类似
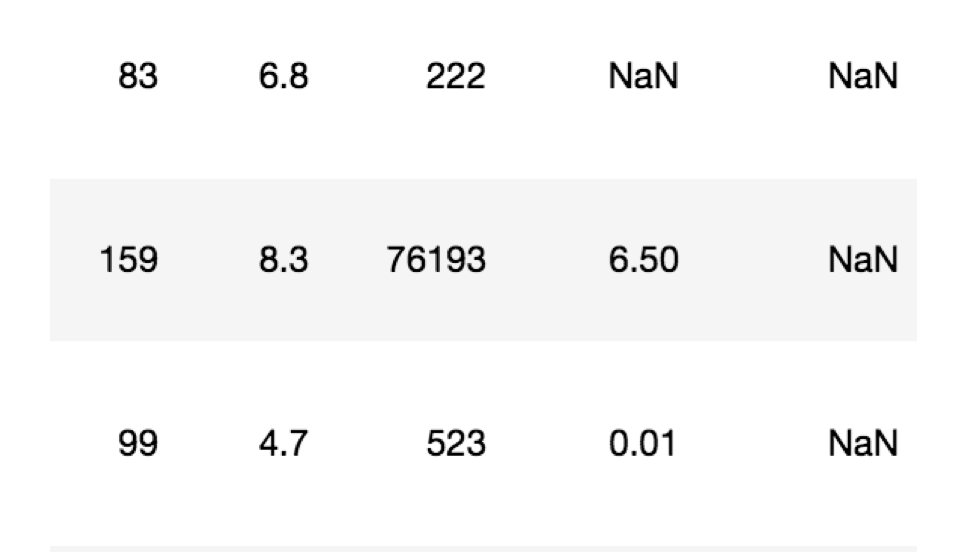
如何处理nan
判断数据中是否包含NaN:
pd.isnull(df)
pd.notnull(df)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
movie = pd.read_csv("./data/IMDB-Movie-Data.csv")
movie.head()
缺失值是nan
np.all(pd.notnull(movie)) # 里面如果有一个缺失值,那么会返回False,说明有缺失值
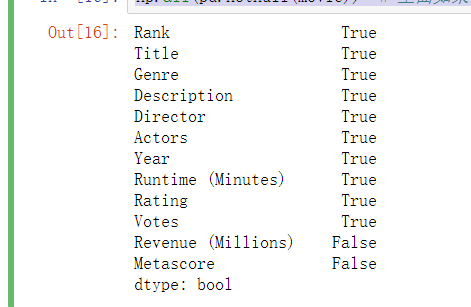
np.any(pd.isnull(movie)) # 里面如果有一个缺失值,那么会返回True,说明有缺失值
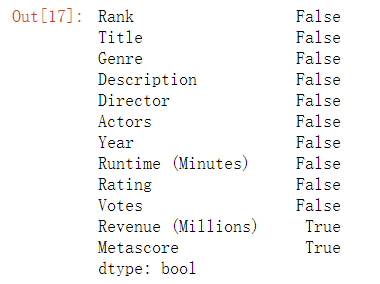
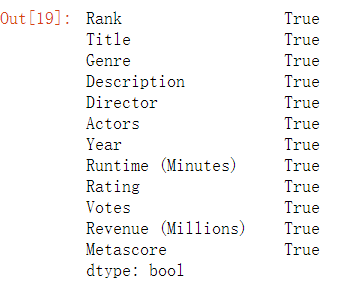
data = movie.dropna() #整行删除
np.all(pd.notnull(data)) # 里面如果有一个缺失值,那么会返回False,说明有缺失值
替换缺失值:fillna(value, inplace=True)
value:替换成的值
inplace:True:会修改原数据,False:不替换修改原数据,生成新的对象
movie["Revenue (Millions)"].mean() #求平均值
movie["Revenue (Millions)"].fillna(movie["Revenue (Millions)"].mean(), inplace=True)
将数据集中的所有缺省值替换为平均值:
for i in movie.columns: if np.any(pd.isnull(movie[i])) == True: print(i) movie[i].fillna(movie[i].mean(), inplace=True)
缺失值是其他符号(如“?”)
处理思路分析:
先替换‘?’为np.nan
df.replace(to_replace=, value=)
- to_replace:替换前的值
- value:替换后的值
wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data") wis.head()
wis = wis.replace(to_replace="?", value=np.nan) wis.head()
wis = wis.dropna()
np.any(pd.isnull(wis)) # 里面如果有一个缺失值,那么会返回True,说明有缺失值