本文介绍如何使用keras作图片分类(2分类与多分类,其实就一个参数的区别。。。呵呵)
先来看看解决的问题:从一堆图片中分出是不是书本,也就是最终给图片标签上:“书本“、“非书本”,简单吧。
先来看看网络模型,用到了卷积和全连接层,最后套上SOFTMAX算出各自概率,输出ONE-HOT码,主要部件就是这些,下面的nb_classes就是用来控制分类数的,本文是2分类:
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.optimizers import SGD
def Net_model(nb_classes, lr=0.001,decay=1e-6,momentum=0.9):
model = Sequential()
model.add(Convolution2D(filters=10, kernel_size=(5,5),
padding='valid',
input_shape=(200, 200, 3)))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(filters=20, kernel_size=(10,10)))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1000))
model.add(Activation('tanh'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
sgd = SGD(lr=lr, decay=decay, momentum=momentum, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
return model
上面的input_shape=(200, 200, 3)代表图片像素大小为宽高为200,200,并且包含RGB 3通道的图片,不是灰度图片(只要1个通道)
也就是说送入此网络的图片宽高必须200*200*3;如果不是这个shape就需要resize到这个shape
下面来看看训练程序,首先肯定是要收集些照片,书本、非书本的照片,我是分别放在了0文件夹和1文件夹下了,再带个验证用途的文件夹validate:

训练程序涉及到几个地方:照片文件的读取、模型加载训练与保存、可视化训练过程中的损失函数value
照片文件的读取
import cv2
import os
import numpy as np
import keras
def loadImages():
imageList=[]
labelList=[]
rootdir="d:\books\0"
list =os.listdir(rootdir)
for item in list:
path=os.path.join(rootdir,item)
if(os.path.isfile(path)):
f=cv2.imread(path)
f=cv2.resize(f, (200, 200))#resize到网络input的shape
imageList.append(f)
labelList.append(0)#类别0
rootdir="d:\books\1"
list =os.listdir(rootdir)
for item in list:
path=os.path.join(rootdir,item)
if(os.path.isfile(path)):
f=cv2.imread(path)
f=cv2.resize(f, (200, 200))#resize到网络input的shape
imageList.append(f)
labelList.append(1)#类别1
return np.asarray(imageList), keras.utils.to_categorical(labelList, 2)
关于(200,200)这个shape怎么得来的,只是几月前开始玩opencv时随便写了个数值,后来想利用那些图片,就适应到这个shape了
keras.utils.to_categorical函数类似numpy.onehot、tf.one_hot这些,只是one hot的keras封装
模型加载训练与保存
nb_classes = 2 nb_epoch = 30 nb_step = 6 batch_size = 3 x,y=loadImages() from keras.preprocessing.image import ImageDataGenerator dataGenerator=ImageDataGenerator() dataGenerator.fit(x) data_generator=dataGenerator.flow(x, y, batch_size, True)#generator函数,用来生成批处理数据(从loadImages中) model=NetModule.Net_model(nb_classes=nb_classes, lr=0.0001) #加载网络模型 history=model.fit_generator(data_generator, epochs=nb_epoch, steps_per_epoch=nb_step, shuffle=True)#训练网络,并且返回每次epoch的损失value model.save_weights('D:\Documents\Visual Studio 2017\Projects\ConsoleApp9\PythonApplication1\书本识别\trained_model_weights.h5')#保存权重 print("DONE, model saved in path-->D:\Documents\Visual Studio 2017\Projects\ConsoleApp9\PythonApplication1\书本识别\trained_model_weights.h5")
ImageDataGenerator构造函数有很多参数,主要用来提升数据质量,比如要不要标准化数字
lr=0.001这个参数要看经验,大了会导致不收敛,训练的时候经常由于这个参数的问题导致重复训练,这在没有GPU的情况下很是痛苦。。痛苦。。。痛苦。。。
model.save_weights是保存权重,但是不保存网络模型 ,对应的是model.load_weights方法
model.save是保存网络+权重,只是。。。。此例中用save_weights保存的h5文件是125M,但用save方法保存后,h5文件就增大为280M了。。。
上面2个save方法都能finetune,只是灵活度不一样。
可视化训练过程中的损失函数value
import matplotlib.pyplot as plt plt.plot(history.history['loss']) plt.show()
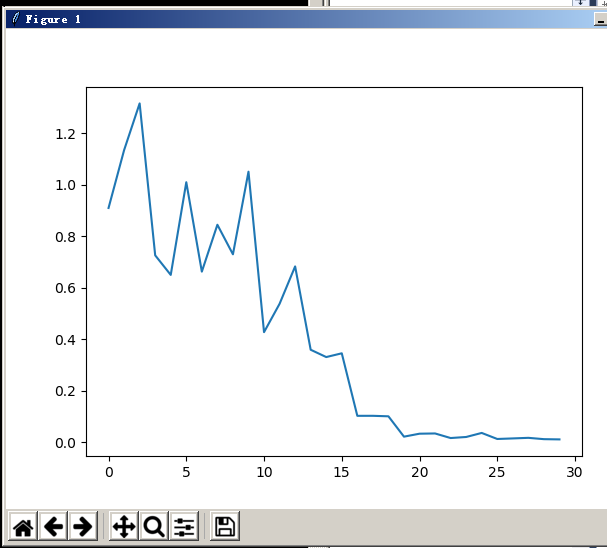
貌似没啥好补充的。。。
AND。。。。看看预测部分吧,这部分加载图片、加载模型,似乎都和训练部分雷同:
def loadImages():
imageList=[]
rootdir="d:\books\validate"
list =os.listdir(rootdir)
for item in list:
path=os.path.join(rootdir,item)
if(os.path.isfile(path)):
f=cv2.imread(path)
f=cv2.resize(f, (200, 200))
imageList.append(f)
return np.asarray(imageList)
x=loadImages()
x=np.asarray(x)
model=NetModule.Net_model(nb_classes=2, lr=0.0001)
model.load_weights('D:\Documents\Visual Studio 2017\Projects\ConsoleApp9\PythonApplication1\书本识别\trained_model_weights.h5')
print(model.predict(x))
print(model.predict_classes(x))
y=convert2label(model.predict_classes(x))
print(y)
predict的返回其实是softmax层返回的概率数值,是<=1的float
predict_classes返回的是经过one-hot处理后的数值,此时只有0、1两种数值(最大的value会被返回称为1,其他都为0)
convert2label:
def convert2label(vector):
string_array=[]
for v in vector:
if v==1:
string_array.append('BOOK')
else:
string_array.append('NOT BOOK')
return string_array
这个函数是用来把0、1转换成文本的,小插曲:
本来这里是中文的“书本”、“非书本”,后来和女儿一起调试时发现都显示成了问号,应该是中文字符问题,就改成了英文显示,和女儿一起写代码是种乐趣啊!
本来只是显示文本,感觉太无聊了,因此加上了opencv显示图片+分类文本的代码段:
for i in range(len(x)):
cv2.putText(x[i], y[i], (50,50), cv2.FONT_HERSHEY_SIMPLEX, 1, 255, 2)
cv2.imshow('image'+str(i), x[i])
cv2.waitKey(-1)
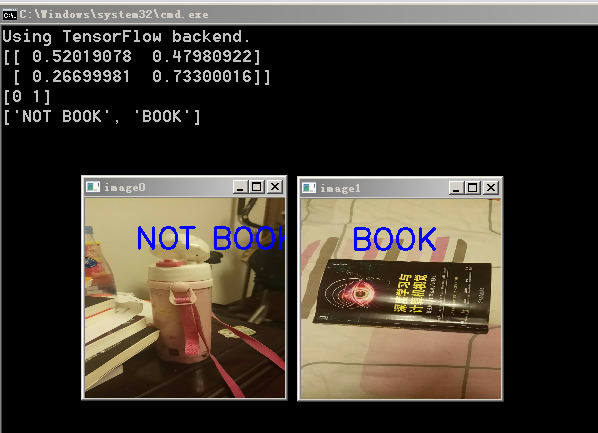
OK, 2018年继续学习,继续科学信仰。