需求:针对personDF中的数据使用SQL和DSL两种方式进行各种查询
package cn.itcast.sql import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SparkSession} /** * Author itcast * Desc 演示SparkSQL-SQL和DSL两种方式实现各种查询 */ object Demo04_Query { def main(args: Array[String]): Unit = { //TODO 0.准备环境 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") //TODO 1.加载数据 val lines: RDD[String] = sc.textFile("data/input/person.txt") //TODO 2.处理数据 val personRDD: RDD[Person] = lines.map(line => { val arr: Array[String] = line.split(" ") Person(arr(0).toInt, arr(1), arr(2).toInt) }) //RDD-->DF import spark.implicits._ val personDF: DataFrame = personRDD.toDF() personDF.printSchema() personDF.show() /* root |-- id: integer (nullable = false) |-- name: string (nullable = true) |-- age: integer (nullable = false) +---+--------+---+ | id| name|age| +---+--------+---+ | 1|zhangsan| 20| | 2| lisi| 29| | 3| wangwu| 25| | 4| zhaoliu| 30| | 5| tianqi| 35| | 6| kobe| 40| +---+--------+---+ */ //TODO ===========SQL============== //注册表名 //personDF.registerTempTable("")//过期的 //personDF.createOrReplaceGlobalTempView("")//创建全局的,夸SparkSession也可以用,但是生命周期太长! personDF.createOrReplaceTempView("t_person")//创建临时的,当前SparkSession也可以用 //=1.查看name字段的数据 spark.sql("select name from t_person").show() //=2.查看 name 和age字段数据 spark.sql("select name,age from t_person").show() //=3.查询所有的name和age,并将age+1 spark.sql("select name,age,age+1 from t_person").show() //=4.过滤age大于等于25的 spark.sql("select name,age from t_person where age >= 25").show() //=5.统计年龄大于30的人数 spark.sql("select count(*) from t_person where age > 30").show() //=6.按年龄进行分组并统计相同年龄的人数 spark.sql("select age,count(*) from t_person group by age").show() //=7.查询姓名=张三的 spark.sql("select * from t_person where name = 'zhangsan'").show() //TODO ===========DSL:面向对象的SQL============== //=1.查看name字段的数据 //personDF.select(personDF.col("name")) personDF.select("name").show() //=2.查看 name 和age字段数据 personDF.select("name","age").show() //=3.查询所有的name和age,并将age+1 //personDF.select("name","age","age+1").show()//错误的:cannot resolve '`age+1`' given input columns: [age, id, name];; //注意$是把字符串转为了Column列对象 personDF.select($"name",$"age",$"age" + 1).show() //注意'是把列名转为了Column列对象 personDF.select('name,'age,'age + 1).show() //=4.过滤age大于等于25的 personDF.filter("age >= 25").show() personDF.filter($"age" >= 25).show() personDF.filter('age >= 25).show() //=5.统计年龄大于30的人数 val count: Long = personDF.where('age > 30).count() //where底层filter println("年龄大于30的人数为:"+count) //=6.按年龄进行分组并统计相同年龄的人数 personDF.groupBy('age).count().show() //=7.查询姓名=张三的 personDF.filter("name = 'zhangsan'").show() personDF.filter($"name"==="zhangsan").show() personDF.filter('name ==="zhangsan").show() personDF.filter('name =!="zhangsan").show() //TODO 3.输出结果 //TODO 4.关闭资源 spark.stop() } case class Person(id:Int,name:String,age:Int) }
结果:
root |-- id: integer (nullable = false) |-- name: string (nullable = true) |-- age: integer (nullable = false) +---+--------+---+ | id| name|age| +---+--------+---+ | 1|zhangsan| 20| | 2| lisi| 29| | 3| wangwu| 25| | 4| zhaoliu| 30| | 5| tianqi| 35| | 6| kobe| 40| +---+--------+---+ +--------+ | name| +--------+ |zhangsan| | lisi| | wangwu| | zhaoliu| | tianqi| | kobe| +--------+ +--------+---+ | name|age| +--------+---+ |zhangsan| 20| | lisi| 29| | wangwu| 25| | zhaoliu| 30| | tianqi| 35| | kobe| 40| +--------+---+ +--------+---+---------+ | name|age|(age + 1)| +--------+---+---------+ |zhangsan| 20| 21| | lisi| 29| 30| | wangwu| 25| 26| | zhaoliu| 30| 31| | tianqi| 35| 36| | kobe| 40| 41| +--------+---+---------+ +-------+---+ | name|age| +-------+---+ | lisi| 29| | wangwu| 25| |zhaoliu| 30| | tianqi| 35| | kobe| 40| +-------+---+ +--------+ |count(1)| +--------+ | 2| +--------+ +---+--------+ |age|count(1)| +---+--------+ | 20| 1| | 40| 1| | 35| 1| | 25| 1| | 29| 1| | 30| 1| +---+--------+ +---+--------+---+ | id| name|age| +---+--------+---+ | 1|zhangsan| 20| +---+--------+---+ +--------+ | name| +--------+ |zhangsan| | lisi| | wangwu| | zhaoliu| | tianqi| | kobe| +--------+ +--------+---+ | name|age| +--------+---+ |zhangsan| 20| | lisi| 29| | wangwu| 25| | zhaoliu| 30| | tianqi| 35| | kobe| 40| +--------+---+ +--------+---+---------+ | name|age|(age + 1)| +--------+---+---------+ |zhangsan| 20| 21| | lisi| 29| 30| | wangwu| 25| 26| | zhaoliu| 30| 31| | tianqi| 35| 36| | kobe| 40| 41| +--------+---+---------+ +--------+---+---------+ | name|age|(age + 1)| +--------+---+---------+ |zhangsan| 20| 21| | lisi| 29| 30| | wangwu| 25| 26| | zhaoliu| 30| 31| | tianqi| 35| 36| | kobe| 40| 41| +--------+---+---------+ +---+-------+---+ | id| name|age| +---+-------+---+ | 2| lisi| 29| | 3| wangwu| 25| | 4|zhaoliu| 30| | 5| tianqi| 35| | 6| kobe| 40| +---+-------+---+ +---+-------+---+ | id| name|age| +---+-------+---+ | 2| lisi| 29| | 3| wangwu| 25| | 4|zhaoliu| 30| | 5| tianqi| 35| | 6| kobe| 40| +---+-------+---+ +---+-------+---+ | id| name|age| +---+-------+---+ | 2| lisi| 29| | 3| wangwu| 25| | 4|zhaoliu| 30| | 5| tianqi| 35| | 6| kobe| 40| +---+-------+---+ 年龄大于30的人数为:2 +---+-----+ |age|count| +---+-----+ | 20| 1| | 40| 1| | 35| 1| | 25| 1| | 29| 1| | 30| 1| +---+-----+ +---+--------+---+ | id| name|age| +---+--------+---+ | 1|zhangsan| 20| +---+--------+---+ +---+--------+---+ | id| name|age| +---+--------+---+ | 1|zhangsan| 20| +---+--------+---+ +---+--------+---+ | id| name|age| +---+--------+---+ | 1|zhangsan| 20| +---+--------+---+ +---+-------+---+ | id| name|age| +---+-------+---+ | 2| lisi| 29| | 3| wangwu| 25| | 4|zhaoliu| 30| | 5| tianqi| 35| | 6| kobe| 40| +---+-------+---+
。
