实验目的
1.了解reduce端join的适用场景
2.准确理解reduce端join的设计原理
3.熟练掌握reduce端join程序代码的编写
实验原理
在Reudce端进行Join连接是MapReduce框架进行表之间Join操作最为常见的模式。
1.Reduce端Join实现原理
(1)Map端的主要工作,为来自不同表(文件)的key/value对打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
(2)Reduce端的主要工作,在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在map阶段已经打标志)分开,最后进行笛卡尔只就ok了。
2.Reduce端Join的使用场景
Reduce端连接比Map端连接更为普遍,因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中,但是Reduce端连接效率比较低,因为所有数据都必须经过Shuffle过程。
3.本实验的Reduce端Join代码执行流程:
(1)Map端读取所有的文件,并在输出的内容里加上标识,代表数据是从哪个文件里来的。
(2)在Reduce处理函数中,按照标识对数据进行处理。
(3)然后将相同的key值进行Join连接操作,求出结果并直接输出。
启动hadoop

生成文件

创建项目、写入代码
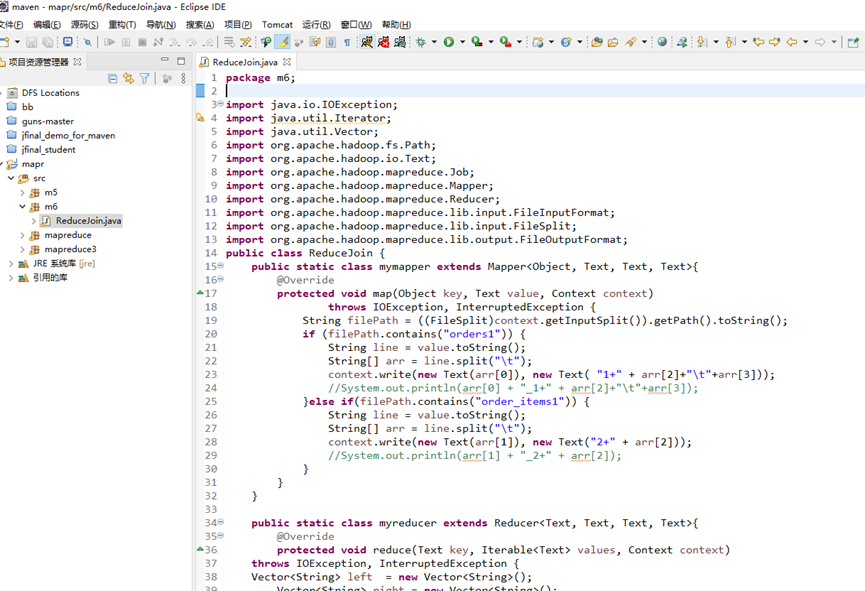
运行
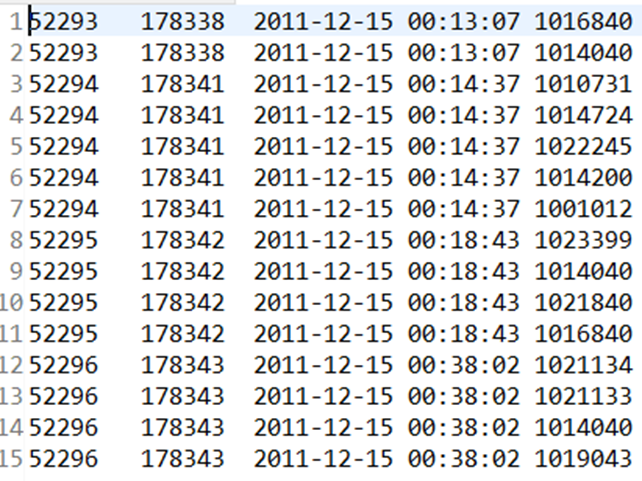
结果:
