1. Series
Series 是一种一维数组,和 NumPy 里的数组很相似。事实上,Series 基本上就是基于 NumPy 的数组对象来的。和 NumPy 的数组不同,Series 能为数据自定义标签,也就是索引(index),然后通过索引来访问数组中的数据。
import numpy as np
import pandas as pd
创建一个 Series 的基本语法如下:
my_series = pd.Series(data, index)
上面的 data 参数可以是任意数据对象,比如字典、列表甚至是 NumPy 数组,而 index 参数则是对 data 的索引值,类似字典的 key。
下面这个例子里,将创建一个 Series 对象,并用字符串对数字列表进行索引:
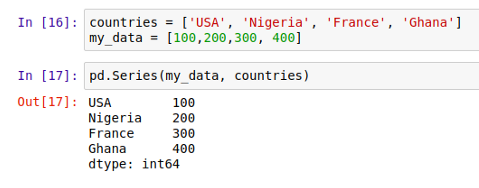
注意:请记住, index 参数是可省略的,你可以选择不输入这个参数。如果不带 index 参数,Pandas 会自动用默认 index 进行索引,类似数组,索引值是 [0, …, len(data) - 1] ,如下所示:
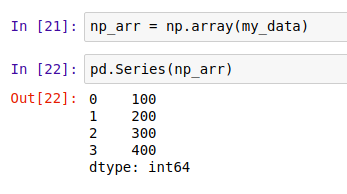
- 从 NumPy 数组对象创建 Series:
- 从 Python 字典对象创建 Series:
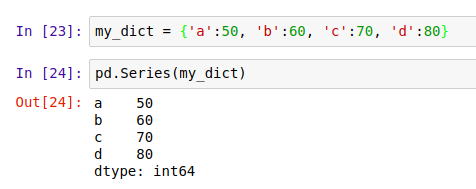
如上图的 out[24] 中所示,如果你从一个 Python 字典对象创建 Series,Pandas 会自动把字典的键值设置成 Series 的 index,并将对应的 values 放在和索引对应的 data 里。
和 NumPy 数组不同,Pandas 的 Series 能存放各种不同类型的对象。
从 Series 里获取数据
访问 Series 里的数据的方式,和 Python 字典基本一样:

对 Series 进行算术运算操作
对 Series 的算术运算都是基于 index 进行的。我们可以用加减乘除(+ - * /)这样的运算符对两个 Series 进行运算,Pandas 将会根据索引 index,对响应的数据进行计算,结果将会以浮点数的形式存储,以避免丢失精度。
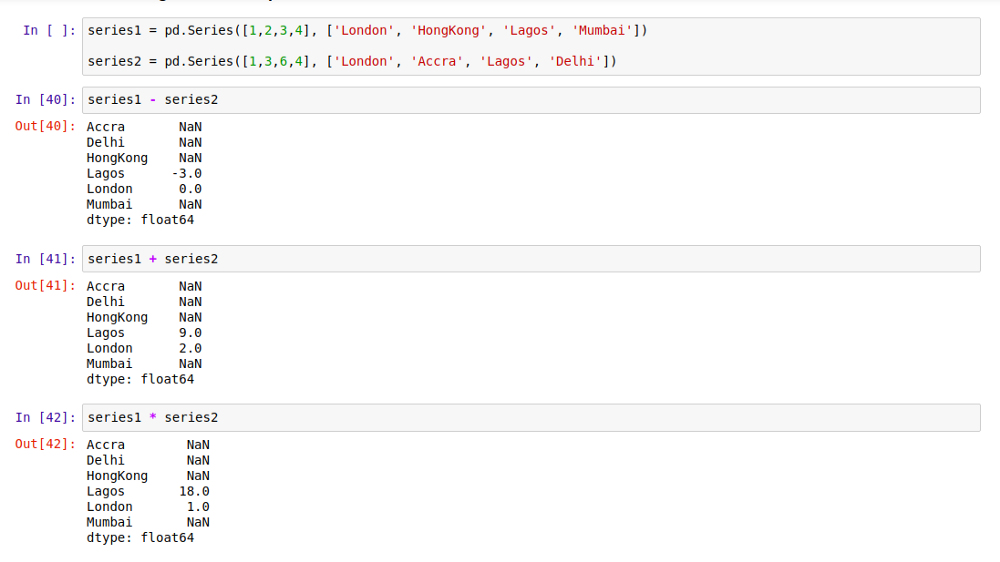
如上,如果 Pandas 在两个 Series 里找不到相同的 index,对应的位置就返回一个空值 NaN。
2. DataFrames
Pandas 的 DataFrame(数据表)是一种 2 维数据结构,数据以表格的形式存储,分成若干行和列。通过 DataFrame,你能很方便地处理数据。常见的操作比如选取、替换行或列的数据,还能重组数据表、修改索引、多重筛选等。
构建一个 DataFrame 对象的基本语法如下:
pd.DataFrame(data,index)
举个例子,我们可以创建一个 5 行 4 列的 DataFrame,并填上随机数据:
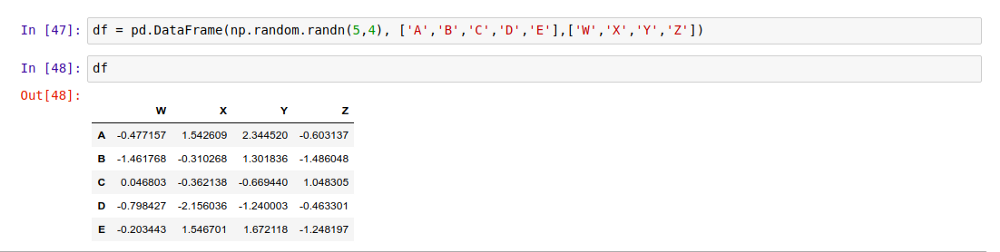
看,上面表中的每一列基本上就是一个 Series ,它们都用了同一个 index。因此,我们基本上可以把 DataFrame 理解成一组采用同样索引的 Series 的集合。
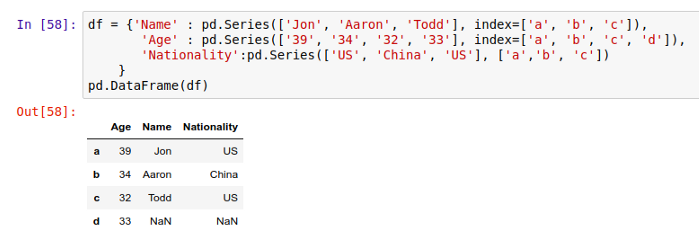
下面这个例子里,我们将用许多 Series 来构建一个 DataFrame:
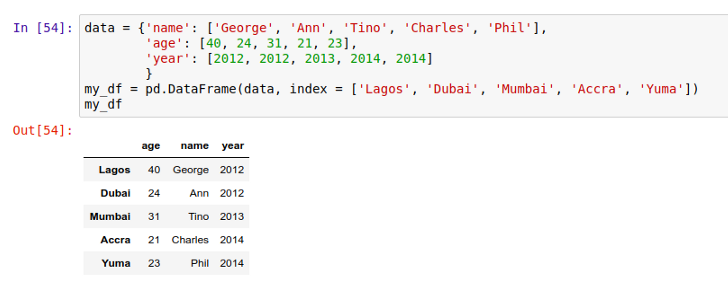
以及用一个字典来创建 DataFrame:
获取 DataFrame 中的列
要获取一列的数据,还是用中括号 [] 的方式,跟 Series 类似。比如尝试获取上面这个表中的 name 列数据:
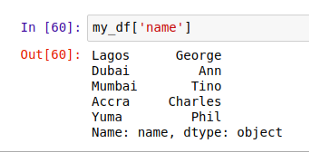
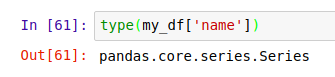
因为我们只获取一列,所以返回的就是一个 Series。可以用 type() 函数确认返回值的类型:
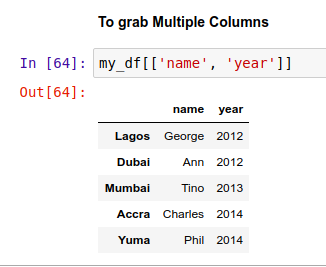
如果获取多个列,那返回的就是一个 DataFrame 类型:
向 DataFrame 里增加数据列
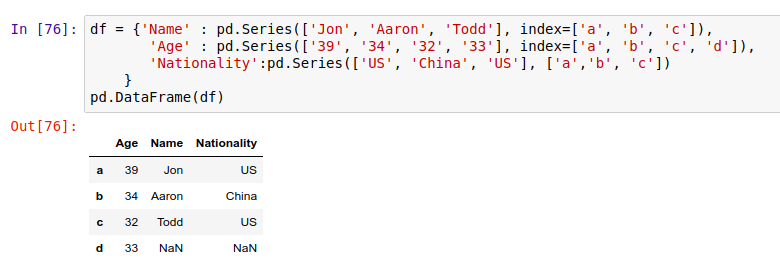
创建一个列的时候,你需要先定义这个列的数据和索引。举个栗子,比如这个 DataFrame:
增加数据列有两种办法:可以从头开始定义一个 pd.Series,再把它放到表中,也可以利用现有的列来产生需要的新列。比如下面两种操作:
定义一个 Series ,并放入 'Year' 列中:
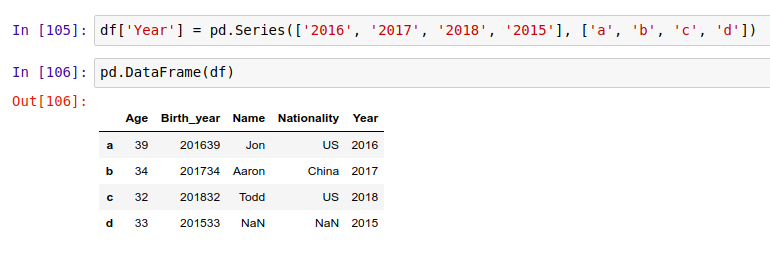
从现有的列创建新列:
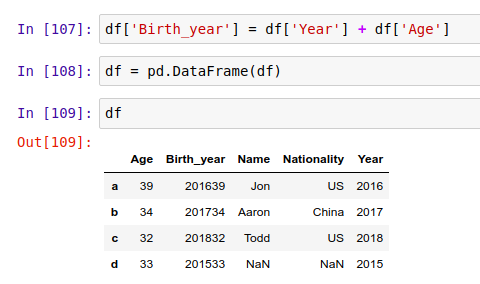
从 DataFrame 里删除行/列
想要删除某一行或一列,可以用 .drop() 函数。在使用这个函数的时候,你需要先指定具体的删除方向,axis=0 对应的是行 row,而 axis=1 对应的是列 column 。
删除 'Birth_year' 列:
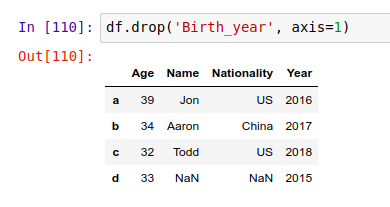
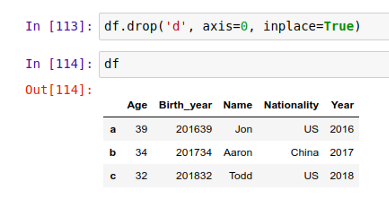
删除 'd' 行:
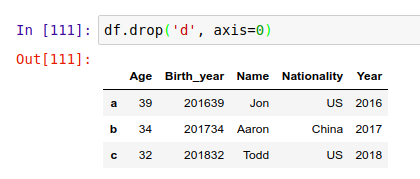
请务必记住,除非用户明确指定,否则在调用 .drop() 的时候,Pandas 并不会真的永久性地删除这行/列。这主要是为了防止用户误操作丢失数据。
你可以通过调用 df 来确认数据的完整性。如果你确定要永久性删除某一行/列,你需要加上 inplace=True 参数,比如:
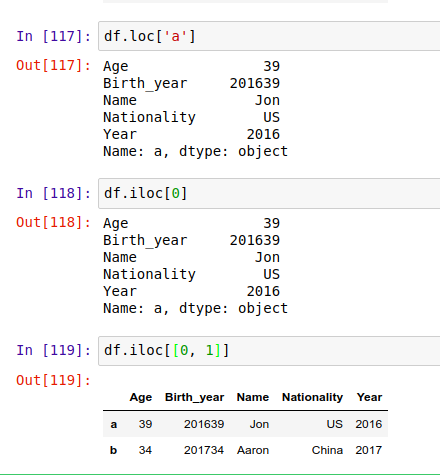
获取 DataFrame 中的一行或多行数据
要获取某一行,你需要用 .loc[] 来按索引(标签名)引用这一行,或者用 .iloc[] ,按这行在表中的位置(行数)来引用。
同时你可以用 .loc[] 来指定具体的行列范围,并生成一个子数据表,就像在 NumPy 里做的一样。比如,提取 'c' 行中 'Name' 列的内容,可以如下操作:
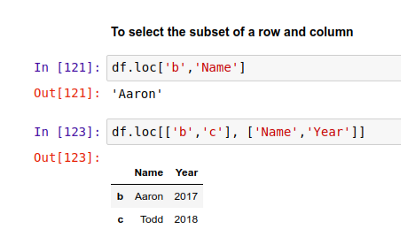
此外,你还可以制定多行和/或多列,如上所示。
条件筛选
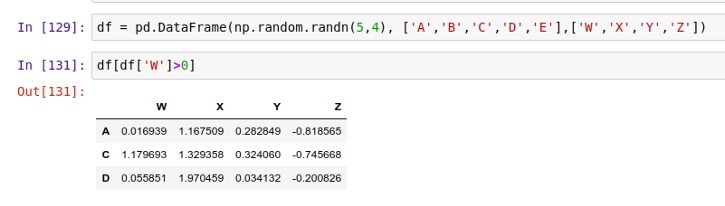
用中括号 [] 的方式,除了直接指定选中某些列外,还能接收一个条件语句,然后筛选出符合条件的行/列。比如,我们希望在下面这个表格中筛选出 'W'>0 的行:
如果要进一步筛选,只看 'X' 列中 'W'>0 的数据:
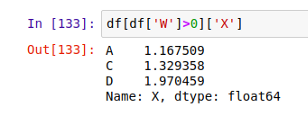
类似的,你还可以试试这样的语句 df[df['W']>0][['X','Y']] ,结果将会是这样:
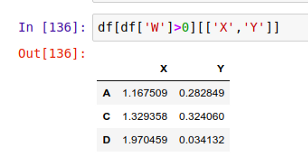
上面那行相当于下面这样的几个操作连在一起:
my_series = df['W'] > 0
result = df[my_series]
my_cols = ['X','Y']
result[my_cols]
你可以用逻辑运算符 &(与)和 |(或)来链接多个条件语句,以便一次应用多个筛选条件到当前的 DataFrame 上。举个栗子,你可以用下面的方法筛选出同时满足 'W'>0 和 'X'>1 的行:
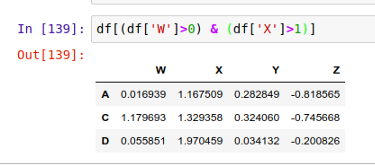
重置 DataFrame 的索引
如果你觉得当前 DataFrame 的索引有问题,你可以用 .reset_index() 简单地把整个表的索引都重置掉。这个方法将把目标 DataFrame 的索引保存在一个叫 index 的列中,而把表格的索引变成默认的从零开始的数字,也就是 [0, …, len(data) - 1] 。比如下面这样:
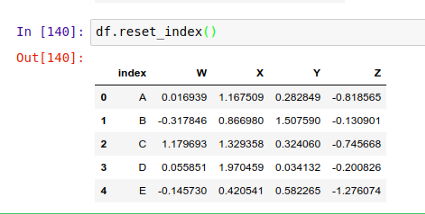
和删除操作差不多,.reset_index() 并不会永久改变你表格的索引,除非你调用的时候明确传入了 inplace 参数,比如:.reset_index(inplace=True)
设置 DataFrame 的索引值
类似地,我们还可以用 .set_index() 方法,将 DataFrame 里的某一列作为索引来用。比如,我们在这个表里新建一个名为 "ID" 的列:
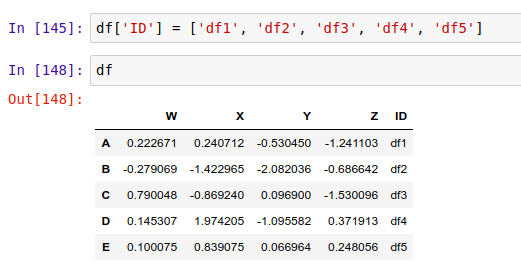
然后把它设置成索引:
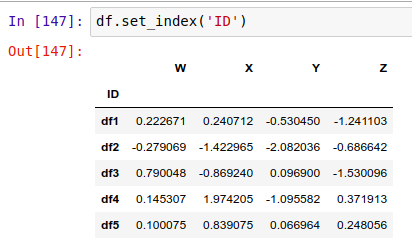
注意,不像 .reset_index() 会保留一个备份,然后才用默认的索引值代替原索引,.set_index() 将会完全覆盖原来的索引值。
多级索引(MultiIndex)以及命名索引的不同等级
多级索引其实就是一个由元组(Tuple)组成的数组,每一个元组都是独一无二的。你可以从一个包含许多数组的列表中创建多级索引(调用 MultiIndex.from_arrays ),也可以用一个包含许多元组的数组(调用 MultiIndex.from_tuples )或者是用一对可迭代对象的集合(比如两个列表,互相两两配对)来构建(调用 MultiIndex.from_product )。
下面这个例子,我们从元组中创建多级索引:

最后这个 list(zip()) 的嵌套函数,把上面两个列表合并成了一个每个元素都是元组的列表。这时 my_index 的内容是这样的:
[('O Level', 21), ('O Level', 22), ('O Level', 23), ('A Level', 21), ('A Level', 22), ('A Level', 23)]
接下来,我们调用 .MultiIndex.from_tuples(my_index) 生成一个多级索引对象:

最后,将这个多级索引对象转成一个 DataFrame:
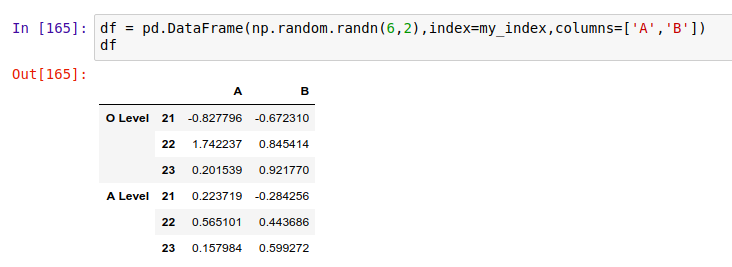
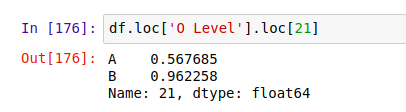
要获取多级索引中的数据,还是用到 .loc[] 。比如,先获取 'O Level' 下的数据:

然后再用一次 .loc[],获取下一层 21 里的数据:
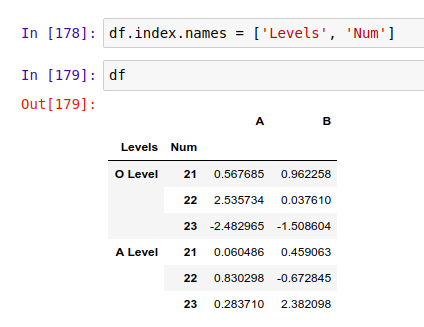
如上所示,df 这个 DataFrame 的头两个索引列没有名字,看起来不太易懂。我们可以用 .index.names 给它们加上名字:
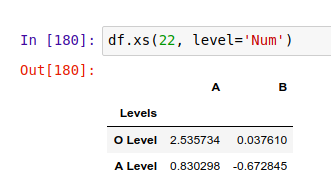
交叉选择行和列中的数据
我们可以用 .xs() 方法轻松获取到多级索引中某些特定级别的数据。比如,我们需要找到所有 Levels 中,Num = 22 的行:
清洗数据
删除或填充空值
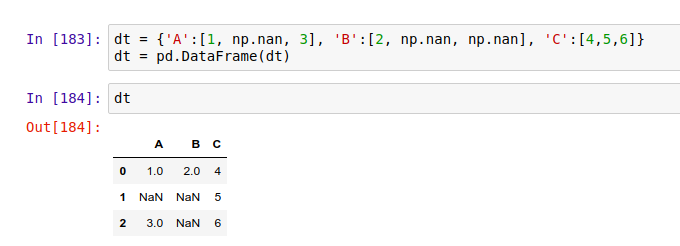
在许多情况下,如果你用 Pandas 来读取大量数据,往往会发现原始数据中会存在不完整的地方。在 DataFrame 中缺少数据的位置, Pandas 会自动填入一个空值,比如 NaN 或 Null 。因此,我们可以选择用 .dropna() 来丢弃这些自动填充的值,或是用 .fillna() 来自动给这些空值填充数据。
比如这个例子:
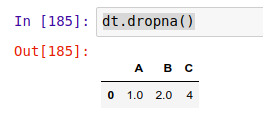
当你使用 .dropna() 方法时,就是告诉 Pandas 删除掉存在一个或多个空值的行(或者列)。删除列用的是 .dropna(axis=0) ,删除行用的是 .dropna(axis=1) 。
请注意,如果你没有指定 axis 参数,默认是删除行。
删除行:
