字段类型
mysql字段定义中INT(x)中的x仅仅指的是显示宽度。该可选显示宽度规定用于显示宽度小于指定的列宽度的值时从左侧填满宽度。显示宽度并不限制可以在列内保存的值的范围,也不限制超过列的指定宽度的值的显示。所以x的定义与存储空间没有任何关系都是4个字节。
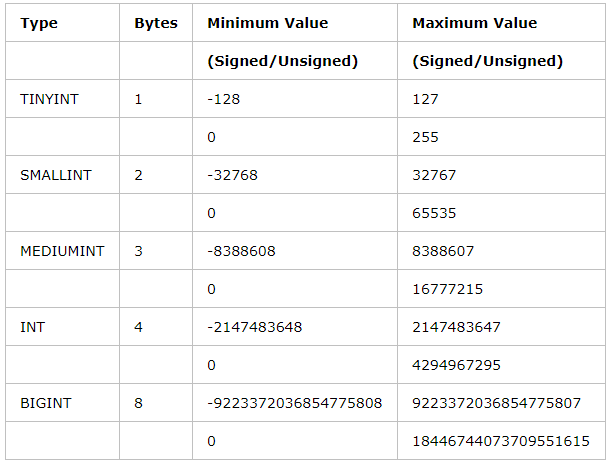
超过最大数值不会报错但是根据此字段查询不到,也关联不起来。
查看mysql数据库编码
show variables like 'character_set_database';
当character_set_database为utf8编码时, 一个汉字算三个字符,一个数字或字母算一个字符。其他编码下,一个汉字算两个字符, 一个数字或字母算一个字符。
char和varchar的length
MySql中cahr(len)/varchar(len)类型字段,len所表示的也是字符数,并非字节数,所以字段可以插入<=n个字符。
如果为定长字段,一定要用char。
增删改查数据库
创建数据库
create database [if not exists] db_name
[default] character set [=] charset_name
[default] collate [=] collation_name
选择数据库
use db_name;
修改数据库
alter database db_name
default character set gb2312
default collate gb2312_chinese_ci;
删除数据库
drop database [if exists] db_name
查看数据库
show databases [like '%pattern%'|where expr]
增删改查表
新建表
create [temporary] table tbl_name(
字段1 数据类型 [列完整性约束条件][默认值],
字段2 数据类型 [列完整性约束条件][默认值],
[表级完整性约束条件]
) [engine=引擎类型]
列完整性约束条件:是否允许为null
表级完整性约束条件:主键primary key(主键字段)、索引index ind_name(字段)
更新表
添加列
alter table add [column] 子句
alter table db_name.tbl_name add column city char(10) not null default 'yz' AFTER sex;
修改列
alter table change [column] 子句,修改列的名称或数据类型
alter table db_name.tbl_name change column cust_sex sex char(1) null default 'M';
alter table alter [column] 子句,修改或删除指定列的默认值
alter table db_name.tbl_name alter column cust_city set default 'beijing'
alter table modify [column] 子句,修改指定列的数据类型
alter table db_name.tbl_name modify column cust_name char(20) FIRST;
删除列
drop [column] 子句
alter table db_name.tbl_name drop column cust_contact;
表重命名
alter table db_name.tbl_name rename to db_name.tbl_new_name
rename table tbl_name to tbl_new_name
删除表
drop [temporary] table [if exists]
查看表
显示数据库中的所有表
show [full] tables [{from|in} db_name] [like 'pattern'|where expr]
查看表结构
show [full] columns {from|in} tbl_name [ {from|in} db_name] [like 'pattern'|where expr]
或者
{describe|desc} tbl_name [col_name|wild]
索引
索引是以文件形式存储的,索引在提高查询速度的同时,会降低更新表的速度。因为每次insert、update、delete都会更新索引以确保索引树与表的内容保持一致。
索引分类:
普通索引(index),没有任何限制,使用的关键字是index或key。
唯一性索引(unique),必须是唯一的。
主键(primary key),不为空且唯一。
索引的创建
create [unique] index index_name on tbl_name(index_col_name,...)
其中,index_col_name的格式为:
col_name[(length)][asc|desc]
length为使用指定列的前length个字符来创建索引。asc|desc用于指定索引按升序还是降序排列。
例子:
create index index_customers on db_name.customer(cust_name(3) asc);
除了上面的创建索引方式还可以在创建表时新建索引也可以修改表增加索引
--新建表时创建索引 create table customer( id int not null auto_increment, name char(50) not null, age int not null 0, primary key(id), index index_customer_name(name) ); --修改表时添加索引 alter table db_name.tbl_name add index index_customer_name(name);
索引的查看
show {index|indexs|keys} {from|in} tbl_name [{from|in} db_name] [where expr]
索引的删除
drop index index_name on tbl_name
删除索引也可以在alter table语句中进行
drop primary key、drop index、drop foreign key
索引的分类
primary:唯一索引,不允许为null,数据的唯一标识。
key:普通索引(非唯一)。
unique:唯一索引,可以为null。
fulltext: 表示全文搜索的索引。 FULLTEXT用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的INDEX 也可以。
spatial:空间索引。
fulltext全文索引
SHOW VARIABLES LIKE 'ft%'; #ft就是FullText的简写 MATCH (columnName) AGAINST ('string') #where条件后使用
视图
视图不是数据库中的真实表,而是一张虚拟表。它的数据存储在引用的真实表中。
外模式对应到数据库中的概念就是视图(View)。
视图优点:
- 集中分散数据。
- 简化查询语句。
- 重用sql语句。
- 保护数据安全。
- 共享所需数据。
- 更改数据格式。
创建视图
createview view_name [(column_list)] as select_statement [with [cascaded|local] check option]
如果在创建视图的时候制定了“WITH CHECK OPTION”,那么更新数据时不能插入或更新不符合视图限制条件的记录。
修改视图
create or replace view dbname.tbl_name as select * from db_name.tbl_name where sex = 'M' with check option --检查限制通过视图只能添加sex为M的记录
删除视图
drop view [if exists] view_name[,view_name] ... [restrict|cascade]
查看视图
show create view view_name
替换视图结果中的数据
case
when 条件1 then 表达式1
when 条件2 then 表达式2
else 表达式
end [as] column_alias
也可以用if函数
if(表达式,true返回的结果,false返回的结果)
存储过程
存储过程是一组为了完成某项特定功能的SQL语句集,其本质上就是一段存储在数据库中的代码,他可以由声明式的sql语句(如create、update、select等语句)和过程式sql语句(如if...then...else控制结构语句)组成。这组语句集经过编译后会存储在数据库中,用户只需要通过制定存储过程的名字并给定参数(如果该存储过程带有参数),即可随时调用并执行它,而不必重新编译,因此通过这种定义一段程序存储在数据库中的方式,可加大数据库操作语句的执行效率。
存储过程是一个可编程的函数,同时可以看做是在数据库编程中面向对象方法的模拟,它允许控制数据的访问方式。因此,当希望在不同的应用程序或平台上执行相同的特定功能时,存储过程尤为适合。使用存储过程的好处如下:
- 可增强sql语言的功能和灵活性(可以用流控制语句,可以完成复杂的判断和比较复杂的运算)
- 良好的密封性(存储过程被创建后,可以在程序中多次调用,而不惜重新编写该存储过程的sql语句,并且数据库专业人员可以随时对存储过程进行修改,而不会影响到调用它的应用程序源代码)
- 高性能(存储过程调用过一次后,其执行规划就驻留在高速缓冲存储器中,在以后的操作中,只需从高速缓冲存储器中调用已编译好的二进制代码执行即可,从而提高了系统性能)。
- 可减少网络流量(存储过程是在服务器端运行,且执行速度快。当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而可降低网络负载)。
- 存储过程可作为一种安全机制来确保数据库的安全性和数据的完整性
创建存储过程
因为存储过程可能包含多条sql,所以要使用delimiter $将sql语句结束符临时设为$,是的mysql服务器可以完整地处理存储过程体中所有的sql语句。而后可通过delimiter命令再将mysql语句的结束标志改回为mysql的默认结束标志(即;)。
create procdure sp_name(【proc_parameter[,...]】) routine_body proc_parameter语法: [in|out|inout] param_name type
routine_body存储过程体
以begin...end嵌套,如果只有一条sql,可以省略
存储过程体
1.声明局部变量(declare)
DECLARE 关键字声明的变量,只能在存储过程中使用,称为存储过程变量,即只在存储过程中的begin和end之间生效。
declare var_name[,...] type [default value]
例: declare cid int(10) 0
2.给局部变量赋值(set)
如果是声明变量用,可以在一个会话的任何地方声明,但变量名要用@开头。作用域是整个会话,称为会话变量(比如某个应用的一个连接过程中)。
set var_name = expr[,var_name = expr] 例: set cid = 910; -- 给declare声明的变量赋值 set @sid = 910; --声明会话变量并赋值
3.给局部变量赋值(select into)
select col_name[,...] into var_name[,...] table_expr col_name用于指定列名,var_name用于指定要赋值的变量名,table_expr表示from子句及后面的语法部分 注意:select ... into ...返回的结果集只能有一行数据
4.流程控制语句
条件判断
if---then---else语句
case语句
循环语句
while、repeat、loop
5.游标
1 declare cusor_name cursor for select_statement --声明游标 2 open cursor_name --打开游标 3 fetch cursor_name into var_name [,var_name]... --读取游标,var_name为指定存放数据的变量名 4 close cursor_name --关闭游标
例:
delimiter $$ create procedure sp_sumofrow(OUT ROWS INT) begin declare cid int; declare found boolean default true; declare cur_cid CURSOR FOR --创建游标 select cust_id from customers; declare continue handler for not found set found = false; --当找不到时,给found设为false set ROWS = 0; -- open cur_cid; fetch cur_cid into cid; while found do set ROWS=ROWS+1; fetch cur_cid into cid; end while; close cur_cid; end$$
declare handler声明异常处理语法
DECLARE {EXIT | CONTINUE} --退出还是继续 HANDLER FOR {error-number | SQLSTATE error-string | condition} --触发条件 SQL statement --错误触发的操作
调用,@rows为输出变量
call sp_sumofrow(@rows)
do it myself
delimiter $$ CREATE proceduregetCount(out rows int) BEGIN DECLARE cid int; DECLARE found boolean default true; DECLARE cur_cid CURSOR for SELECT id from customer; DECLARE CONTINUE HANDLER for not found set found = false; set rows = 0; open cur_cid; fetch cur_cid into cid; while found do set rows = rows +1; fetch cur_cid into cid; end while; close cur_cid; END$$
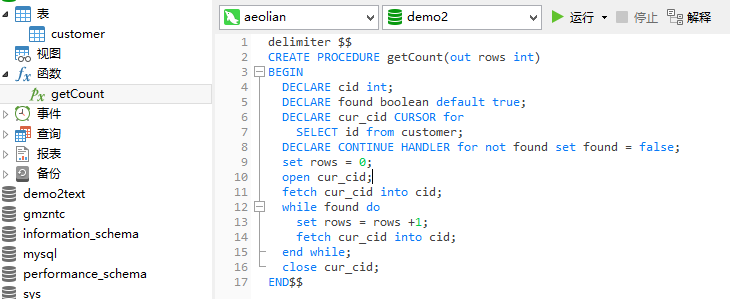
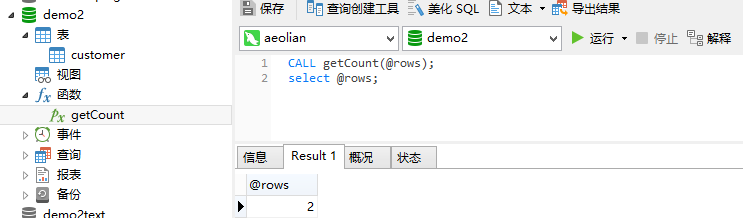
调用存储过程
call sp_name([parameter[,...]]) call sp_name[()]
删除存储过程
drop procedure [if exists] sp_name
例子:
-- 先删除存储过程 drop procedure if exists insertParKing;
-- 新建存储过程,插入车位,注意varchar指定的长度一定要足够长,正常写255 delimiter $$ create procedure insertParKing(IN `parkingCode_start` int,IN `parkingCode_end` int,IN `parkingType` varchar(255),IN `parkingLevel` varchar(255),IN `chargeTypeId` varchar(255),IN `areaId` varchar(255),IN `chargeCode` varchar(255),IN `parkingState` varchar(255)) begin IF parkingCode_start is null THEN set parkingCode_start = 101058; -- 开始号 END IF; IF parkingCode_end is null THEN set parkingCode_end = 101132; -- 结束号 END IF; IF parkingType is null THEN set parkingType = '1'; -- 车位类型,水平还是垂直 END IF; IF parkingLevel is null THEN set parkingLevel = 'bb75e797-3367-4560-affa-aaf41404fa23'; -- 某表id END IF; IF chargeTypeId is null THEN set chargeTypeId = 'efce5ff7-7d1f-4df4-834d-d7664724412f'; -- 某表id END IF; IF areaId is null THEN set areaId = '13bf629f-dfd3-4846-b8d5-57c9c3dd5d26'; -- 某表id END IF; IF chargeCode is null THEN set chargeCode = ''; END IF; IF parkingState is null THEN set parkingState = '1'; END IF; SET @parkingCode = parkingCode_start; REPEAT SET @parkingId = UUID( ); SET @realparkIngID = UUID( ); INSERT INTO base_parking ( parkingId, parkingCode, parkingType, parkingLevel, chargeTypeId, orderCode, areaId, chargeCode, parkingState ) VALUES ( @parkingId, @parkingCode, parkingType, parkingLevel, chargeTypeId, @parkingCode, areaId, chargeCode, parkingState ); INSERT INTO bus_realparking ( realparkIngID, parkingCode, selfAdaptionId, STATUS, dataType ) VALUES ( @realparkIngID, @parkingCode, NULL, 0, 0 ); set @parkingCode = @parkingCode+1; UNTIL @parkingCode > parkingCode_end END REPEAT; end; $$ deleimiter ;
--调用 call insertParKing(101133,101135,null,null,null,null,null,null);
--再删除存储过程 drop procedure if exists insertParKing;
存储函数
存储函数与存储过程一样,都是由sql语句和过程式语句所组成的代码片段,并且可以被应用程序和其他sql语句调用。区别如下:
- 存储函数不能拥有输出函数,因为存储函数本身就是输出参数
- 可以直接对存储函数进行调用,且不需要使用call语句
- 存储函数中必须包含一条return语句,而这条特殊的sql语句不允许包含于存储过程中
create function sp_name([param_name type[,...]]) returns type routine_body
例:
delimiter $$ create function fn_search(cid int) returns char(2) deterministic begin declare sex char(2); select cust_sex into sex from customers where custid=cid; if sex is null then return(select '没有该客户') else
if sex='F' then return(select '女') else return(select '男') end if; end if; end $$
调用存储函数
select sp_name(func_parameter[,...])
