ELK : ELK是ElasticSearch,LogStash以及Kibana三个产品的首字母缩写
一.倒排索引
学习elk,必须先掌握倒排索引思想,
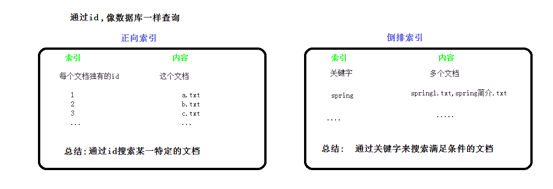
参考文档: https://www.cnblogs.com/zlslch/p/6440114.html
二.什么是全文检索?
诸如传统的正序查询(数据库查询),如果用到京东或淘宝上,用户输入关键字进行查询,无论是标题还是描述只要有关键字就会被查到,很伤!倒排索引能很好的实现电商搜索功能
结构化数据:有固定格式和有限长度 比如 关系型数据库中的数据
查询的方式:sql
如果数据量特别大时:可以使用全文检索技术
非结构化数据:没有固定格式和没有规定长度 比如电脑上的文档 txt word
查询的方式:肉眼查找
如果数据量特别大时:可以使用全文检索技术
三.什么是全文检索技术
3.1全文检索技术:
这种先建立索引,再对索引进行搜索的过程就叫做全文检索
3.2 那些场景用到全文检索技术?
1、搜索引擎 谷歌 百度 360 搜狗 搜搜
2、站内搜索 京东 天猫 微博 天涯 猫扑
3、垂直搜索 视频网站的搜索 优酷,( 在优酷可以搜索到其他视频网站的视频)
四.引入lucene
lucene可以实现全文检索,
Lucene是Apache提供用来实现全文检索的一套类库 jar
五.lucene的使用
5.1需要的坐标
第一步:导入jar
必须的包:lucene-core-4.10.3.jar
lucene-analyzers-common-4.10.3.jar 分词器
commons-io.jar
junit.jar
|
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>4.10.3</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
|
5.2创建索引
- 获取原始文档
- 构建索引文档对象
- 分析文档(分词)
- 创建索引
具体代码示例:
|
/***
* //查询索引分析
// 1.创建一个Directory对象,也就是索引库存放的位置
// 2. 创建一个indexReader对象,需要制定Directory对象
// 3. 创建一个indexSearcher对象,需要指定indexReader对象
// 4. 创建一个TremQuery对象,制定查询的域和查询的关键字
// 5. 执行查询
// 6. 返回查询结果,遍历查询结果并输出
// 7. 关闭indexReader对象
*/
public static void selectIndex(String keywords) throws IOException {
//查询索引分析
// 1.创建一个Directory对象,也就是索引库存放的位置
Directory directory=FSDirectory.open(new File("D:\Documents\Downloads\day02_lucene\索引存放位置"));
// 2. 创建一个indexReader对象,需要指定Directory对象
IndexReader indexReader=
DirectoryReader.open(directory);
// 3. 创建一个indexSearcher对象,需要指定indexReader对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
// 4. 创建一个TremQuery对象,制定查询的域和查询的关键字
Query termQuery=new TermQuery(new Term("filename",keywords));
// 5. 执行查询
TopDocs search =
indexSearcher.search(termQuery, 10);
// 6. 返回查询结果,遍历查询结果并输出
//查询结果的总条数
System.out.println("查询结果的总条数"+search.totalHits);
//遍历查询结果
for (ScoreDoc scoreDoc : search.scoreDocs) {
//scoreDoc.doc就是document的id
Document
document=indexSearcher.doc(scoreDoc.doc);
//通过document对象展示出所有结果信息
System.out.println("filename="+document.get("filename"));
System.out.println("filepath="+document.get("filepath"));
System.out.println("filesize="+document.get("filesize"));
//
System.out.println("filecontent="+document.get("filecontent"));
//来一个分割符
System.out.println("=================================================");
}
// 7. 关闭indexReader对象
indexReader.close();
}
|
5.3 查询索引
1. 创建用户查询接口,提供一个输入关键字的地方
2. 创建查询
3. 执行查询
4. 渲染结果
具体代码示例:
|
/***
* //查询索引分析
// 1.创建一个Directory对象,也就是索引库存放的位置
// 2. 创建一个indexReader对象,需要制定Directory对象
// 3. 创建一个indexSearcher对象,需要指定indexReader对象
// 4. 创建一个TremQuery对象,制定查询的域和查询的关键字
// 5. 执行查询
// 6. 返回查询结果,遍历查询结果并输出
// 7. 关闭indexReader对象
*/
public static void selectIndex(String keywords) throws IOException {
//查询索引分析
// 1.创建一个Directory对象,也就是索引库存放的位置
Directory directory=FSDirectory.open(new File("D:\Documents\Downloads\day02_lucene\索引存放位置"));
// 2. 创建一个indexReader对象,需要指定Directory对象
IndexReader indexReader=
DirectoryReader.open(directory);
// 3. 创建一个indexSearcher对象,需要指定indexReader对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
// 4. 创建一个TremQuery对象,制定查询的域和查询的关键字
Query
termQuery=new TermQuery(new Term("filename",keywords));
// 5. 执行查询
TopDocs search =
indexSearcher.search(termQuery, 10);
// 6. 返回查询结果,遍历查询结果并输出
//查询结果的总条数
System.out.println("查询结果的总条数"+search.totalHits);
//遍历查询结果
for (ScoreDoc scoreDoc : search.scoreDocs) {
//scoreDoc.doc就是document的id
Document
document=indexSearcher.doc(scoreDoc.doc);
//通过document对象展示出所有结果信息
