在上一篇随笔中,分析了HashMap的源码,里面涉及到了3个钩子函数(afterNodeAccess(e),afterNodeInsertion(evict),afterNodeRemoval(node)),用来预设给子类——LinkedHashMap调用。
一,LinkedHashMap数据结构
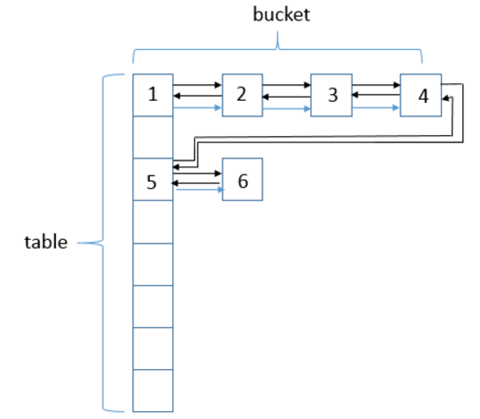
可以从上图中看到,LinkedHashMap数据结构相比较于HashMap来说,添加了双向指针,分别指向前一个节点——before和后一个节点——after,从而将所有的节点已链表的形式串联一起来。数据结构为(数组 + 单链表 + 红黑树 + 双链表),图中的标号是结点插入的顺序。
二,LinkedHashMap源码
1,LinkedHashMap结构
LinkedHashMap继承HashMap,所以HashMap中的非private方法和字段,都可以在LinkedHashMap直接中访问。
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> { static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } } // 版本序列号 private static final long serialVersionUID = 3801124242820219131L; // 链表头结点 transient LinkedHashMap.Entry<K,V> head; // 链表尾结点 transient LinkedHashMap.Entry<K,V> tail; /** * 用来指定LinkedHashMap的迭代顺序, * true则表示按照基于访问的顺序来排列,意思就是最近使用的entry,放在链表的最末尾 * false则表示按照插入顺序来 */ final boolean accessOrder; }
2,构造函数
LinkedHashMap提供了五种方式的构造器,所有构造函数的第一行都会调用父类构造函数,使用super关键字,如下
构造器一:
public LinkedHashMap(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor); accessOrder = false; }
accessOrder默认为false,access为true表示之后访问顺序按照元素的访问顺序进行,即不按照之前的插入顺序了,access为false表示按照插入顺序访问。
构造器二:
public LinkedHashMap(int initialCapacity) { super(initialCapacity); accessOrder = false; }
构造器三:
public LinkedHashMap() { super(); accessOrder = false; }
构造器四:
public LinkedHashMap(Map<? extends K, ? extends V> m) { super(); accessOrder = false; putMapEntries(m, false); }
putMapEntries是调用到父类HashMap的函数。
构造器五:
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }
通过指定accessOrder的值,从而控制访问顺序。
3,LinkedHashMap.Entry内部类
static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }
LinkedHashMap.Entry继承自HashMap.Node,在HashMap.Node基础上增加了前后两个指针域。
4,部分函数
4.1,get()函数
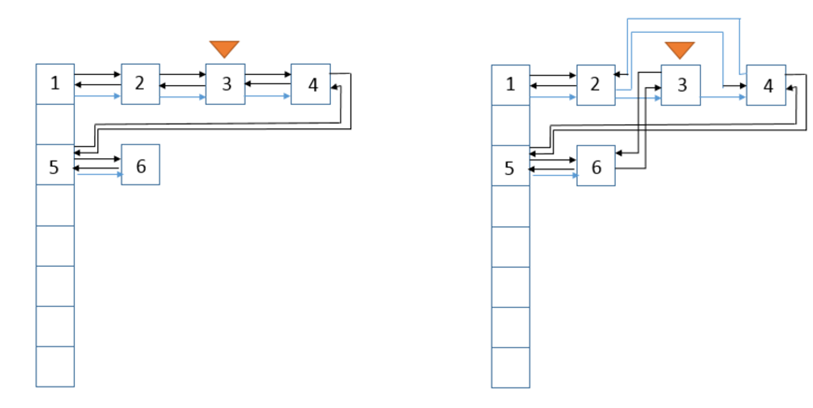
public V get(Object key) { Node<K,V> e; if ((e = getNode(hash(key), key)) == null) return null; //accessOrder为true则表示按照基于访问的顺序来排列,意思就是最近使用的entry,放在链表的最末尾 //在取值后对参数accessOrder进行判断,如果为true,执行afterNodeAccess if (accessOrder) afterNodeAccess(e); return e.value; } //此函数执行的效果就是将最近使用的Node,放在链表的最末尾 void afterNodeAccess(Node<K,V> e) { LinkedHashMap.Entry<K,V> last; //仅当按照LRU原则且e不在最末尾,才执行修改链表,将e移到链表最末尾的操作 if (accessOrder && (last = tail) != e) { //将e赋值临时节点p, b是e的前一个节点, a是e的后一个节点 LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; //设置p的后一个节点为null,因为执行后p在链表末尾,after肯定为null p.after = null; //情况一(p为头部):p前一个节点为null if (b == null) head = a; else b.after = a; //情况二(p为尾部):p的后一个节点为null if (a != null) a.before = b; else last = b; //情况三(p为链表里的第一个节点) if (last == null) head = p; else { //正常情况,将p设置为尾节点的准备工作,p的前一个节点为原先的last,last的after为p p.before = last; last.after = p; } //将p设置为尾节点 tail = p; // 修改计数器+1 ++modCount; } }
概念:
LRU(Least Recently Used): 意思就是最近读取的数据放在最前面,最早读取的数据放在最后面,如果这个时候有新的数据进来,那么最后面存储的数据淘汰。
说明一下:
正常情况下:查询的p在链表中间,那么将p设置到末尾后,它原先的 前节点b 和 后节点a 就变成了前后节点。
情况一:p为头部,前一个节点b不存在,那么考虑到p要放到最后面,则设置p的后一个节点a为head。
情况二:p为尾部,后一个节点a不存在,那么考虑到统一操作,设置last为b。
情况三:p为链表里的第一个节点,head=p。
将最近使用的Node,放在链表的最末尾示意图:
4.2,put()方法
LinkedHashMap的put方法调用的还是HashMap里的put,不同的是重写了里面的部分方法。
LinkedHashMap将其中newNode方法以及之前设置下的钩子方法afterNodeAccess(该方法上面已说明)和afterNodeInsertion进行了重写,从而实现了加入链表的目的。
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e); linkNodeLast(p); return p; } //把新加的节点放在链表的最后面。 private void linkNodeLast(LinkedHashMap.Entry<K,V> p) { //将tail给临时变量last LinkedHashMap.Entry<K,V> last = tail; tail = p; //若没有last,说明p是第一个节点,head=p if (last == null) head = p; else { p.before = last; last.after = p; } } //插入后把最老的Entry删除,不过removeEldestEntry总是返回false,所以不会删除,估计又是一个钩子方法给子类用的 void afterNodeInsertion(boolean evict) { LinkedHashMap.Entry<K,V> first; if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null, false, true); } } protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false; }
4.3,remove()方法
在HashMap的remove方法中也有一个钩子方法afterNodeRemoval。
LinkedHashMap的remove方法调用的还是HashMap里的remove,不同的是重写了里面的部分方法。
void afterNodeRemoval(Node<K,V> e) { //记录e的前后节点b,a LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; //p已删除,前后指针都设置为null,便于GC回收 p.before = p.after = null; if (b == null) head = a; else b.after = a; if (a == null) tail = b; else a.before = b; }
4.4,transferLinks()方法
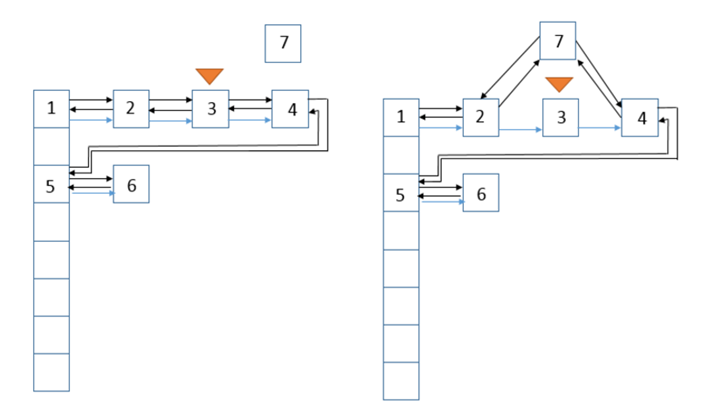
//替换节点的方法,我们使用的replacementNode,replacementTreeNode等方法都是通过该方法实现的 private void transferLinks(LinkedHashMap.Entry<K,V> src, LinkedHashMap.Entry<K,V> dst) { LinkedHashMap.Entry<K,V> b = dst.before = src.before; LinkedHashMap.Entry<K,V> a = dst.after = src.after; if (b == null) head = dst; else b.after = dst; if (a == null) tail = dst; else a.before = dst; }
dst节点替换src节点示意图:
5,LinkedHashMap的迭代器
abstract class LinkedHashIterator { //记录下一个Entry LinkedHashMap.Entry<K,V> next; //记录当前的Entry LinkedHashMap.Entry<K,V> current; //记录是否发生了迭代过程中的修改 int expectedModCount; LinkedHashIterator() { //初始化的时候把head给next next = head; expectedModCount = modCount; current = null; } public final boolean hasNext() { return next != null; } final LinkedHashMap.Entry<K,V> nextNode() { LinkedHashMap.Entry<K,V> e = next; if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (e == null) throw new NoSuchElementException(); current = e; next = e.after; return e; } public final void remove() { Node<K,V> p = current; if (p == null) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException(); current = null; K key = p.key; removeNode(hash(key), key, null, false, false); expectedModCount = modCount; } }