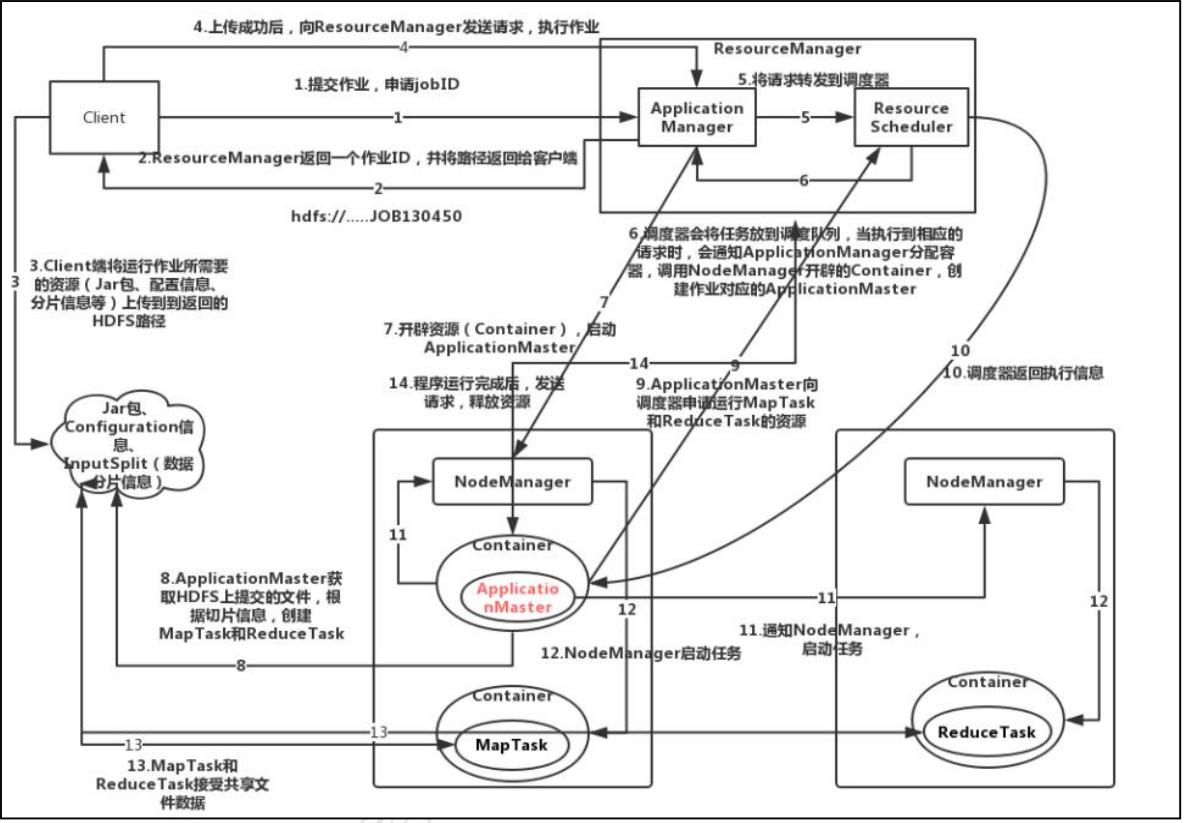
当Client申请作业后,Resource Scheduler会进行调度,同时开启Map Task 和Reduce Task
测试一:mapper->reducer
##数据量<80Mb,在mapper端不设置combiner
若不设置combiner,经过map之后的文件数据将直接到达reduce
代码如下:
public void analyzeByBrowserAndEvent() throws IOException, ClassNotFoundException, InterruptedException {
final String[] params = {
"192.168.142.192","/tmp/test/mylog1.log","/tmp/browser2"
};
Configuration conf = new Configuration();
conf.set("fs.defaultFS",MessageFormat.format("hdfs://{0}:9000",params[0]));
deleteOnExist(conf,params[2]);
Job job = Job.getInstance(conf,"countByBrowserAndEvent");
job.setMapperClass(EBMapper.class);
job.setReducerClass(EBReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(params[1]));
FileOutputFormat.setOutputPath(job,new Path(params[2]));
System.out.println(job.waitForCompletion(true));
}
测试结果:
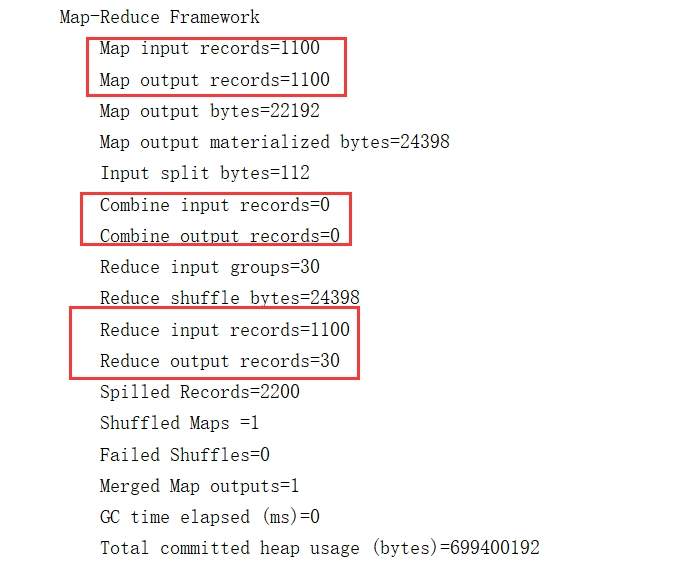
结论:即使不设置combiner进行归并排序,在reduce端也会进行一次归并排序的过程
测试二:mapper端设置combiner
#数据量<80Mb
结果如下:
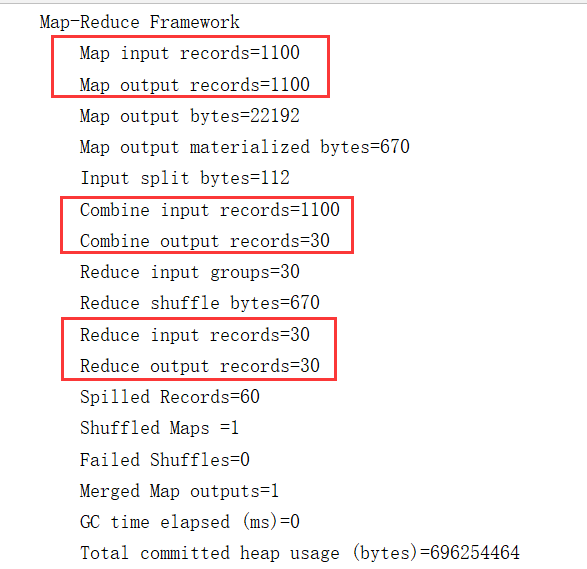
结论:当mapper端设置了combiner之后,数据的归并与排序将在mapper端完成,而reduce的作用为落盘
测试三:mapper端设置combiner且文件片的大小大于80Mb
#由于文件大于80Mb,经过环形缓冲区后溢出的小文件数量将至少2个
结果如下:
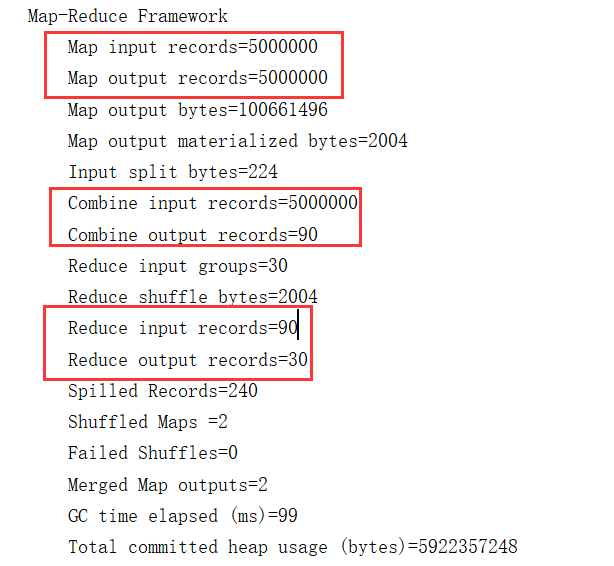
发现在设置了combiner之后,reduce端还是会进行一次归并,证明经过了环形缓冲区后溢出的文件数量不为1时,归并是不完全的
查找资料,分析如下:
Combiner是在Map端被执行,共有两个时机会被触发:
① 从环形缓冲器溢写分区文件的时候
② 合并溢写分区文件的时候
第一次为文件从环形缓冲区溢出的时候,由于环形缓冲区的默认size:100M,当到达80%就会进行溢出,对于每一个溢出的小文件,可以进行一次归并排序,但是对于只有一条记录的情况,combiner将不会被触发
源码如下:
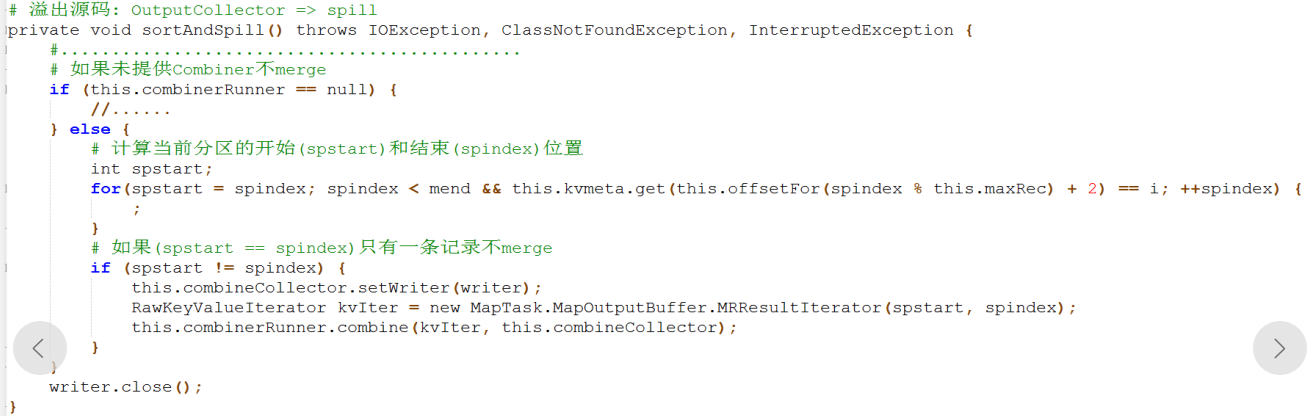
第二次为合并所有的溢出分区文件时,当溢出的文件数量小于规定的数量时,亦不满足第二次的combiner触发条件
源码如下:
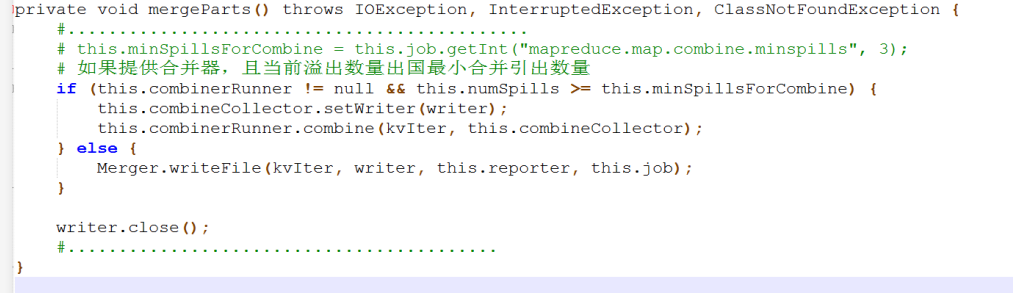
结论:本次测试,虽然设置了combiner,但是只能满足第一个触发条件,即对每一个溢出的文件进行了归并,但是当合并所有的溢出分区文件时,并没有进行第二次合并
参考博客:https://www.iteye.com/blog/heipark-1992419