删除存储函数
drop function [if exists] sp_name
do it myself
delimiter $$ CREATE function getSexByid(var_id int) returns char(2) BEGIN DECLARE var_sex char(2); select sex into var_sex from customer where id = var_id; if var_sex is null then return(select '无'); else if var_sex='0' then return(select '女'); else return(select '男'); end if; end if; END$$
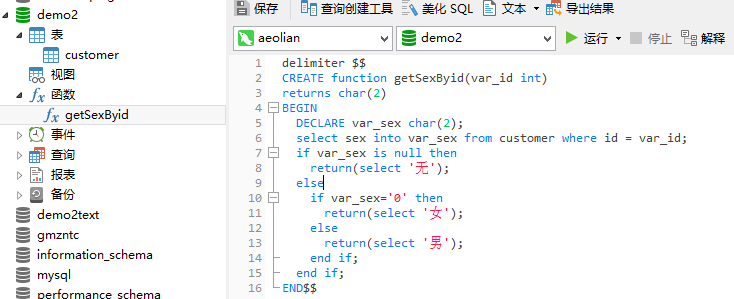
调用存储函数
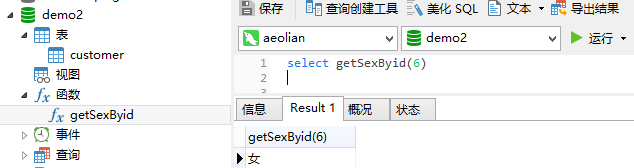
数据库安全与保护
DBMS对数据库的安全保护功能通过完整性控制、安全性控制、并发控制和数据库的备份与恢复四个方面来实现的。
完整性约束对象
(1)列级约束
类型、取值范围、精度、数据格式等约束
(2)元组约束
元组中各个字段的相互约束,例如开始时间不能大于结束时间
(3)表级约束
定义与实现完整性约束
关系模型中可以有三类完整性约束,分别是实体完整性、参照完整性、和用户定义的完整性。
实体完整性
(1)主键约束
(2)侯选建约束
主键与侯选建区别:
一个表中只能有一个主键,可以有若干个侯选建。
定义主键约束时,系统会自动生产primary key索引,而定义侯选键约束时,系统自动产生unique索引。
参照完整性
在create table和alter table语句中
1.在列后面直接加上
references tbl_name(col_name[(length)][asc|desc],...) [on delete restrict|cascade|set null|no action]
2.在表的最后面加上
foreign key(col_name[(length)][asc|desc],...) references tbl_name(col_name[(length)][asc|desc],...) [on delete restrict|cascade|set null|no action]
例:
create table orders ( order_id int not null auto_increment, order_product char(50) not null, cust_id int not null, --外键 order_price double not null, order_date datetime not null, primary key(order_id), foreign key(cust_id) references customers(cust_id) on delete restrict on update restrict );
用户自定义完整性
在create table和alter table
1.非空约束
2.check约束
命名完整性约束
与数据库中的表与视图一样可以对完整性进行添加、删除、修改等操作。其中,为了删除和修改完整性约束,首先需要在定义约束的同时对其进行命名。命名完整性约束的方法是在各种完整性约束的定义说明之前加上constraint和该约束的名字。
constraint [symbol]
更改完整性约束
在alter table 中使用add constraint子句。
例:
alter table emp add constraint ppp primary key (id) --主键约束 alter table emp add constraint xxx check(age>20) --check约束 alter table emp add constraint qwe unique(ename) --unique约束 alter table emp add constraint jfsd default 10000 for gongzi --默认约束 alter table emp add constraint jfkdsj foreign key (did) references dept (id) --外键约束 CREATE TABLE employees (employee_id NUMBER(6), first_name VARCHAR2(20), ... job_id VARCHAR2(10) NOT NULL, CONSTRAINTS emp_emp_id_pk PRIMARY KEY (EMPLOYEE_ID)); 列级的约束定义 column [CONSTRAINT constraint_name] constraint_type, 表级约束的定义 column,..[CONSTRAINT constraint_name] constraint_type (column,...)
事件
-- 创建事件call_hz_event,从2019-01-01 23:00:00开始每天执行一次存储过程。在执行完成之后保留。 DELIMITER // CREATE DEFINER=`root`@`%` EVENT `call_hz_event` ON SCHEDULE EVERY 1 DAY STARTS '2019-01-01 23:00:00' ON COMPLETION PRESERVE ENABLE DO begin call hz_all_date(DATE_SUB(CURDATE(),INTERVAL 1 DAY)); end// DELIMITER ;
触发器
触发器是用户定义在关系表上的一类由事件驱动的数据库对象,也是一种保证数据完整性的方法。
触发器与表的关系十分密切,其主要作用是实现主键和外键不能保证的复杂的参照完整性和数据的一致性,从而有效地保护表中的数据。
注意,如果基于主业务表写的触发器出现问题的话会导致主表自身的insert/update/delete操作失败。用触发器需要谨慎,一定不能出错,出错导致主业务表不能操作,会炸的。
创建触发器
create trigger trigger_name trigger_time trigger_event on tbl_name for each row trigger_body
trigger_name指触发器名称,如果指定特定的数据库,名称前面应该加上数据库的名称。
trigger_time用于指定触发器被触发的时刻。关键字“before”和“after”。
trigger_event用于指定触发事件,关键字insert、update、delete
tbl_name用于指定触发器相关联的表名。必须引用永久性表。
for each row指定对于受触发事件影响的每一行都要激活触发器的动作.
trigger_body指定触发器动作主体,使用begin...end复合语句结构。
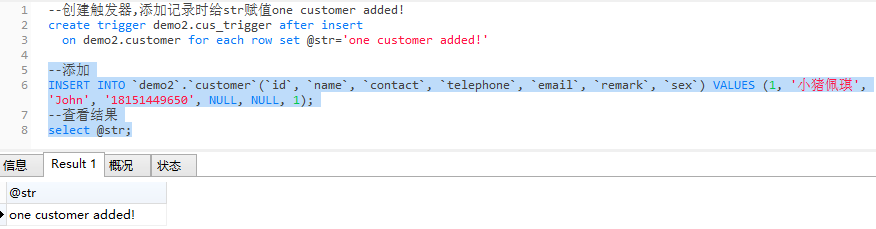
例:
--创建触发器,添加记录时给str赋值one customer added! create trigger demo2.cus_trigger after insert on demo2.customer for each row set @str='one customer added!' --添加 INSERT INTO `demo2`.`customer`(`id`, `name`, `contact`, `telephone`, `email`, `remark`, `sex`)
VALUES (1, '小猪佩琪', 'John', '18151449650', NULL, NULL, 1); --查看结果 select @str;
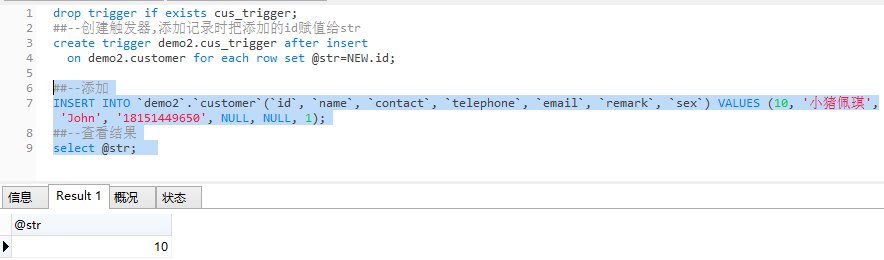
删除触发器
drop trigger [if exists] [schema_name.]trigger_name
使用触发器
insert可以使用new虚拟表,来访问被插入的行。
delete可以使用old虚拟表,来访问删除的记录,old表是只读的,不可修改。
update可以使用new和old虚拟表。
drop trigger if exists cus_trigger; ##--创建触发器,添加记录时把添加的id赋值给str create trigger demo2.cus_trigger after insert on demo2.customer for each row set @str=NEW.id; ##--添加 INSERT INTO `demo2`.`customer`(`id`, `name`, `contact`, `telephone`, `email`, `remark`, `sex`) VALUES (10, '小猪佩琪', 'John', '18151449650', NULL, NULL, 1); ##--查看结果 select @str;
安全性的访问控制
创建用户账号
CREATE USER user_name@host[identified by [password] 'pwd']
删除用户
drop user user_name@host[,user_name]
修改用户账号
rename user old_user to new_user[,old_user to new user]
修改用户口令
set password [for user]= { password('new_pwd')|'encrypted password' }
例:
select password('123456'); #获得123456的加密格式 set password for 'autumn'@'localhost' = '加过密的123456';
账户权限管理
grant all|select|update|delete等数据操作 [colname,colname] on 库名或者表名 to username@lhost [identified by [password]] 'pwd' [with grant option]
撤销权限
revoke all|select|update|delete等数据操作 [colname,colname] on 库名或者表名 from username@lhost
例:
#赋予权限 grant select,update on mysql_test.customers to 'autumn'@'localhost' identified by '123456', 'aeolian'@'localhost' identified by '123456'; #撤销 revoke select on mysql_test.customers from 'autumn'@'localhost'
事务与并发控制
数据库中的数据是共享资源,支持多个不同程序或同一程序的多个独立执行同事(并发地)存取数据库中相同的数据。当多个用户同时操作相同的数据时,会造成数据的异常现象。
DBMS中事务就是为了保证数据的一致性而产生的一个概念和基本手段。这种机制称为“并发控制”。
事务特性:
原子性、一致性、隔离性、持续性。
并发操作问题:
(1).丢失更新
事务T1和T2同时读入一个数据并修改。T1提交后T2也提交会破坏事务T1提交的结果。这是并发带来的不一致性。
(2).不可重复读
T1读取后,T2进行了修改、增加、删除。使得两次读取结果不一致。
(3).脏读
T1修改数据,并写回磁盘。T2读取数据后,T1由于某种原因撤销。这时T1修改过的数据恢复原值。
封锁
排他锁(Exclusive Lock,X锁)、共享锁(Shared Lock,S锁)
一般的,写操作要求X锁,读操作要求S锁。
用锁进行并发控制
1)若事务T对数据D加了X锁,则所有别的事务对数据D的锁请求都必须等待知道事务T释放锁。
2)若事务T对数据D加了S锁,则别的事务还可对数据D请求S锁,而对数据D的X锁请求必须等待知道事务T释放锁。
3)事务执行数据库操作时都要先请求相应的锁,即对读请求S锁,对更新(插入、删除、修改)请求X锁。这个过程一般是由DBMS在执行操作时自动隐含的进行。
4)事务一直占有获得的锁直到结束(Commit或Rollback)时释放。
锁粒度
粒度来描述封锁的数据单元的大小。DBMS可以决定不同粒度的锁。从最底层的数据元素到最高层的整个数据库,粒度越细,并发性就越大,但软件复杂性和系统开销也就越大。封住整个数据库,DBMS的管理与控制最简单,只需设置和测试一个锁,故系统开销也最小,然而对数据的存取则只能顺序进行,因而系统的总体性能大大下降。反之,数据元素层锁将提高最高的并发性,但DBMS要设置大量的锁装置来标示那些当前被封锁的数据元素,同事还要大量的锁检测,影响了每一事物的服务性能,系统总体性能也因此而下降。
锁级别
封锁的级别又称为一致性级别或隔离度。首先,它与封锁的期限有关,依应用的不同,封锁的期限可能不一样,有的只需要单个数据单元的存取期,有的
备份与恢复
txt数据文件
select into..outfile语句备份
select * into outfile 'file_name' [fields [terminated by 'string'] #字段值之间的符号' ' [[optionally] enclosed by 'char'] #包裹字段值的符号,optionally表示所有字段值都在字符之间,默认'' [escaped by 'char'] #转义字符,默认'\' ] [lines [terminated by 'string'] #字段值之间的符号' ' ] |into dumpfile 'file_name'
当导出语句关键字是dumpfile,而非outfile时,导出的备份文件里面所有的数据航都会彼此紧挨着放置,即值和行间没有任何标记
load data...infile
