第三方库 requests是基于urllib编写的。比urllib库强大,非常适合爬虫的编写。
安装: pip install requests
简单的爬百度首页的例子:
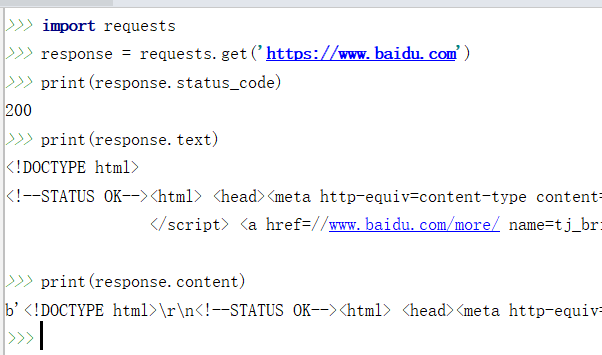
response.text 和 response.content的区别:
- response.text是解过码的字符串。比较容易出现乱码
- response.content 未解码的二进制格式(bytes). 适用于文本,图片和音乐。如果是文本,可以使用 response.content.decode('utf-8') 解码
requests 库支持的请求方法:
import requests requests.get("http://xxxx.com/") requests.post("http://xxxx.com/post", data = {'key':'value'}) requests.put("http://xxxx.com/put", data = {'key':'value'}) requests.delete("http://xxxx.com/delete") requests.head("http://xxxx.com/get") requests.options("http://xxxx.com/get")
发送带参数的get 请求:
在get方法里设置字典格式的params参数即可。requests 方法会自动完成url的拼接
import requests params = { "wd": "python", "pn": 10, } response = requests.get('https://www.baidu.com/s', params=params) print(response.url) print(response.text)
'''
需要设置header,百度会进行反爬验证
'''
发送带数据的post 请求:
只需要在post方法里设置data参数即可。 raise_for_status()会表示成功或失败
import requests post_data = {'username': 'value1', 'password': 'value2'} response = requests.post("http://xxx.com/login/", data=post_data) response.raise_for_status()
post 文件的例子:
>>> import requests >>> url = 'http://httpbin.org/post' >>> files = {'file': open('report.xls', 'rb')} >>> r = requests.post(url, files=files)
设置与查看请求头(headers):
很多网站有反爬机制,如果一个请求不携带请求头headers,很可能被禁止访问。
import requests headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/" "537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" } response1 =requests.get("https://www.baidu.com", headers=headers) response2 =requests.post("https://www.xxxx.com", data={"key": "value"}, headers=headers) print(response1.headers) print(response1.headers['Content-Type']) print(response2.text)
设置代理Proxy:
有的网站反爬机制会限制单位时间内同一IP的请求次数,我们可以通过设置 IP proxy代理来应对这个反爬机制。
import requests proxies = { "http": "http://10.10.1.10:3128", "https": "http://10.10.1.10:1080", } requests.get("http://example.org", proxies=proxies)
Cookie的获取和添加:
有时候我们需要爬取登录后才能访问的页面,这时我们就需要借助cookie来实现模拟登陆和会话维持了。
当用户首次发送请求时,服务器端一般会生成并存储一小段信息,包含在response数据里。如果这一小段信息存储在客户端(浏览器或磁盘),我们称之为cookie.如果这一小段信息存储在服务器端,我们称之为session(会话).这样当用户下次发送请求到不同页面时,请求自动会带上cookie,这样服务器就制定用户之前已经登录访问过了。
可以通过打印 response.cookies来获取查看cookie内容,从而知道首次请求后服务器是否生成了cookie.
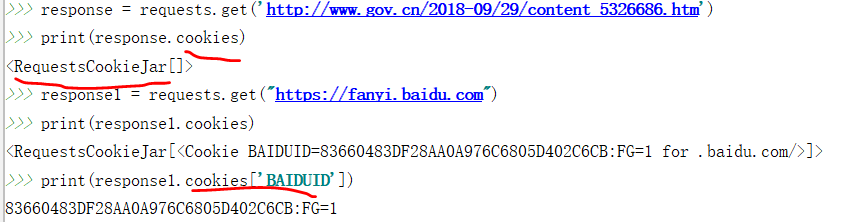
发送请求时添加cookie的方法:
- 设置cookies参数
import requests headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/" "537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" } cookies = {"cookie_name": "cookie_value", } response = requests.get("https://www.baidu.com", headers=headers, cookies=cookies) - 先实例化一个 RequestCookieJar的类,然后把值set进去,最后在get,post方法里面指定cookie参数

Session会话的维持:
session 与cookie不同,因为session一般存储在服务器端。session对象能够帮我们跨请求保持某些参数,也会在同一个session实例发出的所有请求之间保持cookies.
为了保持会话的连续,我们最好的办法是先创建一个session对象,用它打开一个url,而不是直接使用 request.get方法打开一个url.
每当我们使用这个session对象重新打开一个url时,请求头都会带上首次产生的cookie,实现了会话的延续。
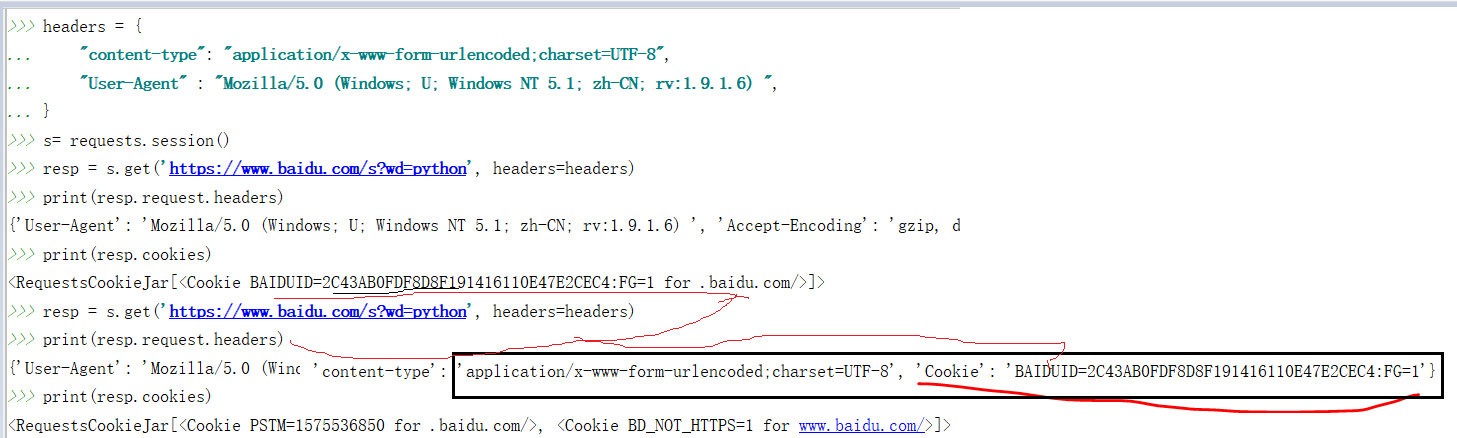
例子:
爬百度前20条搜索记录。(结果还是有点问题的,因为跳转的太多了,搜出不是对应的大条目)
#coding: utf-8 ''' 爬取百度搜索前20个搜索页面的标题和链接 ''' import requests import sys from bs4 import BeautifulSoup as bs import re import chardet headers = { 'Accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language':'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest' } def main(keyword): file_name = "{}.txt".format(keyword) f = open(file_name,'w+', encoding='utf-8') f.close() for pn in range(0,20,10): params = {'wd':keyword,'pn':pn} response = requests.get("https://www.baidu.com/s",params=params,headers=headers) soup = bs(response.content,'html.parser') urls = soup.find_all(name='a',attrs={"href": re.compile('.')}) for i in urls: if 'http://www.baidu.com/link?url=' in i.get('href'): a = requests.get(url=i.get('href'),headers=headers) print(i.get('href')) soup1 = bs(a.content,'html.parser') title = soup1.title.string with open(keyword+'.txt','r',encoding='utf-8') as f: if a.url not in f.read(): f = open(keyword+'.txt','a',encoding='utf-8') f.write(title + ' ') f.write(a.url + ' ') f.close() if __name__ == '__main__': keyword ='Django' main(keyword) print("下载完成")