1.什么是JUC?
JUC指的是java.util 下几个包的简称,涉及多线程开发的相关操作。
- java.util.concurrent
- java.util.concurrent.atomic
- java.util.concurrent.locks
J.U.C 框架是 Java 5 中引入的,而我们最熟悉的线程池机制就在这个包,J.U.C 框架包含的内容有:
- AbstractQueuedSynchronizer(AQS框架),J.U.C 中实现锁和同步机制的基础;
- Locks & Condition(锁和条件变量),比 synchronized、wait、notify 更细粒度的锁机制;
- Executor 框架(线程池、Callable、Future),任务的执行和调度框架;
- Synchronizers(同步器),主要用于协助线程同步,有 CountDownLatch、CyclicBarrier、Semaphore、Exchanger;
- Atomic Variables(原子变量),方便程序员在多线程环境下,无锁的进行原子操作,核心操作是 北京市昌平区建材城西路金燕龙办公楼一层 电话:400-618-9090 CAS 原子操作,所谓的 CAS 操作,即 compare and swap.(swap)当前变量,否则不作操作;
- BlockingQueue(阻塞队列),阻塞队列提供了可阻塞的入队和出对操作,如果队列满了,入队操作将阻塞直到有空间可用,如果队列空了,出队操作将阻塞直到有元素可用;
- Concurrent Collections(并发容器),说到并发容器,不得不提同步容器。在JDK1.5 之前,为了线程安全,我们一般都是使用同步容器,同步容器主要的缺点是:对所有容器状态的访问都串行化,严重降低了并发性;某些复合操作,仍然需要加锁来保护;迭代期间,若其它线程并发修改该容器,会抛出ConcurrentModificationException 异常,即快速失败机制;
- Fork/Join 并行计算框架,这块内容是在 JDK1.7 中引入的,可以方便利用多核平台的计算能力,简化并行程序的编写,开发人员仅需关注如何划分任务和组合中间结果;
- TimeUnit 枚举,TimeUnit 是 java.util.concurrent 包下面的一个枚举类,TimeUnit 提供了可读性更好的线程暂停操作,以及方便的时间单位转换方法;
2. J.U.C之CAS
2.1CAS介绍
CAS,Compare And Swap,即比较并交换。同步组件中大量使用CAS技术实现了Java多线程的并发操作。整个AQS同步组件、Atomic原子类操作等等都是以CAS实现的,甚至ConcurrentHashMap在1.8的版本中也调整为了CAS+Synchronized。可以说CAS是整个JUC的基石.

2.2.CAS原理剖析
CAS是如何提高性能的呢?
CAS的思想很简单:三个参数,旧的预期值A、当前内存值V、即将更新的值B,当且仅当旧的预期值A和内存值V相同时,将内存值修改为B并返回true,否则什么都不做,并返回false。如果CAS操作失败,通过自旋的方式等待并再次尝试,直到成功。
CAS在先比较后修改这个CAS过程中,根本没有获取锁,释放锁的操作,是硬件层面的原子操作,跟JMM内存模型没有关系。大家可以理解为直接使用其他的语言,在JVM虚拟机之外直接操作计算机硬件,正因为如此,对比synchronized的同步,少了很多的逻辑步骤,使得性能大为提高。
JUC下的atomic类都是通过CAS来实现的,下面就是一个AtomicInteger原子操作类的例子,在其中使用了Unsafe unsafe = Unsafe.getUnsafe()。Unsafe是CAS的核心类,它提供了硬件级别的原子操作。
3.J.U.C之锁
3.1.锁的基本概念
3.1.1.互斥锁
在编程中,引入了对象互斥锁的概念,来保证共享数据操作的完整性。每个对象都对应于一个可称为" 互斥锁" 的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
3.1.2.阻塞锁
阻塞锁,可以说是让线程进入阻塞状态进行等待,当获得相应的信号(唤醒,时间) 时,才可以进入线程的准备就绪状态,准备就绪状态的所有线程,通过竞争,进入运行状态。
3.1.3.自旋锁
自旋锁是采用让当前线程不停地的在循环体内执行实现的,当循环的条件被其他线程改变时,才能进入临界区。由于自旋锁只是将当前线程不停地执行循环体,不进行线程状态的改变,所以响应速度更快。但当线程数不停增加时,性能下降明显,因为每个线程都需要执行,占用CPU时间。如果线程竞争不激烈,并且保持锁的时间段。适合使用自旋锁。
3.1.4.读写锁
读者只对共享资源进行读访问,写者则需要对共享资源进行写操作。读写锁相对于自旋锁而言,能提高并发性,因为在多处理器系统中,它允许同时有多个读者来访问共享资源,最大可能的读者数为实际的逻辑CPU数。写者是排他性的,一个读写锁同时只能有一个写者或多个读者(与CPU数相关),但不能同时既有读者又有写者。
3.1.5.公平锁
公平锁(Fair):加锁前检查是否有排队等待的线程,优先排队等待的线程,先来先得
非公平锁(Nonfair):加锁时不考虑排队等待问题,直接尝试获取锁,获取不到自动到队尾等待
非公平锁性能比公平锁高,因为公平锁需要在多核的情况下维护一个队列。
//可重入锁 private Lock lock = new ReentrantLock(); /** * Creates an instance of {@code ReentrantLock}. * This is equivalent to using {@code ReentrantLock(false)}. */ public ReentrantLock() { sync = new NonfairSync(); } /** * Creates an instance of {@code ReentrantLock} with the * given fairness policy. * * @param fair {@code true} if this lock should use a fair ordering policy */ public ReentrantLock(boolean fair) { sync = fair ? new FairSync() : new NonfairSync(); }
3.2.ReentrantLock
ReentrantLock,可重入锁,是一种递归无阻塞的同步机制。它可以等同于synchronized的使用,但是ReentrantLock提供了比synchronized更强大、灵活的锁机制,可以减少死锁发生的概率。ReentrantLock还提供了公平锁和非公平锁的选择,构造方法接受一个可选的公平参数(默认非公平锁),当设置为true时,表示公平锁,否则为非公平锁。公平锁的效率往往没有非公平锁的效率高,在许多线程访问的情况下,公平锁表现出较低的吞吐量。ReentrantLockReentrantLock,可重入锁,是一种递归无阻塞的同步机制。它可以等同于synchronized的使用,但是ReentrantLock提供了比synchronized更强大、灵活的锁机制,可以减少死锁发生的概率。
ReentrantLock还提供了公平锁和非公平锁的选择,构造方法接受一个可选的公平参数(默认非公平锁),当设置为true时,表示公平锁,否则为非公平锁。公平锁的效率往往没有非公平锁的效率高,在许多线程访问的情况下,公平锁表现出较低的吞吐量。
3.2.1.获取锁
一般都是这么使用ReentrantLock获取锁的:(默认非公平锁)
//非公平锁
ReentrantLock lock = new ReentrantLock();
lock.lock();
实例:
 View Code
View Code结果:
3000
3.2.2.释放锁
获取同步锁后,使用完毕则需要释放锁,ReentrantLock提供了unlock释放锁:
private void addCount() {
for (int i = 0; i <1000; i++) {
//加锁
lock.lock();
count++;
//释放锁
lock.unlock();
}
}
3.2.3.ReentrantLock与synchronized的区别
前面提到ReentrantLock提供了比synchronized更加灵活和强大的锁机制,那么它的灵活和强大之处在哪里呢?他们之间又有什么相异之处呢?
1. 与synchronized相比,ReentrantLock提供了更多,更加全面的功能,具备更强的扩展性。例如:时间锁等候,可中断锁等候,锁投票。
2.ReentrantLock还提供了条件Condition,对线程的等待、唤醒操作更加详细和灵活,所以在多个条件变量和高度竞争锁的地方,ReentrantLock更加适合(以后会阐述Condition)。
3.ReentrantLock提供了可轮询的锁请求。它会尝试着去获取锁,如果成功则继续,否则可以等到下次运行时处理,而synchronized则一旦进入锁请求要么成功要么阻塞,所以相比synchronized而言,ReentrantLock会不容易产生死锁些。
4.ReentrantLock支持更加灵活的同步代码块,但是使用synchronized时,只能在同一个synchronized块结构中获取和释放。注:ReentrantLock的锁释放一定要在finally中处理,否则可能会产生严重的后果。
5. ReentrantLock支持中断处理,且性能较synchronized会好些。
3.3.读写锁ReentrantReadWriteLock
但是在大多数场景下,大部分时间都是提供读服务,而写服务占有的时间较少。然而读服务不存在数据竞争问题,如果一个线程在读时禁止其他线程读势必会导致性能降低。所以就提供了读写锁。读写锁维护着一对锁,一个读锁和一个写锁。通过分离读锁和写锁,使得并发性比一般的互斥锁有了较大的提升:在同一时间可以允许多个读线程同时访问,但是在写线程访问时,所有读线程和写线程都会被阻塞。
读写锁的主要特性:
1. 公平性:支持公平性和非公平性。
2. 重入性:支持重入。读写锁最多支持65535个递归写入锁和65535个递归读取锁。
3. 锁降级:写锁能够降级成为读锁,遵循获取写锁、获取读锁在释放写锁的次序。读锁不能升级为写锁。
读写锁ReentrantReadWriteLock实现接口ReadWriteLock,该接口维护了一对相关的锁,一个用于只读操作,另一个用于写入操作。只要没有 writer,读取锁可以由多个 reader 线程同时保持。写入锁是独占的。
public interface ReadWriteLock {
/**
* Returns the lock used for reading.
