简述
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。由于spark带有Python的API,而本人比较专于Python语言。因此在此分享一下我在配置spark的方法以及心得。
配置过程
步骤一:
下载scala压缩包,进入链接http://www.scala-lang.org/,点击download下载scala,并解压到当前目录下。
下载jdk压缩包,进入链接http://www.oracle.com/technetwork/java/javase/downloads/index.html,下载最新版jdk,若为64位系统请下载jdk-8u91-linux-x64.tar.gz(本人下载版本为8u91,系统为64位),32位系统下载jdk-8u91-linux-i586.tar.gz,下载完成后解压到当前目录下。
下载spark压缩包,进入链接https://spark.apache.org/downloads.html,选择当前最新版本人为1.6.2,点击下载。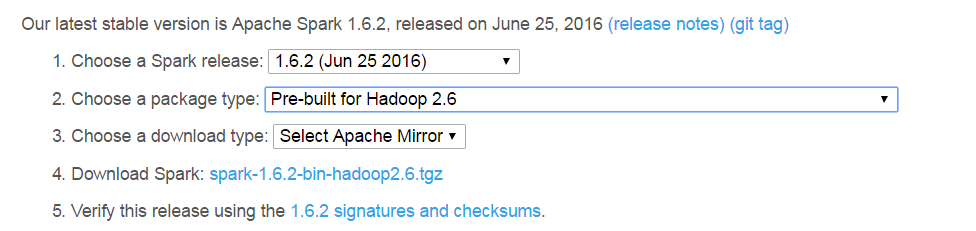
步骤二:
1.打开命令行窗口。
2.执行命令 sudo -i
3.进入到解压文件所在目录
4.将j解压文件转移到opt目录下
执行 mv jdk1.8.0_91 /opt/jdk1.8.0_91
执行 mv scala-2.11.8 /opt/scala-2.11.8
执行 mv spark-1.6.2-bin-hadoop2.6 /opt/spark-hadoop
步骤三:
配置环境变量,编辑/etc/profile,执行以下命令
sudo gedit /etc/profile
在文件最下方增加(注意版本):
#Seeting JDK JDK环境变量
export JAVA_HOME=/opt/jdk1.8.0_91
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH
#Seeting Scala Scala环境变量
export SCALA_HOME=/opt/scala-2.11.8
export PATH=${SCALA_HOME}/bin:$PATH
#setting Spark Spark环境变量
export SPARK_HOME=/opt/spark-hadoop/
#PythonPath 将Spark中的pySpark模块增加的Python环境中
export PYTHONPATH=/opt/spark-hadoop/python
保存文件, 重启电脑,使/etc/profile永久生效,临时生效,打开命令窗口,执行 source /etc/profile 在当前窗口生效
步骤四:
测试安装结果
打开命令窗口,切换到Spark根目录

执行 ./bin/spark-shell,打开Scala到Spark的连接窗口
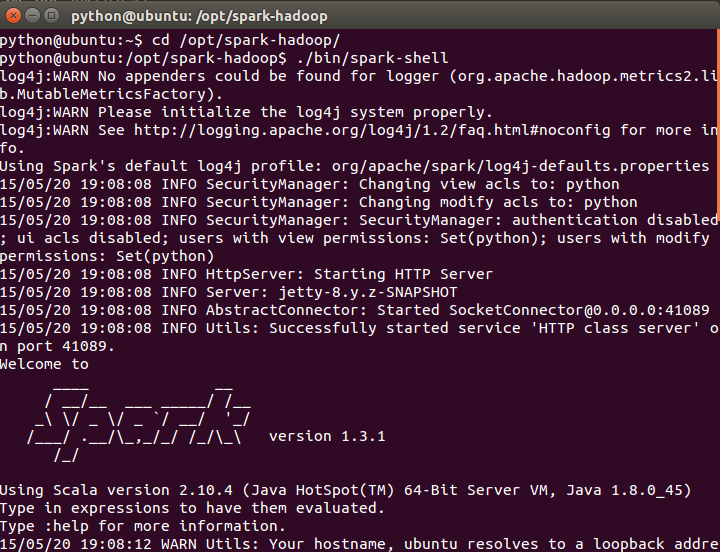
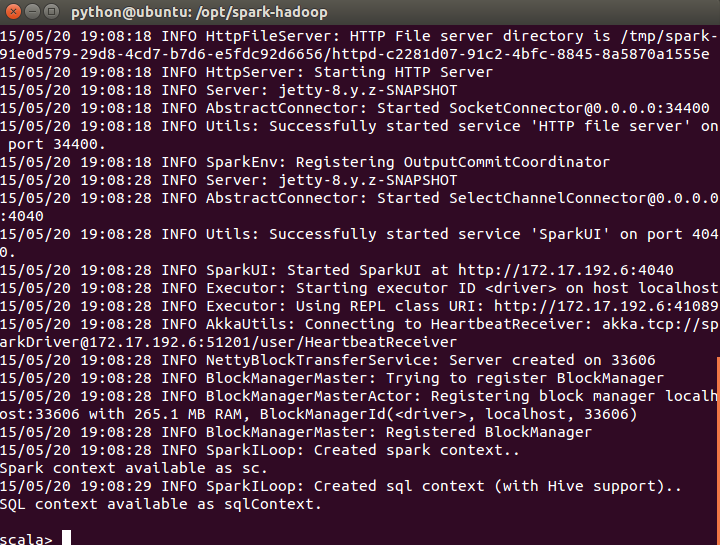
执行结果如上,则无误
执行./bin/pyspark ,打开Python到Spark的连接窗口
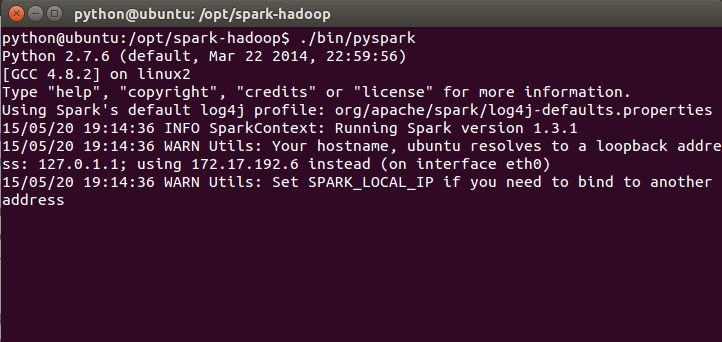

则安装无误
-
Python安发Spark应用
-
前面已设置PYTHONPATH,将pyspark加入到Python的搜寻路径中
-
打开Spark安装目录(/opt/spark-hadoop),在/opt/spark-hadoop/Python/lib文件夹下解压py4j,并复至到/opt/spark-hadoop/Python目录下。
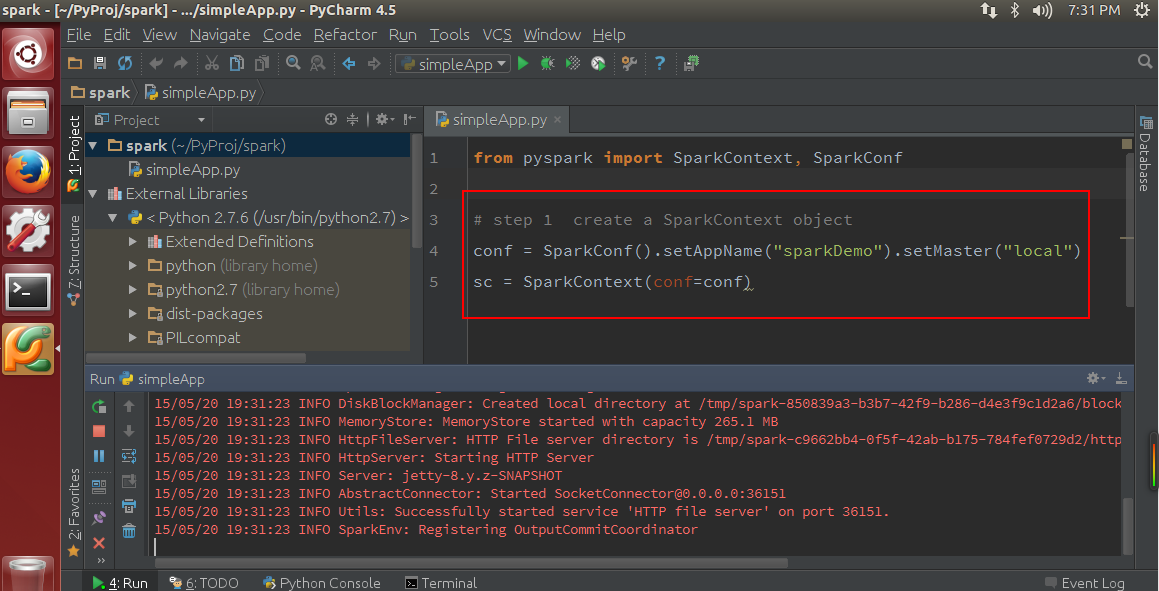
在pycharm中测试,出现如下红色字眼,则配置成功。
参考至:http://www.open-open.com/lib/view/open1432192407317.html