定义
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离
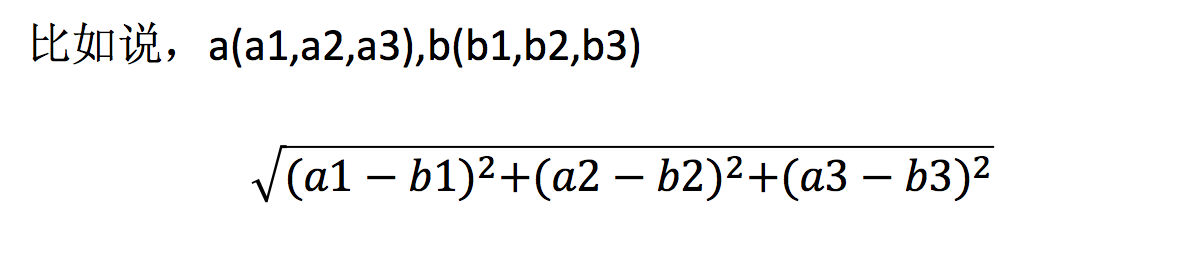
K-近邻算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
案例:
鸢尾花种类预测
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。关于数据集的具体介绍:

步骤分析
- 1.获取数据集
- 2.数据基本处理
- 3.特征工程
- 4.机器学习(模型训练)
- 5.模型评估
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier def knn_iris(): """ 用KNN算法对鸢尾花进行分类 :return: """ # 1)获取数据 iris = load_iris() # 2)划分数据集 x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22) # 3)特征工程:标准化 transfer = StandardScaler() x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test) # 4)KNN算法预估器 estimator = KNeighborsClassifier(n_neighbors=3) estimator.fit(x_train, y_train) # 5)模型评估 # 方法1:直接比对真实值和预测值 y_predict = estimator.predict(x_test) print("y_predict: ", y_predict) print("直接比对真实值和预测值: ", y_test == y_predict) # 方法2:计算准确率 score = estimator.score(x_test, y_test) print("准确率为: ", score) return None if __name__ == "__main__": # 代码1: 用KNN算法对鸢尾花进行分类 knn_iris()
