安装:
sudo tar -zxf /home/hadoop/下载/spark-3.0.1-bin-hadoop3.2.tgz -C /usr/local/ cd /usr/local sudo mv ./spark-3.0.1-bin-hadoop3.2/ ./spark sudo chown -R hadoop:hadoop ./spark cd spark/bin spark-shell
测试:
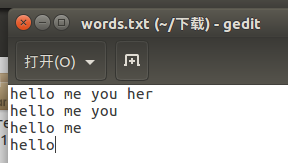
words.txt
hello me you her
hello me you
hello me
hello
运行:
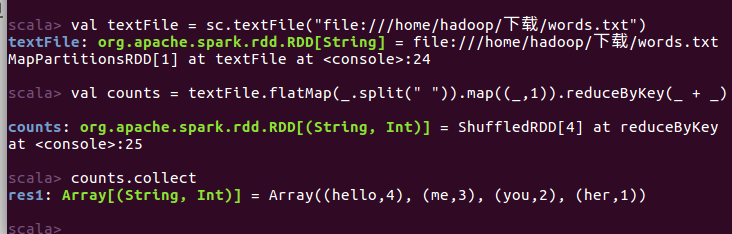
scala> val textFile = sc.textFile("file:///home/hadoop/下载/words.txt") scala> val counts = textFile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
scala> counts.collect
配置集群:(Standalone-独立集群)
master
slave1(worker)
slave2(worker)
slave3(worker)
配置slaves/workers
进入配置目录
cd /usr/local/spark/conf
cp slaves.template slaves
vim slaves
内容如下:

配置master
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
内容如下:
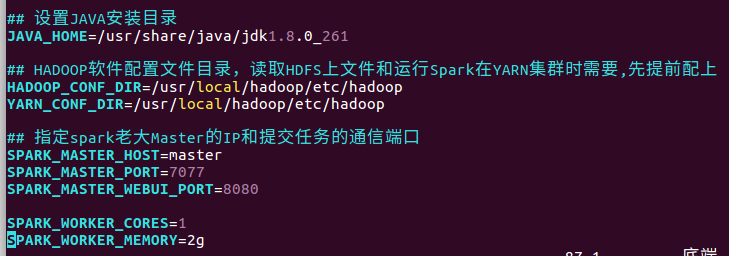
在最下面写入:
