原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/12832908.html
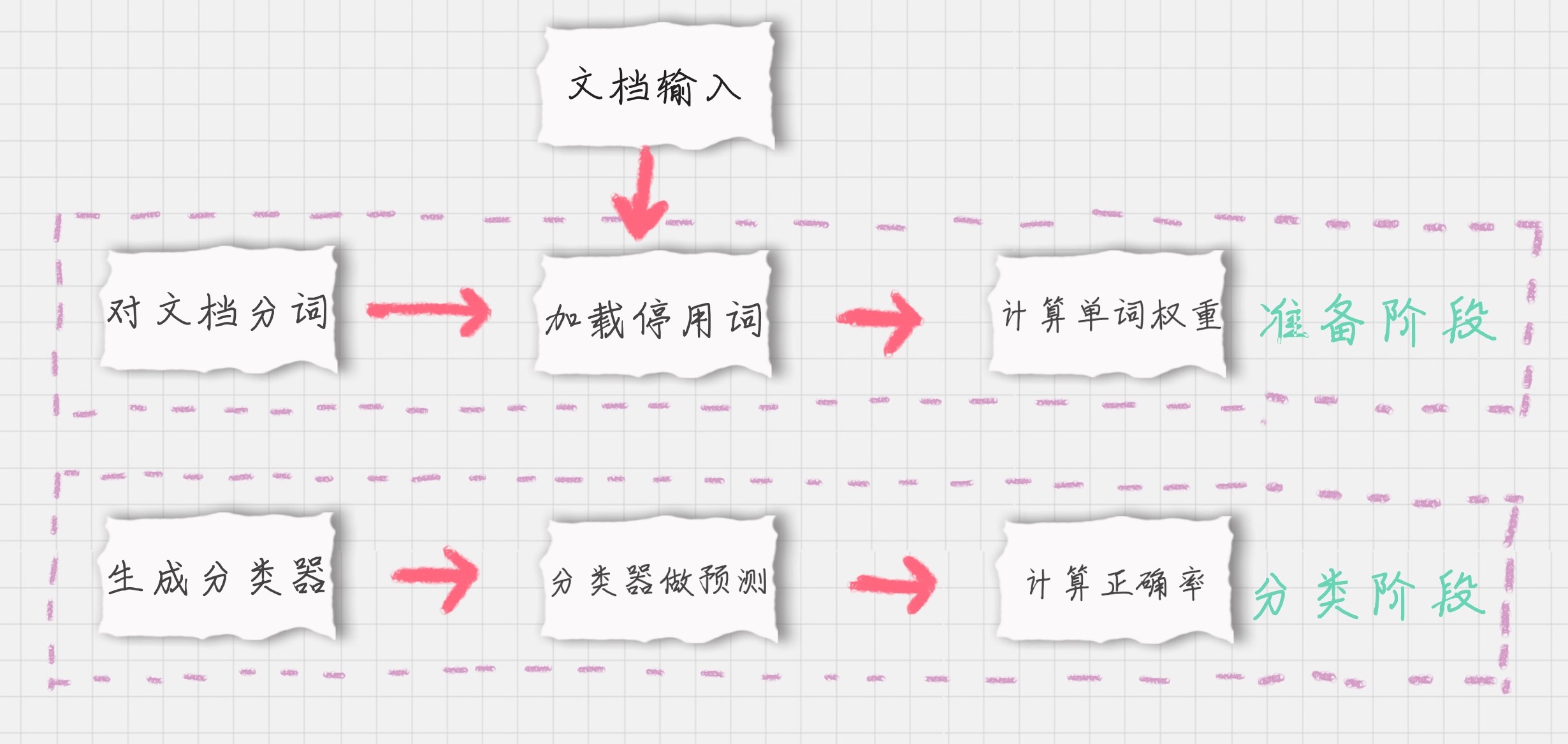
过程划分
- 基于分词的数据准备,包括分词、单词权重计算、去掉停用词;
- 应用朴素贝叶斯分类进行分类,首先通过训练集得到朴素贝叶斯分类器,然后将分类器应用于测试集,并与实际结果做对比,最终得到测试集的分类准确率。
导入文档
参考 https://github.com/cystanford/text_classification/tree/master/text%20classification,下载后将整个目录导入工程目录即可
准备数据
import os import jieba from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB def cut_words(file_path): """ 对文本进行切词 :param file_path: txt文本路径 :return: 用空格分词的字符串 """ text_with_spaces = '' with open(file_path, 'r', encoding='gb18030') as f: text = f.read() textcut = jieba.cut(text) for word in textcut: text_with_spaces += word + ' ' return text_with_spaces def load_file(file_dir, label): """ 将路径下的所有文件加载 :param file_dir: 保存txt文件目录 :param label: 文档标签 :return: 分词后的文档列表和标签 """ file_list = os.listdir(file_dir) words_list = [] labels_list = [] for file in file_list: file_path = file_dir + '/' + file words_list.append(cut_words(file_path)) labels_list.append(label) return words_list, labels_list # 训练数据 train_words_list1, train_labels1 = load_file('text_classification/train/女性', '女性') train_words_list2, train_labels2 = load_file('text_classification/train/体育', '体育') train_words_list3, train_labels3 = load_file('text_classification/train/文学', '文学') train_words_list4, train_labels4 = load_file('text_classification/train/校园', '校园') train_words_list = train_words_list1 + train_words_list2 + train_words_list3 + train_words_list4 train_labels = train_labels1 + train_labels2 + train_labels3 + train_labels4 # 测试数据 test_words_list1, test_labels1 = load_file('text_classification/test/女性', '女性') test_words_list2, test_labels2 = load_file('text_classification/test/体育', '体育') test_words_list3, test_labels3 = load_file('text_classification/test/文学', '文学') test_words_list4, test_labels4 = load_file('text_classification/test/校园', '校园') test_words_list = test_words_list1 + test_words_list2 + test_words_list3 + test_words_list4 test_labels = test_labels1 + test_labels2 + test_labels3 + test_labels4
对文档进行分词
在准备阶段里,最重要的就是分词。在中文文档中,最常用的是 jieba 包。jieba 包中包含了中文的停用词 stop words 和分词方法。
e.g.
import jieba word_list = jieba.cut(text)
英文文档和中文文档所使用的分词工具不同。在英文文档中,最常用的是 NTLK 包。NTLK 包中包含了英文的停用词 stop words、分词和标注方法。
e.g.
import nltk # 分词 word_list = nltk.word_tokenize(text) # 标注单词的词性 nltk.pos_tag(word_list)
加载停用词表
with open('text_classification/stop/stopword.txt', 'r', encoding='utf-8') as f: stop_words = f.read() # 列表头部处理 stop_words = stop_words.encode('utf-8').decode('utf-8-sig') # 根据分隔符分隔 stop_words = stop_words.split(' ')
计算单词的权重
# 计算单词权重 tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5) train_features = tf.fit_transform(train_words_list) test_features = tf.transform(test_words_list)
Note:
max_df 参数用来描述单词在文档中的最高出现率。假设 max_df=0.5,代表一个单词在 50% 的文档中都出现过了,那么它只携带了非常少的信息,因此就不作为分词统计。
一般很少设置 min_df,因为 min_df 通常都会很小。
生成朴素贝叶斯分类器
将特征训练集的特征空间 train_features,以及训练集对应的分类 train_labels 传递给贝叶斯分类器 clf,它会自动生成一个符合特征空间和对应分类的分类器。
这里采用的是多项式贝叶斯分类器,其中 alpha 为平滑参数。为什么要使用平滑呢?因为如果一个单词在训练样本中没有出现,这个单词的概率就会被计算为 0。但训练集样本只是整体的抽样情况,不能因为一个事件没有观察到,就认为整个事件的概率为 0。为了解决这个问题,需要做平滑处理。
当 alpha=1 时,使用的是 Laplace 平滑。Laplace 平滑就是采用加 1 的方式,来统计没有出现过的单词的概率。这样当训练样本很大的时候,加 1 得到的概率变化可以忽略不计,也同时避免了零概率的问题。
当 0<alpha<1 时,使用的是 Lidstone 平滑。对于 Lidstone 平滑来说,alpha 越小,迭代次数越多,精度越高。可以设置 alpha 为 0.001。
clf = MultinomialNB(alpha=0.001)
使用生成的分类器做预测
clf.fit(train_features, train_labels)
计算准确率
# score: 0.91 print('score:', clf.score(test_features, test_labels))