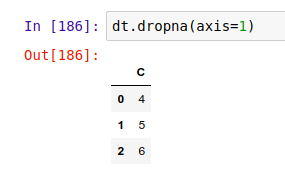
删除列:
类似的,如果你使用 .fillna() 方法,Pandas 将对这个 DataFrame 里所有的空值位置填上你指定的默认值。比如,将表中所有 NaN 替换成 20 :

当然,这有的时候打击范围太大了。于是我们可以选择只对某些特定的行或者列进行填充。比如只对 'A' 列进行操作,在空值处填入该列的平均值:
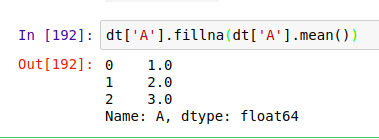
如上所示,’A’ 列的平均值是 2.0,所以第二行的空值被填上了 2.0。
同理,.dropna() 和 .fillna() 并不会永久性改变你的数据,除非你传入了 inplace=True 参数。
分组统计
Pandas 的分组统计功能可以按某一列的内容对数据行进行分组,并对其应用统计函数,比如求和,平均数,中位数,标准差等等…
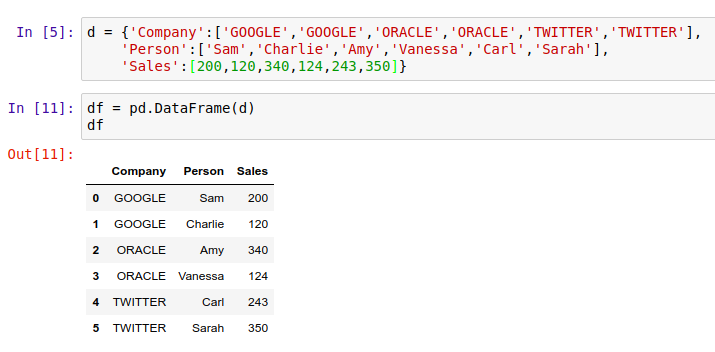
举例来说,用 .groupby() 方法,我们可以对下面这数据表按 'Company' 列进行分组,并用 .mean() 求每组的平均值:
首先,初始化一个DataFrame:
然后,调用 .groupby() 方法,并继续用 .mean() 求平均值:
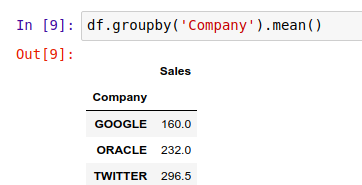
上面的结果中,Sales 列就变成每个公司的分组平均数了。
计数
用 .count() 方法,能对 DataFrame 中的某个元素出现的次数进行计数。
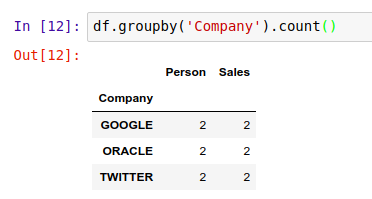
数据描述
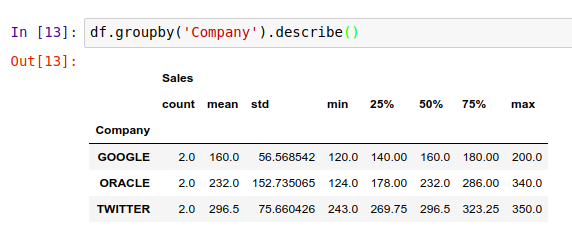
Pandas 的 .describe() 方法将对 DataFrame 里的数据进行分析,并一次性生成多个描述性的统计指标,方便用户对数据有一个直观上的认识。
生成的指标,从左到右分别是:计数、平均数、标准差、最小值、25% 50% 75% 位置的值、最大值。
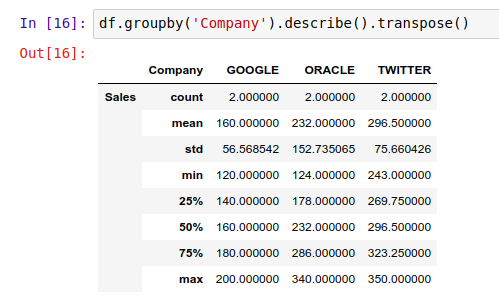
如果你不喜欢这个排版,你可以用 .transpose() 方法获得一个竖排的格式:
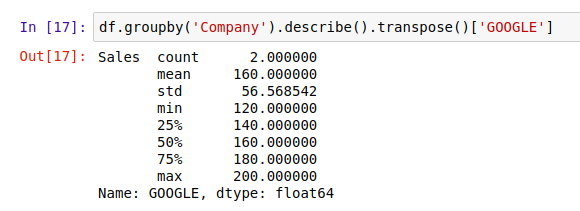
如果你只想看 Google 的数据,还能这样:
合并 DataFrame 的三种方式
堆叠(Concat)
堆叠基本上就是简单地把多个 DataFrame 堆在一起,拼成一个更大的 DataFrame。当你进行堆叠的时候,请务必注意你数据表的索引和列的延伸方向,堆叠的方向要和它一致。
比如,有这样3个 DataFrame:
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9, 10, 11])
我们用 pd.concat() 将它堆叠成一个大的表:

因为我们没有指定堆叠的方向,Pandas 默认按行的方向堆叠,把每个表的索引按顺序叠加。
如果你想要按列的方向堆叠,那你需要传入 axis=1 参数:
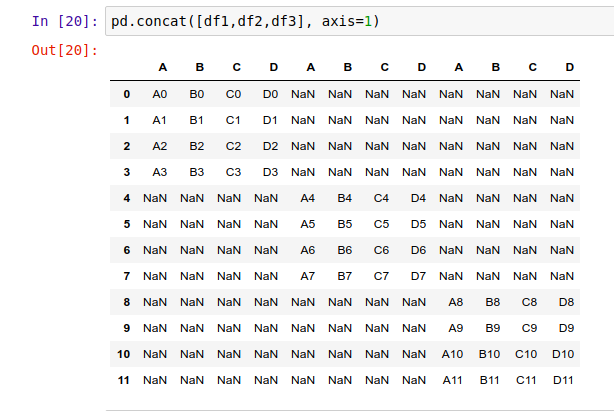
注意,这里出现了一大堆空值。因为我们用来堆叠的3个 DataFrame 里,有许多索引是没有对应数据的。因此,当你使用 pd.concat() 的时候,一定要注意堆叠方向的坐标轴(行或列)含有所需的所有数据。
归并(Merge)
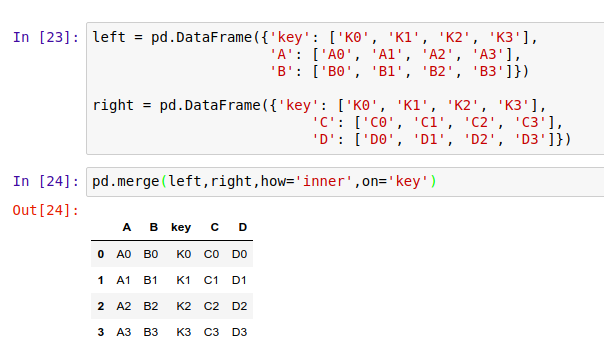
使用 pd.merge() 函数,能将多个 DataFrame 归并在一起,它的合并方式类似合并 SQL 数据表的方式。
归并操作的基本语法是 pd.merge(left, right, how='inner', on='Key') 。其中 left 参数代表放在左侧的 DataFrame,而 right 参数代表放在右边的 DataFrame;how='inner' 指的是当左右两个 DataFrame 中存在不重合的 Key 时,取结果的方式:inner 代表交集;Outer 代表并集。最后,on='Key' 代表需要合并的键值所在的列,最后整个表格会以该列为准进行归并。
对于两个都含有 key 列的 DataFrame,我们可以这样归并:
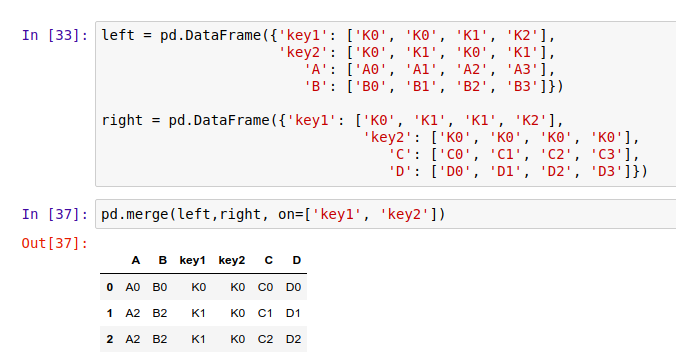
同时,我们可以传入多个 on 参数,这样就能按多个键值进行归并:
连接(Join)
如果你要把两个表连在一起,然而它们之间没有太多共同的列,那么你可以试试 .join() 方法。和 .merge() 不同,连接采用索引作为公共的键,而不是某一列。
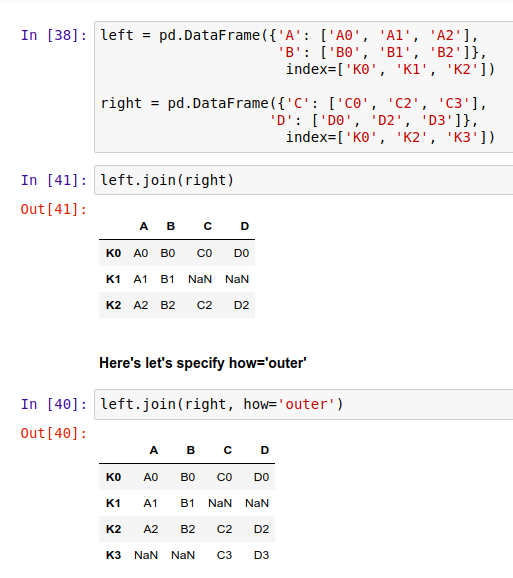
同样,inner 代表交集,Outer 代表并集。
数值处理
查找不重复的值
不重复的值,在一个 DataFrame 里往往是独一无二,与众不同的。找到不重复的值,在数据分析中有助于避免样本偏差。在 Pandas 里,主要用到 3 种方法:
首先是 .unique() 方法。比如在下面这个 DataFrame 里,查找 col2 列中所有不重复的值:
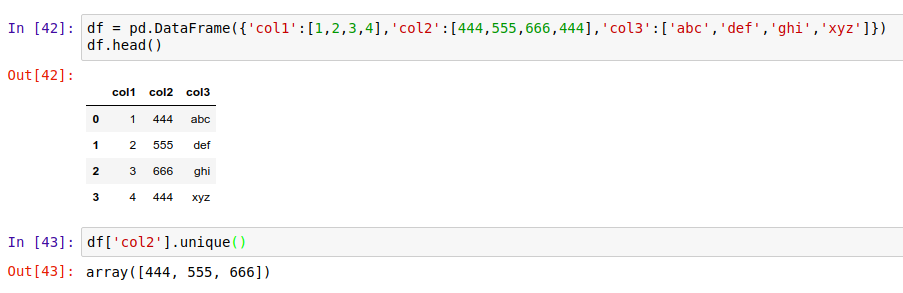
除了列出所有不重复的值,我们还能用 .nunique() 方法,获取所有不重复值的个数:
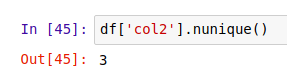
此外,还可以用 .value_counts() 同时获得所有值和对应值的计数:
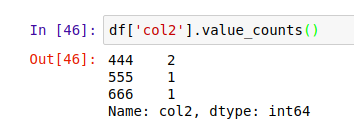
apply() 方法
用 .apply() 方法,可以对 DataFrame 中的数据应用自定义函数,进行数据处理。比如,我们先定义一个 square() 函数,然后对表中的 col1 列应用这个函数:
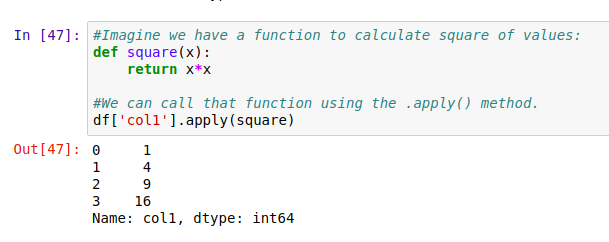
