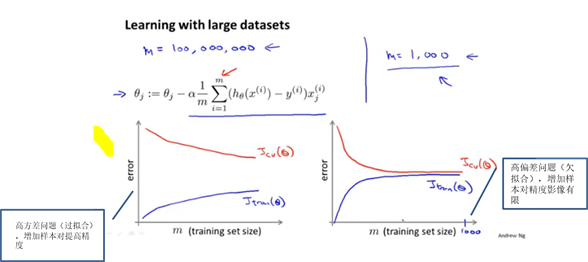
大规模机器学习:
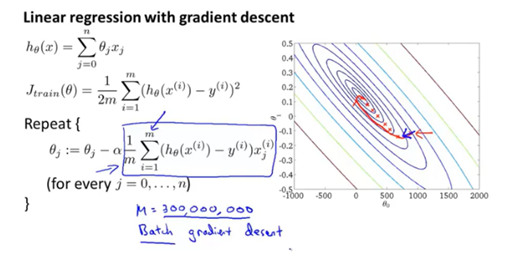
线性回归的梯度下降算法:Batch gradient descent(每次更新使用全部的训练样本)

批量梯度下降算法(Batch gradient descent):
每计算一次梯度会遍历全部的训练样本,如果训练样本的比较多时,内存消耗过大。
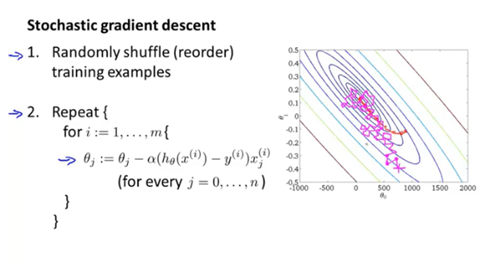
随机梯度下降算法:
1、 首先将随机打乱的训练样本数据
2、 外循环:(一般2—10次即可,若内循环中次数100000以上,则一次即可)
内循环:遍历所有的训练样本,每次梯度下降时使用一个样本计算梯度。
与批量梯度像算法相比,其下降曲线不停,图中右侧红色表示批量梯度下降算法,洋红表示随机梯度下降算法。
Mini-Batch梯度下降算法
1、 设置每次遍历的样本数b
2、 外循环:
内循环:遍历所有的样本,每b个样本更新一次梯度

对比:
批量下降:每次梯度更新使用全部的样本
随机下将:每次梯度更新使用1个样本
Mini-batch:每次梯度更新使用b个样本,b>1,小于全部的样本数。

随机梯度下降算法的收敛:
1、 在更新梯度前计算损失函数:
2、 比如:绘制损失函数的曲线每1000个样本