## 设置JAVA安装目录 JAVA_HOME=/usr/share/java/jdk1.8.0_261 ## HADOOP软件配置文件目录,读取HDFS上文件和运行Spark在YARN集群时需要,先提前配上 HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop YARN_CONF_DIR=/usr/local/hadoop/etc/hadoop ## 指定spark老大Master的IP和提交任务的通信端口 SPARK_MASTER_HOST=master SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=8080 SPARK_WORKER_CORES=1 SPARK_WORKER_MEMORY=2g
分发
cd /usr/local sudo scp -r spark hadoop@slave1:$PWD sudo scp -r spark hadoop@slave2:$PWD sudo scp -r spark hadoop@slave3:$PWD
若出现:

则在目标主机上执行:
sudo chmod 777 /usr/local/
再次执行分发命令即可
测试
集群启动和停止
在主节点上启动spark集群
cd /usr/local/spark/sbin
./start-all.sh
在主节点上停止spark集群
./stop-all.sh
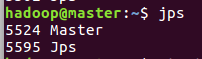
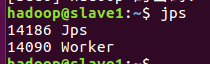
jps查看进程
master:
slave1
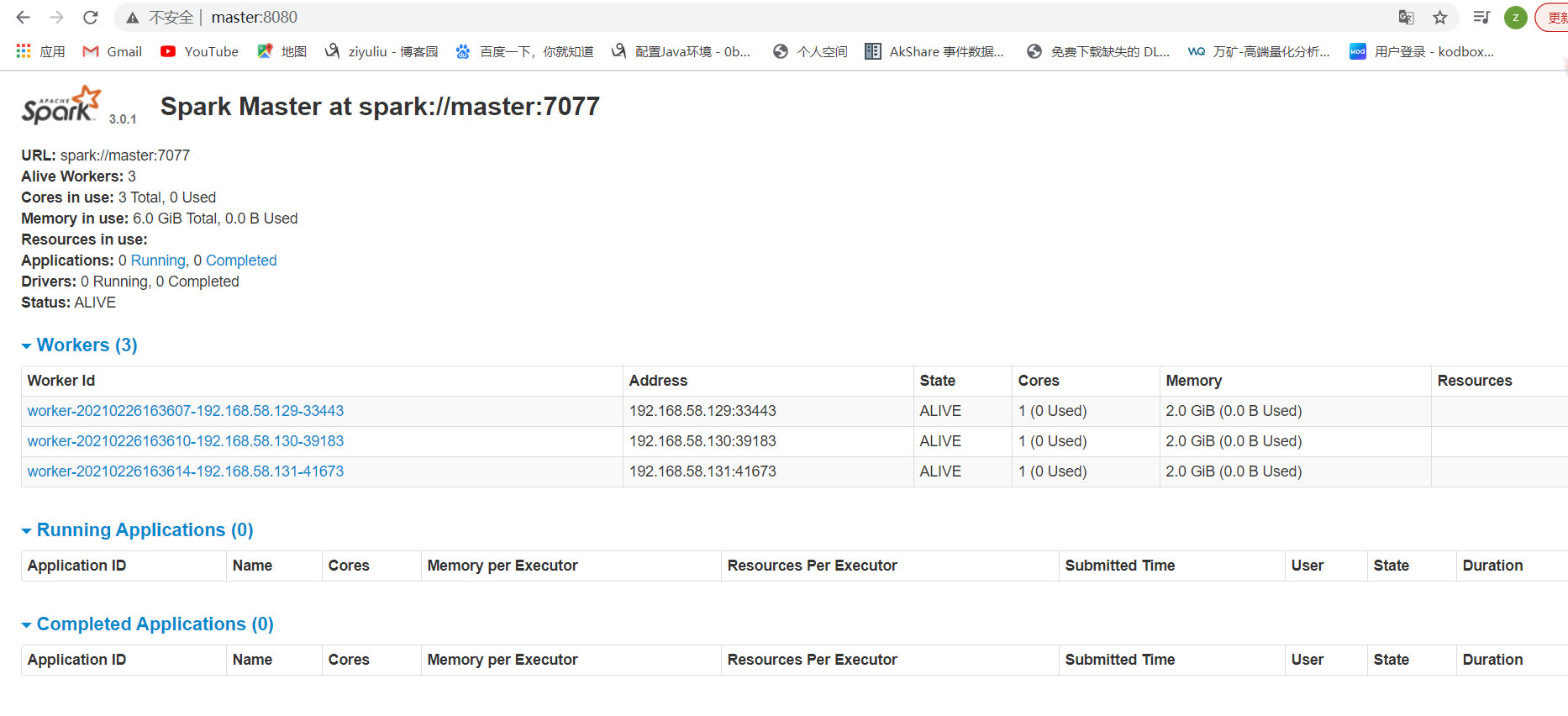
访问:
http://master:8080/
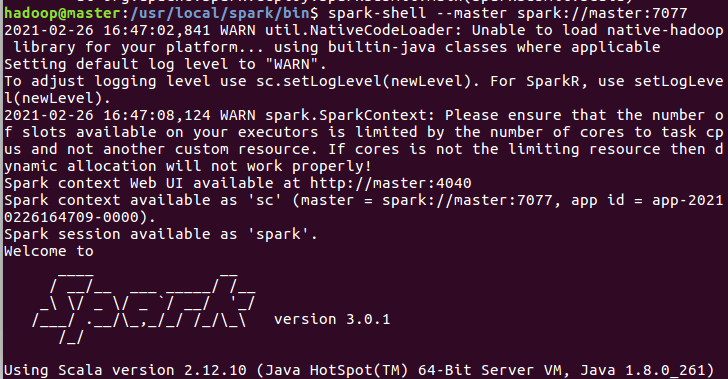
启动spark-shell
cd /usr/local/spark/bin spark-shell --master spark://master:7077
提交WordCount任务
注意:上传文件到hdfs方便worker读取
上传文件到hdfs
hadoop fs -put /home/hadoop/下载/words.txt /wordcount/input/words.txt
在shell上:
scala> val textFile = sc.textFile("hdfs://master:9000/wordcount/input/words.txt"
scala> val counts = textFile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
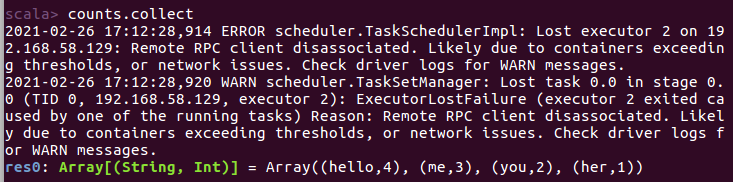
scala> counts.collect
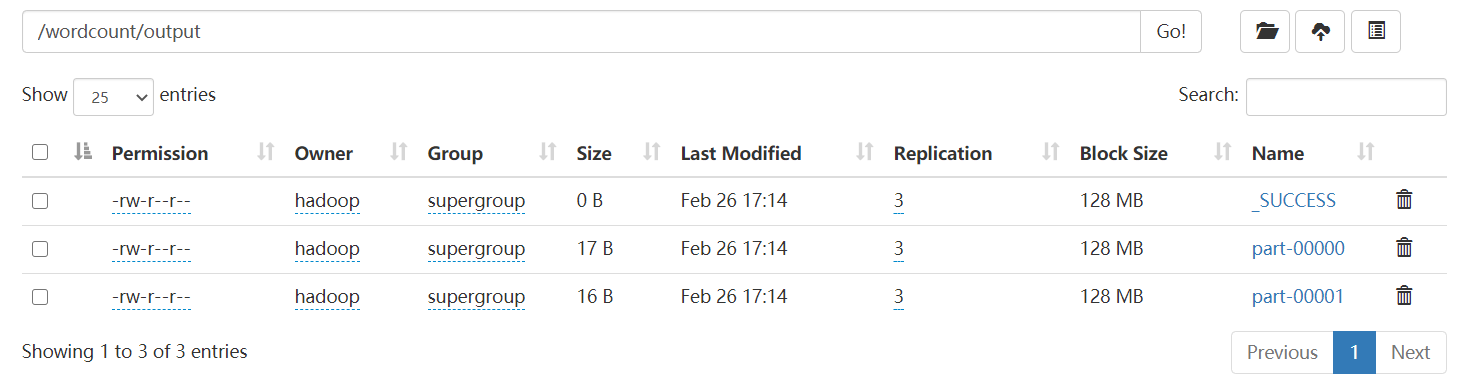
将结果写到hdfs文件系统:
counts.saveAsTextFile("hdfs://master:9000/wordcount/output")
查看spark任务web-ui
http://master:4040/
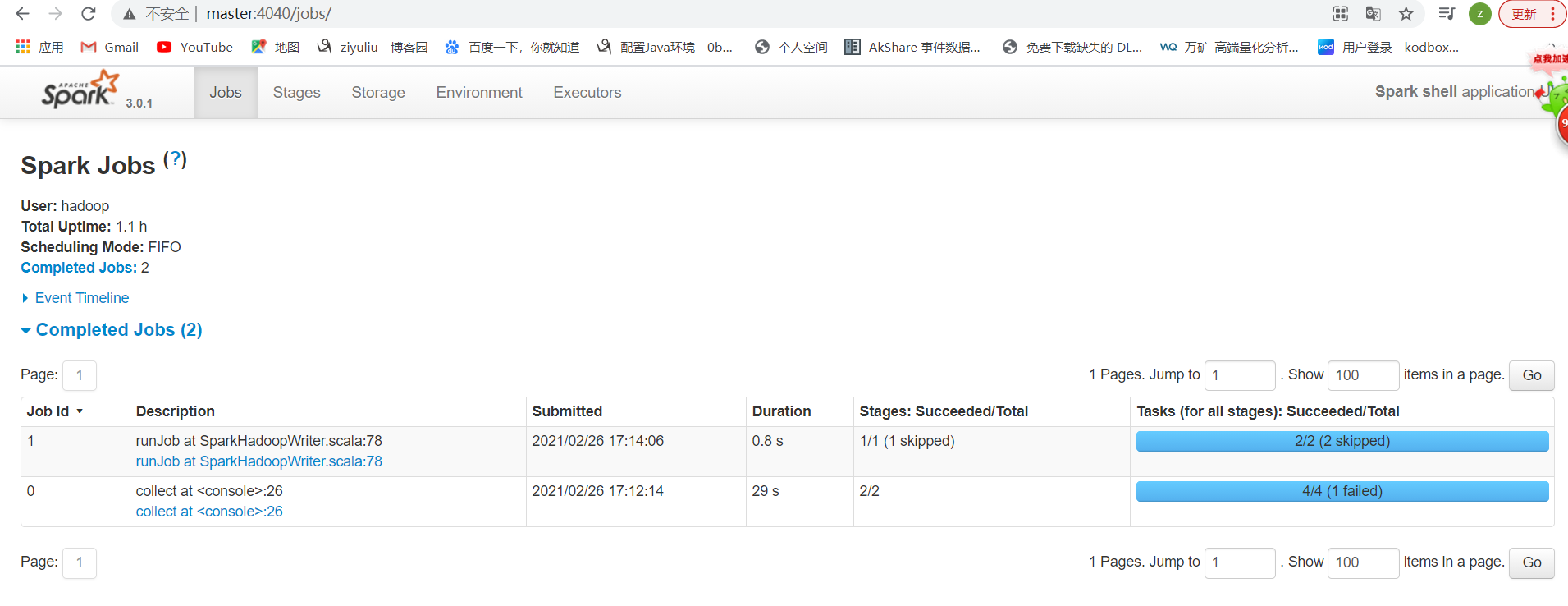
总结:
spark: 4040 任务运行web-ui界面端口
spark: 8080 spark集群web-ui界面端口
spark: 7077 spark提交任务时的通信端口
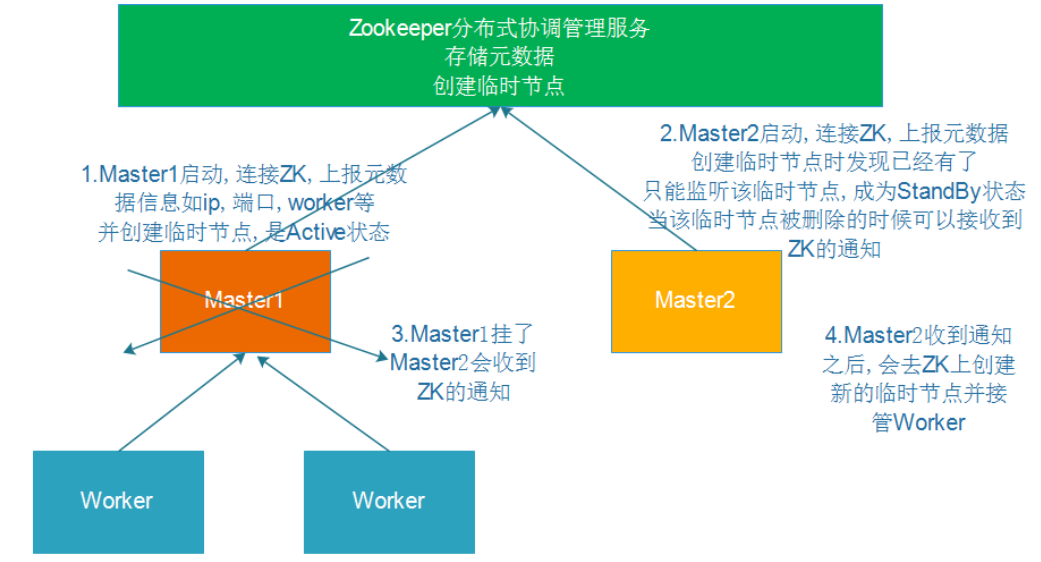
启动zk(每台机器上)
cd /usr/local/zookeeper/bin/
./zkServer.sh start
修改配置
cd /usr/local/spark/conf
vim spark-env.sh
注释
#SPARK_MASTER_HOST=master
修改端口为8888
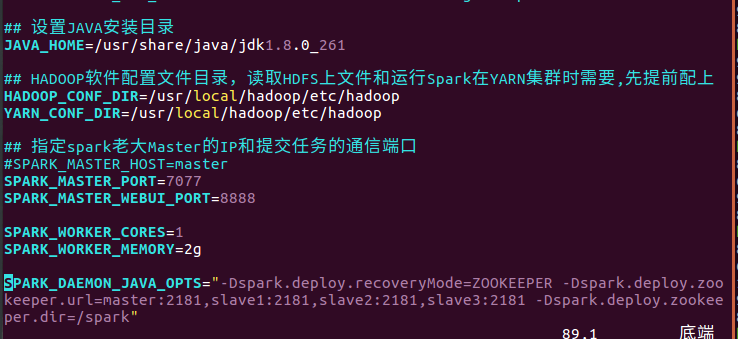
增加:
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181,slave3:2181 -Dspark.deploy.zookeeper.dir=/spark"
分发配置
scp -r spark-env.sh hadoop@slave1:$PWD scp -r spark-env.sh hadoop@slave2:$PWD scp -r spark-env.sh hadoop@slave3:$PWD
测试:
在master上启动Spark集群执行:
cd /usr/local/spark/sbin
./start-all.sh
在slave1上再单独只起个master:
cd /usr/local/spark/sbin
./start-master.sh
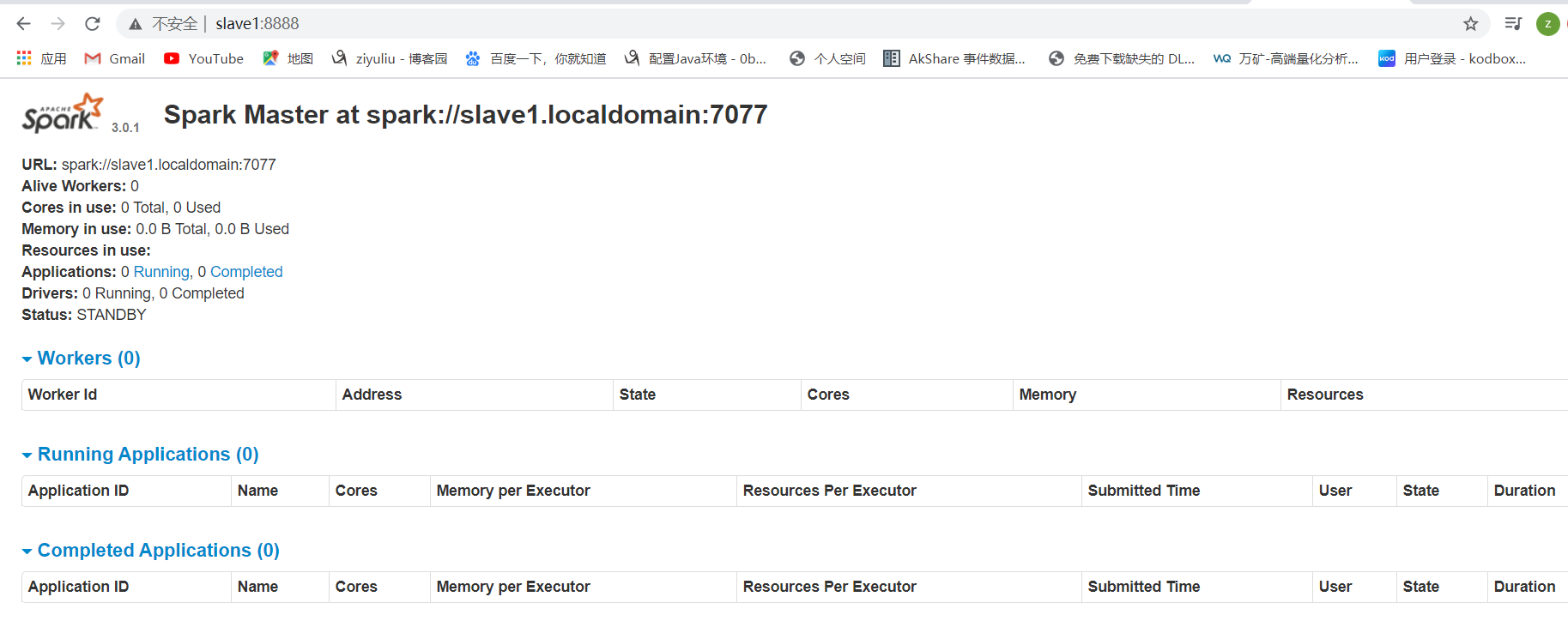
查看:
master:
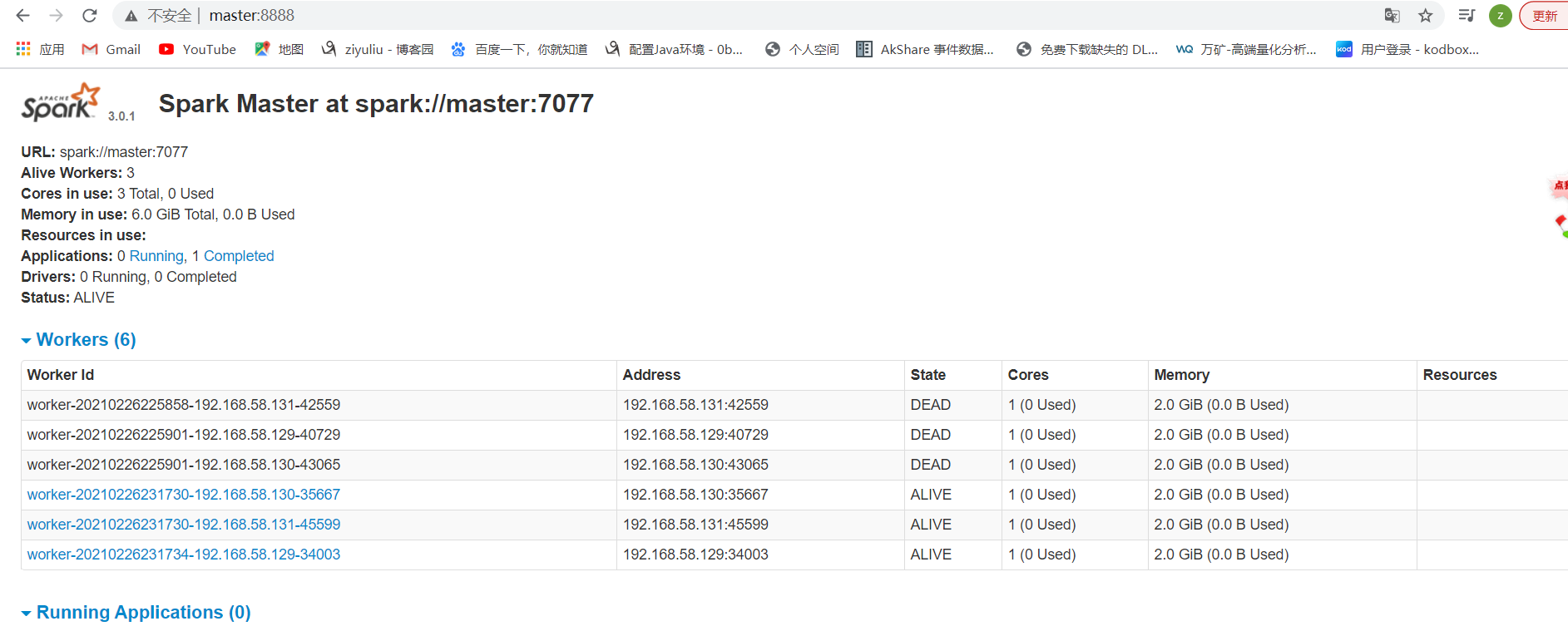
模拟node1宕机
jps
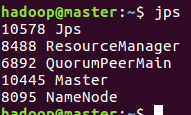
kill -9 10445
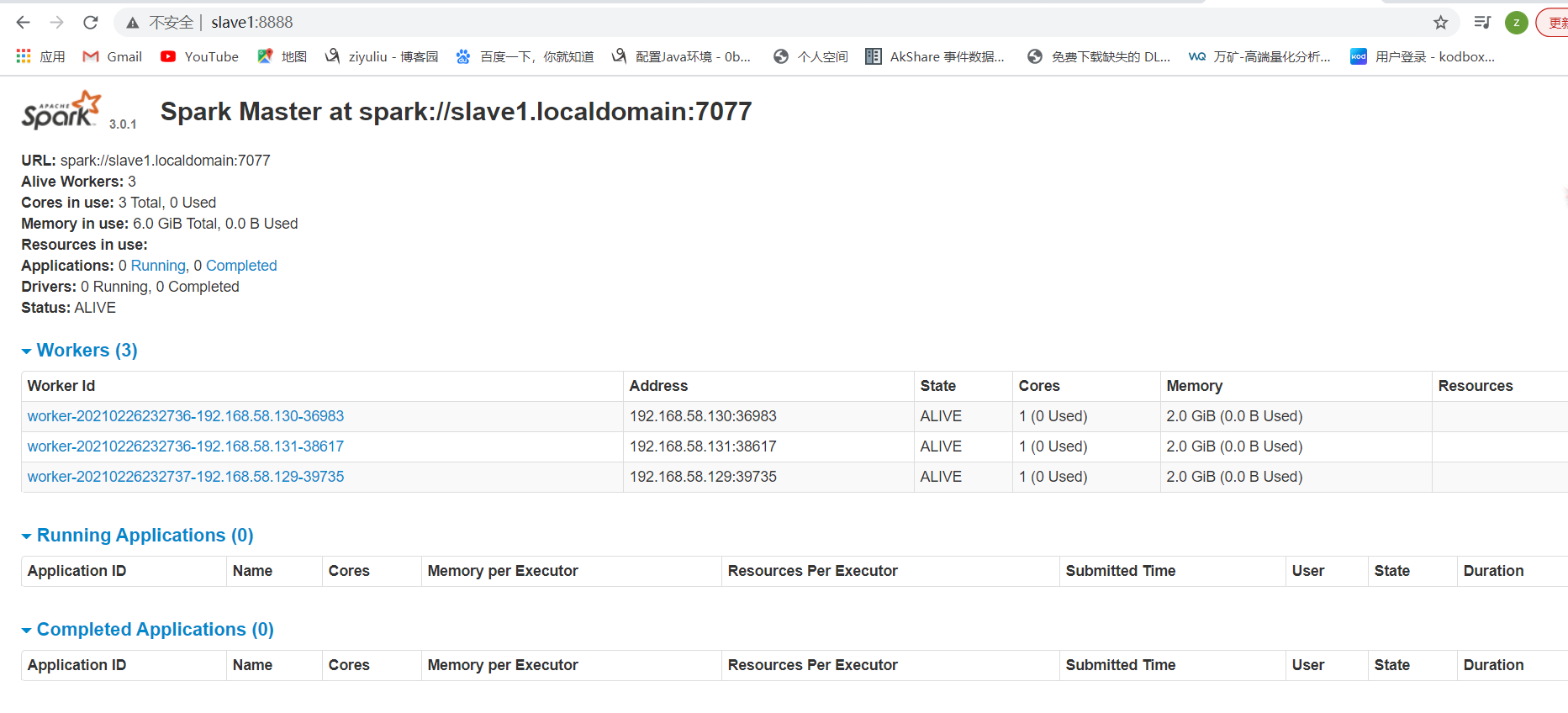
 在实际开发中, 大数据任务都有统一的资源管理和任务调度工具来进行管理! ---Yarn使用的最多!
在实际开发中, 大数据任务都有统一的资源管理和任务调度工具来进行管理! ---Yarn使用的最多!
因为它成熟稳定, 支持多种调度策略:FIFO/Capcity/Fair
可以使用Yarn调度管理MR/Hive/Spark/Flink
cd /usr/local/spark/sbin
stop-all.sh
cd /usr/local/hadoop/etc/hadoop
vim yarn-site.xml
内容如下:
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 设置yarn集群的内存分配方案 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<!-- 开启日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs</value>
</property>
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*</value>
</property>
</configuration>
分发:
scp -r yarn-site.xml hadoop@slave1:$PWD
scp -r yarn-site.xml hadoop@slave3:$PWD
scp -r yarn-site.xml hadoop@slave2:$PWD
cd /usr/local/spark/conf cp spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf
增加:
spark.eventLog.enabled true spark.eventLog.dir hdfs://master:9000/sparklog/ spark.eventLog.compress true spark.yarn.historyServer.address master:18080
修改spark-env.sh
vim spark-env.sh
增加:
## 配置spark历史日志存储地址 SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://master:9000/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
注意:sparklog需要手动创建
hadoop fs -mkdir -p /sparklog
修改日志级别
cd /usr/local/spark/conf
cp log4j.properties.template log4j.properties
vim log4j.properties

分发:
scp -r spark-env.sh hadoop@slave1:$PWD scp -r spark-env.sh hadoop@slave2:$PWD scp -r spark-env.sh hadoop@slave3:$PWD scp -r spark-defaults.conf hadoop@slave1:$PWD scp -r spark-defaults.conf hadoop@slave2:$PWD scp -r spark-defaults.conf hadoop@slave3:$PWD scp -r log4j.properties hadoop@slave1:$PWD log4j.properties scp -r log4j.properties hadoop@slave2:$PWD log4j.properties scp -r log4j.properties hadoop@slave3:$PWD log4j.properties
hadoop fs -mkdir -p /spark/jars/
上传$SPARK_HOME/jars所有jar包到HDFS
hadoop fs -put /usr/local/spark/jars/* /spark/jars/
修改spark-defaults.conf
vim spark-defaults.conf
增加:
spark.yarn.jars hdfs://master:9000/spark/jars/*
分发:
scp -r spark-defaults.conf hadoop@slave1:$PWD scp -r spark-defaults.conf hadoop@slave2:$PWD scp -r spark-defaults.conf hadoop@slave3:$PWD
启动HDFS和YARN服务
start-dfs.sh
start-yarn.sh
或
start-all.sh
启动MRHistoryServer服务
mr-jobhistory-daemon.sh start historyserver
启动Spark HistoryServer服务
cd /usr/local/spark/sbin
start-history-server.sh
MRHistoryServer服务WEB UI页面:
Spark HistoryServer服务WEB UI页面:
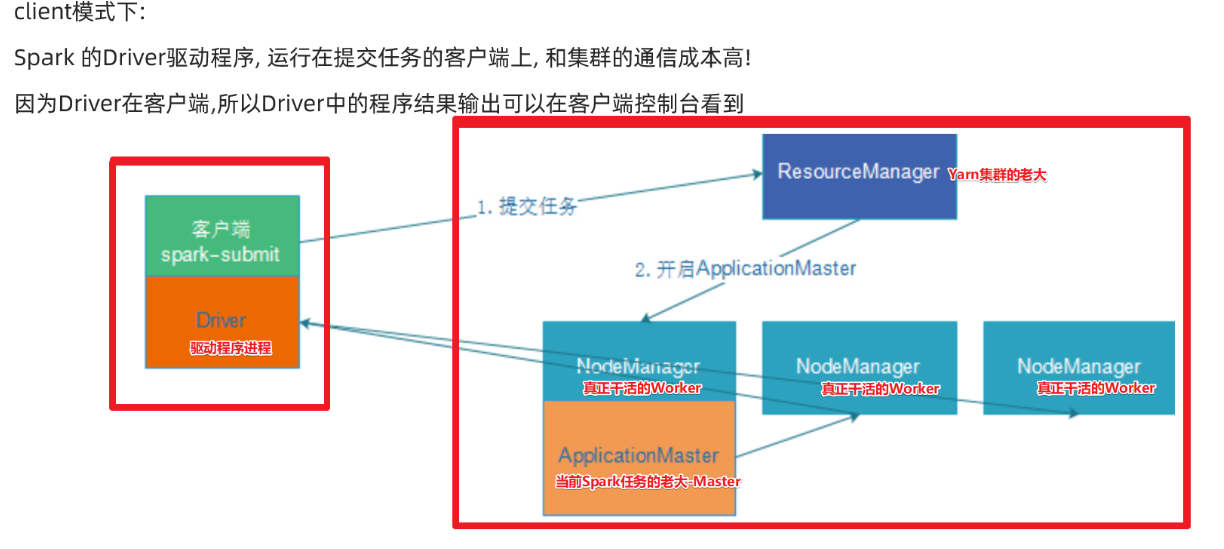
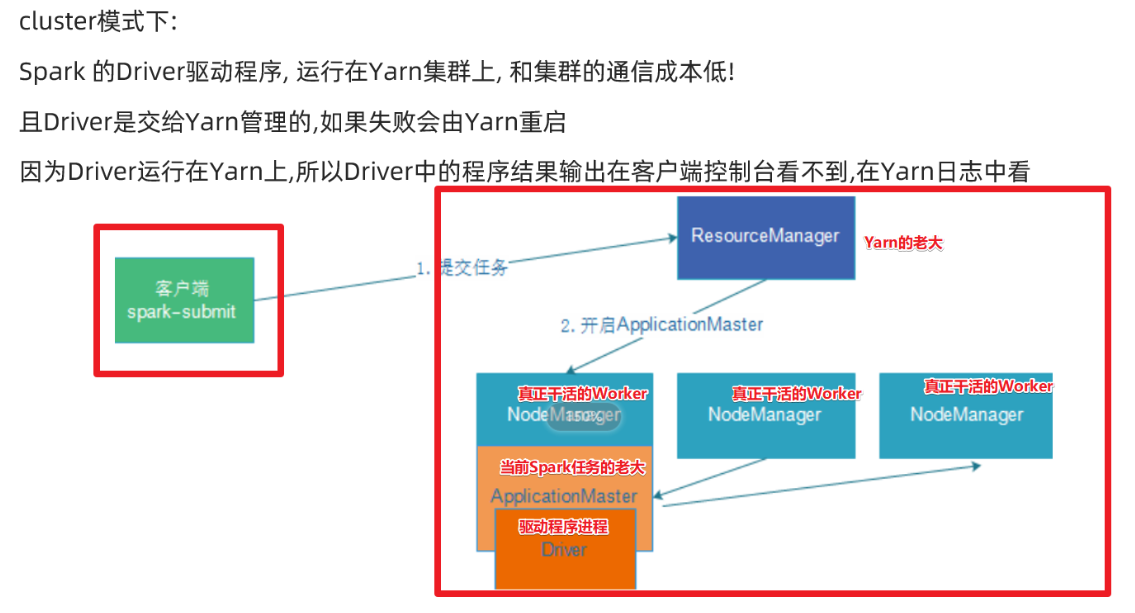
1.需要Yarn集群
2.历史服务器
3.提交任务的的客户端工具-spark-submit命令
4.待提交的spark任务/程序的字节码--可以使用示例程序
SPARK_HOME=/usr/local/spark ${SPARK_HOME}/bin/spark-submit --master yarn --deploy-mode client --driver-memory 512m --driver-cores 1 --executor-memory 512m --num-executors 2 --executor-cores 1 --class org.apache.spark.examples.SparkPi ${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar 10
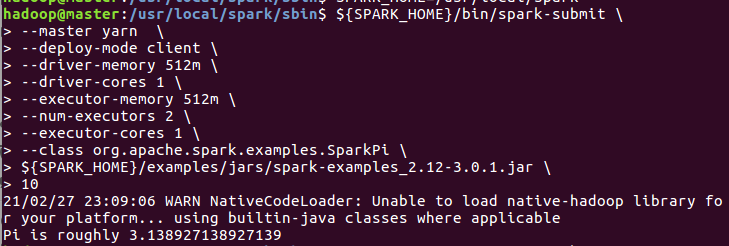
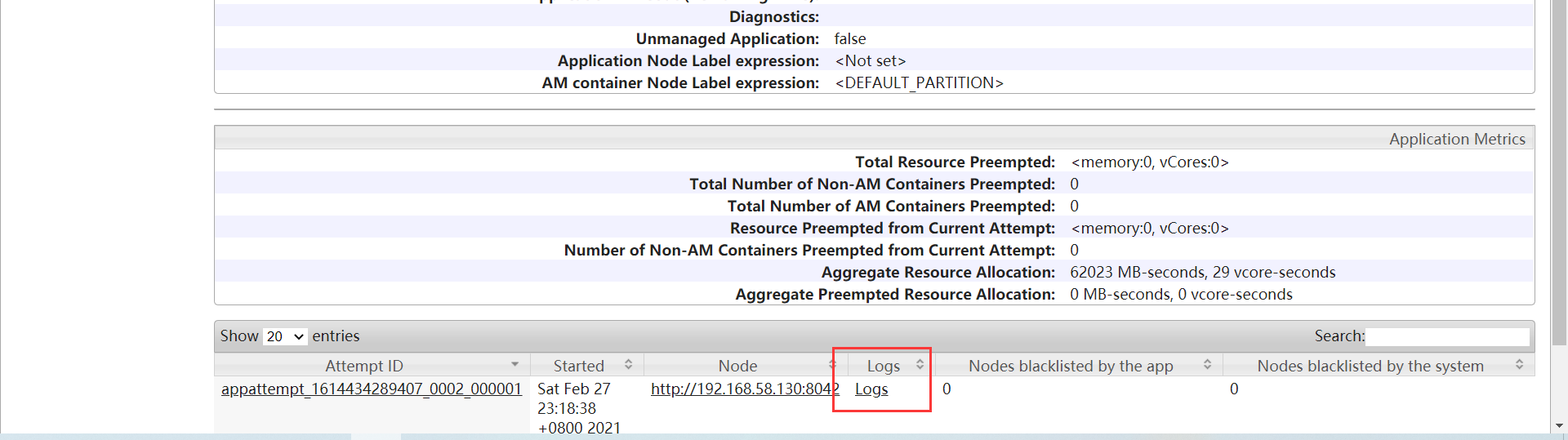
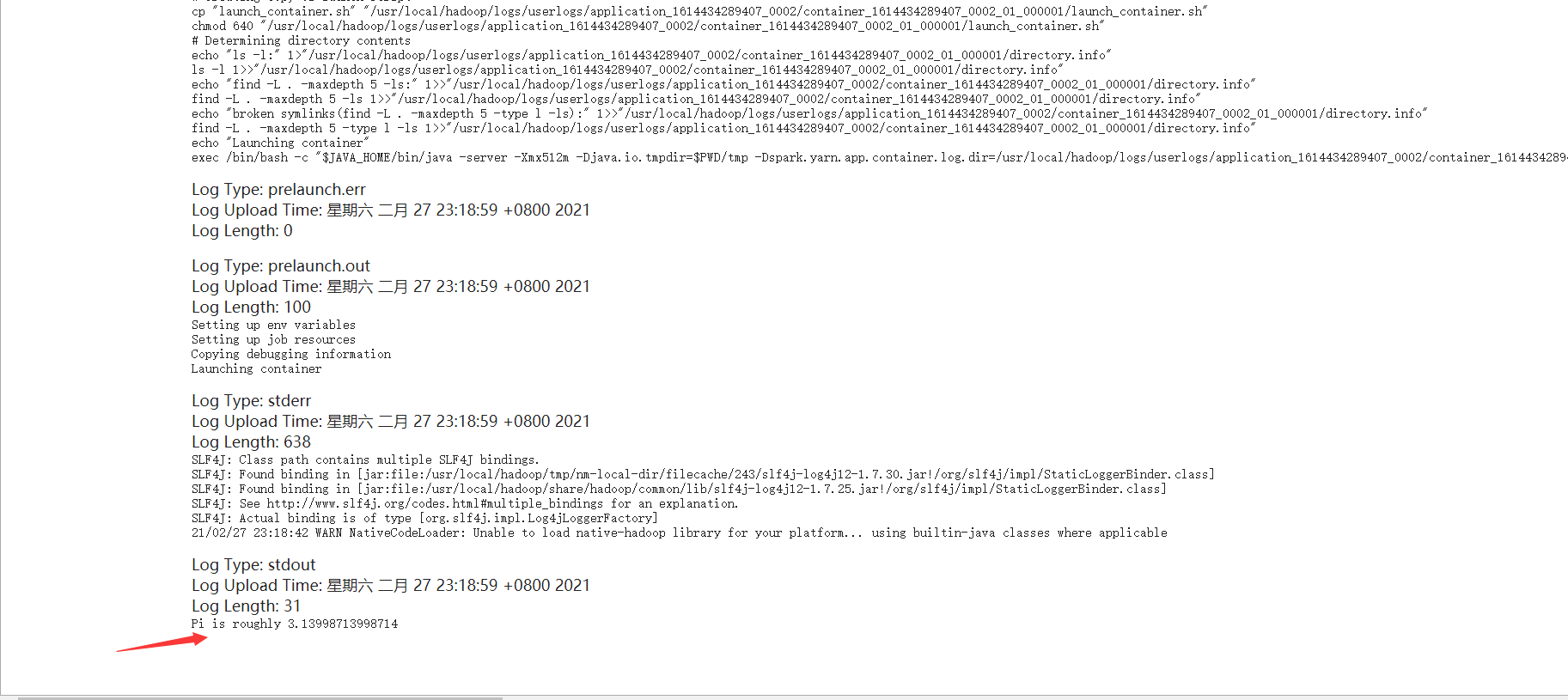
查看web界面
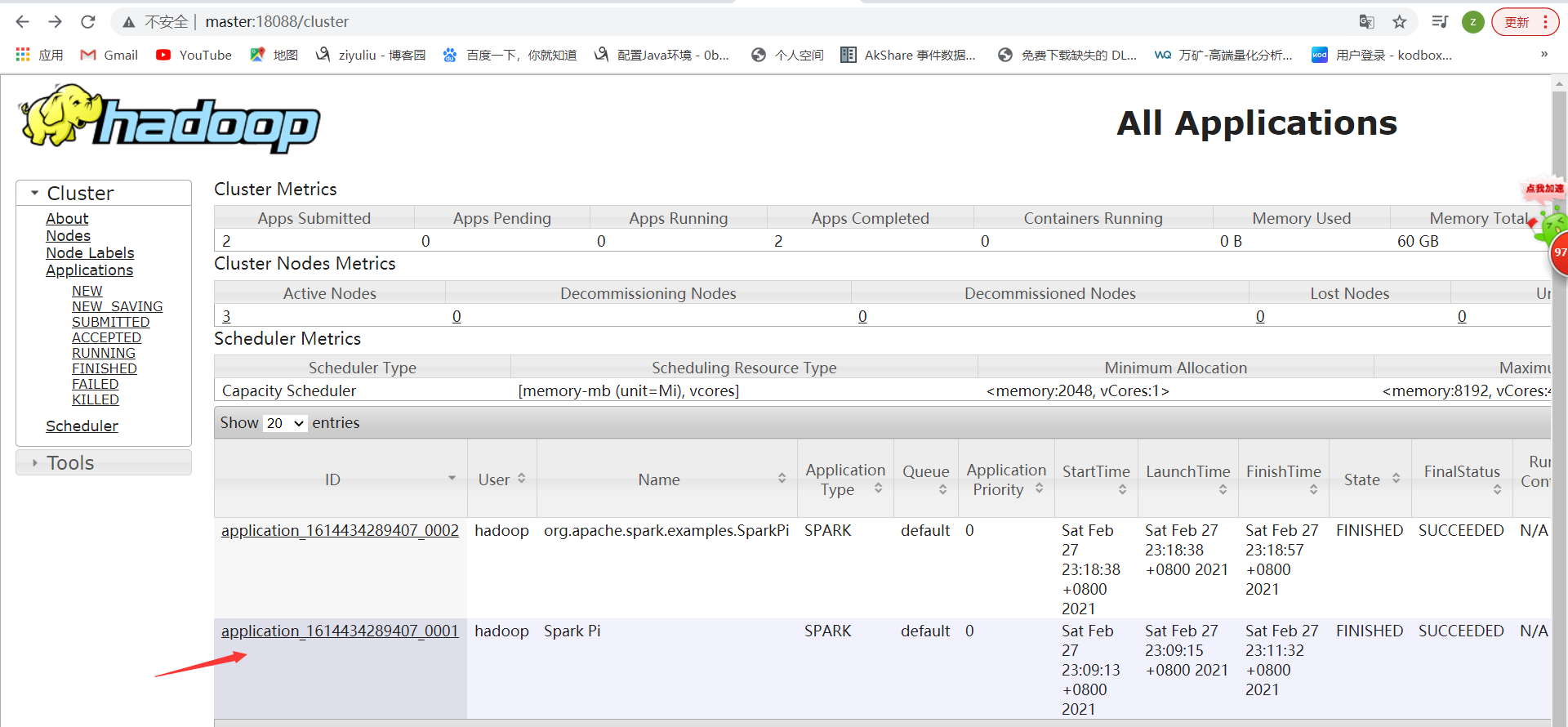
SPARK_HOME=/usr/local/spark ${SPARK_HOME}/bin/spark-submit --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --num-executors 1 --class org.apache.spark.examples.SparkPi ${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar 10
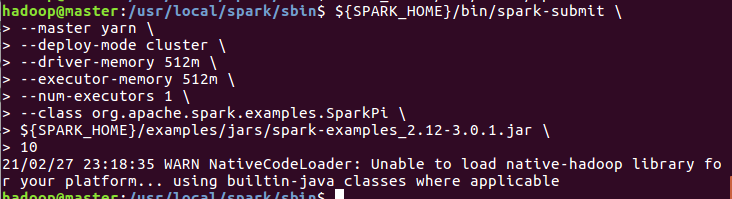
查看web界面

Spark程序开发
创建maven项目
添加pom.xml内容
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.itcast</groupId> <artifactId>spark_study_47</artifactId> <version>1.0-SNAPSHOT</version> <repositories> <repository> <id>aliyun</id> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> </repository> <repository> <id>apache</id> <url>https://repository.apache.org/content/repositories/snapshots/</url> </repository> <repository> <id>cloudera</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url> </repository> </repositories> <properties> <encoding>UTF-8</encoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <scala.version>2.12.11</scala.version> <spark.version>3.0.1</spark.version> <hadoop.version>2.7.5</hadoop.version> </properties> <dependencies> <!--依赖Scala语言--> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <!--SparkCore依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>${spark.version}</version> </dependency> <!-- spark-streaming--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>${spark.version}</version> </dependency> <!--spark-streaming+Kafka依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.12</artifactId> <version>${spark.version}</version> </dependency> <!--SparkSQL依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>${spark.version}</version> </dependency> <!--SparkSQL+ Hive依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive-thriftserver_2.12</artifactId> <version>${spark.version}</version> </dependency> <!--StructuredStreaming+Kafka依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql-kafka-0-10_2.12</artifactId> <version>${spark.version}</version> </dependency> <!-- SparkMlLib机器学习模块,里面有ALS推荐算法--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.12</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.5</version> </dependency> <dependency> <groupId>com.hankcs</groupId> <artifactId>hanlp</artifactId> <version>portable-1.7.7</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.38</version> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.47</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.2</version> <scope>provided</scope> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <plugins> <!-- 指定编译java的插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.5.1</version> </plugin> <!-- 指定编译scala的插件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>2.18.1</version> <configuration> <useFile>false</useFile> <disableXmlReport>true</disableXmlReport> <includes> <include>**/*Test.*</include> <include>**/*Suite.*</include> </includes> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass></mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
新建scala文件夹:
本地实现:
代码:
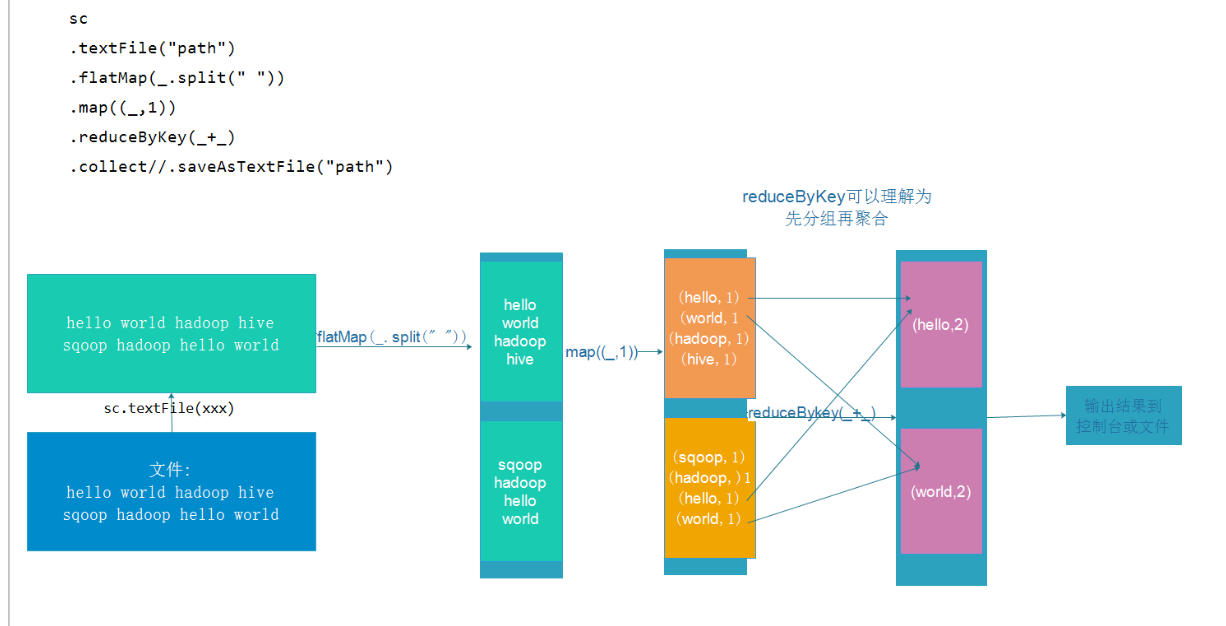
package cn.itcast.hello import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * Author itcast * Desc 演示Spark入门案例-WordCount */ object WordCount_bak { def main(args: Array[String]): Unit = { //TODO 1.env/准备sc/SparkContext/Spark上下文执行环境 val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) sc.setLogLevel("WARN") //TODO 2.source/读取数据 //RDD:A Resilient Distributed Dataset (RDD):弹性分布式数据集,简单理解为分布式集合!使用起来和普通集合一样简单! //RDD[就是一行行的数据] val lines: RDD[String] = sc.textFile("data/input/words.txt") //TODO 3.transformation/数据操作/转换 //切割:RDD[一个个的单词] val words: RDD[String] = lines.flatMap(_.split(" ")) //记为1:RDD[(单词, 1)] val wordAndOnes: RDD[(String, Int)] = words.map((_,1)) //分组聚合:groupBy + mapValues(_.map(_._2).reduce(_+_)) ===>在Spark里面分组+聚合一步搞定:reduceByKey val result: RDD[(String, Int)] = wordAndOnes.reduceByKey(_+_) //TODO 4.sink/输出 //直接输出 result.foreach(println) //收集为本地集合再输出 println(result.collect().toBuffer) //输出到指定path(可以是文件/夹) result.repartition(1).saveAsTextFile("data/output/result") result.repartition(2).saveAsTextFile("data/output/result2") result.saveAsTextFile("data/output/result3") //为了便于查看Web-UI可以让程序睡一会 Thread.sleep(1000 * 60) //TODO 5.关闭资源 sc.stop() } }
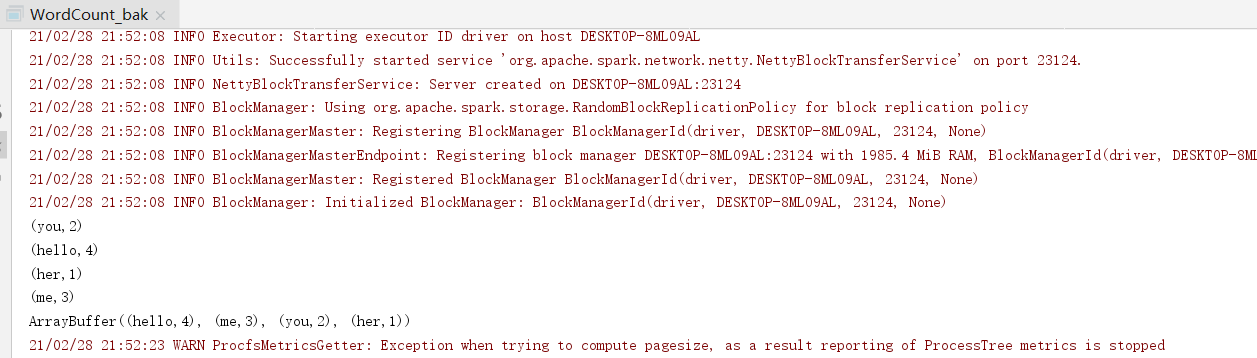

package cn.itcast.hello import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * Author itcast * Desc 演示Spark入门案例-WordCount-修改代码使适合在Yarn集群上运行 */ object WordCount { def main(args: Array[String]): Unit = { if(args.length < 2){ println("请指定input和output") System.exit(1)//非0表示非正常退出程序 } //TODO 1.env/准备sc/SparkContext/Spark上下文执行环境 val conf: SparkConf = new SparkConf().setAppName("wc")//.setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) sc.setLogLevel("WARN") //TODO 2.source/读取数据 //RDD:A Resilient Distributed Dataset (RDD):弹性分布式数据集,简单理解为分布式集合!使用起来和普通集合一样简单! //RDD[就是一行行的数据] val lines: RDD[String] = sc.textFile(args(0))//注意提交任务时需要指定input参数 //TODO 3.transformation/数据操作/转换 //切割:RDD[一个个的单词] val words: RDD[String] = lines.flatMap(_.split(" ")) //记为1:RDD[(单词, 1)] val wordAndOnes: RDD[(String, Int)] = words.map((_,1)) //分组聚合:groupBy + mapValues(_.map(_._2).reduce(_+_)) ===>在Spark里面分组+聚合一步搞定:reduceByKey val result: RDD[(String, Int)] = wordAndOnes.reduceByKey(_+_) //TODO 4.sink/输出 //直接输出 //result.foreach(println) //收集为本地集合再输出 //println(result.collect().toBuffer) //输出到指定path(可以是文件/夹) //如果涉及到HDFS权限问题不能写入,需要执行: //hadoop fs -chmod -R 777 / //并添加如下代码 System.setProperty("HADOOP_USER_NAME", "root") result.repartition(1).saveAsTextFile(args(1))//注意提交任务时需要指定output参数 //为了便于查看Web-UI可以让程序睡一会 //Thread.sleep(1000 * 60) //TODO 5.关闭资源 sc.stop() } }
打包:
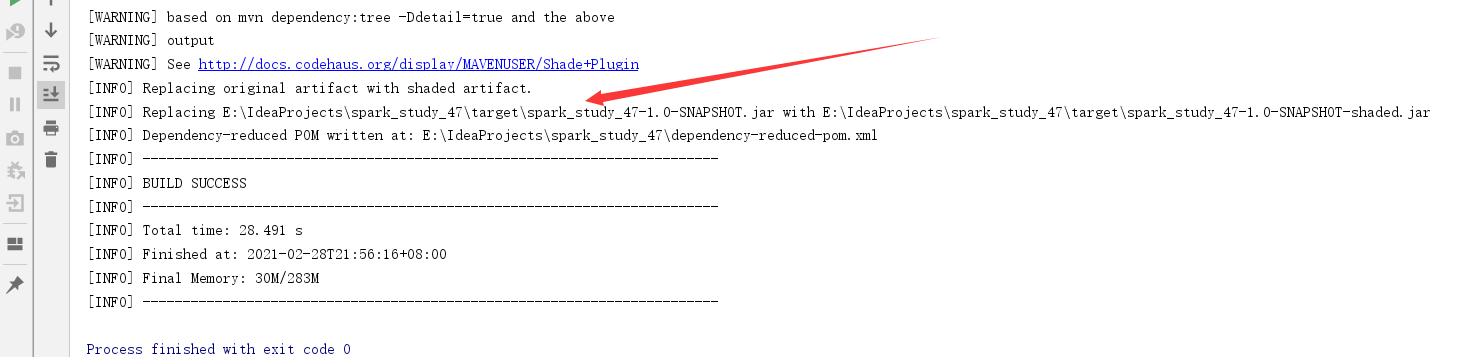

改为wc.jar
上传到linux上

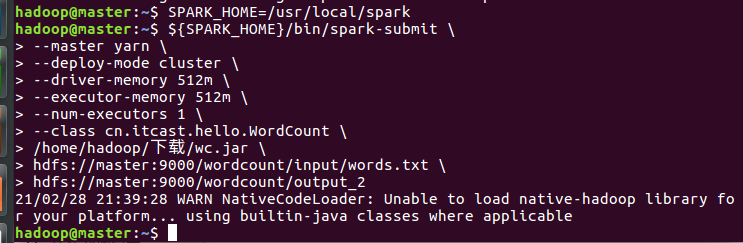
提交任务
先启动yarn集群:
start-all.sh
运行:
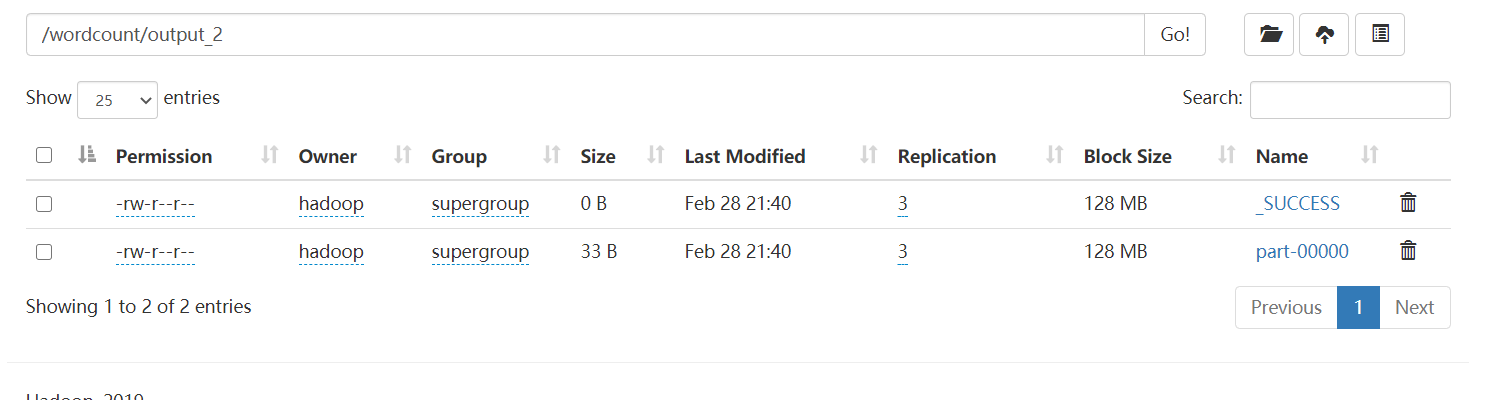
SPARK_HOME=/usr/local/spark ${SPARK_HOME}/bin/spark-submit --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --num-executors 1 --class cn.itcast.hello.WordCount /home/hadoop/下载/wc.jar hdfs://master:9000/wordcount/input/words.txt hdfs://master:9000/wordcount/output_2