今天是 武sir 第一天给我们讲课,讲的非常精彩。
进入正题:
今天所学的知识点包括:
1,set
无序,不重复,可嵌套。
2,函数
定义函数,函数体不执行,只有调用函数时,函数体才执行。
3,三目运算:
4,内置函数简介:
5,文件操作:
包括打开文件,操作文件,关闭文件。
#######################################
好,我们详细说一下今天的收获。
一,引入类:
通过对字符串的讲解,我们引入了类的概念,将所有的字符串归纳起来,将他们的所有功能,写到字符串类里面,使用这些功能时,直接调用即可。

对于其他的字典,列表,元组等都是大同小异的,他们都属于类,之后自建的类,我们都可以这么理解。
二,集合(set):
首先我们创建一个列表,list((11,2,33,44)),,list__init__,内部会执行for循环(11,22,33,44)。
set也是一样,s=set()#创建集合,li = [11,22,33,44],s1 =set(li),print(s1)
1, 创建集合的方法:
s1 = {11,22}
s2 = set()
s3 = set([11,22,33,44])
2,集合的功能:
1),差异性判断:
s1 = {11,22,33}
s2 = {22,33,44}
s3 = s1.difference(s2)
s1中有,s2中没有的。
print(s3)
{11}
s3 = s1.symmetric_difference(s2)
s1,s2中的差异,包括s1中有的s2没有的,以及s2中有的s1没有的
print(s3)
{11,44}
如果是s1.difference_update(s2)就直接将结果{11}赋值给s1
s1.symmetric_difference_update(s2) 同上
总之出现update就将值直接付给使用这个功能的变量。
2)删除:
s1 = {11,22,33,}
s1.discard(11) ----删除11,如果删除111,不存在的元素不会报错
s1.remove(11) ----删除11,如果删除111,不存在的元素会报错
s1.pop() ----随机删除元素。不经常使用
建议使用discard 出现不存在的元素不会报错退出,remove会退出。与字符串中的find和index 索引功能类似
3)并集和交集:
s1 = {11,22,33}
s2 = {22,33,44}
s3 = s1.intersection(s2)
#{33,22}
这个是交集(intersection)。可以用于找到相同的元素,然后可以进行判断。
s1 = {11,22,33}
s2 = {22,33,44}
s3 = s1.union(s2)
#{33,22,11,44}
这个是并集(union)。可以应用到2个集合的所有元素,进行去重
小练习
题目:
固定资产管理
这道题主要应用在cmdb 资产管理里面,可以通过集合的不重复性,可嵌套的特点。将老数据和新数据进行对比,帮我们确认哪些资产有过变动,有哪些变动。
下面是相关代码:


old_dic ={'#1':8,
'#2':4,
'#4':2}
new_dic = {'#1':4,
'#2':4,
'#3':2}
old_set = set(old_dic.keys())
new_set = set(new_dic.keys())
del_list = list(old_set.difference(new_set))
add_list = list(new_set.difference(old_set))
updat_list = list(old_set.intersection(new_set))
print(del_list,add_list,updat_list)
for i in updat_list:
if old_dic[i] != new_dic[i]:
print(i,)
三,函数详解:
1,定义函数:
上图:是函数的定义方法。尽量在函数命名的时候能够让人直观的知道这个函数的用途,方便实用。
2,执行函数:
练习:发邮件
def mail(): import smtplib from email.mime.text import MIMEText from email.utils import formataddr msg = MIMEText('邮件内容', 'plain', 'utf-8') msg['From'] = formataddr(["xxx",'xxx@126.com']) msg['To'] = formataddr(["xx",'xxx@qq.com']) msg['Subject'] = "主题" server = smtplib.SMTP("smtp.126.com", 25) server.login("xxx@126.com", "xxx") server.sendmail('xxxx@126.com', ['xxxx@qq.com',], msg.as_string()) server.quit() mail()
在没有参数的情况下,直接mail()就可以执行整个函数。
3,参数:
def send(xxoo,content,xx='d'): #xxoo和content就是形式参数,xx是默认参数,必须放在最后
print(xxoo,content,xx)
# return True
· return xxoo #返回值 出现返回值整个函数就终止。
#res = send('a','b','c')
#res = send('a','b')
res = send(content='a',xxoo='b') #直接定义形式参数,可不按照顺序
print(res)
默认参数就是在函数调用时可以不输入,他已经有了默认的值。
详解return:

return出来的值,就是这个函数的执行结果,可以通过该结果进行判断,函数是否执行成功或者失败。
res = send() 是函数的执行方法。
详解形式参数:

形式参数在调用时必须赋值。而且必须按照顺序一一对应。
当然也可以进行具体指定,比如在调用时 send(content= "SB",xxoo = em, xx = "ok")这样顺序不一致也没事。
动态参数:
*args -----*形式参数会接收全部参数,以元祖形式出现(动态参数)
**args -----** 指定参数 变成字典 -**形式参数,字典
万能参数:* ** *在前 ** 在后
举例说明:
1)*args 
def f1(*args): print(args,type(args)) li = [1,2,3,4,1,23,] #f1(li) f1(li)
结果li会整个变成一个元组中的一个元素
([1, 2, 3, 4, 1, 23],) <class 'tuple'>
def f1(*args):
print(args,type(args))
li = [1,2,3,4,1,23,]
#f1(li)
f1(*li)
这样就会list就会变成元组,不再是列表。而之前列表中的元素,会变成元组中的元素。
(1, 2, 3, 4, 1, 23) <class 'tuple'>
2)**kwargs
def f1(**kwargs):
print(kwargs,type(kwargs))
li = {'k1':'v1','k2':'v2'}
f1(k1='v1')
这样会对应出一个字典
{'k1': 'v1'} <class 'dict'>
def f1(**kwargs): print(kwargs,type(kwargs)) li = {'k1':'v1','k2':'v2'} #f1(k1='v1') f1(**li)
{'k1': 'v1', 'k2': 'v2'} <class 'dict'>
3)万能函数:
def f1(*args,**kwargs): print(args) print(kwargs) f1(1,2,3,4,k1='v1')
1,2,3,4会变成元组中的元素。
k1='v1'会变成字典
(1, 2, 3, 4)
{'k1': 'v1'}
并且是打印两行
4,补充:
字符串format:

{0} {1}按照顺序进行赋值。
函数创建:
函数参数传递是引用进行传递。
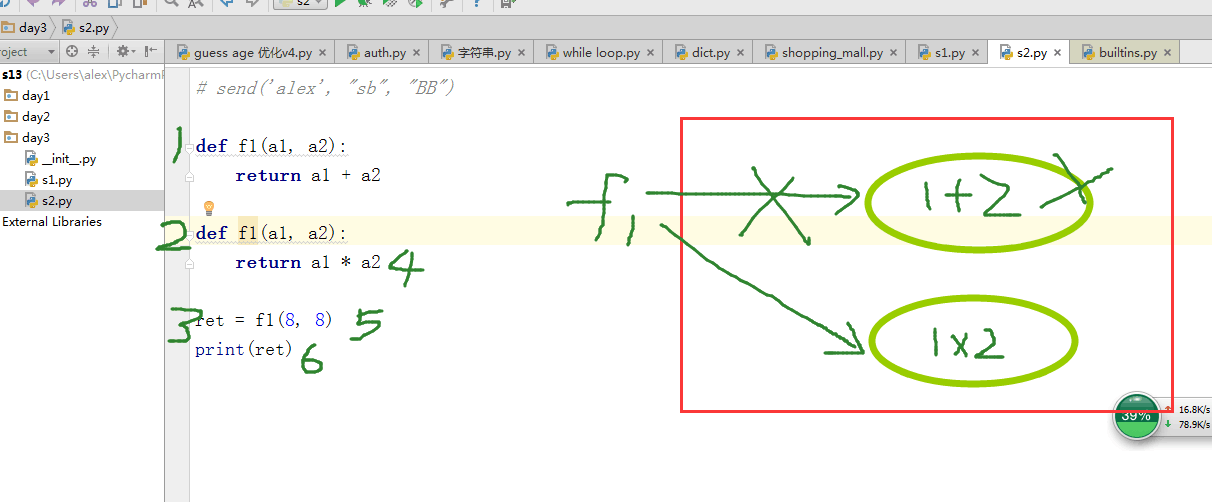
f1先引用内存里的a1+a2
之后有引用了a1*a2
所以在调用函数的时候 返回的结果就是 a1*a2

首先先将a1加了999,函数调用了l1 这个列表,l1就加了999
结果就是 :[11, 22, 33, 44, 999]
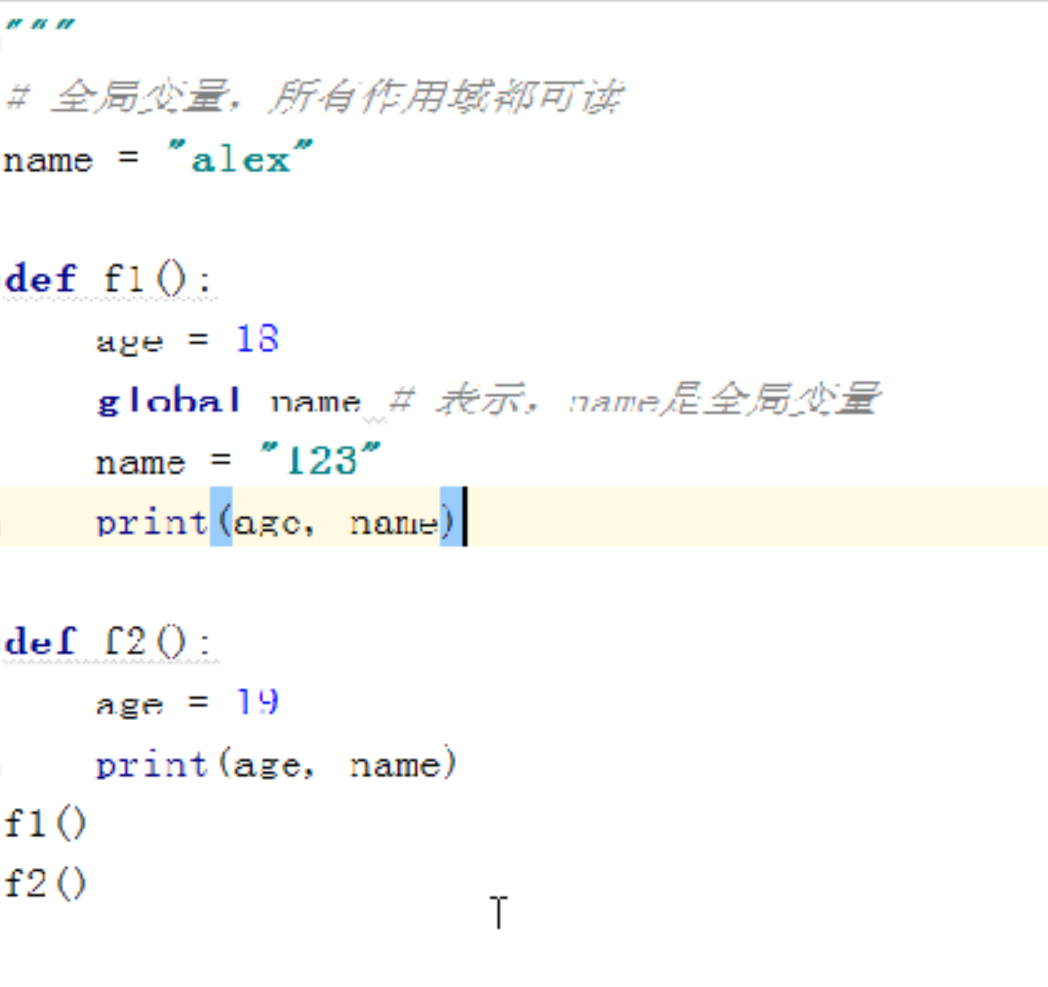
全局变量(作用域)----所有的地方都能读 但是会优先用自己变量
----列表字典可修改,不可以重新赋值
5, 三目运算:
if 1==1:
name = 'alex'
else:
name = 'sb
name = 'alex' if 1==1 else 'sb' #三目运算表达式。
6,lambda:
def f1(a1): return a1 + 100 f2 = lambda a2,a1=10:a2+120+a1 res1 = f1(1) res2 = f2(20) print(res1) print(res2)
在lambda中,a1,a2就是参数 a1是默认参数,:后面是返回值就是150
7,内置函数简介:
abs()绝对值
all()
any()
n = all([1,2,3,4,45,5,0])
print (n)
bin() 10 -2
oct() 10 -8
hex() 10 -16
进制的 转换
代码测试:
n = abs(-10) print(n) n1 = all([10,1,2,3,4,5,0]) print(n1) n2 = any([1,2,3,0,[]]) print(n2) print(bin(10)) print(oct(10)) print(hex(10))
字符问题:

代码如下:
s = '李杰' n = bytes(s,encoding='utf-8') print(n)
将汉字转化为直接格式
b'xe6x9dx8exe6x9dxb0' f =open('db','ab') f.write(bytes('立即',encoding='utf-8')) f.close()
用字节格式打开,要用字节进行写入。 f = open('db','rb') n=f.read() print(n,type(n))
四,文件处理:
1,打开文件,
r 读
w 写 先清空
x 文件存在就报错,不存在,创建并写内容=w
a 追加 --- 永远会写在最后
常用的r+可以按照指针进行修改
a+永远会写在最后
w+会清空后再写
如果模式无B按照字符读取。
seek按照字节找位置(永远是字节)
tell 获取当前的指针位置以字节的位置调整

2,操作文件:
read() 无参数,读全部
有参数 b 按照字节
无b按照字符
flush()强刷
readline 仅仅读取一行
truncate 截断,指针后面的 清空。
for循环文件对象,
for line in
3,关闭文件:
close()
with open('db') as f:
pass
**python3最新推出同时开两个文件:

可以用于相互的拷贝,已经备份更新等。
以上是这节课所学到的知识。
#########################黄金分割线#############################
以下是我的一些感想:
set(集合):是无序的,不可以重复的,可以嵌套。他和列表很相似,但是也有一些不同,比如他不允许重复。
他在差异性判断中很有用处,可以通过集合来确认出两组数据有什么不同,有什么相同。在比较数据前后变化是很有用处。
函数:函数非常重要,我认为函数就是程序中的功能,也可以说程序就是通过一个个函数来完成他的工作。每一个函数就是这个程序的一个功能,而且函数 可以增强整个程序的灵活性,需要那种功能就通过函数来完成在添加到想用的位置即可。
至于形式参数,默认参数,动态参数,还有内置函数等,主要看个人的习惯,那种用的熟,哪种更方便,就用哪种,当然要明确程序的可用性,减少 bug
关于类的概念:
我感觉所有的对象都属于类,每个类中都有相应的功能,类中的对象可以通过这些功能来完成复杂的程序。
文件处理:
单个文件的处理还好理解一下,但是一定要注意for循环的这个区间,以及缩进问题,还有continue break的应用。
我认为多个文件的操作是一个难点,尤其是读一个文件再写到另一个文件,其中的逻辑性非常强,很容易迷糊,需要多加练习。
谢谢