System.out.println("filename="+document.get("filename"));
System.out.println("filepath="+document.get("filepath"));
System.out.println("filesize="+document.get("filesize"));
//
System.out.println("filecontent="+document.get("filecontent"));
//来一个分割符
System.out.println("=================================================");
}
// 7. 关闭indexReader对象
indexReader.close();
}
|
六.分词器
如果检索的是英文,分词器使用标准的就可以,但是外国人编写的中文分词器总是不成功,
这里使用IK-analyzer
StandardAnalyzer:一个字一个字的
CJKAnalyzer:两个字两个字 需要添加
lucene-analyzers-smartcn依赖
SmartChineseAnalyzer:对中文的支持还算可以,但是英文有缺失字母的情况
第三方分词器:IK-analyzer
依赖是:
|
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
<exclusions>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
</exclusion>
</exclusions>
</dependency>
|
需要三个配置文件
IKAnalyzer.cfg.xml 核心配置文件
ext.dic 扩展词典
stopword.dic 停用词典
七. 使用分词器进行查询
public static void selectIndex(String keywords) throws IOException, ParseException {
//查询索引分析
// 1.创建一个Directory对象,也就是索引库存放的位置
Directory directory=FSDirectory.open(new File("D:\Documents\Downloads\day02_lucene\索引存放位置"));
// 2. 创建一个indexReader对象,需要指定Directory对象
IndexReader indexReader= DirectoryReader.open(directory);
// 3. 创建一个indexSearcher对象,需要指定indexReader对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
// 4. 创建一个TremQuery对象,制定查询的域和查询的关键字
//创建一个分词器
Analyzer analyzer=new IKAnalyzer();
//几种查询
//精确查询
// Query termQuery=new TermQuery(new Term("filename",keywords));
// //通配符查询,只要包含关键字都可以
// Query termQuery=new WildcardQuery(new Term("filename","*"+keywords+"*"));
// //模糊查询,容错性高
// Query termQuery=new FuzzyQuery(new Term("filename",keywords));
/* //通配符查询,只要包含关键字都可以
Query termQuery1=new WildcardQuery(new Term("filename","*"+keywords+"*"));
//模糊查询,容错性高
Query termQuery2=new FuzzyQuery(new Term("filename",keywords));
//BooleanQuery 查询,可以查询多个条件
BooleanQuery termQuery=new BooleanQuery();
termQuery.add(termQuery1, BooleanClause.Occur.MUST);//must表示必须满足
termQuery.add(termQuery2, BooleanClause.Occur.SHOULD);//其他条件查询完,如果满足本条件,则添加
//must_not 表示必须不满足才执行*/
//分词查询
//1. 一个域的查询,如上
//2. 多个域的查询
QueryParser queryParser=new MultiFieldQueryParser(new String[]{"filename","filecontent"},analyzer);
Query termQuery=queryParser.parse(keywords);
// 5. 执行查询
TopDocs search = indexSearcher.search(termQuery, 10);
// 6. 返回查询结果,遍历查询结果并输出
//查询结果的总条数
System.out.println("查询结果的总条数"+search.totalHits);
//遍历查询结果
for (ScoreDoc scoreDoc : search.scoreDocs) {
//scoreDoc.doc就是document的id
Document document=indexSearcher.doc(scoreDoc.doc);
//通过document对象展示出所有结果信息
System.out.println("filename="+document.get("filename"));
System.out.println("filepath="+document.get("filepath"));
System.out.println("filesize="+document.get("filesize"));
// System.out.println("filecontent="+document.get("filecontent"));
//来一个分割符
System.out.println("=================================================");
}
// 7. 关闭indexReader对象
indexReader.close();
}
|
八. 打分
关键字占的比重及权重
举例说明
关键字占的比例即权重
spring.txt 分词后的结果:spring txt 50%
spring_README.txt 分词后的结果:spring README txt 33%
spring的简介.txt 分词后的结果:spring 简介 简 介 txt 20%
spring是个非常流行的框架.txt
spring是个开发中非常流行的框架.txt
问题
为什么百度搜索时权重较低的广告可以排在最前面?
设置权重
可以设置boost值 默认是1.0
在添加索引的时候设置权重
Field fileContentField=new TextField("filecontent",fileContent,Field.Store.YES);
//权重默认是1.0,越大权重越高
fileContentField.setBoost(1.5f);
Field filePathField=new StringField("filepath",filePath,Field.Store.YES);
Field fileNameField=new TextField("fileName",fileName,Field.Store.YES);
Field filesizeField=new LongField("filesize",fileSize,Field.Store.YES);
|