数据文件是数据库用于存储数据的操作系统文件,它保存了数据库中的全部数据。数据文件又分为主数据文件和次要数据文件。主数据文件是数据库的起点,指向数据库的其他文件。每个数据库有且仅有一个主数据文件,而次要数据文件可以有多个或没有。主数据文件的默认扩展名是.mdf,次要数据文件的默认扩展名是.ndf。
日志文件记录了针对数据库的所有修改操作,其中每条日志记录可能是记录了所执行的逻辑操作,也可能记录了已修改数据的前像和后像。前像是操作执行前的数据复本;后像是操作执行后的数据复本。日志文件包含了用于恢复数据库的所有日志信息。利用日志文件,可以在数据库出现故障或崩溃时把它恢复到最近的状态,从而最大限度地减少由此带来的损失。在创建数据库的时候,默认创建一个日志文件被,其推荐的文件扩展名是.ldf。每个数据库至少有一个日志文件,当然也可以有多个。
数据文件和日志文件可以保存在FAT或NTFS文件系统中。但从安全性角度考虑,一般使用NTFS文件系统保存这些文件。数据文件名和日志文件名是面向操作系统的,即操作系统是通过这些名称来访问数据文件和日志文件。
从逻辑结构看,数据库是数据表的集合,此外数据库还包含索引、视图等“附属部件”,数据表、索引、视图等统称为数据库对象。在创建数据库的时候,我们要给数据库输入一个合法的字符串作为数据库的名称,这个名称简称为数据库名。
数据库名是数据库的逻辑名称,应用程序对数据库对象的访问必须通过数据库名来完成,即数据库名是面向应用程序的(而非操作系统,数据库文件是面向操作系统的)。另外,支撑数据库的数据文件和日志文件也有面向应用程序的名称,分别称为数据文件和日志文件的逻辑文件名。通过逻辑文件名,SQL语句就可以有限度地访问和操作数据文件和日志文件。为了区别于逻辑文件名,数据文件和日志文件对应的磁盘文件(即.mdf文件、.ndf文件、.ldf文件)称为它们的物理文件名。
对于每个数据文件和日志文件,它们既有自己的逻辑文件名(面向应用程序),也有自己的物理文件名(面向操作系统)。在SQL Server 2014中,当创建数据库时会自动生成一个主数据文件和一个日志文件。在默认情况下,主数据文件的逻辑文件名与数据库名(数据库名由用户设置)相同,其物理文件名等于其逻辑文件名加上扩展名“.mdf”;日志文件的逻辑文件名等于数据库名加上“_log”,日志文件的物理文件名等于数据库名加上“_log.ldf”。
【例子】 当创建一个名为MyDatabase的数据库时,会自动形成一个主数据文件和一个日志文件,其默认的逻辑文件和物理文件名如表7.1所示。

7.1.2 文件组
文件组是数据文件的一种逻辑划分。文件组就是将若干个数据文件放在一起而形成的文件集。
文件组有两种类型:主文件组(PRIMARY)和用户定义文件组。
主文件组包含主数据文件和任何没有明确指定文件组的其他数据文件。
用户定义文件组是用户利用Transact-SQL语句或者在SQL Server Management Studio(SSMS)中通过可视化操作创建的文件组。
一个文件组包含多个不同的数据文件,一个数据文件只能属于一个文件组。一个数据库至少有一个文件组(主文件组),也可能有多个文件组(至多为32767个文件组)。在一个数据库中,有且仅有一个文件组被指定为默认文件组。在数据库创建时主文件组会自动被设置为默认文件组,但我们也可以将用户定义文件组设置为默认文件组。在创建数据表或者其他数据库对象的时候,如果不显式指定文件组,那么这些数据库对象将自动在默认文件组上创建,即被建对象的所有页都在默认文件组中分配。
• 7.2 数据库的创建
7.2.1 创建数据库的SQL语法
创建数据库可用CREATE DATABASE语句来完成,其语法如下:
CREATE DATABASE database_name [ ON [ PRIMARY ] [ <filespec> [ ,...n ] [ , <filegroup> [ ,...n ] ] [ LOG ON { <filespec> [ ,...n ] } ] ] [ COLLATE collation_name ] [ WITH <external_access_option> ] ] [;]
其中,<filespec>、<filegroup>和<external_access_option>分别定义如下:
<filespec> ::= { ( NAME = logical_file_name , FILENAME = { 'os_file_name' | 'filestream_path' } [ , SIZE = size [ KB | MB | GB | TB ] ] [ , MAXSIZE = { max_size [ KB | MB | GB | TB ] | UNLIMITED } ] [ , FILEGROWTH = growth_increment [ KB | MB | GB | TB | % ] ] ) [ ,...n ] } ---------- <filegroup> ::= { FILEGROUP filegroup_name [ CONTAINS FILESTREAM ] [ DEFAULT ] <filespec> [ ,...n ] } ---------- <external_access_option> ::= { [ DB_CHAINING { ON | OFF } ] [ , TRUSTWORTHY { ON | OFF } ] }
语法参数说明如下:
database_name
database_name表示待创建数据库的名称,它在当前的实例中必须唯一,且要符合标识符规则,最大长度为128个字节。
ON
关键字ON用于指定数据文件,其后跟以逗号分隔的<filespec>项列表。该项列表用以定义主文件组的数据文件,主文件组的文件列表可后跟以逗号分隔的<filegroup>项列表。该项列表是可选项,用于定义用户文件组。
PRIMARY
PRIMARY则用于指定关联的<filespec>列表定义主文件。在主文件组的<filespec>项中指定的第一个文件将成为主文件,一个数据库只能有一个主文件。如果没有指定PRIMARY,那么database_name将成为主文件。
NAME
NAME用于为<filespec>定义的数据库文件指定逻辑名称,如果未指定逻辑名称则使用database_name作为逻辑名称。
FILENAME
FILENAME用于指定数据库文件的物理文件名(操作系统文件名,也称磁盘文件名)。如果未指定该名称则将NAME值(逻辑名称)后缀“.mdf”(对数据文件)或后缀“.ldf”(对日志文件)作为数据库文件的物理文件名,存储的路径可以根据需要来设定。
SIZE
SIZE用于指定数据库文件的初始大小,如果没有指定则采用默认值(数据文件的默认值为3MB,日志文件的默认值为1MB)。
MAXSIZE
MAXSIZE用于指定数据库文件能够增长到的最大值(最大文件大小)。如果取值为UNLIMITED则表示无穷大。实际上是受到磁盘空间的限制,在 SQL Server 2008 中,指定为UNLIMITED的日志文件的最大大小为2 TB,而数据文件的最大大小为16 TB。
FILEGROWTH
FILEGROWTH用于指定文件大小增长的幅度,可以用百分比,也可以用绝对数值,设置值为0时表明关闭自动增长功能,不允许自动增加空间。
LOG ON
LOG ON用于指定用于存储数据库日志的磁盘文件。LOG ON后跟以逗号分隔的<filespec>项列表,该项列表用于定义日志文件。如果没有指定LOG ON,将自动创建一个日志文件,其大小为该数据库的所有数据文件大小总和的25%或512KB,取两者之中的较大者。
FILEGROUP
FILEGROUP用于定义文件组,其中,filegroup_name为文件组的逻辑名称,在数据库中必须是唯一的,不能是系统提供的名称PRIMARY和 PRIMARY_LOG。名称可以是字符或 Unicode 常量,也可以是常规标识符或分隔标识符。名称必须符合标识符规则。 当待参数DEFAULT时,表示将该文件组设置为数据库中默认的文件组。
COLLATE
COLLATE用于指定数据库的默认排序规则。如果没有指定排序规则,则采用SQL Server实例的默认排序规则。排序规则名称既可以是Windows排序规则名称,也可以是SQL排序规则名称。
7.2.2 创建使用默认参数的数据库
由CREATE DATABASE的语法结构可以看出,除了database_name(数据库名)以外,其他的参数都是可选参数。因此,仅带database_name的CREATE DATABASE语句是最简单的形式,相应的简化语法如下:
CREATE DATABASE database_name;
这是最简单、也是较为常用的数据库创建方法,由此创建的数据库的参数都是使用默认设置。
【例7.1】 创建名为DB1的数据库,数据库的所有可选参数使用默认值。
这种数据库的创建方法最简单,相应代码如下:
CREATE DATABASE DB1;
执行上述代码,当显示“命令已成功完成。”的提示时,即可完成创建名为DB1的数据库,这是会自动生成一个数据文件DB1.mdf和一个日志文件DB1_log.ldf。除数据库名称以外,该数据库的其他参数都使用了默认初始值。
7.2.3 创建指定数据文件的数据库
出于某种需要,有时候需要创建一个数据库,使得它的数据文件名和日志文件名分别为给定的名称。这时需要在CREATE DATABASE语句中指定NAME和FILENAME项的值。
【例7.2】 创建既定数据文件名及其逻辑文件名的数据库。
假设数据库名为DB2,指定的数据文件的物理文件名和逻辑文件名分别DataFile2.mdf和LogicFile2,相应的CREATE DATABASE语句如下:
CREATE DATABASE DB2 ON PRIMARY( -- 设置数据文件的逻辑文件名 NAME='LogicFile2', -- 设置数据文件的物理文件名,注意,指定的目录D:datafiles必须是已经存在的目录,否则创建失败。
-- 另外,该目录下不能存在任何已有的同名文件 FILENAME = 'D:datafilesDataFile2.mdf' );
执行上述代码,当显示“命令已成功完成。”的提示时,即可完成创建名为DB2的数据库。该CREATE DATABASE语句中,没有指定日志文件信息,故会产生默认的日志文件DB2_log.ldf。
【例7.3】 创建指定数据文件名、日志文件名及相应逻辑文件名的数据库。
假设数据库名为DB3,指定的数据文件的物理文件名和逻辑文件名分别为DataFile3.mdf和LogicFile3,日志文件的物理文件名及其逻辑文件名分别为LogFile3.ldf和LogicLog3,则相应CREATE DATABASE语句如下:
CREATE DATABASE DB3 ON PRIMARY( -- 设置数据文件的逻辑文件名 NAME='LogicFile3', -- 设置数据文件的物理文件名 FILENAME = 'D:datafilesDataFile3.mdf' ) LOG ON( -- 设置日志文件的逻辑名称 NAME = 'LogicLog3', -- 设置日志文件的物理文件名 FILENAME = 'D:datafilesLogFile3.ldf' );
7.2.4 创建指定大小的数据库
这里的“大小”包含数据文件的设置初始大小、最大存储空间、自动增长幅度等。
【例7.4】 创建指定数据文件大小的数据库。
假设数据库名为DB4,指定的数据文件的物理文件名为DataFile4.mdf,逻辑名称为LogicFile4,该数据文件初始大小为5MB,最大值为100MB,自动增长幅度为15MB。相应的Transact-SQL语句如下:
CREATE DATABASE DB4 ON PRIMARY( -- 设置逻辑文件名 NAME = ' LogicFile4', -- 设置物理文件名 FILENAME ='D:datafilesDataFile4.mdf', SIZE = 5MB , -- 设置初始大小 MAXSIZE = 100MB, -- 设置数据文件的最大存储空间 FILEGROWTH = 15MB); -- 设置自动增长幅度
【例7.5】 创建指定数据文件和日志文件大小的数据库。
假设数据库名为DB5,指定的数据文件和日志文件的信息如下:
数据文件:其物理文件名为DataFile5.mdf,逻辑文件名为:LogicFile5,初始大小为10MB,最大值为200MB,自动增长幅度为20MB;
日志文件:其物理文件名为LogFile5.ldf,逻辑文件名为:LogicLog5,日志文件初始大小为10MB,最大值为100MB,自动增长幅度为初始大小的10%。
--创建此数据库的代码如下: CREATE DATABASE DB5 ON PRIMARY( -- 设置逻辑名称 NAME = ' LogicFile5', -- 设置数据文件名 FILENAME ='D:datafilesDataFile5.mdf', SIZE = 10MB , -- 设置初始大小 MAXSIZE = 200MB, -- 设置数据文件的最大存储空间 FILEGROWTH = 20MB) -- 设置自动增长幅度 LOG ON( -- 设置日志文件的逻辑名称 NAME = 'LogicLog5', -- 设置日志文件 FILENAME = 'D:datafilesLogFile5.ldf', SIZE = 10MB, -- 设置初始大小 MAXSIZE = 100MB, -- 设置数据文件的最大存储空间 FILEGROWTH = 10% -- 设置自动增长幅度 );
7.2.5 创建带多个数据文件的数据库
一个数据库至少有一个主数据文件,同时可能有多个次要数据文件。
【例7.6】 创建带两个数据文件的数据库。
假设待创建的数据库的名称为DB6,包含两个数据文件,它们的物理名称分别为DataFile6.mdf(主数据文件)和DataFile6.ndf(次要数据文件),对应的逻辑名称分别为LogicFile6_1和LogicFile6_2。
相应代码如下:
CREATE DATABASE DB6 ON PRIMARY ( NAME = ' LogicFile6_1', -- 主数据文件的逻辑名称 FILENAME = 'D:datafilesDataFile6.mdf' -- 主数据文件的物理名称 ), ( NAME = ' LogicFile6_2', -- 次要数据文件的逻辑名称 FILENAME = 'D:datafilesDataFile6.ndf ' -- 次要数据文件的物理名称 );
注意,在创建时,主数据文件和次要数据文件不是根据扩展名来确定的,而是根据先后顺序来确定。也就是说,紧跟关键字ON PRIMARY之后定义的数据文件为主数据文件,其余的为次要数据文件。
【例子】 如果使用下列代码创建DB6,则DataFile6.ndf将变成主数据文件,DataFile6.mdf为次要数据文件:
CREATE DATABASE DB6 ON PRIMARY ( NAME = ' LogicFile6_2', -- 主数据文件的逻辑名称 FILENAME = 'D:datafilesDataFile6.ndf ' -- 主数据文件的物理名称 ), ( NAME = ' LogicFile6_1', -- 次要数据文件的逻辑名称 FILENAME = 'D:datafilesDataFile6.mdf' -- 次要数据文件的物理名称 );
7.2.6 创建指定文件组的数据库
文件组包括主文件组(PRIMARY)和用户定义文件组。如果不指定文件组,则默认使用主文件组(PRIMARY)创建数据库,所有的数据文件都将被分到这个文件组中。我们也可以将数据文件划分到指定的用户定义文件组中,但主数据文件永远自动被划分到主文件组(PRIMARY)中。
【例7.7】 创建带用户定义文件组的数据库,并将相应的数据文件分配到该文件组中。
假设待创建的数据库的名称为DB7,使之带有用户定义文件组UserFG7_2和UserFG7_3,其中:
数据文件:物理文件名分别为DataFile7_1.mdf(主数据文件)、DataFile7_2.ndf和DataFile7_3.ndf,它们的逻辑文件名分别为:LogicFile7_1、LogicFile7_2和LogicFile7_3,初始大小分别为5MB、2MB和3MB,最大值均为100MB,自动增长幅度分别为初始大小的15%、10%和5%,且次要数据文件DataFile7_2.ndf和DataFile7_3.ndf分别分配到文件组UserFG7_2和UserFG7_3中。
日志文件:其物理文件名为LogFile7.ldf,逻辑文件名为:LogicLog7,日志文件初始大小为10MB,最大值为100MB,自动增长幅度为1MB。
相应代码如下:
CREATE DATABASE DB7 ON PRIMARY ( -- 主数据文件 NAME = ' LogicFile7_1', FILENAME = 'D:datafilesDataFile7_1.mdf', SIZE = 5MB , -- 设置初始大小 MAXSIZE = 100MB, -- 设置数据文件的最大存储空间 FILEGROWTH = 15% -- 设置自动增长幅度 ), FILEGROUP UserFG7_2 -- 将数据库文件DataFile7_2.ndf分配到文件组UserFG7_2中 ( -- 次要数据文件 NAME = 'LogicFile7_2', FILENAME = 'D:datafilesDataFile7_2.ndf', SIZE = 2MB , -- 设置初始大小 MAXSIZE = 100MB, -- 设置数据文件的最大存储空间 FILEGROWTH = 10% -- 设置自动增长幅度 ), FILEGROUP UserFG7_3 -- 将数据库文件DataFile7_3.ndf分配到文件组UserFG7_3中 ( -- 次要数据文件 NAME = 'LogicFile7_3', FILENAME = 'D:datafilesDataFile7_3.ndf', SIZE = 3MB , -- 设置初始大小 MAXSIZE = 100MB, -- 设置数据文件的最大存储空间 FILEGROWTH = 5% -- 设置自动增长幅度 ) LOG ON( -- 设置日志文件的逻辑名称 NAME = 'LogicLog7', -- 设置日志文件 FILENAME = 'D:datafilesLogFile7.ldf', SIZE = 10MB, -- 设置初始大小 MAXSIZE = 100MB, -- 设置数据文件的最大存储空间 FILEGROWTH = 1MB -- 设置自动增长幅度 );
• 7.3 查看数据库
7.3.1 服务器上的数据库
Master数据库中的目录视图sysdatabases保存了服务器上所有的数据库信息,通过查询该视图可以获取所有的数据库信息:
SELECT * FROM sysdatabases;
执行上面查询语句,结果如图7.1所示,这表明笔者机器上一共有16个数据库。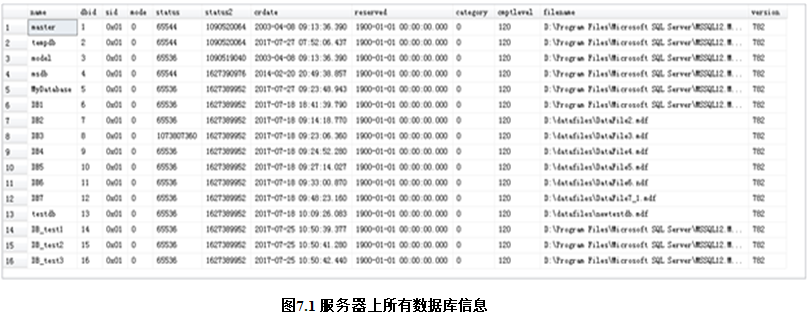
如果要判断一个数据库是否存在,可以使用EXISTS函数来实现。
--下面语句可以判断数据库MyDatabase是否存在: IF EXISTS(select * from sysdatabases where name='MyDatabase') PRINT '存在‘ --也可以用下列语句判断该数据库是否存在: IF db_id('MyDatabase') is not null PRINT '存在'
利用存储过程sp_helpdb,可以查看指定数据库的基本信息或当前数据库服务器上在运行的所有数据库的基本信息。
7.3.2 数据库的基本信息
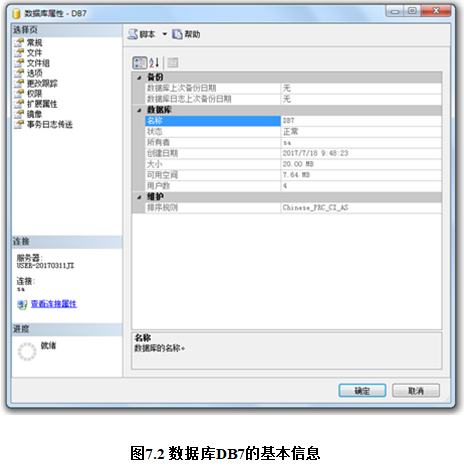
在SQL Server 2014中,查看数据库信息最简便的方法是,在SQL Server Management Studio的对象资源管理器中右击要查看的数据库,然后在弹出的菜单中选择“属性”项,将打开“数据库属性”对话框。在此对话框中可以看到数据库所有基本信息。
【例子】 图7.2显示的是数据库MyDatabase7的基本信息。
系统存储过程sp_helpdb也是一种常用于查看数据库信息的工具,其使用方法很简单,语法格式如下:
sp_helpdb database_name --database_name为待查看信息的数据库名。
【例7.8】 查看数据库DB7的信息。
该查询任务的实现代码如下
sp_helpdb DB7;
执行上述代码,结果如图7.3所示。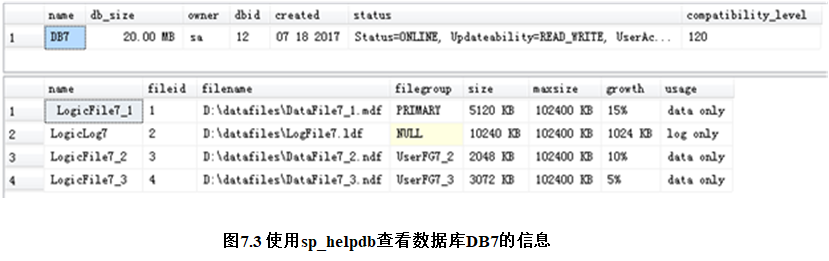
对图7.3中出现各列的意义说明如下:
上表:
name:数据库名
db_size:数据库总的大小
owner:数据库拥有者
dbid:数据库ID
created:创建日期
status:数据库状态
compatibility_level:数据库兼容等级
下表:
name:(数据文件和日志文件的)逻辑名称
fileid:文件ID
filename:物理文件的位置及名称
filegroup:文件组
size:文件大小(所有文件大小之和等于上面的db_size)
maxsize:文件的最大存储空间
growth:文件的自动增长幅度
usage:文件用途
7.3.3 数据库中的数据表
有时候希望能知道当前数据库中到底包含了哪些数据表,这时可以通过查询信息架构视图information_schema.tables来获得,该视图包含了当前数据库中所有数据表的基本信息。
【例子】 查看数据库MyDatabase中所有的数据表,相关代码如下:
USE MyDatabase; -- 打开数据库MyDatabase SELECT * FROM information_schema.tables;
在笔者的机器上执行上述代码,结果如图7.4所示。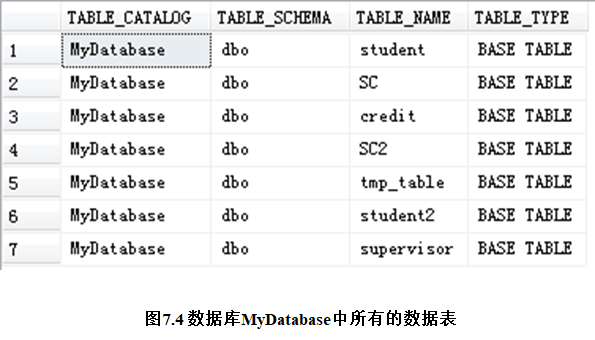
• 7.4 修改数据库
7.4.1 更改数据库的名称
更改数据库名是最简单的操作、也是最常用的操作之一。其语法如下:
ALTER DATABASE database_name MODIFY NAME = new_database_name;
【例7.9】 更改数据库名。
对于已存在的数据库oldDB,后将之改名为newDB,相应代码如下:
ALTER DATABASE oldDB -- 改名 MODIFY NAME = newDB;
另外,利用SQL Server提供的系统存储过程sp_renamedb也可以对数据库进行改名。其语法如下:
sp_renamedb database_name, new_database_name
【例子】 对于例7.9中的更名操作,也可以用下列语句来实现:
sp_renamedb oldDB, newDB;
7.4.2 修改数据库的大小
数据库的大小(存储容量)是由数据文件和日志文件的大小来决定的,因此数据库大小的修改是通过修改数据库文件的相关属性值来实现的,如初始值、增长幅度、最大容量等。这主要是利用带MODIFY FILE选项的ALTER DATABASE语句来完成。
【例7.10】 修改数据库的“容量”,同时修改主数据文件的逻辑名称和物理名称。
对于存在的数据库testdb,将其数据文件的逻辑名称和物理名称分别改为newtestdb和newtestdb.mdf,数据文件的初始大小为25MB、最大空间为150MB、数据增长幅度为10MB。
相应代码如下:
USE master GO ALTER DATABASE testdb MODIFY FILE ( NAME = testdb, -- 必需是原来的逻辑文件名 NEWNAME = newtestdb, -- 新的逻辑文件名 FILENAME = 'D:datafiles ewtestdb.mdf', -- 新的物理文件名(不需要原来的物理文件名) SIZE = 25MB, -- 初始大小 MAXSIZE = 150MB, -- 最大存储空间 FILEGROWTH = 10MB -- 数据增长幅度 );
【例7.11】 更改数据库的日志文件。
更改数据库DB3的日志文件,更改后,日志文件名变为newlogdb3.ldf,对应的逻辑文件名不变(通过引用逻辑文件名来更改信息的),初始大小为10MB。相应代码如下:
USE master GO ALTER DATABASE DB3 MODIFY FILE ( NAME = LogicLog3, -- 必需是原来的逻辑文件名 FILENAME ='D:datafiles ewlogdb3.ldf’, -- 新的物理文件名 SIZE = 10MB , -- 初始大小 MAXSIZE = 50MB, -- 数据文件的最大存储空间 FILEGROWTH = 5MB -- 自动增长幅度 );
注意:对数据文件和日志文件来说,更改后文件的初始值(SIZE)也必须大于更改前的初始值,否则ALTER语句操作将失败。
• 7.5 数据库的分离和附加
数据库分离是指将数据库从服务器实例中分离出来,结果是数据库文件(包括数据文件和日志文件)脱离数据库服务器,得到静态的数据库文件,进而可以像其他操作系统文件那样,对它们进行拷贝、剪切、粘贴等操作。
数据库附加是指利用数据库文件将分离的数据库加入到数据库服务器中,形成服务器实例。通过数据库的分离与附加,可以一个数据库从一台服务器移到另外一台服务器上,这为数据库的备份、移动等提供了一种有效的途径。
7.5.1 用户数据库的分离
数据库分离可视为是一种特殊的数据库删除操作,不同的是,分离的结果是形成静态的数据文件和日志文件,这些文件分别保存了数据库中的数据信息和日志信息。数据库删除操作则不但将数据库从服务器中分离出来,而且相应的数据文件和日志文件都从磁盘上被删除,数据是不可恢复的。这是数据库分离和数据库删除的本质区别。
分离数据库可用系统存储过程sp_detach_db来实现,其语法如下:
sp_detach_db [ @dbname= ] 'database_name' [ , [ @skipchecks= ] 'skipchecks' ] [ , [ @keepfulltextindexfile = ] 'KeepFulltextIndexFile' ]
其参数意义说明如下:
[ @dbname = ] 'database_name'
指定要分离的数据库的名称,默认值为NULL。
[ @skipchecks = ] 'skipchecks'
指定是否运行UPDATE STATISTIC。默认值为NULL。如果设置为true,则表示要跳过UPDATE STATISTICS;如果指定为false,则表示要运行UPDATE STATISTICS。运行UPDATE STATISTICS可更新SQL Server数据库引擎内表和索引中的数据的信息。
[ @keepfulltextindexfile =] 'KeepFulltextIndexFile'
指定是否在数据库分离过程中删除与所分离的数据库关联的全文索引文件。如果KeepFulltextIndexFile被设置为false,则表示只要数据库不是只读的,就会删除与数据库关联的所有全文索引文件以及全文索引的元数据;如果设置为NULL或true(默认值),则保留与全文相关的元数据。
【例7.12】 分离数据库MyDatabase。
下列代码将分离数据库MyDatabase,并保留全文索引文件和全文索引的元数据。
USE master; -- 为了关闭要分离的数据库MyDatabase EXEC sp_detach_db 'MyDatabase', NULL, 'true’;
执行上述语句后,将得到两个数据库文件:MyDatabase.mdf和MyDatabase_log.LDF(它们位于创建数据库时指定的目录下),这时我们可以对之进行复制、剪切、粘贴等操作(在分离之前是不允许进行这些操作的)。
7.5.2 用户数据库的附加
数据库附加是利用已有的数据库文件(分离时形成的数据库文件)来创建数据库的过程。它使用带FOR ATTACH子句的
CREATE DATABASE语句来完成,相应的语法如下: CREATE DATABASE database_name ON <filespec> [ ,...n ] FOR { ATTACH [ WITH <service_broker_option> ] | ATTACH_REBUILD_LOG } [;]
选项FOR ATTACH表示用指定的操作系统文件来创建数据库,即创建的数据库的许多参数将由这些操作系统文件指定的数值来设置,而不再继承系统数据库model的参数设置。其参数意义见7.2.1节。
【例7.13】附加数据库MyDatabase。
利用例7.12中分离数据库MyDatabase而形成的数据库文件MyDatabase.mdf和MyDatabase_log.LDF来附加该数据库。假设这两个数据库文件位于D:datafiles目录下,则可以通过
下列代码将数据库MyDatabase附加到当前的服务器实例中:
CREATE DATABASE MyDatabase ON (FILENAME = 'D:datafilesMyDatabase.mdf') -- 只利用了MyDatabase.mdf FOR ATTACH
注意,在数据库附加过程中只显式利用了数据文件MyDatabase.mdf,并没有利用日志文件MyDatabase_log.LDF。但MyDatabase_log.LDF最好与MyDatabase.mdf位于同一目录下,否则会产生一些警告。
在SSMS对数据库进行分离和附加的操作也比较简单。分离时,在SSMS的对象资源管理器中右击要分离的数据库图片,在弹出的菜单中选择“任务”|“分离…”,然后在打开的“分离数据库”对话框中单击【确定】按钮即可,如图7.5所示。
附加数据库时,在SSMS的对象资源管理器中右击“数据库”节点,在弹出的菜单中选择“附加…”,然后在弹出的“附加数据库”对话框中单击【添加…】按钮,选择相应的数据库文件(.mdf文件)即可,如图7.6所示。
• 7.6 删除数据库
当数据库已经确认不再需要的时候,应该将之删除,以释放服务器资源。需要提醒的是,为了避免不必要的损失,在实际应用当中不管删除哪一个数据库,在删除之前都应进行备份。
删除数据库是利用DROP DATABASE语句来实现,其语法如下:
DROP DATABASE { database_name | database_snapshot_name } [ ,...n ] [;]
其参数说明如下:
database_name:指定要删除的数据库的名称
database_snapshot_name:指定要删除的数据库快照的名称
【例7.14】 删除单个数据库
删除数据库MyDatabase,代码如下:
USE master; GO DROP DATABASE MyDatabase;
【例7.15】 同时删除多个数据库
删除数据库MyDatabase2,MyDatabase3,MyDatabase4,代码如下:
USE master; GO DROP DATABASE MyDatabase2,MyDatabase3,MyDatabase4;
注意:使用DROP DATABASE语句删除数据库以后,数据文件和日志文件都将从磁盘上删除。一旦使用了DROP DATABASE语句,数据库中的数据是不可恢复的。如果只是希望将数据库从当前服务器中删除,但不希望从文件系统删除数据库文件,则可使用数据库分离的方法来操作。
