spark简介和生态系统
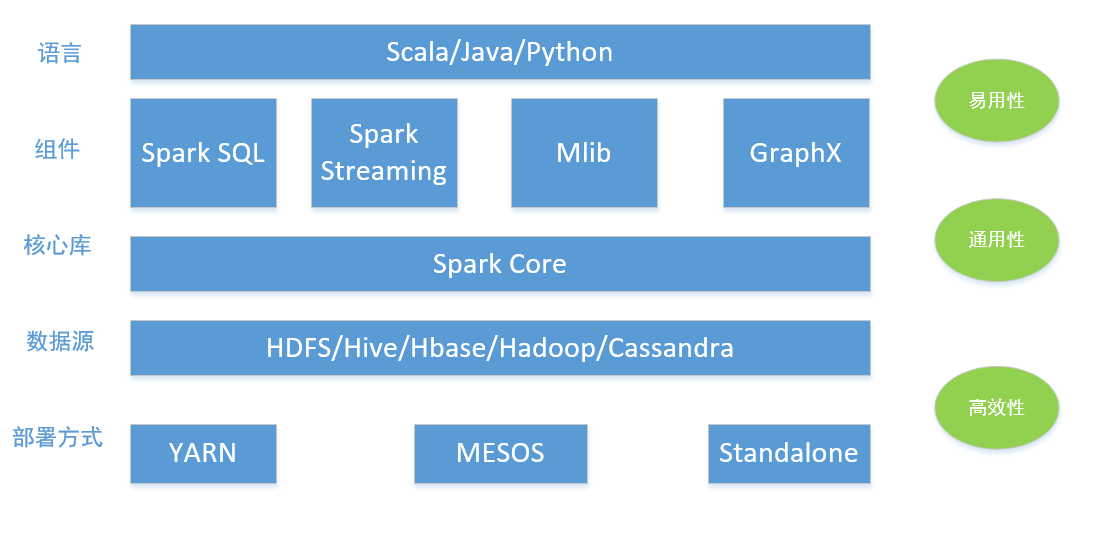
Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,相对对hadoop有如下特点
特点
- 运行速度快
Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据有磁盘读取,速度是MapReduce的10倍以上。如果数据从内存读取,速度可以高达100多倍。
- 易用性好
支持java、scala、python多语言进行应用程序的编写,同时提供众多高水平的函数进行数据集操作。
- 通用性强
提供众多组件,包括即席查询的Spark SQL和DataFrames、机器学习MLlib,图处理GraphX以及实时处理的Spark Streaming。
- 随处运行
Spark具有很强的适应性,能以Yarn,Mesos和自身的Standalone作为资源管理器调度job,同时也能够读取HDFS、Hbase、Cassandra、Hive、Tachyon读取数据
生态系统
Spark Core
Spark Core 提供了Spark最基础和最核心的功能,主要包括:
- SparkContext:通常而言,DriverApplication的执行与输出都是通过SparkContext完成的,在正式提交Application前,需要初始化SparkContext,SparkContext隐藏了网络通信、分布式部署、消息通信、存储能力、计算能力、缓存、文件服务、web服务等内容,应用开发者只需要使用SparkContext提供的API完成功能开发。SparkContext内置的DAGScheduler负责创建Job,将DAG中的RDD划分到不同的Stage,提交Stage等功能,内置的TaskScheduler负责资源的申请,任务的提交及请求集群对任务的调度等工作
- 存储体系:Spark优先使用各节点的内存作为存储,当内存不足时才会考虑使用磁盘,极大地减少磁盘I/O,提升了任务执行的效率,使得Spark适用于实时计算、流式计算等场景。此外还提供了以内存为中心的高容错的分布式文件系统Tachyon供用户选择
- 计算引擎:计算引擎由SparkContext中的DAGScheduler、RDD以及具体节点上的Executor负责执行的Map和Reduce任务组成。DAGScheduler和RDD虽然位于SparkContext内部,但是在任务正式提交与执行前将Job中的RDD组织成有向无环图(简称DAG)、并对Stage进行划分,决定了任务执行阶段任务的数量、迭代计算、shuffle等过程
- 部署模式:由于单节点不足以提供足够的存储及计算能力,所以spark在SparkContext的TaskScheduler组件中提供了对Standalone部署模式的实现和Yarn、Mesos等分布式资源管理系统的支持。通过使用Standalone、Yarn、Mesos等部署模式为Task分配计算资源,提高任务的并发执行效率。
Spark SQL
Spark SQL允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行查询,并进行更复杂的数据分析;
Spark Mlib
MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只要具备一定的理论知识就能进行机器学习的工作;
GraphX
GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写及优化,Graphx性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
适用场景
目前大数据处理场景有以下几个类型:
- 复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;
- 基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间
- 基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间
目前对以上三种场景需求都有比较成熟的处理框架,第一种情况可以用Hadoop的MapReduce来进行批量海量数据处理,第二种情况可以Impala进行交互式查询,对于第三中情况可以用Storm分布式处理框架处理实时流式数据。以上三者都是比较独立,各自一套维护成本比较高,而Spark的出现能够一站式平台满意以上需求。
通过以上分析,总结Spark场景有以下几个:
数据集大,反复操作次数越多,受益越大,数据量小计算密度大的场景,受益相对较小
由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合,如数据量不是特别大,但是要求实时统计分析需求。
关于作者
爱编程、爱钻研、爱分享、爱生活
关注分布式、高并发、数据挖掘
如需捐赠,请扫码