*
* @return the lock used for reading
*/
Lock readLock();
/**
* Returns the lock used for writing.
*
* @return the lock used for writing
*/
Lock writeLock();
}
3.3.1.写锁的获取与释放
只有等读锁完全释放后,写锁才能够被当前线程所获取,一旦写锁开始获取了,所有其他读、写线程均会被阻塞。
View Code3.3.2.读锁的获取与释放
读锁为一个可重入的共享锁,它能够被多个线程同时持有,在没有其他写线程访问时,读锁总是获取成功 。
3.3.3.锁降级
读写锁有一个特性就是锁降级,锁降级就意味着写锁是可以降级为读锁的。锁降级
需要遵循以下顺序:获取写锁=>获取读锁=>释放写锁
重量锁重量级锁通过对象内部的监视器(monitor)实现,其中monitor的本质是依赖于底层操作系统的Mutex Lock(互斥锁)实现,操作系统实现线程之间的切换需要从用户态到内核态的切换,切换成本非常高。
4.J.U.C之Condition
4.1.Condition介绍
在没有Lock之前,我们使用synchronized来控制同步,配合Object的wait()、notify()系列方法可以实现等待/通知模式。在JDK5后,Java提供了Lock接口,相对于
Synchronized而言,Lock提供了条件Condition,对线程的等待、唤醒操作更加详细和灵活。
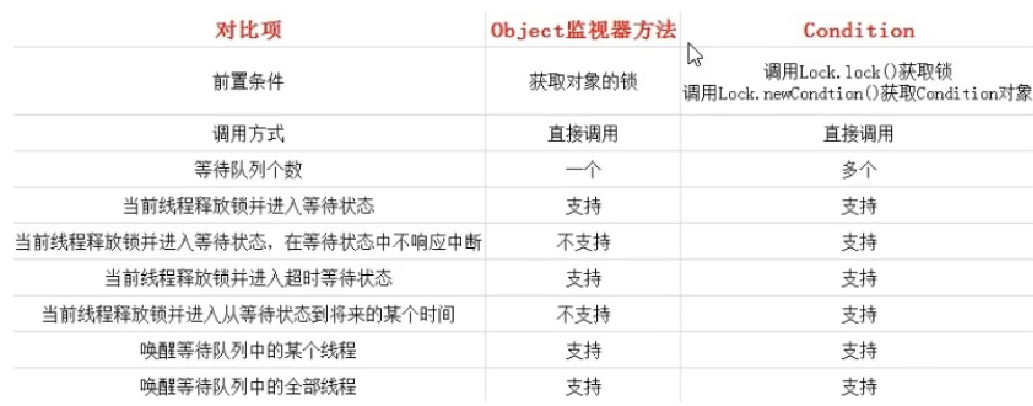
下图是Condition与Object的监视器方法的对比:
Condition提供了一系列的方法来对阻塞和唤醒线程:
1. await() :造成当前线程在接到信号或被中断之前一直处于等待状态。
2. await(long time, TimeUnit unit) :造成当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。
3. awaitNanos(long nanosTimeout) :造成当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。返回值表示剩余时间,如果在nanosTimesout之前唤醒,那么返回值 = nanosTimeout – 消耗时间,如果返回值 <= 0 ,则可以认定它已经超时了。
4. awaitUninterruptibly() :造成当前线程在接到信号之前一直处于等待状态。【注意:该方法对中断不敏感】。
5. awaitUntil(Date deadline) :造成当前线程在接到信号、被中断或到达指定最后期限之前一直处于等待状态。如果没有到指定时间就被通知,则返回true,否则表示到了指定时间,返回返回false。
6. signal():唤醒一个等待线程。该线程从等待方法返回前必须获得与Condition相关的锁。
7. signal()All:唤醒所有等待线程。能够从等待方法返回的线程必须获得与Condition相关的锁。
Condition是一种广义上的条件队列(等待队列)。他为线程提供了一种更为灵活的等待/通知模式,线程在调用await方法后执行挂起操作,直到线程等待的某个条件为真时才会被唤醒。Condition必须要配合锁一起使用,因为对共享状态变量的访问发生在多线程环境下。一个Condition的实例必须与一个Lock绑定,因此Condition一般都是作为Lock的内部实现。
举例:

1 public class Demo11Condition { 2 3 private Lock reentrantLock = new ReentrantLock(); 4 private Condition condition1 = reentrantLock.newCondition(); 5 private Condition condition2 = reentrantLock.newCondition(); 6 7 public void m1() { 8 reentrantLock.lock(); 9 try { 10 System.out.println("线程 " + Thread.currentThread().getName() + " 已经进入执行等待。。。"); 11 //await() :造成当前线程在接到信号或被中断之前一直处于等待状态。 12 condition1.await(); 13 System.out.println("线程 " + Thread.currentThread().getName() + " 已被唤醒,继续执行。。。"); 14 } catch (Exception e) { 15 e.printStackTrace(); 16 } finally { 17 reentrantLock.unlock(); 18 } 19 } 20 21 public void m2() { 22 reentrantLock.lock(); 23 try { 24 System.out.println("线程 " + Thread.currentThread().getName() + " 已经进入执行等待。。。"); 25 condition1.await(); 26 System.out.println("线程 " + Thread.currentThread().getName() + " 已被唤醒,继续执行。。。"); 27 } catch (Exception e) { 28 e.printStackTrace(); 29 } finally { 30 reentrantLock.unlock(); 31 } 32 } 33 34 public void m3() { 35 reentrantLock.lock(); 36 try { 37 System.out.println("线程 " + Thread.currentThread().getName() + " 已经进入执行等待。。。"); 38 condition2.await(); 39 System.out.println("线程 " + Thread.currentThread().getName() + " 已被唤醒,继续执行。。。"); 40 } catch (Exception e) { 41 e.printStackTrace(); 42 } finally { 43 reentrantLock.unlock(); 44 } 45 } 46 47 public void m4() { 48 reentrantLock.lock(); 49 try { 50 System.out.println("线程 " + Thread.currentThread().getName() + " 已经进入发出condition1唤醒信号。。。"); 51 //signal()All:唤醒所有等待线程。能够从等待方法返回的线程必须获得与Condition相关的锁 52 condition1.signalAll(); 53 } catch (Exception e) { 54 e.printStackTrace(); 55 } finally { 56 reentrantLock.unlock(); 57 } 58 } 59 60 public void m5() { 61 reentrantLock.lock(); 62 try { 63 System.out.println("线程 " + Thread.currentThread().getName() + " 已经进入发出condition2唤醒信号。。。"); 64 condition2.signalAll(); 65 } catch (Exception e) { 66 e.printStackTrace(); 67 } finally { 68 reentrantLock.unlock(); 69 } 70 } 71 72 public static void main(String[] args) throws Exception { 73 final Demo11Condition useCondition = new Demo11Condition(); 74 Thread t1 = new Thread(new Runnable() { 75 public void run() { 76 useCondition.m1(); 77 } 78 }, "t1"); 79 Thread t2 = new Thread(new Runnable() { 80 public void run() { 81 useCondition.m2(); 82 } 83 }, "t2"); 84 Thread t3 = new Thread(new Runnable() { 85 public void run() { 86 useCondition.m3(); 87 } 88 }, "t3"); 89 Thread t4 = new Thread(new Runnable() { 90 public void run() { 91 useCondition.m4(); 92 } 93 }, "t4"); 94 Thread t5 = new Thread(new Runnable() { 95 public void run() { 96 useCondition.m5(); 97 } 98 }, "t5"); 99 100 t1.start(); 101 t2.start(); 102 t3.start(); 103 104 Thread.sleep(2000); 105 t4.start(); 106 107 108 Thread.sleep(2000); 109 t5.start(); 110 } 111 }
结果:
线程 t2 已经进入执行等待。。。
线程 t3 已经进入执行等待。。。
线程 t4 已经进入发出condition1唤醒信号。。。
线程 t1 已被唤醒,继续执行。。。
线程 t2 已被唤醒,继续执行。。。
线程 t5 已经进入发出condition2唤醒信号。。。
线程 t3 已被唤醒,继续执行。。。
4.2.Condition的实现
获取一个Condition必须通过Lock的newCondition()方法。该方法定义在接口Lock下面,返回的结果是绑定到此 Lock 实例的新 Condition 实例。Condition为一个接口,其下仅有一个实现类ConditionObject,由于Condition的操作需要获取相关的锁,而AQS则是同步锁的实现基础,所以ConditionObject则定义为AQS的内部类。定义如下:
1 public class ConditionObject implements Condition, java.io.Serializable { 2 private static final long serialVersionUID = 1173984872572414699L; 3 /** First node of condition queue. */ 4 private transient Node firstWaiter; 5 /** Last node of condition queue. */ 6 private transient Node lastWaiter; 7 8 /** 9 * Creates a new {@code ConditionObject} instance. 10 */ 11 public ConditionObject() { } 12 13 // Internal methods 14 15 16 }
4.2.1.等待队列
每个Condition对象都包含着一个FIFO队列,该队列是Condition对象通知/等待功能的关键。在队列中每一个节点都包含着一个线程引用,该线程就是在该Condition能的关键。在队列中每一个节点都包含着一个线程引用,该线程就是在该Condition对象上等待的线程。源码如下:
public class ConditionObject implements Condition, java.io.Serializable { private static final long serialVersionUID = 1173984872572414699L; /** First node of condition queue. */ private transient Node firstWaiter; /** Last node of condition queue. */ private transient Node lastWaiter; /** * Creates a new {@code ConditionObject} instance. */ public ConditionObject() { } // Internal methods }
从上面代码可以看出Condition拥有首节点(firstWaiter),尾节点(lastWaiter)。当前线程调用await()方法,将会以当前线程构造成一个节点(Node),并将节点加入到该队列的尾部。结构如下
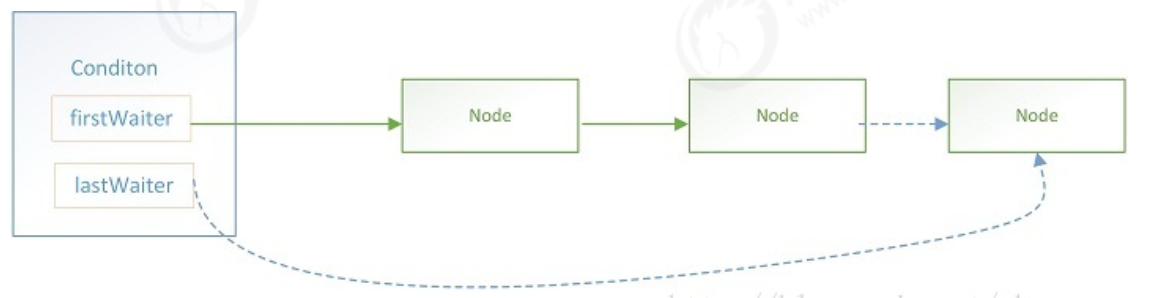
Node里面包含了当前线程的引用。Node定义与AQS的CLH同步队列的节点使用的都是同一个类(AbstractQueuedSynchronized.Node静态内部类)。Condition的队列结构比CLH同步队列的结构简单些,新增过程较为简单只需要将原尾节点的nextWaiter指向新增节点,然后更新lastWaiter即可。
5.J.U.C之并发容器ConcurrentHashMap
5.1.介绍
HashMap是我们用得非常频繁的一个集合,但是它是线程不安全的。并且在多线程环境下,put操作是有可能产生死循环,不过在JDK1.8的版本中更换了数据插入的顺序,已经解决了这个问题。
为了解决该问题,提供了Hashtable和Collections.synchronizedMap(hashMap)两种解决方案,但是这两种方案都是对读写加锁,独占式。一个线程在读时其他线程必须等待,吞吐量较低,性能较为低下。而J.U.C给我们提供了高性能的线程安全HashMap:ConcurrentHashMap。在1.8版本以前,ConcurrentHashMap采用分段锁的概念,使锁更加细化,但是1.8已经改变了这种思路,而是利用CAS+Synchronized来保证并发更新的安全,当然底层采用数组+链表+红黑树的存储结构。
5.2.JDK7 HashMap
HashMap 是最简单的,它不支持并发操作,下面这张图是 HashMap 的结构:

HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
public HashMap(int initialCapacity, float loadFactor)初始化方法的参数说明: capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。 loadFactor:负载因子,默认为 0.75。 threshold:扩容的阈值,等于 capacity * loadFactor
put 过程:
(1)数组初始化,在第一个元素插入 HashMap 的时候做一次数组的初始化,先确定初始的数组大小,并计算数组扩容的阈值。
(2)计算具体数组位置,使用key进行hash值计算,根据hash值计算应该放在哪个数组中
(3)找到数组下标后,会先进行 key 判断是否重复,如果没有重复,就准备将新值放入到链表的表头(在多线程操作中,这种操作会造成死循环,在jdk1.8已解决)。
(4)数组扩容,在插入新值的时候,如果当前的 size已经达到了阈值,并且要插入的数组位置上已经有元素,那么就会触发扩容,扩容后,数组大小为原来的2倍。扩容就是用一个新的大数组替换原来的小数组,并将原来数组中的值迁移到新的数组中。
get过程:
(1)根据 key 计算 hash 值。
(2)根据hash值找到相应的数组下标。
(3)遍历该数组位置处的链表,直到找到相等的 key
5.3.JDK7 ConcurrentHashMap
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。
整个 ConcurrentHashMap 由一个个 Segment 组成,Segment代表”部分“或”一段“的意思,所以很多人都会将其描述为分段锁。简单的说,ConcurrentHashMap是一个Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的。
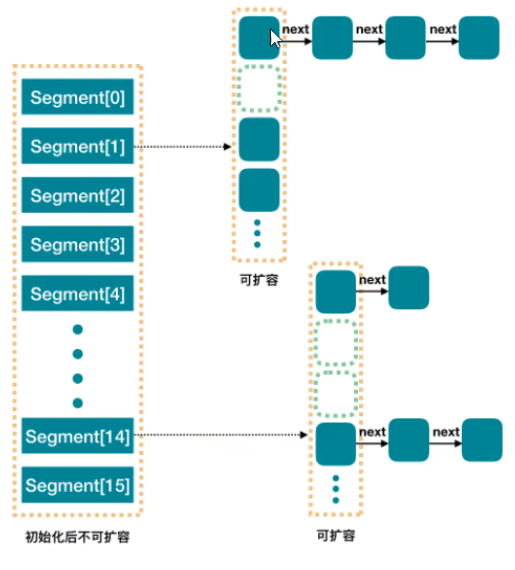
再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的 HashMap,每次操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的。
public ConcurrentHashMap(int initialCapacity, float loadFactor)初始化方法
- initialCapacity:整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment。
- concurrencyLevel:并发数(或者Segment 数,有很多叫法,重要的是如何理解)。默认是 16,也就是说 ConcurrentHashMap 有 16 个Segments,所以这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
- loadFactor:负载因子,Segment 数组不可以扩容,所以这个负载因子是给每个 Segment 内部使用的。
举个简单的例子:
用 new ConcurrentHashMap() 无参构造函数进行初始化的,那么初始化完成后:
- Segment数组长度为 16,不可以扩容。
- Segment[i] 的默认大小为 2,负载因子是 0.75,得出初始阈值为 1.5,也就是以后插入第一个元素不会触发扩容,插入第二个会进行第一次扩容。
- 这里初始化了 segment[0],其他位置还是 null。
put过程:
- 根据 hash 值能找到相应的 Segment,之后就是 Segment 内部的 put 操作了。
- Segment 内部是由 数组+链表 组成的,由于有独占锁的保护,所以 segment内部的操作并不复杂。保证多线程安全的,就是做了一件事,那就是获取该segment 的独占锁。
- Segment 数组不能扩容,rehash方法扩容是 segment 数组某个位置内部的数组 HashEntry[] 进行扩容,扩容后,容量为原来的 2 倍。
get过程:
- 计算 hash 值,找到 segment 数组中的具体位置
- segment 数组中也是数组,再根据 hash 找到数组中具体值的位置
- 到这里是链表了,顺着链表进行查找即可
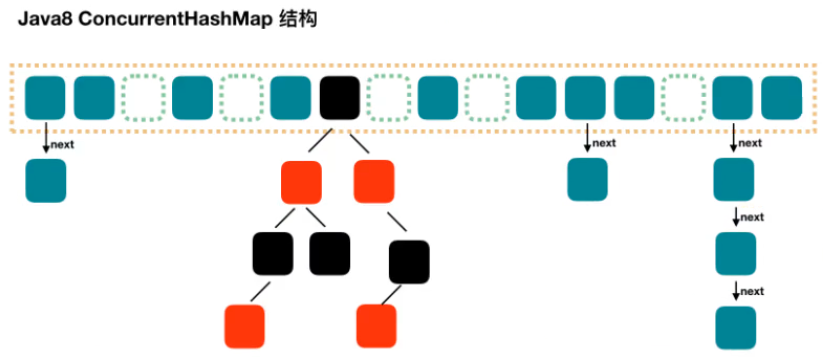
5.4.JDK8 HashMap
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由数组+链表+红黑树 组成。
根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度。为了降低这部分的开销,在 Java8 中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度。
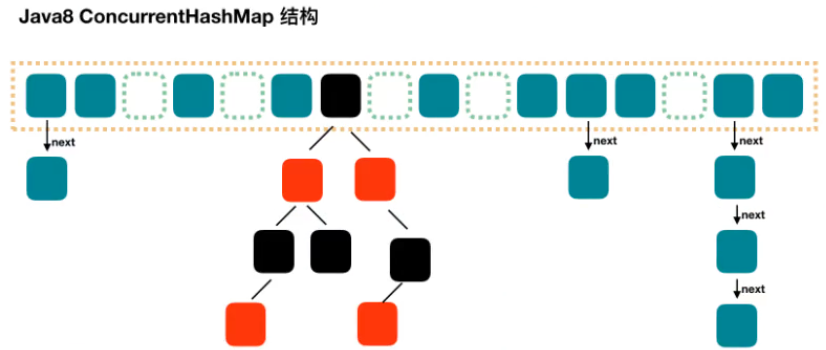
jdk7 中使用 Entry 来代表每个 HashMap 中的数据节点,jdk8 中使用 Node,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于
链表的情况,红黑树的情况需要使用 TreeNode。我们根据数组元素中,第一个节点数据类型是 Node 还是 TreeNode 来判断该位置下是链表还是红黑树的。
put过程:
和jdk7的put差不多
和 Jdk7 不一样的地方就是,jdk7是先扩容后插入新值的,jdk8 先插值再扩容先使用链表进行存放数据,当数量超过8个的时候,将链表转为红黑树
get 过程:
1. 计算 key 的 hash 值,根据 hash 值找到对应数组下标。
2. 判断数组该位置处的元素是否刚好就是我们要找的,如果不是,走第三步。
3. 判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据,如果不是,走第四步。
4. 遍历链表,直到找到相等(==或equals)的 key。
5.5.JDK8 ConcurrentHashMap
Java7 中实现的 ConcurrentHashMap 还是比较复杂的,Java8 对ConcurrentHashMap 进行了比较大的改动。可以参考 Java8 中 HashMap 相对于Java7 HashMap 的改动,对于 ConcurrentHashMap,Java8 也引入了红黑树。
1.8版本以前,ConcurrentHashMap采用分段锁的概念,使锁更加细化,但是1.8已经改变了这种思路,而是利用CAS+Synchronized来保证并发更新的安全,底在层采用数组+链表+红黑树的存储结构。
5.6.使用场景
ConcurrentHashMap通常只被看做并发效率更高的Map,用来替换其他线程安全的Map容器,比如Hashtable和Collections.synchronizedMap。线程安全的容器,特别是Map,很多情况下一个业务中涉及容器的操作有多个,即复合操作,而在并发执行时,线程安全的容器只能保证自身的数据不被破坏,和数据在多个线程间是可见的,但无法保证业务的行为是否正确。
ConcurrentHashMap总结:
- HashMap是线程不安全的,ConcurrentHashMap是线程安全的,但是线程安全仅仅指的是对容器操作的时候是线程安全的。
- ConcurrentHashMap的public V get(Object key)不涉及到锁,也就是说获得对象时没有使用锁
- put、remove方法,在jdk7使用锁,但多线程中并不一定有锁争用,原因在于ConcurrentHashMap将缓存的变量分到多个Segment,每个Segment上有一个锁,只要多个线程访问的不是一个Segment就没有锁争用,就没有堵塞,各线程用各自的锁,ConcurrentHashMap缺省情况下生成16个Segment,也就是允许16个线程并发的更新而尽量没有锁争用。而在jdk8中使用的CAS+Synchronized来保证线程安全,比加锁的性能更高。
- ConcurrentHashMap线程安全的,允许一边更新、一边遍历,也就是说在对象遍历的时候,也可以进行remove,put操作,且遍历的数据会随着remove,put操作产出变化。
5.6.1.例1: 遍历的同时删除
1 /** 2 * 遍历的同时删除 3 */ 4 public class Demo4ConcurrentHashMap1 { 5 public static void main(String[] args) { 6 //Map<String, Integer> map = new HashMap(); 7 Map<String, Integer> map = new ConcurrentHashMap<>(); 8 //Map<String, Integer> map = new Hashtable<>(); 9 10 map.put("a", 1); 11 // map.put("a", 2);//会覆盖前一个元素 12 map.put("b", 1); 13 map.put("c", 1); 14 for (Map.Entry<String, Integer> entry : map.entrySet()) { 15 map.remove(entry.getKey()); 16 } 17 18 System.out.println(map.size()); 19 System.out.println(map); 20 } 21 }
5.6.2.案例2:业务操作的线程安全不能保证
1 /** 2 * 案例2:业务操作的线程安全不能保证 3 */ 4 public class Demo4ConcurrentHashMap2 { 5 public static void main(String[] args) { 6 //final Map<String, Integer> count = new HashMap<>(); 7 final Map<String, Integer> count = new ConcurrentHashMap<>(); 8 //final Hashtable<String, Integer> count = new Hashtable<>(); 9 count.put("count", 0); 10 11 Runnable task = new Runnable() { 12 @Override 13 public void run() { 14 // synchronized (count) { 15 int value; 16 for (int i = 0; i < 2000; i++) { 17 value = count.get("count"); 18 count.put("count", value + 1); 19 // } 20 } 21 } 22 }; 23 new Thread(task).start(); 24 new Thread(task).start(); 25 new Thread(task).start(); 26 27 try { 28 Thread.sleep(1000l); 29 System.out.println(count); 30 } catch (Exception e) { 31 e.printStackTrace(); 32 } 33 } 34 }
5.6.3.案例3:多线程删除
1 public class Demo4ConcurrentHashMap3 { 2 public static void main(String[] args) { 3 //final Map<String, Integer> count = new HashMap<>(); 4 final Map<String, Integer> count = new ConcurrentHashMap<>(); 5 //final Hashtable<String, Integer> count = new Hashtable<>(); 6 7 for (int i = 0; i < 2000; i++) { 8 count.put("count" + i, 1); 9 } 10 11 Runnable task1 = new Runnable() { 12 @Override 13 public void run() { 14 for (int i = 0; i < 500; i++) { 15 count.remove("count" + i); 16 } 17 } 18 }; 19 Runnable task2 = new Runnable() { 20 @Override 21 public void run() { 22 for (int i = 1000; i < 1500; i++) { 23 count.remove("count" + i); 24 } 25 } 26 }; 27 28 new Thread(task1).start(); 29 new Thread(task2).start(); 30 31 try { 32 Thread.sleep(1000l); 33 System.out.println(count.size()); 34 } catch (Exception e) { 35 e.printStackTrace(); 36 } 37 } 38 }
5.7.对比Hashtable
Hashtable和ConcurrentHashMap的不同点:
- Hashtable对get,put,remove都使用了同步操作,它的同步级别是正对Hashtable来进行同步的,也就是说如果有线程正在遍历集合,其他的线程就暂时不能使用该集合了,这样无疑就很容易对性能和吞吐量造成影响,从而形成单点。而ConcurrentHashMap则不同,它只对put,remove操作使用了同步操作,get操作并不影响。
- Hashtable在遍历的时候,如果其他线程,包括本线程对Hashtable进行了put,remove等更新操作的话,就会抛出ConcurrentModificationException异常,但如果使用ConcurrentHashMap的话,就不用考虑这方面的问题了。