哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。树的带权路径长度记为WPL=(W1*L1+W2*L2+W3*L3+...+ Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,...n)。可以证明哈夫曼树的WPL是最小的。
构造哈夫曼树的算法如下:
1)对给定的n个权值{W1,W2,W3,...,Wi,...,Wn}构成n棵二叉树的初始集合F={T1,T2,T3,...,Ti,..., Tn},其中每棵二叉树Ti中只有一个权值为Wi的根结点,它的左右子树均为空。
2)在F中选取两棵根结点权值最小的树作为新构造的二叉树的左右子树,新二叉树的根结点的权值为其左右子树的根结点的权值之和。
3)从F中删除这两棵树,并把这棵新的二叉树同样以升序排列加入到集合F中。
4)重复2)和3),直到集合F中只有一棵二叉树为止。
例如,对于4个权值为1、3、5、7的节点构造一棵哈夫曼树,其构造过程如下图所示:
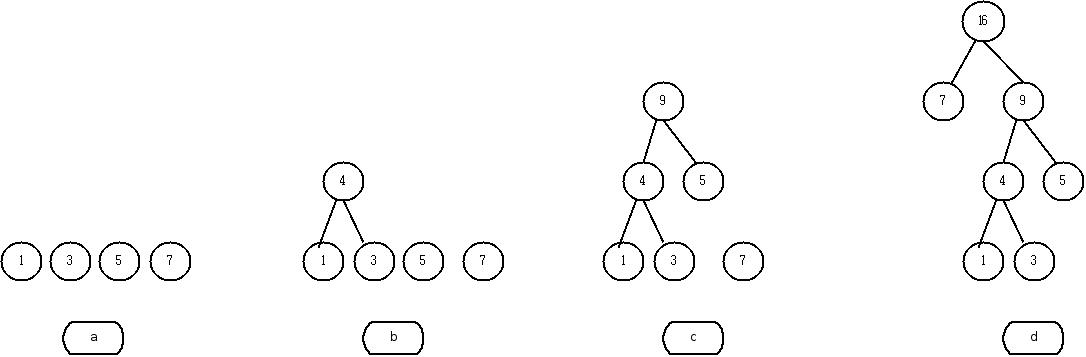
可以计算得到该哈夫曼树的路径长度WPL=(1+3)*3+2*5+1*7=26。
对于哈夫曼树,有一个很重要的定理:对于具有n个叶子节点的哈夫曼树,共有2*n-1个节点。
这个定理的解释如下:对于二叉树来说,有三种类型节点,即度数(只算出度)为2的节点,度数为1的节点和度数为0的叶节点。而哈夫曼树的非叶子节点是由两个节点生成的,因此不能出现度数为1的节点,而生成的非叶子节点的个数为叶子节点个数减一,于此定理就得证了。
这里给出构造哈夫曼树的算法(算法实现使用C语言而不是java)。出于简单性考虑,构造的哈夫曼树不是采用链式存储,而是以数组方式存储,其中使用数组位置索引标识节点的链接。对于哈夫曼树中的节点其数据类型如下:
typedef struct QHTNode{ char c; //存储的数据,为一个字符 double weight; //节点权重 int parent;//父节点在数组中的位置索引 int lchild;//左孩子在数组中的位置索引 int rchild;//右孩子在数组中的位置索引}HTNode; |
构造哈夫曼树的算法的实现原理如下:对于n个叶子节点,我们根据上面的定理构造出大小为2*n-1的数组来存放整个哈夫曼树。这个数组的前n个位置存放的为已知的叶子节点,后(n-1)个位置存放的为动态生成的树内节点。在算法的大循环过程中,要做的事情就是根据位置i前面的已知节点(或者是叶节点或者是生成的树内节点),找出parent为-1(即节点尚且是一个子树的根结点)的节点中权值最小的两个节点,然后根据这两个节点构造出位置为i的新的父节点(也就是一棵新树的根结点)。程序如下:
void creatHuffmanTree(HTNode ht[],int n){ int i,j; int lchild,rchild; double minL,minR; for(i=0;i<2*n-1;i++){ ht[i].parent = ht[i].lchild = ht[i].rchild = -1; } for(i=n;i<2*n-1;i++){ minL = minR = MAXNUMBER; lchild = rchild = -1; for(j=0;j<i;j++){ if(ht[j].parent == -1){ if(ht[j].weight < minL){ minR = minL; minL = ht[j].weight; rchild = lchild; lchild = j; }else if(ht[j].weight < minR){ minR = ht[j].weight; rchild = j; } } } ht[lchild].parent = ht[rchild].parent = i; ht[i].weight = minL + minR; ht[i].lchild = lchild; ht[i].rchild = rchild; } } |
哈夫曼树的一个经典应用就是哈夫曼编码。在数据通信中,经常需要将传送的文字转换成二进制字符串,这个过程就是编码。哈夫曼编码是一种变长的编码方案,其核心就是使频率越高的码元(这个词不知用的是否准确,就是要编码的对象,可以是字符串等等了)采用越短的编码。编码过程就根据不同码元的频率(相当于权值)构造出哈夫曼树,然后求叶子节点到根节点的路径,其中节点的左孩子路径标识为0,右孩子路径标识为1。对于上面的例子,权值为1的节点编码为000,权值为3的节点编码为001,权值为5的节点编码为01,权值为7的节点编码为1。
下面的实现采用的方法是从叶子节点向上遍历到根结点,其中数据类型 HCode中的 code存储路径信息,而start表示路径信息是从code数组的start位置开始的,结束位置为节点数n。
typedef struct QHCode{ char* code; int start;}Hcode;void createHuffmanCode(HTNode ht[],HCode hc[],int n){ int i,f,c; HCode father; for(i=0;i<n;i++){ hc[i].start = n; c = i; while((f=ht[c].parent) != -1){ if(ht[f].lchild == c){ hc[i].code[hc[i].start--] = '0'; }else{ hc[i].code[hc[i].start--] = '1'; } c = f; } hc[i].start++; }} |