package cn.itcast.sql import org.apache.spark.SparkContext import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} /** * Author itcast * Desc 演示SparkSQL-SQL和DSL两种方式实现WordCount */ object Demo05_WordCount { def main(args: Array[String]): Unit = { //TODO 0.准备环境 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") import spark.implicits._ //TODO 1.加载数据 val df: DataFrame = spark.read.text("data/input/words.txt") val ds: Dataset[String] = spark.read.textFile("data/input/words.txt") df.printSchema() df.show() ds.printSchema() ds.show() /* root |-- value: string (nullable = true) +----------------+ | value| +----------------+ |hello me you her| | hello you her| | hello her| | hello| +----------------+ */ //TODO 2.处理数据 //df.flatMap(_.split(" "))//注意:df没有泛型,不能直接使用split val words: Dataset[String] = ds.flatMap(_.split(" ")) words.printSchema() words.show() /* root |-- value: string (nullable = true) +-----+ |value| +-----+ |hello| | me| | you| | her| |hello| | you| | her| |hello| | her| |hello| +-----+ */ //TODO ===SQL=== words.createOrReplaceTempView("t_words") val sql:String = """ |select value,count(*) as counts |from t_words |group by value |order by counts desc |""".stripMargin spark.sql(sql).show() //TODO ===DSL=== words.groupBy('value) .count() .orderBy('count.desc) .show() //TODO 3.输出结果 //TODO 4.关闭资源 spark.stop() } }

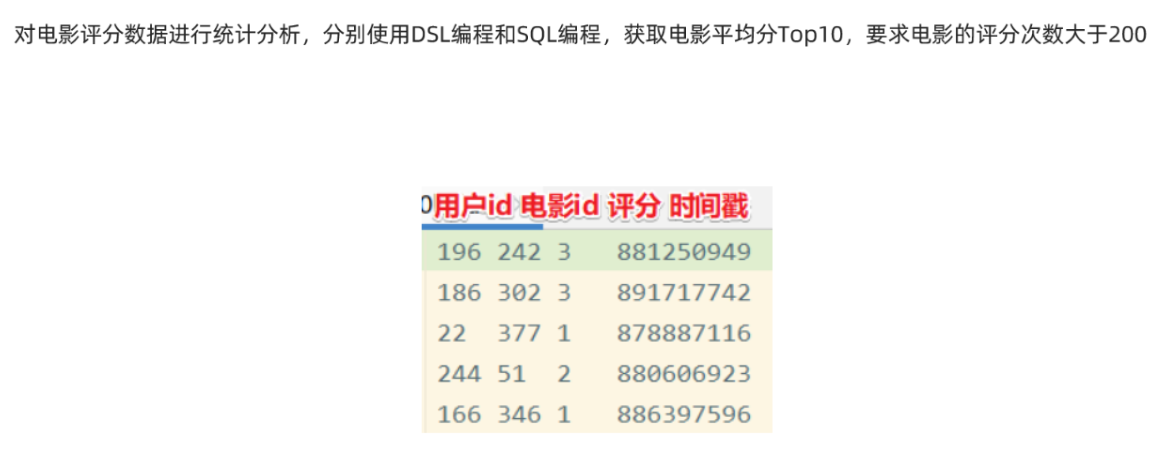
package cn.itcast.sql import org.apache.spark.SparkContext import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} /** * Author itcast * Desc 演示SparkSQL-完成电影数据分析 */ object Demo07_MovieDataAnalysis { def main(args: Array[String]): Unit = { //TODO 0.准备环境 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]") .config("spark.sql.shuffle.partitions", "4")//本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200 .getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") import spark.implicits._ //TODO 1.加载数据 val ds: Dataset[String] = spark.read.textFile("data/input/rating_100k.data") //TODO 2.处理数据 val movieDF: DataFrame = ds.map(line => { val arr: Array[String] = line.split(" ") (arr(1), arr(2).toInt) }).toDF("movieId", "score") movieDF.printSchema() movieDF.show() /* +-------+-----+ |movieId|score| +-------+-----+ | 242| 3| | 302| 3| */ //需求:统计评分次数>200的电影平均分Top10 //TODO ======SQL //注册表 movieDF.createOrReplaceTempView("t_movies") val sql: String = """ |select movieId,avg(score) as avgscore,count(*) as counts |from t_movies |group by movieId |having counts > 200 |order by avgscore desc |limit 10 |""".stripMargin spark.sql(sql).show() /* +-------+------------------+------+ |movieId| avgscore|counts| +-------+------------------+------+ | 318| 4.466442953020135| 298| | 483| 4.45679012345679| 243| | 64| 4.445229681978798| 283| | 603|4.3875598086124405| 209| ..... */ //TODO ======DSL import org.apache.spark.sql.functions._ movieDF.groupBy('movieId) .agg( avg('score) as "avgscore", count("movieId") as "counts" ).filter('counts > 200) .orderBy('avgscore.desc) .limit(10) .show() //TODO 3.输出结果 //TODO 4.关闭资源 spark.stop() } }