- 首先是一部分概念和示例,这部分转自:http://coolshell.cn/articles/9104.html
- Pattern Space
- 第零个是关于-n参数的,大家也许没看懂,没关系,我们来看一下sed处理文本的伪代码,并了解一下Pattern Space的概念:
foreach line in file {//放入把行Pattern_SpacePattern_Space <= line;// 对每个pattern space执行sed命令Pattern_Space <= EXEC(sed_cmd, Pattern_Space);// 如果没有指定 -n 则输出处理后的Pattern_Spaceif (sed option hasn't "-n") {print Pattern_Space}}
- Address
- 第一个是关于address,几乎上述所有的命令都是这样的(注:其中的!表示匹配成功后是否执行命令)
[address[,address]][!]{cmd}
address可以是一个数字,也可以是一个模式,你可以通过逗号要分隔两个address 表示两个address的区间,参执行命令cmd,伪代码如下:
bool bexec = falseforeach line in file {if ( match(address1) ){bexec = true;}if ( bexec == true) {EXEC(sed_cmd);}if ( match (address2) ) {bexec = false;}}
关于address可以使用相对位置,如:
# 其中的+3表示后面连续3行$ sed '/dog/,+3s/^/# /g' pets.txtThis is my catmy cat's name is betty# This is my dog# my dog's name is frank# This is my fish# my fish's name is georgeThis is my goatmy goat's name is adam
- 命令打包
- cmd可以是多个,它们可以用分号分开,可以用大括号括起来作为嵌套命令。下面是几个例子:
$ cat pets.txtThis is my catmy cat's name is bettyThis is my dogmy dog's name is frankThis is my fishmy fish's name is georgeThis is my goatmy goat's name is adam# 对3行到第6行,执行命令/This/d$ sed '3,6 {/This/d}' pets.txtThis is my catmy cat's name is bettymy dog's name is frankmy fish's name is georgeThis is my goatmy goat's name is adam# 对3行到第6行,匹配/This/成功后,再匹配/fish/,成功后执行d命令$ sed '3,6 {/This/{/fish/d}}' pets.txtThis is my catmy cat's name is bettyThis is my dogmy dog's name is frankmy fish's name is georgeThis is my goatmy goat's name is adam# 从第一行到最后一行,如果匹配到This,则删除之;如果前面有空格,则去除空格$ sed '1,${/This/d;s/^ *//g}' pets.txtmy cat's name is bettymy dog's name is frankmy fish's name is georgemy goat's name is adam
- Hold Space
- 接下来,我们需要了解一下Hold Space的概念,我们先来看四个命令:
g: 将hold space中的内容拷贝到pattern space中,原来pattern space里的内容清除
G: 将hold space中的内容append到pattern space
后
h: 将pattern space中的内容拷贝到hold space中,原来的hold space里的内容被清除
H: 将pattern space中的内容append到hold space
后
x: 交换pattern space和hold space的内容
这些命令有什么用?我们来看两个示例吧,用到的示例文件是:
$ cat t.txtonetwothree
第一个示例:
$ sed 'H;g' t.txtoneonetwoonetwothree
是不是有点没看懂,我作个图你就看懂了。 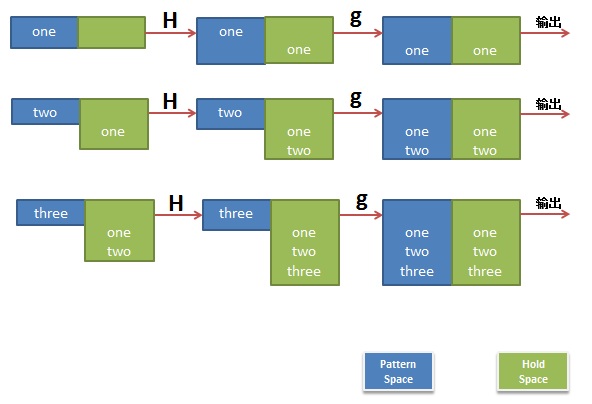
第二个示例,反序了一个文件的行:
$ sed '1!G;h;$!d' t.txtthreetwoone
其中的 ‘1!G;h;$!d’ 可拆解为三个命令
1!G —— 只有第一行不执行G命令,将hold space中的内容append回到pattern space
h —— 第一行都执行h命令,将pattern space中的内容拷贝到hold space中
$!d —— 除了最后一行不执行d命令,其它行都执行d命令,删除当前行
如图: 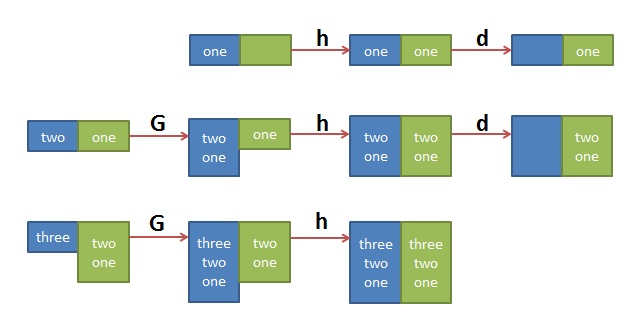
附上自己的一点理解:sed有P区(Pattern space)和H区(Hold space),每读取一行就会把内容放入P区,这时如果我们想对之前对内容做些操作,就需要用到H区用于暂存一些数据。
拿上面最后一个图来说,读取第一行,读取one到P区,然后h命令放到H区;
后面依次读取到P区,然后追加到H区,删除P区是为了不输出内容;
读到最后一行,把数据追加到H区,然后用H区的内容替换掉P区,最后输出P区的内容。