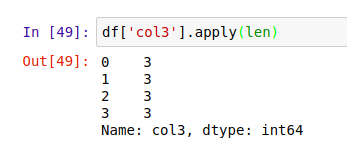
在上面这个例子中,这个函数被应用到这一列里的每一个元素上。同样,我们也可以调用任意的内置函数。比如对 col3 列取长度 len :
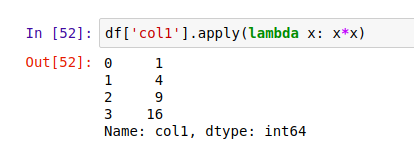
有的时候,你定义了一个函数,而它其实只会被用到一次。那么,我们可以用 lambda 表达式来代替函数定义,简化代码。比如,我们可以用这样的 lambda 表达式代替上面 In[47] 里的函数定义:
获取 DataFrame 的属性
DataFrame 的属性包括列和索引的名字。假如你不确定表中的某个列名是否含有空格之类的字符,你可以通过 .columns 来获取属性值,以查看具体的列名。

排序
如果想要将整个表按某一列的值进行排序,可以用 .sort_values() :
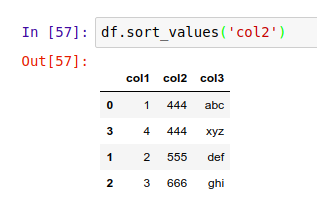
如上所示,表格变成按 col2 列的值从小到大排序。要注意的是,表格的索引 index 还是对应着排序前的行,并没有因为排序而丢失原来的索引数据。
查找空值
假如你有一个很大的数据集,你可以用 Pandas 的 .isnull() 方法,方便快捷地发现表中的空值:
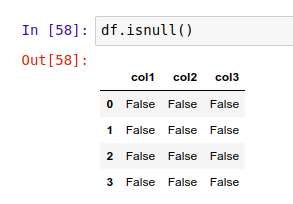
这返回的是一个新的 DataFrame,里面用布尔值(True/False)表示原 DataFrame 中对应位置的数据是否是空值。
数据透视表
在使用 Excel 的时候,你或许已经试过数据透视表的功能了。数据透视表是一种汇总统计表,它展现了原表格中数据的汇总统计结果。Pandas 的数据透视表能自动帮你对数据进行分组、切片、筛选、排序、计数、求和或取平均值,并将结果直观地显示出来。比如,这里有个关于动物的统计表:
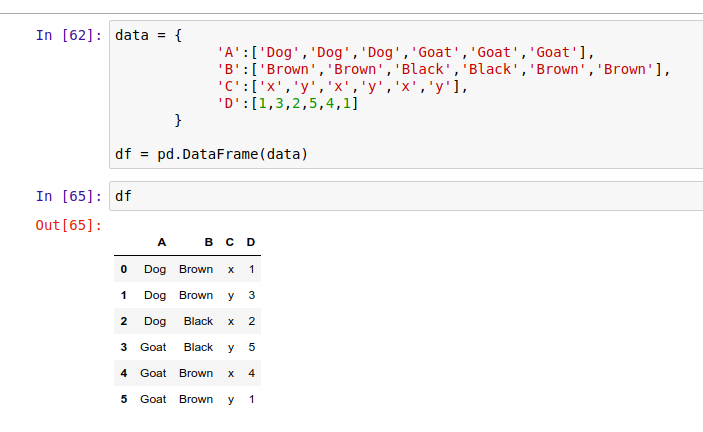
Pandas 数据透视表的语法是 .pivot_table(data, values='', index=[''], columns=['']) ,其中 values 代表我们需要汇总统计的数据点所在的列,index 表示按该列进行分组索引,而 columns 则表示最后结果将按该列的数据进行分列。你可以在 Pandas 的官方文档中找到更多数据透视表的详细用法和例子。
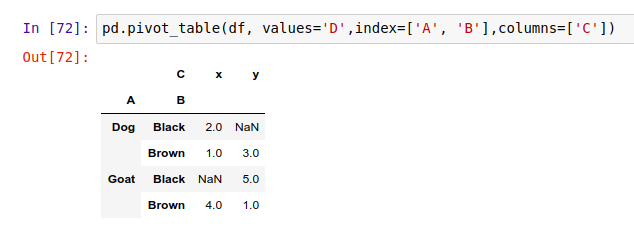
于是,我们按上面的语法,给这个动物统计表创建一个数据透视表:
或者也可以直接调用 df 对象的方法:
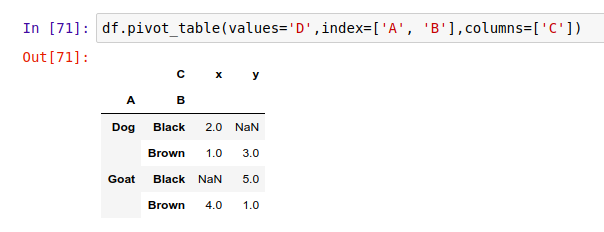
在上面的例子中,数据透视表的某些位置是 NaN 空值,因为在原数据里没有对应的条件下的数据。
导入导出数据
采用类似 pd.read_ 这样的方法,你可以用 Pandas 读取各种不同格式的数据文件,包括 Excel 表格、CSV 文件、SQL 数据库,甚至 HTML 文件等。
