一.前言
在做神经网络的训练学习过程中,一开始,经常是喜欢用二次代价函数来做损失函数,因为比较通俗易懂,后面在大部分的项目实践中却很少用到二次代价函数作为损失函数,而是用交叉熵作为损失函数。为什么?一直在思考这个问题,这两者有什么区别,那个更好?下面通过数学的角度来解释下。
思考:
1.我们希望我们损失函数能够做到,当我们预测的值跟目标值越远时,在修改参数时候,减去一个更大的值,做到更加快速的下降。
2.哪个函数更不容易陷入局部最优解
二.两种代价函数的表达式
二次代价损失函数:
交叉熵损失函数:
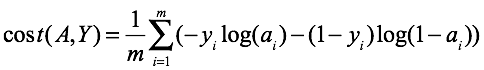
针对二分类来说,其中:
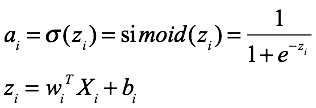
ai第Xi个样本经过前向传播之后到达最后一个节点的值
三.收敛速度比较
两个函数反向传播梯度比较
1.二次代价函数
为了方便只取一个样本,那么损失为:

那么w,b的梯度为:
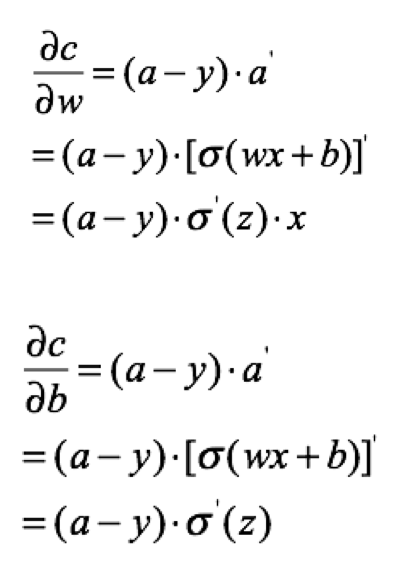
2.交叉熵
为了方便只取一个样本,损失为:
计算w,b的梯度:

分析和结论
由此可看出,在做后向传播时
1.对于square mean在更新w,b时候,w,b的梯度跟激活函数的梯度成正比,激活函数梯度越大,w,b调整就越快,训练收敛就越快,但是Simoid函数在值非常高时候,梯度是很小的,比较平缓。
2.对于cross entropy在更新w,b时候,w,b的梯度跟激活函数的梯度没有关系了,bz已经表抵消掉了,其中bz-y表示的是预测值跟实际值差距,如果差距越大,那么w,b调整就越快,收敛就越快。
四.两个损失函数的函数图像
square mean:
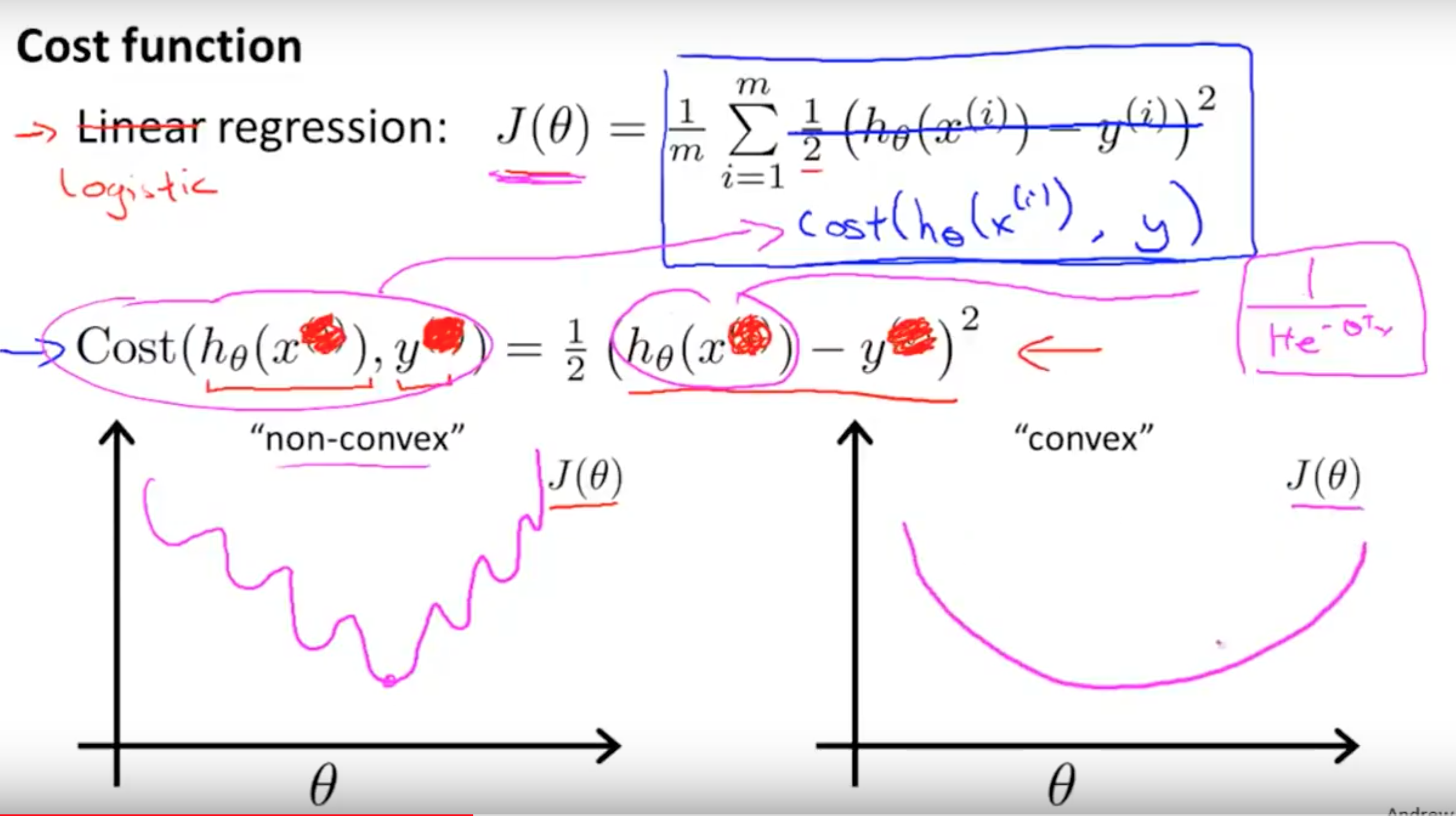
交叉熵:
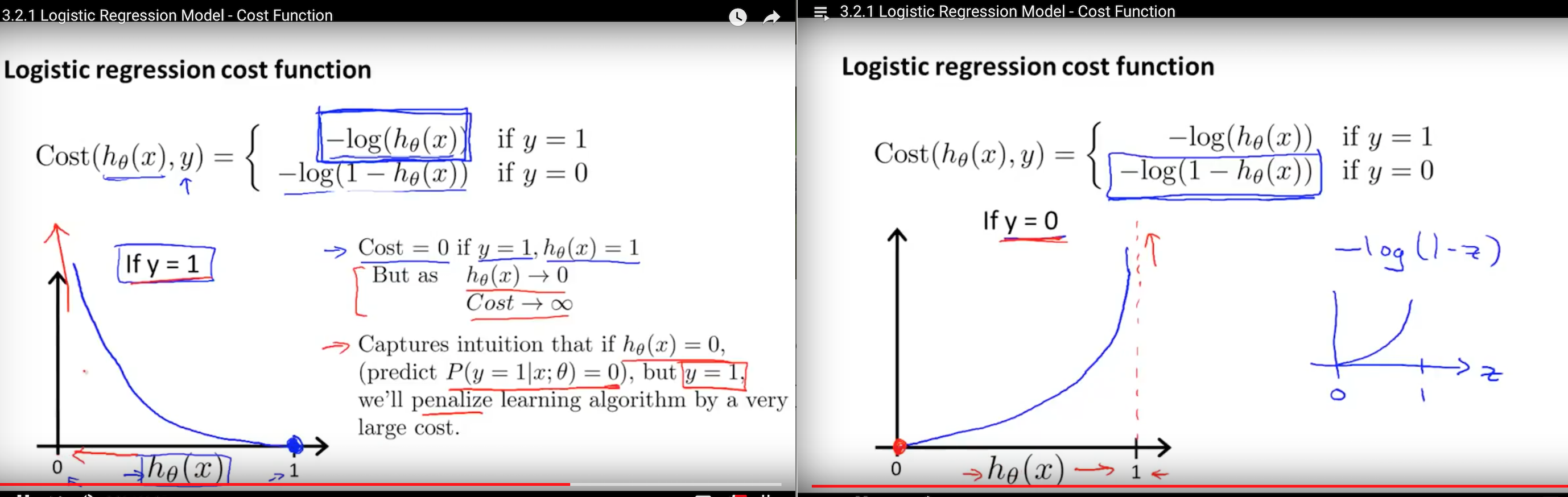
(这两个图是从吴恩达课程中截取出来的)可以看出,二次代价函数存在很多局部最小点,而交叉熵就不会。
附录:
simoid函数的导数:
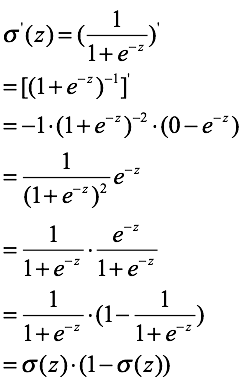
参考: