##约束 /* 含义:一种限制,用于限制表中的数据, 为了保证表中的数据的准确性和可靠性 分类:六大约束 not null: 非空,用于保证该字段的不能为空,比如姓名,学号等 default: 默认, 用于保证该字段有默认值,比如性别 primary key: 主键,用于保证该字段具有唯一性,并且非空,比如学号,员工编号 unique: 唯一,用于保证该字段的值具有唯一性,可以为空 check(mysql中不支持): 检查约束,比如年龄,性别等 foreign key: 外键约束,-用于限制两个表的关系,用于保证该字段的值必须来自于主表的关联值的值。 添加约束的时机: 1.创建表时 2.修改表时 约束的添加分类: 列级约束: 六大约束语法上都支持,但外键约束没有效果 表级约束 ①除了非空, 默认, 其他都支持 ②在各个字段的最下面 语法:【constraint 约束名】 约束类型(字段名) 括号的可以不写,会有默认值 FOREIGN KEY(majorId) REFERENCES major(id) 主键和唯一的对比 保证为唯一性 是否为空 一个表中可以有多少个 是否允许组合 primary key 主键 √ × 至多有一个(一个或没有) √,但不推荐 unique 唯一 √ √ 可以有多个 √,但不推荐 外键特点: 1.要求在从表设置外键关系 2.从表的外键类列的类型和主表的关联的类型要求一致或兼容 3.主表的关联列必须是一个key(一般是主键或唯一) 4.插入数据时,先插入主表,再插入从表 删除数据时,先删除从表,再删除主表 */ CREATE TABLE 表名( 字段名 字段类型 列级约束, 字段名 字段类型, 表级约束 ); ##1.创建表时添加约束 CREATE TABLE major( id INT PRIMARY KEY , majorName VARCHAR(20) ); CREATE TABLE stu( id INT PRIMARY KEY , stuName VARCHAR(20), gender CHAR(1) CHECK(gender = '男' OR gender = '女'), seat INT UNIQUE, age INT DEFAULT 18, majorId INT REFERENCES major(id) -- 没有效果的,列级约束mysql不支持 ); CREATE TABLE stud( id INT , stuName VARCHAR(20), gender CHAR(1), seat INT , age INT , majorId INT, CONSTRAINT pk PRIMARY KEY(id),#主键 CONSTRAINT uq UNIQUE(seat),#唯一键 CONSTRAINT ck CHECK(gender = '男' OR gender = '女'),#检查 CONSTRAINT fk_stud_major FOREIGN KEY(majorId) REFERENCES major(id) #外键 ); -- constraint ###通用的写法: CREATE TABLE IF NOT EXISTS students( id INT PRIMARY KEY , stuName VARCHAR(20) NOT NULL, gender CHAR(1) CHECK(gender = '男' OR gender = '女'), seat INT UNIQUE, age INT DEFAULT 18, majorId INT, CONSTRAINT fk_student_major FOREIGN KEY(majorId) REFERENCES major(id) ); SELECT * FROM major; SELECT * FROM stu; DESC stud; SHOW INDEX FROM stud; ##2.修改表时添加约束 /* 添加列级约束 alter table 表名 modify column 字段名 字段类型 新约束 添加表级约束 alter table 表名 add【constraint 约束名】 约束类型(字段名) 外键引用 */ CREATE TABLE studinfo( id INT , stuName VARCHAR(20), gender CHAR(1), seat INT , age INT , majorId INT ); -- 添加非空约束 ALTER TABLE studinf MODIFY COLUMN stuName VARCHAR(20) NOT NULL; -- 添加默认约束 ALTER TABLE studinf MODIFY COLUMN age INT DEFAULT 15; -- 添加主键①列级约束 ALTER TABLE studinf MODIFY COLUMN id INT PRIMARY KEY; -- 添加主键②表级约束 ALTER TABLE studinf ADD PRIMARY KEY(id); -- 添加唯一键①列级约束 ALTER TABLE studinf MODIFY COLUMN seat INT UNIQUE; -- 添加唯一键①表级约束 ALTER TABLE studinf ADD UNIQUE(seat); -- 添加外键(只有表级约束) ALTER TABLE studinf ADD CONSTRAINT fk_studinfo_major FOREIGN KEY(majorId) REFERENCES major(id); ##修改表时删除约束 -- 删除非空约束 ALTER TABLE studinf MODIFY COLUMN stuName VARCHAR(20) NULL; -- 或者直接不写,其他同理 ALTER TABLE studinf MODIFY COLUMN stuName VARCHAR(20) ; -- 删除主键 ALTER TABLE studinf DROP PRIMARY KEY ; -- 删除唯一键 ALTER TABLE studinf DROP INDEX seat; ##标识列 /* 含义:又称为自增长列:可以不用手动插入值,系统提供默认的序列值 特点:1.标识列必须和主键搭配吗? 不一定,但是要求必须为一个key,unique也是key 2.一个表至多有一个标识列、 3.标识列的类型只能是数值型(一般为int) 4.标识列可以通过auto_increment_increment = 3;设置步长, 可以通过手动插入值,设置起始值 */ -- 创建表时设置标识列 CREATE TABLE ta_de( id PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20) ); SET auto_increment_increment = 3; -- AUTO_INCREMENT -- 修改表时设置标识列 ALTER TABLE ta_de MODIFY COLUMN id INT PRIMARY KEY AUTO_INCREMENT; -- 修改表时删除标识列 ALTER TABLE ta_de MODIFY COLUMN id INT ;
事务
#事务 /* 事务的ACID(acid)属性 1. 原子性(Atomicity) 原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 2. 一致性(Consistency) 事务必须使数据库从一个一致性状态变换到另外一个一致性状态 3. 隔离性(Isolation) 事务的隔离性是指一个事务的执行不能被其他事务干扰,即一个 事务内部的操作及使用的数据对并发的其他事务是隔离的,并发 执行的各个事务之间不能互相干扰。 4. 持久性(Durability) 持久性是指一个事务一旦被提交,它对数据库中数据的改变就是 永久性的,接下来的其他操作和数据库故障不应该对其有任何影响 事务的创建:事务没有明显的开启和结束的标记 比如insert update delete语句 delete from 表 where id= 1; 显示事务:事务具有明显的开启和结束的标记 前提:必须设置自动提交功能为禁用 set autcommit = 0;只对当前的事务有效 开启事务的语句; update 表 set 李玲的余额=500 where name='李玲'; update 表 set 李静的余额=1500 where name='李静'; 结束事务的语句; 步骤: 1.开启事务 set aotocommit=0; start transaction;可选的 2.编写事务的sql语句(select insert update delete) 语句1; 语句2; ... 3.结束事务 commit;提交事务 rollback;回滚事务 */ CREATE TABLE acccount( id INT PRIMARY KEY, username VARCHAR(20), balance DOUBLE ); SELECT * FROM acccount; -- 开启事务 SET autocommit=0; START TRANSACTION; UPDATE acccount SET balance=1000 WHERE username='李玲'; UPDATE acccount SET balance=1000 WHERE username='李静'; -- 结束事务; ROLLBACK; -- commit; /* 脏读: 对于两个事务 T1, T2, T1 读取了已经被 T2 更新但还 没有被提交的字段. 之后,若 T2 回滚, T1读取的内容就是临时且无效的. 幻读: 对于两个事务T1, T2, T1 从一个表中读取了一个字段, 然后 T2 在该表中 插 入了一些新的行. 之后, 如果 T1 再次读取同一个表, 就会多出几行. 不可重复读: 对于两个事务T1, T2, T1 读取了一个字段, 然后 T2 更新了该字段. 之后, T1再次读取同一个字段, 值就不同了. /*

Oracle 支持的 2 种事务隔离级别:READ COMMITED,SERIALIZABLE。
Oracle 默认的事务隔离级别为: READCOMMITED
Mysql 支持 4 种事务隔离级别. Mysql 默认的事务隔离级别为: REPEATABLE READ
查看当前的隔离级别: SELECT @@tx_isolation;
设置当前 mySQL 连接的隔离级别:set transaction isolation level read committed;
设置数据库系统的全局的隔离级别:set global transaction isolation level read committed;
#savepoint的使用 SET autocommit = 0; START TRANSACTION; DELETE FROM account WHERE id = 23; save POINT a;-- 设置保存点 DELETE FROM acount WHERE id = 25; ROLLBACK TO a;-- 回滚到保存点
##视图 /* 视图: MySQL从5.0.1版本开始提供视图功能。一种虚拟存在的表,行和列的数据来自定义视图的查询中使用的表, 并且是在使用视图时动态生成的,只保存了sql逻辑,不保存查询结果 • 应用场景: – 多个地方用到同样的查询结果 – 该查询结果使用的sql语句较复杂 */ -- 例子 CREATE VIEW my_v1 AS SELECT studentname,majorname FROM student s INNER JOIN major m ON s.majorid=m.majorid WHERE s.majorid=1; /* 创建视图: 语法; create view 视图名 As 查询语句 */ -- 1.查询姓名中包含a字符的员工名、部门名和工种信息 CREATE VIEW view1 AS SELECT last_name,department_name,job_title FROM employees e JOIN departments d ON e.department_id = d.department_id JOIN jobs j ON j.job_id = e.job_id; -- 使用视图 SELECT * FROM view1 WHERE last_name LIKE '%a%'; -- 2.查询各部门的平均工资级别 CREATE VIEW view2 AS SELECT AVG(salary) a,department_id FROM employees GROUP BY department_id; -- 使用视图 SELECT view2.a,g.grade_level FROM view2 JOIN job_grades g ON view2.a BETWEEN g.lowest_sal AND g.hightest_sal; -- 3.查询平均工资最低的部门信息 SELECT * FROM view2 ORDER BY a LIMIT 1; /*视图的好处: 1.重用sql语句 2.简化复杂的sql操作,不必知道它的查询细节 3.保护数据,提高安全性 */ ##视图的修改 /* 方式1: create or replace 视图名 as 查询语句 方式2: alter view 视图名 as 查询语句 */ #删除视图 DROP VIEW view1,view2,view3; #查看视图 DESC view1; SHOW CREATE VIEW view_name G #视图的更新 /* 视图的可更新性和视图中查询的定义有关系,以下类型的视图是不能更新的。 ① 包含以下关键字的sql语句:分组函数、distinct、group by having union或者union all ② 常量视图 ③ Select中包含子查询 ④ join ⑤ from一个不能更新的视图 ⑥ where子句的子查询引用了from子句中的表 */ #视图和表的区别 /* 创建语法的关键字 是否实际占用物理空间 使用 视图 create view 没有(只保存了sql逻辑) 增删改查,一般不做增删改,只做查询 表 create table 占用(保存了数据) 可以增删改查 */ #delete和truncate在事务使用时的区别 -- truncate 不可以回滚的 -- delete是可以回滚的
##变量 /* 系统变量: 会话变量 作用域:针对于当前的会话连接有效 全局变量 1.查看所有的全局变量 查看全局的 show global variables; 2.查看满足条件的部分全局变量 show show global variables like '%char%'; 3.查看指定的某个全局变量的值 select @@global.系统变量名; select @@global.autocommit; 4.为某个全局变量赋值 set @@global.系统变量名 = 值; select @@global.autocommit = 0; -- 跨连接有效 作用域:服务器每次启动将会为所有的全局变量赋初始值,针对于所有的的会话都有效 但是不能夸重写 系统变量使用语法:1.查看所有的系统变量 查看全局的 show global variables; 查看会话的 show session variables;(session可以不写) 2.查看满足条件的部分系统变量 show show global|session variables like '%char%'; 3.查看指定的某个系统变量的值 select @@global|【session】系统变量名; 4.为某个系统变量赋值 方式一: set global|【session】.系统变量名 = 值; 方式二: set @@global|【session】.系统变量名 = 值; 注意: 如果是全局级别,则需要加global,如果是会话级别,则需要加session,如果不写,则默认session 自定义变量:变量是用户自定义的,不是由系统的 用户变量: 作用域:针对当前会话有效,同于会话变量的作用域 应用在任何地方,也就是begin end里面或者外面 声明并初始化: ① set @用户变量名 = 值; ② set @用户变量名:= 值; ③ select @用户变量名: = 值; 赋值: ① set @用户变量名 = 值; ② set @用户变量名:= 值; ③ select @用户变量名: = 值; ④ select 字段 into 变量名 from 表; 使用: (查看用户变量的值) select @用户变量名; 局部变量 作用域:仅仅定义在begin end中有效 应用在begin end中的第一句话 声明初始化: declare 变量名 类型; declare 变量名 类型 default 值; 赋值: ① set 局部变量名 = 值; ② set 局部变量名:= 值; ③ select @局部变量名: = 值; ④ select 字段 into 局部变量名 from 表; 使用: (查看局部变量的值) select 局部变量名; */ /* 对比用户变量和局部变量 作用域 定义和使用的位置 语法 用户变量 当前会话 会话中的任何地方 必须加@符号,不用限定类型 局部变量 begin end中 只能在begin end中,且为第一句话 一般不用加@符号,需要限定类型 */ -- 案例:声明两个变量并赋值初始化,求和,并打印 -- 用户变量 SET @m = 1; SET @n = 2; SET @sum = @m+@n; SELECT @sum; -- 局部变量 下面写的会报错的,权限不够 DECLARE m INT DEFAULT 1; DECLARE n INT DEFAULT 2; DECLARE SUM INT ; SET SUM = n+m;
#存储过程 /* 含义:一组预先编译好的sql语句集合,理解成批处理语句 ①提高代码的重用性 ②简化操作 ③减少了编译次数并且减少了和数据库服务器连接次数,提高了效率 存储过程: 可以有0个返回,也可以有多个返回,适合做批量插入,批量更新 函数: 有且仅有一个返回适合做处理数据后返回一个结果 */ #1.创建语法 CREATE PROCEDURE 存储过程名(参数列表) BEGIN 存储过程体(一组合法的sql语句) END /* 注意:参数列表包含三部分 参数模式 in:该参数可以作为输入,也就是该参数需要调用方传入值 out :该参数可以作为输出,也就是可以作为返回值 intout: 该参数既可以作为输入又可以作为输出,即需要传入值,又可以返回值 2.如果存储过程仅仅只有一句话,begin end可以省略 3.存储过程体中的每条SQL语句的结尾必须加分号,存储过程的结尾可以使用delimiter重新设置 4.语法: delimiter 结束标记 delimiter $ 调用语法: call存储过程名(实参列表) 参数名 参数类型 */ /* 修改存储过程: alter procedure 存储过程名 [charactristic…] 修改函数: alter function 函数名 [charactristic…] 说明:一次只能删除一个存储过程或者函数,并且要求有该 过程或函数的alter routine 权限 删除存储过程: drop procedure [if exists] 存储过程名 删除函数: drop function [if exists] 函数名 1. 查看存储过程或函数的状态: show {procedure|function} status like 存储过程或函数名 2. 查看存储过程或函数的定义: show create {procedure|function} 存储过程或函数名 3. 通过查看 information_schema.routines 了解存储过程和函数的信息(了解) select * from rountines where rounine_name =存储过程名|函数名 */ #创建函数 -- 创建语法: CREATE FUNCTION 函数名(参数列表) RETURN 返回类型 BEGIN 函数体 END /* 注意: 1.参数列表包含两部分: 参数名 参数类型 2.函数体:肯定会有return语句,如果没有回报错 如果return没有放在函数体的最后也不会报错,但是不建议。 3.函数体中仅有一句话,则可以省略begin end 4.使用delimiter语句设置结束语句 */ #调用语法: SELECT 函数名(参数列表)
case结构——作为表达式

case结构——作为独立的语句
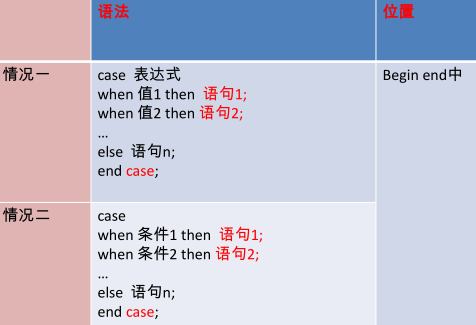
循环结构