一、wordcloud是什么
词云,在一段文本中提取关键词进行扁平化的展示,更能吸引目标客户的眼球。
市面上有很多在线生成词云的工具,本文以Python中的第三方库wordcloud为例讲解如何自动生成词云图
二、在python3环境中安装
1. 使用conda install wordcloud或者pip install wordcloud安装,此方法可能会报错或者安装失败
2. 下载whl安装,https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud搜索下载匹配的
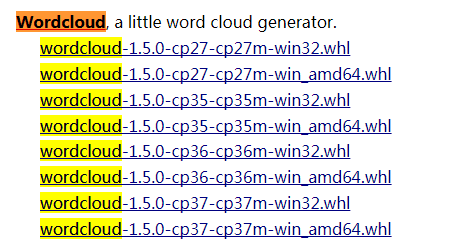
在命令行中进入到whl下载路径所在的文件夹,输入命令pip install +此文件的名称.whl
三、详解
3.1 类属性
官方介绍:http://amueller.github.io/word_cloud/generated/wordcloud.WordCloud.html#wordcloud.WordCloud
class wordcloud.WordCloud(
font_path=None, #(string)字体OTF or TTF路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = '黑体.ttf'
width=400,#(int)输出画布的宽度,默认400像素
height=200,(int) #输出画布的宽度,默认200像素
margin=2, #(int)画布边缘留白的空隙,默认留白空间是2像素
ranks_only=None,
prefer_horizontal=0.9, #(float)词语水平方向排版出现的频率,默认 0.9 ,所以词语垂直方向排版出现频率为 0.1
mask=None, #(nd-array or None) 是否使用mask(蒙板),默认不使用。若使用mask,则需提供一个二值化的mask(即只有0和1的黑白色mask),此时参数width和height会被忽略,单词会出现在mask非白色(#FFFFFF)的位置上。
scale=1, #(float)在字段width和height乘以的倍数,最终呈现的画布尺寸以这个结果。默认是1,此方法适合需要呈现大尺寸的画布
color_func=None,#(callable)生成新颜色的函数,默认为空。如果为空,则使用 self.color_func
max_words=200, #(int)单词最多显示数量,默认200个
min_font_size=4, #(int)单词最小尺寸,默认4像素
stopwords=None,#(set of strings or None)设置需要屏蔽展示的词,如果为空,则使用内置的STOPWORDS。若使用generate_from_frequencies生成方式,则会忽略此参数
random_state=None, #(int or None)为每个单词返回一个PIL颜色
background_color='black', #(string)输出画布背景颜色,默认黑色
max_font_size=None, #(int)单词最大尺寸,默认不限制
font_step=1,#(int)字体步长,默认1。如果步长大于1,会加快运算但是可能导致结果出现较大的误差(这块确实不知道啥意思)
mode='RGB', #(string) 颜色显示模式,默认”RGB”。当参数为“RGBA”并且background_color是None时,背景色为透明
relative_scaling='auto', #(float)词频和字体大小的关联性(倍数)。默认是auto,即为0.5。若为0,只考虑单词的排列顺序;若为1,则单词展现的大小和出现的频率一致;若两者都考虑则可以设置为auto。若参数repeat=True,则此项为0
regexp=None, #(string or None (optional))把文本切片的通用方法。若为空,则使用正则匹配r"w[w'];若使用generate_from_frequencies生成方式,则忽略此参数
collocations=True,#(bool) 是否包含两个单词的搭配性,默认包含。若使用generate_from_frequencies生成方式,则忽略此参数
colormap=None, #(string or matplotlib colormap)给每个单词随机分配颜色或者使用Matplotlib调色板,默认颜色是”viridis”即翠绿色。若使用了参数color_func,则忽略此项
normalize_plurals=True, #(bool)是否去掉单词末尾的‘s’,默认去掉。若为真,并且单词以‘s’结尾(若以‘ss’结尾则不符合此规则),‘s’会被去除并且去除后的单词出现的频率会被统计。若使用generate_from_frequencies生成方式,则忽略此参数
contour_width=0, #(float)mask轮廓线宽。若mask不为空且此项值大于0,就绘制出mask轮廓 (default=0)
contour_color='black', #(color value) Mask轮廓颜色,默认黑色
repeat=False #(bool)单词是否重复展示,默认不重复
)
3.2 方法
| 方法名 | 参数 | 返回值 | 备注 |
fit_words(frequencies) |
frequencies:dict from string to float | self | 根据单词及其频率生成词云 |
|
(frequencies, max_font_size=None) |
frequencies:dict from string to float max_font_size:int |
self | |
generate(text) |
text:string | self | 根据文本生成词云,是方法generate_from_text的别称。输入的文本应该是一个自然文本。若输入的是已排列好的单词,那么单词会出现两次,可以设置参数collocations=False去除此单词重复。调用process_text和genereate_from_frequences |
generate_from_text(text) |
text:string | self | |
process_text(text) |
text:string | words:dict (string, int) | 将一长段文本切片成单词,并去除stopwords。返回单词(words)和其出现次数的字典格式 |
|
random_state:RandomState, int, or None, default=None color_func:function or None, default=None colormap:string or matplotlib colormap, default=None |
self | |
to_array() |
image:nd-array size (width, height, 3) | 转换成numpy array | |
|
filename:string | self | 保存图片文件 |
四、一些栗子
4.1 默认参数+通过文本生成
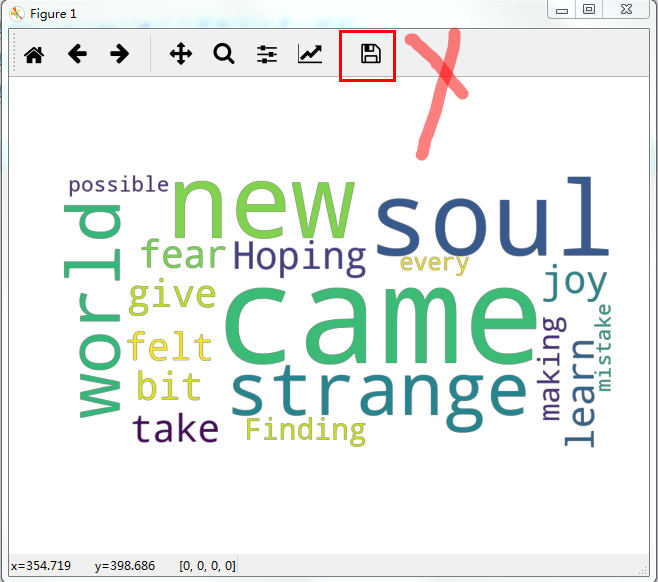
文本text内容是歌曲《soul》的一段歌词:
I'm a new soul。
I came to this strange world。
Hoping I could learn a bit about how to give and take。
But since I came here, felt the joy and the fear。
Finding myself making every possible mistake。
1 text = open('ABC.txt').read() 2 wc = WordCloud() 3 #wc.generate_from_text(text) 4 wc.generate(text)
输出结果:

tips:
1.每次运行的结果均不同,单词展示位置有随机性
2. 对比歌词可以看到,英文单词中的一些介词、主谓宾名词等直接被当成了STOPWORDS
查看了作者在Github上提交的文档https://github.com/amueller/word_cloud/blob/master/wordcloud/stopwords
作者已经设置了193个停止词
3. 当然,也可以自定义停止词,后续讲解
4.2 字体上限、下限设置、更改画布背景颜色
WordCloud(max_font_size=50,min_font_size=10,background_color='yellow')
颜色写法还可以用下面的形式表示:
WordCloud(max_font_size=50,min_font_size=10,background_color=(255,255,0))
WordCloud(max_font_size=50,min_font_size=10,background_color='#FFFF00')

颜色代码可以直接度娘或者参考http://xh.5156edu.com/page/z1015m9220j18754.html
4.3 更改边缘留白宽度、对比水平和垂直方向展示文字概率的不同、更改画布尺寸
WordCloud(margin=50,prefer_horizontal=0.5,height=600)

4.4 设置画布背景为透明,画布扩展至默认尺寸的2倍
WordCloud(background_color=None,mode='RGBA',scale=2)

tips:
1、为了让大家更好看出来是透明背景(灰色马赛克表示透明)上图我是截图的,若放原图是看不出来的(因为现在的背景本来就是白色)
2、若在python中使用pyplot中的show()方法查看的话,弹出的Figure是看不出背景是透明的
3、在Figure中点击右上角的“保存”按钮(如下图)存储的图片也不是python生成的原图,而是你此刻看到的图片大小
若需要保存图片要使用to_file()这个方法
4.5 自定义字体,设置单词重复显示,使用蒙板(mask)
蒙板mask的概念很简单,就是说在你选定的一张图片非白色的区域上生成词云
py_mask = np.array(Image.open('girl_mask.png'))
wc = WordCloud(background_color='white',mask=py_mask,contour_width=1, contour_color='blue',repeat='True',font_path='NexaRustSlab-BlackShadow01.otf')


tips:
1. 若使用的mask图片是二值图片,展现效果更好。
二值图片的意思就是直观上看只有纯黑色和纯白色,并且查看每个像素的数值只有0和1或者0和255;但是 不是看起来是纯黑色和纯白色的图片就一定是二值图片,也有可能是灰度图。查询是否是二值化图片的方法可以使用photoshop或者matlab、python等,当然也可以只用这些工具将其他图片改为二值图片。方法不难,但是涉及到了图像处理方面的内容,这里不展开讲解了
2. 若使用的是普通的彩色图片,系统会进行像素点值大小的判断。这里我没有进去查看作者设定的阈值是多少。根据我之前在matlab做图像处理的经验,这个值应该是0~某一个灰度值区间内,如果想展现的更好还应该根据区域做判断。因此如果使用彩色图片做蒙板,最好这个图片的白色和彩色对比明显且边缘区域不要模糊(不用用带边缘有阴影的图)
3. 实际应用中,蒙板不要太复杂一定要简单,因为展示词云不会展示到细节,也就是大轮廓能看清楚。一般场景中不用描绘轮廓边缘(主要是描绘出来很丑……)


4.6 颜色随mask改变
同样使用mask,但是与4.5不同的是字体颜色随mask颜色变化
py_mask = np.array(Image.open('tree.jpg'))
wc = WordCloud(mask=py_mask,repeat=True,background_color='white')
image_colors = ImageColorGenerator(py_mask)
wc.generate_from_text(text)
wc.recolor(color_func=image_colors)


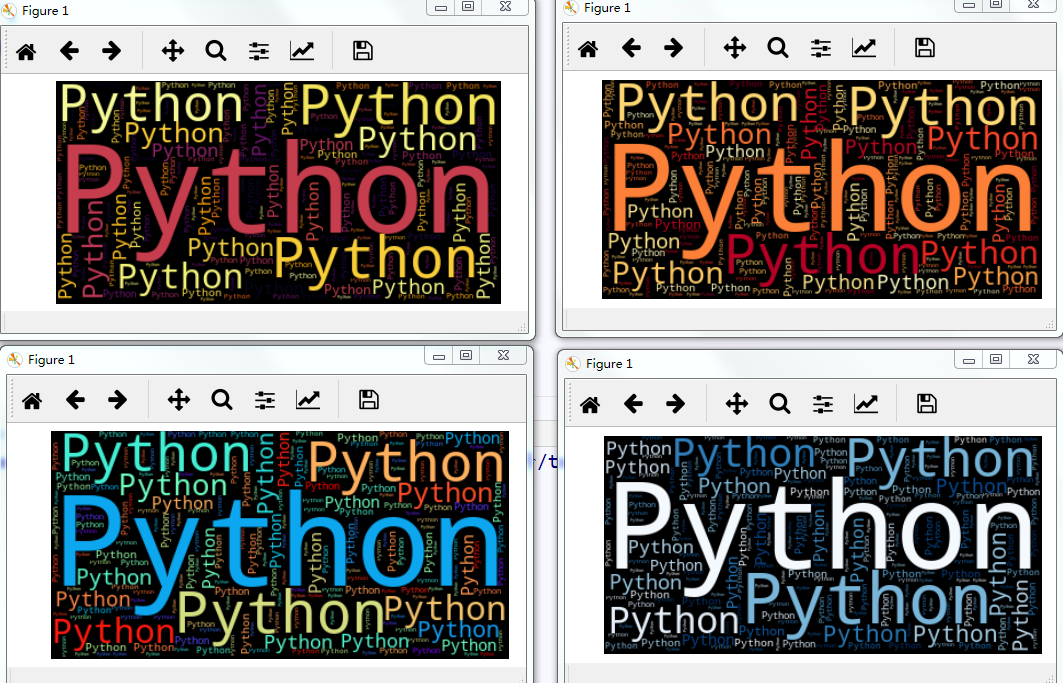
4.7 字体主题
默认的字体主题颜色是viridis(翠绿色),更改参数colormap的值即可改变主题颜色,colormap颜色表可参考:
https://blog.csdn.net/Mr_Cat123/article/details/78638491
wc = WordCloud(repeat=True,colormap='inferno')
下面是任选的四种主题颜色
4.8 根据频率生成
顾名思义,词云显示的单词大小与其出现的频率成正比。因此,需要使用process_text()方法统计各个单词出现的频率,返回的是字典格式
然后词云生成方法使用generate_from_frequencies()或者fit_words(),参数格式是字典(列表或者其他形式不行)
process_word = WordCloud.process_text(wc, text)#已过滤掉STOPWORDS
wc.generate_from_frequencies(process_word)
例如本例中使用的文章经过process_text()可得出其单词和出现的频率:
{'boy': 8, 'practise': 1, 'perseverance': 2, 'often': 4, 'never': 3, 'give': 2, 'thing': 2, 'hard': 3, 'inconvenient': 1, 'want': 1, 'light': 1, 'must': 1, 'conquer': 2, 'darkness': 1, 'sometimes': 1, 'equal': 1, 'genius': 1, 'results': 1, 'two': 2, 'creatures': 1, 'proverb': 1, 'surmount': 1, 'pyramids': 1, 'eagle': 1, 'snail': 1, 'school': 2, 'habit': 3, 'attention': 4, 'let': 1, 'nothing': 3, 'come': 2, 'subject': 1, 'hand': 1, 'remember': 2, 'good': 1, 'skater': 1, 'tries': 1, 'skate': 1, 'directions': 1, 'part': 1, 'life': 6, 'begin': 1, 'early': 3, 'enough': 1, 'hear': 1, 'grown': 1, 'people': 1, 'say': 4, 'fix': 1, 'lecture': 1, 'book': 1, 'although': 1, 'wished': 1, 'reason': 1, 'formed': 1, 'youth': 1, 'live': 1, 'pay': 1, 'cultivation': 2, 'memory': 2, 'strengthen': 1, 'faculty': 1, 'every': 2, 'possible': 2, 'means': 1, 'occasion': 1, 'takes': 1, 'little': 3, 'work': 1, 'first': 1, 'accurately': 1, 'soon': 1, 'helps': 1, 'trouble': 2, 'needs': 1, 'become': 2, 'power': 1, 'cultivate': 1, 'courage': 2, 'mild': 1, 'gentle': 1, 'cruel': 1, 'pitiless': 1, 'cowardice': 1, 'wise': 1, 'author': 1, 'borrow': 1, 'anticipate': 1, 'may': 1, 'appear': 1, 'fear': 2, 'ill': 2, 'exceeds': 1, 'Dangers': 1, 'will': 3, 'arise': 1, 'career': 1, 'presence': 1, 'mind': 1, 'worst': 1, 'prepared': 1, 'fate': 1, 'harm': 1, 'feared': 1, 'look': 3, 'cheerful': 1, 'side': 1, 'much': 1, 'mirror': 1, 'smile': 2, 'upon': 2, 'back': 1, 'frown': 1, 'doubtful': 1, 'similar': 1, 'return': 1, 'Inner': 1, 'sunshine': 1, 'warms': 1, 'heart': 1, 'owner': 1, 'contact': 1, 'love': 2, 'turn': 1, 'shut': 2, 'oftener': 1, 'might': 1, 'write': 1, 'pages': 1, 'importance': 1, 'learning': 1, 'gain': 1, 'point': 1, 'young': 1, 'stand': 1, 'erect': 1, 'decline': 1, 'unworthy': 2, 'act': 1, 'demand': 1, 'courtesy': 1, 'towards': 2, 'companions': 1, 'friends': 1, 'indeed': 1, 'strangers': 1, 'well': 1, 'smallest': 1, 'courtesies': 1, 'along': 1, 'rough': 1, 'roads': 1, 'birds': 1, 'sing': 1, 'us': 1, 'winter': 1, 'long': 1, 'make': 2, 'season': 1, 'ice': 1, 'snow': 1, 'endurable': 1, 'Finally': 1, 'instead': 1, 'trying': 1, 'happy': 2, 'sole': 1, 'purpose': 1, 'try': 1, 'still': 1, 'harder': 1, 'others': 1}
显示结果:

可以看出来,单词boy、life、often出现的频率较高,因此也显示的字体较大。如果在wordcloud()方法中指定了max_words的数量,则显示结果根据频率从大到小排列筛选显示
例如设定max_words=20

由于字典是无序的,因此我们更希望结果是能按照一定的顺序排列的,因此这里可以做一下排序处理
sorted_words = sorted(dict_words.items(), key=operator.itemgetter(1), reverse=True)#按照词频降序处理,返回列表格式
在返回的列表中可以截取top10、去除某些不想要的单词等等,例如我这里截取了top20
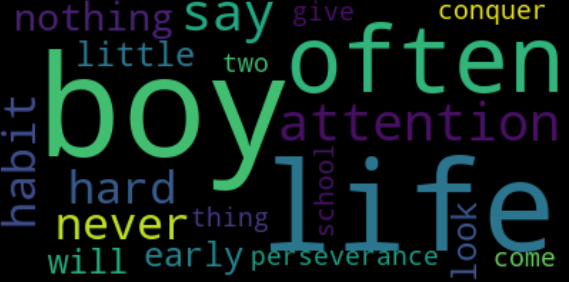
可以看出来,与直接设定显示单词数量的结果是一样的。但是这种方法更加灵活、直观
4.9 中文
跟英文单词不同的是,中文最小单位是“字”而不是单词,因此需要一定的算法将一段文本单词筛选出来
这里选用第三方库“jieba”,俗称结巴分词。当然,机器判断分词标准还是存在一定的误差,本文不具体详解结巴分词的用法
wordlist_after_jieba = jieba.cut(text, cut_all = False)
wl_space_split = " ".join(wordlist_after_jieba)
wc = WordCloud(font_path ='HYHeiFangW.ttf',background_color='white')
process_word = WordCloud.process_text(wc, wl_space_split)
本例选用2019年两会政府工作报告全文,提取前50个关键词
根据统计结果:
[('发展', 112), ('改革', 67), ('加强', 62), ('建设', 56), ('推进', 51), ('加快', 43), ('创新', 41), ('经济', 40), ('企业', 40), ('支持', 40), ('推动', 40), ('政策', 38), ('促进', 35), ('深化', 34), ('坚持', 33), ('服务', 31), ('就业', 29), ('继续', 27), ('提高', 27), ('我们', 27), ('社会', 27), ('全面', 26), ('市场', 24), ('实施', 23), ('保障', 23), ('增长', 22), ('基本', 22), ('机制', 22), ('中国', 21), ('加大', 21), ('今年', 21), ('持续', 20), ('完善', 20), ('改革 完善', 20), ('优化', 19), ('扩大', 19), ('问题', 19), ('投资', 19), ('健全', 19), ('落实', 19), ('坚决', 19), ('保持', 18), ('稳定', 18), ('制度', 18), ('国际', 18), ('体系', 18), ('教育', 18), ('工作', 17), ('我国', 17), ('提升', 17)]

发展才是硬道理,有木有!
tips:
1. 在有中文显示的情况下,必须添加字体路径,否则显示错误
2. 很多文章中指出process_word()只屏蔽了英文的停止词,但是根据我测试结果来看,中文的一些词例如“的、了、之”等等
4.10 停止词
对于英文的STOPWORDS作者已经在内部设置了一部分,如果想添加一些自定义的单词(在不多的情况下),可以使用在STOPWORDS后面追加单词的形式
例如我想把单词“came”屏蔽掉
stopwords = set(STOPWORDS)
stopwords.add('came')
wc = WordCloud(stopwords=stopwords)

如果是中文,可以从网上直接下载