load data infile 'file_name.txt' into table tbl_name [fields [terminated by 'string'] #字段值之间的符号' ' [[optionally] enclosed by 'char'] #包裹字段值的符号,optionally表示所有字段值都在字符之间,默认'' [escaped by 'char'] #转义字符,默认'\' ] [lines [string by 'string'] #亚子句指定一个前缀,导入数据行时,忽略数据行中的该前缀和前缀之前的内容.如果不包括该前缀,则整个数据行被跳过。 [terminated by 'string'] #字段值之间的符号' ' ]
例:
导出
select * from mysql_test.customers into outfile 'C:/backup/backupfile.txt' fields terminated by ',' optionally enclosed by '"' lines terminated by '?';
导入
load data infile 'c:/backup/backupfile.txt' into table mysql_test.customers_copy fields terminated by ',' optionally enclosed by '"' lines terminated by '?';
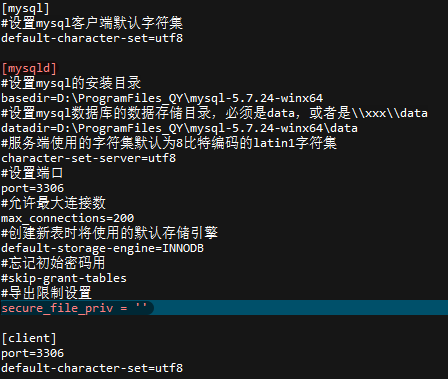
导出时提示The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
show variables like '%secure%'; -- 查看secure_file_priv的值,若为null则不允许导出
secure_file_prive=null --限制mysqld 不允许导入导出
secure_file_priv=/path/ -- 限制mysqld的导入导出只能发生在默认的/path/目录下
secure_file_priv='' --不对mysqld 的导入导出做限制
找到mysql安装目录的my.ini文件,将mysqld下面的secure_file_priv的值改'',重启启动即可。
.sql文件
windows下直接用cmd
备份sql
mysqldump -u root -p --all-databases > D:/mysql.sql #备份所有数据库 mysqldump -uroot -p123456 --databases db1 db2 db3 > D:/mysql.sql #备份多个数据库 mysqldump -hhostname -Pport -uroot -p'123456' --databases act > D:/mysql.sql #远程备份(远程时,需要多加入-h:主机名,-P:端口号) mysqldump --opt -uroot -p123456 -h127.0.0.1 --database dbname --ignore-table=dbname.table1 | gzip>/db_back/dbname_`date +%F`.zip #导出为压缩包,这样会小很多,线上服务器尽量用这个,推荐!!!
推荐使用最后一个导出为zip文件,导出的文件大小小很多,解压后和sql文件大小一样。`date +%F` 在文件名中会转换为日期。
如果要忽略某些表要用--ignore-table,每忽略一张表都要用一个--ignore-table
--ignore-table=database.table1 --ignore-table=database.table2

导入sql
在本机上用mysql -uroot -p123456登录服务器,然后执行如下语句,可以不用sql文件,只要文本内容是sql语法都可以,上面的导出文件为zip时,解压后的文本文件无后缀直接导入即可。
source d:/mysql.sql;
Hedisql等GUI工具
谨防误删
这个使用简单的多。需要注意的是drop database、drop table等字样千万别选。否则导入时存在会把你之前的数据库或者表给删掉。线上环境要真的被执行了就麻烦了。导出的sql文件一定要打开看一下有没有drop database字样。
多行sql操作数据大小
还有一个最大INSERT大小(max_allowed_packet)字样的东西,这个代表Mysql能接受的最大的多行操作sql数据大小(单位kb),大小一定不能超过mysql设定的值否则会断开连接。
可以用如下语句查看mysql的配置
show variables like 'max_allowed_packet'