实验目的
1.了解Hadoop自带的几种输入格式
2.准确理解MapReduce自定义输入格式的设计原理
3.熟练掌握MapReduce自定义输入格式程序代码编写
4.培养自己编写MapReduce自定义输入格式程序代码解决实际问题
实验原理
1.输入格式:InputFormat类定义了如何分割和读取输入文件,它提供有下面的几个功能:
(1)选择作为输入的文件或对象;
(2) 定义把文件划分到任务的InputSplits;
(3)为RecordReader读取文件提供了一个工厂方法;
Hadoop自带了好几个输入格式。其中有一个抽象类叫FileInputFormat,所有操作文件的InputFormat类都是从它那里继承功能和属性。当开启Hadoop作业时,FileInputFormat会得到一个路径参数,这个路径内包含了所需要处理的文件,FileInputFormat会读取这个文件夹内的所有文件(译注:默认不包括子文件夹内的),然后它会把这些文件拆分成一个或多个的InputSplit。你可以通过JobConf对象的setInputFormat()方法来设定应用到你的作业输入文件上的输入格式。下表给出了一些
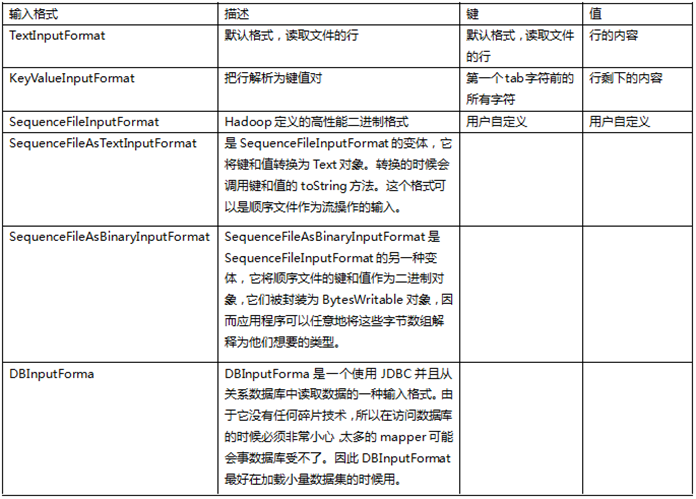
默认的输入格式是TextInputFormat,它把输入文件每一行作为单独的一个记录,但不做解析处理。这对那些没有被格式化的数据或是基于行的记录来说是很有用的,比如日志文件。更有趣的一个输入格式是KeyValueInputFormat,这个格式也是把输入文件每一行作为单独的一个记录。然而不同的是TextInputFormat把整个文件行当做值数据,KeyValueInputFormat则是通过搜寻tab字符来把行拆分为键值对。这在把一个MapReduce的作业输出作为下一个作业的输入时显得特别有用,因为默认输出格式(下面有更详细的描述)正是按KeyValueInputFormat格式输出数据。最后来讲讲SequenceFileInputFormat,它会读取特殊的特定于Hadoop的二进制文件,这些文件包含了很多能让Hadoop的mapper快速读取数据的特性。Sequence文件是块压缩的并提供了对几种数据类型(不仅仅是文本类型)直接的序列化与反序列化操作。Squence文件可以作为MapReduce任务的输出数据,并且用它做一个MapReduce作业到另一个作业的中间数据是很高效的。
输入块(InputSplit):一个输入块描述了构成MapReduce程序中单个map任务的一个单元。把一个MapReduce程序应用到一个数据集上,即是指一个作业,会由几个(也可能几百个)任务组成。Map任务可能会读取整个文件,但一般是读取文件的一部分。默认情况下,FileInputFormat及其子类会以64MB(与HDFS的Block默认大小相同,译注:Hadoop建议Split大小与此相同)为基数来拆分文件。你可以在hadoop-site.xml(译注:0.20.*以后是在mapred-default.xml里)文件内设定mapred.min.split.size参数来控制具体划分大小,或者在具体MapReduce作业的JobConf对象中重写这个参数。通过以块形式处理文件,我们可以让多个map任务并行的操作一个文件。如果文件非常大的话,这个特性可以通过并行处理大幅的提升性能。更重要的是,因为多个块(Block)组成的文件可能会分散在集群内的好几个节点上(译注:事实上就是这样),这样就可以把任务调度在不同的节点上;因此所有的单个块都是本地处理的,而不是把数据从一个节点传输到另外一个节点。当然,日志文件可以以明智的块处理方式进行处理,但是有些文件格式不支持块处理方式。针对这种情况,你可以写一个自定义的InputFormat,这样你就可以控制你文件是如何被拆分(或不拆分)成文件块的。
输入格式定义了组成mapping阶段的map任务列表,每一个任务对应一个输入块。接着根据输入文件块所在的物理地址,这些任务会被分派到对应的系统节点上,可能会有多个map任务被分派到同一个节点上。任务分派好后,节点开始运行任务,尝试去最大并行化执行。节点上的最大任务并行数由mapred.tasktracker.map.tasks.maximum参数控制。
记录读取器(RecordReader):InputSplit定义了如何切分工作,但是没有描述如何去访问它。 RecordReader类则是实际的用来加载数据并把数据转换为适合mapper读取的键值对。RecordReader实例是由输入格式定义的,默认的输入格式,TextInputFormat,提供了一个LineRecordReader,这个类的会把输入文件的每一行作为一个新的值,关联到每一行的键则是该行在文件中的字节偏移量。RecordReader会在输入块上被重复的调用直到整个输入块被处理完毕,每一次调用RecordReader都会调用Mapper的map()方法。
2.当面对一些特殊的<key,value>键值对时,如key是由一个文件名和记录位置组成的键值时,这时hadoop本身提供的TextInputFormat、CombineInputFormat、NLineInputFormat等肯定是无法满足我们的需求的,所以这里需要重写自己的输入分隔。MapReduce定义了接口InputFormat,它提供了两个方法,getSplits()和createRecordRead(),其中getSplits()负责对输入文件进行切割,切割之后便是一个个split,比如hadoop默认提供的几个InputFormat都是对大于BlockSize的文件进行切割,小于它的不切割,我们这里可以直接按照这种特性。而createRecordRead()则负责将一个split按照一定格式切割成一个个<K,V>对,以便MapReduce在map时调用。所以,我们的关键就是去定义这个<K,V>的切割。就要求开发人员继承FileInputFormat,用于实现一种新的输入格式,同时还需要继承RecordReader,用于实现基于新输入格式Key和Value值的读取方法。
FileInputFormat实现了InputFormat这个接口,实现了只对大于BlockSize的文件进行切割,并且保留了createRecordRead()这个方法让我们自己去实现。所以我们可以写一个类FileKeyInputFormat来extends这个FileInputFormat类,然后Override这个createRecordRead()方法。
参考TextInputFormat发现,它也是继承FileInputFormat,然后重写了createRecordRead(),在createRecordRead()里面call了LineRecordReader,由它来实现输入分隔。好吧,重点就来到了,那就是自己写一个类似于LineRecordReader的FileKeyRecordReader类,然后给我们的FileKeyInputForma来调用。LineRecordReader 继承 RecordReader时,重写了它的六个方法,分别是initialize()、getCurrentKey()、getCurrentValue()、getProgress()、Close()、nextKeyValue(),这里也一样需要重写这几个方法。
启动hadoop

生成文件

创建项目、写入代码
运行

结果:
