基础概念
Spark Streaming 是 Spark Core API 的扩展, 它支持弹性的, 高吞吐的, 容错的实时数据流的处理. 数据可以通过多种数据源获取, 例如 Kafka, Flume, Kinesis 以及 TCP sockets, 也可以通过例如 map, reduce, join, window 等的高级函数组成的复杂算法处理. 最终, 处理后的数据可以输出到文件系统, 数据库以及实时仪表盘中. 事实上, 你还可以在 data streams(数据流)上使用 机器学习 以及 图计算 算法.

在内部, 它工作原理如下, Spark Streaming 接收实时输入数据流并将数据切分成多个 batch(批)数据, 然后由 Spark 引擎处理它们以生成最终的 stream of results in batches(分批流结果)。
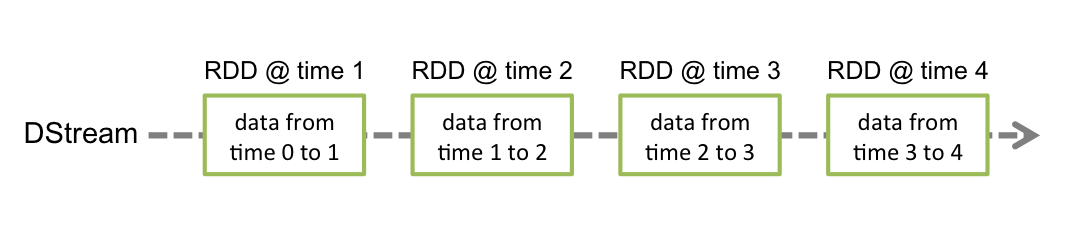
在内部, 它工作原理如下, Spark Streaming 接收实时输入数据流并将数据切分成多个 batch(批)数据, 然后由 Spark 引擎处理它们以生成最终的 stream of results in batches(分批流结果)。
依赖
Spark Streaming 可以通过 Maven 来管理依赖. 为了编写你自己的 Spark Streaming 程序,需要添加如下依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.2.0</version>
</dependency>
其他常见关联软件依赖包如下:
| Source | Artifact |
|---|---|
| Kafka | spark-streaming-kafka-0-8_2.11 |
| Flume | spark-streaming-flume_2.11 |
| Kinesis | spark-streaming-kinesis-asl_2.11 |
初始化StreamingContext
StreamingContext是Spark Streaming程序的主入口,可以通过SparkConf或者SparkContext创建:
-
通过SparkConf创建
import org.apache.spark._ import org.apache.spark.streaming._ val conf = new SparkConf().setAppName(appName).setMaster(master) val ssc = new StreamingContext(conf, Seconds(1)) -
通过SparkContext创建
-
import org.apache.spark.streaming._ val sc = ... // 已存在的 SparkContext val ssc = new StreamingContext(sc, Seconds(1))
StreamingContext定义完成后,可以执行以下操作.
- 通过创建输入 DStreams 来定义输入源.
- 通过应用转换和输出操作 DStreams 定义流计算(streaming computations).
- 开始接收输入并且使用 streamingContext.start() 来处理数据.
- 使用 streamingContext.awaitTermination() 等待处理被终止(手动或者由于任何错误).
- 使用 streamingContext.stop() 来手动的停止处理.
需要注意的是StreamingContext定义完成后
- 一旦一个 context 已经启动,将不会有新的数据流的计算可以被创建或者添加到它。
- 一旦一个 context 已经停止,它不会被重新启动.
- 同一时间内在 JVM 中只有一个 StreamingContext 可以被激活.
- 在 StreamingContext 上的 stop() 同样也停止了 SparkContext 。为了只停止 StreamingContext ,设置 stop() 的可选参数,名叫 stopSparkContext 为 false.
- 一个 SparkContext 就可以被重用以创建多个 StreamingContexts,只要前一个 StreamingContext 在下一个StreamingContext 被创建之前停止(不停止 SparkContext).
Discretized Streams (DStreams)(离散化流)
DStream 是 Spark Streaming 提供的基本抽象. 它代表了一个连续的数据流, 无论是从 source(数据源)接收到的输入数据流, 还是通过转换输入流所产生的处理过的数据流. 在内部, 一个 DStream 被表示为一系列连续的 RDDs, 它是 Spark 中一个不可改变的抽象, 在一个 DStream 中的每个 RDD 包含来自一定的时间间隔的数据,如下图所示.

应用于 DStream 的任何操作转化为对于底层的 RDDs 的操作. 例如,在 如下的示例,
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.StreamingContext._
object SocketWordCount {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
// 创建一个将要连接到 hostname:port 的 DStream,如 localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)
// 将每一行拆分成 words(单词)
val words = lines.flatMap(_.split(" "))
// 计算每一个 batch(批次)中的每一个 word(单词)
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// 在控制台打印出在这个离散流(DStream)中生成的每个 RDD 的前十个元素
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
转换一个行(lines)流成为单词(words)中,flatMap 操作被应用于在行离散流(lines DStream)中的每个 RDD 来生成单词离散流(words DStream)的 RDDs。
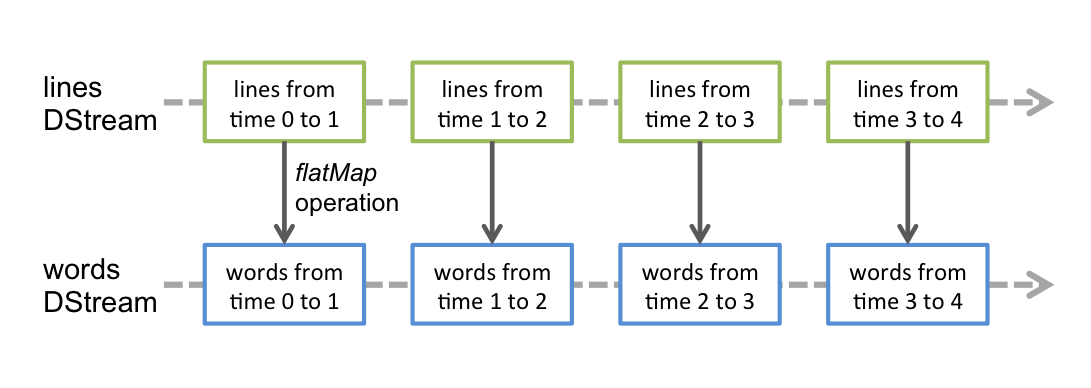
这些底层的 RDD 变换由 Spark 引擎(engine)计算。 DStream 操作隐藏了大多数这些细节并为了方便起见,提供给了开发者一个更高级别的 API 。这些操作细节会在后边的章节中讨论。
Input DStreams 和 Receivers(接收器)
输入 DStreams 是代表输入数据是从流的源数据(streaming sources)接收到的流的 DStream. 在 上个示例 中, lines 是一个 input DStream, 因为它代表着从 netcat 服务器接收到的数据的流. 每一个 input DStream(除了 file stream 之外, 会在本章的后面来讨论)与一个 Receiver (Scala doc, Java doc) 对象关联, 它从 source(数据源)中获取数据,并且存储它到 Spark 的内存中用于处理.
Spark Streaming 提供了两种内置的 streaming source(流的数据源).
- Basic sources(基础的数据源): 在 StreamingContext API 中直接可以使用的数据源. 例如: file systems 和 socket connections.
- Advanced sources(高级的数据源): 像 Kafka, Flume, Kinesis, 等等这样的数据源. 可以通过额外的 utility classes 来使用。
如果你想要在你的流处理程序中并行的接收多个数据流, 你可以创建多个 input DStreams(在 性能优化 部分进一步讨论). 这将创建同时接收多个数据流的多个 receivers(接收器). 但需要注意,一个 Spark 的 worker/executor 是一个长期运行的任务(task),因此它将占用分配给 Spark Streaming 的应用程序的所有核中的一个核(core). 因此,要记住,一个 Spark Streaming 应用需要分配足够的核(core)(或线程(threads),如果本地运行的话)来处理所接收的数据,以及来运行接收器(receiver(s)).
基础数据源
socket
应用从监听的端口中读取数据,
def socketStream[T: ClassTag](
hostname: String,
port: Int,
converter: (InputStream) => Iterator[T],
storageLevel: StorageLevel
): ReceiverInputDStream[T]
具体实例参考第一个例子,不再赘述。
文件
用于从文件中读取数据,在任何与 HDFS API 兼容的文件系统中(即,HDFS,S3,NFS 等),一个 DStream 可以像下面这样创建:
def fileStream[
K: ClassTag,
V: ClassTag,
F <: NewInputFormat[K, V]: ClassTag
] (directory: String): InputDStream[(K, V)]
Spark Streaming 将监控dataDirectory 目录并且该目录中任何新建的文件 (写在嵌套目录中的文件是不支持的). 注意
- 文件必须具有相同的数据格式.
- 文件必须被创建在 dataDirectory 目录中, 通过moving或 renaming它们到数据目录.
- 一旦移动,这些文件必须不能再更改,因此如果文件被连续地追加,新的数据将不会被读取.
对于简单的文本文件,还有一个更加简单的方法 streamingContext.textFileStream(dataDirectory). 并且文件流(file streams)不需要运行一个接收器(receiver),因此,不需要分配内核(core)。
实例如下:
object FileWordCount {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName("FileWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.textFileStream("/home/spark/temp")
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
基于自定义的接收器的流
DStreams 可以使用通过自定义的 receiver(接收器)接收到的数据来创建。
如下CustomReceiver通过继承org.apache.spark.streaming.receiver.Receiver类,并重写onStart()、onStop()、receive()方法来达到类似监听
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import java.nio.charset.StandardCharsets
import org.apache.spark.SparkConf
import org.apache.spark.internal.Logging
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.receiver.Receiver
class CustomReceiver(host: String, port: Int)
extends Receiver[String](StorageLevel.MEMORY_AND_DISK_2) with Logging {
def onStart() {
// Start the thread that receives data over a connection
new Thread("Socket Receiver") {
override def run() {
receive()
}
}.start()
}
def onStop() {
// There is nothing much to do as the thread calling receive()
// is designed to stop by itself isStopped() returns false
}
/** Create a socket connection and receive data until receiver is stopped */
private def receive() {
var socket: Socket = null
var userInput: String = null
try {
logInfo("Connecting to " + host + ":" + port)
socket = new Socket(host, port)
logInfo("Connected to " + host + ":" + port)
val reader = new BufferedReader(
new InputStreamReader(socket.getInputStream(), StandardCharsets.UTF_8))
userInput = reader.readLine()
while (!isStopped && userInput != null) {
store(userInput)
userInput = reader.readLine()
}
reader.close()
socket.close()
logInfo("Stopped receiving")
restart("Trying to connect again")
} catch {
case e: java.net.ConnectException =>
restart("Error connecting to " + host + ":" + port, e)
case t: Throwable =>
restart("Error receiving data", t)
}
}
}
自定义接收器完成后,其使用则和自带的数据源接收器一致,如下:
object CustomReceiver {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: CustomReceiver <hostname> <port>")
System.exit(1)
}
// Create the context with a 1 second batch size
val sparkConf = new SparkConf().setAppName("CustomReceiver")
val ssc = new StreamingContext(sparkConf, Seconds(1))
// Create an input stream with the custom receiver on target ip:port and count the
// words in input stream of
delimited text (eg. generated by 'nc')
val lines = ssc.receiverStream(new CustomReceiver(args(0), args(1).toInt))
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
RDDs 队列作为一个流
为了使用测试数据测试 Spark Streaming 应用程序,还可以使用 streamingContext.queueStream(queueOfRDDs) 创建一个基于 RDDs 队列的 DStream,每个进入队列的 RDD 都将被视为 DStream 中的一个批次数据,并且就像一个流进行处理.
def queueStream[T: ClassTag](
queue: Queue[RDD[T]],
oneAtATime: Boolean = true
): InputDStream[T]
def queueStream[T: ClassTag](
queue: Queue[RDD[T]],
oneAtATime: Boolean,
defaultRDD: RDD[T]
): InputDStream[T]
实例如下:
import scala.collection.mutable.Queue
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
object QueueStream {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("QueueStream")
// Create the context
val ssc = new StreamingContext(sparkConf, Seconds(1))
// Create the queue through which RDDs can be pushed to
// a QueueInputDStream
val rddQueue = new Queue[RDD[Int]]()
// Create the QueueInputDStream and use it do some processing
val inputStream = ssc.queueStream(rddQueue)
val mappedStream = inputStream.map(x => (x % 10, 1))
val reducedStream = mappedStream.reduceByKey(_ + _)
reducedStream.print()
ssc.start()
// Create and push some RDDs into rddQueue
for (i <- 1 to 30) {
rddQueue.synchronized {
rddQueue += ssc.sparkContext.makeRDD(1 to 1000, 10)
}
Thread.sleep(1000)
}
ssc.stop()
}
}
高级数据源
高级数据源需要使用非 Spark 库中的外部接口,它们中的其中一些还需要比较复杂的依赖关系(例如, Kafka 和 Flume). 因此,为了最小化有关的依赖关系的版本冲突的问题,这些资源本身不能创建 DStream 的功能,它是通过 依赖 单独的类库实现创建 DStream 的功能.相关集成见相关链接。
kafka:http://spark.apachecn.org/docs/cn/2.2.0/streaming-kafka-integration.html
flume:http://spark.apachecn.org/docs/cn/2.2.0/streaming-flume-integration.html
Receiver Reliability(接收器的可靠性)
可以有两种基于他们的 reliability可靠性 的数据源. 数据源(如 Kafka 和 Flume)允许传输的数据被确认. 如果系统从这些可靠的数据来源接收数据,并且被确认(acknowledges)正确地接收数据,它可以确保数据不会因为任何类型的失败而导致数据丢失. 这样就出现了 2 种接收器(receivers):
-
可靠的接收器 - 当数据被接收并存储在 Spark 中并带有备份副本时,一个可靠的接收器正确地发送确认通知给一个可靠的数据源。
-
不可靠的接收器- 一个不可靠的接收器不发送确认通知到数据源。这可以用于不支持确认的数据源,或者甚至是可靠的数据源当你不想或者不需要进行复杂的确认的时候.
DStreams 上的 Transformations(转换)
基本操作
transformation 允许从 input DStream 输入的数据做修改. DStreams 支持很多在 RDD 中可用的 transformation 算子。一些常用的如下所示 :
| Transformation | Meaning |
|---|---|
| map(func) | Return a new DStream by passing each element of the source DStream through a function func. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items. |
| filter(func) | Return a new DStream by selecting only the records of the source DStream on which func returns true. |
| repartition(numPartitions) | Changes the level of parallelism in this DStream by creating more or fewer partitions. |
| union(otherStream) | Return a new DStream that contains the union of the elements in the source DStream and otherDStream. |
| count() | Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
| reduce(func) | Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func (which takes two arguments and returns one). The function should be associative and commutative so that it can be computed in parallel. |
| countByValue() | When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. |
| reduceByKey(func, [numTasks]) | When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the
values for each key are aggregated using the given reduce function. Note: By default,
this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number
is determined by the config property spark.default.parallelism) to do the grouping.
You can pass an optional numTasks argument to set a different number of tasks. |
| join(otherStream, [numTasks]) | When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
| cogroup(otherStream, [numTasks]) | When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. |
| transform(func) | Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
| updateStateByKey(func) | Return a new "state" DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key. |
updateStateByKey操作
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)]
updateStateByKey 操作允许您维护任意状态,同时不断更新新信息. 你需要通过两步来使用它.
- 定义 state - state 可以是任何的数据类型.
- 定义 state update function(状态更新函数) - 使用函数指定如何使用先前状态来更新状态,并从输入流中指定新值.
在每个 batch 中,Spark 会使用状态更新函数为所有已有的 key 更新状态,不管在 batch 中是否含有新的数据。如果这个更新函数返回一个none,这个 key-value pair 也会被消除.
假设你想保持在文本数据流中看到的每个单词的运行计数,运行次数用一个 state 表示,它的类型是整数, 我们可以使用如下方式来定义 update 函数:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}
这里是一个应用于包含 words(单词)的 DStream 上(也就是说,在 先前的示例中,该 pairs DStream 包含了 (word, 1) pair).
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)
update 函数将会被每个单词调用,newValues 拥有一系列的 1(来自 (word, 1) pairs),runningCount 拥有之前的次数.
请注意, 使用 updateStateByKey 需要配置的 checkpoint (检查点)的目录,这里是更详细关于讨论 checkpointing 的部分。
transform操作
transform 操作(以及它的变化形式如 transformWith)允许在 DStream 运行任何 RDD-to-RDD 函数. 它能够被用来应用任何没在 DStream API 中提供的 RDD 操作. 例如,连接数据流中的每个批(batch)和另外一个数据集的功能并没有在 DStream API 中提供,然而你可以简单的利用 transform 方法做到. 这使得有非常强大的可能性. 例如,可以通过将输入数据流与预先计算的垃圾邮件信息(也可以使用 Spark 一起生成)进行实时数据清理,然后根据它进行过滤.
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
val cleanedDStream = wordCounts.transform { rdd =>
rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning
...
}
请注意,每个 batch interval(批间隔)提供的函数被调用. 这允许你做随时间变动的 RDD 操作, 即 RDD 操作, 分区的数量,广播变量,等等. batch 之间等可以改变。
窗口操作
Spark Streaming支持窗口计算,允许在数据上的一个滑动窗口上应用transformation(转换)操作,
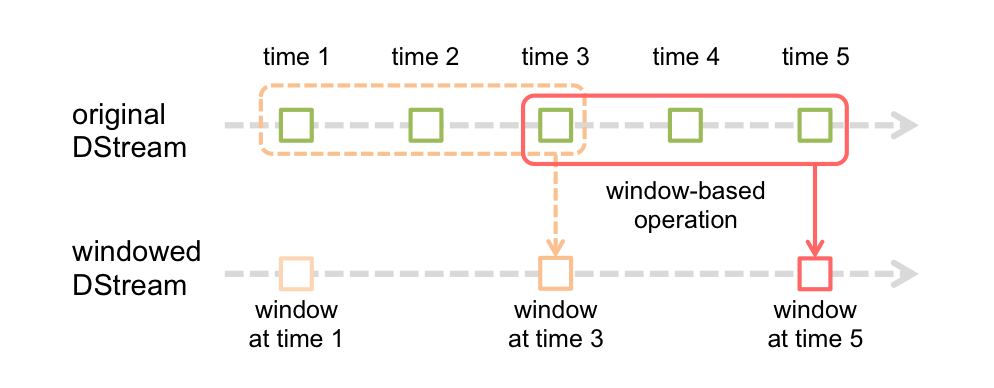
如上图显示,窗口在源 DStream 上滑动,合并和操作落入窗内的源 RDDs,产生窗口化的 DStream 的 RDDs。在这个具体的例子中,程序在三个时间单元的数据上进行窗口操作,并且每两个时间单元滑动一次。 这说明,任何一个窗口操作都需要指定两个参数.
- window length(窗口长度) - 窗口的持续时间(图 3).
- sliding interval(滑动间隔) - 执行窗口操作的间隔(图 2).
这两个参数必须是 source DStream 的 batch interval(批间隔)的倍数(图 1).
让我们举例以说明窗口操作. 例如,你想扩展前面的例子用来计算过去 30 秒的词频,间隔时间是 10 秒. 为了达到这个目的,我们必须在过去 30 秒的 (wrod, 1) pairs 的 pairs DStream 上应用 reduceByKey 操作. 用方法 reduceByKeyAndWindow 实现.
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
一些常用的窗口操作如下所示,这些操作都需要用到上文提到的两个参数 - windowLength(窗口长度) 和 slideInterval(滑动的时间间隔)。
| Transformation | Meaning |
|---|---|
| window(windowLength, slideInterval) | Return a new DStream which is computed based on windowed batches of the source DStream. |
| countByWindow(windowLength, slideInterval) | Return a sliding window count of elements in the stream. |
| reduceByWindow(func, windowLength, slideInterval) | Return a new single-element stream, created by aggregating elements in the stream over a sliding interval using func. The function should be associative and commutative so that it can be computed correctly in parallel. |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, V)
pairs where the values for each key are aggregated using the given reduce function func
over batches in a sliding window. Note: By default, this uses Spark's default number of
parallel tasks (2 for local mode, and in cluster mode the number is determined by the config
property spark.default.parallelism) to do the grouping. You can pass an optional
numTasks argument to set a different number of tasks.
|
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | A more efficient version of the above reduceByKeyAndWindow() where the reduce
value of each window is calculated incrementally using the reduce values of the previous window.
This is done by reducing the new data that enters the sliding window, and "inverse reducing" the
old data that leaves the window. An example would be that of "adding" and "subtracting" counts
of keys as the window slides. However, it is applicable only to "invertible reduce functions",
that is, those reduce functions which have a corresponding "inverse reduce" function (taken as
parameter invFunc). Like in reduceByKeyAndWindow, the number of reduce tasks
is configurable through an optional argument. Note that [checkpointing](#checkpointing) must be
enabled for using this operation.
|
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long) pairs where the
value of each key is its frequency within a sliding window. Like in
reduceByKeyAndWindow, the number of reduce tasks is configurable through an
optional argument.
|
object WindowWordCount {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName("WindowWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint(".")
val lines = ssc.socketTextStream("localhost", 9999, StorageLevel.MEMORY_ONLY_SER)
val words = lines.flatMap(_.split(","))
// 叠加处理
val wordCounts = words.map(x => (x , 1)).reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(15), Seconds(10))
//增量处理
//val wordCounts = words.map(x => (x , 1)).reduceByKeyAndWindow(_+_, _-_,Seconds(15), Seconds(10))
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
批处理间隔=5s
窗口长度=15s
滑动间隔=10s
以图为例

第二个窗口计算时,reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])是将time3,time4,time5的数据直接叠加处理,而reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])计算时会利用time3已经计算的结果,然后和time4,time5聚合后,再减去time1,time2的结果。后者总体来说更加高效,但仅仅针对函数可逆这种情况。
join操作
join操作主要是用于数据的联合,分stream-stream和stream-dataset两种。
Stream-stream joins
每个批处理间隔中,stream和stream可以join,
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)
你也可以做 leftOuterJoin,rightOuterJoin,fullOuterJoin. 此外,在 stream(流)的窗口上进行 join 通常是非常有用的。
val windowedStream1 = stream1.window(Seconds(20))
val windowedStream2 = stream2.window(Minutes(1))
val joinedStream = windowedStream1.join(windowedStream2)
Stream-dataset joins
批处理流和dataset数据join,前面解释 DStream.transform 操作时已经在前面演示过了. 这里展示window stream(窗口流)与 dataset 数据join例子.
val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds(20))...
val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }
实际上,您也可以动态更改要加入的 dataset. 提供给 transform 的函数是每个 batch interval(批次间隔)进行评估,因此将使用 dataset 引用指向当前的 dataset.
DStreams 上的输出操作
输出操作允许将 DStream 的数据推送到外部系统, 如数据库或文件系统. 由于输出操作实际上允许外部系统使用变换后的数据, 所以它们触发所有 DStream 变换的实际执行(类似于RDD的动作). 目前, 定义了以下输出操作:
| Output Operation | Meaning |
|---|---|
| print() | Prints the first ten elements of every batch of data in a DStream on the driver node running
the streaming application. This is useful for development and debugging.
|
| saveAsTextFiles(prefix, [suffix]) | Save this DStream's contents as text files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". |
| saveAsObjectFiles(prefix, [suffix]) | Save this DStream's contents as SequenceFiles of serialized Java objects. The file
name at each batch interval is generated based on prefix and
suffix: "prefix-TIME_IN_MS[.suffix]".
|
| saveAsHadoopFiles(prefix, [suffix]) | Save this DStream's contents as Hadoop files. The file name at each batch interval is
generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]".
|
| foreachRDD(func) | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
DataFrame 和 SQL 操作
您在流数据上使用 DataFrames and SQL 和 SQL 操作. 您必须使用 StreamingContext 正在使用的 SparkContext 创建一个 SparkSession.此外, 必须这样做, 以便可以在 driver 故障时重新启动. 这是通过创建一个简单实例化的 SparkSession 单例实例来实现的.这在下面的示例中显示.它使用 DataFrames 和 SQL 来修改早期的字数 示例以生成单词计数.将每个 RDD 转换为 DataFrame, 注册为临时表, 然后使用 SQL 进行查询.
val words: DStream[String] = ...
words.foreachRDD { rdd =>
// Get the singleton instance of SparkSession
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
// Convert RDD[String] to DataFrame
val wordsDataFrame = rdd.toDF("word")
// Create a temporary view
wordsDataFrame.createOrReplaceTempView("words")
// Do word count on DataFrame using SQL and print it
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
}
还可以对来自不同线程的流数据(即异步运行的 StreamingContext )上定义的表运行 SQL 查询. 只需确保您将 StreamingContext 设置为记住足够数量的流数据, 以便查询可以运行. 否则, 不知道任何异步 SQL 查询的 StreamingContext 将在查询完成之前删除旧的流数据. 例如, 如果要查询最后一个批次, 但是您的查询可能需要5分钟才能运行, 则可以调用 streamingContext.remember(Minutes(5))。
缓存 / 持久性
与 RDD 类似, DStreams 还允许开发人员将流的数据保留在内存中. 也就是说, 在 DStream 上使用 persist() 方法会自动将该 DStream 的每个 RDD 保留在内存中. 如果 DStream 中的数据将被多次计算(例如, 相同数据上的多个操作), 这将非常有用. 对于基于窗口的操作, 如 reduceByWindow 和 reduceByKeyAndWindow 以及基于状态的操作, 如 updateStateByKey, 这是隐含的.因此, 基于窗口的操作生成的 DStream 会自动保存在内存中, 而不需要开发人员调用 persist().
对于通过网络接收数据(例如: Kafka, Flume, sockets 等)的输入流, 默认持久性级别被设置为将数据复制到两个节点进行容错.
Checkpointing
streaming 应用程序必须 24/7 运行, 因此必须对应用逻辑无关的故障(例如, 系统故障, JVM 崩溃等)具有弹性. 为了可以这样做, Spark Streaming 需要 checkpoint 足够的信息到容错存储系统, 以便可以从故障中恢复.checkpoint 有两种类型的数据.
- Metadata checkpointing - 将定义 streaming 计算的信息保存到容错存储(如 HDFS)中.这用于从运行 streaming 应用程序的 driver 的节点的故障中恢复(稍后详细讨论). 元数据包括:
Configuration - 用于创建流应用程序的配置.
DStream operations - 定义 streaming 应用程序的 DStream 操作集.
Incomplete batches - 批量的job 排队但尚未完成. - Data checkpointing - 将生成的 RDD 保存到可靠的存储.这在一些将多个批次之间的数据进行组合的 状态 变换中是必需的.在这种转换中, 生成的 RDD 依赖于先前批次的 RDD, 这导致依赖链的长度随时间而增加.为了避免恢复时间的这种无限增加(与依赖关系链成比例), 有状态转换的中间 RDD 会定期 checkpoint 到可靠的存储(例如 HDFS)以切断依赖关系链.
总而言之, 元数据 checkpoint 主要用于从 driver 故障中恢复, 而数据或 RDD checkpoint 对于基本功能(如果使用有状态转换)则是必需的.
何时启用 checkpoint
对于具有以下任一要求的应用程序, 必须启用 checkpoint:
- 使用状态转换 - 如果在应用程序中使用 updateStateByKey或 reduceByKeyAndWindow(具有反向功能), 则必须提供 checkpoint 目录以允许定期的 RDD checkpoint.
- 从运行应用程序的 driver 的故障中恢复 - 元数据 checkpoint 用于使用进度信息进行恢复.
请注意, 无需进行上述有状态转换的简单 streaming 应用程序即可运行, 无需启用 checkpoint. 在这种情况下, 驱动器故障的恢复也将是部分的(一些接收但未处理的数据可能会丢失). 这通常是可以接受的, 许多运行 Spark Streaming 应用程序. 未来对非 Hadoop 环境的支持预计会有所改善.
如何配置 checkpoint
可以通过在保存 checkpoint 信息的容错, 可靠的文件系统(例如, HDFS, S3等)中设置目录来启用 checkpoint. 这是通过使用 streamingContext.checkpoint(checkpointDirectory) 完成的. 这将允许您使用上述有状态转换. 另外, 如果要使应用程序从 driver 故障中恢复, 您应该重写 streaming 应用程序以具有以下行为.
- 当程序第一次启动时, 它将创建一个新的 StreamingContext, 设置所有流, 然后调用 start().
- 当程序在失败后重新启动时, 它将从 checkpoint 目录中的 checkpoint 数据重新创建一个 StreamingContext.
可以通过使用 StreamingContext.getOrCreate 可以简化。
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // new context
val lines = ssc.socketTextStream(...) // create DStreams
...
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
ssc
}
// Get StreamingContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
// Do additional setup on context that needs to be done,
// irrespective of whether it is being started or restarted
context. ...
// Start the context
context.start()
context.awaitTermination()
除了使用 getOrCreate 之外, 还需要确保在失败时自动重新启动 driver 进程. 这只能由用于运行应用程序的部署基础架构完成. 这在 部署 部分进一步讨论.
请注意, RDD 的 checkpoint 会导致保存到可靠存储的成本. 这可能会导致 RDD 得到 checkpoint 的批次的处理时间增加. 因此, 需要仔细设置 checkpoint 的间隔. 在小批量大小(例如: 1秒), 检查每个批次可能会显着降低操作吞吐量. 相反, checkpoint 太少会导致谱系和任务大小增长, 这可能会产生不利影响. 对于需要 RDD checkpoint 的状态转换, 默认间隔是至少10秒的批间隔的倍数. 它可以通过使用 dstream.checkpoint(checkpointInterval) 进行设置. 通常, DStream 的5到10个滑动间隔的 checkpoint 间隔是一个很好的设置
Accumulators, Broadcast 变量, 和 Checkpoint
在Spark Streaming中, 无法从 checkpoint 恢复 Accumulators 和 Broadcast 变量 . 如果启用 checkpoint 并使用 Accumulators 或 Broadcast 变量 , 则必须为 Accumulators 和 Broadcast 变量 创建延迟实例化的单例实例, 以便在 driver 重新启动失败后重新实例化. 这在下面的示例中显示:
object WordBlacklist {
@volatile private var instance: Broadcast[Seq[String]] = null
def getInstance(sc: SparkContext): Broadcast[Seq[String]] = {
if (instance == null) {
synchronized {
if (instance == null) {
val wordBlacklist = Seq("a", "b", "c")
instance = sc.broadcast(wordBlacklist)
}
}
}
instance
}
}
object DroppedWordsCounter {
@volatile private var instance: LongAccumulator = null
def getInstance(sc: SparkContext): LongAccumulator = {
if (instance == null) {
synchronized {
if (instance == null) {
instance = sc.longAccumulator("WordsInBlacklistCounter")
}
}
}
instance
}
}
wordCounts.foreachRDD { (rdd: RDD[(String, Int)], time: Time) =>
// Get or register the blacklist Broadcast
val blacklist = WordBlacklist.getInstance(rdd.sparkContext)
// Get or register the droppedWordsCounter Accumulator
val droppedWordsCounter = DroppedWordsCounter.getInstance(rdd.sparkContext)
// Use blacklist to drop words and use droppedWordsCounter to count them
val counts = rdd.filter { case (word, count) =>
if (blacklist.value.contains(word)) {
droppedWordsCounter.add(count)
false
} else {
true
}
}.collect().mkString("[", ", ", "]")
val output = "Counts at time " + time + " " + counts
})
应用程序部署
Monitoring Applications (监控应用程序)
性能调优
在集群上的 Spark Streaming application 中获得最佳性能需要一些调整.本节介绍了可调整的多个 参数和配置提高你的应用程序性能.在高层次上, 你需要考虑两件事情:
-
通过有效利用集群资源, Reducing the processing time of each batch of data (减少每批数据的处理时间).
-
设置正确的 batch size (批量大小), 以便 batches of data (批量的数据)可以像 received (被接收)处理一样快(即 data processing (数据处理)与 data ingestion (数据摄取)保持一致).
Reducing the Batch Processing Times (减少批处理时间)
在 Spark 中可以进行一些优化, 以最小化每批处理时间,可参考http://spark.apachecn.org/docs/cn/2.2.0/tuning.html
数据接收中的并行级别
通过网络接收数据需要考虑反序列化数据并存储在spark中,如果数据接收称为系统的瓶颈,则考虑并行化接收数据。注意每个input DStream创建接收单个数据流的单个接收器。因此可以通过创建多个input DStreams,配置多个接收数据流来从数据源的不同分区中接收数据。
val numStreams = 5
val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...) }
val unifiedStream = streamingContext.union(kafkaStreams)
unifiedStream.print()
此外,应考虑的另一个参数是 接收器的块间隔, 这由spark.streaming.blockInterval 决定.对于大多数 receivers 接收器, 接收到的数据合并在一起存储在 Spark 内存之前的 数据块.每个批次中的块数将用于确定用户处理接收数据的任务(transformation)的数量,每个接收器单批次的任务数量将是大约批间隔/ 块间隔。例如, 200 ms的 block interval (块间隔)每 2 秒 batches (批次)创建 10 个 tasks (任务).如果 tasks (任务)数量太少(即少于每个机器的内核数量), 那么它将无效, 因为所有可用的内核都不会被使用处理数据.要增加 given batch interval (给定批间隔)的 tasks (任务)数量, 请减少 block interval (块间隔).但是, 推荐的 block interval (块间隔)最小值约为 50ms , 低于此任务启动开销可能是一个问题.
使用 multiple input streams (多个输入流)/ receivers (接收器)接收数据的替代方法是明确 repartition (重新分配) input data stream (输入数据流)(使用 inputStream.repartition(
Level of Parallelism in Data Processing (数据处理中的并行度水平)
如果在任何计算阶段中使用并行任务的数量, 则集群资源可能未得到充分利用. 例如, 对于分布式 reduce操作, 如 reduceByKey 和 reduceByKeyAndWindow , 默认并行任务的数量由 spark.default.parallelism 控制.默认配置参数较小为8,为充分利用集群资源,需要通过 spark.default.parallelism configuration property 更改默认值.
数据序列化
可以通过优化序列化格式来减少数据序列化的开销.在 streaming 的情况下, 有两种类型的数据被 serialized (序列化).
-
Input data (输入数据): 默认情况下, 通过 Receivers 接收的 input data (输入数据)通过 StorageLevel.MEMORY_AND_DISK_SER_2 存储在 executors 的内存中.也就是说, 将数据 serialized (序列化)为 bytes (字节)以减少 GC 开销, 并复制以容忍 executor failures (执行器故障).此外, 数据首先保留在内存中, 并且只有在内存不足以容纳 streaming computation (流计算)所需的所有输入数据时才会 spilled over (溢出)到磁盘.这个 serialization (序列化)显然具有开销 - receiver (接收器)必须使接收的数据 deserialize (反序列化), 并使用 Spark 的 serialization format (序列化格式)重新序列化它.
-
Persisted RDDs generated by Streaming Operations (流式操作生成的持久 RDDs): 通过 streaming computations (流式计算)生成的 RDD 可能会持久存储在内存中.例如, window operations (窗口操作)会将数据保留在内存中, 因为它们将被处理多次.但是, 与 StorageLevel.MEMORY_ONLY 的 Spark Core 默认情况不同, 通过流式计算生成的持久化 RDD 将以 StorageLevel.MEMORY_ONLY_SER (即序列化), 以最小化 GC 开销.
在这两种情况下, 使用 Kryo serialization (Kryo 序列化)可以减少 CPU 和内存开销.有关详细信息, 请参阅 Spark Tuning Guide .对于 Kryo , 请考虑 registering custom classes , 并禁用对象引用跟踪(请参阅 Configuration Guide 中的 Kryo 相关配置).
在 streaming application 需要保留的数据量不大的特定情况下, 可以将数据(两种类型)作为 deserialized objects (反序列化对象)持久化, 而不会导致过多的 GC 开销.例如, 如果您使用几秒钟的 batch intervals (批次间隔)并且没有 window operations (窗口操作), 那么可以通过明确地相应地设置 storage level (存储级别)来尝试禁用 serialization in persisted data (持久化数据中的序列化).这将减少由于序列化造成的 CPU 开销, 潜在地提高性能, 而不需要太多的 GC 开销.
Task Launching Overheads (任务启动开销)
如果每秒启动的任务数量很高(比如每秒 50 个或更多), 那么这个开销向 slaves 发送任务可能是重要的, 并且将难以实现 sub-second latencies (次要的延迟).可以通过以下更改减少开销:
- Execution mode (执行模式): 以 Standalone mode (独立模式)或 coarse-grained Mesos 模式运行 Spark 比 fine-grained Mesos 模式更好的任务启动时间.有关详细信息, 请参阅 Running on Mesos guide .
这些更改可能会将批处理时间缩短 100 毫秒, 从而允许 sub-second batch size (次秒批次大小)是可行的.
Setting the Right Batch Interval (设置正确的批次间隔)
对于在集群上稳定地运行的spark streaming应用, 应该保证数据尽可能快地被接收和处理.即 processing time批处理处理时间)应小于 batch interval (批间隔).
取决于 streaming computation (流式计算)的性质, 使用的 batch interval (批次间隔)可能对处理由应用程序持续一组固定的 cluster resources (集群资源)的数据速率有重大的影响.例如, 让我们考虑早期的 WordCountNetwork 示例.对于特定的 data rate (数据速率), 系统可能能够跟踪每 2 秒报告 word counts (即 2 秒的 batch interval (批次间隔)), 但不能每 500 毫秒.因此, 需要设置 batch interval (批次间隔), 使预期的数据速率在生产可以持续.
为您的应用程序找出正确的 batch size (批量大小)的一个好方法是使用进行测试 conservative batch interval (保守的批次间隔)(例如 5-10 秒)和 low data rate (低数据速率).验证是否系统能够跟上 data rate (数据速率), 可以检查遇到的 end-to-end delay (端到端延迟)的值通过每个 processed batch (处理的批次)(在 Spark driver log4j 日志中查找 “Total delay” , 或使用 StreamingListener 接口). 如果 delay (延迟)保持与 batch size (批量大小)相当, 那么系统是稳定的.除此以外, 如果延迟不断增加, 则意味着系统无法跟上, 因此不稳定.一旦你有一个 stable configuration (稳定的配置)的想法, 你可以尝试增加 data rate and/or 减少 batch size .请注意, momentary increase (瞬时增加)由于延迟暂时增加只要延迟降低到 low value (低值), 临时数据速率增加就可以很好(即, 小于 batch size (批量大小)).
Memory Tuning (内存调优)
调整 Spark 应用程序的内存使用情况和 GC behavior 已经有很多的讨论在 Tuning Guide 中.我们强烈建议您阅读一下.在本节中, 我们将在 Spark Streaming applications 的上下文中讨论一些 tuning parameters (调优参数).
Spark Streaming application 所需的集群内存量在很大程度上取决于所使用的 transformations 类型.例如, 如果要在最近 10 分钟的数据中使用 window operation (窗口操作), 那么您的集群应该有足够的内存来容纳内存中 10 分钟的数据.或者如果要使用大量 keys 的 updateStateByKey , 那么必要的内存将会很高.相反, 如果你想做一个简单的 map-filter-store 操作, 那么所需的内存就会很低.
一般来说, 由于通过 receivers (接收器)接收的数据与 StorageLevel.MEMORY_AND_DISK_SER_2 一起存储, 所以不适合内存的数据将会 spill over (溢出)到磁盘上.这可能会降低 streaming application (流式应用程序)的性能, 因此建议您提供足够的 streaming application (流量应用程序)所需的内存.最好仔细查看内存使用量并相应地进行估算.
memory tuning (内存调优)的另一个方面是 garbage collection (垃圾收集).对于需要低延迟的 streaming application , 由 JVM Garbage Collection 引起的大量暂停是不希望的.
有几个 parameters (参数)可以帮助您调整 memory usage (内存使用量)和 GC 开销:
-
Persistence Level of DStreams (DStreams 的持久性级别): 如前面在 Data Serialization 部分中所述, input data 和 RDD 默认保持为 serialized bytes (序列化字节).与 deserialized persistence (反序列化持久性)相比, 这减少了内存使用量和 GC 开销.启用 Kryo serialization 进一步减少了 serialized sizes (序列化大小)和 memory usage (内存使用).可以通过 compression (压缩)来实现内存使用的进一步减少(参见Spark配置 spark.rdd.compress ), 代价是 CPU 时间.
-
Clearing old data (清除旧数据): 默认情况下, DStream 转换生成的所有 input data 和 persisted RDDs 将自动清除. Spark Streaming 决定何时根据所使用的 transformations (转换)来清除数据.例如, 如果您使用 10 分钟的 window operation (窗口操作), 则 Spark Streaming 将保留最近 10 分钟的数据, 并主动丢弃旧数据. 数据可以通过设置 streamingContext.remember 保持更长的持续时间(例如交互式查询旧数据).
-
CMS Garbage Collector (CMS垃圾收集器): 强烈建议使用 concurrent mark-and-sweep GC , 以保持 GC 相关的暂停始终如一.即使 concurrent GC 已知可以减少 系统的整体处理吞吐量, 其使用仍然建议实现更多一致的 batch processing times (批处理时间).确保在 driver (使用 --driver-java-options 在 spark-submit 中 )和 executors (使用 Spark configuration spark.executor.extraJavaOptions )中设置 CMS GC.
-
Other tips (其他提示): 为了进一步降低 GC 开销, 以下是一些更多的提示.
使用 OFF_HEAP 存储级别的保持 RDDs .在 Spark Programming Guide 中查看更多详细信息.
使用更小的 heap sizes 的 executors.这将降低每个 JVM heap 内的 GC 压力.
需要记住的是:
-
DStream 与 single receiver (单个接收器)相关联.为了获得读取并行性, 需要创建多个 receivers , 即 multiple DStreams .receiver 在一个 executor 中运行.它占据一个 core (内核).确保在 receiver slots are booked 后有足够的内核进行处理, 即 spark.cores.max 应该考虑 receiver slots . receivers 以循环方式分配给 executors .
-
当从 stream source 接收到数据时, receiver 创建数据 blocks (块).每个 blockInterval 毫秒生成一个新的数据块.在 N = batchInterval/blockInterval 的 batchInterval 期间创建 N 个数据块.这些块由当前 executor 的 BlockManager 分发给其他执行程序的 block managers .之后, 在驱动程序上运行的 Network Input Tracker (网络输入跟踪器)通知有关进一步处理的块位置
-
在驱动程序中为在 batchInterval 期间创建的块创建一个 RDD .在 batchInterval 期间生成的块是 RDD 的 partitions .每个分区都是一个 spark 中的 task. blockInterval == batchinterval 意味着创建 single partition (单个分区), 并且可能在本地进行处理.
-
除非 non-local scheduling (非本地调度)进行, 否则块上的 map tasks (映射任务)将在 executors (接收 block, 复制块的另一个块)中进行处理.具有更大的 block interval (块间隔)意味着更大的块. spark.locality.wait 的高值增加了处理 local node (本地节点)上的块的机会.需要在这两个参数之间找到平衡, 以确保在本地处理较大的块.
-
而不是依赖于 batchInterval 和 blockInterval , 您可以通过调用 inputDstream.repartition(n) 来定义 number of partitions (分区数).这样可以随机重新组合 RDD 中的数据, 创建 n 个分区.是的, 为了更大的 parallelism (并行性).虽然是 shuffle 的代价. RDD 的处理由 driver’s jobscheduler 作为一项工作安排.在给定的时间点, 只有一个 job 是 active 的.因此, 如果一个作业正在执行, 则其他作业将排队.
-
如果您有两个 dstream , 将会有两个 RDD 形成, 并且将创建两个将被安排在另一个之后的作业.为了避免这种情况, 你可以联合两个 dstream .这将确保为 dstream 的两个 RDD 形成一个 unionRDD .这个 unionRDD 然后被认为是一个 single job (单一的工作).但 RDD 的 partitioning (分区)不受影响.
-
如果 batch processing time (批处理时间)超过 batchinterval (批次间隔), 那么显然 receiver 的内存将会开始填满, 最终会抛出 exceptions (最可能是 BlockNotFoundException ).目前没有办法暂停 receiver .使用 SparkConf 配置 spark.streaming.receiver.maxRate , receiver 的 rate 可以受到限制.
关于作者
爱编程、爱钻研、爱分享、爱生活
关注分布式、高并发、数据挖掘
如需捐赠,请扫码
