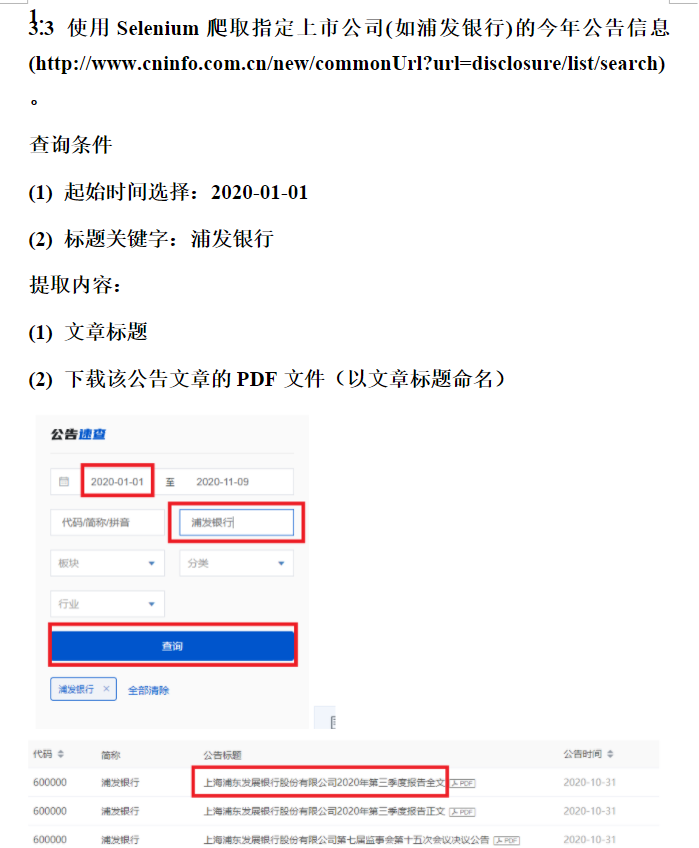
1 from selenium import webdriver#导入库 2 from selenium.webdriver.common.keys import Keys 3 from bs4 import BeautifulSoup 4 import csv,time 5 import os,re 6 import requests 7 import selenium.webdriver.support.ui as ui 8 import urllib 9 10 chromeOptions = webdriver.ChromeOptions() 11 prefs = {"download.default_directory":"D:\pufa"} 12 chromeOptions.add_experimental_option("prefs", prefs) 13 browser = webdriver.Chrome(chrome_options=chromeOptions)#声明浏览器 14 15 positon = {} 16 def enterinfo(): 17 url = 'http://www.cninfo.com.cn/new/commonUrl?url=disclosure/list/search' 18 browser.get(url)#打开浏览器预设网址 19 input = browser.find_element_by_css_selector('input[placeholder $= "标题关键字"]') 20 input.send_keys('浦发银行') 21 22 browser.find_element_by_class_name("el-range__close-icon").click()#删除原来日期信息 23 input = browser.find_element_by_css_selector('input[placeholder $= "开始日期"]') 24 input.send_keys('2020-01-01') 25 26 input = browser.find_element_by_css_selector('input[placeholder $= "结束日期"]') 27 xianzai = time.strftime("%Y-%m-%d", time.localtime()) 28 input.send_keys(xianzai) 29 30 time.sleep(2) 31 32 browser.find_elements_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div[1]/div[2]/div[1]/button/span')[0].click() 33 #填写文本 34 time.sleep(2)#睡眠5 35 36 def GainPage(): 37 source = browser.page_source # 打印网页源代码 38 soup = BeautifulSoup(source, 'lxml') 39 40 ul_list = soup.select('div.el-table__body-wrapper')[0] 41 for ul in ul_list.select('tr.el-table__row'): 42 web = ul.select('td.el-table_1_column_3')[0].select('span.ahover')[0].select('a')[0] 43 webs = web.get('href') 44 45 url = 'http://www.cninfo.com.cn' 46 url = url + webs 47 48 biaoti = web.text 49 positon[biaoti] = url 50 51 52 time.sleep(2) 53 enterinfo() 54 i = 1 55 while(i): 56 GainPage() 57 browser.find_elements_by_xpath('//*[@id="main"]/div[2]/div[1]/div[1]/div[3]/div/button[2]/i')[0].click() 58 i = i+1 59 if i==9: 60 break 61 print(len(positon)) 62 63 64 for it in positon.items(): 65 print(it) 66 for val in positon.values(): 67 68 url = val 69 browser.get(url) # 打开浏览器预设网址 70 71 browser.find_elements_by_xpath('//*[@id="noticeDetail"]/div/div[1]/div[3]/div[1]/button/span')[0].click()