需求:爬取豆瓣电影top250的排名、电影名称、评分、评论人数和一句话影评
环境:python3.6.5
准备工作:
豆瓣电影top250(第1页)网址:https://movie.douban.com/top250?start=0 或者 https://movie.douban.com/top250
每页展示25个电影,一共10张翻页
第2页:https://movie.douban.com/top250?start=25&filter=
第3页:https://movie.douban.com/top250?start=50&filter=
……
最后一页:https://movie.douban.com/top250?start=225&filter=
由此可见,除了首页代码其他9页(相对首页增加了一些字符串)以25递增
查看每页的html代码:
在浏览器空白区域点击“查看源代码”(不同的浏览器可能起的名字不一样),找到所需要的内容。
快速定位html有效信息的方法:
例如排名第一的电影是《肖申克的救赎》,在html源码中搜索(ctrl+F)这个名字(不要加书名号),快速定位大致位置,如下图
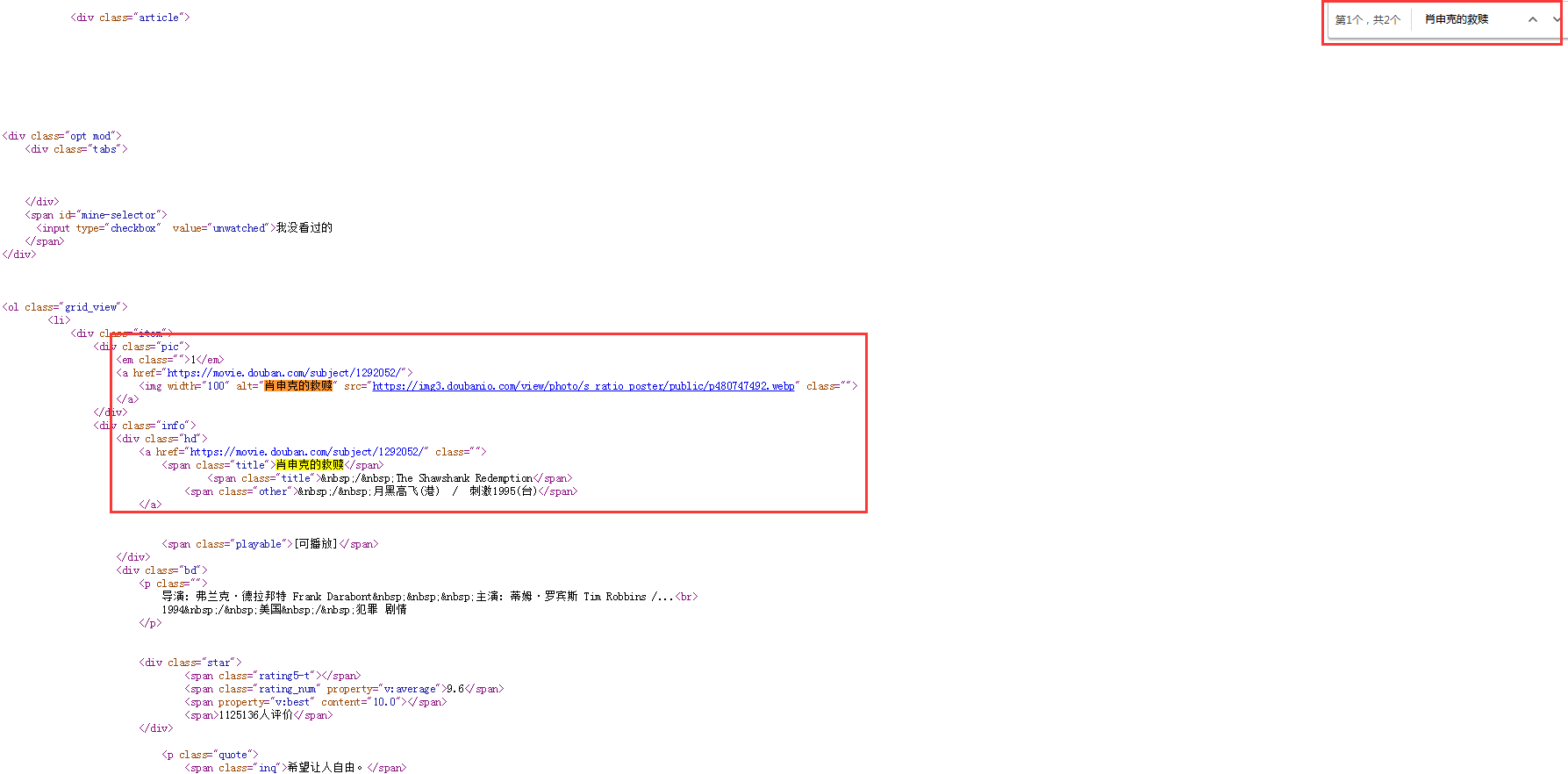
仔细研究html代码:
所有影片存放在ol列表中,每一部影片在一个li中,需要提取的信息在不同的标签中,如下图所示

代码逻辑为:查找ol→li→各个标签
需要用到的第三方库:
from bs4 import BeautifulSoup as bs from urllib import request
读取html源码(以首页为例)
1 h="https://movie.douban.com/top250" 2 resp = request.urlopen(h) 3 html_data = resp.read().decode('utf-8') 4 soup = bs(html_data,'lxml') 5 #print(soup.prettify())
第5行的soup.prettify()输出的比较好看,但是有可能更改一些并列标签的前后位置,用这个输出只是看起来更人性化一些
查找ol标签,获取本页面上25部电影
通过class名称,因为这个class是唯一命名的,因此无需find_all,只需要find(这个是查找第一个)
1 movieList = soup.find('ol',attrs={'class':"grid_view"})
在ol内查找li标签,无class和id,只需标签名即可
1 movie = movieList.find_all('li')#获取每一个li(每个li是一个电影),以数组方式
返回结果是一位数组,每个元素是li标签
在每一个li标签内提取有用信息
1 for i in range(0,25): 2 name = movie[i].find('span',class_="title").string#获得影片名称 3 score = movie[i].find('span',class_="rating_num").string#获得影片评分 4 num = movie[i].find('div',class_="star").find_all('span')[-1].string.strip('人评价')#获得影片评价人数 5 quote = movie[i].find('span',class_="inq")#获得影片短评
.string和get_text()在本代码中显示结果一样(有些代码中返回显示也是不同的),但是返回类型不同
注意第4行获取评价人数时,span标签内无class和id等,只能先把div中所有的信息提取(返回结果是一位数组),人数在数组中最后一个,通过数组方法[-1]提取这个标签,通过string提取标签内内容,再用strip字符串方法去掉“人评价”这几个字
还有一点需要注意是,有几部影片是没有短评的(通过运行程序的结果才能看到,返回的是None),如果需要显示的更加人性化一些,添加以下语句:
1 if quote is None: 2 quote = "暂无" 3 else: 4 quote = quote.string
查找所有信息:不要想着把10页的html先拼接成一个html处理,这样的的html进行soup时只能提取到第一个<html>标签内的,也就是说只能查到第一页的信息。因此总体思路还是遍历每一页的电影信息,然后将结果拼接成数组。如果只是print出来或者逐行写入歧途文件的话无需整合所有影片
写入txt文件,提取出的结果是二维数组
1 #将数组movieData250写入文件txt 2 import codecs 3 s ="—————————豆瓣电影top250—————————— " 4 f = codecs.open("豆瓣电影top250.txt",'w','utf-8') 5 f.write(s) 6 7 for i in movieData250: 8 f.write(str(i)+' ') # 为换行符 9 f.close()
源代码:
1 #豆瓣电影前250信息,写入txt文件 2 3 from bs4 import BeautifulSoup as bs 4 from urllib import request 5 k = 0 6 n = 1 7 movieData250 = [] 8 9 #读取每一个网页25个电影信息 10 def info25(): 11 movieData = [] 12 for i in range(0,25): 13 name = movie[i].find('span',class_="title").string#获得影片名称 14 score = movie[i].find('span',class_="rating_num").string#获得影片评分 15 num = movie[i].find('div',class_="star").find_all('span')[-1].string.strip('人评价')#获得影片评价人数 16 quote = movie[i].find('span',class_="inq")#获得影片短评 17 if quote is None: 18 quote = "暂无" 19 else: 20 quote = quote.string 21 #movieData[i] = [i+1,name,score,num,quote] 22 movieData.append([i+1+k,name,score,num,quote]) 23 #print(movieData) 24 return movieData 25 #movieData250 = movieData250 + movieData 26 27 28 29 while(k == 0): 30 h="https://movie.douban.com/top250" 31 resp = request.urlopen(h) 32 html_data = resp.read().decode('utf-8') 33 soup = bs(html_data,'lxml') 34 #print(soup.prettify()) 35 #movieList=soup.find('ol')#寻找第一个ol标签,得到所有电影 36 #movieList=soup.find('ol',class_="grid_view")#以下两种方法均可 37 movieList = soup.find('ol',attrs={'class':"grid_view"}) 38 movie = movieList.find_all('li')#获取每一个li(每个li是一个电影),以数组方式 39 movieData250 +=info25() 40 k += 25 41 42 while(k<250): 43 44 h = "https://movie.douban.com/top250?start=" + str(k) + "&filter=" 45 resp=request.urlopen(h) 46 html_data=resp.read().decode('utf-8') 47 soup=bs(html_data,'lxml') 48 #print(soup.prettify()) 49 #movieList=soup.find('ol')#寻找第一个ol标签,得到所有电影 50 #movieList=soup.find('ol',class_="grid_view")#以下两种方法均可 51 movieList=soup.find('ol',attrs={'class':"grid_view"}) 52 movie=movieList.find_all('li')#获取每一个li(每个li是一个电影),以数组方式 53 movieData250 += info25() 54 k+=25 55 56 print(movieData250) 57 58 59 #将数组movieData250写入文件txt 60 import codecs 61 s ="—————————豆瓣电影top250—————————— " 62 f = codecs.open("豆瓣电影top250.txt",'w','utf-8') 63 f.write(s) 64 65 for i in movieData250: 66 f.write(str(i)+' ') # 为换行符 67 f.close()
输出的txt:

显示结果不是很友好~~~