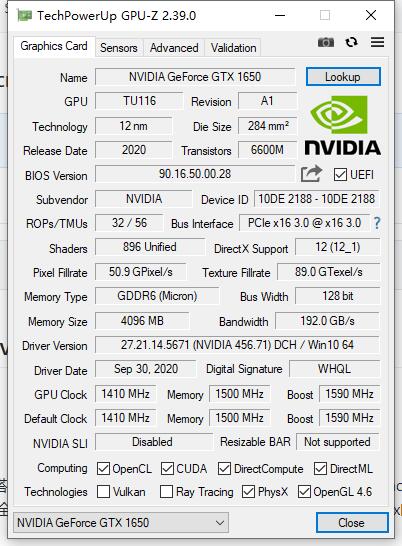
显卡:GTX 1650
cuda:cuda_10.1.105_418.96_win10
Python:
pip install paddlex -i https://mirror.baidu.com/pypi/simple
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install chardet -i https://mirror.baidu.com/pypi/simple
导出模型后运行
model = pdx.deploy.Predictor('D:paddlex_workspaceP0001-T0001_export_modelinference_model', use_gpu=False)
python predict.py
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv10.1extrasdemo_suite>deviceQuery.exe
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 1650"
CUDA Driver Version / Runtime Version 11.1 / 10.1
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 4096 MBytes (4294967296 bytes)
(14) Multiprocessors, ( 64) CUDA Cores/MP: 896 CUDA Cores
GPU Max Clock rate: 1590 MHz (1.59 GHz)
Memory Clock rate: 6001 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 1048576 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: zu bytes
Total amount of shared memory per block: zu bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: zu bytes
Texture alignment: zu bytes
Concurrent copy and kernel execution: Yes with 6 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.1, CUDA Runtime Version = 10.1, NumDevs = 1, Device0 = GeForce GTX 1650
Result = PASS
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv10.1extrasdemo_suite>bandwidthTest.exe
[CUDA Bandwidth Test] - Starting... Running on... Device 0: GeForce GTX 1650 Quick Mode Host to Device Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 12217.3 Device to Host Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 12734.4 Device to Device Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 161388.2 Result = PASS NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.