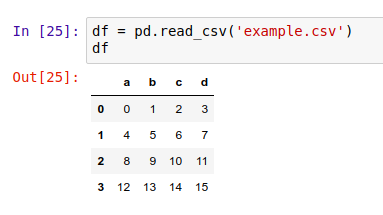
读取 CSV 文件
简单地说,只要用 pd.read_csv() 就能将 CSV 文件里的数据转换成 DataFrame 对象:
写入 CSV 文件
将 DataFrame 对象存入 .csv 文件的方法是 .to_csv(),例如,我们先创建一个 DataFrame 对象:
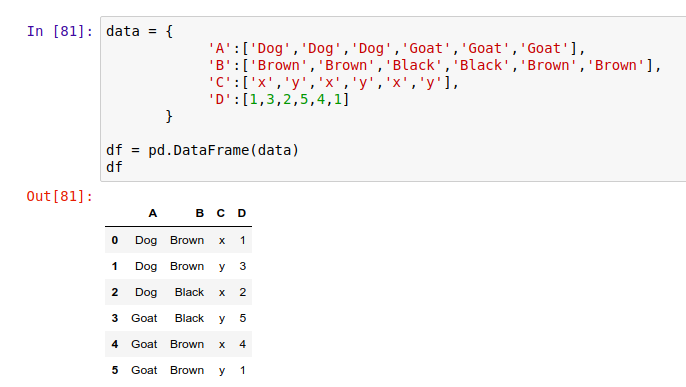
然后我们将这个 DataFrame 对象存成 'New_dataframe' 文件,Pandas 会自动在磁盘上创建这个文件。

这里传入 index=False 参数是因为不希望 Pandas 把索引列的 0~5 也存到文件中。
为了确保数据已经保存好了,你可以试试用 pd.read_csv('New_dataframe') ,把这个文件的内容读取出来看看。
读取 Excel 表格文件
Excel 文件是一个不错的数据来源。使用 pd.read_excel() 方法,我们能将 Excel 表格中的数据导入 Pandas 中。请注意,Pandas 只能导入表格文件中的数据,其他对象,例如宏、图形和公式等都不会被导入。如果文件中存在有此类对象,可能会导致 pd.read_excel() 方法执行失败。
举个例子,假设我们有一个 Excel 表格 'excel_output.xlsx',然后读取它的数据:
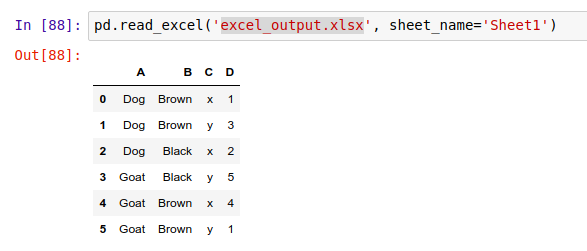
请注意,每个 Excel 表格文件都含有一个或多个工作表,传入 sheet_name='Sheet1' 这样的参数,就表示只读取 'excel_output.xlsx' 中的 Sheet1 工作表中的内容。
写入 Excel 表格文件
跟写入 CSV 文件类似,我们可以将一个 DataFrame 对象存成 .xlsx 文件,语法是 .to_excel() :
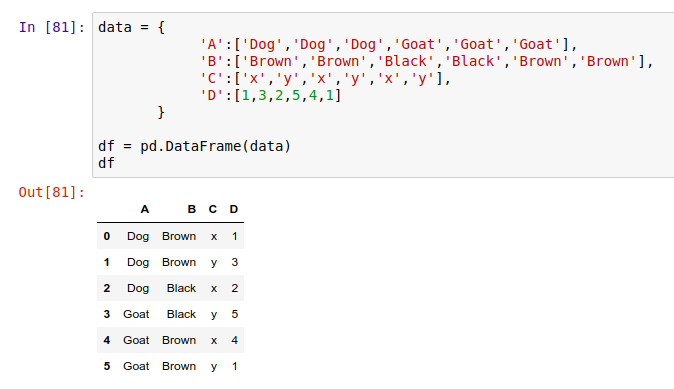
和前面类似,把数据存到 ‘excel_output.xlsx’ 文件中:

读取 HTML 文件中的数据
为了读取 HTML 文件,你需要安装 htmllib5,lxml 以及 BeautifulSoup4 库,在终端或者命令提示符运行以下命令来安装:
conda install lxml
conda install html5lib
conda install BeautifulSoup4
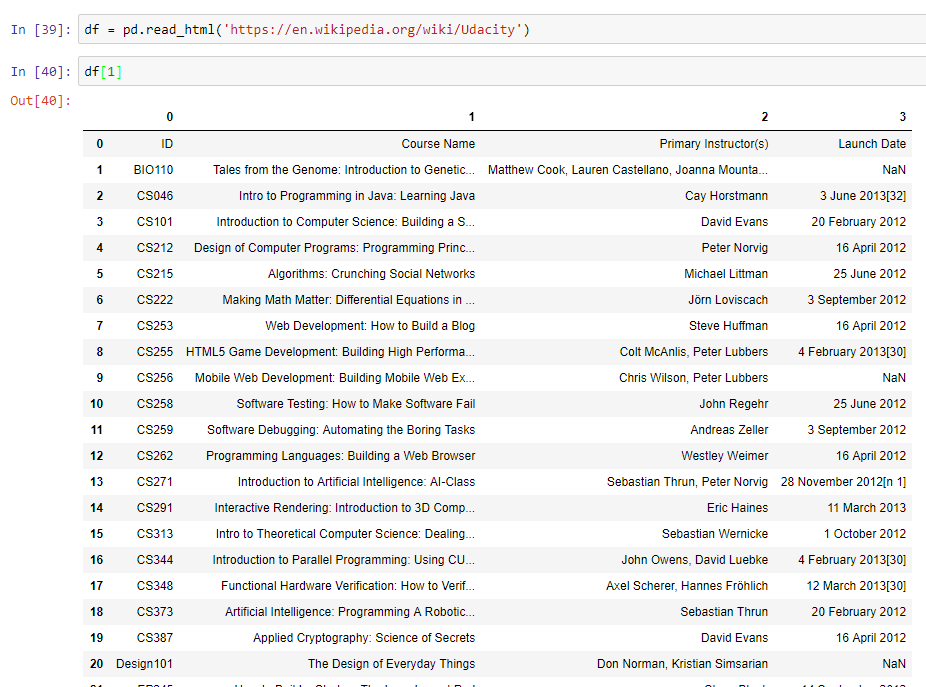
举个例子,我们用 .read_html() 让 Pandas 读取这个页面的数据:https://en.wikipedia.org/wiki/Udacity。由于一个页面上含有多个不同的表格,我们需要通过下标 [0, ..., len(tables) - 1] 访问数组中的不同元素。
下面的这个例子,我们显示的是页面中的第 2 个表格: