商品列表页的视图处理函数:


class ListView(View): def get(self,request,catagory_id,page): # 取出当前页的分类商品,商品的主页 sort = request.GET.get("sort",'default') if sort not in ("price", "hot"): sort = "default" try: catagory = GoodsCategory.objects.get(id=catagory_id) except GoodsCategory.DoesNotExist: return redirect(reverse("goods:index")) # 取出全部商品的分类 catagorys = GoodsCategory.objects.all() # 获取新品推荐的连个商品 new_skus = GoodsSKU.objects.filter(category=catagory).order_by("-create_time")[:2] # 根据当前的分类商品,取出所有的商品 if sort == "price": goods_skus = GoodsSKU.objects.filter(category=catagory).order_by("price") elif sort == "hot": goods_skus = GoodsSKU.objects.filter(category=catagory).order_by("sales") else: goods_skus = GoodsSKU.objects.filter(category=catagory) # 获取购物车的数量 cart_num = 0 redis_con = get_redis_connection('default') if request.user.is_authenticated: cart = redis_con.hgetall('cart_%s' % request.user.id) for count in cart.values(): cart_num += int(count) # 把当前分类的全部商品分页处理 paginator=Paginator(goods_skus,1) # 获取当前也的数据 page = int(page) try: page_skus=paginator.page(page) except EmptyPage: page_skus = paginator.page(1) # 查看当前页面的总数 num_pages = paginator.num_pages # 页面展示的页数 # 如果页数超过5页 页数属于最后三页 页面总数 paginator.num_pages paginator.num_pages - page < 3 # 其他剩余情况 # 如果页数小于5页,展示全部的页数 if num_pages <= 5: page_list = range(1, num_pages + 1) # 如果页数超过5页 页数属于前三页 page<=3,战士前5页 elif page <= 3: # 页数属于前三页, 页数展示前5页 page_list = range(1, 6) elif num_pages - page < 3: # 页数属于最后三页 page_list = range(num_pages - 4, num_pages + 1) else: page_list = range(page - 2, page + 3) context = { "catagory": catagory, "catagorys": catagorys, "page_skus": page_skus, "new_skus": new_skus, "page_list": page_list, 'sort': sort, 'cart_num': cart_num } return render(request, "list.html", context)
商品列表页的请求路径
url(r"^list/(?P<category_id>d+)/(?P<page>d+)$", views.ListView.as_view(), name="list"),
商品列表页的html页面:
{% extends "base.html" %} {% load staticfiles %} {% block title %}天天生鲜-商品列表{% endblock %} {% block body %} <div class="navbar_con"> <div class="navbar clearfix"> <div class="subnav_con fl"> <h1>全部商品分类</h1> <span></span> <ul class="subnav"> {% for category in categorys %} <li><a href="{% url 'goods:list' category.id 1 %}" class="{{ category.logo }}">{{ category.name }}</a></li> {% endfor %} </ul> </div> <ul class="navlist fl"> <li><a href="">首页</a></li> <li class="interval">|</li> <li><a href="">手机生鲜</a></li> <li class="interval">|</li> <li><a href="">抽奖</a></li> </ul> </div> </div> <div class="breadcrumb"> <a href="{% url 'goods:index' %}">全部分类</a> <span>></span> <a href="{% url 'goods:list' category.id 1 %}">新鲜水果</a> </div> <div class="main_wrap clearfix"> <div class="l_wrap fl clearfix"> <div class="new_goods"> <h3>新品推荐</h3> <ul> {% for sku in new_skus %} <li> <a href="{% url 'goods:detail' sku.id %}"><img src="{{ sku.default_image.url }}"></a> <h4><a href="{% url 'goods:detail' sku.id %}">{{ sku.name }}</a></h4> <div class="prize">¥{{ sku.price }}</div> </li> {% endfor %} </ul> </div> </div> <div class="r_wrap fr clearfix"> <div class="sort_bar"> <a href="{% url 'goods:list' category.id 1 %}?sort=default" {% if sort == "default" %}class="active"{% endif %}>默认</a> <a href="{% url 'goods:list' category.id 1 %}?sort=price" {% if sort == "price" %}class="active"{% endif %}>价格</a> <a href="{% url 'goods:list' category.id 1 %}?sort=hot" {% if sort == "hot" %}class="active"{% endif %}>人气</a> </div> <ul class="goods_type_list clearfix"> {% for sku in page_skus %} <li> <a href="{% url 'goods:detail' sku.id %}"><img src="{{ sku.default_image.url }}"></a> <h4><a href="{% url 'goods:detail' sku.id %}">{{ sku.name }}</a></h4> <div class="operate"> <span class="prize">¥{{ sku.price }}</span> <span class="unit">{{ sku.price }}/{{ sku.unit }}</span> <a href="#" class="add_goods" title="加入购物车"></a> </div> </li> {% endfor %} </ul> <div class="pagenation"> {% if page_skus.has_previous %} <a href="{{ page_skus.previous_page_number }}">上一页</a> {% endif %} {% for p in page_list %} <a href="{% url 'goods:list' category.id p %}?sort={{ sort }}" {% if p == page_skus.number %}class="active"{% endif %}>{{ p }}</a> {% endfor %} {% if page_skus.has_next %} <a href="{{ page_skus.next_page_number }}">下一页></a> {% endif %} </div> </div> </div> {% endblock %}
全文检索
全文检索不同于特定字段的模糊查询,使用全文检索的效率更高,并且能够对于中文进行分词处理。
- haystack:全文检索的框架,支持whoosh、solr、Xapian、Elasticsearc四种全文检索引擎,点击查看官方网站。
- whoosh:纯Python编写的全文搜索引擎,虽然性能比不上sphinx、xapian、Elasticsearc等,但是无二进制包,程序不会莫名其妙的崩溃,对于小型的站点,whoosh已经足够使用,点击查看whoosh文档。
- jieba:一款免费的中文分词包,如果觉得不好用可以使用一些收费产品。
在虚拟环境中依次安装需要的包。
pip install django-haystack pip install whoosh pip install jieba
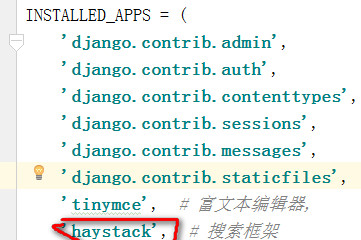
1 settings.py文件,安装应用haystack。
INSTALLED_APPS = ( ... 'haystack', )
2 在settings.py文件中配置搜索引擎
# haystack搜索框架的配置
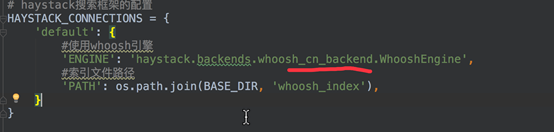
HAYSTACK_CONNECTIONS = {
'default': {
#使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
#索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
#当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
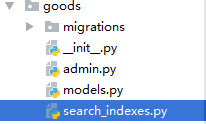
3 在goods应用目录下新建一个search_indexes.py(固定的)文件,在其中定义一个商品索引类(类名可以随便取)
因为要对goods应用建立搜索,所以,search_indexes.py要建立在它的下面
from haystack import indexes from goods.models import GoodsSKU class GoodsSKUIndex(indexes.SearchIndex, indexes.Indexable): """索引类, 告诉haystack在建立数据索引的时候使用""" text = indexes.CharField(document=True, use_template=True) def get_model(self): """把那个表建立索引""" return GoodsSKU def index_queryset(self, using=None): """对表中的那个字段建立索引""" return self.get_model().objects.all()
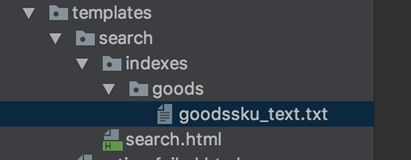
4 在templates下面新建目录search/indexes/goods/goodssku_text.txt
goods是和应用的名字对应上,而goodssku是和get_model中对象的名字(小写)对应上的
# 执行建立索引的字段
{{ object.name }}
{{ object.title }}
5 使用命令生成索引文件。
python manage.py rebuild_index
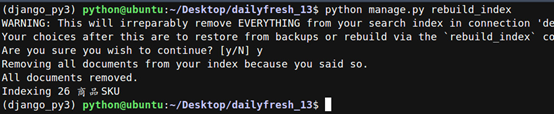
多了下面的文件
全文检索的使用:
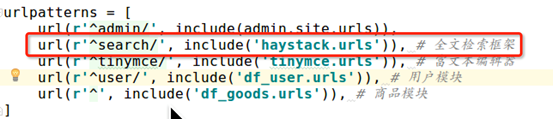
1在项目根级配置url。
import haystack.urls url(r'^search/', include(haystack.urls)),
2 表单搜索时设置表单内容如下:
这个就是把搜索框写成固定的格式,我这继承的是base.html:
下面的是原来的页面:

修改后的代码:
<div class="search_con fl"> <form action="/search/" method="get"> <input type="text" class="input_text fl" name="q" placeholder="搜索商品"> <input type="submit" class="input_btn fr" name="" value="搜索"> </form> </div>
点击标题进行提交时,会通过haystack搜索数据。
全文检索结果:
搜索出结果后,haystack会把搜索出的结果传递给templates/search目录下的search.html,在templates/search目录下建立search.html:
编写如下的代码,对查询的结果进行渲染
{% extends 'base.html' %} {% load staticfiles %} {% block title %}天天生鲜-搜索结果{% endblock %} {% block search_bar %} <div class="search_bar clearfix"> <a href="{% url 'goods:index' %}" class="logo fl"><img src="{% static 'images/logo.png' %}"></a> <div class="sub_page_name fl">| 搜索结果</div> <div class="search_con fr"> <form action="/search/" method="get"> <input type="text" class="input_text fl" name="q" placeholder="搜索商品"> <input type="submit" class="input_btn fr" value="搜索"> </form> </div> </div> {% endblock %} {% block body %} <div class="main_wrap clearfix"> <ul class="goods_type_list clearfix"> {% for result in page %} <li> <a href="{% url 'goods:detail' result.object.id %}"><img src="{{ result.object.default_image.url }}"></a> <h4><a href="{% url 'goods:detail' result.object.id %}">{{result.object.name}}</a></h4> <div class="operate"> <span class="prize">¥{{ result.object.price }}</span> <span class="unit">{{ result.object.price }}/{{ result.object.unit }}</span> </div> </li> {% empty %} <p>没有找到您要查询的商品。</p> {% endfor %} </ul> {% if page.has_previous or page.has_next %} <div class="pagenation"> {% if page.has_previous %}<a href="/search/?q={{ query }}&page={{ page.previous_page_number }}">{% endif %}<上一页{% if page.has_previous %}</a>{% endif %} | {% if page.has_next %}<a href="/search/?q={{ query }}&page={{ page.next_page_number }}">{% endif %}下一页>{% if page.has_next %}</a>{% endif %} </div> {% endif %} </div> {% endblock %}
query:搜索关键字 page:当前页的page对象 paginator:分页paginator对象,result.object.id中的object对应的是进行建立所以的表GoodsSKU
通过HAYSTACK_SEARCH_RESULTS_PER_PAGE可以控制每页显示数量
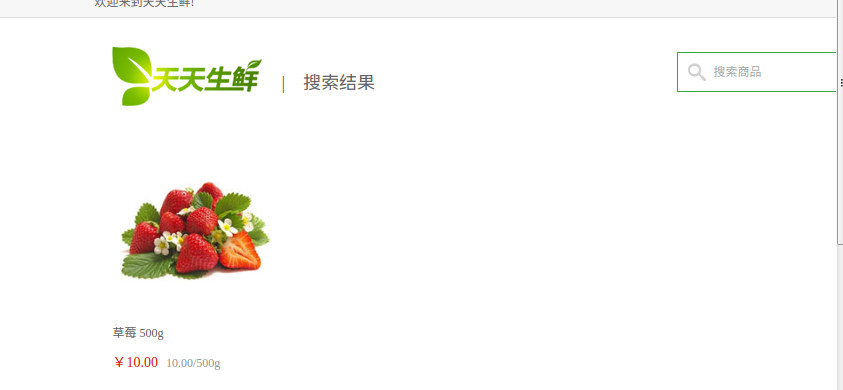
在搜索框搜索草莓:

返回结果如下:
上面的whoosh只支持对英文的分词,对中文支持的不好,所以更改它分词的方式:
cd /home/python/.virtualenvs/django_py3/lib/python3.5//site-packages//haystack/backends/
在上面的目录中创建ChineseAnalyzer.py文件

import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode, **kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()
复制whoosh_backend.py文件,改为如下名称:whoosh_cn_backend.py
打开复制出来的新文件,引入中文分析类,内部采用jieba分词
在里面添加以下代码:
from .ChineseAnalyzer import ChineseAnalyzer
更改词语分析类
查找 analyzer=StemmingAnalyzer() 改为 analyzer=ChineseAnalyzer()
更改配置信息:
重新创建索引数据
python manage.py rebuild_index
