海量数据处理
分而治之
核心思想:
- 把数据分发到多个节点
- 移动计算到数据附近
- 计算节点进行本地数据处理
- 优选顺序,次之随机读
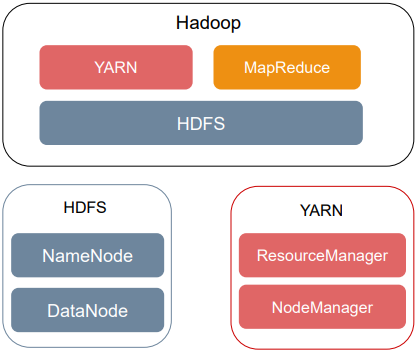
一、HDFS概述


修改,先删除,再重新生成
1.架构
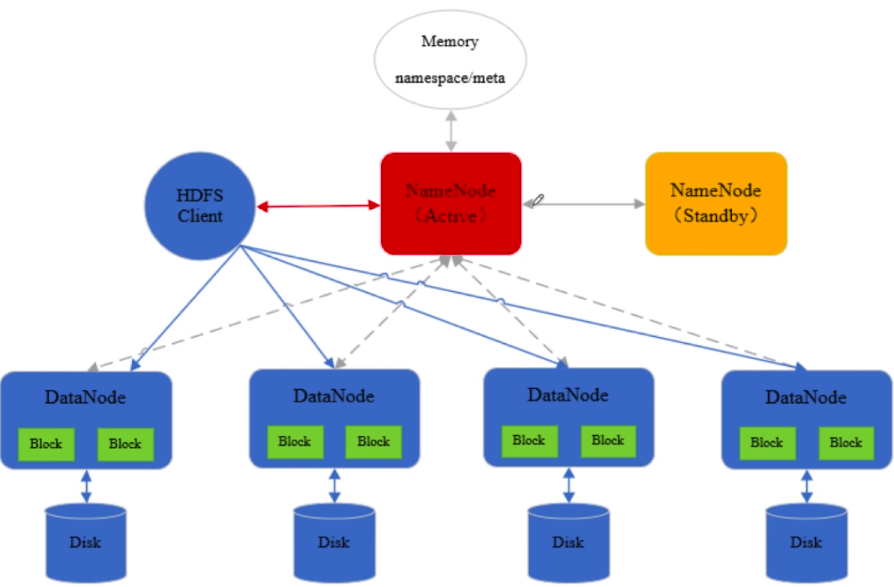
namenode维护着HDFS中存储的文件的元数据,以及每个文件块的列表,以及块所在datanode的信息。namenode会把元数据信息加载到内存中,管理副本数,默认副本是三个副本,每个block复制到多个datanode上存储。
通常启动两个namenode,active和standby。
Datanode真正数据块存储,执行客户端读写请求,datanode也会周期性的与namenode进行通信,汇报datanode上block的信息及其运行状态。
2.Active NameNode
- 主Master(只有一个)
- 管理HDFS文件系统的命名空间
- 维护文件元数据信息
- 管理副本策略,默认3个副本
- 处理客户端读写请求

HDFS文件系统和Linux文件系统非常相似,都是通过文件和目录管理的,所有目录和文件的层级关系可以看成一棵文件树。
由上图可知,namenode维护着文件系统树,及整棵树内所有的文件和目录,这些信息以命名空间镜像文件fsimage和编辑日志文件edits两种文件形式,永久保存在本地磁盘当中。
为了快速访问,在集群运行的时候,会把命名空间信息加载到内存当中。
namenode在内存中维护着文件的元数据,包括文件被切分成哪些块,每个块的副本数,生成时间,文件的权限,以及块所在的datanode位置的映射信息。这个映射信息并不保存到磁盘中,即fsimage当中不保存block块和datanode的映射关系。datanode周期性的向namenode发送心跳信息,汇报其存储的所有块的列表信息,namenode通过datanode上传列表信息,就会确保拥有最新的块映射信息。如果namenode重启,datanode向namenode汇报自己存储的block块的信息,namenode可以汇总datanode上存储的块信息,在内存中重建block和datanode的映射。
在HDFS中,某个datanode心跳超时,namenode就认为这个datanode不可用,就把该datanode标记为死亡,并且不会向这个标记为死亡的datanode转发任何新的读写请求,如果datanode这台机器被标记为死亡,存储的block块不可用,导致块的副本数低于正常水平,namenode会在适当的时候拷贝部分,使副本保持正常的水平。
namenode还负责处理客户端的读写请求,客户端从namenode获取元数据信息,再根据这些信息与datanode进行联系,进行数据块真正的读写操作。
3.NameNode元数据文件
NameNode启动的时候,会先将fsimage文件中的元数据加载到内存中,并执行编辑日志中的各项操作。一旦在内存中建立文件系统元数据的映像,则创建一个新的fsimage文件和一个空的edits文件,在这个过程中namenode运行在安全模式下。
系统中数据块的位置并不是由namenode维护的,而是以块列表的形势存储在datanode中,在安全模式中,datanode会向namenode发送最新的块列表信息,namenode在内存中建立一块和datanode的映射关系, namenode了解到足够多的块位置信息之后,namenode会对外提供服务。
在NameNode运行期间,客户端对HDFS的写操作都保存到edits文件中,久而久之edits文件会变得很大,虽然这对NameNode运行的时候是没有影响的,但是在NameNode重启的时候,NameNode先将fsimage中的内容映射到内存中,然后再一条一条执行edits编辑日志中的操作。当edits文件非常大的时候会导致namenode启动的时间非常漫长,而在这段时间中HDFS处于安全模式,所以需要在Namenode运行的时候将edits和fsimage定时进行合并,减小edits文件的大小。
- fsimage文件:是HDFS文件系统存于硬盘中的元数据检查点(即全量),里面记录了自最后一次检查点之前HDFS文件系统中所有目录和文件的序列化信息;
- edits log文件:保存了自最后一次检查点之后所有针对HDFS文件系统的操作(即增量),比如:增加文件、重命名文件、删除目录等等
NameNode定期将内存中的新增的edits与fsimage合并保存到磁盘。操作被记录到edits中,fsimage并不会同步记录操作,而是在namenode定期地设置检查点,到点将edits与fsimage进行合并,保存到磁盘当中,使fsimage定期的与内存中的元数据信息保持同步,这就保证了NameNode内存中保存一份最新的镜像信息,新的镜像内容=fsimage(旧的镜像内容)+edits(新增的信息)
4.DataNode
- Slave工作节点,可以启动多个
- 存储数据块
- 执行客户端的读写请求操作
- 通过心跳机制定期向NameNode汇报运行状态和所有块列表信息
- 在集群启动时DataNode向NameNode提供存储的Block块列表信息
5.Block数据块
- 文件写入到HDFS会被切分成若干个Block块
- 数据块大小固定,默认大小128MB,可自定义修改
- HDFS最小存储单元
- 若一个块的大小小于设置的数据块大小,则不会占用整个块的空间
- 默认情况下每个Block有三个副本
6.Client
- 文件切分
- 与NameNode交互获取文件元数据信息
- 与DataNode交互,读取或写入数据
- 管理HDFS
7.不适合存储小文件

8.Secondary NameNode和Standby NameNde
HDFS单NameNode,即没有配置高可用,会有Secondary NameNode
- Secondary NameNode负责每隔一段时间将旧的fsimage文件和edits log文件merge成新的fsimage并替换,即为NameNode 合并编辑日志edits log,减少 NameNode 启动时间;
-
非实时merge,一旦NameNode挂了,可能会导致元数据丢失;
高可用下会有Standby NameNode
- 实时merge,一旦前者挂了,后者能够马上顶上,不会出现元数据丢失;
- 同步edits编辑日志,定期合并fsimage与edits到本地磁盘
- Active NameNode故障快速切换为新的Active
二、高可用原理
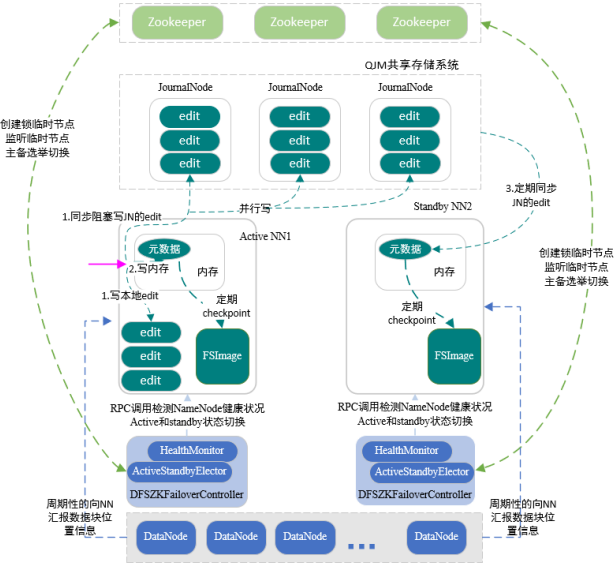
基于QJM的高可用机制
搭建Hadoop集群时,在三台及以上,一般奇数个机器上启动JournalNode,组成QJM共享存储系统,该系统非常轻量级,一般不会出现问题
一般会在两个namenode节点上启动两个JournalNode,在另一台节点上再启动一个JournalNode,这个系统里面存储edit log这个编辑日志
1.数据同步
通常启动两个namenode,一个active,一个standby
standbynamenode定期从QJM存储系统里同步activenamenode的元数据信息,使节点间元数据保持一致
active在处理客户端提交的创建文件,移除文件等写请求操作的时候,会首先把这些记录,记录到edit编辑日志中,同时也会同步阻塞并行的向JorunalNode集群中每一个JournalNode发送写请求,大多数Journalnode节点写成功,就认为整个集群写入edit成功了,最后修改内存中的元数据
actice会定对内存中的文件系统命名空间元数据信息创建检查点,在磁盘中生成fsimage镜像文件,持久化存储,另外一个standbynamenode定期从Journalnode集群中同步编辑日志edit,回放到其内存中,也会定期对内存中的元数据信息创建检查点,在磁盘中生成fsimage文件,持久化存储。
2.主备切换
主要使用主备切换控制器,ZKFC
当启动namenode的时候,也会在namenode所在的节点上启动ZKFC守护进程,作为主备切换的控制器,ZKFC启动时,会创建HealthMonitor和ActiveStandbyElector两个组件,前者循环检查namenode健康状况,后者使用zookeeper完成主备的选举。
在HDFS集群启动时,每个namenode对应一个ZKFC,每个ZKFC启动一个ActiveStandbyElector
每次启动时,都会尝试在zookeeper中创建临时锁节点,利用zookeeper写一致性保证最终只有一个activeelector创建锁节点成功。不管ActiveElector在zookeeper上是否创建成功临时锁节点,都会随后向zookeeper来注册监听事件,监听临时锁节点的删除事件
三、 HDFS文件写入流程
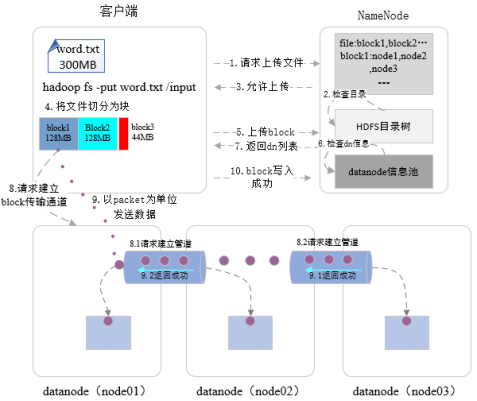
首先与namenode进行通信,创建远程的RPC请求,发起创建文件的请求,namenode接收到请求后,执行对新建文件的各种检查,以确保文件是不存在的,以及客户端有创建新文件的权限。所有检查结束后,返回运行写文件的消息。客户端接收到消息后,会把数据流式的写到客户端本地文件系统临时文件中,当临时文件大小达到block块大小(默认128M)的时候,客户端再次向namenode发送上传block块的请求,namenode根据请求在datanode信息池里检查datanode的状态,把存储block的datanode列表,包括备份节点的datanode返回给客户端
客户端接收到该列表,创建第一个datanode连接,请求将这组datanode列表构建成信息流通道
创建完数据流通道,客户端将以数据包的形式按照流式的方式写入到数据文档之中,首先将一个数据包package写入到第一个datanode,node01上,当第一个datanode写磁盘的时候,从第一datanode,通过数据管道将数据包发送到第二个datanode,第二个datanode开始写本地磁盘的时候,从第二个datanode发送数据包到第三个datanode,最后一个datanode写完之后,有确认信息,这个确认信息从保存了该数据包的节点通过管道(第9步)反馈给前一个节点,第二个节点反馈给第一个节点,第一个节点发送确认信息给客户端
等数据块传完之后,客户端发送最终的确认信息给namenode(第10步),第一数据块传输完成。
其他数据块重复上述4-10步
当整个文件写入完成被关闭时,namenode执行提交操作,从而使文件在集群中可见
四、读取流程
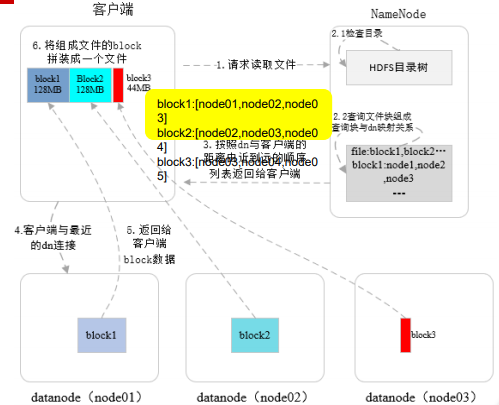
首先,客户端通过远程RPC调用,向namenode发送读文件请求(1),namenode接收到请求后,检查读取文件是否存在,检查客户端是否有读该文件的权限(2.1)
namenode从文件的元数据中查询这个文件是由哪些block块组成,这些block块存储在哪些datanode上(2.2)
检查通过后,返回给客户端(3),返回给客户端组成这个要读取文件的数据块列表 以及数据块所在datanode的位置
以及数据块所在datanode的位置
列表中datanode的顺序是按照与客户端的由近到远的顺序来排列的,即客户端访问哪个机器更快一些,哪个排在前面
客户端接收到namenode返回的信息后,创建与存储第一个块的最近的datanode连接
比如在node01上获取block1
datanode将block这个数据传输给客户端,如果访问的datanode出现故障,就会访问备份数据块的数据节点,直到数据块传输完成,关闭与该datanode的连接
然后寻找下一个数据块
直到整个文件合并完成
客户端只要读取连续的数据流即可,其他操作都是透明的,读取完成关闭连接
五、操作
1.Hadoop服务脚本

2.HDFS文件操作命令
hadoop fs: 使用面最广,可以操作任何文件系统。
hadoop dfs和hdfs dfs: 只能操作HDFS文件系统相关(包括与Local FS间的操作),hadoop dfs已经废弃,被hdfs dfs代替。
hadoop fs -ls 显示目录信息,递归-lsr
hadoop fs -mkdir /user/tguigu 在hdfs上创建目录
hadoop fs -moveFromlocal test.txt /user/tguigu/data 从本地剪切粘贴到hdfs
hadoop fs -appendTofile test.txt /user/tguigudata/test.txt 追加一个文件到已经存在的文件末尾
hadoop fs -cat 显示文件内容
hadoop fs -tail 显示一个文件的末尾
hadoop fs -cp /user/tguigu/../x.txt /user/tguigu/test../ 从hdfs的一个路径拷贝到hdfs的另一个路径
hadoop fs -mv /user/tguigu/../x.txt /.../ 在hdfs目录中移动文件
hadoop fs -get /user/tguigu/../x.txt ./ 等同于copyToLocal,就是从hdfs下载文件到本地
hadoop fs -getmerge /user/tguigu//test/* ./zaiyiqi.txt 合并下载多个文件
hadoop fs -put 等同于copyFromLocal上传
hadoop fs -rm 删除文件或文件夹
hadoop fs -rm -r 递归删除
hadoop fs -rmdir 删除空目录
hadoop fs -df 统计文件系统的可用空间
hadoop fs -du 统计文件的大小信息
hadoop fs -setrep 设置hdfs中文件的副本量数
3.HDFS API
public class HDFSClient { /** * 获取HDFS文件系统对象 * @return * @throws IOException */ private FileSystem getFileSystem() throws IOException { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf);//创建hdfs文件系统对象 return fs; } /** * 读取hdfs中的文件内容 * @param hdfsFilePath */ public void readHDFSFile(String hdfsFilePath){ BufferedReader reader = null; FSDataInputStream fsDataInputStream = null; //通过HDFS Java API读取HDFS中的文件 try { Path path = new Path(hdfsFilePath); fsDataInputStream = this.getFileSystem().open(path);//根据path创建FSDataInputStream输入流对象 reader = new BufferedReader(new InputStreamReader(fsDataInputStream)); String line = ""; while((line = reader.readLine()) != null){ System.out.println(line); } } catch (IOException e) { e.printStackTrace(); } finally { try { if (fsDataInputStream != null) { fsDataInputStream.close(); } if (reader != null) { reader.close(); } }catch (IOException e) { e.printStackTrace(); } } } /** * 将本地文件内容写入到HDFS指定文件中 * @param localFilePath * @param hdfsFilePath */ public void writeHDFSFile(String localFilePath,String hdfsFilePath){ FSDataOutputStream fsDataOutputStream = null; FileInputStream fileInputStream = null; Path path = new Path(hdfsFilePath); try { //根据path创建输出流对象 fsDataOutputStream = this.getFileSystem().create(path); //创建读取本地文件的输入流对象 fileInputStream = new FileInputStream(new File(localFilePath)); IOUtils.copyBytes(fileInputStream,fsDataOutputStream,4096,false); } catch (IOException e) { e.printStackTrace(); } finally { try { if (fsDataOutputStream != null){ fsDataOutputStream.close(); } if (fileInputStream != null){ fileInputStream.close(); } } catch (IOException e) { e.printStackTrace(); } } } public static void main(String[] ars) { String hdfsFilePath = "hdfs://ns/hdfs_client/from_local_2_hdfs.txt"; HDFSClient client = new HDFSClient(); // client.readHDFSFile(hdfsFilePath); String localFilePath = "/Users/derek/hdfstest.txt"; client.writeHDFSFile(localFilePath,hdfsFilePath); client.readHDFSFile(hdfsFilePath); } }