特殊视图类的继承流和路径如图所示:
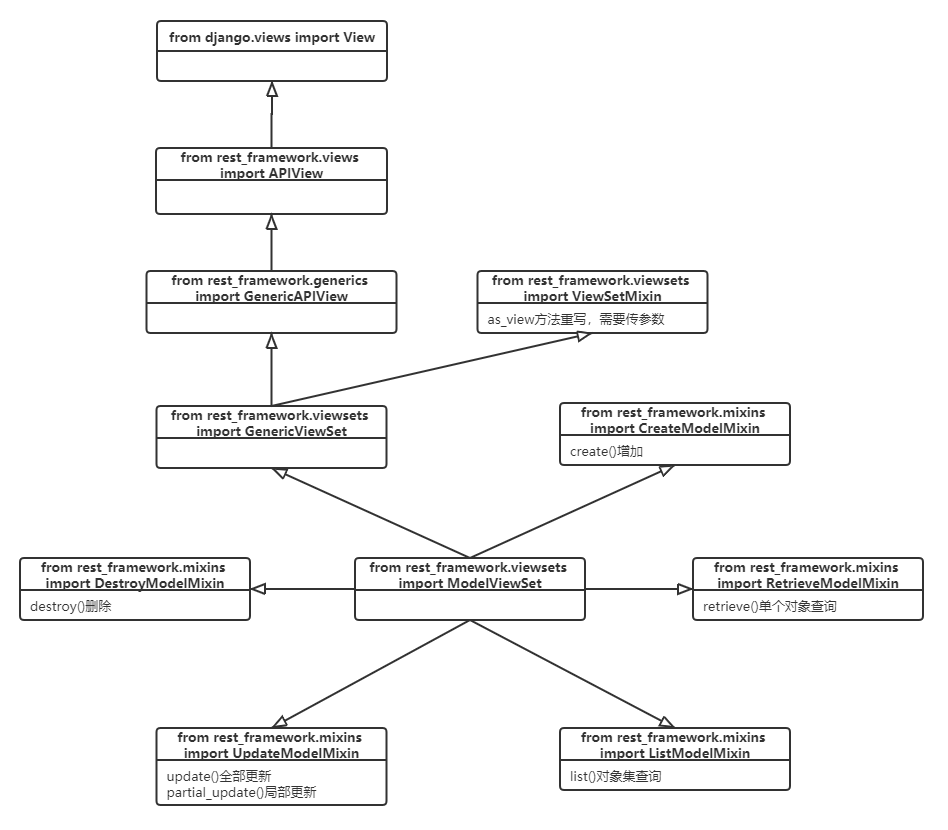
视图类在最先继承的时候是继承Django框架提供的View类,之后是restframework中提供了APIView类,这个是直接继承了View类,APIView的基本使用以及流程,前几篇已经做过描述。GenericAPIView(from rest_framework.generic import GenericAPIView):这个类是直接继承APIView的类,功能只是封装了一些基本使用,我们以上篇的分页博客为例,博主附上相关的代码
# 自定义的序列化类 from rest_framework import serializer class PagerSerializer(serializer.ModelSerializer): class Meta: model = Role fields = "__all__" # 自定义的分页类 from rest_framework.pagination import PageNumberPagination class MyPagination(PageNumberPagination): # 页面显示的数据条数 page_size = 2 # 页码请求地址上的url的get参数名称 page_query_param = "size" # 页面允许显示的最多数据条数 max_page_size = 8 # 自定义的视图类 from rest_framework.response import Response class RoleView(APIView): def get(self, request, *args, **kwargs): roles = Role.object.all() # 将得到的所有数据分好页 pg = MyPagination() role_pages = pg.paginate_queryset(queryset=roles, request=request, view=self) # 将分好页的数据放置分页序列化器中即可 ser = PagerSerializer(instance=role_oages, many=True) # 这种只会返回数据 # return Response(ser.data) # 这种就会额外显示上下页url地址和总记录数 return pg.get_paginated_response(ser.data)
接下来会定义一个继承GenericAPIView父类的视图类来代替上面的视图类。query_set指定获取的数据集,serializer_class指定序列化类,pagination_class指定分页类。指定这些必要的属性之后,一切的准备工作GenericAPIView类已经封装好了
from rest_framework.generic import GenericAPIView class RoleView(GenericAPIView): queryset = Role.object.all() serializer_class = PagerSerializer pagination_class = MyPagination def get(self, request, *args, **kwargs): roles = self.get_queryset() role_pages = self.paginate_queryset(roles) ser = self.get_serializer(instance=role_pages, many=True) return Response(ser.data)
博主附上GenericAPIView类的源码及中文注释,上面的视图类方法的调用是调用源码的方法。但是在实际开发的业务是比较复杂的,所以继承这个类是没有太多的用处,因为这个的局限性比较大。


class GenericAPIView(views.APIView): # 指定查询的数据集 queryset = None # 指定序列化类 serializer_class = None # If you want to use object lookups other than pk, set 'lookup_field'. # For more complex lookup requirements override `get_object()`. # 这两个变量在反向生成url会使用到 lookup_field = 'pk' lookup_url_kwarg = None # 可以理解为查询的过滤条件 filter_backends = api_settings.DEFAULT_FILTER_BACKENDS # 指定分页类 pagination_class = api_settings.DEFAULT_PAGINATION_CLASS def get_queryset(self): # 这个方法是获取查询集 assert self.queryset is not None, ( "'%s' should either include a `queryset` attribute, " "or override the `get_queryset()` method." % self.__class__.__name__ ) queryset = self.queryset if isinstance(queryset, QuerySet): # Ensure queryset is re-evaluated on each request. # 这个就是查询集 queryset = queryset.all() return queryset def get_object(self): # 这个方法就是根据过滤条件获取单个对象 queryset = self.filter_queryset(self.get_queryset()) # Perform the lookup filtering. # 返回其中的一个值,值的决定是基于下面式子终止的出口 lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field assert lookup_url_kwarg in self.kwargs, ( 'Expected view %s to be called with a URL keyword argument ' 'named "%s". Fix your URL conf, or set the `.lookup_field` ' 'attribute on the view correctly.' % (self.__class__.__name__, lookup_url_kwarg) ) # 根据参数以及参数的值去获取对象,如果没有就返回404页面 filter_kwargs = {self.lookup_field: self.kwargs[lookup_url_kwarg]} obj = get_object_or_404(queryset, **filter_kwargs) # May raise a permission denied # 这个方法会跳转到权限验证类中,类中有一个方法就是has_object_permissions方法 # 会验证当前对象是否有权限 self.check_object_permissions(self.request, obj) return obj def get_serializer(self, *args, **kwargs): # 实例化序列化类对象 serializer_class = self.get_serializer_class() # 将相关参数放置在context中 kwargs['context'] = self.get_serializer_context() return serializer_class(*args, **kwargs) def get_serializer_class(self): # 获取序列化类 assert self.serializer_class is not None, ( "'%s' should either include a `serializer_class` attribute, " "or override the `get_serializer_class()` method." % self.__class__.__name__ ) return self.serializer_class def get_serializer_context(self): """ Extra context provided to the serializer class. """ return { 'request': self.request, 'format': self.format_kwarg, 'view': self } # 这个源码注释中提及方法不常用,就是根据条件获取单个查询对象 def filter_queryset(self, queryset): for backend in list(self.filter_backends): queryset = backend().filter_queryset(self.request, queryset, self) return queryset @property def paginator(self): # 实例化分页类对象 if not hasattr(self, '_paginator'): if self.pagination_class is None: self._paginator = None else: self._paginator = self.pagination_class() return self._paginator def paginate_queryset(self, queryset): # 如果分页类对象为空,就返回空,否则就获取的数据集分页 if self.paginator is None: return None return self.paginator.paginate_queryset(queryset, self.request, view=self) def get_paginated_response(self, data): # 这个方法就是额外显示上下一页url地址和总记录数 assert self.paginator is not None return self.paginator.get_paginated_response(data)
请求视图类还可以继承GenericViewSet类,而这个类的父类是ViewSetMixin和GenericAPIView,但是ViewSetMixin类是重写了as_view方法,而且这个类在最开始的注释中已经给予描述MyViewSet.as_view({'get': 'list', 'post': 'create'}),也就是说我们需要在路由上的as_view方法添加参数:键表示用户请求的方式,值表示请求视图类的方法名称,其他属性或者方法都会使用GenericAPIView类中的。那么自定义一个请求试图类和上面的区别在于路由的不同和方法名称的不同,路由上的as_view()方法添加参数{"get", "list"},请求试图类如下
from rest_framework.viewsets import GenericViewSet class RoleView(GenericViewSet): queryset = Role.object.all() serializer_class = PagerSerializer pagination_class = MyPagination def list(self, request, *args, **kwargs): roles = self.get_queryset() role_pages = self.paginate_queryset(roles) ser = self.get_serializer(instance=role_pages, many=True) return Response(ser.data)
如果请求视图类继承了ModelViewSet类时,那么这个类的功能就极其丰富了,因为ModelViewSet的父类有六个,分别对应CreateModelMixin(增加)、DestroyModelMixin(删除)、UpdateModelMixin(修改)、ListModelMixin(查询集为list)、RetrieveModelMixin(查询单个对象)、GenericViewSet。前五个父类中有相对应功能的方法create增加、destroy删除、update,partial_updare全局和局部修改、list查询、retrieve查询等,由于还继承了GenericViewSet类,那么as_view方法参数还是要添加的,根据查询条件,我们可以分为两类(以id为条件):增加和list查询为一类,删除、修改、单对象查询为一类,那么路由可以写两种:url(r'v1/role/', views.RoleView.as_view({"get":"list", "post":"create"}), name="role"),url(r'v1/role/?P<pk>d+', views.RoleView.as_view({"get":"retrieve", "delete":"destroy", "put":"update", "patch":"partial_update"}), name="role")。对于这种需求,我们只需要写一个视图类即可实现以上描述的功能,视图类如下:
from rest_framework.viewsets import ModelViewSet class RoleView(ModelViewSet): queryset = Role.object.all() serializer_class = PagerSerializer pagination_class = MyPagination
但是视图类只想要部分功能,可继承部分类也行的,类的导入路径可参考顶部类图。