1.MyBatis介绍
MyBatis 是支持 普通 SQL 查询 , 存储过程 和 高级映射 的优秀持久层框架。MyBatis 消除了几乎所有的 JDBC 代码和参数的手工设置以及对结果集的检索封装。MyBatis 可以使用简单的 XML 或注解用于配置和原始映射,将接口和 Java 的 POJO(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录.JDBC- dbutils- MyBatis- Hibernate
2.MyBatis快速入门
编写第一个基于 mybaits 的测试例子:
2.1. 添加 jar
【mybatis 】
mybatis-3.1.1.jar
【MYSQL 驱动包】
mysql-connector-java-5.1.7-bin.jar
2.2. 建库建表
create database mybatis; use mybatis; CREATE TABLE users(id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20), age INT); INSERT INTO users(NAME, age) VALUES('Tom', 12); INSERT INTO users(NAME, age) VALUES('Jack', 11);
2.3. 添加 Mybatis 的配置文件 conf.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <environments default="development"> <environment id="development"> <transactionManager type="JDBC" /> <dataSource type="POOLED"> <property name="driver" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://localhost:3306/mybatis" /> <property name="username" value="root" /> <property name="password" value="root" /> </dataSource> </environment> </environments> </configuration>
2.4. 定义表所对应的实体类
public class User { private int id; private String name; private int age; //get,set 方法 }
2.5. 定义操作 users 表的 sql 映射文件 userMapper.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace=" com.atguigu.mybatis_test.test1.userMapper"> <select id="getUser" parameterType="int" resultType="com.atguigu.mybatis_test.test1.User"> select * from users where id=#{id} </select> </mapper>
2.6. 在 在 conf.xml 文件中注册 userMapper.xml 文件
<mappers> <mapper resource="com/atguigu/mybatis_test/test1/userMapper.xml"/> </mappers>
2.7. 编写测试代码:执行定义的 select 语句
public class Test { public static void main(String[] args) throws IOException { String resource = "conf.xml"; //加载 mybatis 的配置文件(它也加载关联的映射文件) Reader reader = Resources.getResourceAsReader(resource); //构建 sqlSession 的工厂 SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(reader); //创建能执行映射文件中 sql 的 sqlSession SqlSession session = sessionFactory.openSession(); //映射 sql 的标识字符串 String statement = "com.atguigu.mybatis.bean.userMapper"+".selectUser"; //执行查询返回一个唯一 user 对象的 sql User user = session.selectOne(statement, 1); System.out.println(user); } }
3.操作user表的CRUD
3.1XML的实现
1). 定义 sql 映射 xml 文件
<insert id="insertUser" parameterType="com.atguigu.ibatis.bean.User"> insert into users(name, age) values(#{name}, #{age}); </insert> <delete id="deleteUser" parameterType="int"> delete from users where id=#{id} </delete> <update id="updateUser" parameterType="com.atguigu.ibatis.bean.User"> update users set name=#{name},age=#{age} where id=#{id} </update> <select id="selectUser" parameterType="int" resultType="com.atguigu.ibatis.bean.User"> select * from users where id=#{id} </select> <select id="selectAllUsers" resultType="com.atguigu.ibatis.bean.User"> select * from users </select>
2). 在 config.xml 中注册映射文件
<mapper resource="net/lamp/java/ibatis/bean/userMapper.xml"/>
3). 在 dao 中调用
public User getUserById(int id) { SqlSession session = sessionFactory.openSession(); User user = session.selectOne(URI+".selectUser", id); return user; }
3.2. 注解的实现
1). 定义 sql 映射的接口
public interface UserMapper { @Insert("insert into users(name, age) values(#{name}, #{age})") public int insertUser(User user); @Delete("delete from users where id=#{id}") public int deleteUserById(int id); @Update("update users set name=#{name},age=#{age} where id=#{id}") public int updateUser(User user); @Select("select * from users where id=#{id}") public User getUserById(int id); @Select("select * from users") public List<User> getAllUser(); }
2). 在 config 中注册这个映射接口
<mapper class="com.atguigu.ibatis.crud.ano.UserMapper"/>
3). dao
public User getUserById(int id) { SqlSession session = sessionFactory.openSession(); UserMapper mapper = session.getMapper(UserMapper.class); User user = mapper.getUserById(id); return user; }
4. 几个可以优化的地方
4.1. 连接数据库的配置单独放在一个 properties 文件中
## db.properties <properties resource="db.properties"/> <property name="driver" value="${driver}" /> <property name="url" value="${url}" /> <property name="username" value="${username}" /> <property name="password" value="${password}" />
4.2. 为实体类定义别名, 简化 sql 映射 xml 文件中的引用
<typeAliases> <typeAlias type="com.atguigu.ibatis.bean.User" alias="_User"/> </typeAliases>
4.3. 可以在 src 下加入 log4j 的配置文件
1. 添加 jar: log4j-1.2.16.jar 2.1. log4j.properties( 方式一) log4j.properties, log4j.rootLogger=DEBUG, Console #Console log4j.appender.Console=org.apache.log4j.ConsoleAppender log4j.appender.Console.layout=org.apache.log4j.PatternLayout log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n log4j.logger.java.sql.ResultSet=INFO log4j.logger.org.apache=INFO log4j.logger.java.sql.Connection=DEBUG log4j.logger.java.sql.Statement=DEBUG log4j.logger.java.sql.PreparedStatement=DEBUG
2.2. log4j.xml( 方式二) <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE log4j:configuration SYSTEM "log4j.dtd"> <log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/"> <appender name="STDOUT" class="org.apache.log4j.ConsoleAppender"> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%-5p %d{MM-dd HH:mm:ss,SSS} %m (%F:%L) " /> </layout> </appender> <logger name="java.sql"> <level value="debug" /> </logger> <logger name="org.apache.ibatis"> <level value="debug" /> </logger> <root> <level value="debug" /> <appender-ref ref="STDOUT" /> </root> </log4j:configuration>
5. 解决字段名与实体类属性名不相同的冲突
5.1. 准备表和数据
CREATE TABLE orders( order_id INT PRIMARY KEY AUTO_INCREMENT, order_no VARCHAR(20), order_price FLOAT ); INSERT INTO orders(order_no, order_price) VALUES('aaaa', 23); INSERT INTO orders(order_no, order_price) VALUES('bbbb', 33); INSERT INTO orders(order_no, order_price) VALUES('cccc', 22);
5.2. 定义实体类 :
public class Order { private int id; private String orderNo; private float price; }
5.3. 实现 getOrderById(id)
方式一: 通过在 sql 语句中定义别名 <select id="selectOrder" parameterType="int" resultType="_Order"> select order_id id, order_no orderNo,order_price price from orders where order_id=#{id} </select>
方式二: 通过<resultMap> <select id="selectOrderResultMap" parameterType="int" resultMap="orderResultMap"> select * from orders where order_id=#{id} </select> <resultMap type="_Order" id="orderResultMap"> <id property="id" column="order_id"/> <result property="orderNo" column="order_no"/> <result property="price" column="order_price"/> </resultMap>
6.实现关联表查询
6.1. 一对一关联
1). 提出需求
根据班级 id 查询班级信息(带老师的信息)
2). 创建表和数据
CREATE TABLE teacher( t_id INT PRIMARY KEY AUTO_INCREMENT, t_name VARCHAR(20) );
CREATE TABLE class( c_id INT PRIMARY KEY AUTO_INCREMENT, c_name VARCHAR(20), teacher_id INT );
ALTER TABLE class ADD CONSTRAINT fk_teacher_id FOREIGN KEY (teacher_id) REFERENCES teacher(t_id); INSERT INTO teacher(t_name) VALUES('LS1'); INSERT INTO teacher(t_name) VALUES('LS2'); INSERT INTO class(c_name, teacher_id) VALUES('bj_a', 1); INSERT INTO class(c_name, teacher_id) VALUES('bj_b', 2);
3). 定义实体类
public class Teacher { private int id; private String name;
//省略get/set } public class Classes { private int id; private String name; private Teacher teacher;
//省略get/set
}
4). 定义 sql 映射文件 ClassMapper.xml
<!-- association 用于一对一的关联查询 property: 对象属性的名称 javaType: 对象属性的类型 column:所对应的外键字段名称 select:使用另一个查询封装的结果 -->
<!-- 方式一: 嵌套结果:使用嵌套结果映射来处理重复的联合结果的子集 封装联表查询的数据(去除重复的数据) select * from class c, teacher t where c.teacher_id=t.t_id and c.c_id=1 --> <select id="getClass" parameterType="int" resultMap="ClassResultMap"> select * from class c, teacher t where c.teacher_id=t.t_id and c.c_id=#{id} </select> <resultMap type="_Classes" id="ClassResultMap"> <id property="id" column="c_id"/> <result property="name" column="c_name"/> <association property="teacher" column="teacher_id" javaType="_Teacher"> <id property="id" column="t_id"/> <result property="name" column="t_name"/> </association> </resultMap> <!-- 方式二: 嵌套查询:通过执行另外一个 SQL 映射语句来返回预期的复杂类型 SELECT * FROM class WHERE c_id=1; SELECT * FROM teacher WHERE t_id=1 //1 是上一个查询得到的 teacher_id 的值 --> <select id="getClass2" parameterType="int" resultMap="ClassResultMap2"> select * from class where c_id=#{id} </select> <resultMap type="_Classes" id="ClassResultMap2"> <id property="id" column="c_id"/> <result property="name" column="c_name"/> <association property="teacher" column="teacher_id" javaType="_Teacher" select="getTeacher"> </association> </resultMap> <select id="getTeacher" parameterType="int" resultType="_Teacher"> SELECT t_id id, t_name name FROM teacher WHERE t_id=#{id} </select>
5). 测试
@Test public void testOO() { SqlSession sqlSession = factory.openSession(); Classes c = sqlSession.selectOne("com.atguigu.day03_mybatis.test5.OOMapper.getClass", 1); System.out.println(c); } @Test public void testOO2() { SqlSession sqlSession = factory.openSession(); Classes c = sqlSession.selectOne("com.atguigu.day03_mybatis.test5.OOMapper.getClass2", 1); System.out.println(c); }
6.2. 一对多关联
1). 提出需求
根据 classId 查询对应的班级信息,包括学生,老师
2). 创建表和数据:
CREATE TABLE student( s_id INT PRIMARY KEY AUTO_INCREMENT, s_name VARCHAR(20), class_id INT ); INSERT INTO student(s_name, class_id) VALUES('xs_A', 1); INSERT INTO student(s_name, class_id) VALUES('xs_B', 1); INSERT INTO student(s_name, class_id) VALUES('xs_C', 1); INSERT INTO student(s_name, class_id) VALUES('xs_D', 2); INSERT INTO student(s_name, class_id) VALUES('xs_E', 2); INSERT INTO student(s_name, class_id) VALUES('xs_F', 2);
3). 定义实体类
public class Student { private int id; private String name; } public class Classes { private int id; private String name; private Teacher teacher; private List<Student> students; }
4). 定义 sql 映射文件 ClassMapper.xml
<!-- collection : 一对多关联查询 ofType : 指定集合中元素对象的类型 -->
<!-- 方式一: 嵌套结果: 使用嵌套结果映射来处理重复的联合结果的子集 SELECT * FROM class c, teacher t,student s WHERE c.teacher_id=t.t_id AND c.C_id=s.class_id AND c.c_id=1 --> <select id="getClass3" parameterType="int" resultMap="ClassResultMap3"> select * from class c, teacher t,student s where c.teacher_id=t.t_id and c.C_id=s.class_id and c.c_id=#{id} </select> <resultMap type="_Classes" id="ClassResultMap3"> <id property="id" column="c_id"/> <result property="name" column="c_name"/> <association property="teacher" column="teacher_id" javaType="_Teacher"> <id property="id" column="t_id"/> <result property="name" column="t_name"/> </association> <!-- ofType 指定 students 集合中的对象类型 --> <collection property="students" ofType="_Student"> <id property="id" column="s_id"/> <result property="name" column="s_name"/> </collection> </resultMap> <!-- 方式二:嵌套查询:通过执行另外一个 SQL 映射语句来返回预期的复杂类型 SELECT * FROM class WHERE c_id=1; SELECT * FROM teacher WHERE t_id=1 //1 是上一个查询得到的 teacher_id 的值 SELECT * FROM student WHERE class_id=1 //1 是第一个查询得到的 c_id 字段的值 --> <select id="getClass4" parameterType="int" resultMap="ClassResultMap4"> select * from class where c_id=#{id} </select> <resultMap type="_Classes" id="ClassResultMap4"> <id property="id" column="c_id"/> <result property="name" column="c_name"/> <association property="teacher" column="teacher_id" javaType="_Teacher" select="getTeacher2"></association> <collection property="students" ofType="_Student" column="c_id" select="getStudent"></collection> </resultMap> <select id="getTeacher2" parameterType="int" resultType="_Teacher"> SELECT t_id id, t_name name FROM teacher WHERE t_id=#{id} </select> <select id="getStudent" parameterType="int" resultType="_Student"> SELECT s_id id, s_name name FROM student WHERE class_id=#{id} </select>
5). 测试
@Test public void testOM() { SqlSession sqlSession = factory.openSession(); Classes c = sqlSession.selectOne("com.atguigu.day03_mybatis.test5.OOMapper.getClass3", 1); System.out.println(c); } @Test public void testOM2() { SqlSession sqlSession = factory.openSession(); Classes c = sqlSession.selectOne("com.atguigu.day03_mybatis.test5.OOMapper.getClass4", 1); System.out.println(c); }
7. 动态SQL与模糊查询
7.1. 提出 需求:
实现多条件查询用户(姓名模糊匹配, 年龄在指定的最小值到最大值之间)
7.2. 准备数据表和数据
create table d_user( id int primary key auto_increment, name varchar(10), age int(3) ); insert into d_user(name,age) values('Tom',12); insert into d_user(name,age) values('Bob',13); insert into d_user(name,age) values('Jack',18);
7.3. ConditionUser( 查询条件实体类)
private String name; private int minAge; private int maxAge;
7.4. User(表实体类)
private int id; private String name; private int age;
7.5. userMapper.xml(映射文件)
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.atguigu.day03_mybatis.test6.userMapper"> <select id="getUser" parameterType="com.atguigu.day03_mybatis.test6.ConditionUser" resultType="com.atguigu.day03_mybatis.test6.User"> select * from d_user where age>=#{minAge} and age<=#{maxAge} <if test='name!="%null%"'>and name like #{name}</if> </select> </mapper>
7.6. UserTest( 测试)
public class UserTest { public static void main(String[] args) throws IOException { Reader reader = Resources.getResourceAsReader("conf.xml"); SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(reader); SqlSession sqlSession = sessionFactory.openSession(); String statement = "com.atguigu.day03_mybatis.test6.userMapper.getUser"; List<User> list = sqlSession.selectList(statement, new ConditionUser("%a%", 1, 12)); System.out.println(list); } }
MyBatis 中可用的动态 SQL
- if
- choose(when, otherwise)
- trim(where, set)
- foreach
8调用存储过程
8.1. 提出需求:
查询得到男性或女性的数量, 如果传入的是 0就是女性否则就是男性
8.2. 准备数据库表和存储过程
create table p_user( id int primary key auto_increment, name varchar(10), sex char(2) ); insert into p_user(name,sex) values('A',"男"); insert into p_user(name,sex) values('B',"女"); insert into p_user(name,sex) values('C',"男"); #创建存储过程( 查询得到男性或女性的数量, 如果传入的是 0 就女性否则是男性) DELIMITER $ CREATE PROCEDURE mybatis.ges_user_count(IN sex_id INT, OUT user_count INT) BEGIN IF sex_id=0 THEN SELECT COUNT(*) FROM mybatis.p_user WHERE p_user.sex='女' INTO user_count; ELSE SELECT COUNT(*) FROM mybatis.p_user WHERE p_user.sex='男' INTO user_count; END IF; END $ #调用存储过程 DELIMITER ; SET @user_count = 0; CALL mybatis.ges_user_count(1, @user_count); SELECT @user_count;
8.3. 创建表的实体类
public class User { private String id; private String name; private String sex; }
8.4. userMapper.xml
<!-- <select> parameterMap : 引用<parameterMap> statementType : 指定Statement的真实类型: CALLABLE执行调用存储过程的语句 <parameterMap>: 定义多个参数的键值对 type : 需要传递的参数的真实类型 java.util.Map <parameter> : 指定一个参数key-value -->
<mapper namespace="com.atguigu.day03_mybatis.test7.userMapper"> <select id="getCount" resultType="java.util.Map" statementType="CALLABLE"> {call ges_user_count(#{sex_id,mode=IN,jdbcType=INTEGER},#{result,mode=OUT,jdbcType=INTEGER})} </select> </mapper>
8.5. 测试调用
Map<String, Integer> paramMap = new HashMap<>(); paramMap.put("sex_id", 1); Object returnValue = sqlSession.selectOne(statement, paramMap); System.out.println("result="+paramMap.get("result")); System.out.println("sex_id="+paramMap.get("sex_id")); System.out.println("returnValue="+returnValue);
9. MyBatis缓存
9.1. MyBatis 缓存 理解
正如大多数持久层框架一样,MyBatis 同样提供了 一级缓存和 二级缓存的支持
1. 一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session
flush 或 close 之后,该 Session 中的所有 Cache 就将清空。
2. 二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于
其存储作用域为 Mapper(Namespace),并且 可自定义存储源,如 Ehcache。
3. 对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存 Namespaces)的进行了
C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear。
9.2. Mybatis 一级缓存
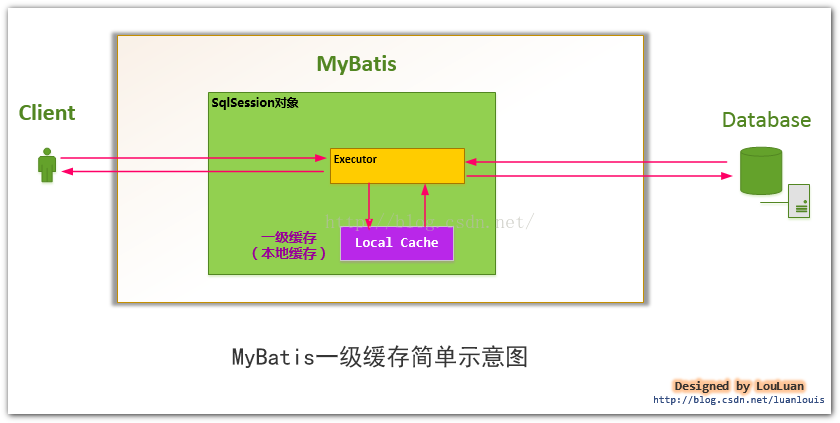
MyBatis中的一级缓存是怎样组织的?(即SqlSession中的缓存是怎样组织的?)
由于MyBatis使用SqlSession对象表示一次数据库的会话,那么,对于会话级别的一级缓存也应该是在SqlSession中控制的。
SqlSession只是一个MyBatis对外的接口,SqlSession将它的工作交给了Executor执行器这个角色来完成,负责完成对数据库的各种操作。
当创建了一个SqlSession对象时,MyBatis会为这个SqlSession对象创建一个新的Executor执行器,而缓存信息就被维护在这个Executor执行器中,MyBatis将缓存和对缓存相关的操作封装成了Cache接口中。
SqlSession、Executor、Cache之间的关系如下列类图所示:

如上述的类图所示,Executor接口的实现类BaseExecutor中拥有一个Cache接口的实现类PerpetualCache,则对于BaseExecutor对象而言,它将使用PerpetualCache对象维护缓存。
综上,SqlSession对象、Executor对象、Cache对象之间的关系如下图所示:

PerpetualCache实现原理其实很简单,其内部就是通过一个简单的HashMap<k,v>
来实现的,没有其他的任何限制。如下是PerpetualCache的实现代码:
package org.apache.ibatis.cache.impl; import java.util.HashMap; import java.util.Map; import java.util.concurrent.locks.ReadWriteLock; import java.util.concurrent.locks.ReentrantReadWriteLock; import org.apache.ibatis.cache.Cache; import org.apache.ibatis.cache.CacheException; public class PerpetualCache implements Cache { private String id; <strong>private Map<Object, Object> cache = new HashMap<Object, Object>();</strong> private ReadWriteLock readWriteLock = new ReentrantReadWriteLock(); public PerpetualCache(String id) { this.id = id; } public String getId() { return id; } public int getSize() { return cache.size(); } public void putObject(Object key, Object value) { cache.put(key, value); } public Object getObject(Object key) { return cache.get(key); } public Object removeObject(Object key) { return cache.remove(key); } public void clear() { cache.clear(); } public ReadWriteLock getReadWriteLock() { return readWriteLock; } public boolean equals(Object o) { if (getId() == null) throw new CacheException("Cache instances require an ID."); if (this == o) return true; if (!(o instanceof Cache)) return false; Cache otherCache = (Cache) o; return getId().equals(otherCache.getId()); } public int hashCode() { if (getId() == null) throw new CacheException("Cache instances require an ID."); return getId().hashCode(); } }
一级缓存的生命周期有多长?
a.MyBatis在开启一个数据库会话时,会创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象,Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。
b.如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用;
c.如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用;
d.SqlSession中执行了任何一个update操作(update()、delete()、insert()),都会清空PerpetualCache对象的数据,但是该对象可以继续使用;
SqlSession 一级缓存的工作流程:
1.对于某个查询,根据statementId,params,rowBounds来构建一个key值,根据这个key值去缓存Cache中取出对应的key值存储的缓存结果;
2. 判断从Cache中根据特定的key值取的数据数据是否为空,即是否命中;
3. 如果命中,则直接将缓存结果返回;
4. 如果没命中:
4.1 去数据库中查询数据,得到查询结果;
4.2 将key和查询到的结果分别作为key,value对存储到Cache中;
4.3. 将查询结果返回;
5. 结束。
Cache中Map的key值:CacheKey
Cache最核心的实现其实就是一个Map,将本次查询使用的特征值作为key,将查询结果作为value存储到Map中。怎样来确定一次查询的特征值?怎样判断某两次查询是完全相同的查询?如何确定Cache中的key值?
MyBatis认为,对于两次查询,如果以下条件都完全一样,那么就认为它们是完全相同的两次查询:
1. 传入的statementId
传入的statementId,对于MyBatis而言,你要使用它,必须需要一个statementId,它代表着你将执行什么样的Sql;
2. 查询时要求的结果集中的结果范围(结果的范围通过rowBounds.offset和rowBounds.limit表示);
3. 这次查询所产生的最终要传递给JDBC java.sql.Preparedstatement的Sql语句字符串(boundSql.getSql())
4. 传递给java.sql.Statement要设置的参数值
综上所述,CacheKey由以下条件决定:statementId + rowBounds + 传递给JDBC的SQL + 传递给JDBC的参数值
1) 提出需求:
根据 id 查询对应的用户记录对象
2). 准备数据库表和数据
CREATE TABLE c_user( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20), age INT ); INSERT INTO c_user(NAME, age) VALUES('Tom', 12); INSERT INTO c_user(NAME, age) VALUES('Jack', 11);
3). 创建表的实体类
public class User implements Serializable{ private int id; private String name; private int age; }
4). userMapper.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.atguigu.mybatis.test8.userMapper"> <select id="getUser" parameterType="int" resultType="_CUser"> select * from c_user where id=#{id} </select> <update id="updateUser" parameterType="_CUser"> update c_user set name=#{name}, age=#{age} where id=#{id} </update> </mapper>
5). 测试
/* * 一级缓存: 也就 Session 级的缓存(默认开启) */ @Test public void testCache1() { SqlSession session = MybatisUtils.getSession(); String statement = "com.atguigu.mybatis.test8.userMapper.getUser"; User user = session.selectOne(statement, 1); System.out.println(user); /* * 一级缓存默认就会被使用 */ /* user = session.selectOne(statement, 1); System.out.println(user); */ /* 1. 必须是同一个 Session,如果 session 对象已经 close()过了就不可能用了 */ /* session = MybatisUtils.getSession(); user = session.selectOne(statement, 1); System.out.println(user); */ /* 2. 查询条件是一样的 */ /* user = session.selectOne(statement, 2); System.out.println(user); */ /* 3. 没有执行过 session.clearCache()清理缓存 */ /* session.clearCache(); user = session.selectOne(statement, 2); System.out.println(user); */ /* 4. 执行过增删改的操作(这些操作都会清理缓存) */ /* session.update("com.atguigu.mybatis.test8.userMapper.updateUser", new User(2, "user", 23)); user = session.selectOne(statement, 2); System.out.println(user); */ }
9.3. Mybatis 二级缓存
MyBatis的缓存机制整体设计以及二级缓存的工作模式
MyBatis的二级缓存是Application级别的缓存,它可以提高对数据库查询的效率,以提高应用的性能。
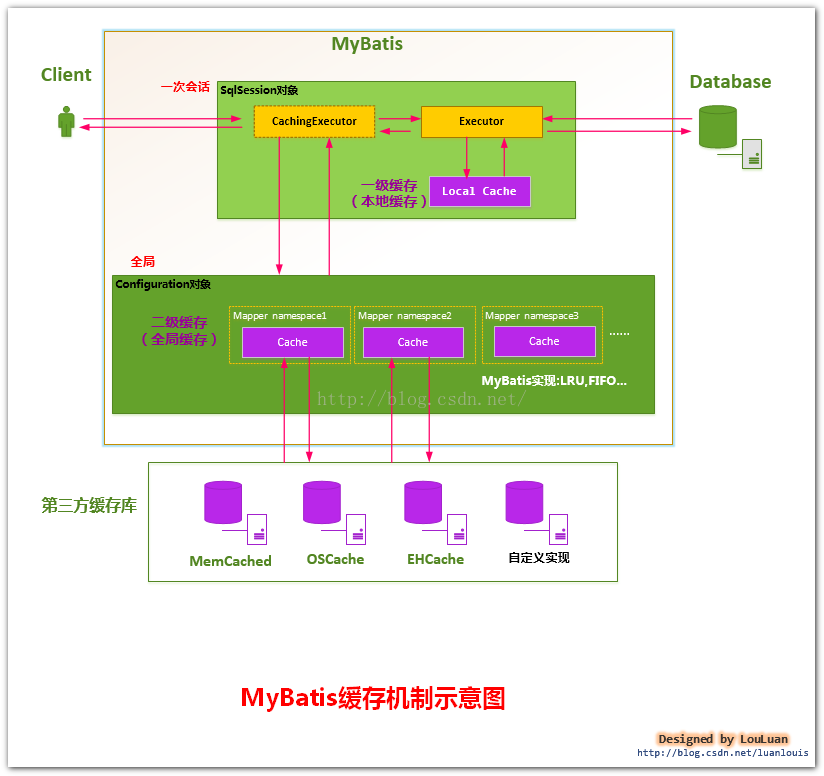
当开一个会话时,一个 SqlSession 对象会使用一个 Executor 对象来完成会话操作,MyBatis 的二级缓存机制的关键就是对这个 Executor 对象做文章。如果用户配置了" cacheEnabled=true ",那么 MyBatis 在为 SqlSession 对象创建 Executor 对象时,会对 Executor 对象加上一个装饰者: CachingExecutor ,这时 SqlSession 使用 CachingExecutor 对象来完成操作请求。
CachingExecutor 对于查询请求,会先判断该查询请求在 Application 级别的二级缓存中是否有缓存结果,
如果有查询结果,则直接返回缓存结果;
如果缓存中没有,再交给真正的 Executor 对象来完成查询操作,
之后 CachingExecutor 会将真正 Executor 返回的查询结果放置到缓存中,
然后再返回给用户。
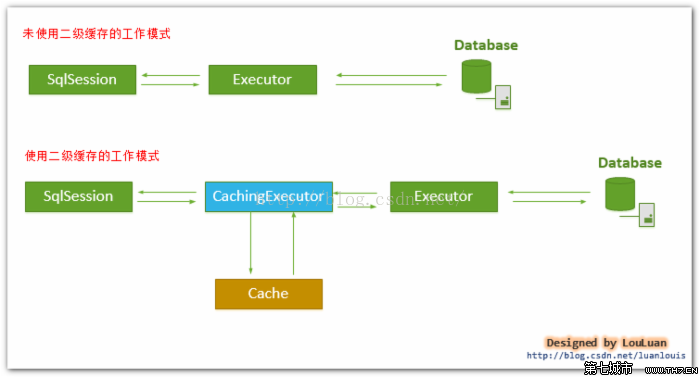
CachingExecutor是Executor的装饰者,以增强Executor的功能,使其具有缓存查询的功能,这里用到了设计模式中的装饰者模式。
MyBatis二级缓存的划分
MyBatis并不是简单地对整个Application就只有一个Cache缓存对象,
它将缓存划分的更细,即是Mapper级别的,即每一个Mapper都可以拥有一个Cache对象,具体如下:
a.为每一个Mapper分配一个Cache缓存对象(使用<cache>节点配置);
b.多个Mapper共用一个Cache缓存对象(使用<cache-ref>节点配置);
使用二级缓存,必须要具备的条件
MyBatis对二级缓存的支持粒度很细,它会指定某一条查询语句是否使用二级缓存。
虽然在Mapper中配置了<cache>,并且为此Mapper分配了Cache对象,
这并不表示我们使用Mapper中定义的查询语句查到的结果都会放置到Cache对象之中,
我们必须指定Mapper中的某条选择语句是否支持缓存,即在<select>节点中配置useCache="true" ,Mapper才会对此Select的查询支持缓存特性,
总之,要想使某条Select查询支持二级缓存,需要保证:
1.MyBatis支持二级缓存的总开关:全局配置变量参数cacheEnabled=true
2.该select语句所在的Mapper,配置了<cache> 或<cached-ref>节点,并且有效
3.该select语句的参数useCache=true
二级缓存实现的选择
MyBatis对二级缓存的设计非常灵活,它自己内部实现了一系列的Cache缓存实现类,并提供了各种缓存刷新策略如LRU,FIFO等等;
另外,MyBatis还允许用户自定义Cache接口实现,用户是需要实现org.apache.ibatis.cache.Cache接口,
然后将Cache实现类配置在<cache type="">节点的type属性上即可;
除此之外,MyBatis还支持跟第三方内存缓存库如Memecached的集成,总之,使用MyBatis的二级缓存有三个选择:
1.MyBatis自身提供的缓存实现;
2.用户自定义的Cache接口实现;
3.跟第三方内存缓存库的集成;
MyBatis自身提供的二级缓存的实现
MyBatis自身提供了丰富的,并且功能强大的二级缓存的实现,它拥有一系列的Cache接口装饰者,可以满足各种对缓存操作和更新的策略。
MyBatis定义了大量的Cache的装饰器来增强Cache缓存的功能,如下类图所示。
对于每个Cache而言,都有一个容量限制,MyBatis各供了各种策略来对Cache缓存的容量进行控制,以及对Cache中的数据进行刷新和置换。
MyBatis主要提供了以下几个刷新和置换策略:
LRU:(Least Recently Used),最近最少使用算法,即如果缓存中容量已经满了,会将缓存中最近做少被使用的缓存记录清除掉,然后添加新的记录;
FIFO:(First in first out),先进先出算法,如果缓存中的容量已经满了,那么会将最先进入缓存中的数据清除掉;
Scheduled:指定时间间隔清空算法,该算法会以指定的某一个时间间隔将Cache缓存中的数据清空;
Cache使用时的注意事项/避免使用二级缓存
注意事项
1. 只能在【只有单表操作】的表上使用缓存
不只是要保证这个表在整个系统中只有单表操作,而且和该表有关的全部操作必须全部在一个namespace下。
2. 在可以保证查询远远大于insert,update,delete操作的情况下使用缓存
这一点不需要多说,所有人都应该清楚。记住,这一点需要保证在1的前提下才可以!
避免使用二级缓存,二级缓存带来的好处远远比不上他所隐藏的危害。
1.缓存是以namespace为单位的,不同namespace下的操作互不影响。
2.insert,update,delete操作会清空所在namespace下的全部缓存。
3.通常使用MyBatis Generator生成的代码中,都是各个表独立的,每个表都有自己的namespace。
针对一个表的某些操作不在它独立的namespace下进行。
例如在UserMapper.xml中有大多数针对user表的操作。但是在一个XXXMapper.xml中,还有针对user单表的操作.
这会导致user在两个命名空间下的数据不一致。如果在UserMapper.xml中做了刷新缓存的操作,
在XXXMapper.xml中缓存仍然有效,如果有针对user的单表查询,使用缓存的结果可能会不正确。
更危险的情况是在XXXMapper.xml做了insert,update,delete操作时,会导致UserMapper.xml中的各种操作充满未知和风险。
多表操作一定不能使用缓存
首先不管多表操作写到那个namespace下,都会存在某个表不在这个namespace下的情况。
最后还是建议,放弃二级缓存,在业务层使用可控制的缓存代替更好。
1). 添加一个<cache>在 在 userMapper.xml
<mapper namespace="com.atguigu.mybatis.test8.userMapper"> <cache/>
2). 测试
/* * 测试二级缓存 */ @Test public void testCache2() { String statement = "com.atguigu.mybatis.test8.userMapper.getUser"; SqlSession session = MybatisUtils.getSession(); User user = session.selectOne(statement, 1); session.commit();
System.out.println("user="+user); SqlSession session2 = MybatisUtils.getSession(); user = session2.selectOne(statement, 1); session.commit(); System.out.println("user2="+user); }
3). 补充说明
映射语句文件中的所有 select 语句将会被缓存。
映射语句文件中的所有 insert,update 和 delete 语句会刷新缓存。
缓存会使用 Least Recently Used(LRU,最近最少使用的)算法来收回。
根据时间表(比如 no Flush Interval,没有刷新间隔),缓存不会以任何时间顺序来刷新。
缓存会存储列表集合或对象(无论查询方法返回什么)的 1024 个引用。
缓存会被视为是 read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以安
全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改
<cache eviction="FIFO" //回收策略为先进先出 flushInterval="60000" //自动刷新时间 60s size="512" //最多缓存 512 个引用对象 readOnly="true"/> //只读
10. spring 集成 MyBits
10.1. 添加 Jar
【mybatis 】
mybatis-3.2.0.jar
mybatis-spring-1.1.1.jar
log4j-1.2.17.jar
【spring 】
spring-aop-3.2.0.RELEASE.jar
spring-beans-3.2.0.RELEASE.jar
spring-context-3.2.0.RELEASE.jar
spring-core-3.2.0.RELEASE.jar
spring-expression-3.2.0.RELEASE.jar
spring-jdbc-3.2.0.RELEASE.jar
spring-test-3.2.4.RELEASE.jar
spring-tx-3.2.0.RELEASE.jar
aopalliance-1.0.jar
cglib-nodep-2.2.3.jar
commons-logging-1.1.1.jar
【MYSQL 驱动包】
mysql-connector-java-5.0.4-bin.jar
10.2. 数据库表
CREATE TABLE s_user( user_id INT AUTO_INCREMENT PRIMARY KEY, user_name VARCHAR(30), user_birthday DATE, user_salary DOUBLE )
10.3. 编码:
1).
2). 实体类: User
public class User { private int id; private String name; private Date birthday; private double salary; //set,get 方法 }
3). DAO 接口: UserMapper (XXXMapper)
public interface UserMapper { void save(User user); void update(User user); void delete(int id); User findById(int id); List<User> findAll(); }
4). SQL 映射文件: UserMapper.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.atguigu.mybatis.test9.UserMapper"> <resultMap type="User" id="userResult"> <result column="user_id" property="id"/> <result column="user_name" property="name"/> <result column="user_birthday" property="birthday"/> <result column="user_salary" property="salary"/> </resultMap> <!-- 取得插入数据后的 id --> <insert id="save" keyColumn="user_id" keyProperty="id" useGeneratedKeys="true"> insert into s_user(user_name,user_birthday,user_salary) values(#{name},#{birthday},#{salary}) </insert> <update id="update"> update s_user set user_name = #{name}, user_birthday = #{birthday}, user_salary = #{salary} where user_id = #{id} </update> <delete id="delete"> delete from s_user where user_id = #{id} </delete> <select id="findById" resultMap="userResult"> select * from s_user where user_id = #{id} </select> <select id="findAll" resultMap="userResult"> select * from s_user </select> </mapper>
5). 数据库连接文件: db.properties
jdbc.driverClassName=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/mybatis
jdbc.username=root
jdbc.password=root
6). spring 的配置文件: beans.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.2.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.2.xsd"> <!-- 关联 properties 文件 --> <context:property-placeholder location="db.properties" /> <!-- 数据源 --> <bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource" p:driverClassName="${jdbc.driverClassName}" p:url="${jdbc.url}" p:username="${jdbc.username}" p:password="${jdbc.password}"/> <!-- class: 指定用来创建 sqlSession 的工厂 dataSource-ref: 使用的数据源 typeAliasesPackage: 自动扫描的实体类包 --> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean" p:dataSource-ref="dataSource" p:typeAliasesPackage="org.monmday.springmybatis.domian"/> <!-- class : 指定自动扫描 xxxMapper.xml 映射文件的类 basePackage: 自动扫描的配置包 --> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer" p:basePackage="org.monmday.springmybatis.mappers" p:sqlSessionFactoryBeanName="sqlSessionFactory"/> <!-- 事务管理 --> <bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager" p:dataSource-ref="dataSource"/> <tx:annotation-driven transaction-manager="txManager" /> </beans>
7). 测试
@RunWith(SpringJUnit4ClassRunner.class) //使用Springtest框架 @ContextConfiguration("/beans.xml") //加载配置 public class SMTest { @Autowired //注入 private UserMapper userMapper; @Test public void save() { User user = new User(); user.setBirthday(new Date()); user.setName("marry"); user.setSalary(300); userMapper.save(user); System.out.println(user.getId()); } @Test public void update() { User user = userMapper.findById(2); user.setSalary(2000); userMapper.update(user); } @Test public void delete() { userMapper.delete(3); } @Test public void findById() { User user = userMapper.findById(1); System.out.println(user); } @Test public void findAll() { List<User> users = userMapper.findAll(); System.out.println(users); } }