性能调优在整个工程中是非常重要的,也是非常有必要的。但有的时候我们往往都不知道如何对性能进行调优。其实性能调优主要分两个方面:一方面是硬件调优,一方面是软件调优。本章主要是介绍Kettle的性能优化及效率提升。
一、Kettle调优
1、 调整JVM大小进行性能优化,修改Kettle定时任务中的Kitchen或Pan或Spoon脚本。
修改脚本代码片段
set OPT=-Xmx512m -cp %CLASSPATH% -Djava.library.path=libswtwin32 -DKETTLE_HOME="%KETTLE_HOME%" -DKETTLE_REPOSITORY="%KETTLE_REPOSITORY%" -DKETTLE_USER="%KETTLE_USER%" -DKETTLE_PASSWORD="%KETTLE_PASSWORD%" -DKETTLE_PLUGIN_PACKAGES="%KETTLE_PLUGIN_PACKAGES%" -DKETTLE_LOG_SIZE_LIMIT="%KETTLE_LOG_SIZE_LIMIT%"
参数参考:
-Xmx1024m:设置JVM最大可用内存为1024M。
-Xms512m:设置JVM促使内存为512m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
样例:OPT=-Xmx1024m -Xms512m
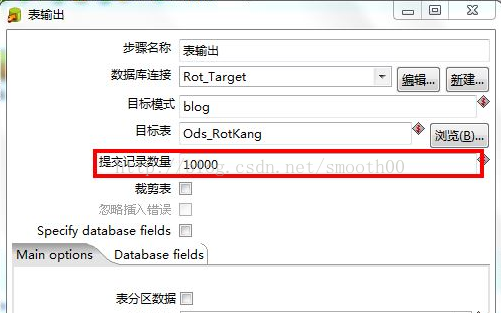
2、 调整提交(Commit)记录数大小进行优化
如修改RotKang_Test01中的“表输出”组件中的“提交记录数量”参数进行优化,Kettle默认Commit数量为:1000,可以根据数据量大小来设置Commitsize:1000~50000。
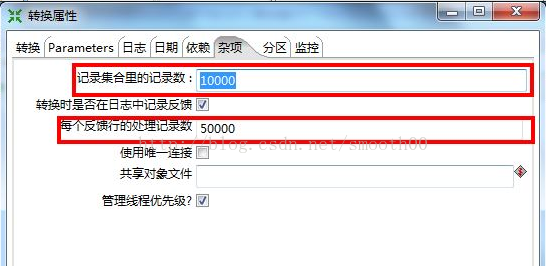
3、 调整记录集合里的记录数
4、尽量使用数据库连接池;
5、尽量提高批处理的commit size;
6、尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流);
7、Kettle是Java做的,尽量用大一点的内存参数启动Kettle;
8、可以使用sql来做的一些操作尽量用sql;
Group , merge , stream lookup,split field这些操作都是比较慢的,想办法避免他们.,能用sql就用sql;
9、插入大量数据的时候尽量把索引删掉;
10、尽量避免使用update , delete操作,尤其是update,如果可以把update变成先delete, 后insert;
11、能使用truncate table的时候,就不要使用deleteall row这种类似sql合理的分区,如果删除操作是基于某一个分区的,就不要使用delete row这种方式(不管是deletesql还是delete步骤),直接把分区drop掉,再重新创建;
12、尽量缩小输入的数据集的大小(增量更新也是为了这个目的);
13、尽量使用数据库原生的方式装载文本文件(Oracle的sqlloader, mysql的bulk loader步骤);
14、尽量不要用kettle的calculate计算步骤,能用数据库本身的sql就用sql ,不能用sql就尽量想办法用procedure,实在不行才是calculate步骤;
15、要知道你的性能瓶颈在哪,可能有时候你使用了不恰当的方式,导致整个操作都变慢,观察kettle log生成的方式来了解你的ETL操作最慢的地方;
16、远程数据库用文件+FTP的方式来传数据,文件要压缩。(只要不是局域网都可以认为是远程连接)。
二、索引的正确使用
在ETL过程中的索引需要遵循以下使用原则:
1、当插入的数据为数据表中的记录数量10%以上时,首先需要删除该表的索引来提高数据的插入效率,当数据全部插入后再建立索引。
2、避免在索引列上使用函数或计算,在where子句中,如果索引列是函数的一部分,优化器将不使用索引而使用全表扫描。
3、避免在索引列上使用 NOT和 “!=”,索引只能告诉什么存在于表中,而不能告诉什么不存在于表中,当数据库遇到NOT和 “!=”时,就会停止使用索引转而执行全表扫描。
4、索引列上用 >=替代 >
高效:select * from temp where deptno>=4
低效:select * from temp where deptno>3
两者的区别在于,前者DBMS将直接跳到第一个DEPT等于4的记录而后者将首先定位到DEPTNO=3的记录并且向前扫描到第一个DEPT大于3的记录。
三、数据抽取的SQL优化
1、Where子句中的连接顺序。
2、删除全表是用TRUNCATE替代DELETE。
3、尽量多使用COMMIT。
4、用EXISTS替代IN。
5、用NOT EXISTS替代NOT IN。
6、优化GROUP BY。
7、有条件的使用UNION-ALL替换UNION。
8、分离表和索引。