没想到python是如此强大,令人着迷,以前看见图片总是一张一张复制粘贴,现在好了,学会python就可以用程序将一张张图片,保存下来。
今天逛贴吧看见好多美图,可是图片有点多,不想一张一张地复制粘贴,怎么办呢?办法总是有的,即便没有我们也可以创造一个办法。

下面就看看我今天写的程序:
#coding=utf-8 #urllib模块提供了读取Web页面数据的接口 import urllib.request #re模块主要包含了正则表达式 import re #定义一个getHtml()函数 def getHtml(url): page = urllib.request.urlopen(url) #urllib.request.urlopen()方法用于打开一个URL地址 html = page.read() #read()方法用于读取URL上的数据 return html def getImg(html): reg = r'src="(.+?.jpg)" pic_ext' #正则表达式,得到图片地址 imgre = re.compile(reg) #re.compile() 可以把正则表达式编译成一个正则表达式对象. html = html.decode('utf-8') #python3 imglist = re.findall(imgre,html) #re.findall() 方法读取html 中包含 imgre(正则表达式)的数据 #把筛选的图片地址通过for循环遍历并保存到本地 #核心是urllib.request.urlretrieve()方法,直接将远程数据下载到本地,图片通过x依次递增命名 x = 0 for imgurl in imglist: urllib.request.urlretrieve(imgurl,'D:E\%s.jpg' % x) x += 1 html = getHtml("https://tieba.baidu.com/p/xxxxxxxx") print(getImg(html))
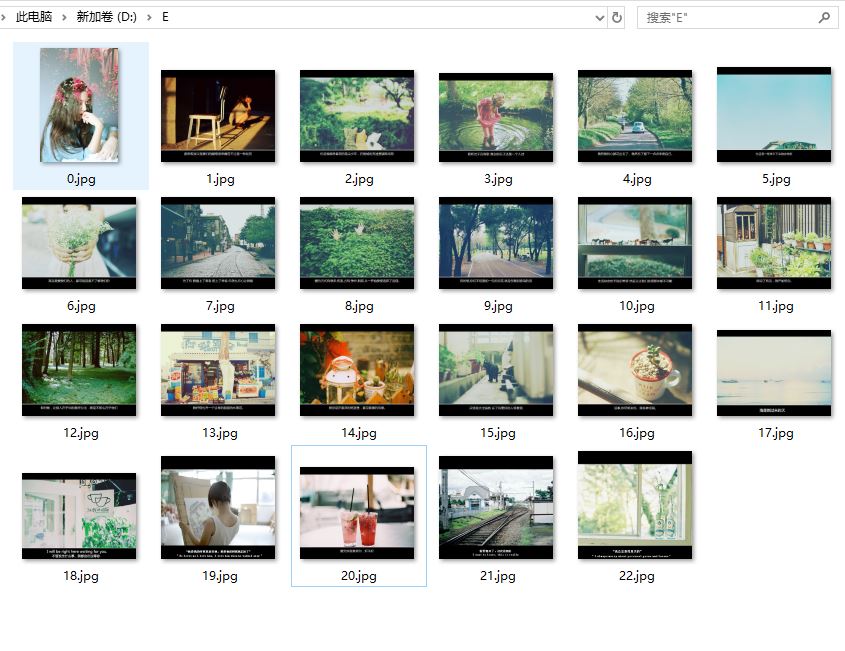
运行程序后,下面就是见证奇迹的时刻,打开对应文件夹:
哇!图片全部保存了下来,so nice! :-)
2019年1月更新备注:
此前代码为2015年Python2.x环境测试,现在已将代码更新,测试环境为Python3.7 ,注意请在D盘新建一个文件夹重命名为E
测试网址:https://tieba.baidu.com/p/2555125530
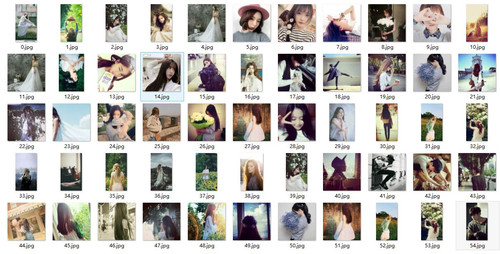
测试结果如图: