最近想爬点啥东西看看,
所以接着学习了一点Scrapy,
学习过程中就试着去爬取Scrapy的官方文档作为练习之用,
现在已经基本完成了。
实现原理:
以 overview.html 为起点,通过 response.selector.xpath 获取到 next page路径下载到本地。
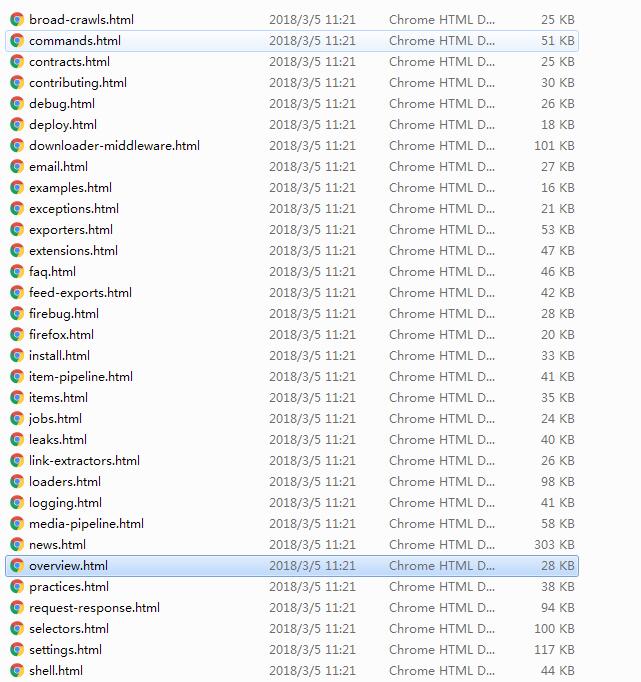
最终的结果是下载了一份完成的Scrapy的官方离线文档,
因为页面之间采用的是相对路径。
完整代码如下:
import scrapy,os
class ScrapyDocSpider(scrapy.Spider):
name = "scrapy_doc"
urls = []
inited = False
def start_requests(self):
if not os.path.exists(self.name):
os.makedirs(self.name)
self.rootPage = ""
yield scrapy.Request(url="https://doc.scrapy.org/en/1.5/intro/overview.html", callback=self.parse)
def parse(self, response):
self.log("LOADED:"+response.url)
last_index = len(response.url) - response.url[::-1].index("/")
self.rootPage = response.url[:last_index]
page = response.url.split("/")[-1]
filename = self.name+"/"+page
# self.log("parseSubPage:"+filename)
with open(filename, "wb") as f:
f.write(response.body)
f.close()
self.log("Save file %s" % filename)
pages = response.selector.xpath('//div/section/div/div/footer/div/a[@rel="next"]/@href').extract()
if len(pages) != 0 :
next_page = str(pages[0])
self.log("ROOT PAGE")
self.log(self.rootPage)
self.log(next_page)
self.log(type(next_page))
if next_page.startswith(".") or next_page.startswith("/") :
next_page = self.rootPage+next_page
yield response.follow(url=next_page,callback=self.parse,errback=self.errcallback)
def errcallback(self, failure):
self.logger.error(failure)
爬取到的结果如下: