Reference:https://time.geekbang.org/column/article/121710
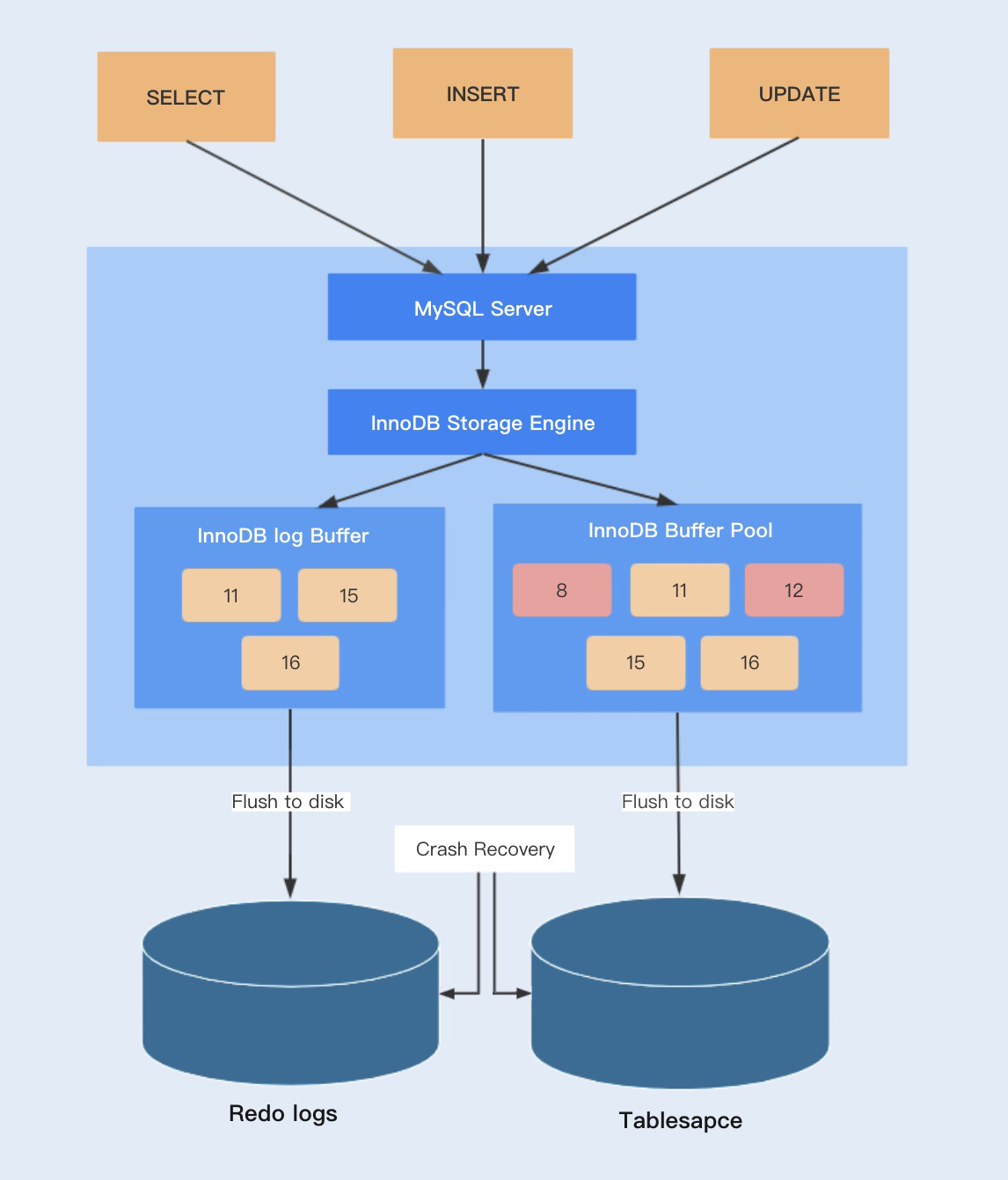
InnoDB是一个事务性的存储引擎,而InnoDB的事务实现是基于事务日志redo log和undo log实现的。
redo log是重做日志,提供再写入操作,实现事务的持久性;undo log是回滚日志,提供回滚操作,保证事务的一致性。
redo log又包括了内存中的日志缓冲(redo log buffer)以及保存在磁盘的重做日志文件(redo log file),前者存储在内存中,容易丢失,后者持久化在磁盘中,不会丢失。
InnoDB的更新操作采用的是Write Ahead Log策略,即先写日志,再写入磁盘。当一条记录更新时,InnoDB会先把记录写入到redo log buffer中,并更新内存数据。可以通过参数innodb_flush_log_at_trx_commit自定义commit时,如何将redo log buffer中的日志刷新到redo log file中。
在这里,需要注意的是InnoDB的redo log的大小是固定的,分别有多个日志文件采用循环方式组成一个循环闭环,当写到结尾时,会回到开头循环写日志。可以通过参数innodb_log_files_in_group和innodb_log_file_size配置日志文件数量和每个日志文件的大小。
Buffer Pool中更新的数据未刷新到磁盘中,该内存页称之为脏页。最终脏页的数据会刷新到磁盘中,将磁盘中的数据覆盖,这个过程与redo log不一定有关系。
只有当redo log日志满了的情况下,才会主动触发脏页刷新到磁盘,而脏页不仅只有redo log日志满了的情况才会刷新到磁盘,以下几种情况同样会触发脏页的刷新:
- 系统内存不足时,需要将一部分数据页淘汰掉,如果淘汰的是脏页,需要先将脏页同步到磁盘;
- MySQL认为空闲的时间,这种情况没有性能问题;
- MySQL正常关闭之前,会把所有的脏页刷入到磁盘,这种情况也没有性能问题。
在生产环境中,如果开启了慢SQL监控,会发现偶尔会出现一些用时稍长的SQL。这是因为脏页在刷新到磁盘时可能会给数据库带来性能开销,导致数据库操作抖动。