什么是对象池技术?对象池应用在哪些地方?
对象池其实就是缓存一些对象从而避免大量创建同一个类型的对象,类似线程池的概念。对象池缓存了一些已经创建好的对象,避免需要时才创建对象,同时限制了实例的个数。池化技术最终要的就是重复的使用池内已经创建的对象。从上面的内容就可以看出对象池适用于以下几个场景:
- 创建对象的开销大
- 会创建大量的实例
- 限制一些资源的使用
如果创建一个对象的开销特别大,那么提前创建一些可以使用的并且缓存起来(池化技术就是重复使用对象,提前创建并缓存起来重复使用就是池化)可以降低创建对象时的开销。
会大量创建实例的场景,重复的使用对象可减少创建的对象数量,降低GC的压力(如果这些对象的生命周期都很短暂,那么可以降低YoungGC的频率;如果生命周期很长,那么可以避免掉这些对象被FullGC——生命周期长,且大量创建,这里就要结合系统的TPS等考虑池的大小了)。
对于限制资源的使用更多的是一种保护策略,比如数据库链接池。除去这些对象本身的开销外,他们对外部系统也会造成压力,比如大量创建链接对DB也是有压力的。那么池化除了优化资源以外,本身限制了资源数,对外部系统也起到了一层保护作用。
如何实现对象池?
开源实现:Apache Commons Pool
自己实现:Netty轻量级对象池实现
Apache Commons Pool开源软件库提供了一个对象池API和一系列对象池的实现,支持各种配置,比如活跃对象数或者闲置对象个数等。DBCP数据库连接池基于Apache Commons Pool实现。
Netty自己实现了一套轻量级的对象池。在Netty中,通常会有多个IO线程独立工作,基于NioEventLoop的实现,每个IO线程轮询单独的Selector实例来检索IO事件,并在IO来临时开始处理。最常见的IO操作就是读写,具体到NIO就是从内核缓冲区拷贝数据到用户缓冲区或者从用户缓冲区拷贝数据到内核缓冲区。这里会涉及到大量的创建和回收Buffer,Netty对Buffer进行了池化从而降低系统开销。
Netty对象池实现分析
上面提到了IO操作中会涉及到大量的缓冲区操作,NIO提供了两种Buffer最为缓冲区:DirectByteBuffer和HeapByteBuffer。Netty在两种缓冲区的基础上进行了池化进而提升性能。
DirectByteBuffer
DirectByteBuffer顾名思义是直接内存(Direct Memory)上的Byte缓存区,直接内存不是JVM Runtime数据区域的一部分,也不是Java虚拟机规范中定义的内存区域。简单的说这部分就是机器内存,分配的大小等都和虚拟机限制无关。JDK1.4中开始我们可以使用native方法在直接内存上来分配内存,并在JVM堆内存上维持一个引用来进行访问,当JVM堆内存上的引用被回收后,这块内存被操作系统回收。
HeapByteBuffer
HeapByteBuffer是在JVM堆内存上分配的Byte缓冲区,可以简单的理解为byte[]数组的一种封装。基于HeapByteBuffer的写流程通常要先在直接内存上分配一个临时的缓冲区,将数据从Heap拷贝到直接内存,然后再将直接内存的数据发送到IO设备的缓冲区,之后回收直接内存。读流程也类似。使用DirectByteBuffer避免了不必要的拷贝工作,所以在性能上会有提升。
DirectByteBuffer的缺点在于分配和回收的的代价相对较大,因此DirectByteBuffer适用于缓冲区可以重复使用的场景。
Netty的池化实现
以Buffer为例,对应直接内存和堆内存,Netty的池化分别为PooledDirectByteBuffer和PolledHeapByteBuffer。

通过PooledDirectByteBuffer的API定义可以看到,它的构造方法是私有的,而创建一个实例的入口是:

1 static PooledDirectByteBuf newInstance(int maxCapacity) {
2
3 PooledDirectByteBuf buf = RECYCLER.get();
4
5 buf.reuse(maxCapacity);
6
7 return buf;
8
9 }
可见RECYCLER是池化的核心,创建对象时都通过RECYCLER.get来获得一个实例(Recycler就是Netty实轻量级池化技术的核心)。
Recycler实现分析(源码分析)
1 /** 2 3 * Light-weight object pool based on a thread-local stack. 4 5 * 6 7 * @param <T> the type of the pooled object 8 9 */ 10 11 public abstract class Recycler<T>
从注释可以看出Netty基于thread-local实现了轻量级的对象池。

Recycler的API非常简单:
get():获取一个实例
recycle(T, Handle<T>):回收一个实例
newObject(Handle<T>):创建一个实例
get流程
1 public final T get() {
2
3 if (maxCapacity == 0) {
4
5 return newObject((Handle<T>) NOOP_HANDLE);
6
7 }
8
9 Stack<T> stack = threadLocal.get();
10
11 DefaultHandle<T> handle = stack.pop();
12
13 if (handle == null) {
14
15 handle = stack.newHandle();
16
17 handle.value = newObject(handle);
18
19 }
20
21 return (T) handle.value;
22
23 }
get的简化流程(这里先不深究细节):
- 拿到当前线程对应的stack
- 从stack中pop出一个元素
- 如果不为空则返回,否则创建一个新的实例
可以大概明白Stack是对象池化背后存储实例的数据结构:如果能从stack中拿到可用的实例就不再创建新的实例。
recycle流程
一个“池子”最核心的就是做两件事情,第一个是上面的Get,即从池子中拿出一个可用的实例。另一个就是在用完后将数据放回到池子中(线程池、连接池都是这样)。
1 public final boolean recycle(T o, Handle<T> handle) {
2
3 if (handle == NOOP_HANDLE) {
4
5 return false;
6
7 }
8
9
10
11 DefaultHandle<T> h = (DefaultHandle<T>) handle;
12
13 if (h.stack.parent != this) {
14
15 return false;
16
17 }
18
19
20
21 h.recycle(o);
22
23 return true;
24
25 }
26
27
28
29 ----------------------------------------------------------------------------------------
30
31 public void recycle(Object object) {
32
33 if (object != value) {
34
35 throw new IllegalArgumentException("object does not belong to handle");
36
37 }
38
39 Thread thread = Thread.currentThread();
40
41 if (thread == stack.thread) {
42
43 stack.push(this);
44
45 return;
46
47 }
48
49 // we don't want to have a ref to the queue as the value in our weak map
50
51 // so we null it out; to ensure there are no races with restoring it later
52
53 // we impose a memory ordering here (no-op on x86)
54
55 Map<Stack<?>, WeakOrderQueue> delayedRecycled = DELAYED_RECYCLED.get();
56
57 WeakOrderQueue queue = delayedRecycled.get(stack);
58
59 if (queue == null) {
60
61 delayedRecycled.put(stack, queue = new WeakOrderQueue(stack, thread));
62
63 }
64
65 queue.add(this);
66
67 }
回收一个实例核心的步骤由以上两个方法组成:Recycler的recycle方法和DefaultHandle的recycle方法。
Recycler的recycle方法主要做了一些参数验证。
DefaultHandle的recycle方法流程如下:
- 如果当前线程是当前stack对象的线程,那么将实例放入stack中,否则:
- 获取当前线程对应的Map<Stack, WeakOrderQueue>,并将实例加入到Stack对应的Queue中。
从获取实例和回收实例的代码可以看出,整个对象池的核心实现由ThreadLocal和Stack及WrakOrderQueue构成,接着来看Stack和WrakOrderQueue的具体实现,最后概括整体实现。
Stack实体
Stack<T>
parent:Recycler // 关联对应的Recycler
thread:Thread // 对应的Thread
elements:DefaultHandle<?>[] // 存储DefaultHandle的数组
head:WeakOrderQueue // 指向WeakOrderQueue元素组成的链表的头部“指针”
cursor,prev:WrakOrderQueue // 当前游标和前一元素的“指针”
pop实现
1 DefaultHandle<T> pop() {
2
3 int size = this.size;
4
5 if (size == 0) {
6
7 if (!scavenge()) {
8
9 return null;
10
11 }
12
13 size = this.size;
14
15 }
16
17 size --;
18
19 DefaultHandle ret = elements[size];
20
21 if (ret.lastRecycledId != ret.recycleId) {
22
23 throw new IllegalStateException("recycled multiple times");
24
25 }
26
27 ret.recycleId = 0;
28
29 ret.lastRecycledId = 0;
30
31 this.size = size;
32
33 return ret;
34
35 }
- 如果size为0(这里的size表示stack中可用的元素),尝试进行scavenge。
- 返回elements中的最后一个元素。
1 boolean scavenge() {
2 // continue an existing scavenge, if any
3 if (scavengeSome()) {
4 return true;
5 }
6
7 // reset our scavenge cursor
8 prev = null;
9 cursor = head;
10 return false;
11 }
12
13 boolean scavengeSome() {
14 WeakOrderQueue cursor = this.cursor;
15 if (cursor == null) {
16 cursor = head;
17 if (cursor == null) {
18 return false;
19 }
20 }
21
22 boolean success = false;
23 WeakOrderQueue prev = this.prev;
24 do {
25 if (cursor.transfer(this)) {
26 success = true;
27 break;
28 }
29
30 WeakOrderQueue next = cursor.next;
31 if (cursor.owner.get() == null) {
32 // If the thread associated with the queue is gone, unlink it, after
33 // performing a volatile read to confirm there is no data left to collect.
34 // We never unlink the first queue, as we don't want to synchronize on updating the head.
35 if (cursor.hasFinalData()) {
36 for (;;) {
37 if (cursor.transfer(this)) {
38 success = true;
39 } else {
40 break;
41 }
42 }
43 }
44 if (prev != null) {
45 prev.next = next;
46 }
47 } else {
48 prev = cursor;
49 }
50
51 cursor = next;
52
53 } while (cursor != null && !success);
54
55 this.prev = prev;
56 this.cursor = cursor;
57 return success;
58 }
简要概括上面的流程就是Stack从“背后”的Queue中获取可用的实例,如果Queue中没有可用实例就遍历到下一个Queue(Queue组成了一个链表)。
push实现
1 void push(DefaultHandle<?> item) {
2 if ((item.recycleId | item.lastRecycledId) != 0) {
3 throw new IllegalStateException("recycled already");
4 }
5 item.recycleId = item.lastRecycledId = OWN_THREAD_ID;
6
7 int size = this.size;
8 if (size >= maxCapacity) {
9 // Hit the maximum capacity - drop the possibly youngest object.
10 return;
11 }
12 if (size == elements.length) {
13 elements = Arrays.copyOf(elements, Math.min(size << 1, maxCapacity));
14 }
15
16 elements[size] = item;
17 this.size = size + 1;
18 }
push相对pop流程要更加简单,直接将回收的元素放到队尾(实际是一个数组)。
WeakOrderQueue实体
WeakOrderQueue
head,tail:Link // 内部元素的指针(WeakOrderQueue内部存储的是一个Link的链表)
next:WeakOrderQueue // 指向下一个WeakOrderQueue的指针
owner:Thread // 对应的线程
WeakOrderQueue核心包含两个方法,add方法将元素添加到自身的“队列”中,transfer方法将自己拥有的元素“传输”到Stack中。
Linke结构如下
1 private static final class Link extends AtomicInteger {
2 private final DefaultHandle<?>[] elements = new DefaultHandle[LINK_CAPACITY];
3
4 private int readIndex;
5 private Link next;
6 }
Link内部包含了一个数组用于存放实例,同时标记了读取位置的索引和下一个Link元素的指针。
结合Link的结构,Weak的结构如下:
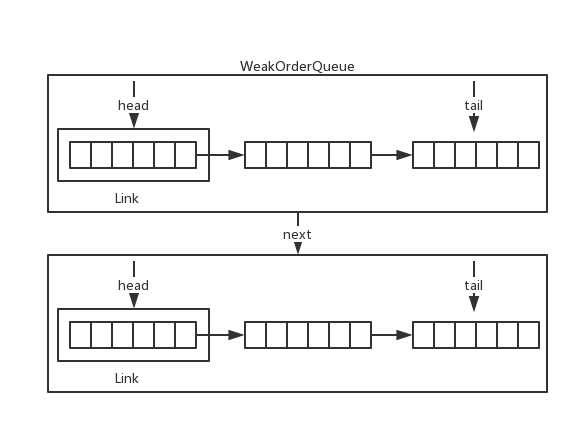
add方法
1 void add(DefaultHandle<?> handle) {
2
3 handle.lastRecycledId = id;
4
5
6
7 Link tail = this.tail;
8
9 int writeIndex;
10
11 if ((writeIndex = tail.get()) == LINK_CAPACITY) {
12
13 this.tail = tail = tail.next = new Link();
14
15 writeIndex = tail.get();
16
17 }
18
19 tail.elements[writeIndex] = handle;
20
21 handle.stack = null;
22
23 // we lazy set to ensure that setting stack to null appears before we unnull it in the owning thread;
24
25 // this also means we guarantee visibility of an element in the queue if we see the index updated
26
27 tail.lazySet(writeIndex + 1);
28
29 }
add操作将元素添加到tail指向的Link对象中,如果Link已满则创建一个新的Link实例。
transfer方法
1 boolean transfer(Stack<?> dst) {
2
3 Link head = this.head;
4 if (head == null) {
5 return false;
6 }
7
8 if (head.readIndex == LINK_CAPACITY) {
9 if (head.next == null) {
10 return false;
11 }
12 this.head = head = head.next;
13 }
14
15 final int srcStart = head.readIndex;
16 int srcEnd = head.get();
17 final int srcSize = srcEnd - srcStart;
18 if (srcSize == 0) {
19 return false;
20 }
21
22 final int dstSize = dst.size;
23 final int expectedCapacity = dstSize + srcSize;
24
25 if (expectedCapacity > dst.elements.length) {
26 final int actualCapacity = dst.increaseCapacity(expectedCapacity);
27 srcEnd = Math.min(srcStart + actualCapacity - dstSize, srcEnd);
28 }
29
30 if (srcStart != srcEnd) {
31 final DefaultHandle[] srcElems = head.elements;
32 final DefaultHandle[] dstElems = dst.elements;
33 int newDstSize = dstSize;
34 for (int i = srcStart; i < srcEnd; i++) {
35 DefaultHandle element = srcElems[i];
36 if (element.recycleId == 0) {
37 element.recycleId = element.lastRecycledId;
38 } else if (element.recycleId != element.lastRecycledId) {
39 throw new IllegalStateException("recycled already");
40 }
41 element.stack = dst;
42 dstElems[newDstSize ++] = element;
43 srcElems[i] = null;
44 }
45 dst.size = newDstSize;
46
47 if (srcEnd == LINK_CAPACITY && head.next != null) {
48 this.head = head.next;
49 }
50
51 head.readIndex = srcEnd;
52 return true;
53 } else {
54 // The destination stack is full already.
55 return false;
56 }
57 }
transfer方法收件根据stack的容量和自身拥有的实例数,计算出最终需要转移的实例数。之后就是数组的拷贝和指标的调整。
基本上所有的流程有个大致的了解,下面从整体的角度回顾一下Netty对象池的实现。
整体实现
结构

整个设计上核心的几点:
- Stack相当于是一级缓存,同一个线程内的使用和回收都将使用一个Stack
- 每个线程都会有一个自己对应的Stack,如果回收的线程不是Stack的线程,将元素放入到Queue中
- 所有的Queue组合成一个链表,Stack可以从这些链表中回收元素(实现了多线程之间共享回收的实例)
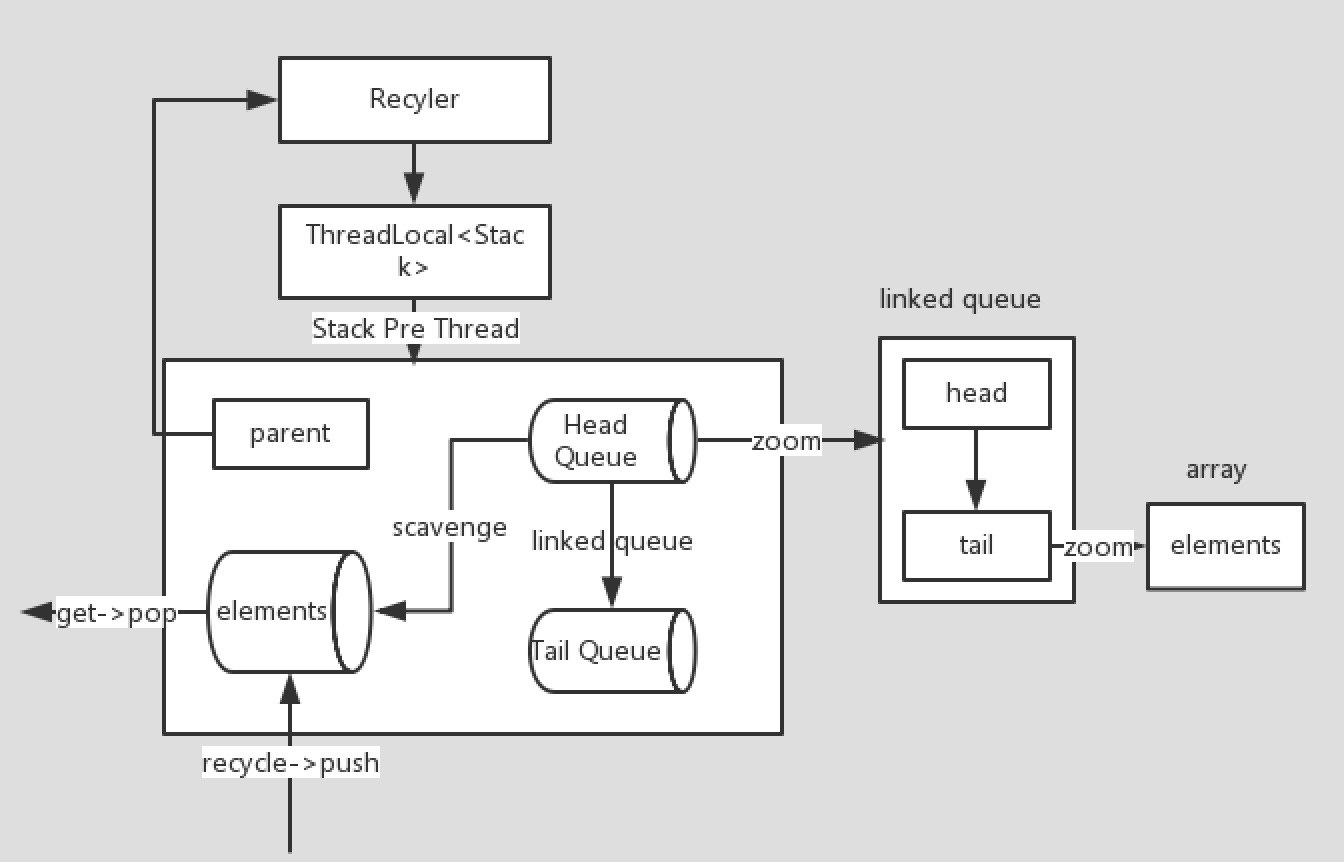
引用自网上的一幅图。